

このチュートリアルでは、以下の内容を学びます:
- AWS Glue の概要と提供機能
- Bright Dataがウェブデータ取得サービスを通じてETLパイプラインをサポートする理由
- AWS GlueのETLジョブにBright Dataを統合する方法
さあ、始めましょう!
AWS Glueとは?
AWS Glueは、あらゆる規模の複数のソースからのデータの発見、準備、結合のプロセスを簡素化するために構築されたサーバーレスのデータ統合サービスです。
インフラ管理なしで、分析、機械学習、アプリケーション開発向けのETL(抽出、変換、ロード)ワークフローを構築できます。AWS Glueはデータパイプラインの開発を加速し、分析用にデータを容易にアクセス可能にします。これはデータカタログを一元化し、視覚的およびコードベースのジョブ作成ツールを提供することで実現されます。
AWS Glueが提供する主な機能は以下の3つです:
- データの発見と整理:スキーマの自動推測、メタデータのカタログ化、AWS、オンプレミス、他クラウドにまたがるデータソースへの接続を実現。
- データの変換とクレンジング:ビジュアルジョブエディター、インタラクティブノートブック、ストリーミングETLサポート、組み込みの機械学習ベース重複排除機能を提供。
- パイプラインの構築と監視:ジョブのスケジュール設定、自動化、スケーリングを実現し、詳細なインサイトとトリガーによるパイプライン監視機能を提供。
AWS Glue ETLワークフローにBright Dataを統合する理由
Bright Data をAWS ETL ワークフローに統合することで、データパイプラインの範囲と品質を劇的に拡大できます。
従来のETLは既知のソースからの構造化データ抽出に重点を置いていましたが、Bright Dataはリアルタイムの構造化ウェブデータへのアクセスを可能にします。これにより、手動収集や複雑なスクレイピングインフラが必要なインサイトが解放されます。
豊富なウェブデータ抽出(E)に加え、Bright Dataは変換(T)フェーズも強化します。変換時に、ライブの市場情報、製品情報、ソーシャル情報をレコードに追加することでデータセットを充実させられます。例えば、社内データセットに株価パフォーマンス指標、競合他社の価格、企業メタデータを付加することが可能です。
こうした知見はチームの意思決定を高度化します。スクレイピングデータの権威ある情報源との照合によるデータ検証も重要な利点です。これにより、ターゲットデータストアへのロード前に正確性を確保できます。
Bright Dataを使用したAWS Glue ETLジョブ向けWebデータ取得方法
このガイドセクションでは、AWS Glue ETLジョブにおけるBright Dataの統合例を紹介します。具体的には、以下のサンプルETLパイプラインの構築方法をご覧いただけます:
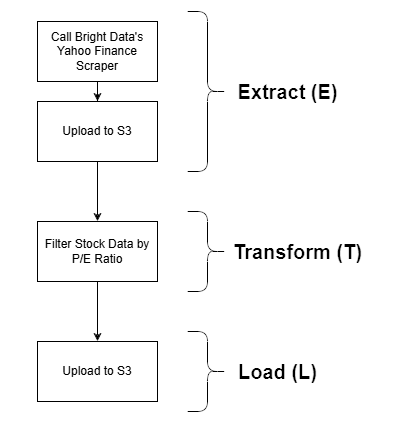
Bright Dataは、その強力なウェブデータ取得オプションにより、抽出(E)フェーズで活用されます。Yahoo Financeスクレイパーを使用して株価データを取得し、P/E比率でフィルタリングした後、最終的にS3バケットに保存します。これはシンプルな例ですが、完全なETLワークフローを現実的に示すものです。
注:本チュートリアル終了後、AWS Glueにおけるその他のBright Data統合手法の検討が可能です。
以下の手順に従って始めましょう!
前提条件
このチュートリアルを実行する前に、以下の環境が整っていることを確認してください:
- AWSアカウント(無料トライアルアカウントでも可)
- APIキーが設定済みのBright Dataアカウント。公式手順に従ってAPIキーを生成してください。
- AWSアカウント内に定義済みのS3バケット。
- Bright DataのスクレイピングAPIと連携し、取得したデータをS3バケットにアップロードするスクリプトを作成できる基本的なPython知識。
- ETLパイプラインの変換(T)フェーズで簡易クエリを記述できる基本的なSQLスキル。
このチュートリアルでは、S3バケット名がbright-data-etl-bucketであると仮定します:
Bright DataウェブスクレイピングAPIの動作についてある程度理解していることも役立ちます。
ステップ #1: Bright Data スクラッピング API の開始
ETLパイプラインの開発では、当然ながらExtract(E)フェーズから開始します。最初のステップはBright Data Yahoo Financeスクレイパーを使用してデータを取得することなので、その操作に慣れることが重要です。
まず、Bright Dataアカウントをお持ちでない場合は作成してください。既存アカウントをお持ちの場合はログインします。コントロールパネルで「Webスクレイパー」セクションに移動します:
次に「Web Scrapers Library」タブに移動します。「finance」を検索し、「Yahoo Finance スクレイパー」オプションを選択します。利用可能なスクレイパーにアクセスします:
Yahoo Finance スクレイパーページでは、このスクレイパーの入力要件と出力スキーマを確認できます: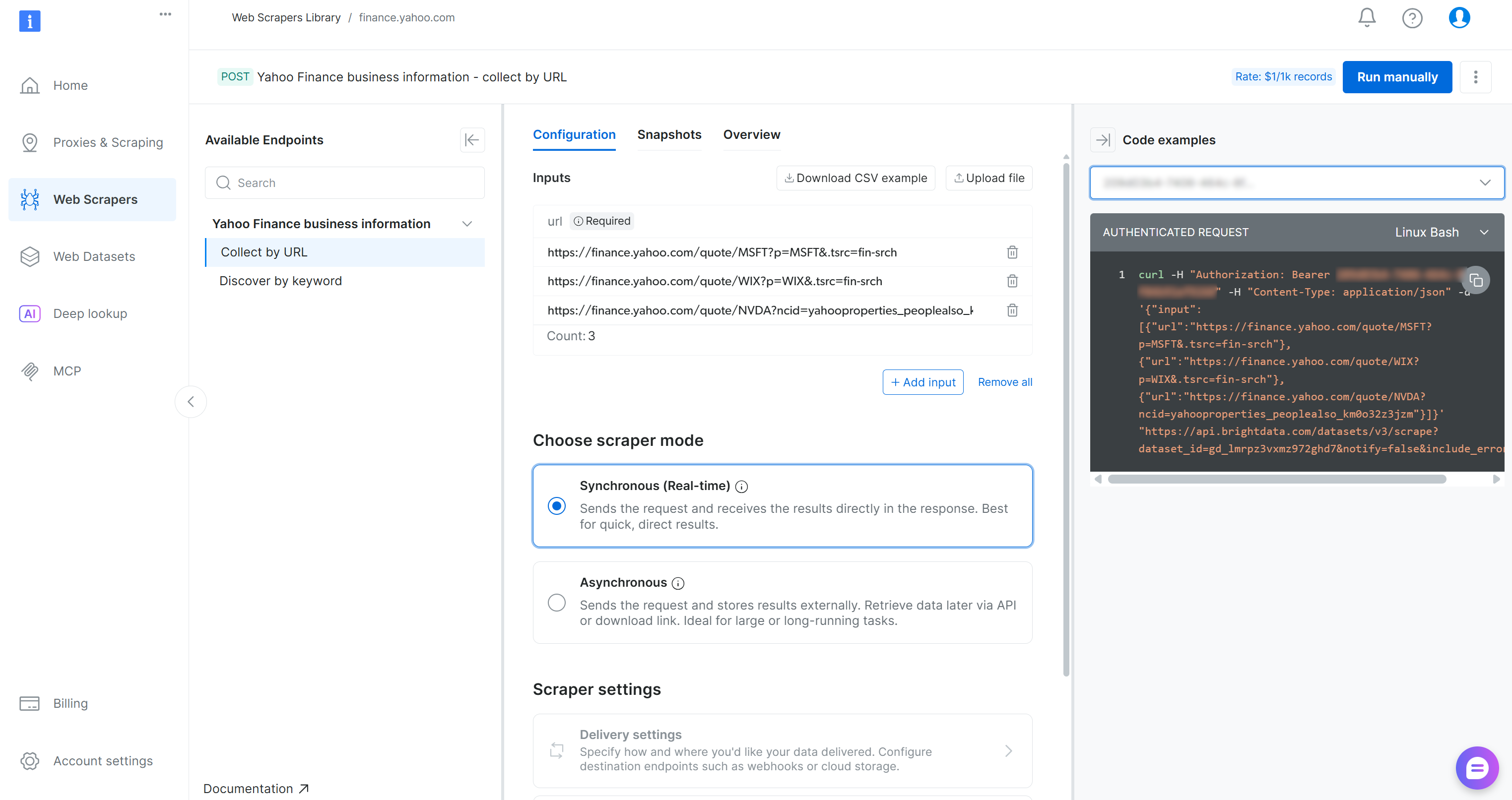
コントロールパネルでは、複数のプログラミング言語でコードスニペットを提供しており、迅速なセットアップが可能です。重要な点は、このスクレイパーが1つ以上のYahoo Finance株価ページを入力として受け取り、構造化されたリアルタイム株価データを返すことです。完璧です!
