

AIエージェントは単独でライブウェブデータにアクセスできません。この設定では2つのツールを組み合わせ、エージェントにアクセス権限を与えます:
- – 軽量AIエージェントフレームワーク「Nanobot」:内蔵メモリ、スケジューリング、Model Context Protocol (MCP)対応
- –Bright Data MCP Server:検索、ウェブスクレイピング、構造化データ抽出、ブラウザ自動化のための65種類のウェブツールを提供
エージェントは単発の質問に答えるだけでなく、スケジュールに沿ってウェブサイトを監視し、変更点を記憶し、自律的に報告します。Bright Dataが困難な部分(IPブロック、ボット検知、JavaScriptレンダリング)を処理し、MCPがグルーコードなしでエージェントと連携します。
要約:
このチュートリアルでは、軽量AIエージェントフレームワーク「Nanobot」とBright Data MCPサーバーを連携させ、検索・ウェブスクレイピング・データ抽出のための65種類のウェブツールを備えた自律エージェントを構築します。
- 機能– Google検索、公開ウェブサイトのスクレイピング、Amazon/LinkedInからの構造化商品データ抽出、ページ変更の継続的監視
- セットアップ– カスタムコード不要で、約15分で1つのJSONファイルを設定
- デモ– 検索からリアルタイムページ監視まで6つの動作例を実行
BrightData無料プランで始めよう – 月5,000リクエストを無料で利用可能
Nanobotとは?
Nanobotは香港大学HKUDS Labが開発したパーソナルAIエージェントフレームワークです。GitHubスター数3万以上、コアコード約4,000行で構成され、以下の機能を備えています:
- ツール使用– ウェブ検索、ウェブフェッチ、ファイルシステム操作、シェルコマンド用の組み込みツール
- メモリ– セッションをまたいで永続化する長期記憶と検索可能な会話履歴
- Cronスケジューリング– 設定されたスケジュールで自律的に実行される定期タスク
- サブエージェント起動– 委任タスク用の並列バックグラウンドエージェント
- マルチチャネル対応– Telegram、Discord、WhatsApp、Slackとの連携
- MCPサポート– 任意のModel Context Protocolサーバー経由での外部ツールアクセス
Bright Data MCPサーバーとは?
Bright Data MCPサーバーは、Model Context Protocolを通じて65種類の専門的なWebツールを公開しています。MCP互換エージェントが接続すると、利用可能なすべてのツールとその呼び出し方法を自動的に検出します。このチュートリアルではNanobotを使用しますが、Bright Data MCPサーバーはプロトコルをサポートするあらゆるフレームワークで動作します。(詳細な比較については、MCPと従来のウェブスクレイピングの比較を参照してください。)
| カテゴリー | カウント | 主要ツール |
|---|---|---|
| 検索&スクレイピング | 7 | 検索エンジン、マークダウンとしてスクレイピング、HTMLとしてスクレイピング、抽出、バッチ処理 |
| eコマース | 10 | Amazon(商品、レビュー、検索)、ウォルマート(商品、販売者)、eBay、ホームデポ、ザラ、Etsy、ベストバイ |
| ソーシャルメディア | 23 | LinkedIn(5)、Instagram(4)、Facebook(4)、TikTok(4)、X/Twitter(2)、YouTube(3)、Reddit |
| ビジネスインテリジェンス | 5 | Crunchbase、ZoomInfo、Yahoo Finance、ロイター、GitHub |
| ブラウザ自動化 | 14 | ナビゲート、クリック、入力、スクリーンショット、スクロール、フォーム入力、テキスト/HTML取得、ネットワークリクエスト |
| その他 | 6 | Google Maps、Google Shopping、Zillow、Booking、Google Play、Apple App Store |
無料プランでは、検索およびスクレイピングツールが月5,000リクエストまで利用可能です。プロプランでは、構造化データ抽出ツールやブラウザ自動化を含むすべてのツールが利用可能になります。
前提条件
開始前に、以下の環境が整っていることを確認してください:
- Python 3.11+がインストールされていること(ダウンロード)
- Node.js 18以上とnpmがインストールされていること(ダウンロード) – MCPサーバーはNode.js上で動作します
- Bright Data APIトークン–無料登録後、アカウント設定>APIキーで生成
