

このチュートリアルでは、以下の内容を学びます:
- Bright Dataの配信インフラからデータを受け取るためのSnowflakeのセットアップ方法。
- GoodreadsブックスのデータセットをSnowflakeの内部ステージに直接配信するよう設定する方法。
- スナップショットをトリガーしてクエリ可能なテーブルに読み込み、600万件以上のブックレコードに対してSQLを実行する方法。
さっそく始めましょう!
Snowflakeインジェストワークフローの紹介
大まかに言うと、パイプラインには3つのフェーズがあり、それぞれ独自のセクションで説明されています:
- Snowflakeのセットアップ:Bright Dataが認証するデータベース、ステージ、ロール、およびサービスユーザーを作成します。これは最もSQLが多い部分ですが、各コマンドは完全な形で提供され、順番に実行されます。
- Bright Dataの設定:マーケットプレイスからデータセットを選択し、Snowflake環境に接続して、スナップショットをトリガーします。Bright Dataはファイルを直接内部ステージにプッシュします。
- ロードとクエリ:単一の
COPY INTOコマンドでステージングされたファイルを構造化テーブルに移動します。残りは標準SQLです。
出力は、ユースケースに応じたスケジュールで更新される、構造化されたウェブデータが格納された完全にクエリ可能なSnowflakeテーブルです。CSVエクスポートも、カスタムETLグルーコードも不要です。
各フェーズとその実装方法について詳しく学びましょう!
1. Snowflakeのセットアップ
Bright Dataは、Snowflakeアカウントに直接認証してファイルを配信します。これには、専用の内部ステージ(受信ファイルのランディングゾーン)、そのステージへの書き込みアクセス権を持つサービスロール、およびそのロールに割り当てられたサービスユーザーが必要です。
この目的に専用オブジェクトを使用することで、インジェストを分析ワークロードから分離し、後で資格情報の監査、取り消し、またはローテーションを容易にします。
2. Bright Dataデータセットの設定とスナップショット配信
Bright Dataのデータセットマーケットプレイスには、Amazon、LinkedIn、Crunchbase、Glassdoor、ホテルリスト、不動産、求人情報などをカバーする、事前構築・検証済みのデータセットが含まれています。各データセットには完全なフィールドリファレンスが付属しており、最初のバイトが届く前にSnowflakeスキーマを設計できます。
Snowflakeへの直接配信はデータセット製品で利用可能です。Web Scraper APIを使用している場合は、S3バケットにファイルを配信し、外部ステージからロードしてください。
Snowflakeを配信先として設定すると、Bright Dataが転送を処理します。作成したサービスユーザーを使用して認証し、ファイルを内部ステージにステージングし、コントロールパネルに配信を記録します。スナップショットは、オンデマンド、スケジュール、またはマーケットプレイスデータセットAPIを介してトリガーできます。
3. ロードとクエリ
ステージにファイルがある状態で、単一のCOPY INTOコマンドでテーブルにロードします。そこから、特別な構文も新しいツールも不要な標準SQLでクエリを実行します。
Bright Dataを受け取るためのSnowflakeのセットアップ
Snowflake側を準備してパイプラインの構築を始めましょう。このセクションのすべてのコマンドは、SnowsightのSQLワークシートまたはSnowSQL内で実行されます。まず、データベース、ロール、ユーザーを作成するために必要な権限があることを確認するために、これを実行してください:
USE ROLE ACCOUNTADMIN;前提条件
