
このチュートリアルでは以下を学びます:
- MLflowとは何か、そしてそれが提供する追跡機能について。
- ウェブスクレイピングで取得したデータセットを基盤としたML/AI実験構築が優位な手法である理由
- MLflowでスクレイピングしたデータセットを用いた実験追跡の実行方法。
さあ、始めましょう!
MLflowとは?
MLflowは、機械学習のライフサイクル全体を管理するためのオープンソースプラットフォームです。モデルの追跡、再現、デプロイを効率的に行うための豊富な機能とAPIを提供します。
MLflowは従来型機械学習と深層学習の両ワークフローをサポートし、実験、バージョン管理、評価、デプロイのためのツールを提供します。これらすべてを再現性と協働性を保ちながら実現します。
MLflowは言語非依存で、Python、R、Javaを横断して動作し、ローカル、クラウド、マネージド環境をサポートします。これによりベンダー中立性と高い柔軟性を実現しています。また、オープンソースの性質を保ち、GitHubリポジトリは24,000以上のスターを獲得しています。
主な機能は以下の通りです:
- トラッキング: 実験のログ記録、パラメータ・メトリクス・コードバージョン・成果物の追跡
- モデル: 異なるプラットフォーム間でのデプロイメントに向けたモデルパッケージングの標準化。
- モデルレジストリ:モデルバージョン管理、ステージ遷移、注釈のための中央リポジトリ。
- プロジェクト:一貫性と再現性を確保するための再利用可能なデータサイエンスコードのパッケージ化。
- AI/LLM評価: 生成AIやLLMの出力を追跡、比較、評価します。
- 統合と自動ロギング: scikit-learn、TensorFlow、PyTorch、OpenAI などと連携し、ロギングを自動化。
詳細は公式ドキュメントでご確認ください。
MLflowの実験にスクレイピングされたウェブデータを含むデータセットが理想的な理由
ML/AIパイプラインを構築する際、実験の成否は通常、データセットの品質と多様性にかかっています。スクレイピングされたウェブデータは、その性質上、多様性と規模の両方を提供します。これらは有意義な実験を行うための2つの主要な要素です。
小規模なデータセットや合成データとは異なり、ウェブ由来のデータセットは現実世界の分布、エッジケース、自然な変動性を捉えます。これらの特性により、モデルはより頑健になり、MLflow実験はより有益な知見をもたらします。これがウェブデータが一般的に最良のデータソースの一つと見なされる理由です。
Bright Dataは最高のデータセットプロバイダーとして際立っています。そのマーケットプレイスでは、eコマースや小売からソーシャルメディア、旅行まで150以上の分野に及ぶ、ML/AI対応の構造化データセットを提供しています。各データセットは数百万件のレコードを含み、広さと深さを保証します。
これらのデータセットはウェブの動的な性質を反映し定期的に更新されるため、ML/AIワークフローは最新情報でトレーニングおよび評価できます。この規模、鮮度、ML対応フォーマットの組み合わせにより、Bright DataのデータセットはMLflowを用いた堅牢で再現性が高く、影響力の大きい実験に最適です。マーケットプレイスで利用可能なデータセットを探索しましょう!
MLflowとBright Dataデータセットを用いた実験追跡の実行方法
このガイドセクションでは、MLflowによる実験追跡の実行方法を学びます。具体的には、Bright DataのAmazonベストセラー商品データセットを用いて機械学習パイプラインを構築します。