- 大規模言語モデル(LLM)プロバイダーのAPIキー– 本チュートリアルではAnthropic(Claude)を使用(APIクレジットが必要)。NanobotはOpenAI、DeepSeek、Google Gemini、OpenRouter、およびLiteLLM経由のその他12のプロバイダーをサポート
ステップ1: Nanobotのインストール
このステップでは、Nanobotコマンドラインインターフェース(CLI)をインストールし、エージェントの設定を保存するワークスペースを初期化します。
nanobot-ai AIパッケージをインストールします:
pip install nanobot-ai AI
pipが動作しない場合は、pip3 install nanobot-AIを試してください。
インストールを確認します:
nanobot --help出力にはonboard、agent、gateway、status、cron、channels、provider などのコマンドが一覧表示されます。
ワークスペースを初期化:
nanobot onboardonboardコマンドは、デフォルトの設定とワークスペースファイルを含む~/.nanobot/ディレクトリを作成します。
Nanobotのインストールとワークスペースの初期化が完了しました。次に、Bright Data MCPサーバー接続を設定します。
ステップ 2: ウェブスクレイピング用AIエージェントの設定
このステップでは、単一の JSON 設定ファイルを編集して Nanobot を Bright Data MCP サーバーに接続します。
任意のテキストエディタで~/.nanobot/config.jsonを開き、内容を以下で置き換えてください。VS Code (code ~/.nanobot/config.json)、nano (nano ~/.nanobot/config.json)、またはお好みのエディタを使用できます:
{
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4-6",
"provider": "auto",
"maxTokens": 8192,
"temperature": 0.1,
"maxToolIterations": 40,
"memoryWindow": 100
}
},
"providers": {
"anthropic": {
"apiKey": "YOUR_ANTHROPIC_API_KEY"
}
},
"tools": {
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHT_DATA_API_TOKEN",
"PRO_MODE": "true"
},
"toolTimeout": 120
}
}
}
}YOUR_ANTHROPIC_API_KEY をあなたの Anthropic API キーに、YOUR_BRIGHT_DATA_API_TOKEN をあなたの Bright Data API トークンに置き換えてください。
エージェントの動作を制御する3つのフィールド:
agents.defaults.model– エージェントを駆動するLLM。ツール使用にはClaude Sonnet 4.6が適しています。tools.mcpServers.brightdata– Nanobotにnpx経由でBright Data MCPサーバーを起動させ、APIトークンを渡すよう指示します。PRO_MODEをtrueに設定すると、エージェントが全ツールを利用可能になります。toolTimeout: 120– 構造化データ抽出ツール(Amazon、LinkedIn)は結果の返却に時間がかかる場合があるため、120秒のタイムアウトを設定します。
設定は完了です。次に接続を確認し、エージェントを起動してください。
ステップ3: AIエージェントの確認と起動
このステップでは、NanobotがLLMプロバイダーに到達でき、Bright Data MCPサーバーが接続できることを確認します。
設定が正しく行われていることを確認してください:
nanobot status出力結果でプロバイダー接続が確認できます:
🐈 nanobot Status
Config: ~/.nanobot/config.json ✓
Workspace: ~/.nanobot/workspace ✓
Model: anthropic/claude-sonnet-4-6
Anthropic: ✓次にエージェントを起動します:
nanobot agentターミナルにMCPサーバー接続とプロキシゾーン設定が表示されます:
🐈 対話モード (終了するには exit または Ctrl+C を押す)
必要なゾーンを確認中...
必要なゾーン "mcp_unlocker" が見つかりません。作成中...
必要なゾーン "mcp_browser" が見つかりません。作成中...