このセクションに沿って進めるには、以下が必要です:
ACCOUNTADMINまたはSYSADMIN権限を持つSnowflakeアカウント。- Snowflake UI(Snowsight)の基本的な知識。
ステップ#1:データベースとスキーマの作成
Snowflakeでは、データベースはすべてのデータオブジェクトのトップレベルコンテナです。スキーマはデータベース内に位置し、関連するテーブル、ステージ、その他のオブジェクトをグループ化します。Bright Data専用のデータベースとスキーマを作成することで、そのオブジェクトを既存のデータから分離し、権限管理を容易にします。
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;既存のデータベースを使用することもできます。その場合、以降のコマンドでbright_data_dbが表示される箇所をそのデータベース名に置き換えてください。
ステップ#2:専用ウェアハウスの作成
Snowflakeでは、ウェアハウスはCOPY INTOを含むSQLステートメントを実行するコンピュートクラスターです。ストレージとは別であるため、アクティブに実行中の時のみコンピュートコストが発生します。Bright Dataインジェスト用の専用ウェアハウスを使用することで、そのコンピュートコストを可視化し、インジェストワークロードが分析クエリとリソースを競合しないようにします。
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60は、60秒間アイドル状態が続いた後にウェアハウスをシャットダウンし、配信の合間に無駄に実行されないようにします。AUTO_RESUME = TRUEは、次のCOPY INTOが実行される際に自動的に再起動します。XSmallはほとんどのBright Data配信を快適に処理します。ボリュームが増えた場合はサイズを変更してください。
ステップ#3:内部名前付きステージの作成
Snowflakeでは、ステージはファイルがテーブルにロードされる前に置かれる名前付きの場所です。内部名前付きステージはSnowflake自体の中に存在します。S3バケットや外部クラウドストレージは不要です。
このステージはBright Dataとテーブルの橋渡し役です。Bright Dataはデータを行ごとに直接テーブルにロードするのではなく、最初に構造化ファイル(ParquetまたはJSON)をステージに格納します。Snowflakeはその後、COPY INTOを介してこれらのファイルを一括で読み取ります。これは行レベルの挿入よりも大幅に高速でコスト効率が高いです。また、チェックポイントも提供されます:ステージ内のファイルを検査し、正しく見えることを確認し、ロードをトリガーするタイミングを選択できます。
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';ステップ#4:ロールの作成と適切な権限の付与
Snowflakeでは、ロールはユーザーに割り当てられる権限のコレクションです。権限をユーザーに直接付与するのではなく、ロールに付与してそのロールをユーザーに割り当てます。これにより、ユーザーアカウント自体に触れることなく、後でアクセスを取り消したり変更したりすることが容易になります。
このロールはBright Dataに必要なアクセスだけを与え、それ以上は与えません。
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;各グラントの内容とそれが必要な理由を以下に示します:
- データベースとスキーマへのUSAGE:ロールがその中のオブジェクトを参照してナビゲートできるようにします。これがないと、ロールがステージに直接権限を持っていても、Snowflakeは「オブジェクトが存在しない」エラーを返します。
