

このガイドでは、ウェブデータを用いたLlama 4の微調整について学びます:
- ファインチューニングとは何か
- スクレイピングAPIを用いた微調整対応データセットの取得方法
- – ファインチューニングプロセス用のクラウドインフラ設定方法
- – ステップバイステップチュートリアルによるLlama 4のファインチューニング方法
さっそく始めましょう!
ファインチューニングとは?
ファインチューニング(監督付きファインチューニング:SFT)とは、事前学習済みLLMの特定の知識や能力を向上させるプロセスです。LLMの文脈における事前学習とは、AIモデルを一から訓練することを指します。
SFTが用いられる理由は、モデルが学習データを模倣する性質にある。しかし現状、LLMは主に汎用モデルである。つまり特定の知識を習得させたい場合、ファインチューニングが必要となる。
SFTについてさらに詳しく知りたい場合は、LLMにおける教師あり微調整に関するガイドをお読みください。
LLama 4のファインチューニング用データスクレイピング
LLMをファインチューニングするには、まずファインチューニング用データセットが必要です。このセクションでは、BrightDataのWeb Scraper APIを使用してウェブサイトからデータを取得する方法を説明します。これは100以上のドメイン向けに設計された専用エンドポイントで、最新のデータをスクレイピングし、指定された形式で取得します。
対象ウェブページはAmazonのオフィス用品ベストセラーページとします:
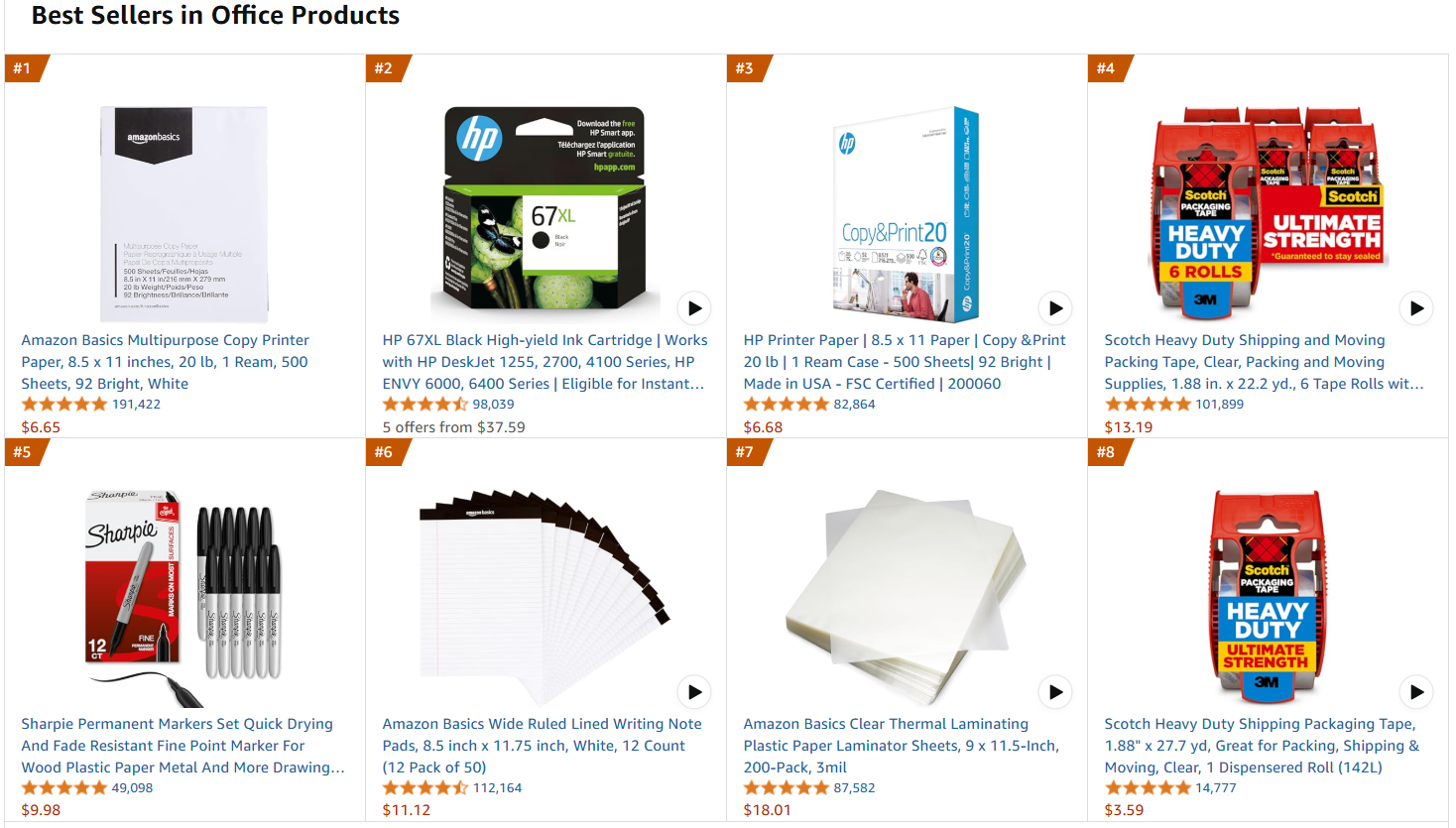
以下の手順に従ってファインチューニングデータを取得しましょう!
必要条件
Amazonからデータを取得するコードを使用するには、以下が必要です:
- Python 3.10以上がマシンにインストールされていること。
- 有効なBright DataスクレイパーAPIキー。
APIキーの取得方法については、Bright Dataのドキュメントに従ってください。
プロジェクト構造と依存関係
プロジェクトのメインフォルダをamazon_scraper/とします。このステップ終了時、フォルダ構造は以下のようになります:
amazon_scraper/
├── scraper.py
└── venv/各要素の説明:
scraper.pyはコーディングロジックを含む Python ファイルです。venv/は仮想環境を含みます。
venv/ 仮想環境ディレクトリは以下のように作成できます:
python -m venv venvWindowsで有効化するには、以下を実行します:
venvScriptsactivatemacOS および Linux では、同等の操作として以下を実行します:
source venv/bin/activateアクティブ化された仮想環境内で、依存関係をインストールするには:
pip install requestsここでrequests はHTTP ウェブリクエストを行うためのライブラリです。
素晴らしい!これでBright DataのスクレイパーAPIを使用して必要なデータを取得する準備が整いました。
ステップ #1: スクラッピングロジックの定義
以下のスニペットがスクレイピングロジック全体を定義します:
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
# Web スクレイパー API タスクをトリガーするエンドポイント
url = "https://api.brightdata.com/data sets/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
# API呼び出し用にデータを変換
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"リクエスト成功! 応答: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"リクエスト失敗! エラー: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"スナップショットID: {snapshot_id} の取得を開始します...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("スナップショットの準備が完了しました。 ダウンロード中...")
snapshot_data = response.json()
# スナップショットを出力用jsonファイルに書き込む
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"スナップショットを {output_file} に保存しました")
return
elif response.status_code == 202:
print(F"スナップショットはまだ準備できていません。{polling_timeout} 秒後に再試行します...")
time.sleep(polling_timeout)
else:
print(f"リクエスト失敗! エラー: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<YOUR api key>" # Bright DataのWebスクレイパーAPIキーに置き換えるか、環境変数から読み取る
# データを取得するベストセラー商品のURL
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")このコードは:
-
- トリガー対象のスクレイパーAPIエンドポイントを定義します。
- スクレイピング活動のパラメータを設定します。
- APIが期待するJSON構造へ入力
URLをフォーマット。 - 指定されたエンドポイント、ヘッダー、パラメータ、データと共にBright DataスクレイパーAPIへ
POSTリクエストを送信します。 - レスポンスステータスの管理。
poll_and_retrieve_snapshot()関数を作成し、スクレイピングタスク(snapshot_idで識別)のステータスを確認し、準備が整い次第データを取得します。
注:スクレイピングAPIは1つのURLのみを使用して呼び出されています。したがって、上記のコードは1つの対象Amazonページからのデータのみを取得します。このチュートリアルの範囲ではこれで十分ですが、リストに任意の数のAmazon URLを追加できます。
追加するURLが増えるほど、データセットのサイズも増加します。適切に管理された大規模なデータセットは、より良い微調整を意味します。一方で、データセットが大きくなるほど、必要な計算時間も長くなります。
完璧です!スクレイピングロジックは明確に定義されており、スクリプトを実行する準備が整いました。
ステップ #2: スクリプトの実行
対象ウェブページをスクレイピングするには、以下のコマンドでスクリプトを実行します:
python スクレイパー.py以下のような結果が表示されます:
リクエスト成功! 応答: s_m9in0ojm4tu1v8h78
ID: s_m9in0ojm4tu1v8h78 のスナップショットをポーリング中...