サーバーを起動中...注:初回起動時、
npxが@brightdata/mcpパッケージをダウンロードします(ダウンロードに1分程度かかる場合があります)。その後MCPサーバーがBright Dataアカウントに必要なプロキシゾーンを作成します(「ゾーンを作成中…」と表示されます)。ゾーン名はアカウント設定に依存します。以降の起動は高速化されます。
エージェントの準備が完了しました。以下のデモでは6つの実例を解説します。
デモ1: AI搭載Google検索
search_engineツールはGoogleにクエリを送信し、タイトル・URL・説明を含む構造化結果を返します。
エージェントに以下を入力してください:
「best AI agent frameworks 2025」を検索し、タイトルと簡単な説明付きのトップ5結果を表示エージェントはBrightDataのsearch_engineツールを呼び出し、195カ国を対象とした地理的ターゲティング機能付きGoogle検索結果を返します。
結果は生のHTMLではなく構造化データとして返され、エージェントは整理された要約を表示します。

デモ2: ウェブサイトをスクレイピングしてクリーンなMarkdownに変換
scrape_as_markdownツールは公開ウェブページを取得し、クリーンなMarkdown形式に変換します。
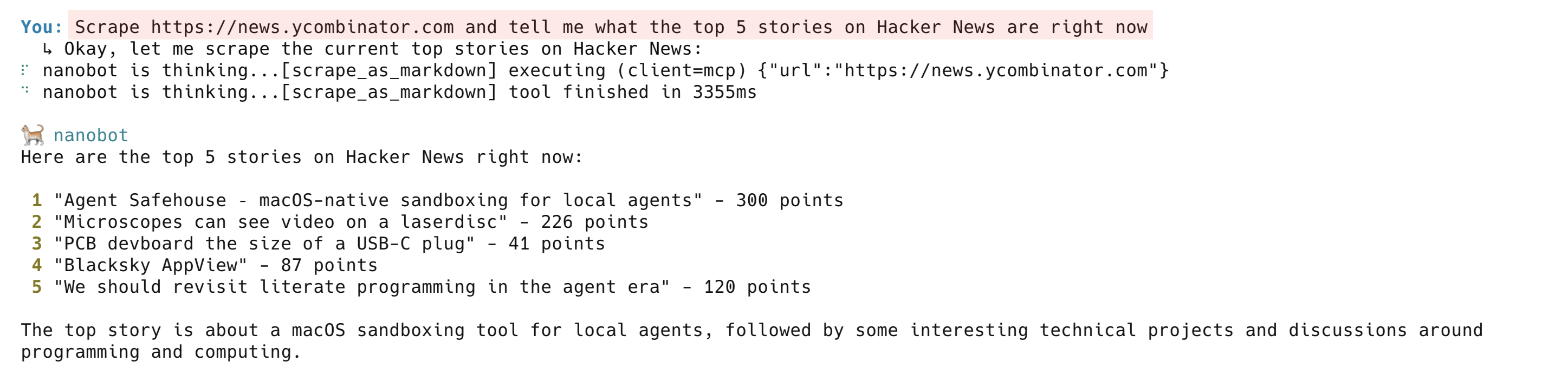
ライブページをスクレイピング:
https://news.ycombinator.com をスクレイピングし、Hacker News の現在のトップ5記事を教えてくださいエージェントはscrape_as_markdown を呼び出し、現在の Hacker News フロントページのクリーンな要約を返します。内部では、Bright DataWeb Unlockerがプロキシルーティング、ボット対策チャレンジ、JavaScript レンダリングを処理します。scrape_as_markdownツールはほとんどの公開ウェブサイトで動作します。
デモ3: Amazon商品データの構造化