ステップ #2: S3配信の設定
Bright DataウェブスクレイピングAPIは、ウェブスクレイピングしたデータのAmazon S3への自動配信をサポートしています。この便利な機能を活用してデータ収集ステップを高速化するのが理にかなっています。Amazon S3配信を設定するには、まず非同期モードを有効にする必要があります。
「設定」タブで「非同期」オプションを選択します。次に「配信設定」ボタンをクリックします:
以下のフォームに入力して、Amazon S3バケットへのデータ配信を設定します:
- 「配信を有効にする」トグルをオンにします。
- フォーマットを
JSONに設定します。 - ストレージ先として「Amazon S3」を選択します。
- S3バケット名を入力します(この例
ではbright-data-etl-bucket)。(エンドポイントURLフィールドは空欄のままにできます。) - 「ターゲットパス」は空欄のままにすると、ファイルがバケットのルートフォルダにアップロードされます。
- 「認証タイプ」オプションを「アクセスキー」に設定します。
- AWS アクセスキー ID と AWS シークレットアクセスキーを貼り付けます。
- ファイル名を
stocksに設定します。
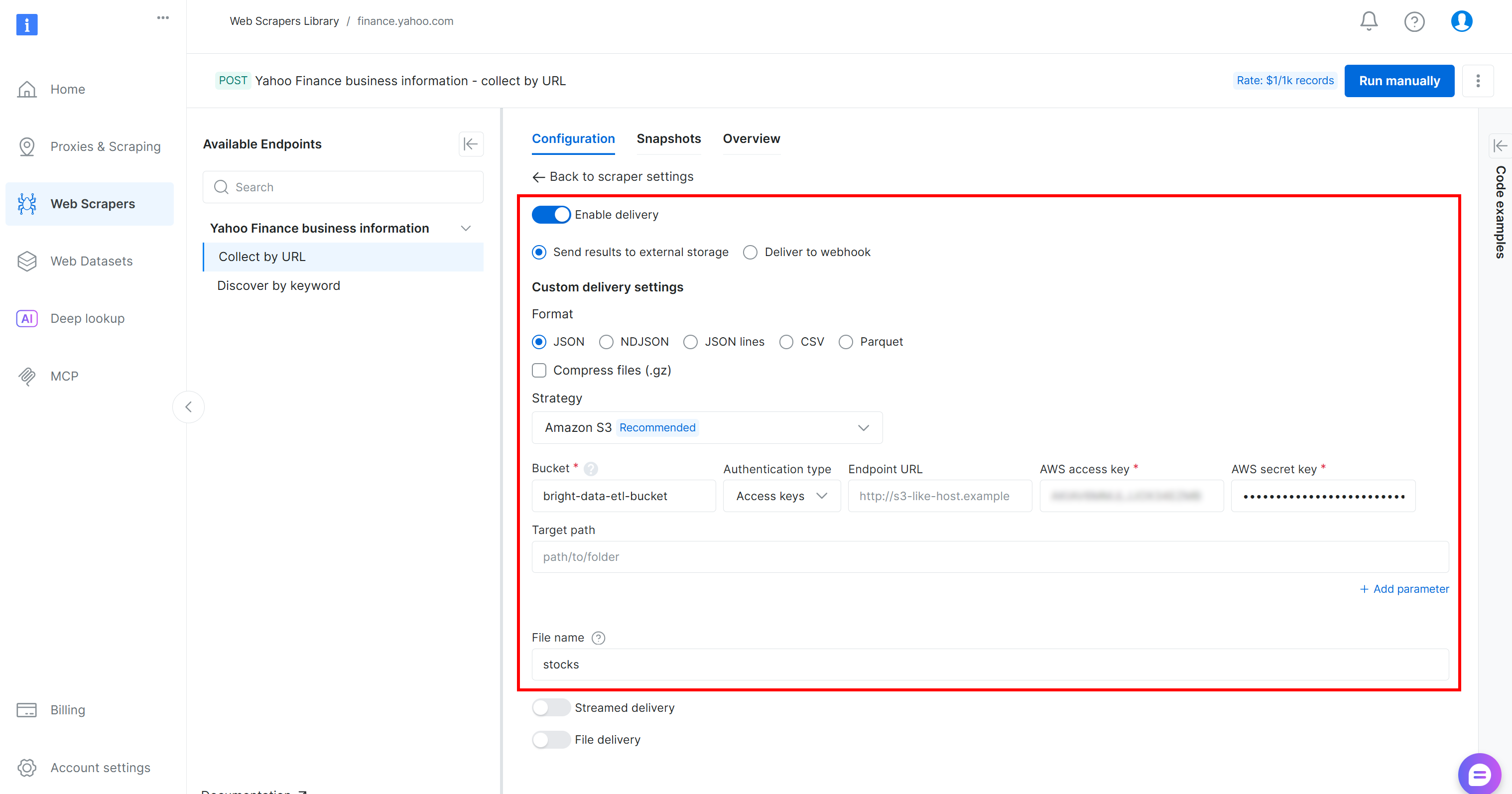
この設定により、ウェブスクレイピングAPIは非同期モードで実行されます。つまり、Bright Dataが自社インフラ上で実行するウェブスクレイピングタスクを作成します。タスク完了後、ウェブスクレイピングされたデータは自動的にAmazon S3バケットにアップロードされ、AWS Glue ETLジョブからアクセス可能になります。素晴らしい!
