
このブログ記事では以下を確認できます:
- AIエージェントの定義。
- AIエージェントの仕組みと主要構成要素
- 知能と行動に基づくAIエージェントの主要な種類。
- AIエージェント構築に必要な全ステップ。
- AIエージェント開発に最適な技術スタック。
- 実世界のエージェント事例。
さあ、始めましょう!
AIエージェントとは?
AIエージェントとは、人間の介入がほとんど、あるいは全くない状態で(ヒューマン・イン・ザ・ループシナリオを除く)、ツールを活用し意思決定を行い、目標を達成するために自律的にタスクを実行できるソフトウェアシステムです。
目標達成のため、AIエージェントは通常、複数の処理ステップを調整し、記憶を活用し、API、データベース、サードパーティ製ソリューションなどの外部ツールと連携することで、計画を立て、推論し、行動を適応させます。
AIエージェントの仕組みと構成要素
AIエージェントは、一般的に複雑で複数のステップを伴う目標達成を目的とした自律的なサイクルを実行することで動作します。そのためには、環境を認識し、アクセス可能または取得した情報について推論し、行動を起こし、結果から学習する必要があります。このサイクルは、目標が達成されたと判断するまで継続されます。
単一のタスクを実行する従来のLLM呼び出しとは異なり、AIエージェントは戦略を適応させ、失敗から学びながら、多段階の問題解決に取り組むことができます。
AIエージェントの挙動は、特に基盤となる概念的アーキテクチャを含む様々な要因に依存する。大まかに言えば、そのワークフローは知覚・推論・行動・学習などのフェーズからなるループで構成される。これらのフェーズが連携することで、エージェントは自律的に目標を追求できる。
技術的な観点では、エージェントは目標検証に基づく終了条件付きのwhile Trueループという単純な形で実装可能です。例えば、Hugging Faceが最近実装したAgentクラスはこの方式を採用しています。Hugging Face AIエージェントの構築方法の詳細はこちら。
AIエージェントの中核コンポーネント
AIエージェントは通常、自律的かつ適応的な行動を可能にするいくつかの主要コンポーネントで構成されます。それらは以下の通りです:
- 大規模言語モデル(LLM):エージェントの「頭脳」または「エンジン」と呼ばれることが多いAIモデルは、基礎的な推論と自然言語処理能力を提供します。これによりエージェントはユーザー入力を解釈し、応答を生成し、計画を立案する能力を獲得します。単一のエージェントが複数のLLMモジュール(例:推論用、計画用、目標検証用)を使用できる点に留意してください。 また、AIモデルはリモート配置またはローカルホストのいずれかとなります。
- メモリ:文脈の維持と学習に不可欠であり、エージェントのメモリは通常以下の2つのシステムで構成される:
- 短期記憶:現在のタスクや会話の即時的な文脈を扱い、継続的な一貫性に必要な直近の情報を保存します。高速アクセスと低遅延が重要であるため、ほとんどの場合、一時キャッシュ、セッションベースのストレージ、Redisなどのインメモリデータ構造やデータベースを使用して実装されます。
- 長期記憶:事実知識、過去の経験、ユーザー嗜好、複数セッションで蓄積されたスキルを保存する。このコンポーネントによりエージェントは継続性を維持し、よりパーソナライズされた文脈認識型応答を提供できる。 長期記憶に用いられる一般的な技術には、埋め込み値を保存するためのベクトルデータベース(例:Pinecone、Weaviate、FAISS)、SQL/NoSQLデータベース、ドキュメントストア、ナレッジベース(例:MySQL、PostgreSQL、MongoDBなど)が含まれます。
- ツール:LLMは知識が限定的であり、単独ではあらゆるタスクを実行できません。AIエージェントは外部ツールを統合することで機能を拡張し、基盤となるLLMが環境や外部世界(例:ファイルシステムへのアクセス、ウェブ閲覧、ビジネスインフラとの連携)と対話できるようにします。これらのツールは、ウェブスクレイピング、ウェブサイトとの対話、ファイル作成などの特定タスクの実行を支援します。 ツール使用を管理するため、エージェントは様々なAIプロトコルに依存しており、MCP(Multi-Tool Control Protocol)が(少なくとも現時点では)最も普及している。