このパイプラインの目的は、商品の評価、レビュー数、ブランドに基づいて最終価格を予測するモデルをトレーニングすることです。これらの特徴量には商品価格と相関する予測シグナルが含まれているという前提に基づいています。
このパイプラインでは、前処理とランダムフォレストモデルを組み合わせ、その性能を評価します。プロセス全体を通じて、MLflowがメトリクス、アーティファクト、データセット、システムリソース使用量を追跡します。
以下の手順に従ってください!
前提条件
このチュートリアルを実践するには、以下の環境が必要です:
- ローカルにインストールされたPython 3.10以上
- スクレイピングされたデータセットにアクセスするためのBright Dataアカウント。
- scikit-learnを使用した予測機械学習モデルのトレーニングに関する基礎知識。
ステップ #1: プロジェクト設定
ターミナルを開き、MLflow実験プロジェクト用の新規フォルダを作成します:
mkdir mlflow-experiment-tracking次に、プロジェクトディレクトリに移動し、その中にPython仮想環境を作成します:
cd mlflow-experiment-tracking
python -m venv .venvお好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
プロジェクトディレクトリのルートにexperiment.pyという名前の新規ファイルを作成します。プロジェクト構造は次のようになります:
mlflow-experiment-tracking/
├── .venv/
└── experiment.pyターミナルで仮想環境を有効化します。LinuxまたはmacOSの場合、以下を実行してください:
source venv/bin/activateWindowsでは同等の操作として以下を実行します:
venv/Scripts/activate仮想環境をアクティブ化した状態で、プロジェクトの依存関係をインストールします:
pip install mlflow pandas scikit-learn psutil nvidia-ml-py必要なライブラリは以下の通りです:
mlflow: エンドツーエンドの実験追跡、可観測性、MLモデルとメトリクスのロギングのため。pandas: モデルトレーニング用にJSON/CSVから表形式データをロード、クリーニング、操作します。scikit-learn: MLパイプラインの構築、前処理の処理、モデルのトレーニング、評価メトリクスの計算を行います。psutil, nvidia-ml-py: MLflowが実験中にCPU/GPUリソースやその他のシステムメトリクスを監視するために必要です。
次に、experiment.py で必要なライブラリをすべてインポートします:
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer完了!Python開発環境がMLflowで機械学習とAIの実験を追跡する準備が整いました。
ステップ #2: MLflow UI に慣れる
MLflowが動作していることを確認するため、仮想環境をアクティブ化した状態でターミナルを開き、MLflow UIを起動します:
mlflow ui初回起動時、MLflowは実験データを保存するためのローカルSQLiteデータベースを初期化します。具体的には、プロジェクトフォルダ内にmlflow.dbファイルが生成されていることに気づくでしょう。これがSQLiteが使用するローカルデータベースです。