ステップ #3: Webデータ抽出ロジックの実行
Webデータ抽出ロジックが正常に動作することを確認するため、Yahoo Financeの株価URL(例:NVDA、AAPL、GOOGL、MSFT、AMZN、TSLA、META、AVGO、BRK.B、LLY)をいくつか追加し、「手動で実行」ボタンを押します: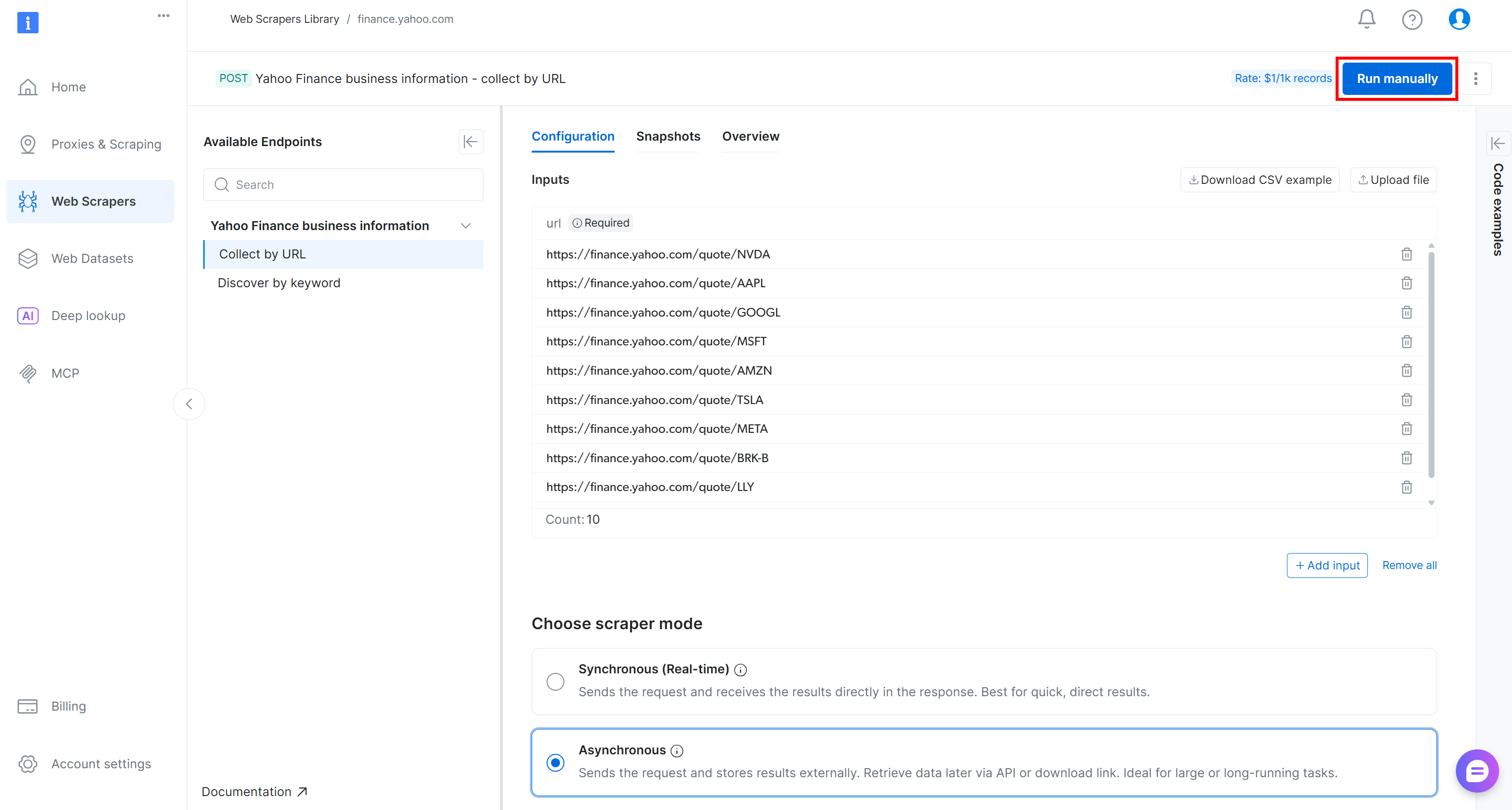
スクレイピングAPIリクエストが送信され、クラウド上でスクレイピングタスクが開始されます。Bright Dataコントロールパネルからタスクのステータスをリアルタイムで監視できます: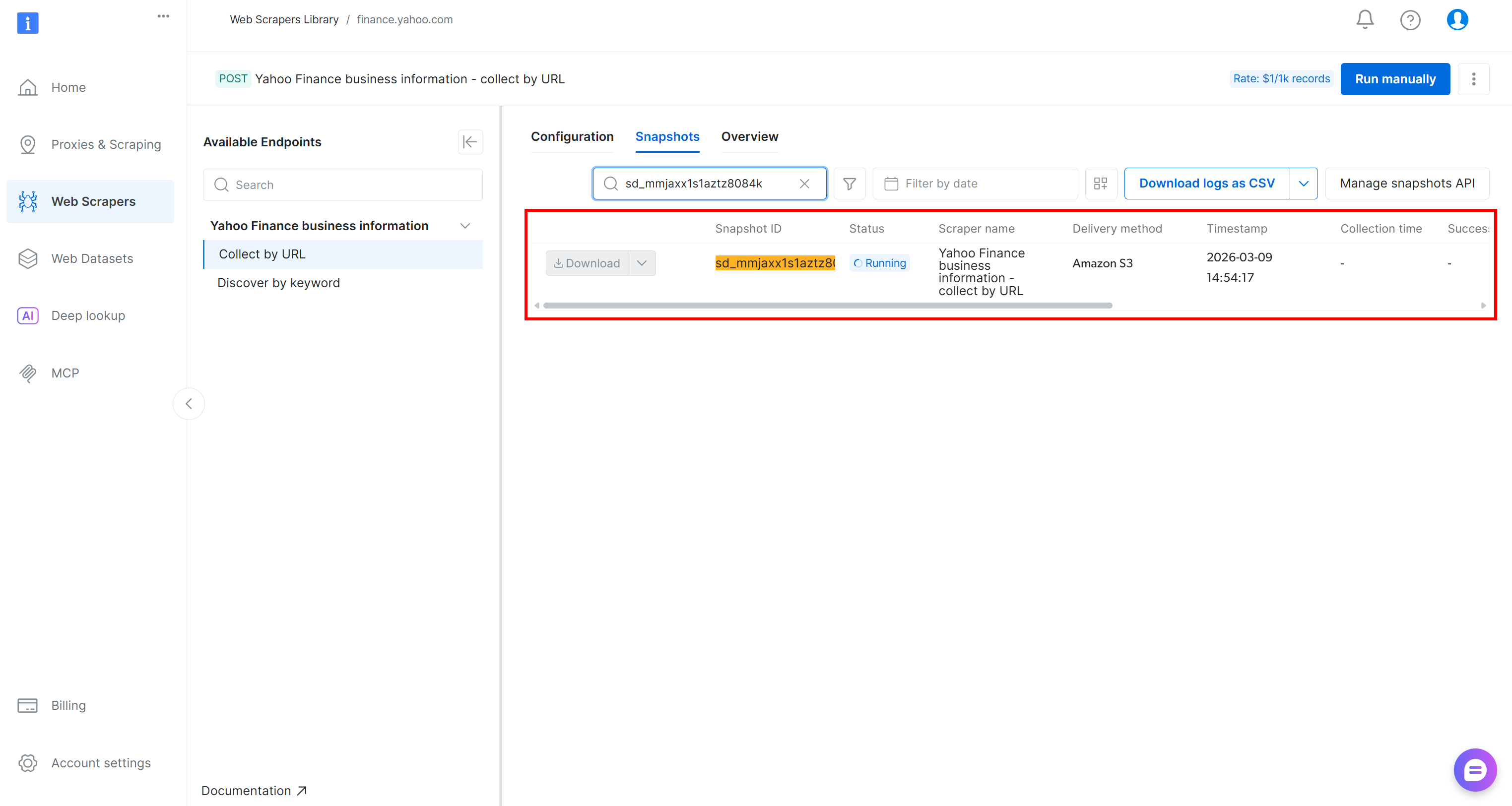
あるいは、Bright Dataコンソール(右カラムに表示)で提供されているコードスニペットのいずれかをお好みのプログラミング言語で実行することで、同様の結果をプログラム的に達成できます: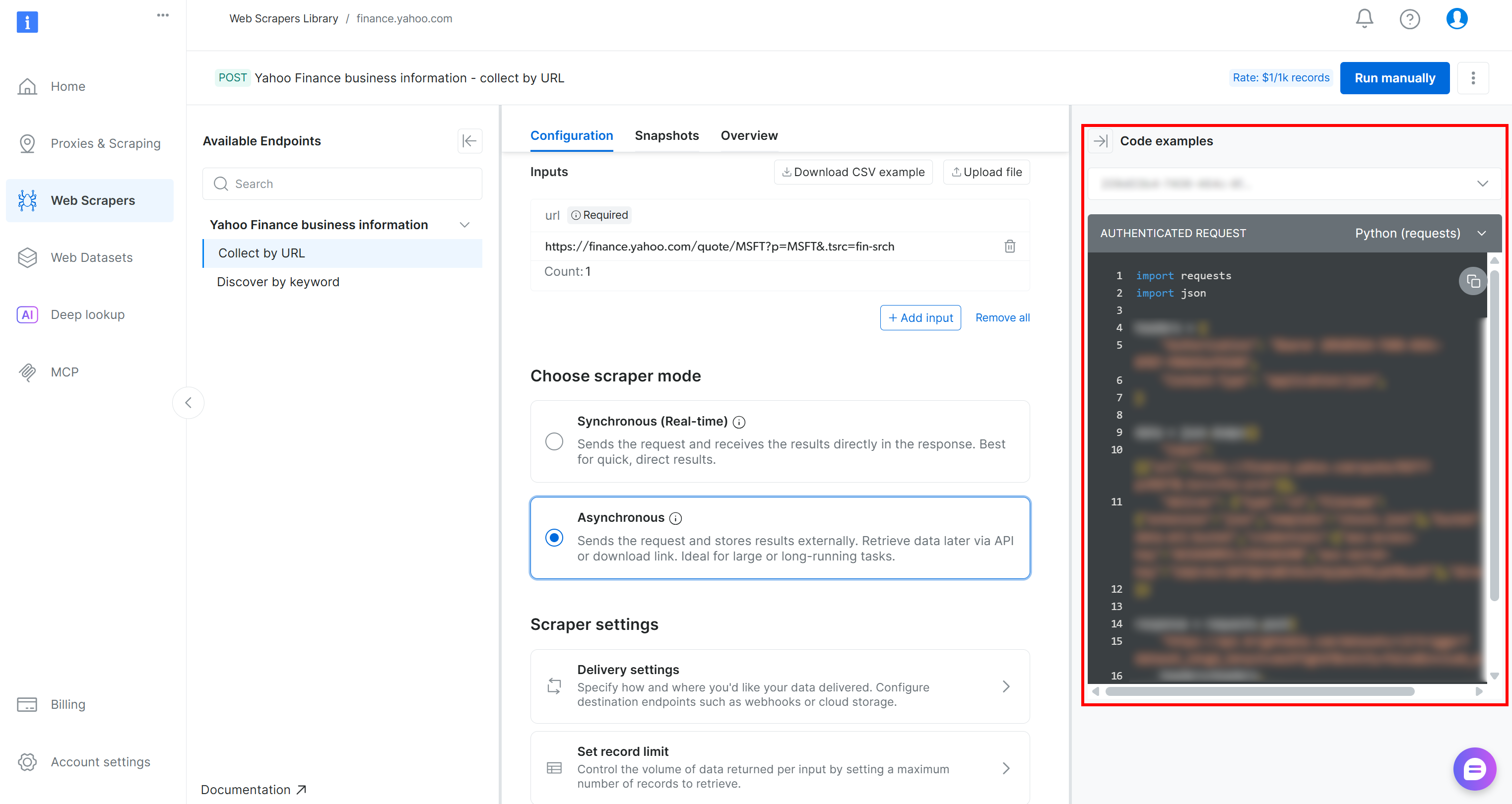
タスクステータスが「準備完了」に変わったら、AWS S3バケットを確認してください。stocks.jsonという名前の新しいファイルが作成されているはずです:
ブラウザでstocks.jsonファイルを開くと、以下のような内容が表示されます: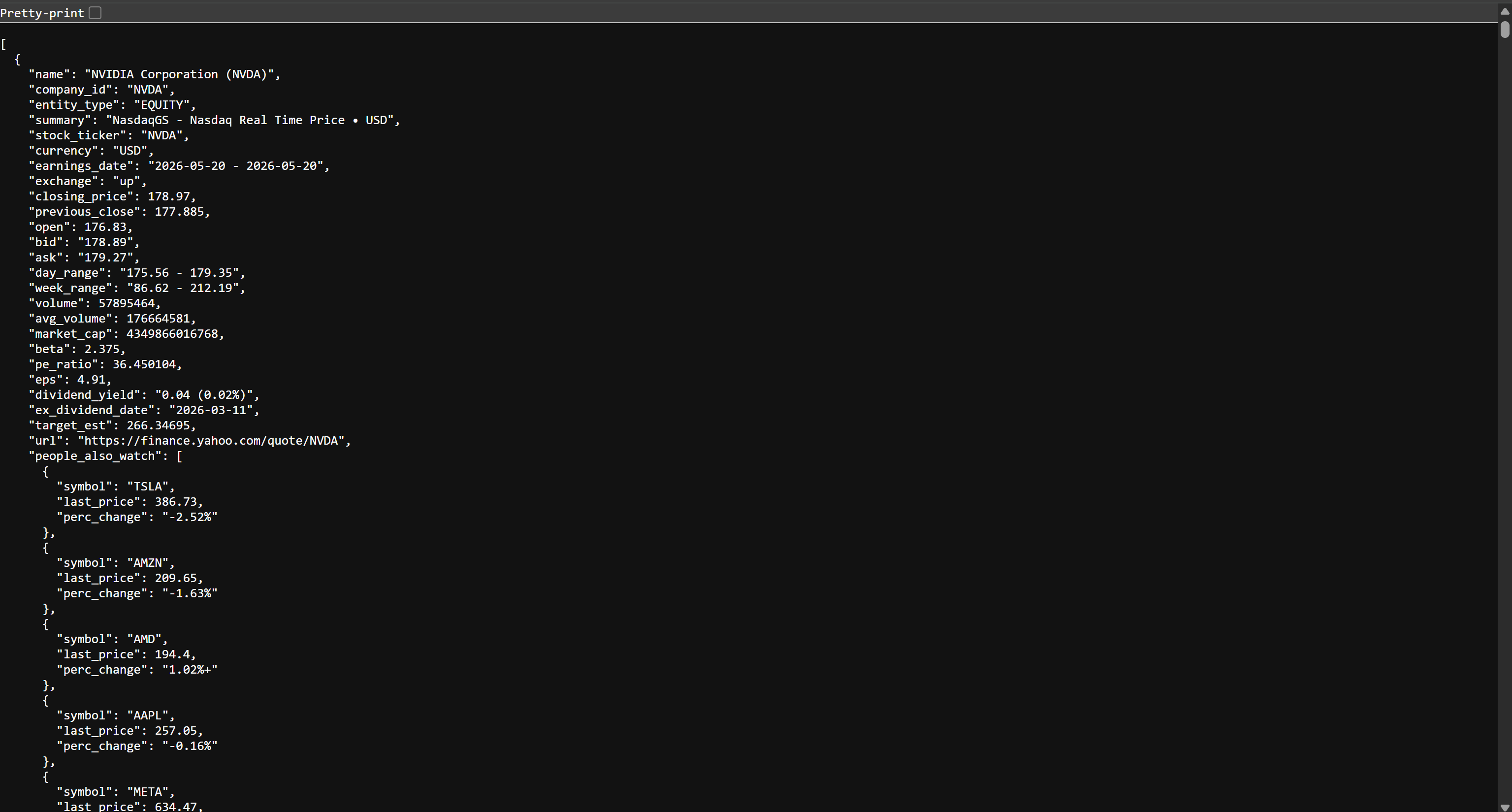
これはYahoo Financeで提供されている株価データと同じ内容ですが、JSON形式で構造化されています。このデータはBright DataウェブスクレイピングAPIによってスクレイピングされました。これで完了です!AWS Glue ETLパイプライン構築に必要なデータを取得できました。