- 実行ランタイム:このオーケストレーション層はエージェントの全体的なワークフローを管理します。計画が順守されているか確認し、ツール呼び出しを正しく順序付け、すべての可動部分を調整します。さらに、AIエージェントのアーキテクチャのデプロイと管理を容易にします。実行ランタイムの例としては、LangChain、LlamaIndex、CrewAI、AutoGenなどがあります。
関連文献:
- AIエージェント技術スタックの内部構造
- 最高のAIウェブスクレイピングツール:完全比較
- LLM向けAI対応ベクトルデータセット構築ガイド:Bright Data、Google Gemini、Pineconeを活用した実践手法
AIエージェントの種類
本セクションでは、AIエージェントの異なる種類に焦点を当てます。これらは意思決定のレベルと、望ましい結果を達成するために環境とどのように相互作用するかに基づいて分類されます。
注:AIエージェントの分類方法は多数存在しますが、この分類は最も関連性の高いものの一つです。エージェントの行動と意思決定の方法を明確に定義しているためです。その他の分類方法としては、ReAct、ReWOOなどの推論パラダイムに基づくものがあります。
関連文献:
単純反射型エージェント
単純反射エージェントは最も基礎的なAIエージェントである。現在の環境入力と事前定義された条件-行動ルールのみに基づいて意思決定を行う。内部状態や過去の経験の記憶を維持せず、将来の結果を考慮しない。行動は即時的かつ反応的である。
モデルベース反射エージェント
モデルベース反射エージェントは単純反射エージェントの改良版である。世界の内部モデルを組み込み、エージェントが現在の状態を追跡し、過去の相互作用や行動が環境に与えた影響を理解するのに役立つ。つまり、部分的に観測可能な環境でも機能できる。
条件-行動ルールを使用しつつも、意思決定は現在の知覚と推論された内部状態の両方に基づきます。環境のダイナミクスに関するこの記憶と推論により、単純な対比物よりも情報に基づいた効果的な意思決定が可能となります。
目標ベースエージェント
目標ベースエージェントは能動的で、特定の目標や目的を持つ。計画と推論を用いて様々な可能な行動を評価し、目標達成に近づく一連の手順を選択する。これらのAIエージェントは望ましい将来状態を先読みし、目的に対する結果の論理的評価に基づいて意思決定を行う。
効用ベースのエージェント
効用ベースのエージェントは、単純な目標達成を超え、効用関数を用いて全体的な利益や幸福を最大化する。様々な結果の可能性を評価し、それぞれに数値的な効用値を割り当てることで、競合する目的やトレードオフ(例:速度と安全性のバランス)を調整する微妙な意思決定を可能にする。
学習型エージェント
学習エージェントは、環境からのフィードバックに基づき新たな経験やデータに適応することで、時間の経過とともに性能を向上させます。学習コンポーネントを通じて行動を継続的に更新します。学習エージェントを実装する一般的な手法として強化学習があり、エージェントは継続的な試行錯誤を通じて報酬を最大化する行動を学習します。
関連文献:
マルチエージェントシステム
マルチエージェントシステムは、複雑な問題に対処するために相互に連携する複数のエージェントで構成されます。上位のエージェントは包括的な目標に焦点を当て、下位のエージェントは特定のサブタスクを処理します。中核となる概念はAIオーケストレーションであり、システムがこれらの多様なエージェントを統合して複数領域にまたがる複雑なタスクを管理します。マルチエージェントシステムを実装する最も人気のあるライブラリの一つがCrewAIです。
関連記事:
- CrewAIとBright Dataを用いた不動産エージェント構築
- CrewAIとBright Dataを用いたマルチソースレビューインテリジェンスエージェントの構築
- CrewAIとBright DataによるGEO向けコンテンツ最適化
AIエージェント構築:構想からデプロイまで
以下の手順は、ゼロからAIエージェントをオンライン化するために必要なすべてを説明しています。順を追って見ていきましょう!