ターミナルには以下のようなログが表示されます:
INFO: Uvicorn running on http://127.0.0.1:5000 (Press CTRL+C to quit)これは UI が起動したことを意味します。ブラウザでhttp://127.0.0.1:5000/ にアクセスしてください。以下が表示されます: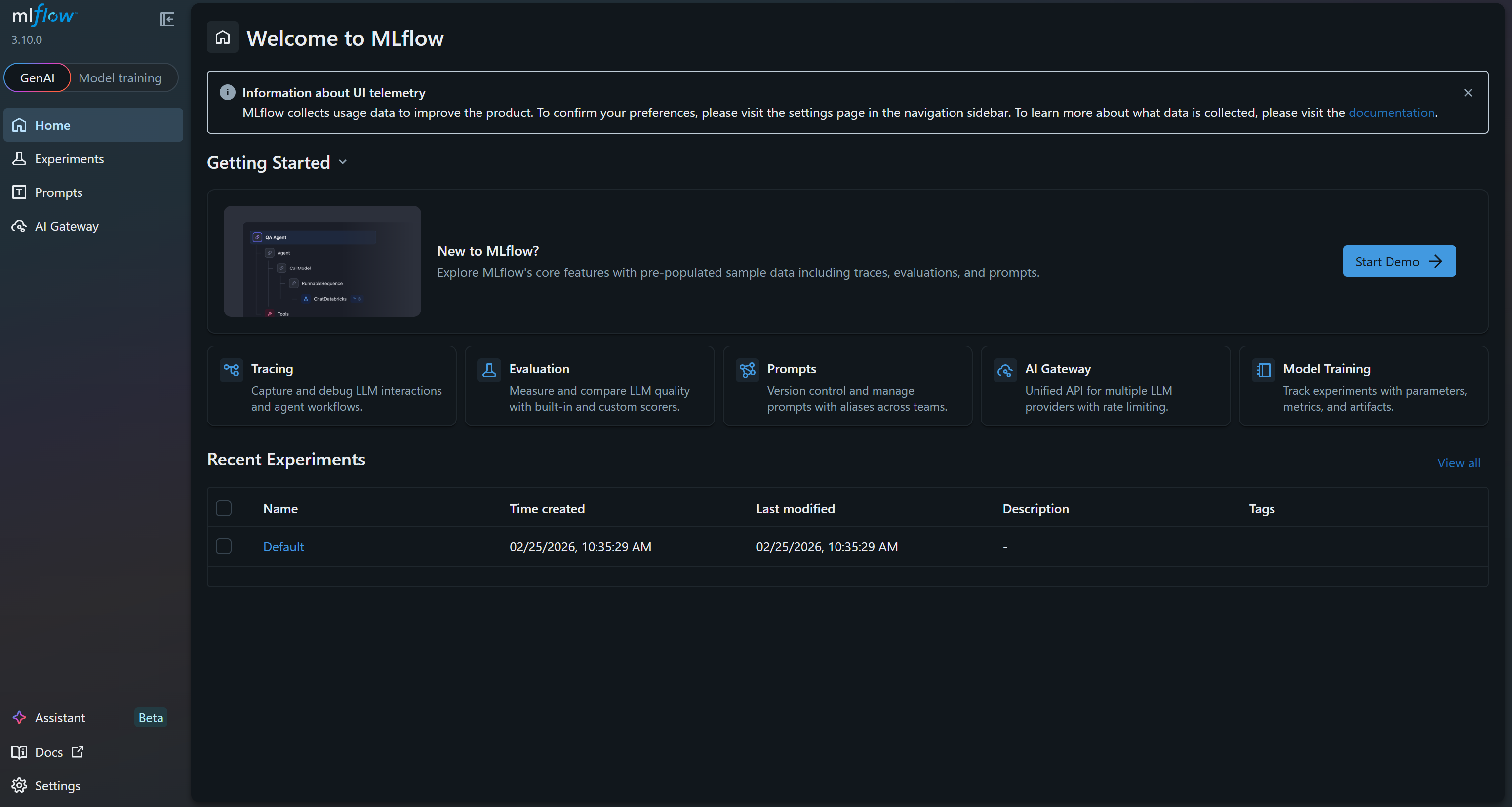
これがMLflow UIです。ここで実験の監視や追跡が可能です。メニューリンクや利用可能な機能を数分かけて探索し、操作に慣れてください。ここではMLプロジェクト中にメトリクス、ログ、アーティファクトを効果的に監視します。素晴らしい!
ステップ #3: MLflow 自動ロギングとシステムトレース機能を有効化
experiment.mlファイルで、トレーニング中のCPU使用率、ディスク使用率、RAM使用率などのシステムレベルメトリクスを追跡するため、MLflowシステムメトリクスロギングを有効化します。
# 自動システムメトリクスロギングを有効化(CPU、メモリなど)
mlflow.enable_system_metrics_logging()
# sklearnのイベントログを自動ログ記録
mlflow.sklearn.autolog()
# システムメトリクスのサンプリング間隔とログ記録頻度を設定
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1) このスニペットでは自動記録も有効化され、MLflowがscikit-learnイベントを自動的に記録します。さらにシステムメトリクスのサンプリング間隔を1秒に設定し、詳細かつ頻繁なモニタリングを確保します。
素晴らしい!これでMLflowアプリケーションが機械学習モデルのトレーニング実験に関する有用な情報を追跡します。
ステップ #4: Bright Data からスクレイピングしたデータを含むソースデータセットを取得
これでMLflow環境が整い、ML/AI実験を実行する準備が整いました。不足しているのはモデル訓練用のデータソースです。前述の通り、Bright DataのAmazonベストセラーデータセットを使用し、ランダムフォレストパイプラインに基づく価格予測モデルを構築します。
まず、ソースデータセットを取得する必要があります。このデータセットには45以上のデータフィールドが含まれ、1億7100万点以上のAmazonベストセラー商品がカバーされています。
Bright Dataアカウントをお持ちでない場合は新規作成し、お持ちの場合はログインしてください。Bright Dataコントロールパネルで「Web Dataセット」メニューを選択し、「Dataset Marketplace」タブに移動します:
「データセットマーケットプレイス」タブに移動します:
「データセットマーケットプレイス」ページが表示されます: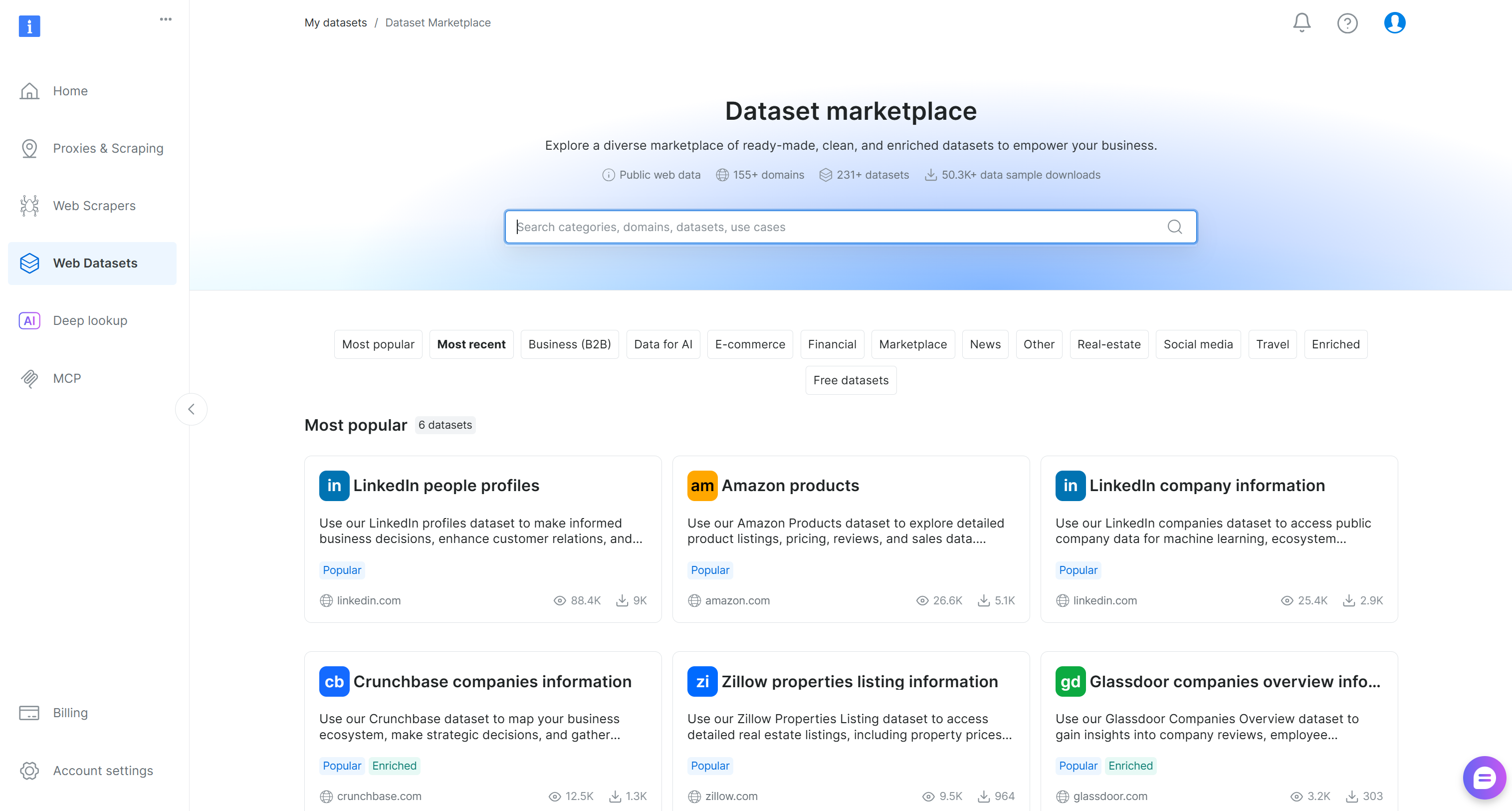
ここでは、155以上のドメインから収集された200以上のスクレイピングデータセットを閲覧でき、数十億件のレコードが利用可能です。
「Amazon best seller products」を検索して選択します。これによりデータセットのページに移動します: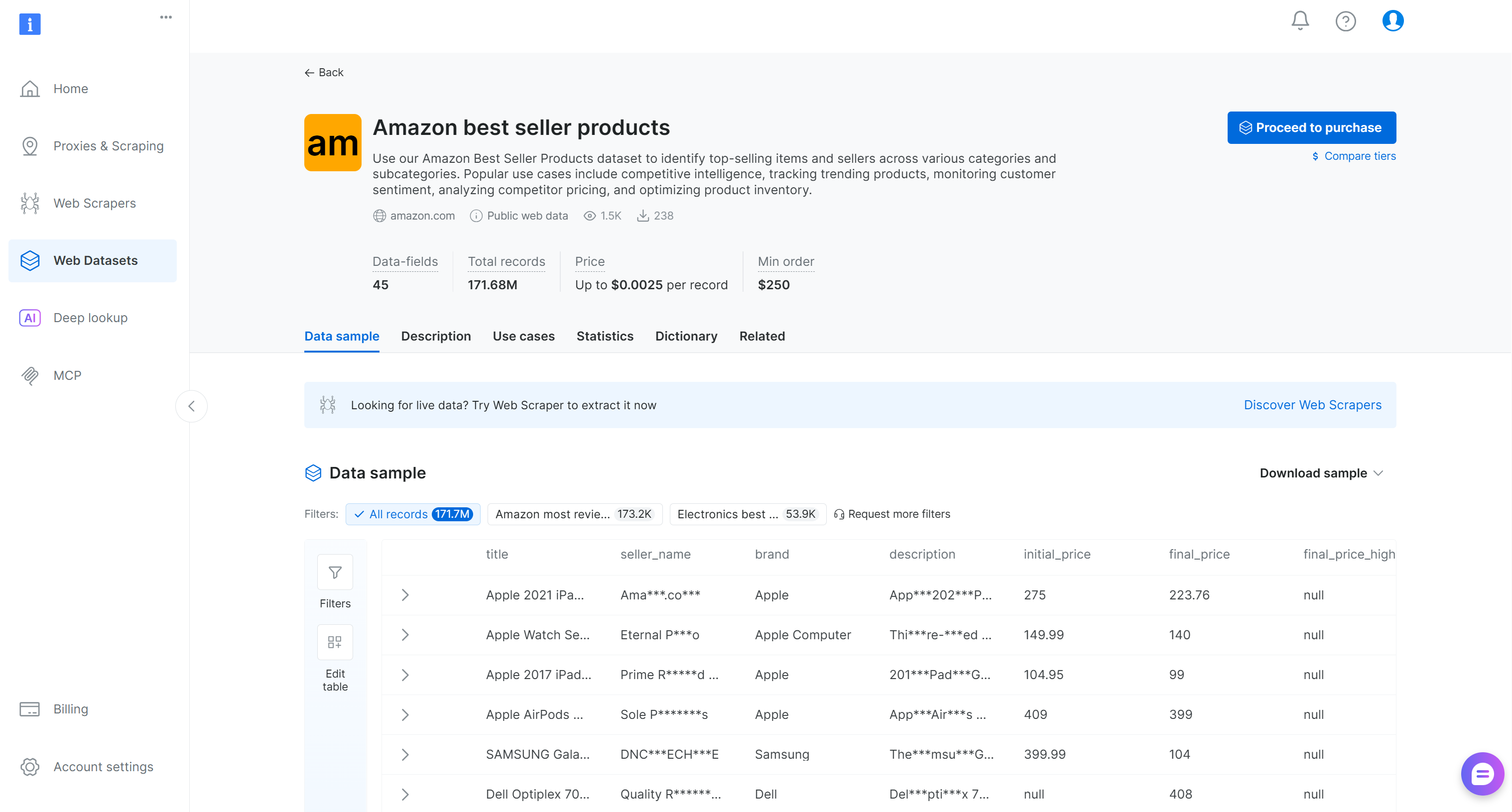
フィルタリングされたレコードのサブセットを購入するか、無料サンプルをダウンロードできます。ここでは例として無料サンプルを使用します。