スナップショットはまだ準備できていません。20秒後に再試行...
# ...
スナップショットはまだ準備できていません。20秒後に再試行...
スナップショットの準備が完了しました。ダウンロード中...
スナップショットをamazon-data.jsonに保存しました処理終了時、プロジェクトフォルダには以下が含まれます:
amazon_scraper/
├── scraper.py
├── amazon-data.json # <-- 注:微調整用データセット
└── venv/プロセスにより自動的に作成されたamazon-data.jsonにはスクレイピングされたデータが含まれます。以下はJSONファイルの想定される構造です:
[
{
"title": "Amazon Basics 汎用コピー用紙、8.5 x 11インチ、20ポンド、1連(500枚)、92 GE ブライトホワイト",
"seller_name": "Amazon.com",
"brand": "Amazon Basics",
"description": "製品説明 Amazon Basics 多目的コピー用紙、8.5 x 11インチ 20Lb 紙 - 1連 (500枚)、92 GE 明るい白色 メーカー AmazonBasics",
"initial_price": 6.65,
"currency": "USD",
"availability": "在庫あり",
"reviews_count": 190989,
"categories": [
"事務用品",
"オフィス&スクール用品",
"紙",
"コピー&印刷用紙",
"コピー&多目的用紙"
],
...
// 簡略化のため省略...
}素晴らしい!Amazonからデータをスクレイピングし、JSONファイルに保存することに成功しました。このJSONファイルは、後で微調整プロセスで使用する微調整用データセットです。
Hugging FaceでLlama 4を使用するための設定
使用するモデルはHugging FaceのLlama-4-Scout-17B-16E-Instructです。
Hugging Faceを初めて利用する場合、リンクをクリックするとアカウント作成を求められます:
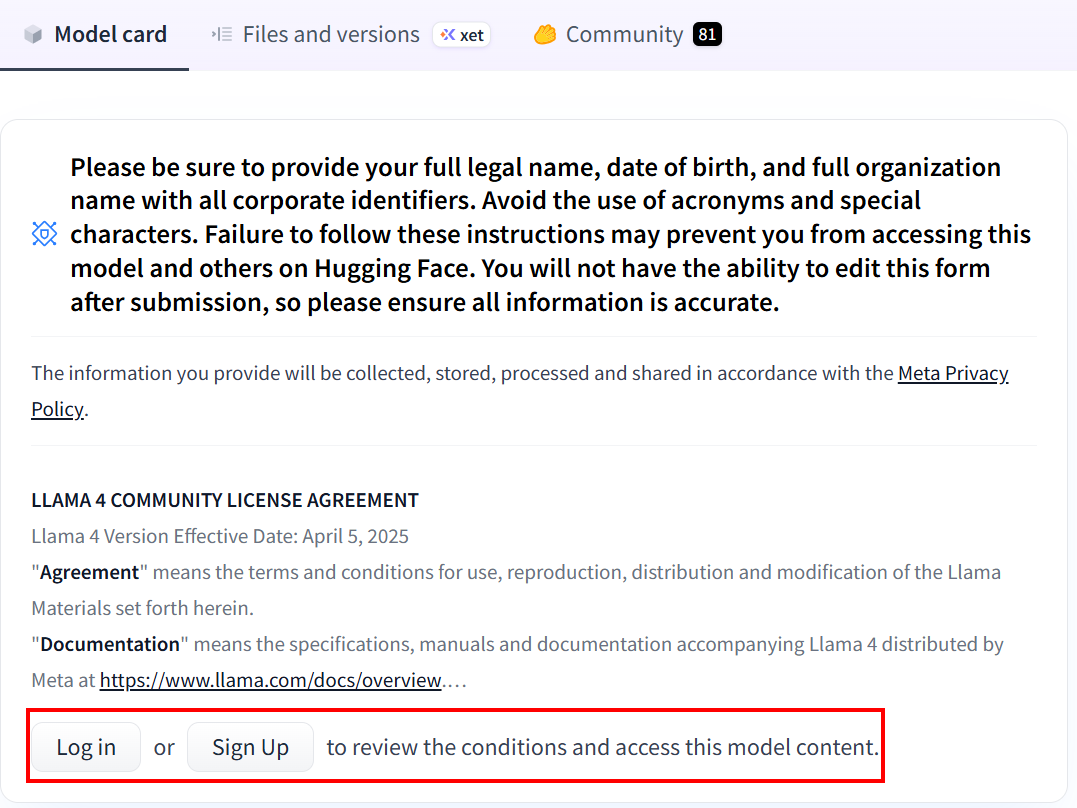
アカウント作成後、Llama 4モデルを初めて使用する場合は、同意書への同意が必要です。「Expand to review and access」をクリックして同意書を読み、同意してください:
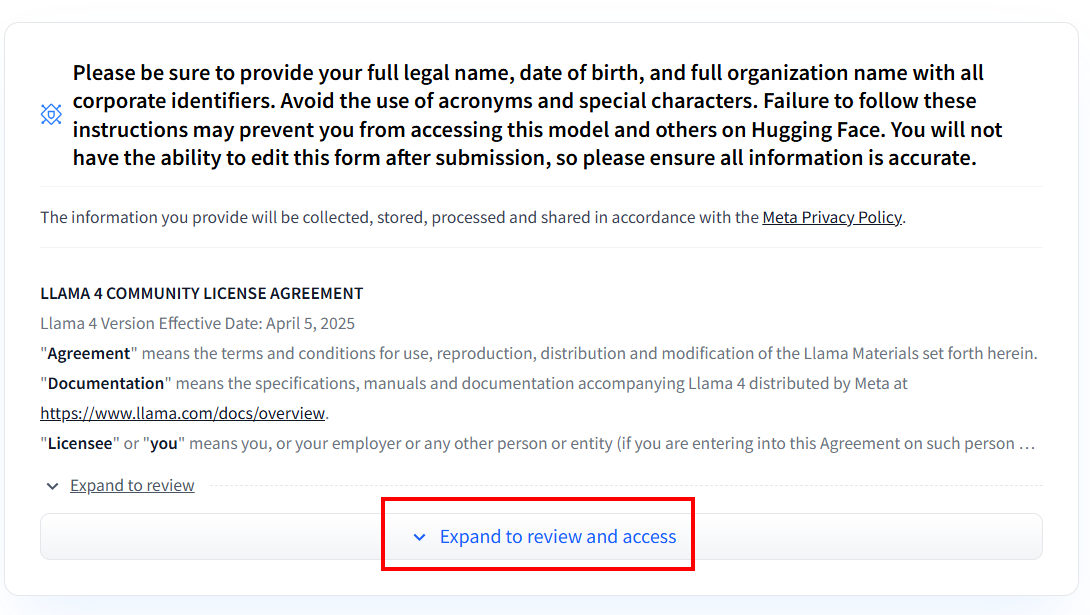
フォーム記入後、リクエストは審査されます:
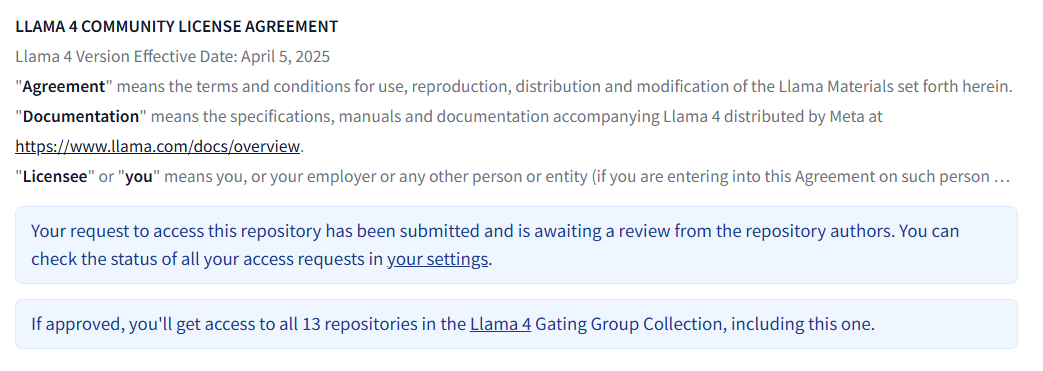
「Gated Repositories」セクションでリクエストのステータスを確認してください:
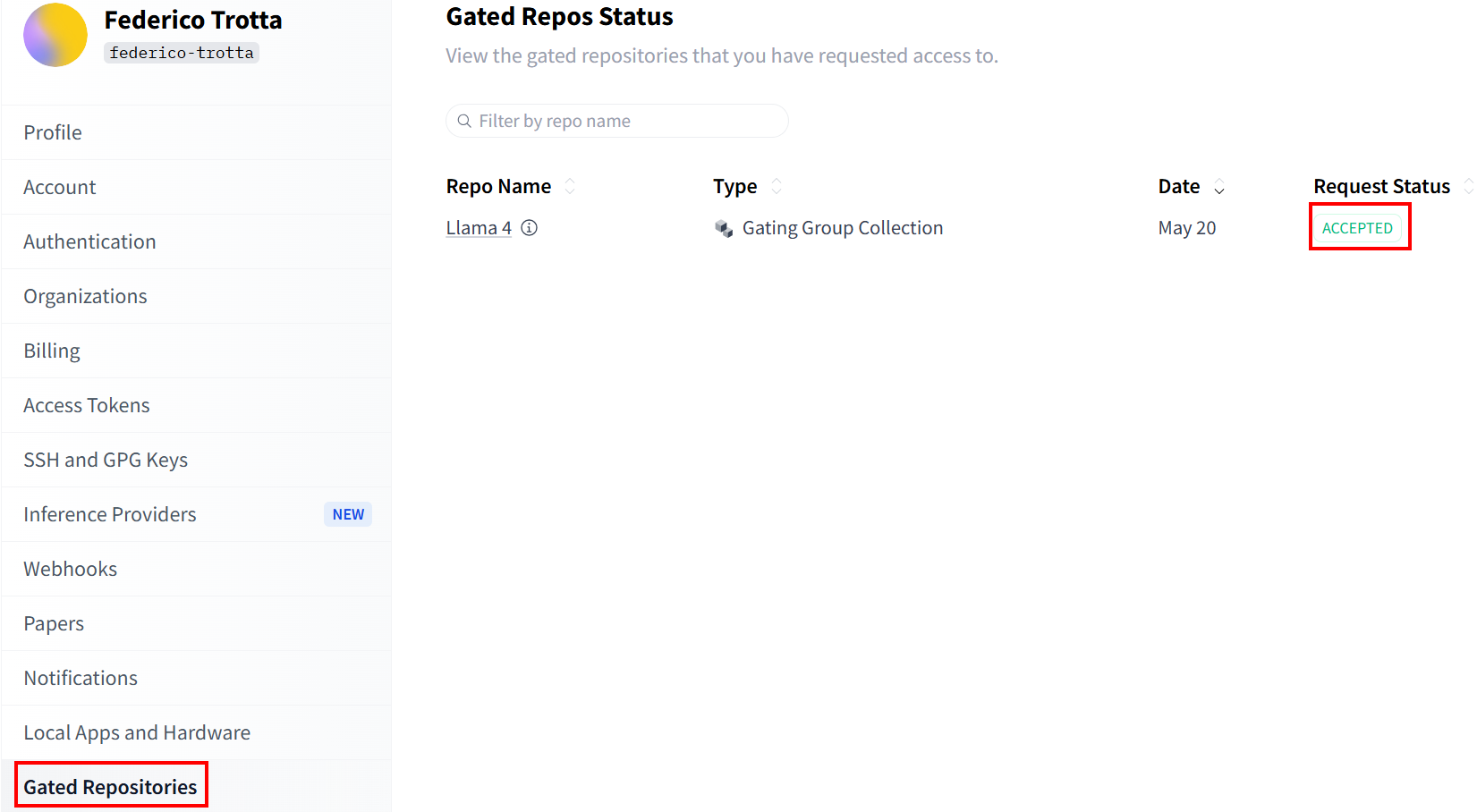
リクエストが承認されると、新しいトークンを作成できます。「アクセストークン」に移動し、書き込み権限付きのトークンを作成してください。その後、後で使用できるよう安全な場所にコピーして保存してください:
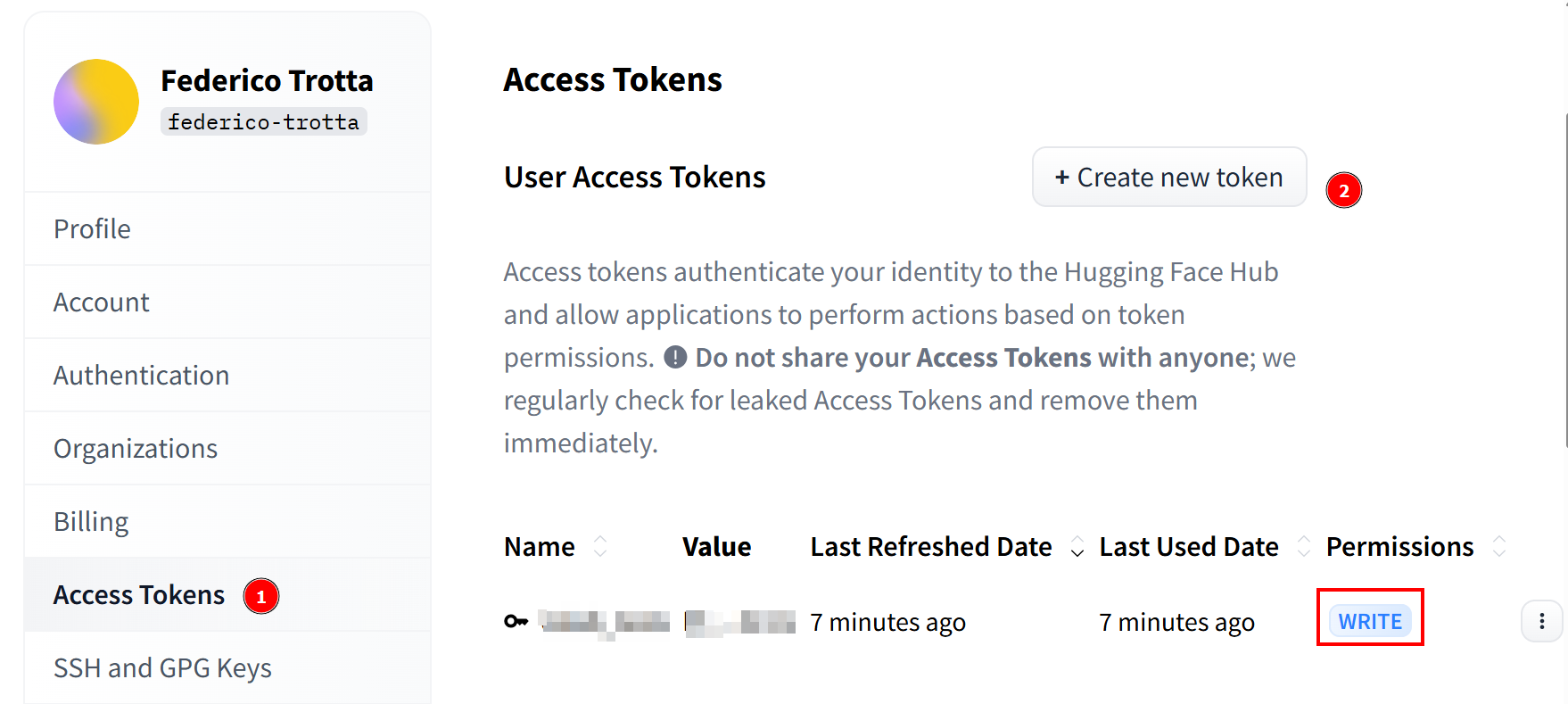
おめでとうございます!Hugging FaceでLlama 4モデルを使用するために必要なすべての手順を完了しました。
Llama 4のファインチューニング用クラウドインフラのセットアップ
Llama 4モデルは非常に大規模です。その名称からもその規模が伺えます。例えば「Llama-4-Scout-17B-16E-Instruct」は、170億のパラメータと128のエキスパートを持つことを意味します。
ファインチューニングプロセスでは、事前に取得したファインチューニングデータセットを用いてモデルを訓練する必要があります。170億のパラメータを持つモデルを訓練するには、大量のハードウェアが必要です。具体的には複数のGPUが必須です。このため、ファインチューニング処理にはクラウドサービスを利用します。
本チュートリアルではクラウドサービスとしてRunPodを使用します。「RunPod」にアクセスしアカウントを作成してください。その後「Billing」メニューでクレジットカードを使用して25ドルを追加します:
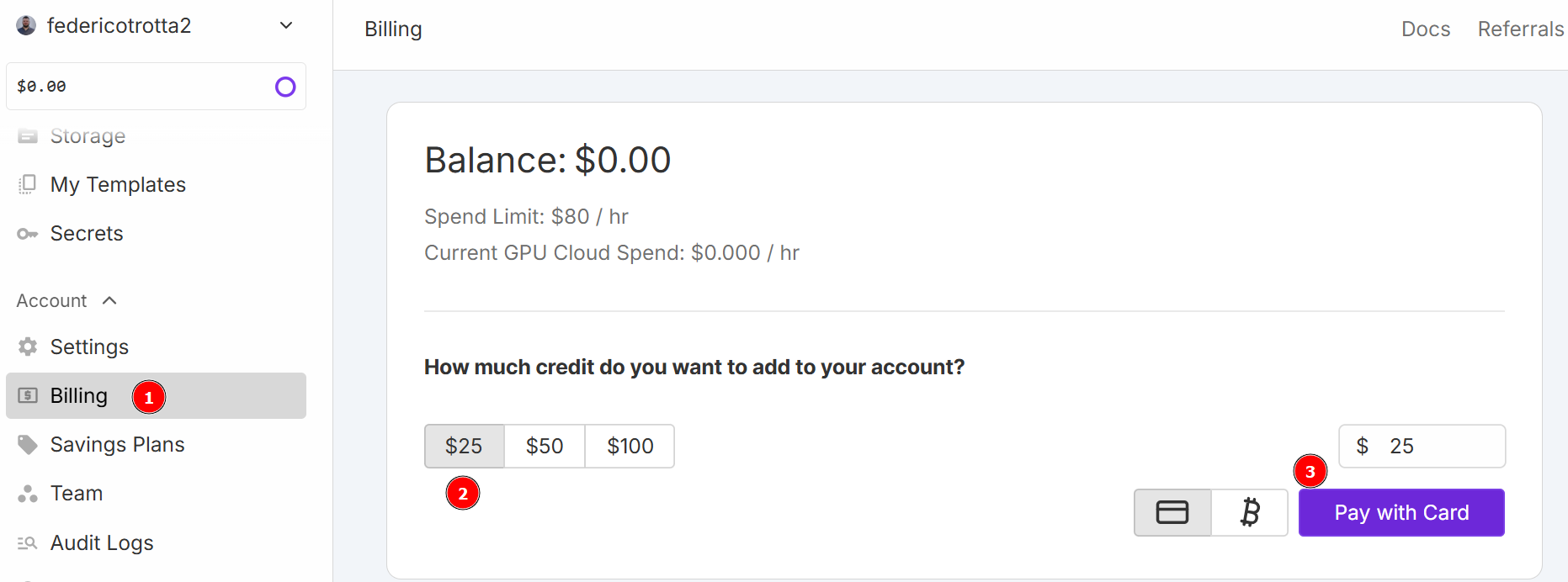
注:即時25ドルが請求され、RunPodは同額のクレジットをアカウントに付与します。クレジットは時間単位で消費され、デプロイ時のPod稼働時間に応じて課金されます。そのため、確実に使用できる場合にのみデプロイしてください。さもなければ、実際に使用していない間もクレジットが消費されます。実際の時間当たりの消費量は、次のステップで選択するGPUの種類と台数によって異なります。
「Pods」メニューに移動し、ポッドの設定を開始します。ポッドは仮想サーバーとして機能し、タスクに必要なCPU、GPU、メモリ、ストレージを提供します。「Deploy」ボタンをクリックしてください:
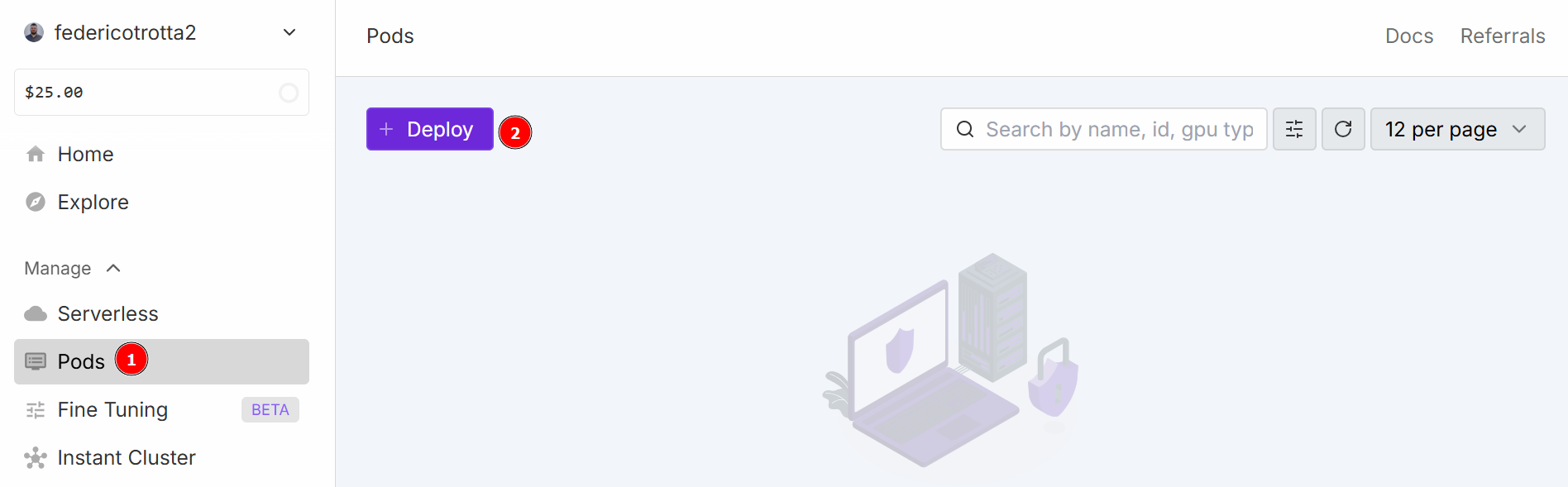
以下の構成から選択できます:
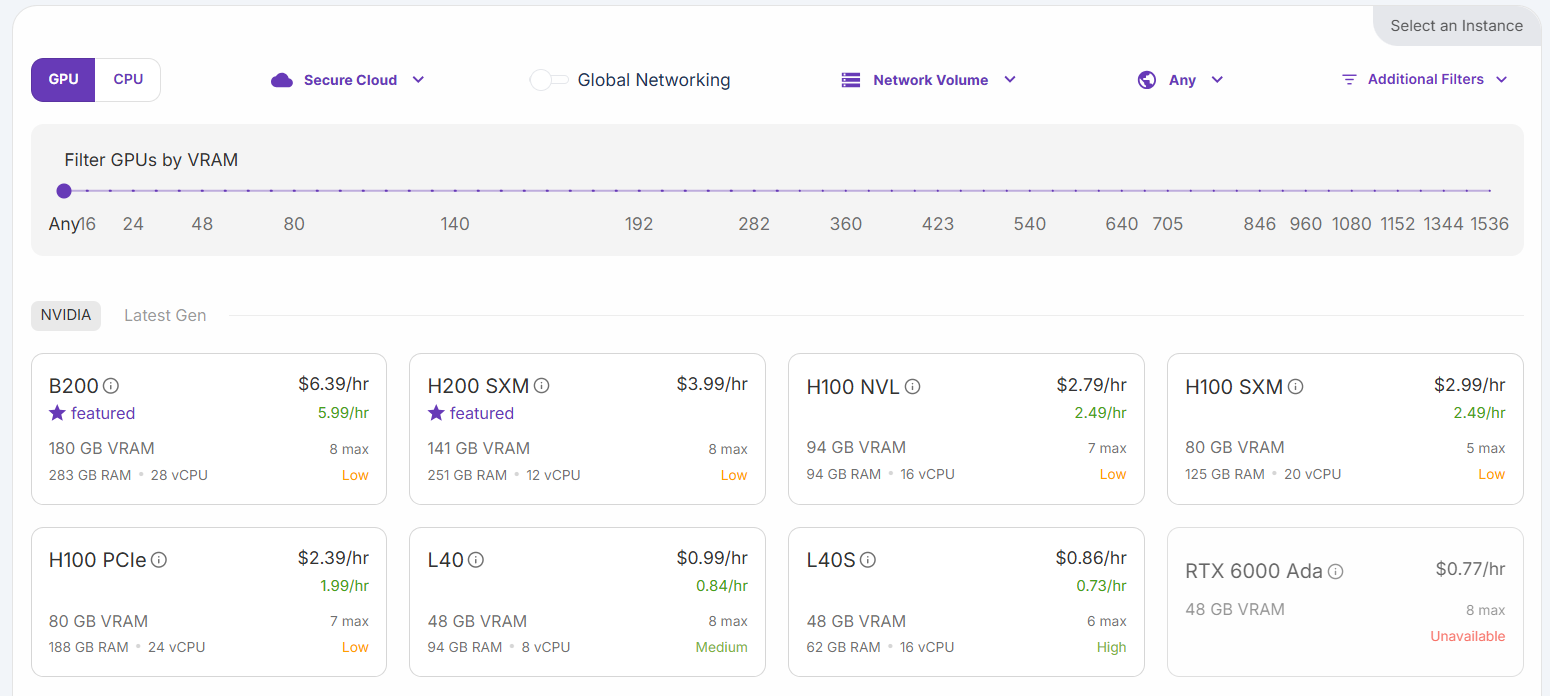
「H200 SXM GPU」オプションを選択します。ポッドに名前を付け、GPUの数を指定します。このチュートリアルでは3 GPUで十分です:
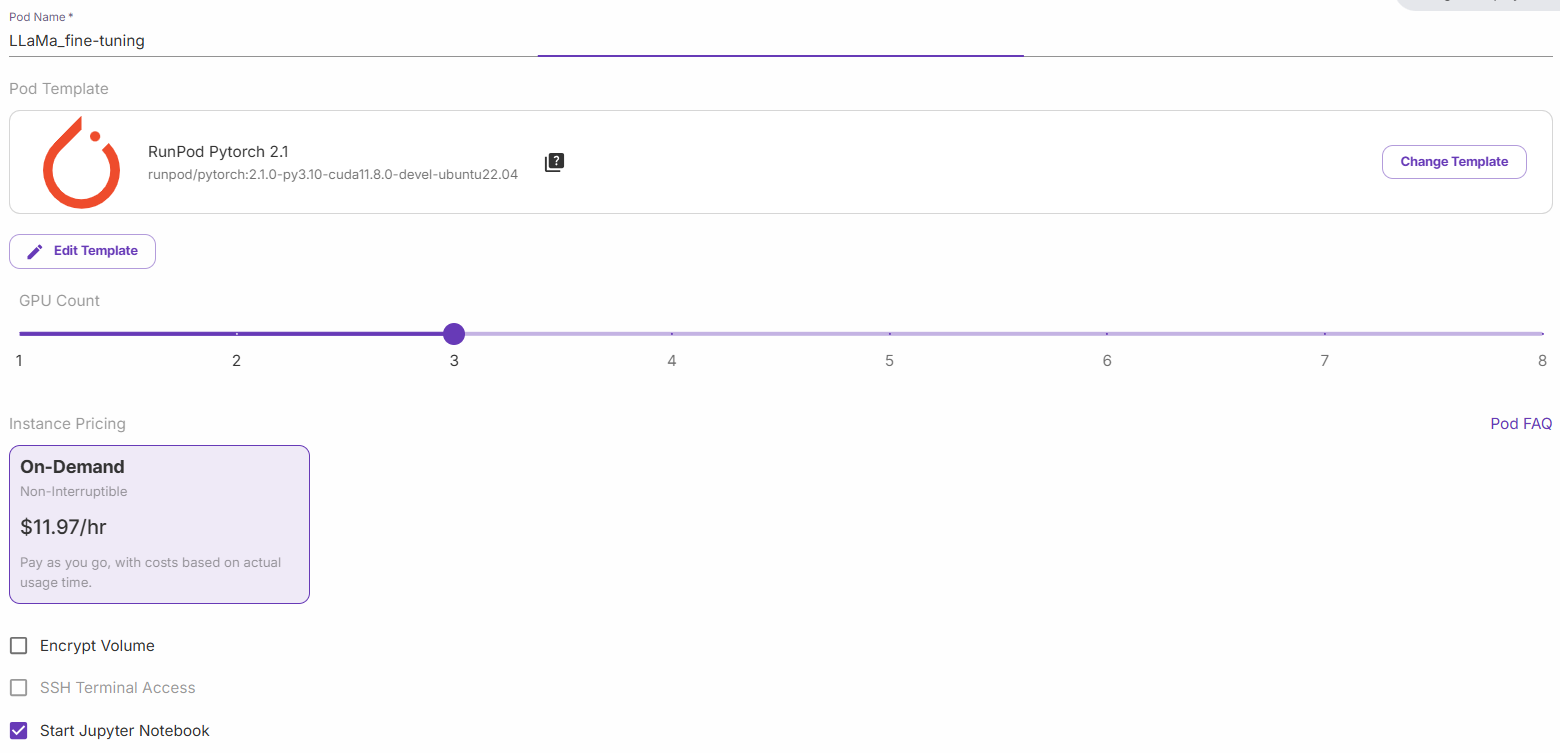
「Jupyter Notebookを起動」を選択し、「オンデマンドでデプロイ」をクリックします。次に「Pods」セクションに移動し、Podを編集します:
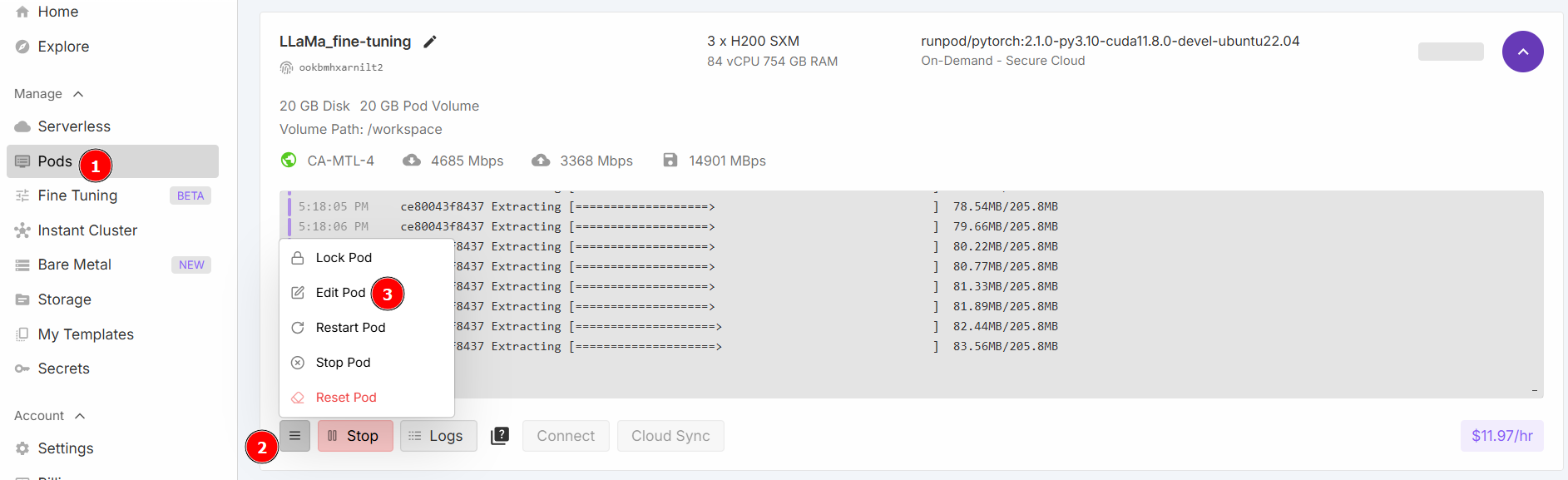
「Contained Disk」と「Volume Disk」の値を以下のように変更し、保存します:
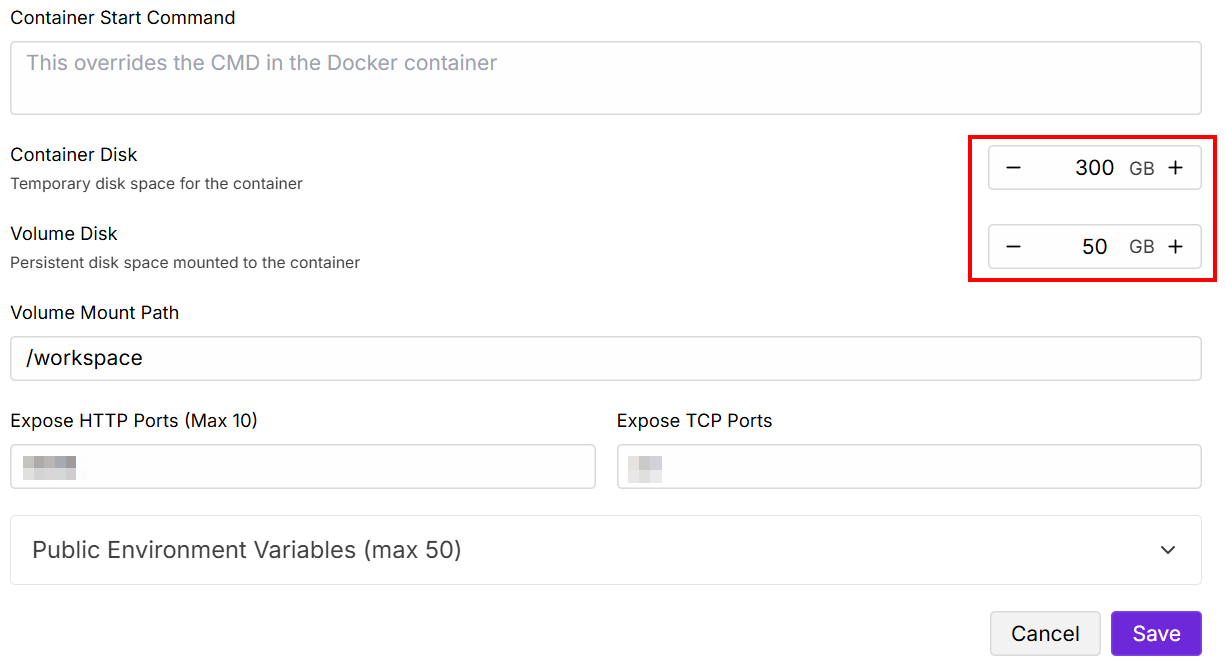
設定が完了したら、「接続」ボタンをクリックします:

これによりポッドをJupyter Labノートブックに接続できます:
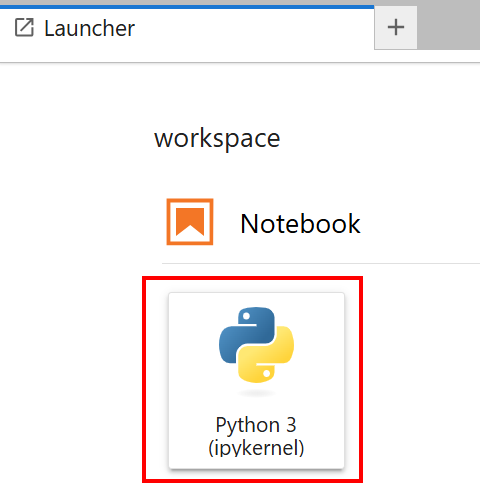
「Python 3 (ipykernel)」カードが付いたノートブックを選択します:
これで完了です!Llama 4モデルのトレーニングに必要なインフラが整いました。
スクレイピングしたデータを用いたLlama 4のファインチューニング
モデルの微調整を開始する前に、amazon-data.jsonファイルをJupyterLabノートブックにアップロードしてください。そのためには「ファイルをアップロード」ボタンをクリックします:
このチュートリアルの微調整の目的は、amazon-data.jsonデータセットを使用してLlama4をトレーニングすることです。これにより、オブジェクトの名前や特徴などの特性から、オフィス用品の説明文を生成する方法をLlama 4に教えます。
これでモデルのトレーニングを開始する準備が整いました。以下の手順に従い、最新のウェブデータでLlama 4をファインチューニングしましょう!
ステップ #1: ライブラリのインストール
ノートブックの最初のセルで、必要なライブラリをインストールします:
%%capture
!pip install transformers==4.51.0
%pip install -U データセット
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]これらのライブラリは以下のものです:
transformers: 数千の事前学習済みモデルを提供します。データセット: 膨大なデータセットコレクションと効率的なデータ処理ツールへのアクセスを提供します。accelerate: コード変更を最小限に抑えつつ、様々な分散構成でPyTorchトレーニングスクリプトの実行を簡素化します。peft: 事前学習済みモデルのパラメータの一部のみを更新することで、大規模モデルの微調整を効率的に行います。trl: 強化学習技術を用いたトランスフォーマー言語モデルのトレーニング向けに設計されています。scipy: Python での科学技術計算のためのライブラリ。huggingface_hub: Hugging Face Hub と連携するための Python インターフェースを提供します。これにより、モデル、データセット、Spaces のダウンロードとアップロードが可能になります。bitsandbytes: 使いやすい 8 ビットオプティマイザと量子化関数を提供し、大規模な深層学習モデルのトレーニングと推論のメモリフットプリントを削減します。
完璧です!ファインチューニングに必要なライブラリをインストールしました。
ステップ #2: Hugging Face への接続
ノートブックの2番目のセルに以下を記述してください:
from huggingface_hub import notebook_login, login
# 対話型ログイン
notebook_login()
print("ログインセルを実行しました。成功した場合、続行できます。")実行すると以下が表示されます:
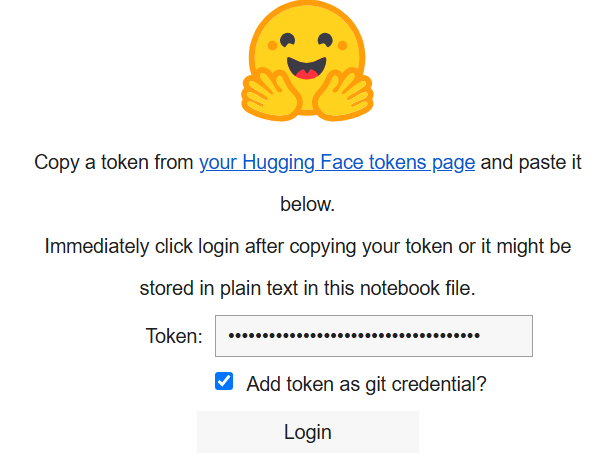
「Token」ボックスに、Hugging Faceアカウントで作成したトークンを貼り付けてください。
素晴らしい!これでHugging FaceからLlama 4モデルを取得できるようになりました。
ステップ #3: Llama 4モデルの読み込み
ノートブックの3番目のセルに以下のコードを記述してください:
import os
import torch
import json
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, Llama4ForConditionalGeneration, BitsAndBytesConfig
from trl import SFTTrainer
# モデルの読み込み
base_model_name = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
# BitsAndBytes量子化の設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
# 指定した設定でLlama4モデルを読み込み
model = Llama4ForConditionalGeneration.from_pre-trained(
base_model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
# モデルのキャッシュを無効化
model.config.use_cache = False
# 事前学習のテンソル並列処理を1に設定
model.config.pre-training_tp = 1
# ファインチューニング用JSONデータファイルのパス
fine_tuning_data_file_path = "amazon-data.json"
# 出力モデルディレクトリ
output_model_dir = "results_llama_office_items_finetuned/"
final_model_adapter_path = os.path.join(output_model_dir, "final_adapter")
