
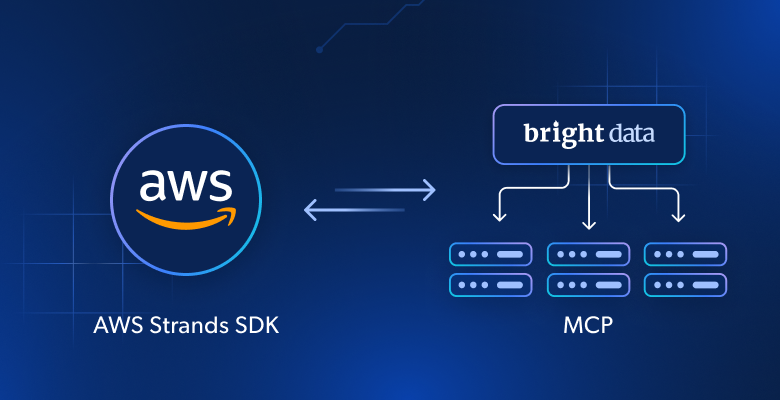
大規模言語モデル(LLM)で駆動されるAIエージェントは推論や意思決定が可能ですが、その能力は学習データに制限されます。真に有用なエージェントを構築するには、リアルタイムのウェブデータへの接続が必要です。本ガイドでは、AWS Strands SDKとBright DataのWeb MCPサーバーを組み合わせて、ライブウェブデータにアクセス・分析できる自律型AIエージェントを作成する方法を説明します。
このガイドでは以下を学びます:
- AWS Strands SDKの定義と、AIエージェント構築フレームワークとしての独自性
- ウェブ対応エージェント構築において、AWS Strands SDKがBright DataのWeb MCPサーバーと完璧に連携する理由
- AWS StrandsとBright DataのWeb MCPを統合し、自律的な競合情報収集エージェントを作成する方法
- 目標に基づいて使用するウェブスクレイピングツールを自律的に決定するエージェントの構築方法
さあ、始めましょう!
AWS Strands SDKとは?
AWS Strands SDKは、最小限のコードでAIエージェントを構築するためにAWSが開発した軽量なコードファーストフレームワークです。エージェントの能力はハードコードされたロジックではなくモデルの決定から生まれる、モデル駆動型のアプローチを採用しています。
他のAIエージェントフレームワークと比較して、AWS Strands SDKはシンプルさ、柔軟性、実運用準備の整った状態を重視しています。具体的には、主な特徴は以下の通りです:
- モデル非依存性:AWS Bedrock、OpenAI、Anthropicなど複数のLLMプロバイダーをサポート
- ネイティブMCPサポート:1000以上の事前構築ツールにアクセス可能なModel Context Protocolとの組み込み統合
- 最小限のコード:わずか数行のコードで高度なエージェントを構築
- 本番環境対応:エラー処理、再試行、監視機能を標準装備
- エージェントループ: 知覚-推論-行動のサイクルを実装し自律的意思決定を実現
- マルチエージェント対応:複数の特化型エージェントを調整するためのオーケストレーションプリミティブ
- 状態管理:インタラクション間でのセッションおよびコンテキスト管理
AWS Strands SDKの理解
コアアーキテクチャ
AWS Strands SDK は、機能を損なうことなく、3 つのコンポーネントで構成される明確な設計により、エージェント開発を簡素化します。
このアプローチにより、数千行のコードを必要とするスマートエージェントを最小限のコードで構築できます。
- モデルコンポーネント:複数のAIプロバイダーと連携する中核
- ツール統合: MCPサーバーを介してエージェントを外部システムに接続
- プロンプトベースタスク:コードではなく自然言語でエージェントの動作を定義
エージェントループの実装
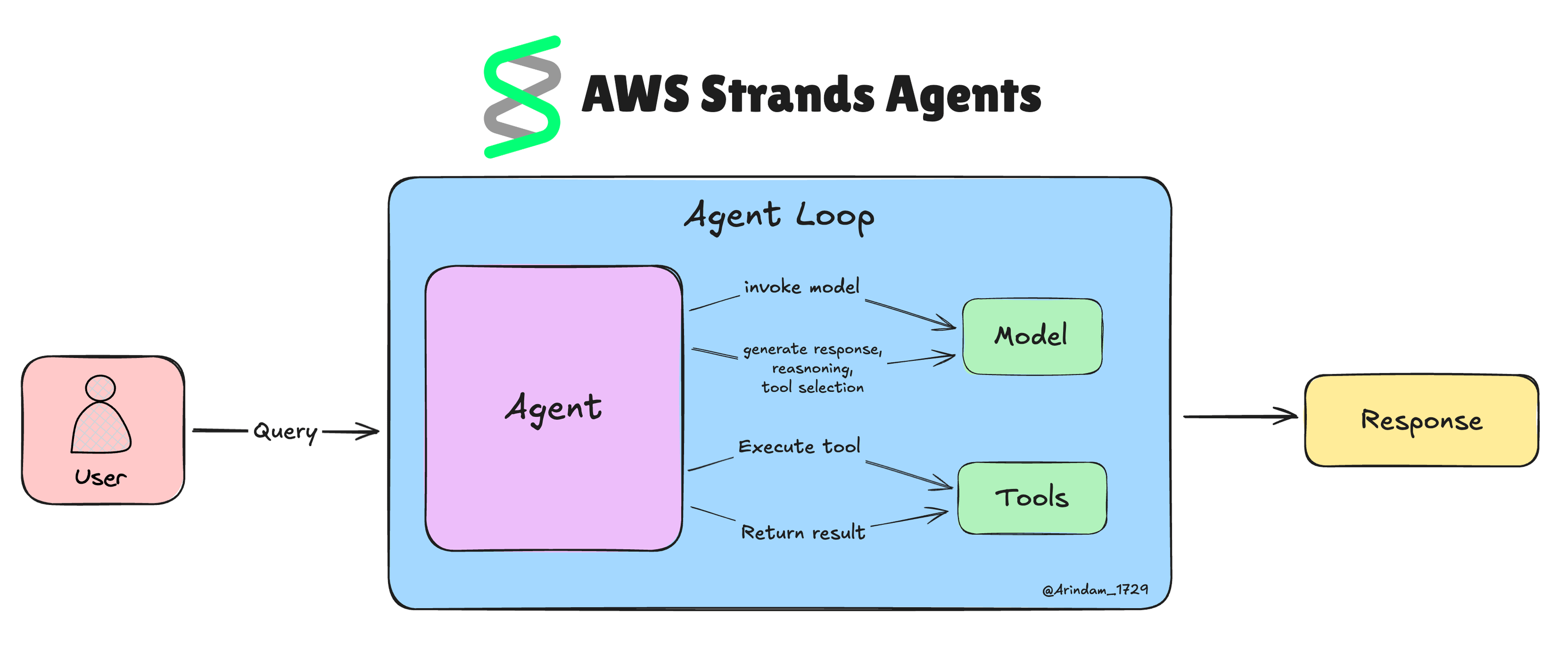