- ウェアハウスへのUSAGE:ロールがウェアハウスに対してSQLステートメントを実行できるようにします。これにより
COPY INTOが実際に実行されます。 - ウェアハウスへのOPERATE:ウェアハウスが一時停止されている場合にロールが再開できるようにします。これがないと、Bright Dataがロードをトリガーしたときに自動一時停止されたウェアハウスが再起動しません。
- ステージへのREAD:
COPY INTOがステージからファイルを読み取ってテーブルに格納するために必要です。 - ステージへのWRITE:Bright Dataがそもそもステージにファイルを格納するために必要です。
ステップ#5:Bright Dataサービスユーザーの作成
サービスユーザーは、人ではなくシステムやアプリケーションのために作成されたSnowflakeアカウントです。専用サービスユーザーを使用することで、Bright Dataのアクセスが人間のユーザーアカウントから分離され、他の誰にも影響を与えることなく資格情報をローテーションまたは取り消すことができます。
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSEは、最初のログイン時にSnowflakeがパスワードリセットを求めるのを防ぎます。これがないと自動接続が壊れます。DEFAULT_ROLE、DEFAULT_WAREHOUSE、DEFAULT_NAMESPACEは、セッションの開始方法に関わらず、サービスユーザーが常に正しいコンテキストで接続することを保証します。最後の行は、このユーザーにbright_data_loaderロールを割り当て、ステップ#4で定義された権限を正確に付与します。
ユーザー名とパスワードを安全に保管してください。次のセクションでBright Dataコントロールパネルに貼り付けます。
ステップ#6:Bright DataのIPをホワイトリストに追加する(ネットワークポリシーを使用している場合)
Snowflakeアカウントがネットワークポリシーを適用している場合、Bright Dataの配信サーバーを許可リストに追加する必要があります。以下のIPは執筆時点で最新のものです。静的IPは変更される可能性があるため、適用前にBright Dataサポートまたはドキュメントで最新の範囲を確認してください:
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);アカウントにアクティブなネットワークポリシーがない場合は、このステップをスキップしてください。
ステップ#7:ターゲットテーブルの作成
このチュートリアルでは、例としてGoodreadsのブックデータを使用します。以下のスキーマは、Bright DataのGoodreads BooksデータセットがJSONで配信するフィールド名に直接マッピングされます:
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANTはSnowflakeの半構造化型です。配列とネストされたオブジェクトをそのまま格納し、ドット記法とブラケット構文(author[0]:name、community_reviews['5_stars']:reviews_num)を使用してクエリできます。これにより、ロード時に複雑なネストされたフィールドをフラット化する必要がなくなります。必要なサブフィールドがわかったら、ビューまたはLATERAL FLATTENを使用して後で行うことができます。
理解しておく価値のあるいくつかのフィールドの決定事項:
authorをVARIANTとして:各ブックには複数の著者がいる可能性があります。フィールドはオブジェクトの配列として届きます。VARIANTとして格納することで、別の結合テーブルを必要とせずにすべての著者データが保持されます。genresをVARIANTとして:ジャンルも配列です。1冊の本は複数のジャンルに属することができます。ジャンルでクエリする必要がある場合は、LATERAL FLATTEN(INPUT => genres)でフラット化します。num_reviewsをVARCHARとして:Bright Dataのデータ辞書では、このフィールドはNumberではなくTextとしてマークされており、フォーマットされた形式(例:1234ではなく"1,234")で届く可能性があります。集計が必要な場合は、クエリ時にTO_NUMBER(REPLACE(num_reviews, ',', ''))でキャストしてください。community_reviewsをVARIANTとして:スターレベルごとの評価の内訳が含まれており、それぞれにカウントとパーセンテージがあります。VARIANTとして格納し、必要に応じて特定のスターレベルをクエリします。
注意:マーケットプレイスから別のデータセット(LinkedIn企業、求人情報、Amazon製品など)を選択する場合は、そのフィールドリストに合わせてスキーマを調整してください。Bright Dataはコントロールパネルのデータセットページで各データセットの完全なフィールドリファレンスを提供しています。
素晴らしい!これでSnowflake環境がBright Dataからデータを受け取る準備が整いました。
SnowflakeへのBright Data配信の設定
Snowflake側の準備ができたので、Bright Dataがデータをプッシュするよう設定しましょう。
前提条件
このセクションに沿って進めるには、以下が必要です:
- アクティブなサブスクリプションまたはトライアルを持つBright Dataアカウント。
- 前のセクションからのSnowflake接続詳細:アカウント識別子、ユーザー名、パスワード、データベース、スキーマ、ステージ、ウェアハウス名。
ステップ#1:データセットの選択
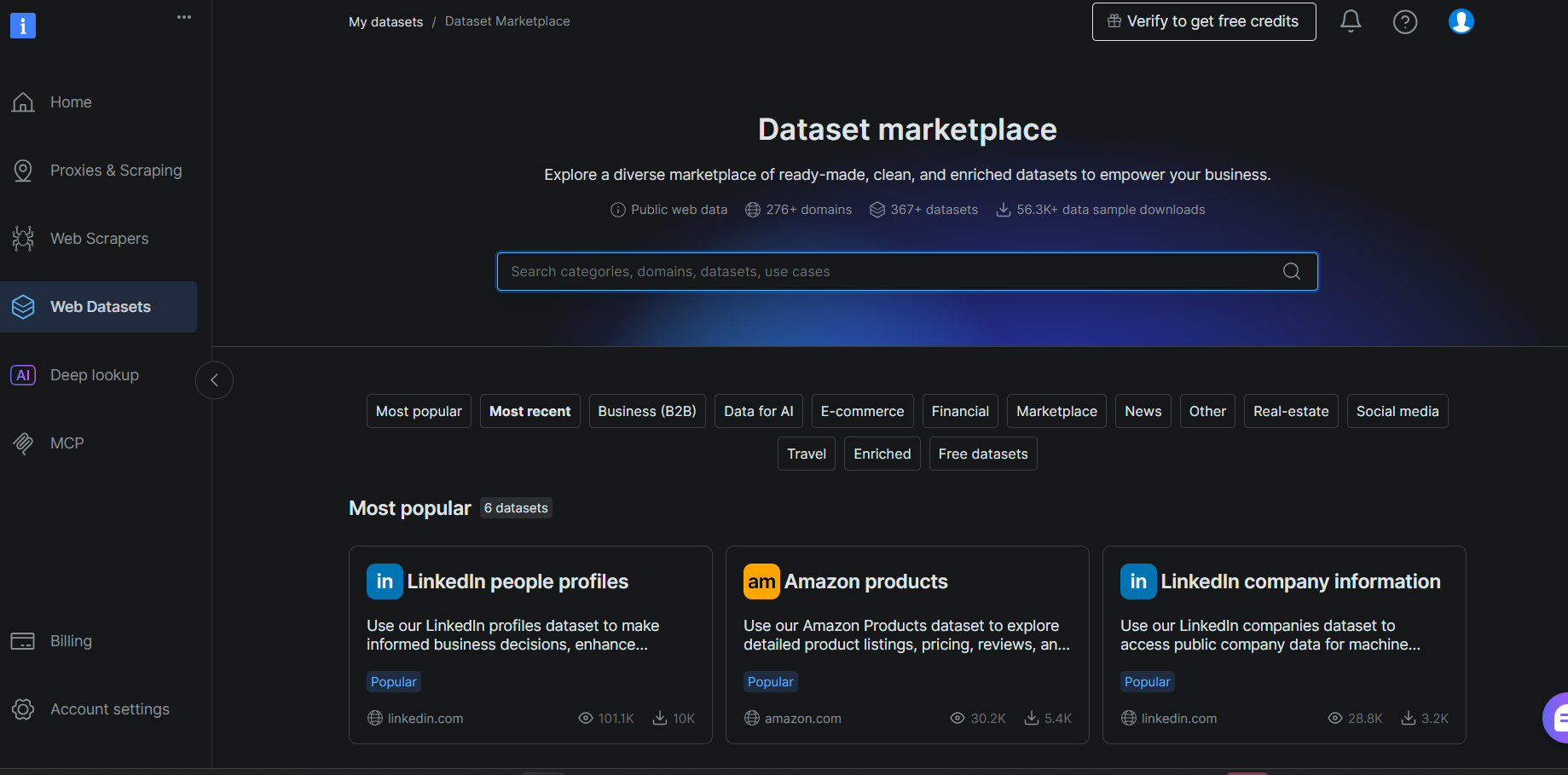
Bright Dataアカウントにログインし、Webデータセット > データセットマーケットプレイスに移動します。Goodreadsを検索し、結果からGoodreads Booksデータセットを選択します。
データセットページで、左パネルのフィールドリストを確認してください。すべてのフィールドがステップ#7で作成したテーブルの列に直接マッピングされていることに注目してください。これにより、最初の行が届く前にスキーマが正しいことが確認できます。
ステップ#2:配信先としてSnowflakeを設定する
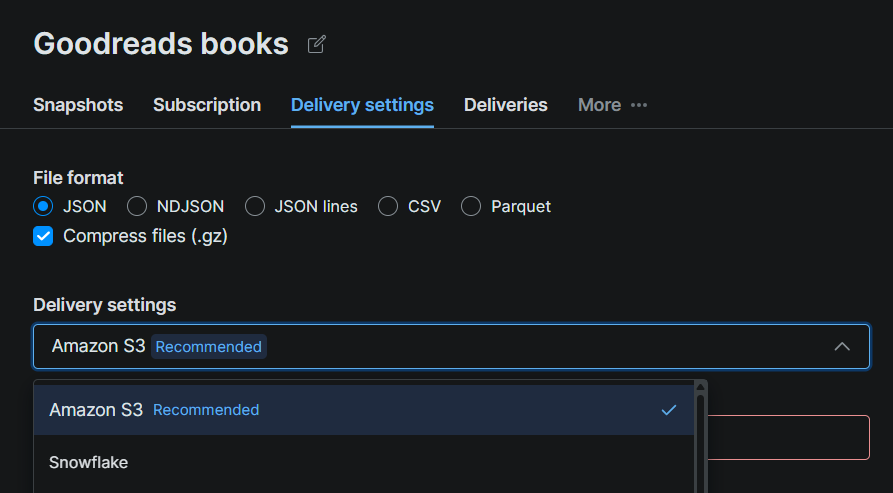
データセットページの配信設定タブをクリックし、配信先としてSnowflakeを選択します。Snowflakeセットアップからの詳細を接続フォームに入力します:
| フィールド | 値 |
|---|---|
| アカウント識別子 | SnowflakeアカウントのURL(例:xy12345.us-east-1) |
| データベース | bright_data_db |
| スキーマ | web_data |
| ステージ | bright_data_stage |
| ウェアハウス | bright_data_wh |
| ロール | bright_data_loader |
| ユーザー | brightdata_svc |
| パスワード | ステップ#5で設定したパスワード |
接続フォームの下の3つのフィールドはオプションであり、このチュートリアルではデフォルトのままにできます:
- データセットファイル名:Bright Dataがステージングするファイルのカスタムプレフィックス。デフォルトの命名を使用する場合は空白のままにします。
- バッチサイズ(レコード数):Bright Dataが各ステージングファイルにパックするレコード数。デフォルトはほとんどのワークロードに適しています。