max_seq_length_for_tokenization = 1024
# 出力ディレクトリ作成
os.makedirs(output_model_dir)上記のスニペット:
base_model_nameで読み込むモデルの名称を定義します。BitsAndBytesConfig()メソッドを使用してbnb_configでモデルの重みを設定します。from_pre-trained()メソッドでモデルを読み込み、トレーニングを実施。fine_tuning_data_file_pathで微調整用データセットを読み込みます。- 結果の出力ディレクトリパスを定義し、
makedirs()メソッドで作成します。
セルの実行が完了すると、次のような結果が表示されます:

素晴らしい!Llama 4モデルの設定が完了し、ノートブックに読み込まれました。
ステップ #4: トレーニングプロセス用の微調整データセットを準備する
トレーニングプロセス用にファインチューニングデータセットを準備するため、ノートブックの4番目のセルに以下のコードを記述します:
from datasets import Dataset
# ファインチューニングデータセットを開く
with open(fine_tuning_data_file_path, "r") as f:
data_list = json.load(f)
# データ項目のリストをHugging Face Datasetオブジェクトに変換
raw_fine_tuning_dataset = Dataset.from_list(data_list)
print(f"JSONデータをHugging Face データセットに変換しました。例の数: {len(raw_fine_tuning_dataset)}")
def format_fine_tuning_entry(data_item):
system_message = "あなたはプロのコピーライターです。提供された詳細に基づいて、簡潔で魅力的な製品説明を生成してください。"
# 以下の行をファインチューニングファイルに合わせて調整
item_title = data_item.get("title")
item_brand = data_item.get("brand")
item_category = data_item.get("categories")
item_name = data_item.get("name")
item_features_list = data_item.get("features")
item_features_str = ", ".join(item_features_list) if isinstance(item_features_list, list) else str(item_features_list)
target_description = data_item.get("description")
# トレーニング用プロンプト
user_prompt = (
f"以下のアイテムの説明文を生成してください:n"
f"タイトル: {item_title}nブランド: {item_brand}nカテゴリ: {item_category}n"
f"名称: {item_name}n特徴: {item_features_str}n説明:"
)
# Llamaチャットフォーマット
formatted_string = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn{target_description}<|eot_id|>"
)
return {"text": formatted_string}
# フォーマット関数を生のデータセットの各エントリに適用し、微調整用に構造化
text_formatted_dataset = raw_fine_tuning_dataset.map(format_fine_tuning_entry)
# トークナイザー設定
tokenizer = AutoTokenizer.from_pre-trained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# データセットの事前トークナイゼーション
def tokenize_function_for_sft(examples):
# チャット形式の全文を含む"text"フィールドをトークン化
tokenized_output = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=max_seq_length_for_tokenization,
)
return tokenized_output
# フォーマット済みデータセットにトークン化関数を適用
tokenized_train_dataset = text_formatted_dataset.map(
tokenize_function_for_sft,
batched=True,
remove_columns=["text"]
)このノートブックのセル:
- 微調整用データセットを開き、
Dataset.from_list()メソッドを使用して Hugging FaceDatasetオブジェクトに変換します。 format_fine_tuning_entry()関数を定義します。この関数の目的は、単一のデータ項目(製品の詳細)を受け取り、Llama のようなチャットモデルの指示微調整に適した構造化テキスト形式に変換することです。これは、微調整データセットの構造に合わせて調整する必要があることに注意してください。- データセットをトークン化し、