ステップ #4: AWS Glueジョブの初期化
AWSコンソールにログインし、「AWS Glue」を検索します。サービスを選択してメインページを開きます。
そこから「ETLジョブに移動」ボタンをクリックし、ETLワークフロー作成の公式インターフェースであるAWS Glue Studioを開きます:
ここで新しいAWS Glueジョブを初期化できます。このチュートリアルでは「ビジュアルETL」オプションを選択してください。簡素化されたドラッグ&ドロップインターフェースでパイプラインを構築するのに適しています。
すると空白のキャンバスが表示され、異なるノードを接続することで AWS Glue ETL ワークフローを視覚的に定義できます:
ETLジョブに「Bright Data Glue ETLジョブ」などの説明的な名前を付けます。これでETLパイプラインの構築を開始する準備が整いました。
ステップ #5: IAMロールの作成
AWS Glueジョブを実行するには、Amazon S3などのリソースへのアクセスやAWS Glueの管理を行うためのIAMロールを提供する必要があります。これらの権限は、ジョブ、クローラー、開発エンドポイントなどのGlueコンポーネントに必須です。
Glue Studioから直接ロールを作成するには、「ジョブの詳細」パネルに移動し、「新しいロールを作成」ボタンをクリックします: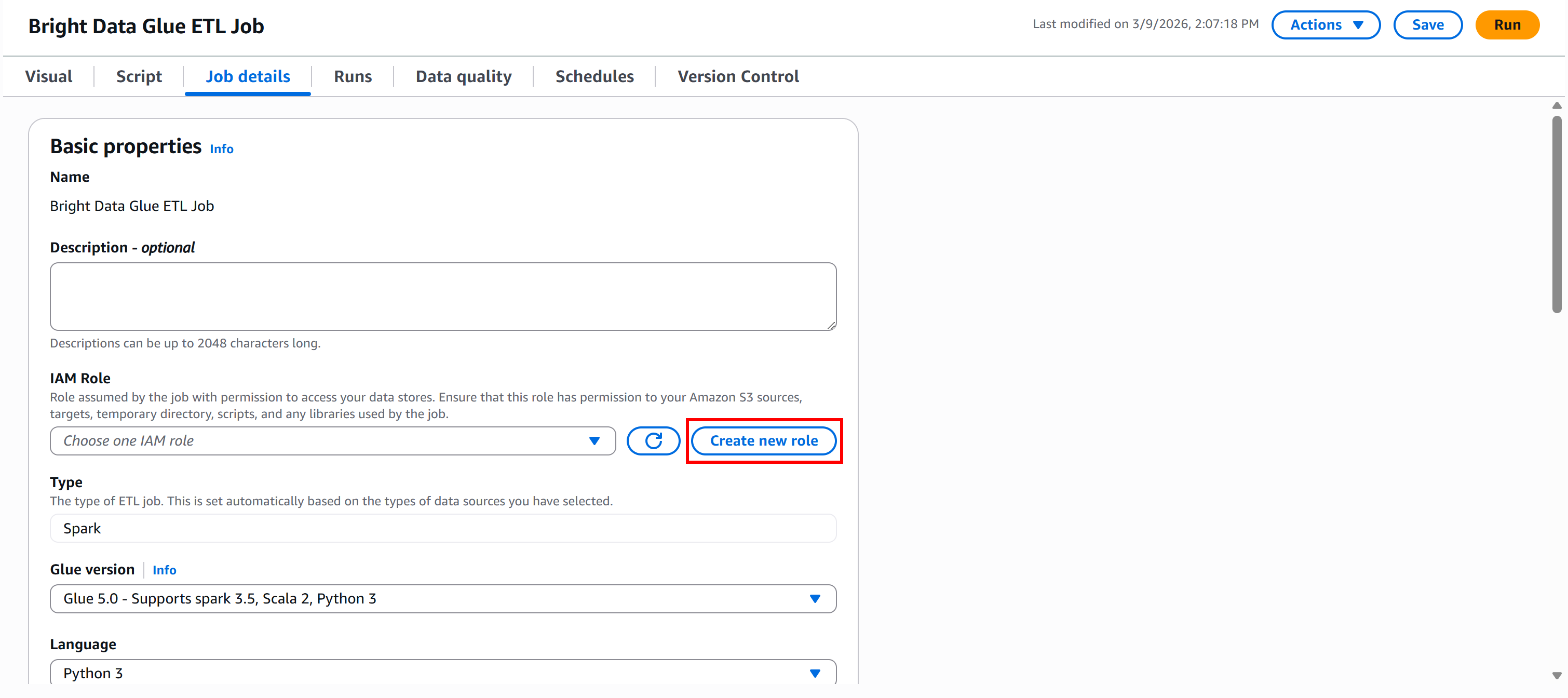
「ロールの作成」セクションで、IAMロールに「bd-glue-role」などの説明的な名前を付けます:
デフォルトでは、AWS が必要な 2 つのポリシーをアタッチします:
AWSGlueConsoleFullAccess: AWS Management Console 経由で AWS Glue への完全なアクセス権を提供します。AWSGlueServiceRole: AWS Glueサービスロール用のポリシー。EC2、S3、CloudWatch Logsなど関連サービスへのアクセスを許可します。

次に、S3バケットのARNを取得します。S3コンソールのバケット「プロパティ」ページで確認できます: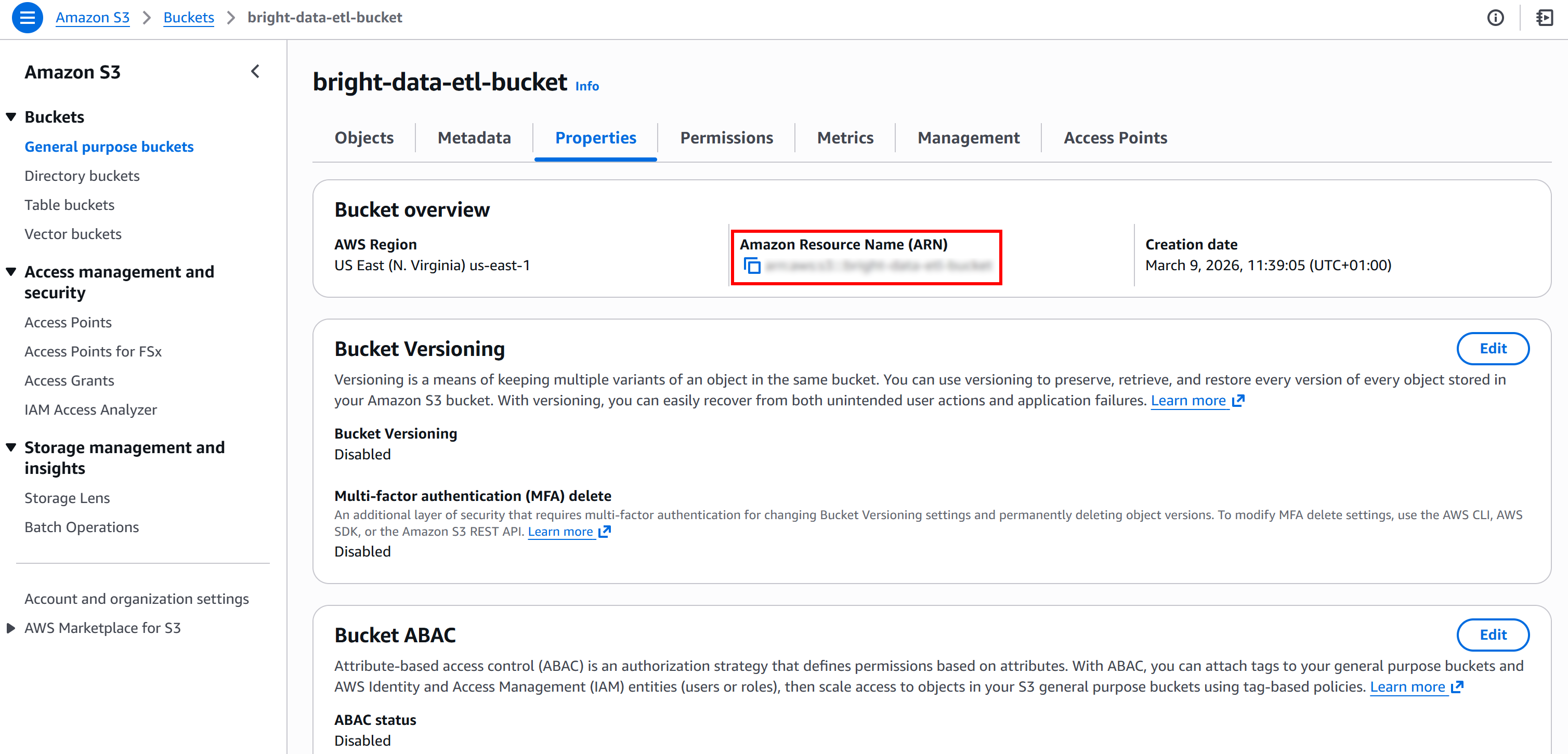
この情報が、AWS Glueが提供するデフォルトポリシーを上書きするために必要です。具体的には、「ロールの作成」ページの「追加ポリシー」テキストエディタの「リソース」フィールドにS3バケットARNを貼り付けます:
"Resource": {
"<YOUR_S3_BUCKET_ARN>/*"
} 
最後に「ロールの作成」ボタンをクリックします。ロールが作成されると、自動的にAWS Glueジョブ設定に表示されます: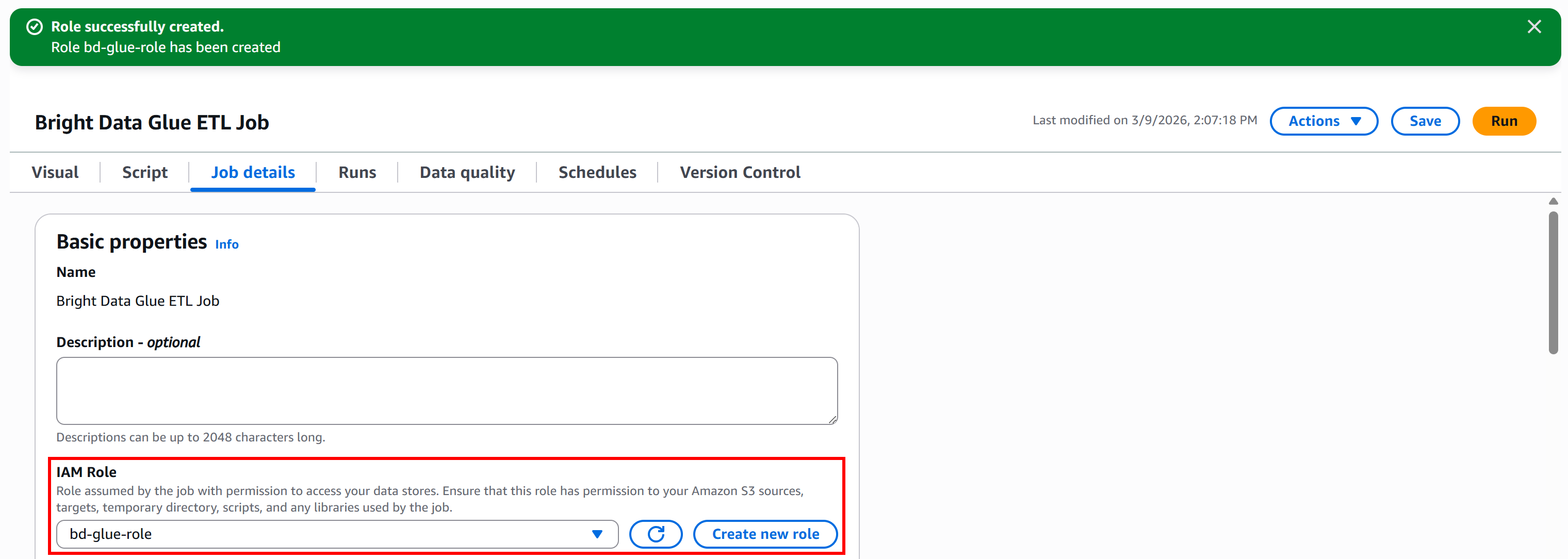
これで完了です!AWS Glueジョブに、S3へのアクセスとETLパイプラインの実行に必要な権限を持つIAMロールが設定されました。
ステップ #6: パイプラインに抽出 (E) ノードを追加する
パイプラインの抽出(E)フェーズは、Bright Dataスクレイパーを実行して株価データを収集し、Amazon S3にアップロードした時点で開始されました。
次に、AWS Glue ETLパイプラインをそのデータに接続し、処理できるようにします。そのためには、「ノードの追加」パネルの「ソース」タブに移動し、「Amazon S3」ノードを選択します。