- バッチを1つのファイルにグループ化する(.tar):ステージングの前にすべてのバッチを単一のアーカイブに結合します。パイプラインが配信ごとに単一ファイルを特に必要とする場合を除き、チェックを外したままにします。
Snowflakeをテストをクリックします。緑色の確認メッセージは、Bright Dataが認証してステージに書き込めることを意味します。テストが通ったら、保存をクリックします。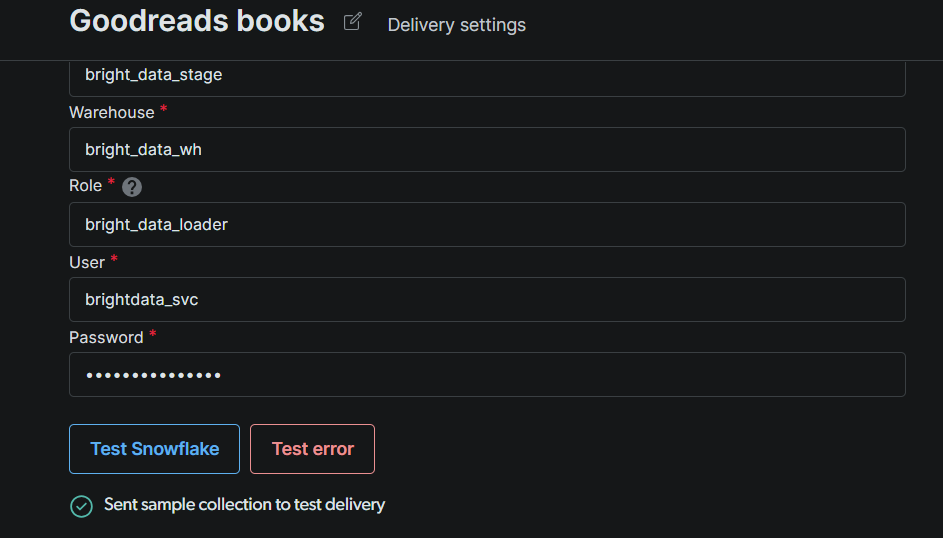
注意:テストが失敗した場合は、順番に3つのことを確認してください:(1) アカウント識別子の形式(Snowflakeはorgname-accountnameまたはレガシーのaccountid.region.cloud形式を期待します);(2) サービスユーザーがロールの割り当てを含むステップ#4のすべてのグラントを持っているか;(3) アカウントにアクティブなネットワークポリシーがある場合、Bright DataのIPがホワイトリストに追加されているか。
ステップ#3:スナップショットのリクエスト
データセットページで、配信タブをクリックします。次に右上隅の配信を追加 +をクリックします。これにより配信設定パネルが開き、配信先(Snowflake)を選択し、配信するスナップショットまたは日付範囲を選択して確認します。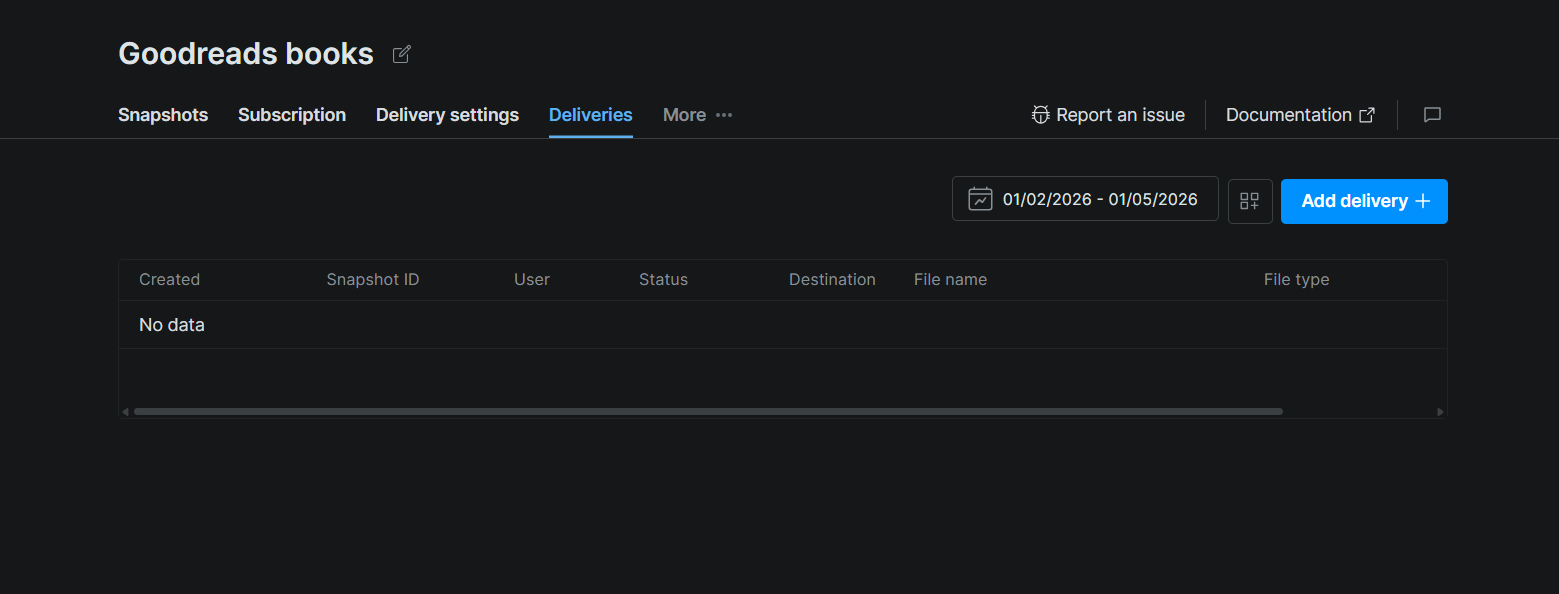
送信後、配信はスナップショットID、ステータス、配信先、ファイル名、ファイルタイプの列を持つテーブルに表示されます。Bright Dataがステージへのファイルのプッシュを完了すると、ステータスは保留中から完了に変わります。
配信をプログラムでトリガーするには、マーケットプレイスデータセットAPIが2ステップのフローを使用します:まずフィルターAPIを呼び出してフィルタリングされたスナップショットを作成し、次にスナップショット配信を呼び出してSnowflakeステージにプッシュします。
ステップ1:フィルタリングされたスナップショットを作成する:
curl --request POST
--url "https://api.brightdata.com/datasets/filter"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'レスポンスにはsnapshot_idが含まれています。それを次の呼び出しに渡します。
ステップ2:スナップショットをSnowflakeステージに配信する:
curl --request POST
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"destination": "snowflake"
}'Bright Dataはデフォルトでデータセットに設定されたフォーマットを使用します。明示的に指定したい場合は、リクエストボディに"format": "parquet"または"format": "ndjson"を追加します。ステージに届いたフォーマットがCOPY INTOのFILE_FORMATに渡すものになります。
GET /datasets/snapshots/YOUR_SNAPSHOT_IDをポーリングして配信ステータスを確認するか、コントロールパネルの配信タブで監視します。ステータス列に完了と表示されたら、ファイルはステージにあり、ロードの準備ができています。素晴らしい!
配信が完了すると、コントロールパネルのスナップショットページへのリンクが記載されたメールも受信します。そこで最初の30件のレコードをプレビューし、総レコード数を確認し、コストサマリーレポートをダウンロードできます。1,000レコードあたり$2.50で、レポートには届いたレコード数とそのコストが正確に表示されます。素晴らしい!