注:デモ3、4、5は構造化データ抽出ツールを使用しており、Proプランが必要です。デモ1、2、6は無料プランで動作します – 無料プランユーザーはデモ6に進んでください。いずれ
の場合もPRO_MODEをtrueに設定したままにしてください。無料プランユーザーがPro専用ツールを呼び出すとエラーが発生します。
Amazonはスクレイピングが最も困難なウェブサイトの一つです。レイアウト変更でCSSセレクタが破綻し、ボット対策システムがリクエストをブロックし、生のHTMLは各フィールドごとにカスタムパーサーを必要とします。Bright Dataの構造化データ抽出ツールはこれら全てを回避します。以下のプロンプトを送信してください:
このAmazon商品の完全な商品詳細を取得してください: https://www.amazon.com/dp/B09468VZ5Wエージェントはweb_data_amazon_product を呼び出し、構造化された JSON を取得します:タイトル、価格、評価、レビュー数、販売者情報、製品特徴。Amazon がレイアウトを変更しても、Bright Data が抽出ツールを更新します。自分でパーサーをメンテナンスする必要はありません。


Bright Dataはウォルマート、eBay、ベストバイを含む120以上のウェブサイト向けに同様の構造化データ抽出ツールを提供しています。
デモ4: LinkedIn企業情報分析
通常のスクレイパーでLinkedInからデータを取得しようとすると、数分でログイン壁、ボット検知、レート制限に直面します。Bright Dataには専用のツールがあります:
https://www.linkedin.com/company/bright-data/のLinkedIn企業プロフィールを取得 - 従業員数、業種、本社所在地、説明を表示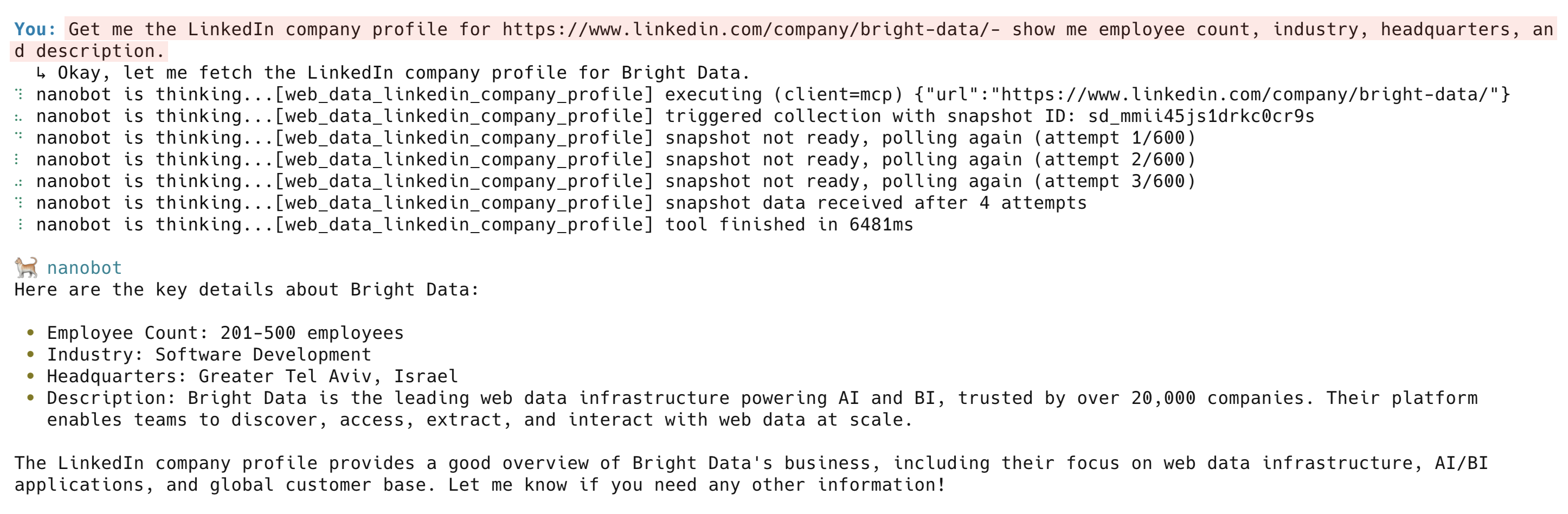
web_data_linkedin_company_profileツールは、企業概要、従業員数、本社所在地、専門分野、設立年、ソーシャルリンクを返します。その他のLinkedInツールには、web_data_linkedin_person_profile、web_data_linkedin_job_listings、web_data_linkedin_postsがあります。