エージェントループこそが、ストランズのエージェントをこれほど賢くする要素です。これは、エージェントが状況を認識し、それを思考し、行動を起こすという継続的なサイクルのようなもので、複雑なタスクをすべて自律的に処理することを可能にします。
StrandsはAIモデルに次の行動を決定させることでゲームを変えます。あらゆるシナリオをコーディングする代わりに、モデルが現状に基づいて判断します。
実際の動作は以下の通りです:
- エージェントはユーザーからタスクを受け取ります。
- モデルは状況と利用可能なツールを分析します。
- ツールを使用するか、説明を求めるか、最終回答を出すかを決定します。
- ツールを使用する場合、Strandsがツールを実行し結果をモデルにフィードバックします。
- このサイクルは、作業が完了するか人間の支援が必要になるまで続きます。
価格監視ツールの構築を考えてみましょう。従来のコーディングでは、競合他社のウェブサイトをチェックするロジック、さまざまなページレイアウトの処理、エラーの管理、結果の収集、アラート閾値の設定などを記述しなければなりません。
Strands を使用すると、ウェブスクレイピングツールを提供し、エージェントに「競合他社のサイトで 5% 以上の価格変動を監視し、概要を通知してください」と指示するだけで済みます。モデルは、どのサイトを監視するか、問題の処理方法、アラートの送信タイミングをすべて独自に判断します。
ウェブデータ取得にAWS Strands SDKとMCPサーバーを組み合わせる理由
AWS Strandsで構築されたAIエージェントは、基盤となるLLMの制限(特にリアルタイム情報へのアクセス不足)を継承します。これにより、競合他社の価格、市場状況、顧客の感情といった最新データが必要な際に、古い情報や不正確な応答が生じる可能性があります。
ここでBrightDataのWeb MCPサーバーが活躍します。Node.jsで構築されたこのMCPサーバーは、Bright DataのAI対応データ取得ツール群と連携します。これらのツールによりエージェントは以下が可能になります:
- ボット対策が施されたサイトも含め、あらゆるウェブサイトのコンテンツにアクセス
- 120以上の主要サイトから構造化データセットをクエリ
- 複数の検索エンジンを同時に横断検索
- 動的ウェブページとのリアルタイムな対話
現在、MCPサーバーにはWeb Scraper APIを活用しAmazon、LinkedIn、TikTokなどのサイトから構造化データを収集する40種類の専用ツールが含まれています。
それでは、AWS Strands SDKでこれらのMCPツールを活用する方法を見ていきましょう!
PythonでAWS Strands SDKとBright Data MCPサーバーを統合する方法
このセクションでは、AWS Strands SDK を使用して、Web MCP サーバーからライブデータをスクレイピングおよび取得する機能を備えた AI エージェントを構築する方法を学びます。
例として、市場や競合他社を自律的に分析できる競合情報エージェントを構築します。このエージェントは目標に基づいて使用するツールを決定し、エージェントループの力を実証します。