1. 目的の定義
エージェントが扱うべきタスクを大まかに考え、カバーすべきシナリオを検討します。エージェントは特定の問題を解決できるほど専門的であるべきですが、幅広いタスクを実行し複数のユースケースをカバーするエージェントを構築したい場合もあります。
いずれにせよ、AIエージェントの背後にある目的を明確に理解しておく必要があります。実際には完全なエージェントではなく、シンプルなAIワークフローで十分だと気づく場合もあるでしょう。
2. エージェントのワークフロー設計
エージェントをノードのマップとして視覚的に表現します。各ノードはコンポーネントに対応し、以下の例のように構成されます: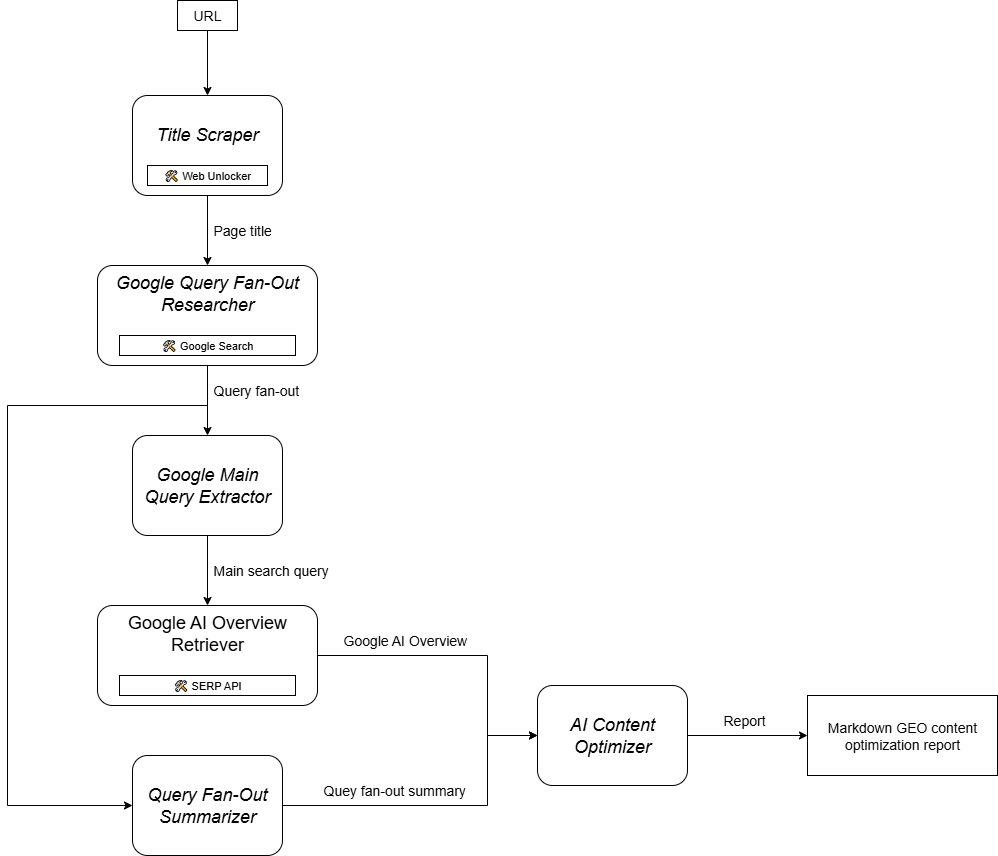
場合によっては、コンポーネントではなくステップ単位で考える方が効果的です。このプロセスによりワークフローを明確に定義し、各ノード/ステップの期待される入力と出力を確立できます。
3. データソースの選定
AIエージェントの能力は、アクセス可能なデータと情報の質に依存します。したがって、AIモデルが目標を達成するために必要なデータを特定し提供する必要があります。これにはAPI、ウェブデータ、データセット、データベース、その他のデータソースが含まれます。経験的ベンチマークが示すように、全てのデータ形式がAIの取り込みに理想的とは限らない点に留意してください。
この点において、Bright Dataは豊富なAI対応インフラ製品を提供しており、以下が含まれます:
- Web Unlocker API:ウェブサイトのボット対策機能を回避し、任意のウェブページをHTMLまたはMarkdown形式で取得可能にします。
- SERP API:主要検索エンジンの検索結果を解放し、SERPデータを抽出することでウェブ検索シナリオを実現します。
- WebスクレイパーAPI:100以上の主要ドメインから、AI最適化フォーマットで構造化データを取得するための事前設定済みAPI。
- Browser API: クラウド制御可能なブラウザインスタンス。AIと連携したプログラムによるウェブ操作を実現し、アンロック機能を内蔵。
- クロールAPI:あらゆるドメインからのコンテンツ抽出を自動化し、ウェブサイト全体のコンテンツをMarkdown、テキスト、HTML、またはJSON形式で取得します。
- トレーニングデータ:AI対応の公開ウェブデータと人気プラットフォームからのマルチモーダルデータセット。数十億件のエントリが利用可能。
4. AIモデルの選択
OpenRouterやHugging Faceなどのプラットフォームには数千のAIモデルが掲載されています。OpenAIやGeminiモデルのような汎用モデルもあれば、ニッチな用途向けに微調整されたモデルもあります。エージェントの視覚的ワークフローと高レベルなアーキテクチャに基づき、LLM統合が必要な各ノードを駆動するAIモデルを選択してください。
関連記事:
- Unslothを用いたGPT-OSSのファインチューニング:ステップバイステップガイド
- より良い結果を得るための最新ウェブデータを用いたLlama 4の微調整
- カスタムQ&Aデータセットを用いたGemma 3の微調整:ステップバイステップガイド
- n8nを使用したWebスクレイパーAPIによるGPT-4oの微調整方法
5. ツールとの連携