キャンバス上に「データソース – S3バケット – Amazon S3」ノードが表示されます。これをクリックし、S3ソースを設定します: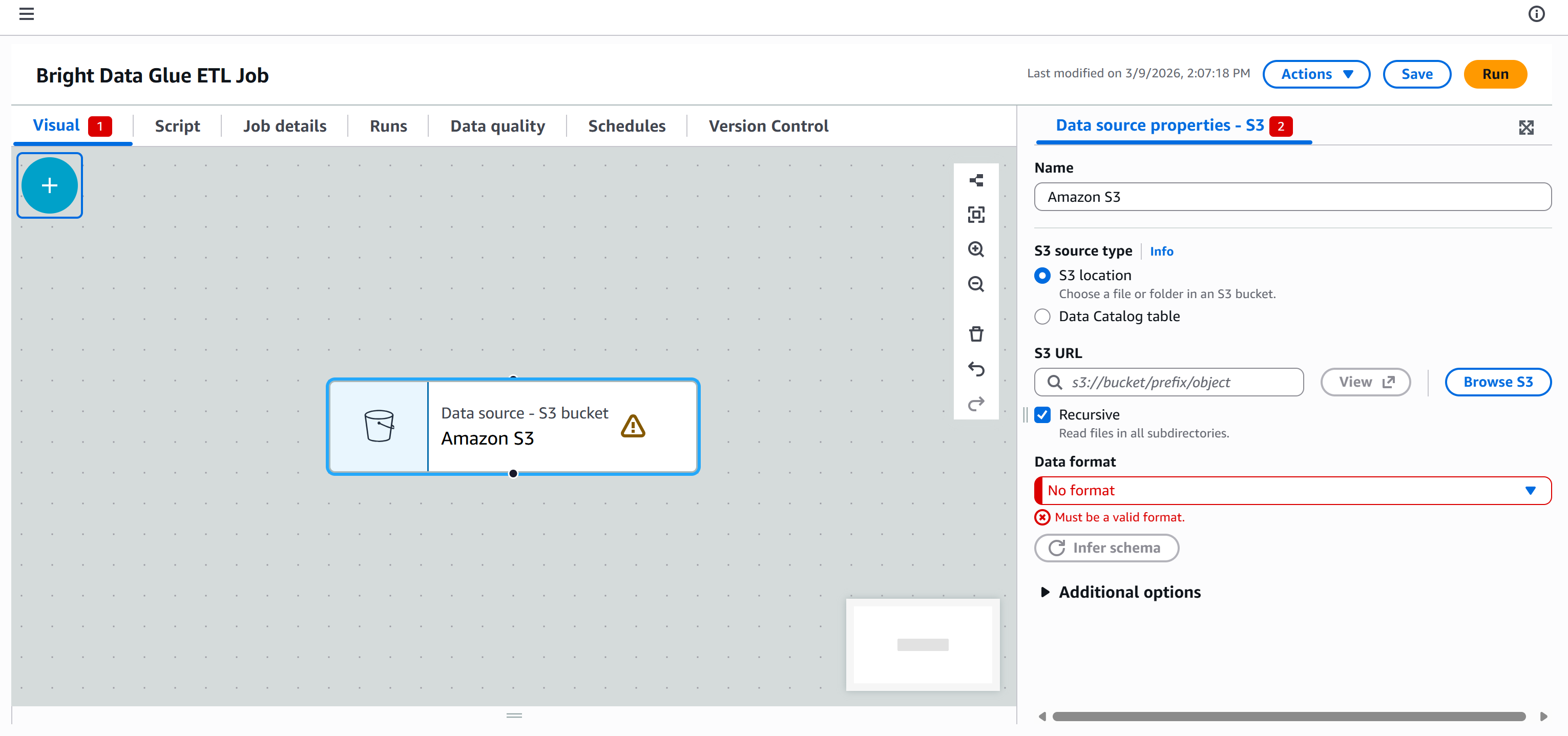
「S3を閲覧」ボタンを押して、S3バケット(例:bright-data-etl-bucket)を選択します。
バケット選択後、AWS Glueが「S3 URL」フィールドに以下のような値を自動入力します:
s3://bright-data-etl-bucketデフォルトでは、AWS Glueは指定されたS3パス内の全ファイルを読み込もうとします。入力ファイルの正確な名前がわかっているため、「S3 URL」フィールドを直接そのファイルを指すように更新します:
s3://bright-data-etl-bucket/stocks.jsonこれにより、Yahoo Financeスクレイパーでスクレイピングしたデータを含む、先にアップロードしたstocks.jsonファイルが使用されます。
次に、データ形式を設定します。入力データセットがJSONファイルであるため、入力形式として「JSON」を選択します。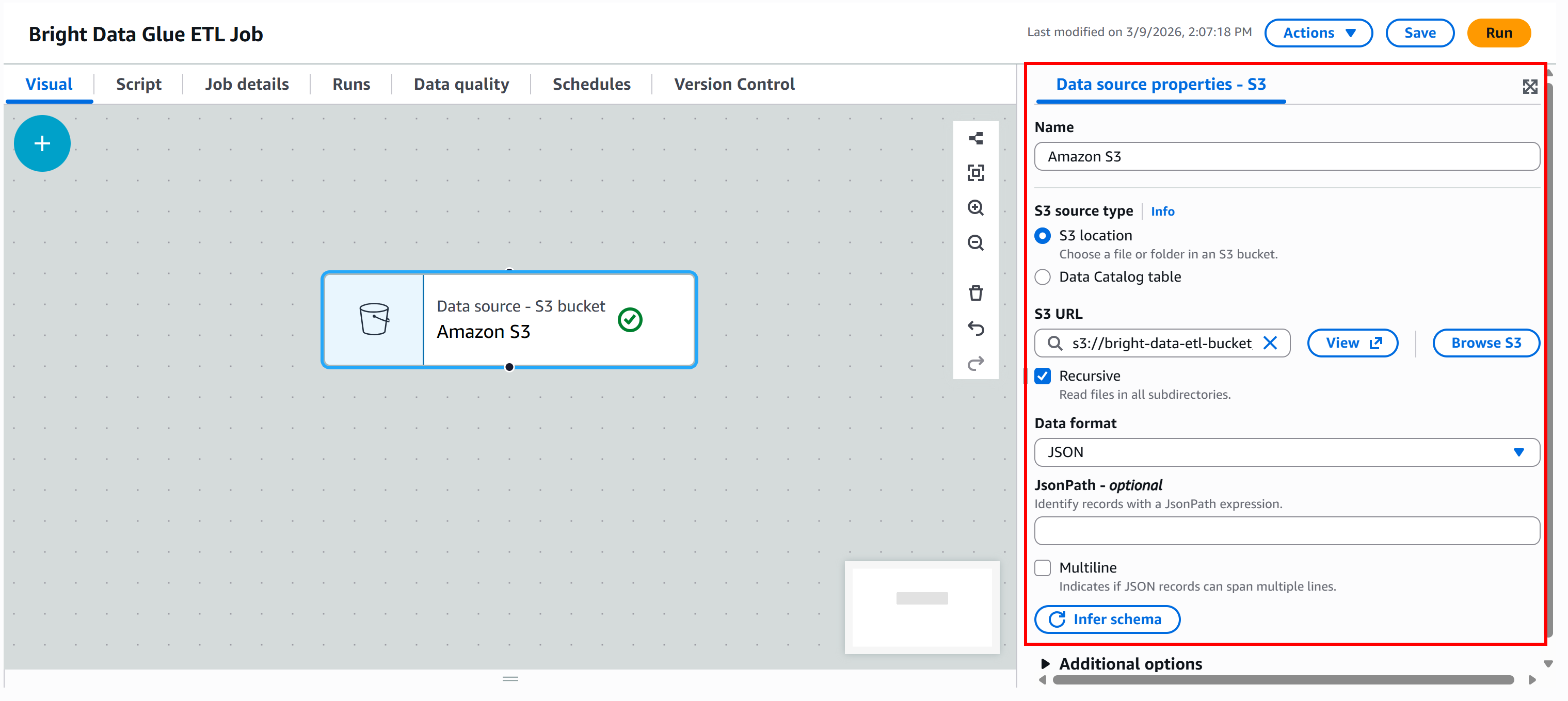
その後、「スキーマを推測」ボタンをクリックします。AWS Glueが入力JSONファイルを自動的に解析し、対応するスキーマを生成します。
ノードの「出力スキーマ」セクションには、JSONデータから推測された構造が表示されます:
推論されたスキーマは、Bright Data Yahoo Financeスクレイパーが返す出力データスキーマと一致しています。素晴らしい!