map()メソッドでトークン化を適用します。これは、言語モデルが生のテキストを理解せず、トークンと呼ばれる数値表現で処理するためです。
セルの実行が完了した際の期待される結果は次の通りです:

「例の数」の値は、ご使用のファインチューニングデータセットによって異なります。
素晴らしい!これでファインチューニングデータセットが準備完了です。
ステップ #5: パラメータ効率化ファインチューニング (PEFT) の環境とパラメータを設定する
ノートブックの新しいセルに、PEFTの環境とパラメータを設定する以下のコードを記述します:
from transformers import BitsAndBytesConfig
from peft import LoraConfig
# QLoRA設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,)
# LoRA設定
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)このコードは:
- 事前学習済み言語モデルを読み込む際の量子化方法を指定する
BitsAndBytesConfig()メソッドを用いた QLoRA 設定を定義します。量子化は計算コストとメモリコストを削減する技術です。 - LoraConfig()メソッドを用いて、パラメータ効率の良い微調整のためのモデル設定を行うLoRA構成を定義します。
素晴らしい!効率的な微調整のための環境が整いました。
ステップ #6: トレーニングプロセスの初期化
新しいセルで、以下のコードを記述してトレーニングプロセスを初期化します:
from peft import get_peft_model, prepare_model_for_kbit_training
from transformers import TrainingArguments
# kビットトレーニング用にモデルを準備
model = prepare_model_for_kbit_training(
model,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# PEFT (LoRA) 設定をモデルに適用
model = get_peft_model(model, lora_config)
# モデル設定でキャッシュを無効化
model.config.use_cache = False
# モデルの学習可能パラメータ数を表示
model.print_trainable_parameters()
# トレーニング引数を定義
training_args = TrainingArguments(
output_dir=output_model_dir,
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=25,
save_steps=50,
fp16=True,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none",
max_grad_norm=0.3,
save_total_limit=2,)
# SFTTrainerを初期化
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
peft_config=lora_config,
)このセルのコード:
prepare_model_for_kbit_training()メソッドは、量子化を用いたトレーニングのために事前読み込み済みモデルを準備します。get_peft_model()メソッドは、量子化済みかつ準備済みのベースモデルを受け取り、lora_configを適用します。TrainingArguments()クラスを呼び出してトレーニング引数を定義します。SFTTrainer()でトレーナーを初期化します。
以下が期待される結果です:

ステップ #7: モデルのトレーニング
train()メソッドを使用してLlama 4モデルのトレーニングを開始します:
# モデルのトレーニング
trainer.train()
# ファインチューニング済みモデルの保存
trainer.save_model(final_model_adapter_path) # LoRAアダプターを保存
tokenizer.save_pre-trained(final_model_adapter_path) # アダプター付きトークナイザーを保存結果は次の通りです:

AIの確率的性質により、異なる数値が得られる可能性がある点に注意してください。
ステップ #8: 推論用モデルの準備
推論用にモデルを準備するには、新しいセルに以下のコードを記述します:
# 推論用に量子化済みモデルを読み込み
base_model_for_inference = AutoModelForCausalLM.from_pre-trained(
base_model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# ファインチューニング済みLoRAアダプターを読み込み、モデルにアタッチ
fine_tuned_model_for_testing = PeftModel.from_pre-trained(
base_model_for_inference,
final_model_adapter_path
)
# LoRAアダプターをベースモデルにマージ
fine_tuned_model_for_testing = fine_tuned_model_for_testing.merge_and_unload()
# トークナイザーを読み込む
fine_tuned_tokenizer_for_testing = AutoTokenizer.from_pre-trained(