Snowflakeへのデータのロード
Bright Dataの仕事はファイルが内部ステージに届いた時点で終わります。テーブルへのロードはあなたの責任であり、1つのSQLコマンドで完了します。この分離を理解することは重要です:ロードをいつ実行するか、どのエラー処理を適用するか、テーブルをどのくらいの頻度で更新するかをあなたが制御できることを意味します。
前提条件
このセクションに沿って進めるには、以下が必要です:
- 上記のSnowflakeセットアップとBright Data設定セクションを完了していること。
- スナップショット配信が完了していることを確認していること(メールまたはBright Dataコントロールパネルのスナップショットページで)。
ステップ#1:ステージにファイルが届いていることを確認する
他の何かを実行する前にこれを実行してください:
LIST @bright_data_db.web_data.bright_data_stage;サイズとタイムスタンプとともに1つ以上のファイルがリストされているはずです。ステージが空の場合、スナップショットはまだ配信が完了していません。Bright Dataコントロールパネルのスナップショットページでステータスを確認してください。
結果のファイル拡張子に注目してください。Bright Dataが配信に使用するフォーマットによって、次のステップでCOPY INTOに渡すFILE_FORMATが決まります。UIでトリガーされたスナップショットの場合、Bright Dataは配信設定時に別途指定しない限り通常NDJSONで配信します。deliver-snapshotエンドポイントを使用してAPIでトリガーされたスナップショットの場合、フォーマットはリクエストボディで渡したものです。.parquetファイルが見える場合はTYPE = 'PARQUET'を使用し、.jsonまたは.ndjsonファイルが見える場合はTYPE = 'JSON'を使用します。
ステップ#2:テーブルへのファイルのロード
Parquetファイルの場合:
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';JSONまたはNDJSONファイルの場合:
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME(Parquetのみ)は列名を自動的にマッピングするため、順序は関係ありません。ON_ERROR = CONTINUEは、ロード全体を中断するのではなく、不正な行をスキップします。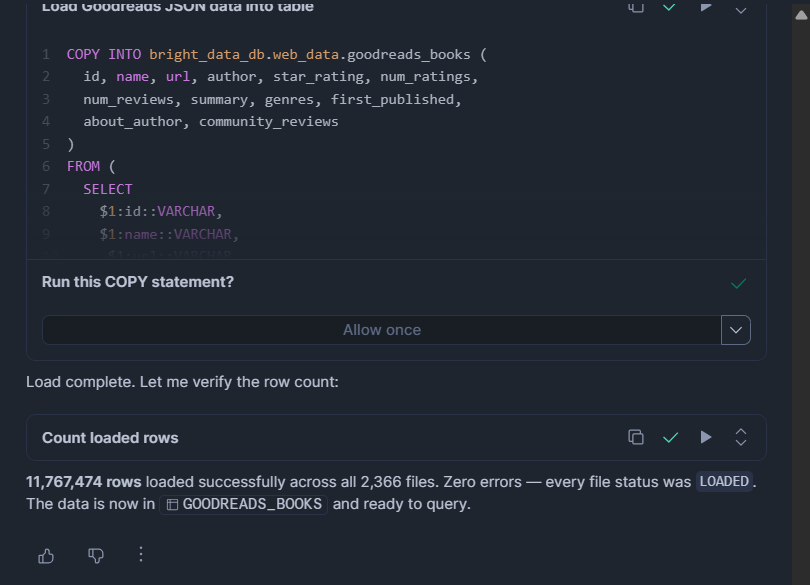
ステップ#3:ロードの確認
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORYは、ロードされた行数、スキップされた行数、処理されたファイル名、および失敗した行の正確なエラーメッセージを表示します。毎回のロード後、特に最初の時は必ずこれを確認してください。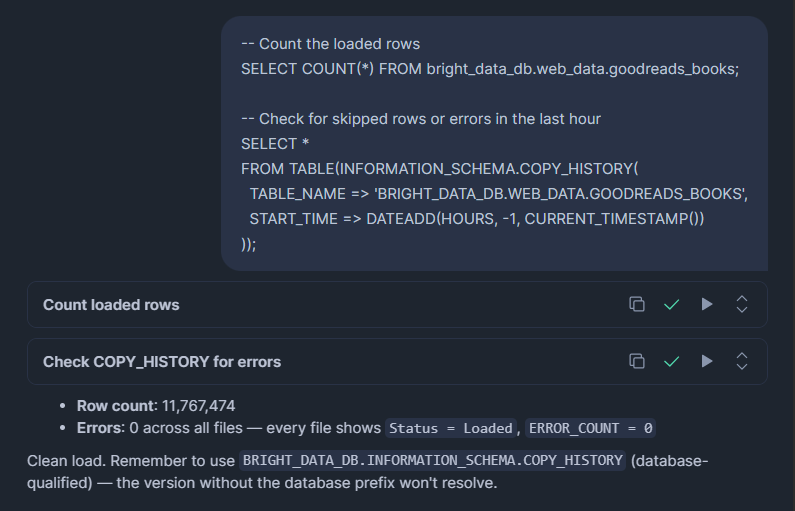
データのクエリ
SnowflakeにGoodreadsのブックデータがある状態で、数百万タイトルにわたる読書トレンド、著者パフォーマンス、ジャンル人気を大規模に理解することが価値となります。以下のクエリはそれらのユースケースを直接反映しています。
生データの確認
分析クエリを作成する前に、データが期待通りに見えることを確認します:
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;結果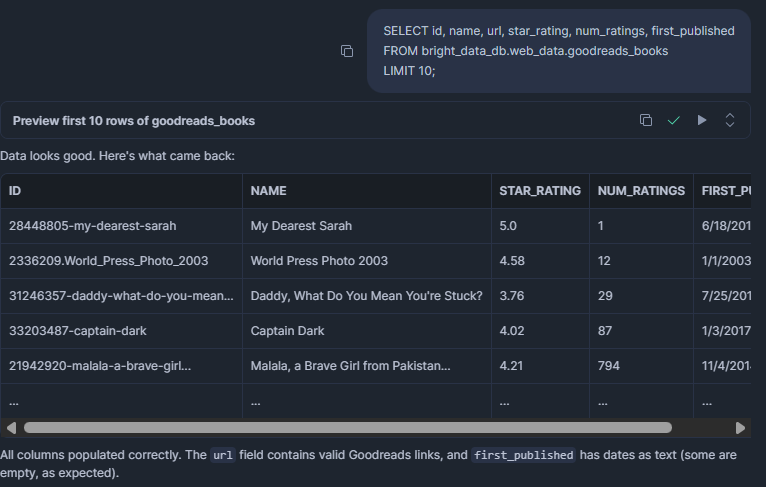
最も強い読者の支持を得ているブックはどれか?