LLMはコンテンツ生成に優れていますが、その他の機能やトレーニングデータによって制限されます。エージェントの機能を拡張するには、LLM搭載ノードに必要なツールを特定してください。これらのツールは、外部APIを呼び出すなどしてカスタム構築することも、ローカルのタスクランナーに依存することも、MCPサーバーなどのすぐに使えるサービスから提供されることもあります。
注:Bright DataのWeb MCPは、60以上の統合ツールにより、LLMやAIエージェントがブロックされることなくオンラインコンテンツを検索・抽出・ナビゲートできるようにし、効果的なWebアクセスを実現します。無料プランも提供されている点にご留意ください。
関連記事:
- Bright Data Web MCPとsmolagentsの連携方法
- LangChainエージェントをBright Data Web MCPに簡単に接続する方法
- CrewAI & Bright Data Web MCP:高度なウェブスクレイピングガイド
- AutoGen AgentChatとBright Data Web MCPの連携
- Pydantic AIとBright Data Web MCPの統合
- AWS Strands SDK + Bright Data MCPを使用したAIエージェント構築
- Bright Data Web MCPの統合ソリューション
6. ロジックの実装
選択したAIエージェントフレームワークまたはローコード/ノーコードソリューションを使用し、設計を機能的なシステムに変換してエージェントを実装します。これにはAIモデル、ツール、その他のコンポーネントの接続が含まれます。
AIエージェントの実装には、スクリプトの記述、設定ファイルの作成、LLM駆動ノードが特定のタスクを実行するためのプロンプト定義が含まれる場合があります。複数のAIエージェントを使用する場合、エージェント間通信のためにA2A(Agent-to-Agent)などのプロトコルを活用することもできます。
関連情報:
- PicaとBright DataでAIエージェントを構築する
- Difyでデータ取得機能を備えたAIエージェントを構築する
- LlamaIndexを使用したWebデータによるAIエージェント構築
- –xpander.aiでスクレイピング機能を備えたAIエージェントを構築
- Hugging FaceとBright Dataを活用したAIスクレイパーの構築方法
7. テストと反復
エージェントが実行可能になったら、単純なシナリオと複雑なシナリオの両方でテストします。各ステップが期待される入力と出力を生成することを確認します。テストは、追加ツールの必要性、異なるモデルの選択、より良いプロンプトの特定など、エージェントの基盤を洗練させるのにも役立ちます。特に正確性と信頼性のためには、エッジケースのテストが重要です。さらに、いくつかのエラーに遭遇する可能性があり、より堅牢なエラー処理プロセスが必要だと気づくかもしれません。
8. デプロイと監視
最後に、エージェントをクラウドまたはオンプレミスにデプロイします。監視ツールを導入し、実環境におけるエージェントの動作を追跡します。監視からのフィードバックは、エージェントの反復と改善に役立ちます。新しいモデル、ツール、機能が利用可能になる可能性があるため、最新のAI進歩を活用するためにエージェントを継続的に更新することを忘れないでください。
参考資料:
AIエージェント開発に最適な技術スタック
ソフトウェア開発においてよくあることですが、AIエージェント構築に「唯一の最適な」技術スタックは存在しません。成功は、AIエージェント開発プロセスに関わる各コンポーネント(例:AIプロバイダー、LLM、データベース、プロンプトバージョン管理ツールなど)に対して適切な選択を行うことに依存します。