AWS Strands SDK を使用して、Claude + Bright Data MCP を活用した AI エージェントを構築するためのステップバイステップガイドに従ってください。
前提条件
コード例を再現するには、以下の環境が必要です:
ソフトウェア要件:
- Python 3.10 以降
- Node.js(最新版LTS推奨)
- Python IDE(Python拡張機能付きVS CodeまたはPyCharm)
アカウント要件:
- Bright Dataアカウント(無料プランでは月間5,000リクエストを提供)
- Claude API アクセス権とクレジット付きのAnthropic アカウント
背景知識(推奨されるが必須ではない):
- MCPの動作原理に関する基礎知識
- AIエージェントとその機能に関する知識
- Pythonにおける非同期プログラミングの基礎知識
ステップ #1: Pythonプロジェクトの作成
ターミナルを開き、プロジェクト用の新規フォルダを作成します:
mkdir strands-mcp-agent
cd strands-mcp-agentPython仮想環境を設定します:
python -m venv venv仮想環境を有効化します:
# Linux/macOSの場合:
source venv/bin/activate
# Windowsの場合:
venvScriptsactivateメインのPythonファイルを作成:
touch agent.pyフォルダ構造は次のようになります:
strands-mcp-agent/
├── venv/
└── agent.pyこれで準備完了です!ウェブデータにアクセスできるAIエージェントを構築するためのPython環境が整いました。
ステップ #2: AWS Strands SDK のインストール
アクティブ化した仮想環境で、必要なパッケージをインストールします:
pip install strands-agents python-dotenvこれにより以下がインストールされます:
strands-agents: AIエージェント構築用AWS Strands SDKpython-dotenv: 安全な環境変数管理用
次に、agent.pyファイルに以下のインポートを追加してください:
from strands import Agent
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.stdio import stdio_client, StdioServerParametersよし!これでエージェント構築にAWS Strands SDKが使用可能になりました。
ステップ #3: 環境変数の設定
安全なAPIキー管理のため、プロジェクトフォルダ内に.envファイルを作成します:
touch .env.envファイルにAPIキーを追加します:
# Anthropic API(Claudeモデル用)
ANTHROPIC_API_KEY=your_anthropic_key_here
# Bright Dataクレデンシャル(ウェブスクレイピング用)
BRIGHT_DATA_API_KEY=your_bright_data_token_hereagent.py で環境変数の読み込みを設定します:
import os
from dotenv import load_dotenv
load_dotenv()
# APIキーを読み込み
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")これで完了です!.envファイルから安全にAPIキーを読み込む準備が整いました。
ステップ #4: Bright Data MCP サーバーのインストールとテスト
npm経由でBright Data Web MCPをグローバルにインストール:
npm install -g @brightdata/mcpAPIキーで動作するかどうかテストします:
# Linux/macOSの場合:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp
# Windows PowerShellの場合:
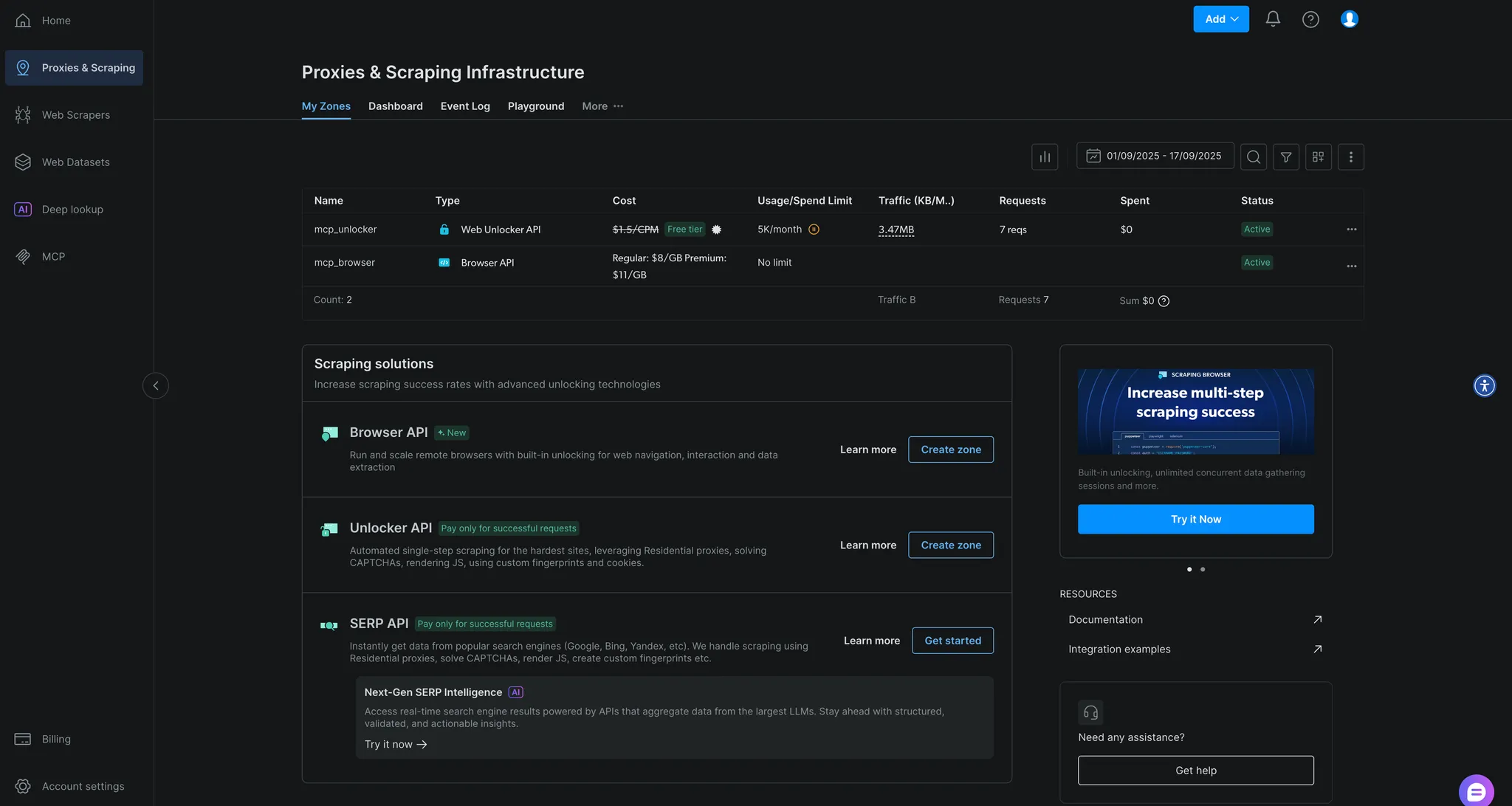
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp正常に動作すると、MCPサーバーの起動を示すログが表示されます。初回実行時に、Bright Dataアカウントに自動的に2つのゾーンが作成されます:
mcp_unlocker: Web Unlocker用mcp_browser: ブラウザAPI用
これらはBright Dataダッシュボードの「プロキシ&スクレイピングインフラ」で確認できます。
素晴らしい!Web MCPサーバーは完璧に動作します。
ステップ #5: Strandsモデルの初期化
agent.py で Anthropic Claude モデルを設定します:
# Anthropicモデルの初期化
model = AnthropicModel(
model_id="claude-3-opus-20240229", # 低コスト版 claude-3-sonnet も使用可能
max_tokens=4096,
params={"temperature": 0.3}
)
# APIキーの設定
os.environ["ANTHROPIC_API_KEY"] = ANTHROPIC_API_KEYこれにより、一貫性のある集中した応答を実現する適切なパラメータで、ClaudeをエージェントのLLMとして設定します。
ステップ #6: Web MCP サーバーへの接続
Bright Dataのツールに接続するためのMCPクライアント設定を作成します:
import asyncio
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def connect_mcp_tools():
"""Bright Data MCPサーバーに接続し、ツールを検索"""
logger.info("Bright Data MCPに接続中...")
# Bright DataがホストするMCPへの接続設定
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={"API_TOKEN": BRIGHT_DATA_API_KEY, "PRO_MODE": "true"}