ステップ #7: 変換 (T) ロジックの定義
前述の通り、これは単純な例ですので、変換(T)ステップは最小限に抑えます。目的はSQLクエリを使用してソースデータをフィルタリングし、P/E比率が30未満の企業のみを保持することです。
これを実現するには、「変換」タブに移動し、「SQLクエリ」ノードを選択します:
ノードがキャンバスに追加されます。クリックして設定し、親ノードを「Amazon S3」にします。これはAmazon S3ノードの出力が「SQLクエリ」ノードの入力となることを意味します。つまり、スクレイピングされたJSONデータに対してSQLクエリを実行します。
次に、入力データセットのエイリアス名をstocksと定義し、以下のSQLクエリを追加します:
select stock_ticker, pe_ratio from stocks
WHERE pe_ratio < 30;このクエリは、スクレイピングされた各銘柄からstock_tickerと pe_ratioフィールドを選択し、株価収益率(P/E比率)が30未満のもののみを保持します。
これらのフィールドの由来が気になる場合、stock_tickerと pe_ratioは BrightData Yahoo Financeスクレイパーが返す属性のうちの2つです(AWS Glueが前のステップで自動的に推測しました)。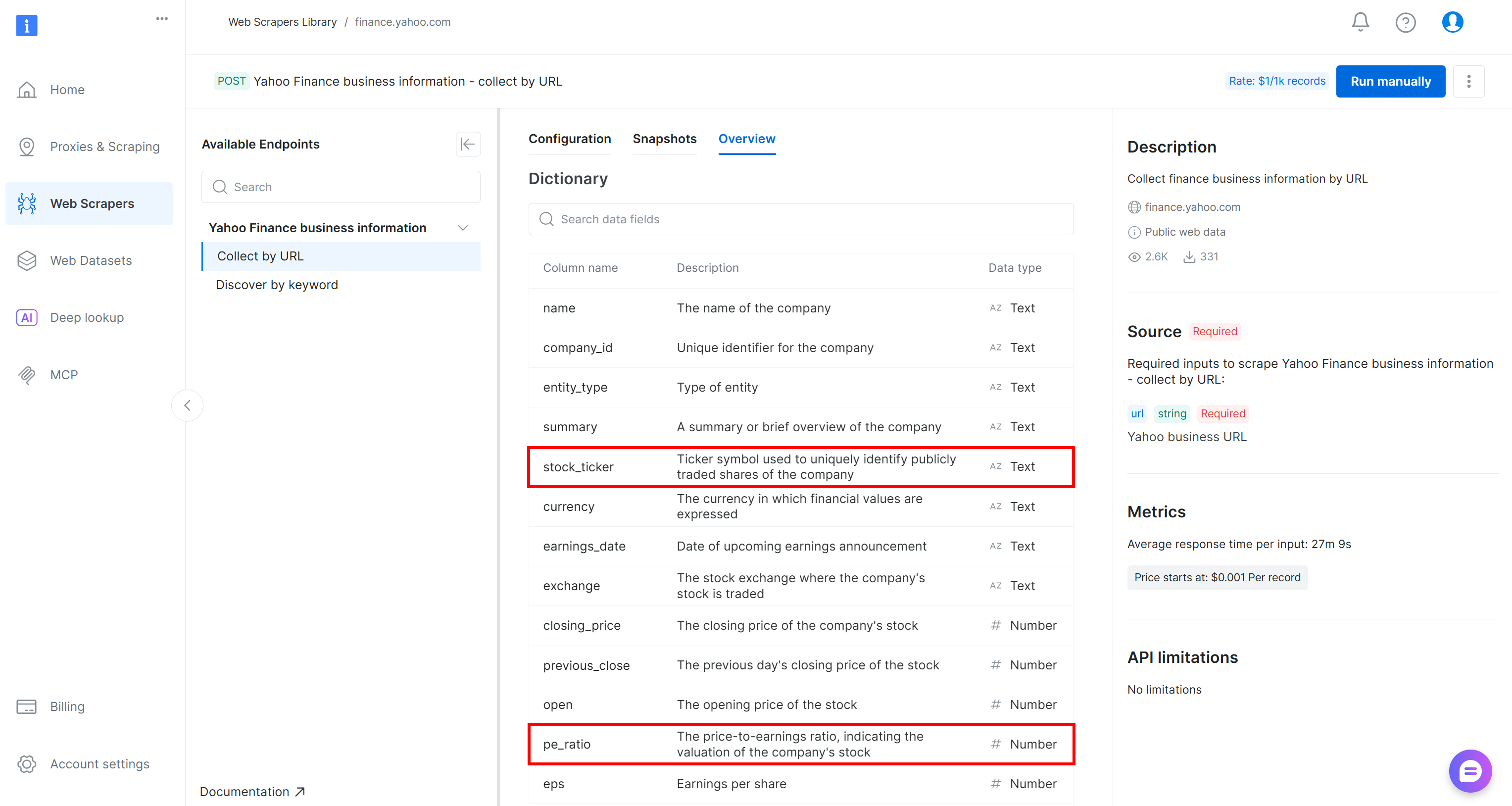
現時点でのETLパイプラインは次のようになります: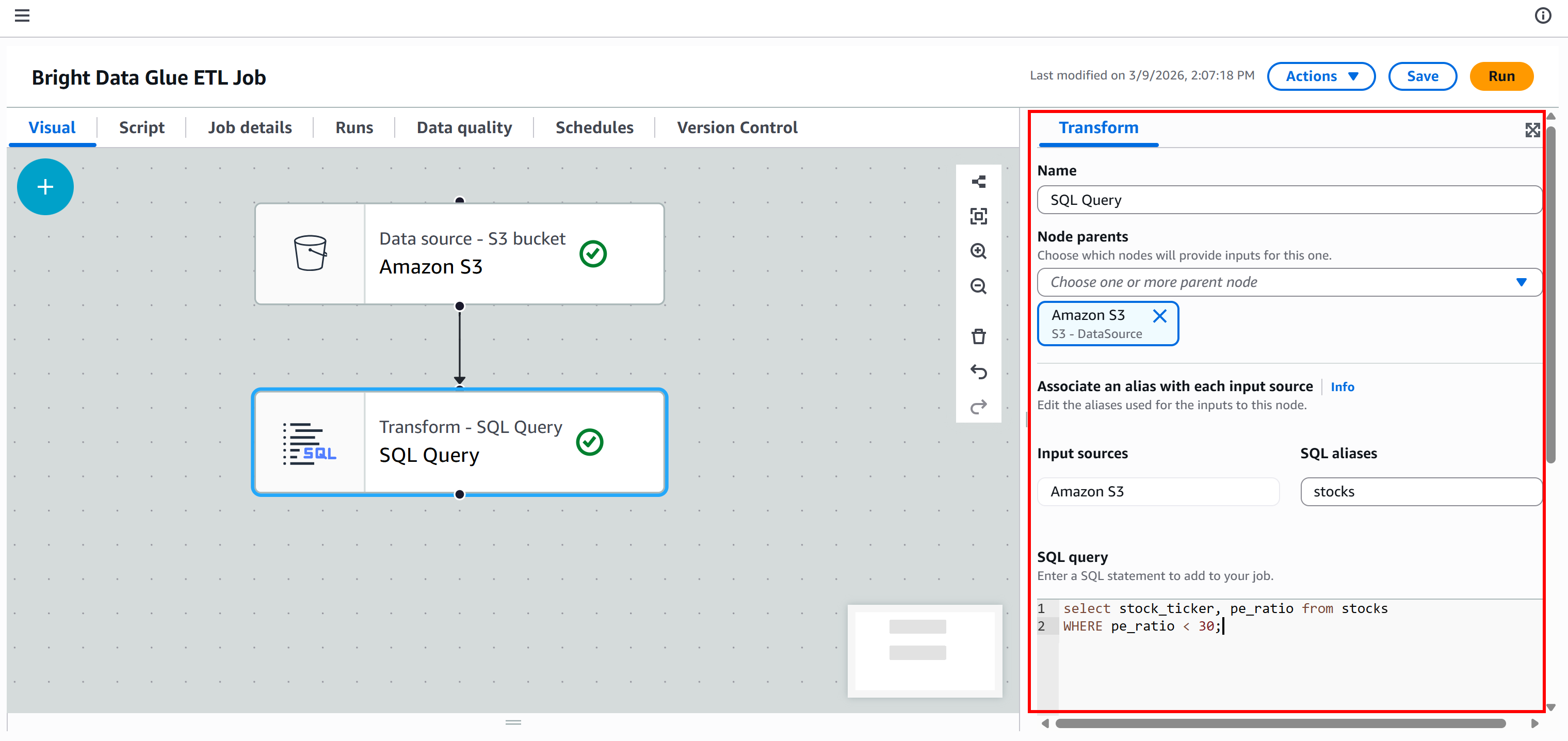
注:実際のパイプラインでは、変換(T)フェーズは通常複数のステップを含みます。複数の変換ノードを追加して順次接続するか、ワークフロー内で複数の分岐を作成することで実装できます。
ステップ #8: Load (L) フェーズで S3 バケットに接続
「SQLクエリ」ノードの出力は、フィルタリングおよび変換されたデータです。最終ステップとして、このデータをS3バケットに保存し、ETLパイプラインのロード(L)フェーズを完了させます。
「ターゲット」タブで、別のAmazon S3ノードを追加します:
新規ノードをクリックして設定します。親ノードを「SQLクエリ」ノードに設定します。「SQLクエリ」ノードの出力が、新規Amazon S3ノードへの入力として送信されます。
出力形式を「JSON」に設定し、圧縮は適用しません。次に、出力先のS3フォルダを指定します。例:
s3://bright-data-etl-bucket/output/注:bright-data-etl-bucket は実際の S3 バケット名に置き換えてください。
これにより、変換されたデータは/outputフォルダ内に保存されます。
その他のオプションはすべてデフォルトのままにし、「保存」を押して AWS Glue ETL ジョブを更新します: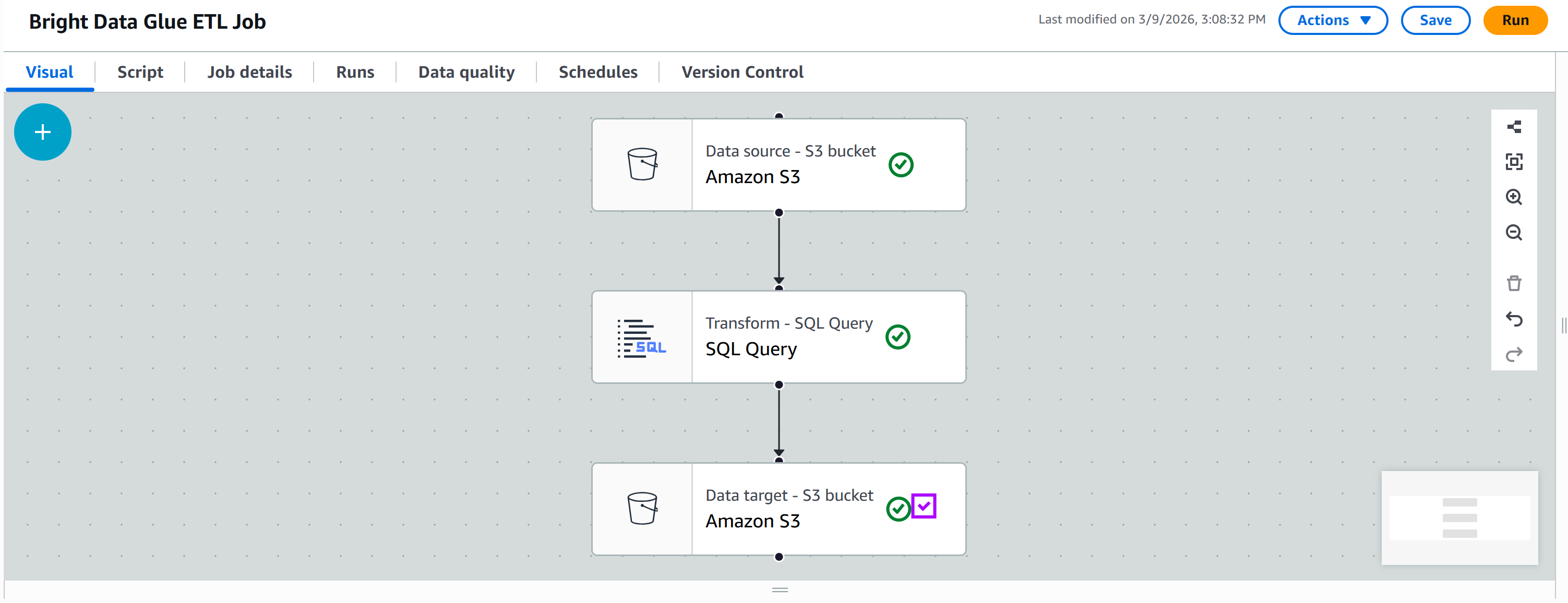
完了!ETLパイプラインの設定が完了し、実行準備が整いました。
ステップ #9: パイプラインを実行し結果を確認する