ここでは、スタックの中で最も重要な側面、つまり実際にAIエージェントを構築するために使用されるフレームワークやソリューションに焦点を当てます!
以下に、GitHubスター数でソートした、最も人気のあるオープンソースオプション15種類以上をまとめた表を掲載します:
| AIエージェントフレームワーク | プログラミング言語 | GitHubスター数 |
|---|---|---|
| AutoGPT | — (ローコード/ノーコード) | 179k+ |
| Langflow | Python、TypeScript/JavaScript | 134k+ |
| LangChain | Python、JavaScript/TypeScript | 118k+ |
| Dify | — (ローコード/ノーコード) | 117k+ |
| AutoGen | Python、.NET | 51k+ |
| Flowise | — (ローコード/ノーコード) | 46k+ |
| LlamaIndex | Python、JavaScript/TypeScript | 44.9k+ |
| CrewAI | Python | 39.6k+ |
| Agno | Python | 34.5k+ |
| ChatDev | Python | 27.6k+ |
| Semantic Kernel | Python、.NET、Java | 26.5k+ |
| smolagents | Python | 23.5k+ |
| Letta | Python、TypeScript | 18.9k+ |
| OpenAI Agents SDK | Python、TypeScript | 16.8k+ |
| Google Agent Development Kit (ADK) | Python、Java | 13.9k |
| PydanticAI | Python | 13k+ |
注:Bright Dataは、上記の技術の大半およびその他多くの技術と、MCPを通じて公式に統合されています。70以上の利用可能な統合をすべてご覧ください。
関連記事:
AIエージェントの実例
AIエージェントとは何か、その仕組み、構成要素、構築ツールについて明確に理解できたところで、最後のステップは実際の動作を確認することです。
そのため、様々な技術で構築され、幅広いユースケースをカバーするように設計されたAIエージェントを厳選して紹介する「AIエージェントショーケース」をご覧になることをお勧めします。
関連記事:
- TrendScan:Crunchbase、LinkedIn、Reddit、Twitter/Xから企業データを自動収集し、AIを活用した分析を行うマルチソース企業情報プラットフォーム。
- Unified Search Agent: LangGraphで構築された高度なマルチモーダル検索エージェント。クエリ意図の分類に基づき、Google検索とウェブスクレイピングをインテリジェントに切り替える。
- 不動産AIエージェントシステム:AIエージェント、Nebius Qwen LLM、Bright Data Web MCPを活用し、不動産物件データを構造化JSONとして抽出するインテリジェントPythonシステム。
- GEO AI Crew:URLのクロール、H1タグの分析、CrewAIによる実行可能な地域別推奨事項の生成を通じて、ウェブサイトコンテンツを監査・最適化するAIツール。