)
# MCPクライアントの作成
mcp_client = MCPClient(lambda: stdio_client(server_params))
# 利用可能なツールの検出
with mcp_client:
tools = mcp_client.list_tools_sync()
logger.info(f"📦 {len(tools)}個のMCPツールを検出")
for tool in tools:
logger.info(f" - {tool.tool_name}")
return mcp_client, toolsこれにより、Bright DataのMCPサーバーへの接続が確立され、利用可能なすべてのウェブスクレイピングツールが検出されます。
ステップ #7: 競合情報収集エージェントの定義
競合情報分析に特化したプロンプトを持つエージェントを作成します:
def create_agent(model, tools):
"""Webデータアクセス機能付き競合情報エージェントを作成"""
system_prompt = """あなたはMCPを通じて強力なWebデータツールにアクセスできる競合情報分析のエキスパートです。
## ミッション
リアルタイムWebデータを用いた包括的な市場・競合分析を実施してください。
## 利用可能なMCPツール
以下のBright Data MCPツールを利用可能:
- search_engine: Google、Bing、Yandexの検索結果をスクレイピング
- scrape_as_markdown: CAPTCHA回避機能付きで任意のウェブページからコンテンツを抽出
- search_engine_batch: 複数検索を同時実行
- scrape_batch: 複数ウェブページを並列スクレイピング
## 自動分析ワークフロー
分析タスクが与えられた場合、自律的に:
1. 目標に基づき使用するツールを決定
2. 複数ソースから包括的なデータを収集
3. 発見事項を実用的な知見に統合
4. 具体的な戦略的提言を提供
ツール選択において能動的に行動 - あらゆるツールの組み合わせを完全に自律的に使用可能。"""
return Agent(
model=model,
tools=tools,
system_prompt=system_prompt
)これにより、自律的な意思決定能力を備えた競合情報分析に特化したエージェントが生成されます。
ステップ #8: エージェントの実行
エージェントを実行するメイン関数を作成します:
async def main():
"""競合情報収集エージェントを実行"""
print("🚀 AWS Strands + Bright Data MCP 競合情報収集エージェント")
print("=" * 70)
try:
# MCPツールに接続
mcp_client, tools = await connect_mcp_tools()
# エージェントを作成
agent = create_agent(model, tools)
print("n✅ エージェント準備完了、Webデータアクセス可能!")