高いstar_ratingだけでは不十分です。12人から4.8つ星のブックはほとんど何も教えてくれません。このクエリは、高評価かつ広く読まれているブック、つまりそのブックが本物の持続力を持つことを示す組み合わせを浮かび上がらせます。
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;結果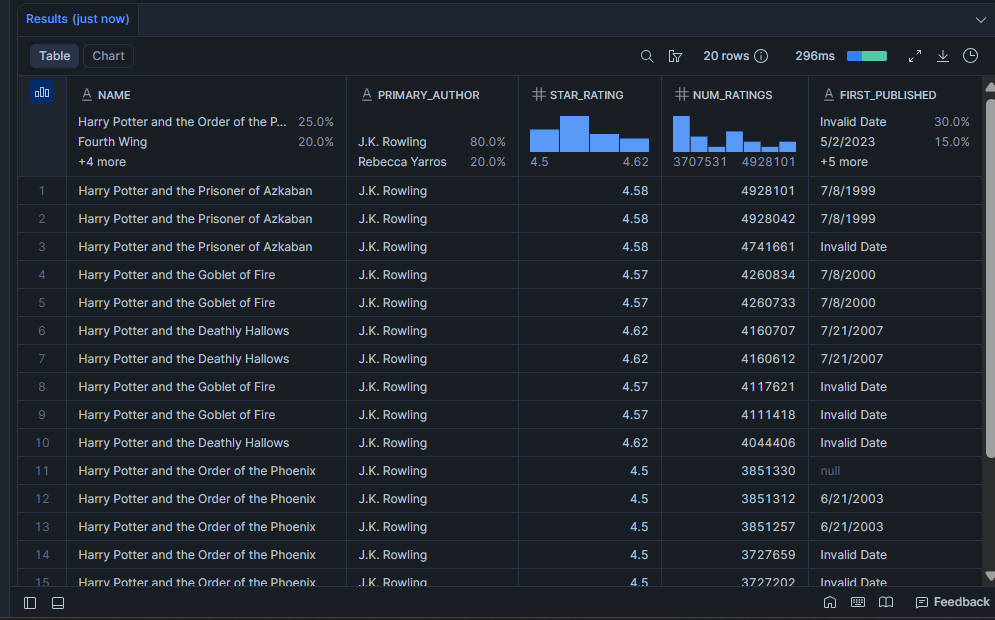
どのジャンルが最も多くのタイトルを持ち、最も高い平均評価を持っているか?
読者の需要がどこに集中しているかを理解するのに役立ちます。タイトル数が多いが平均評価が低いジャンルは、低品質なエントリーで溢れている可能性があり、出版社や推薦エンジンにとってのチャンスとなります。
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;結果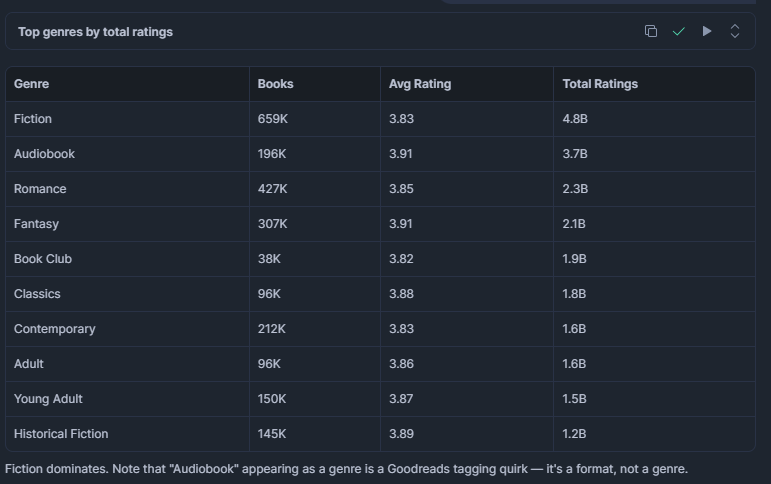
データセット内で最もフォロワーの多い著者は誰か?