「サンプルをダウンロード」ドロップダウンをクリックし、「JSONとしてダウンロード」オプションを選択: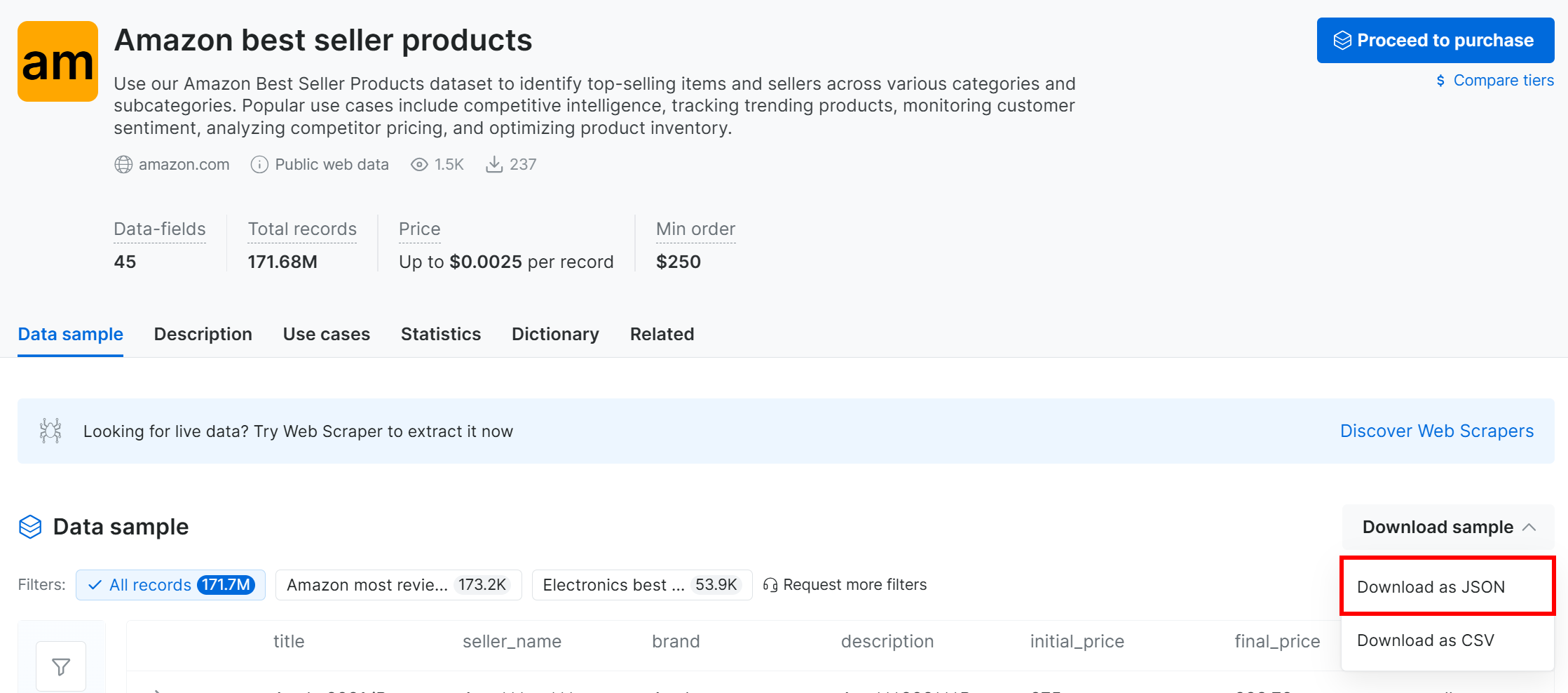
Amazonベストセラー商品1,000件のサンプルデータセットが提供されます。プライバシー保護のため一部のフィールドは「***」でマスクされていますが、有料版では完全なデータセットが利用可能です。ただしMLflowの簡易実験にはこのサンプルで十分です。
あるいは、専用のGitHubリポジトリから同様のサンプルデータセットをダウンロードすることも可能です。
ダウンロードしたデータセットファイルをproducts.jsonにリネームし、プロジェクトフォルダに配置します:
mlflow-experiment-tracking/
├── .venv/
├── experiment.py
├── mlflow.db
└── products.json # <--------ファイルを開くと、以下のような内容が表示されます: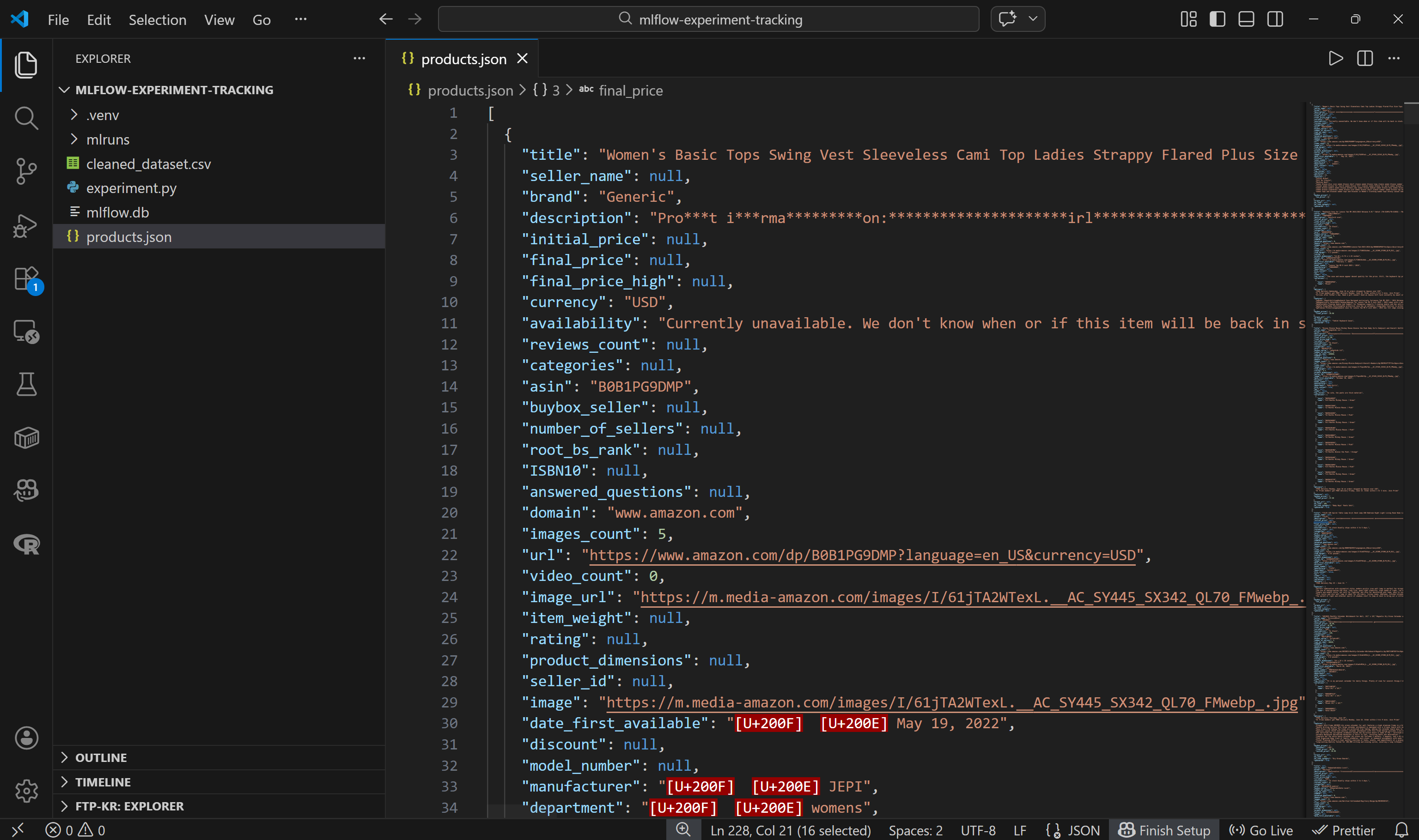
各Amazon製品は約45のデータフィールドを含むJSONオブジェクトとして表現されています。これにより実験のための豊富な基盤が提供されます。
これで準備完了です。このデータセットをコードに読み込み、処理を開始できます。
ステップ #5: データセットの読み込みと前処理
データセットをコードに読み込む前に、利用可能な列を調査する時間を取ってください。「Dictionary」タブに移動すると、各列の詳細情報(説明や出現率など)を確認できます: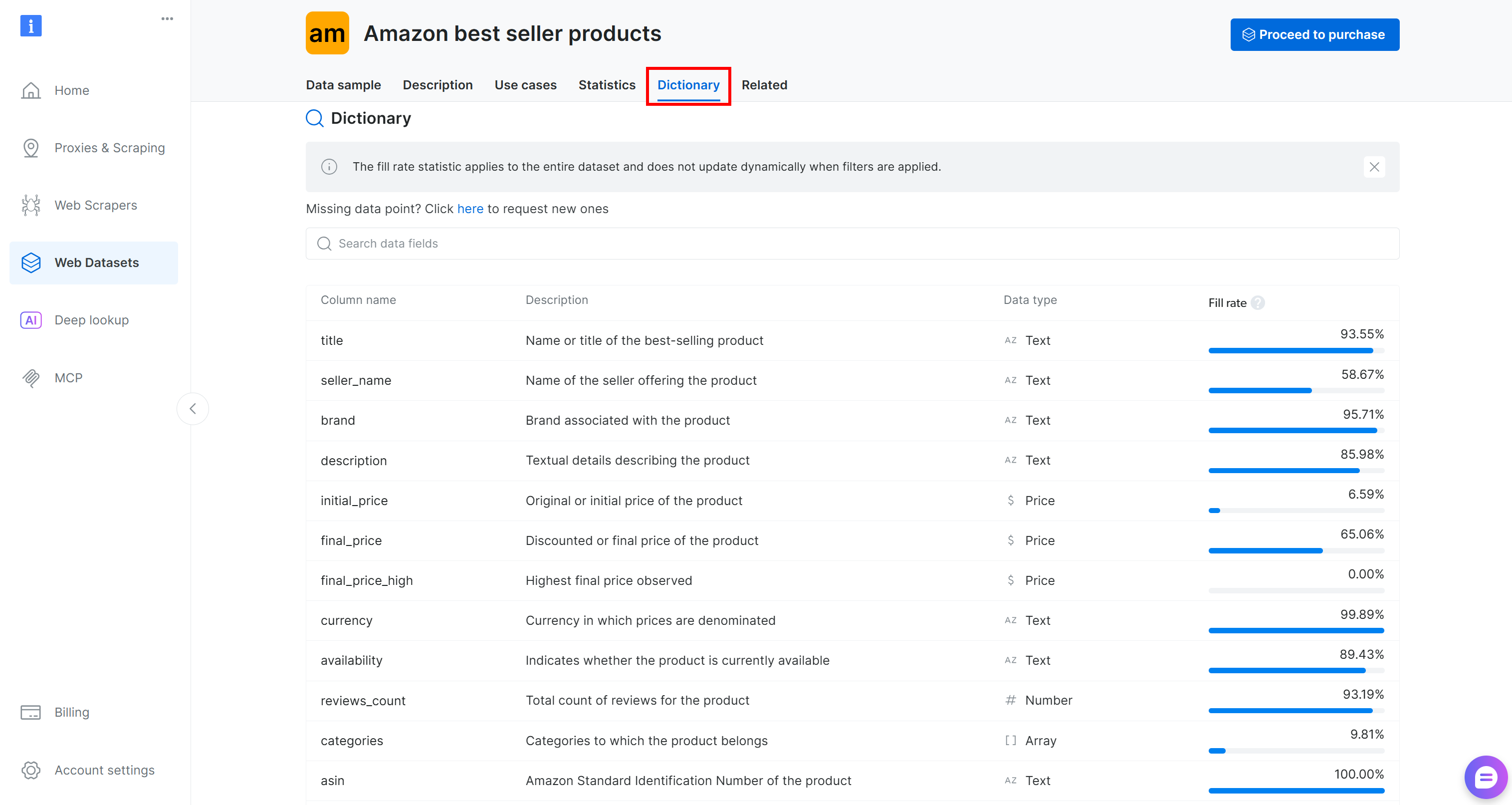
この場合、注目すべき列は以下の通りです:
brand(テキスト): 製品に関連するブランド名。final_price(価格): 製品の割引価格または最終価格。reviews_count(数値): レビューの総数。rating(数値): 商品の平均評価点。
次に、JSONファイルを読み込みます:
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)次にpandasDataFrameに変換します:
df = pd.DataFrame(data)final_price列を確認すると、数値のみ(例:1500)の場合もあれば、フォーマットされた文字列(例:$1,500)を含む場合もあることに気づくでしょう。
一貫した処理のため、すべての価格を数値形式に変換し、final_priceが nullの行を削除します:
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
df = df.dropna(subset=["final_price"])最後に、MLflowにデータセットを登録します:
# 特徴量列とターゲット列を定義
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# データセットソースを明示的に定義
dataset_source = CodeDatasetSource(tags="v1")
# メタデータ付きでMLflowにデータセットを登録
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET
)このコードは、MLパイプラインの入力特徴量(rating、reviews_count、brand)とターゲット変数(final_price)を定義します。その後、CodeDatasetSourceオブジェクトを作成し、選択したDataFrameをメタデータと共にMLflowに登録します。これにより、実験の追跡と再現性が確保されます。