print("n📊 分析開始...")
print("-" * 40)
# 例: テスラの競争ポジション分析
prompt = """
電気自動車市場におけるテスラの競争ポジションを分析せよ。
調査対象:
- 現行製品ラインナップと価格戦略
- 主要競合他社とその提供製品
- 最近の戦略的発表
- 市場シェアとポジショニング
ウェブスクレイピングツールを使用して、tesla.comおよび検索結果からリアルタイムデータを収集してください。
"""
# MCPコンテキストで分析を実行
with mcp_client:
result = await agent.invoke_async(prompt)
print("n📈 分析結果:")
print("=" * 50)
print(result.content)
print("n✅ 分析完了!")
except Exception as e:
logger.error(f"エラー: {e}")
print(f"n❌ エラー: {e}")
if __name__ == "__main__":
asyncio.run(main())ミッション完了!エージェントは自律的な競合分析を実行する準備が整いました。
ステップ #9: 全体を統合する
agent.pyの完全なコードは以下の通りです:
import asyncio
import os
import logging
from dotenv import load_dotenv
from strands import Agent
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.stdio import stdio_client, StdioServerParameters
# 環境変数をロード
load_dotenv()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# APIキーを読み込み
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Anthropicモデルの初期化
model = AnthropicModel(
model_id="claude-3-opus-20240229",
max_tokens=4096,
params={"temperature": 0.3}
)
# APIキーを設定
os.environ["ANTHROPIC_API_KEY"] = ANTHROPIC_API_KEY
async def connect_mcp_tools():
"""Bright Data MCPサーバーに接続し、ツールを検索"""
logger.info("Bright Data MCPに接続中...")
# Bright DataがホストするMCPへの接続設定
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={"API_TOKEN": BRIGHT_DATA_API_KEY, "PRO_MODE": "true"}
)
# MCPクライアントの作成
mcp_client = MCPClient(lambda: stdio_client(server_params))
# 利用可能なツールの検出
with mcp_client:
tools = mcp_client.list_tools_sync()
logger.info(f"📦 {len(tools)}個のMCPツールを検出")
for tool in tools:
logger.info(f" - {tool.tool_name}")
return mcp_client, tools
def create_agent(model, tools):
"""競合情報分析エージェントを作成(Webデータアクセス機能付き)"""
system_prompt = """あなたはMCPを通じて強力なウェブデータツールにアクセスできる競合情報分析の専門家です。
## ミッション
リアルタイムのウェブデータを用いた包括的な市場・競合分析を実施してください。
## 利用可能なMCPツール
以下のBright Data MCPツールを利用できます:
- search_engine: Google、Bing、Yandexの検索結果をスクレイピング
- scrape_as_markdown: CAPTCHA回避機能付きで任意のウェブページからコンテンツを抽出
- search_engine_batch: 複数の検索を同時に実行
- scrape_batch: 複数のウェブページを並列スクレイピング
## 自動分析ワークフロー
分析タスクが与えられた場合、自律的に以下を実行:
1. 目標に基づき使用するツールを決定
2. 複数のソースから包括的なデータを収集
3. 発見事項を実用的な知見に統合
4. 具体的な戦略的提言を提供
ツール選択において能動的に行動せよ - あらゆるツールの組み合わせを完全に自律的に使用できる。"""
return Agent(
model=model,
tools=tools,
system_prompt=system_prompt
)
async def main():
"""競合情報エージェントを実行"""
print("🚀 AWS Strands + Bright Data MCP 競合情報エージェント")
print("=" * 70)
try:
# MCPツールに接続
mcp_client, tools = await connect_mcp_tools()
# エージェントを作成
agent = create_agent(model, tools)
print("n✅ エージェント準備完了、ウェブデータアクセス可能!")