final_model_adapter_path,
trust_remote_code=True)
# 推論用にトークナイザーを設定
fine_tuned_tokenizer_for_testing.pad_token = fine_tuned_tokenizer_for_testing.eos_token
fine_tuned_tokenizer_for_testing.padding_side = "left"
# ファインチューニング済みモデルを評価モードに設定
fine_tuned_model_for_testing.eval()このセルのコード:
- 推論用に
from_pre-trained()メソッドでモデルを読み込みます。 - 推論用にベースモデルにLoRAアダプターを読み込み、適用し、マージします。
- 微調整済みトークナイザーを読み込み、推論用に設定します。
eval()メソッドでモデルを評価モードに設定します。これによりトレーニング固有の動作が無効化され、推論時の一貫性と決定論的な出力が保証されます。
さあ始めましょう!推論のための準備はすべて整いました。
ステップ #9: モデルの推論
この最終ステップでは推論を実行します。これまでAmazonからスクレイピングした商品データでLlama 4を訓練してきました。次に、オフィス用品のようなアイテムの名前と特徴を含むデータを与え、モデルがその説明文を生成できるか確認します。
以下のコードで推論プロセスを管理できます:
# ファインチューニング済みモデルのテスト用合成製品データリストを定義
synthetic_test_items = [
{
"title": "Executive Ergonomic Office Chair", "brand": "ComfortLuxe", "category": "Office Chairs", "name": "ErgoPro-EL100",
"features": ["ハイバックデザイン", "調節可能な腰部サポート", "通気性メッシュ生地", "連動式チルト機構", "パッド入りアームレスト", "頑丈なナイロンベース"]
},
{
"title": "調節可能スタンディングデスクコンバーター", "brand": "FlexiDesk", "category": "デスク&ワークステーション", "name": "HeightRise-FD20",
"features": ["広々とした2段式作業面", "滑らかなガススプリングリフト", "調節可能高さ範囲 6-17インチ", "最大35ポンドまで対応", "キーボードトレイ付属", "滑り止めゴム足"]
},
{
"title": "ワイヤレスキーボード&マウスコンボ", "brand": "TechGear", "category": "コンピューター周辺機器", "name": "SilentType-KM850",
"features": ["テンキー付きフルサイズキーボード", "静音キー", "DPI調整可能なエルゴノミックマウス", "2.4GHzワイヤレス接続", "長寿命バッテリー", "プラグアンドプレイUSBレシーバー"],
{
"title": "引き出し付きデスクトップオーガナイザー", "brand": "NeatOffice", "category": "デスクアクセサリー", "name": "SpaceSaver-DO3",
"features": ["多段収納設計", "引き出し2段", "耐久性のある木製構造", "コンパクト設計", "ペン・メモ・小物収納に最適"]
},
{
"title": "USB充電ポート付きLEDデスクランプ", "brand": "BrightSpark", "category": "オフィス照明", "name": "LumiCharge-LS50",
"features": ["明るさ調整レベル(5段階)", "色温度モード(3種類)", "フレキシブルグースネック設計", "内蔵USB充電ポート", "目に優しいフリッカーフリー光", "省エネLED"],
]
# 推論用システムメッセージとプロンプト構造
system_message_inference = "あなたは専門のコピーライターです。提供された詳細に基づき、簡潔で魅力的な製品説明を生成してください。"
print("n--- ファインチューニング済みモデルによる合成テストデータを用いた説明生成 ---")
# synthetic_test_itemsリストの各アイテムを反復処理
for item_data in synthetic_test_items:
# 合成アイテムの構造に基づきユーザープロンプト部分を構築
user_prompt_inference = (
f"以下のオフィス用品の説明文を生成してください:n"
f"タイトル: {item_data["title"]}n"
f"ブランド: {item_data["brand"]}n"
f"カテゴリー: {item_data["category"]}n"
f"名称: {item_data["name"]}n"
f"特徴: {", ".join(item_data["features"])}n"
f"説明:" # モデルはこの後にテキストを生成します。
)
full_prompt_for_inference = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message_inference}<|eot_id|>"