「実行」ボタンを押してAWS Glueジョブを起動します。以下のような通知が表示されます:
「実行」タブに移動し、パイプラインの実行状況を監視します:
「実行ステータス」が「成功」になるまでお待ちください。1 分以上かかる場合がありますので、しばらくお待ちください。
完了すると、出力ファイルがS3バケットの/outputフォルダに表示されます: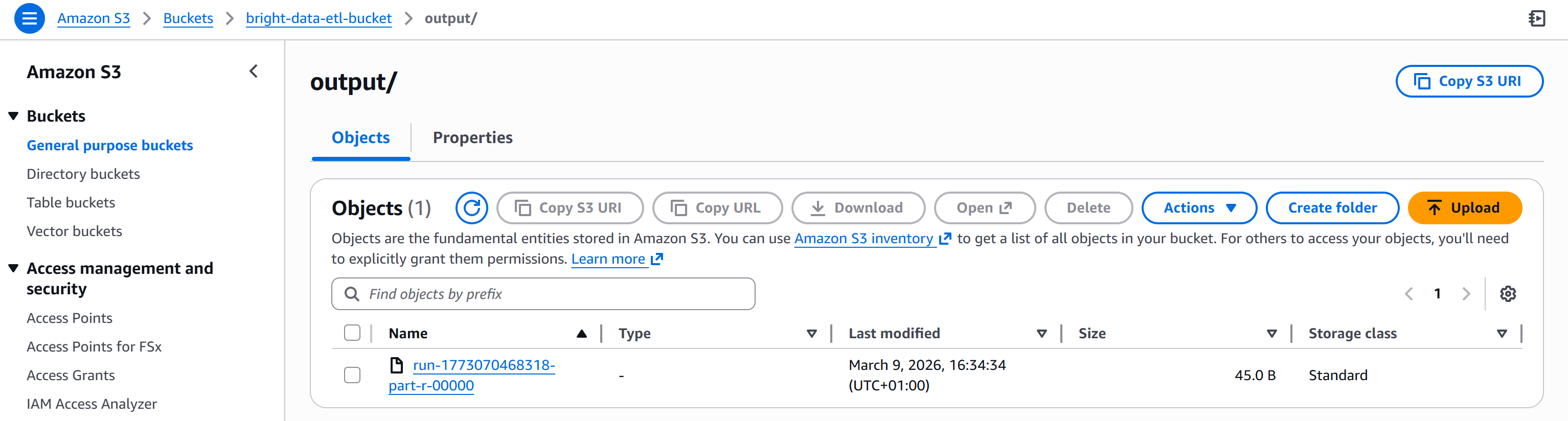
生成されたファイルを開きます。フィルタ閾値(例:30未満)以下のP/E比率を持つ銘柄リストが表示されます:
ご覧の通り、結果としてAMZN、BRK.B、META、MSFT、GOOGLなどの銘柄が含まれています。
これで完成です! Bright Dataと連携したAWS Glue ETLパイプラインを構築しました。ExtractフェーズではBrightDataのウェブスクレイピングAPIを活用し、TransformフェーズではSQLでデータをフィルタリングし、Loadフェーズで結果をS3に保存します。
AWS Glue ETLジョブにおけるその他のBright Data連携アイデア
Bright Dataのウェブデータ取得機能により、ETLパイプラインの抽出フェーズで重要な役割を果たせることは間違いありません。
しかし、Bright Dataは抽出以外にも活用可能です。例えば変換フェーズでのデータエンリッチメント、検証、確認などに活用できます。具体的には以下のような活用方法が考えられます:
- 企業プロフィールの強化:ZoomInfoスクレイパーを使用して、Webソースから抽出されたレコードに企業属性データを追加します。
- 従業員情報の検証:LinkedInプロフィールを統合し、役職、メールアドレス、ソーシャルプロフィールを検証。
- 競合他社の価格や製品詳細の取得:AmazonスクレイパーやAmazon Reviewsスクレイパーを使用して、市場インサイトを含むデータセットを強化します。
- SEOまたは検索データの追加: SERP APIを使用して、検索エンジンのランキングデータやキーワードインサイトを、変換済みデータセットの一部として含めるほか、データ検証にも活用できます。
この統合方法について疑問がある場合は、カスタムビジュアル変換の定義に関する公式ガイドを参照してください。必要なのは、説明を含むJSONファイルと、Bright Data API統合のロジックを含むPythonファイルを含めることだけです。
まとめ
このチュートリアルでは、AWS Glue の概要と、Bright Data の多様なウェブスクレイピングソリューションが AWS Glue の機能を強化する方法について学びました。
特に、Bright DataのウェブスクレイピングAPIがETLパイプラインの抽出(E)と変換(T)の両フェーズ(生データの取得、データセットの強化、情報の検証など)をどのようにサポートできるかを確認しました。
今すぐBright Dataの無料アカウントを作成し、当社のウェブデータソリューションを探索しましょう!