print("n📊 分析開始...")
print("-" * 40)
# 例: テスラの競争的立場を分析
prompt = """
電気自動車市場におけるテスラの競争的立場を分析せよ。
調査対象:
- 現行製品ラインナップと価格戦略
- 主要競合他社とその製品・サービス
- 最近の戦略的発表
- 市場シェアとポジショニング
ウェブスクレイピングツールを使用して、tesla.comおよび検索結果からリアルタイムデータを収集してください。
"""
# MCPコンテキストで分析を実行
with mcp_client:
result = await agent.invoke_async(prompt)
print("n📈 分析結果:")
print("=" * 50)
print(result)
print("n✅ 分析完了!")
except Exception as e:
logger.error(f"エラー: {e}")
print(f"n❌ エラー: {e}")
if __name__ == "__main__":
asyncio.run(main())AIエージェントを実行するには:
python agent.py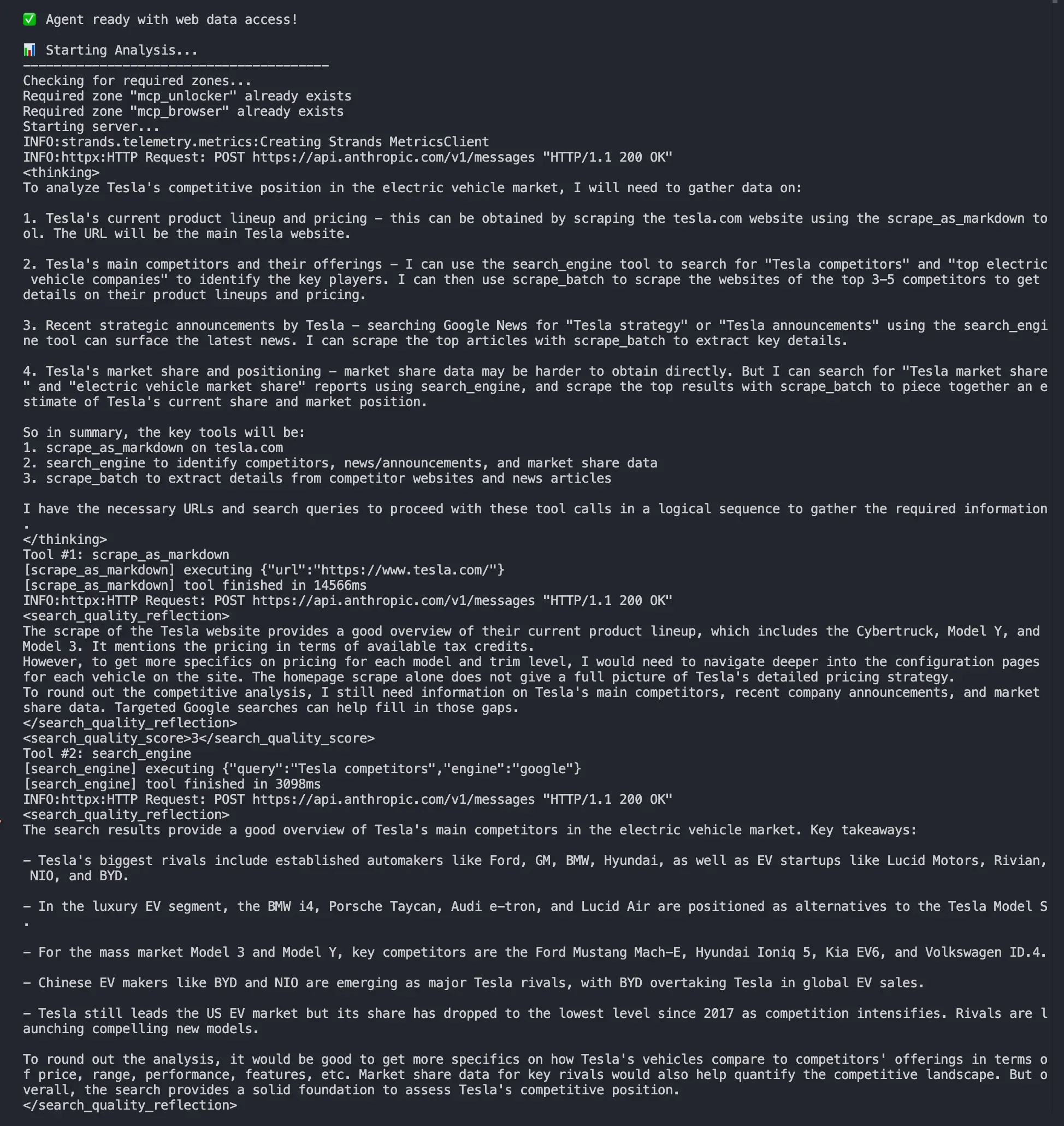
ターミナルには以下のような出力が表示されるはずです:
- MCP接続を確立中
- 利用可能なBright Dataツールの検出中
- エージェントが使用するツールを自律的に選択中
- Tesla.comおよび検索結果からのリアルタイムデータ収集中
- 最新データを用いた包括的な競合分析
エージェントが自律的に決定:
search_engineを使用してテスラと競合他社に関する情報を検索scrape_as_markdownを使用してtesla.comからデータを抽出する- 複数のデータソースを統合して包括的な分析を実施
さあ、これでリアルタイムのウェブデータにアクセスし分析できる自律型競合情報エージェントの構築に成功しました。
次のステップ
ここで構築したAIエージェントは機能しますが、これは出発点に過ぎません。次のレベルへ進化させるために検討すべき点:
- 会話ループの構築:エージェントと対話するためのREPLインターフェースを追加
- 特化型エージェントの作成:価格監視、市場調査、リード生成用のエージェントを構築