f"<|start_header_id|>system<|end_header_id|>nn{system_message_inference}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt_inference}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn"
)
print(f"nアイテム {item_data["name"]} のプロンプト")
# ファインチューニング済みトークナイザーでプロンプト文字列全体をトークン化
inputs = fine_tuned_tokenizer_for_testing(
full_prompt_for_inference,
return_tensors="pt",
padding=False,
truncation=True,
max_length=max_seq_length_for_tokenization - 150
).to(fine_tuned_model_for_testing.device)
# 推論を実行
with torch.no_grad():
outputs = fine_tuned_model_for_testing.generate(
**inputs,
max_new_tokens=150,
num_return_sequences=1,
do_sample=True,
temperature=0.6,
top_k=50,
top_p=0.9,
pad_token_id=fine_tuned_tokenizer_for_testing.eos_token_id,
eos_token_id=[
fine_tuned_tokenizer_for_testing.eos_token_id,
fine_tuned_tokenizer_for_testing.convert_tokens_to_ids("<|eot_id|>")
]
)
# 生成されたトークンIDを人間が読めるテキスト文字列にデコード
generated_text_full = fine_tuned_tokenizer_for_testing.decode(outputs[0], skip_special_tokens=False)
# Llamaチャット形式におけるアシスタント応答の開始を示すマーカーを定義
assistant_marker = "<|start_header_id|>assistant<|end_header_id|>nn"
# 生成テキスト内でアシスタントマーカーの最後の出現位置を検索
assistant_response_start_index = generated_text_full.rfind(assistant_marker)
# モデル出力全体から実際の生成説明文を抽出
if assistant_response_start_index != -1:
# アシスタントマーカーが見つかった場合、その直後のテキストを抽出
generated_description = generated_text_full[assistant_response_start_index + len(assistant_marker):]
# Llama用のターン終了トークンを定義
eot_token = "<|eot_id|>"
# 抽出された説明文がLlamaのターン終了トークンで終わっているか確認し、あれば削除
if generated_description.endswith(eot_token):
generated_description = generated_description[:-len(eot_token)]
# トークナイザの標準シーケンス終了トークンで終わっている場合もチェックし、削除する
if generated_description.endswith(fine_tuned_tokenizer_for_testing.eos_token):
generated_description = generated_description[:-len(fine_tuned_tokenizer_for_testing.eos_token)]
# クリーンアップ後の記述から先頭/末尾の空白を削除
generated_description = generated_description.strip()
else:
# フォールバック: アシスタントマーカーが見つからない場合、元の入力プロンプト以降の全てを生成部分と仮定して抽出を試みる。
input_prompt_decoded_len = len(fine_tuned_tokenizer_for_testing.decode(inputs["input_ids"][0], skip_special_tokens=False))
# 入力プロンプトトークンをデコードし、文字列としてその長さを取得する。
generated_description = generated_text_full[input_prompt_decoded_len:].strip()
# このフォールバック抽出から末尾のLlamaターン終了トークンを削除
if generated_description.endswith("<|eot_id|>"):
generated_description = generated_description[:-len("<|eot_id|>")]
generated_description = generated_description.strip()
# 抽出・クリーンアップ後の生成説明文を出力
print(f"GENERATED (Fine-tuned):n{generated_description}")
# 項目間の可読性向上のため区切り行を出力
print("-" * 50)この最後のJupyter Notebookセルは推論プロセスを管理します。このプロセスは、微調整プロセス中のトレーニングの質を確認するのに役立ちます。