素晴らしい!これでモデルトレーニングパイプラインでこのデータを使用する準備が整いました。
ステップ #6: 予測モデルパイプラインの定義
以下のロジックを使用して、MLモデルトレーニング用にデータを準備します:
# 特徴量とターゲットを分離
X = df[FEATURES]
y = df[TARGET]
# 前処理パイプライン:
# - 数値列に対する中央値補完
# - カテゴリカル列に対する定数埋め + ワンホットエンコーディング
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# フルMLパイプライン: 前処理 + RandomForestモデル
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# データセットを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)このスニペットは、以下の手順でデータを準備し、完全な機械学習パイプラインを構築します:
- 入力特徴量(
rating,reviews_count,brand)とターゲット(final_price)を分離。 - 数値特徴量には中央値補完、カテゴリ特徴量には定数埋め込みで欠損値を処理し、
ブランドテキストフィールドをワンホット符号化で数値形式に変換。これによりモデルがクリーンな数値入力を受け取る。 - 前処理をランダムフォレストモデルと組み合わせ、評価用にデータをトレーニングセットとテストセットに分割します。
よし!Bright DataでスクレイピングしたデータセットでMLflow実験を実行する時が来ました。
ステップ #7: MLflow エクスペリメントの実行
これでMLflow実験を実行する準備が整いました。以下のように実行します:
# MLflow実行を開始しシステムメトリクス追跡を有効化
with mlflow.start_run(log_system_metrics=True) as run:
# 実行への入力としてデータセットをログ記録
mlflow.log_input(mlflow_dataset, context="training")
# モデルパイプラインを学習
pipeline.fit(X_train, y_train)
# テストセットに対する予測を生成
predictions = pipeline.predict(X_test)
# 評価指標(RMSEとR2)をログに記録
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# 出力データセットCSVをローカルファイルにログ記録し、MLflowのアーティファクトとして保存
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# 署名と入力例付きで学習済みモデルをログに記録
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"実行完了。MLflow UIの'System Metrics'タブで実行ID: {run.info.run_id}を確認してください")上記のスニペットは次のことを行います:
- システムメトリクス追跡を有効にして MLflow 実行を開始します。
- トレース可能性と再現性のために、実験への入力として