- FactFlux:AgnoフレームワークとBright Dataツールを用いたソーシャルメディア投稿のファクトチェックを行うインテリジェントマルチエージェントシステム。
- AI Travel Planner:n8nとBright Dataによるリアルタイムスクレイピングで旅行計画を自動化するAIエージェント。
結論
本記事では、AIエージェント構築に必要な知識を網羅的に解説しました。これを読めば、AIエージェント開発に必要な情報を習得できるだけでなく、このトレンドトピックのさらなる専門家となるための豊富なリソースも得られます。
AIエージェント構築の目標が何であれ、信頼できるウェブデータパートナーの存在が成否を分ける。結局のところ、ここで強調したように、エージェントの性能は保有する知識に依存し、それはアクセス可能なデータに完全に左右される。
そこでBright Dataの出番です。幅広いエージェントシナリオやユースケースをサポートする、AIソリューションの包括的なインフラを提供しています。
Bright Dataアカウントを作成し、当社のウェブデータツールをAIエージェントに無料で統合しましょう!
よくある質問
AIエージェントとエージェント型AIの違いとは?
AIエージェントはプロセス全体を自律的に実行します。一方、エージェント型AIは、より複雑な目標を達成するために複数のエージェントを調整できる高次元のシステムを指します。継続的な人間の介入なしに、動的に計画・推論・適応が可能です。要するに、AIエージェントがタスクを処理する一方、エージェント型AIはそれらを調整する知的な基盤として機能します。
AIエージェントとAIワークフロー:主な違いは?
AIワークフローは、事前に定義された手順やロジックに従うプロセスです。高い予測可能性に優れ、構造化された反復タスクに最適です。一方、AIエージェントは自律性を持ち、推論を用いて動的に計画を立て、ツールを選択し、リアルタイムで行動を適応させる非決定論的システムです。解決策が事前に定義されていないオープンエンドの問題に最適です。
AIエージェント構築に最適な技術とは?
エージェント型AIは、計画立案、ツール使用、状態追跡、意思決定といった自律的なタスク実行に焦点を当て、目標達成を目指します。一方、生成AI(GenAIとも呼ばれる)は、プロンプトに基づいてテキスト、画像、動画、コードなどの新規コンテンツを生成します。つまり、エージェント型AIが調整し、生成AIが創造するのです。詳細については、エージェント型AIと生成AIの比較記事をご覧ください。
AIエージェント統合に最適なMCPサーバーは?
AIエージェント向けのMCPサーバーには、リアルタイムWebデータと構造化抽出のためのBright DataのWeb MCP、開発ワークフロー自動化のためのGitHub、データベースとバックエンド管理のためのSupabase、ブラウザ自動化のためのPlaywright MCP、ナレッジ管理のためのNotionなどがあります。その他の注目すべきサーバーには、Atlassian、Serena、Figma、Grafanaなどがあります。AIエージェント向けベストMCPサーバーに関する記事でそれらすべてをご覧ください。
エージェント型RAGとは?
エージェント型RAG(Retrieval-Augmented Generation)は、自律型AIエージェントを用いて検索と応答生成プロセスをインテリジェントに制御・適応させる高度なRAG技術です。Bright Dataを用いたエージェント型RAGシステムの構築方法をご覧ください。