具体的には、上記のコードでは:
- テストデータを
synthetic_test_itemsというリストとして定義します。このリストの各要素は製品を表す辞書であり、タイトル、ブランド、カテゴリ、名前、特徴のリストなどの詳細を含みます。このデータはモデルの入力として機能し、その構造はファインチューニングデータセットのものと一致する必要があります。 system_message_inferenceを使用して推論プロンプト構造を設定します。これはトレーニングプロセスで使用されたプロンプトと一致する必要があります。for item_data in synthetic_test_itemsループでは、各item_dataに対してユーザープロンプトを生成します。各item_dataの構造は、トレーニングプロセスで使用されたものと一致している必要があります。- トークン化を行い、モデルが出力テキストを生成する方法を制御します。実際の推論は
with文の下で実行されます。特に、コアとなる推論ステップであるgenerate()メソッドによって処理されます。 - トークナイザーを使用して、モデルからの生の出力(トークンIDのシーケンス)を人間が読める文字列(
generated_text_full)にデコードします。 if-elseブロックを用いて言語モデルの生の出力をクリーンアップし、アシスタントが生成した製品説明のみを抽出します。生の出力(generated_text_full)には通常、入力プロンプト全体とそれに続くモデルの応答が含まれ、すべてLlamaの特殊なチャットトークンでフォーマットされています。- 結果を出力します。
結果は以下のように期待できます:
--- ファインチューニング済みモデルによる合成テストデータを用いた説明文生成 ---
アイテム用プロンプト: ErgoPro-EL100
生成結果 (ファインチューニング済み):
**ErgoPro-EL100のご紹介:究極のエグゼクティブ向けエルゴノミックオフィスチェア**
ComfortLuxe ErgoPro-EL100で快適さとサポートの頂点を体感してください。ワークエクスペリエンスを高めるために設計されたこのプレミアムオフィスチェアは、上半身を包み込むハイバックデザインを採用。比類なき腰部サポートと健康的な姿勢を促進します。
通気性メッシュ生地が涼しく快適な座り心地を保証し、シンクロナイズドチルト機構が好みの作業姿勢へシームレスな調整を可能にします。 パッド入りアームレストが肩や手首への負担を軽減し、さらなるサポートと快適性を提供します。
耐久性に優れたErgoPro-EL100は、頑丈なナイロン製ベースを採用し、安定性と長寿命を実現。長時間作業でも、あるいは単に
--------------------------------------------------
アイテム用プロンプト: HeightRise-FD20
生成文 (微調整済み):
**フレキシデスクのHeightRise-FD20調節式スタンディングデスクコンバーターで生産性を高めよう**
究極の調節式スタンディングデスクコンバーター、フレキシデスクのHeightRise-FD20で作業環境を新たな高みへ。 ワークスペースに革命をもたらすこの革新的なコンバーターは、あらゆるデスクを快適で人間工学に基づいたスタンディングステーションに変えます。
**スタンディングのメリットを体験**
HeightRise-FD20は広々とした2段式作業面を備え、ノートパソコン、モニター、その他の必須作業ツールを置くのに最適です。滑らかなガススプリングリフトにより、6インチから17インチまでの高さ調整が簡単にでき、ニーズに合った快適な立ち姿勢を確保します。
**耐久性と信頼性**
頑丈な構造と滑り止めゴム足を採用
--------------------------------------------------さあ、完成です!Bright DataスクレイパーAPIで取得した新しいデータセットを用いて、Llama 4を微調整しました。
まとめ
本記事では、Bright Data Scraper APIを用いてAmazonからスクレイピングしたデータセットでLlama 4をファインチューニングする方法を解説しました。以下の全プロセスを実践しました:
- ウェブからのデータ取得
- トークン付きHugging Faceアカウントの設定
- 必要なクラウドインフラの構築
- Llama 4のトレーニングとテスト(推論)
微調整プロセスの核心は、高品質なデータセットの確保にあります。幸い、Bright Dataはデータ取得や作成のための数多くのAI対応サービスを提供しています:
- スクレイピングブラウザ: 組み込みのアンロック機能を備えた、Playwright、Selenium、Puppeteer互換のブラウザ。
- WebスクレイパーAPI:100以上の主要ドメインから構造化データを抽出するための事前設定済みAPI。
- Web Unlocker:アンチボット対策サイトでのロック解除を処理するオールインワンAPI。
- SERP API:検索エンジンの結果をアンロックし、完全なSERPデータを抽出する専用API。
- 基盤モデル:事前学習、評価、微調整を可能にするコンプライアンス対応のウェブ規模データセットへのアクセス。
- データプロバイダー:信頼できるプロバイダーと連携し、高品質でAI対応のデータセットを大規模に調達。
- データパッケージ:構造化・強化・注釈付きで、すぐに使える厳選済みデータセットを入手。
Bright Dataアカウントを無料で作成し、AIのためのデータインフラをテストしましょう!