mlflow_dataset を登録します。 - トレーニングデータに対して完全なMLパイプライン(前処理 + ランダムフォレスト)をフィッティングし、モデルパイプラインをトレーニングします。
- トレーニング済みモデルを活用し、テストセットのターゲット値を予測することで予測を生成します。
- モデル性能評価のため、MLflowにRMSEとR²を記録します。
- クリーンアップされたデータセットをアーティファクトとしてログに記録し、MLflowで参照用に探索できるようにします。
- 再現性を確保するため、入力シグネチャと入力例を含むトレーニング済みパイプラインをMLflowに登録します。
いいね!あとは最終コードを確認してMLflow実験を実行するだけです。
ステップ #8: 全てをまとめ実験を実行する
experiment.pyファイルには以下を含める:
# pip install mlflow pandas scikit-learn psutil nvidia-ml-py
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer
# 自動システムメトリクス記録を有効化 (CPU, メモリ等)
mlflow.enable_system_metrics_logging()
# sklearn のイベントを自動記録
mlflow.sklearn.autolog()
# システムメトリクスのサンプリング間隔を設定 (1秒)
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1)
# 入力Bright Dataデータセットファイルからスクレイピングした商品データをロード
# (ダウンロード先: /cp/datasets/browse/gd_l1vijixj9g2vp7563)
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# JSONをpandas DataFrameに変換
df = pd.DataFrame(data)
# ターゲット列"final_price"をクリーンアップ:
# - ドル記号とカンマを削除
# - 数値型に変換
# - 無効な値はNaNとなる
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
# ターゲット値が欠損している行を削除
df = df.dropna(subset=["final_price"])
# 特徴量列とターゲット列を定義
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# データセットソースを明示的に定義
dataset_source = CodeDatasetSource(tags="v1")
# メタデータ付きでMLflowにデータセットを登録
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET)
# 特徴量とターゲットを分離
X = df[FEATURES]
y = df[TARGET][TARGET]
# 前処理パイプライン:
# - 数値列に対する中央値補完
# - カテゴリカル列に対する定数埋め + ワンホットエンコーディング
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# フルMLパイプライン: 前処理 + RandomForestモデル