- マルチエージェントワークフローの実装:複雑なタスク向けに複数の特化エージェントを連携させる
- メモリと状態の追加:AWS Strandsのステート管理を活用し、文脈を認識した会話を実現
- 本番環境へのデプロイ:スケーラブルなエージェント展開のためにAWSインフラを活用する
- カスタムツールによる拡張:特殊なデータソース向けに独自のMCPツールを作成
- 可観測性の追加:本番環境デプロイ向けにロギングとモニタリングを実装
実世界のユースケース
AWS StrandsとBright Dataの組み合わせにより、多様なビジネスアプリケーションでより高度なAIエージェントを実現:
- 競合情報エージェント:競合他社の価格、製品機能、マーケティングキャンペーンをリアルタイムで監視
- 市場調査エージェント:業界動向、消費者心理、新たな機会を分析
- Eコマース最適化エージェント:動的価格戦略のための競合カタログと価格追跡
- リードジェネレーションエージェント:ウェブソースから潜在顧客を特定・評価
- ブランド監視エージェント:ウェブ上のブランド言及、レビュー、評判を追跡
- 投資調査エージェント:投資判断のための財務データ、ニュース、市場シグナルを収集
結論
本記事では、AWS Strands SDKとBright DataのWeb MCPサーバーを統合し、ライブWebデータにアクセス・分析可能な自律型AIエージェントを構築する方法を解説しました。この強力な組み合わせにより、リアルタイム情報を把握しつつ戦略的に思考するエージェントの作成が可能となります。
このアプローチの主な利点は以下の通りです:
- 最小限のコード:Python約100行で高度なエージェントを構築
- 自律的意思決定:エージェントが目標に基づき使用するツールを決定
- 本番環境対応:両プラットフォームによる組み込みのエラー処理とスケーラビリティ
- リアルタイムデータアクセス:ライブWebデータでLLMの限界を克服
より高度なエージェントを構築するには、Bright Data AIインフラストラクチャで利用可能な全サービスをご検討ください。これらのソリューションは多様なエージェントシナリオを実現します。
Bright Dataアカウントを無料で作成し、AI搭載のウェブデータツールを今すぐお試しください!