著者のフォロワー数はプラットフォームオーディエンスの代理指標です。平均ブック評価と組み合わせることで、最もフォロワーの多い著者が最も尊重されているかどうか、またはフォロワー数と品質が乖離しているかどうかがわかります。
about_authorは各ブックレコードのフラットオブジェクトであり、配列インデックスなしで簡単にクエリできます。これは特定のブックページに記載されている著者を反映しており、クレジットされた著者の配列であるauthorとは若干異なる場合があります。
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;結果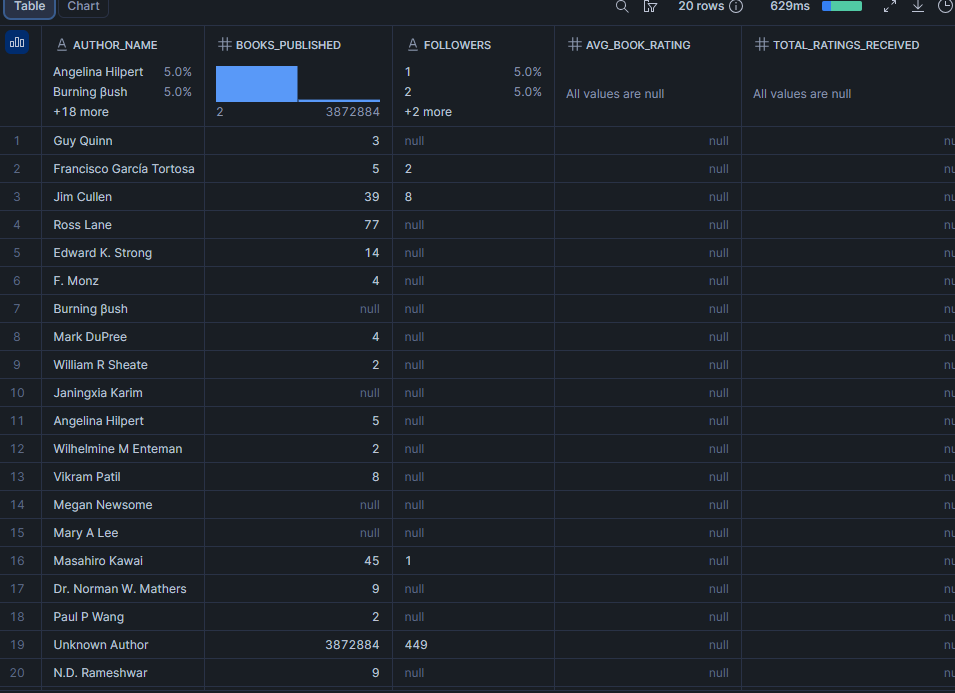
注意:followersはソースフィールドがVARCHARであるため("12.3k"のようなフォーマットされた値が含まれている可能性があります)、テキストとしてソートされています。データセットがクリーンな整数を配信する場合は、TO_NUMBER(followers)でキャストして数値でソートしてください。
ブックはどれほど物議を醸すか?コミュニティレビューからスター内訳を抽出する
高い平均評価を持つが1つ星レビューの割合が大きいブックは、普遍的に愛されているというよりも物議を醸している可能性があります。このクエリは特定のブックの評価分布を取得します。
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviewsはスター内訳とともに総書面レビュー数を提供し、長い書面意見を引き付けるブックとサイレントなスター評価を集めるブックを区別するのに役立ちます。
これで完成です!Bright Dataから構造化されたウェブデータを取得し、Snowflakeでクエリ可能にする動作するパイプラインが完成しました。
更新の自動化
本番環境での使用では、毎回手動でCOPY INTOを実行するのではなく、新しいスナップショットが自動的にロードされるようにしたいでしょう。まずオプションAから始めてください。配信完了後数秒以内にテーブルを更新する必要がある場合のみオプションBに移行してください。
オプションA:スケジュール駆動のインジェストのためのSnowflakeタスク
SnowflakeタスクはcronスケジュールでCOPY INTOを実行し、追加のインフラは不要です。タスクが起動したときにファイルがステージに準備できているよう、Bright Dataに一致する配信スケジュールを設定してください。
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;プロのヒント:最初の自動実行時に、タスクが起動した後COPY_HISTORYを確認して、スケジュールのタイミングがBright Dataの配信完了タイミングと一致しているかを確認してください。配信完了前に実行されるタスクは空のステージを見つけ、0行をロードします。
オプションB:低レイテンシのイベント駆動インジェストのためのSnowpipe REST API
Snowpipeは、insertFiles REST エンドポイントを介してプログラムでトリガーされ、ファイルが届いてから数秒以内にステージからファイルをロードします。ユースケースがほぼリアルタイムの鮮度を必要とする場合にのみ使用してください。オプションAと比べて設定の複雑さが大幅に増します。
セットアップには2つの部分があります。まず、パイプを作成します:
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;AUTO_INGEST = TRUEがないことに注意してください。内部名前付きステージの場合、クラウドメッセージングによる自動インジェストはAWSホストのSnowflakeアカウントでのみ利用可能であり、現在はプレビュー機能です。REST APIアプローチはすべてのクラウドプラットフォームで機能します。
次に、スナップショットの準備ができたときにステージングされたファイルをリストアップしてSnowpipeに送信するよう、Webhookハンドラーを接続します:
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")注意:Snowpipe REST APIはパスワード認証ではなくキーペア認証が必要です。RSAキーペアを生成し、Snowflakeのbrightdata_svcに公開キーを割り当て(ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...')、上記の秘密キーファイルパスを渡します。SDKはpip install snowflake-ingestでインストールしてください。
まとめ
この記事では、Bright DataからSnowflakeへの完全なウェブデータインジェストパイプラインを構築する方法を学びました。ワークフロー:
- Bright Dataが直接認証する専用データベース、ステージ、ロール、サービスユーザーでSnowflakeを準備します。
- 中間ストレージを必要とせず、Snowflakeを配信先としてBright Dataデータセットを設定します。
- コントロールパネルの配信タブまたはデータセットAPIを介してスナップショットをトリガーし、ファイルがステージに届くまで配信ステータスを監視します。
- 単一の
COPY INTOコマンドでステージングされたファイルを構造化されたSnowflakeテーブルにロードし、標準SQLでデータをクエリします。
同じセットアップがBright Dataのマーケットプレイスの任意のデータセットに機能します:Amazon製品、LinkedIn企業、求人情報、ホテルリスト、Crunchbaseレコードなど。各データセットは同じ配信パターンに従い、変わるのはテーブルスキーマだけです。
今すぐ無料のBright Dataアカウントを作成して、Snowflake環境にライブウェブデータを取り込み始めましょう!