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# データセットを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# MLflow実験を設定
mlflow.set_experiment("brightdata_product_price_prediction")
# MLflow実行を開始し、システムメトリクス追跡を有効化
with mlflow.start_run(log_system_metrics=True) as run:
# 実行への入力としてデータセットをログ記録
mlflow.log_input(mlflow_dataset, context="training")
# モデルパイプラインを学習
pipeline.fit(X_train, y_train)
# テストセットに対する予測を生成
predictions = pipeline.predict(X_test)
# 評価指標(RMSEとR2)をログに記録
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# 出力データセットCSVをローカルファイルにログ記録し、MLflowのアーティファクトとして保存
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# 署名と入力例付きで学習済みモデルをログに記録
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"実行完了。MLflow UIの'System Metrics'タブで実行ID: {run.info.run_id}を確認してください")Python環境をアクティブ化した状態で、以下のコマンドでMLflow実験を実行します:
python experiment.py実行には数秒かかる場合がありますので、お待ちください。
ミッション完了! Bright Dataから取得したデータセットを用いたMLflow実験追跡パイプラインの実装が完了しました。
ステップ #9: MLflow 追跡結果の探索
http://127.0.0.1:5000/ の MLflow UI にアクセスしてください。brightdata_product_price_prediction エクスペリメントエントリ(コード内で MLflow エクスペリメントに付与された名前)が表示されるはずです。それをクリックしてください:
詳細を確認するには「トレーニング実行」セクションに移動します:
直前に実行した最新の実行結果が表示されます:
クリックすると、15以上のメトリクスに即時アクセスできます: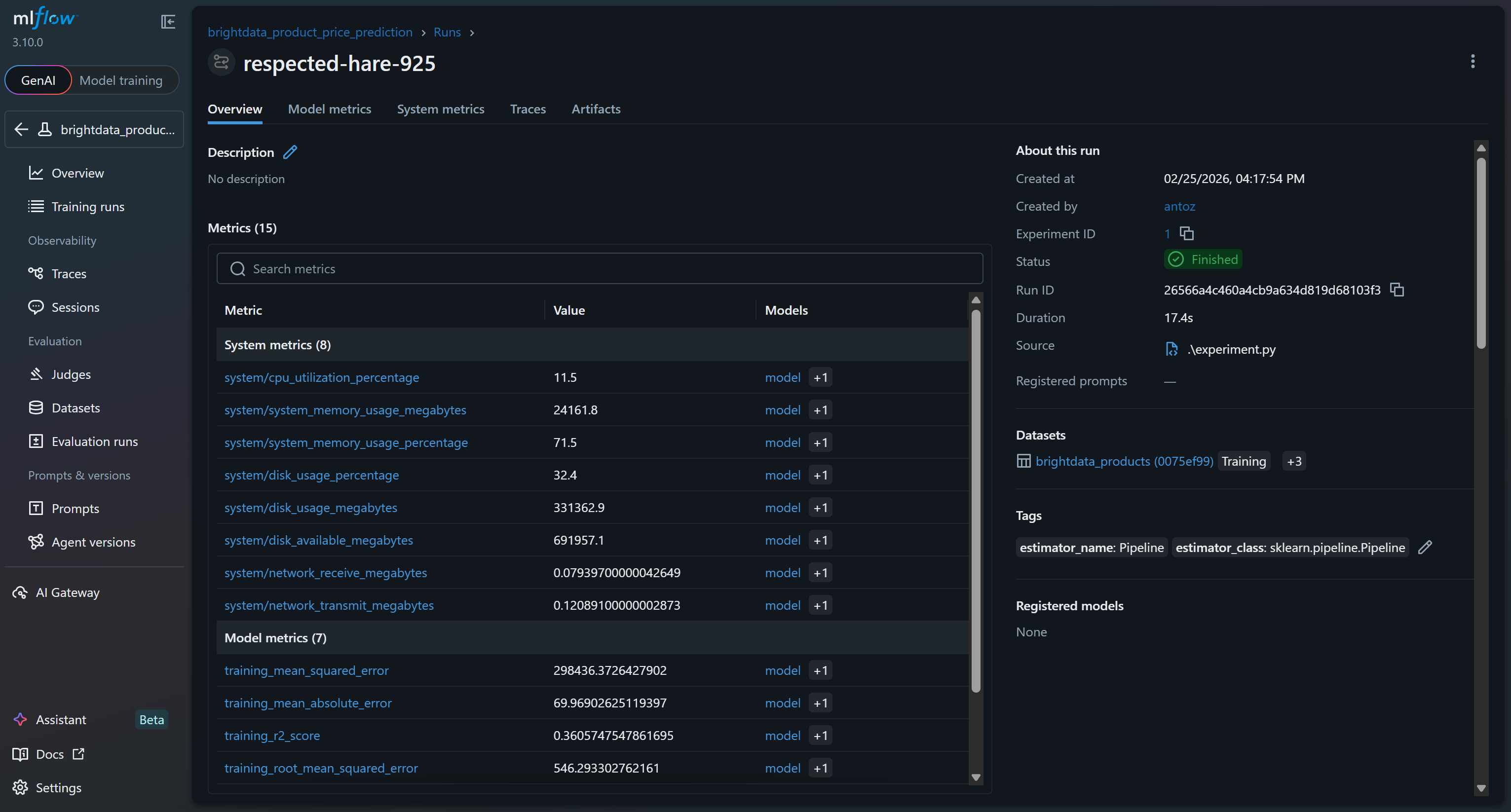
これには、MLflowのトレース機能によって自動的に収集されたシステムおよびモデルメトリクスに加え、実行中に記録されたモデルメトリクス(例:val_rmse、r2_score)が含まれます。
モデルメトリクスを調べるには、対応するタブにアクセスします: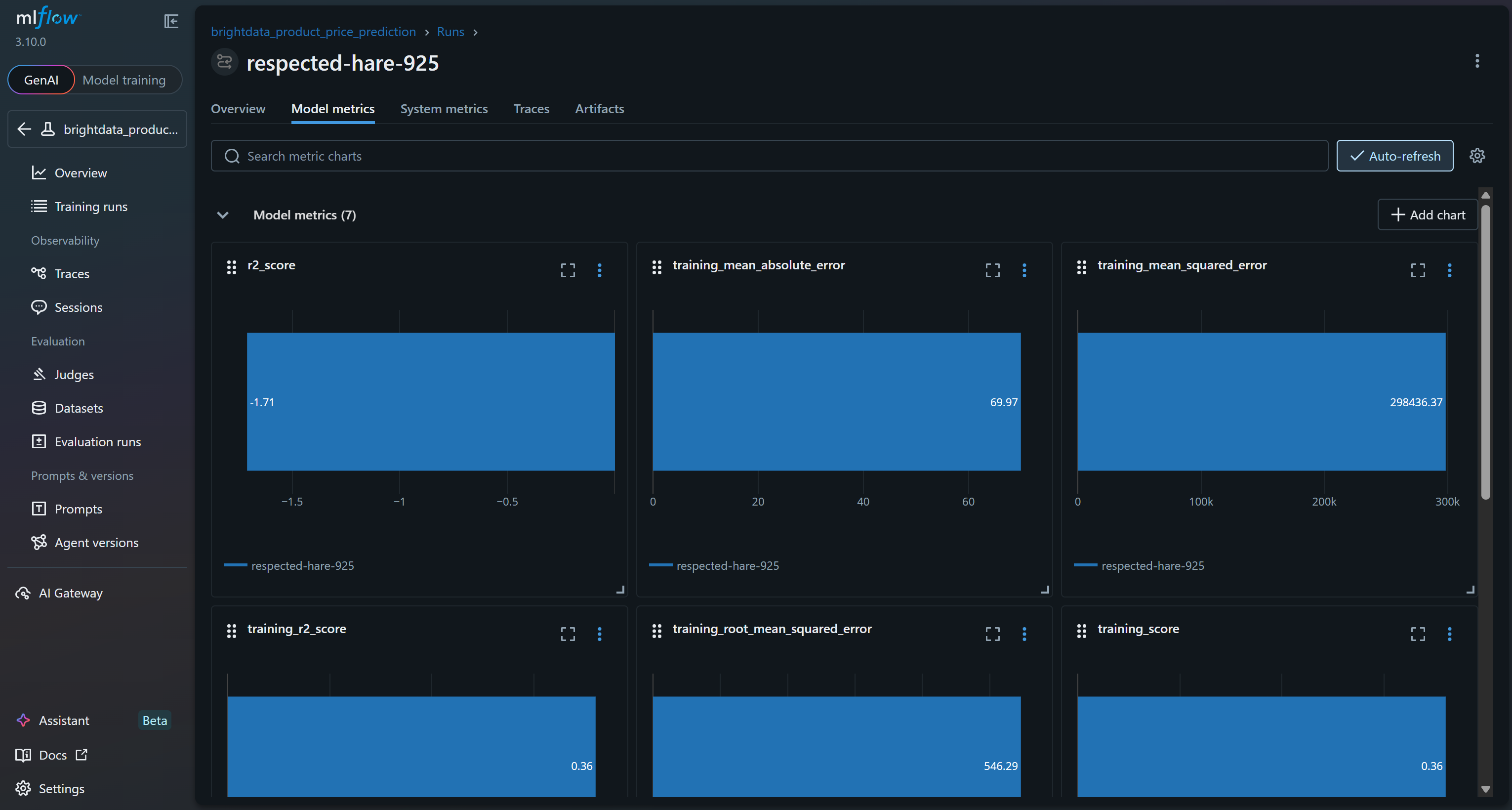
または「システムメトリクス」タブでシステムメトリクスのチャートを確認できます:
また、「アーティファクト」セクションには出力ファイル(コードで記録されたcleaned_dataset.csvファイルなど)が表示されます: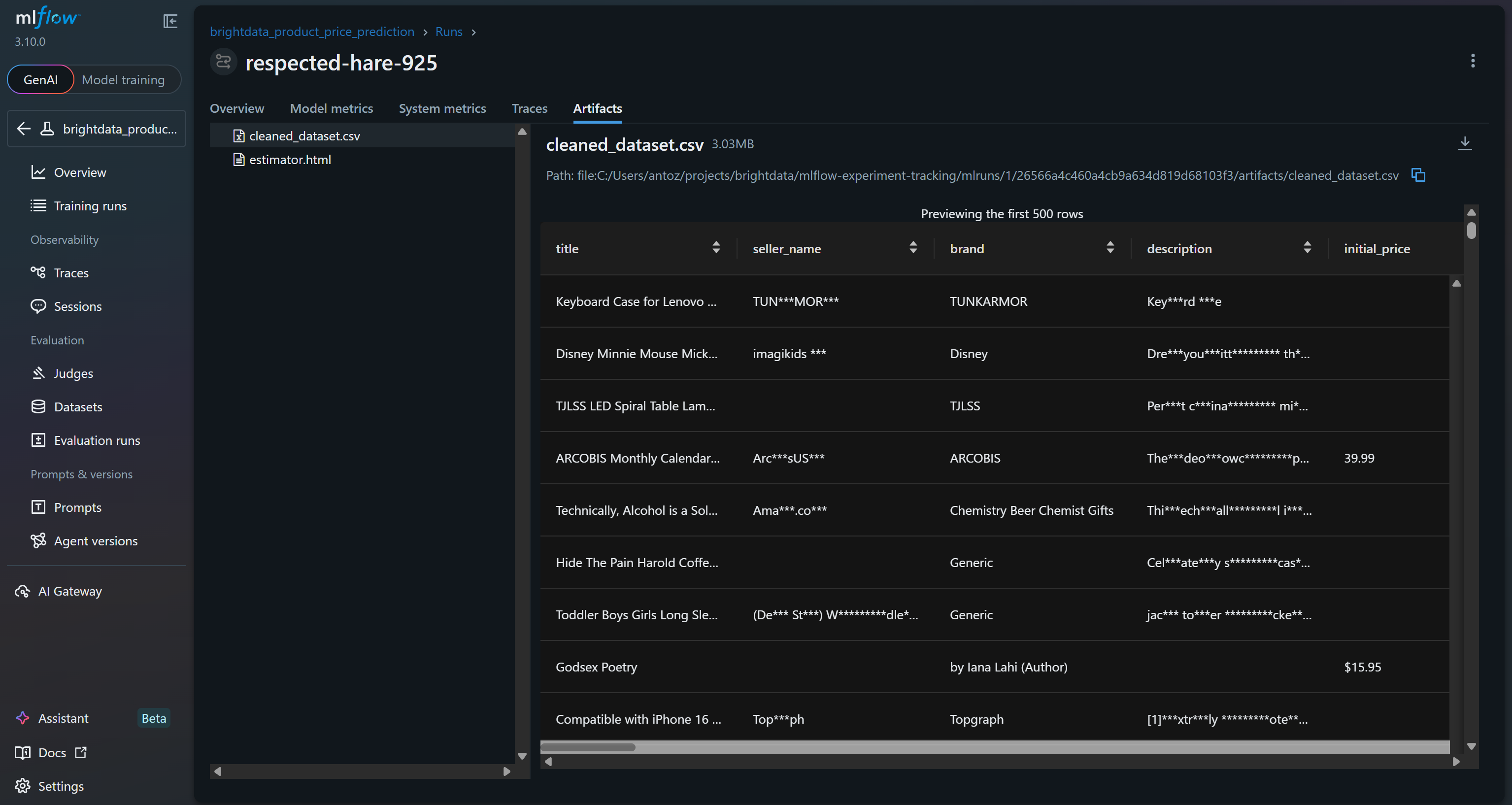
これらは、Bright Dataでスクレイピングしたデータセットを基盤に構築されたMLflow実験により追跡可能なメトリクスと出力の一例に過ぎません!
ステップ #10: 結果についてコメントする
モデルトレーニングプロセスが正常に動作したことを確認するには、モデルメトリクスに注目してください: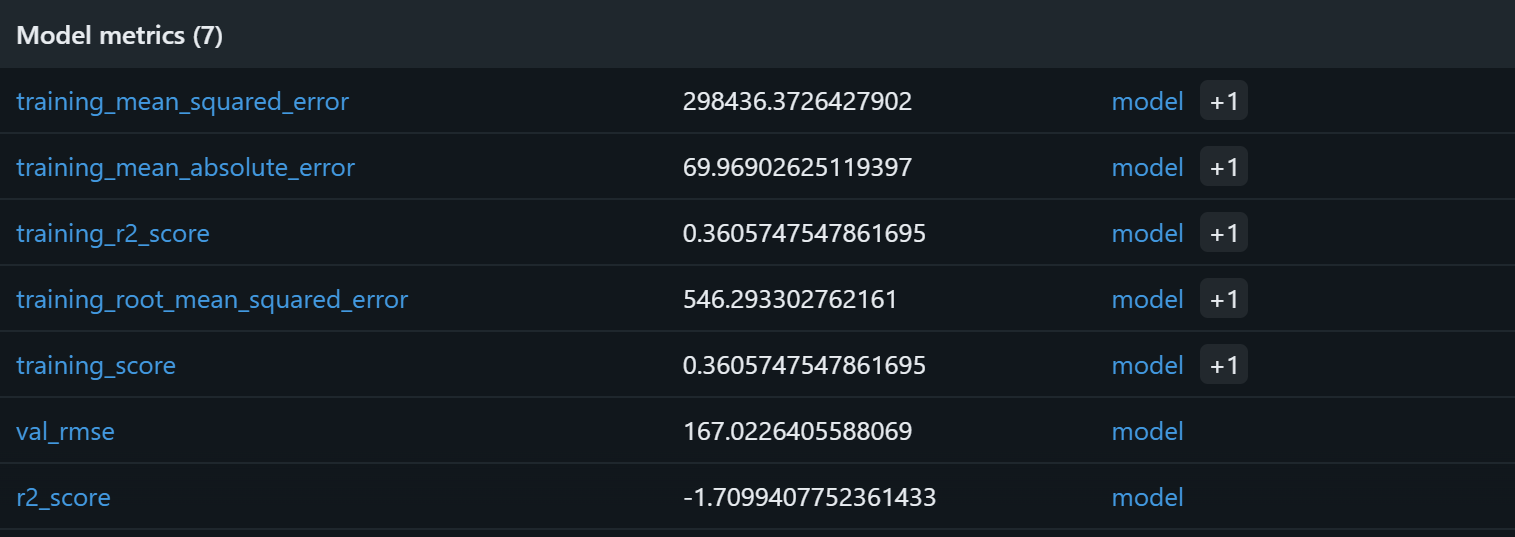
これらのモデルメトリクスに基づくと、現在のパイプラインは検証セットに対して無意味な予測を生成する可能性が高いです。トレーニングR²が0.36であることは、モデルがトレーニングデータの変動の約36%を説明していることを示しており、これは控えめな値です。トレーニングRMSE(546)とMAE(約70)は、典型的な製品価格と比較して誤差がかなり高いことを示唆しており、これはノイズの多いデータや特徴量とターゲット間の弱い相関が原因である可能性があります。
より懸念されるのは検証性能です:R²が負(-1.71)であり、検証RMSE(167)も依然として顕著です。負のR²は、全サンプルの平均価格を単純に予測するよりもモデルの性能が劣ることを意味します。これは、評価、レビュー数、ブランド、最終価格の間の想定される関係が、ランダムフォレストが効果的に捕捉するには強くないか、十分に線形でない可能性を示唆しています!
改善策としては、特徴量セットの拡張、特徴量エンジニアリング(例:レビュー数の対数変換、ブランド人気の符号化)、勾配ブースティングやXGBoostなどの代替モデルの試行、1,000サンプルのサブセットを超えるデータセット規模の拡大が考えられます。より大規模なBright Dataデータセットがあれば、データ量と多様性が増し、より深く関連性の高い実験が可能になります。
要するに、現在のパイプラインは技術的には機能しますが、根本的な価格パターンを適切に捉えられていません。MLflowの実験追跡機能のおかげで、この機械学習パイプラインの根底にある仮定がおそらく欠陥があることを特定できました。
次のステップ
Bright Dataデータセットを用いたAIパイプラインの追跡(微調整やRAG目的)にMLflowを利用する場合、MLflowトレースが完全にOpenTelemetry互換であることを留意してください。具体的には、MLflowはリクエストの中間ステップごとに、入力・出力・メタデータを捕捉するLLM可観測性ソリューションを提供します。
OpenAIとの統合時には、以下で簡単に有効化できます:
import mlflow
mlflow.openai.autolog() 詳細は公式MLflowドキュメントを参照してください。
まとめ
本チュートリアルでは、機械学習およびAIパイプラインの構築と追跡においてMLflowが提供する価値を確認しました。また、スクレイピングされたデータセットがモデルのトレーニングや微調整に優れたソースである理由も理解できたはずです。
実証した通り、Bright Dataは数百のドメインと数十億件のウェブデータレコードを網羅する豊富なデータセットマーケットプレイスを提供しています。これらのデータセットは機械学習とAIワークフローを支援するため、ウェブスクレイピングを通じて継続的に更新されています。具体的には、ここで示した通りMLflowトラッキングと完全に互換性があります。
今すぐ無料のBright Dataアカウントを作成し、当社のウェブデータソリューションを探索しましょう!