デモ5:競合価格分析
Amazonでワイヤレスマウスを発売するにあたり、競合状況を把握する必要があるとします。手作業では、3つの商品ページを開き、データをスプレッドシートにコピーし、比較表を作成する必要があります。ここでは1つのプロンプトで実現します:
Amazonでワイヤレスマウスを発売します。以下の3つの競合製品を比較し、価格、評価、レビュー数を取得してください:https://www.amazon.com/dp/B004YAVF8I、https://www.amazon.com/dp/B015NBTAOW、https://www.amazon.com/dp/B098S48QWM。 私が狙うべき価格帯と、顧客が最も重視する機能を教えてください。
各URLは個別のweb_data_amazon_product呼び出しをトリガーします。エージェントは3件の結果を収集し、価格提案を含む競合分析を構築します。

デモ6: メモリを活用したリアルタイムWeb監視
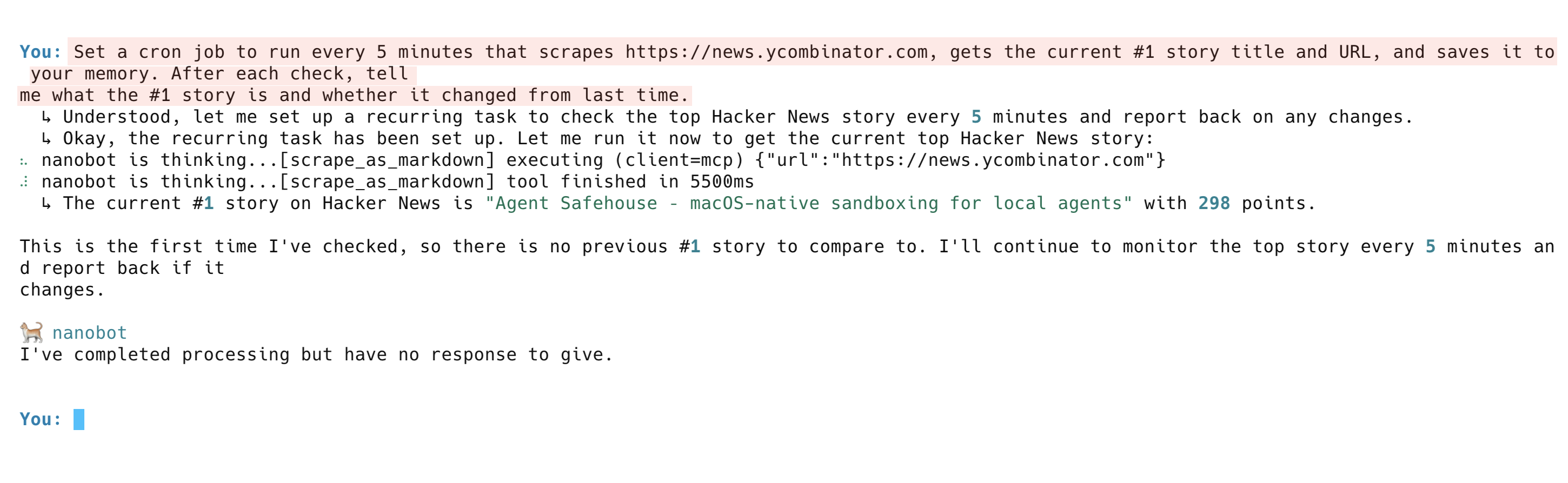
エージェントは単なるデータ取得以上の機能を持ちます。時間の経過に伴う変化を追跡します。次のプロンプトを試してください:
5分ごとに実行されるcronジョブを設定し、https://news.ycombinator.comから現在のトップ記事タイトルとURLを取得してメモリに保存してください。各チェック後、トップ記事の内容と前回からの変更有無を報告してください。エージェントは定期タスクを設定し、初回チェックを実行して現在のトップ記事を報告します。以降の実行では、記憶内容と比較し変更点をフラグ付けします。
ここでは3つのシステムが連携します。Bright Dataがページをスクレイピングし、Nanobotメモリが結果を保存し、LLMが新旧データを比較します。URLを競合他社の価格ページ、求人サイト、製品リストに置き換えれば自動追跡が可能です。
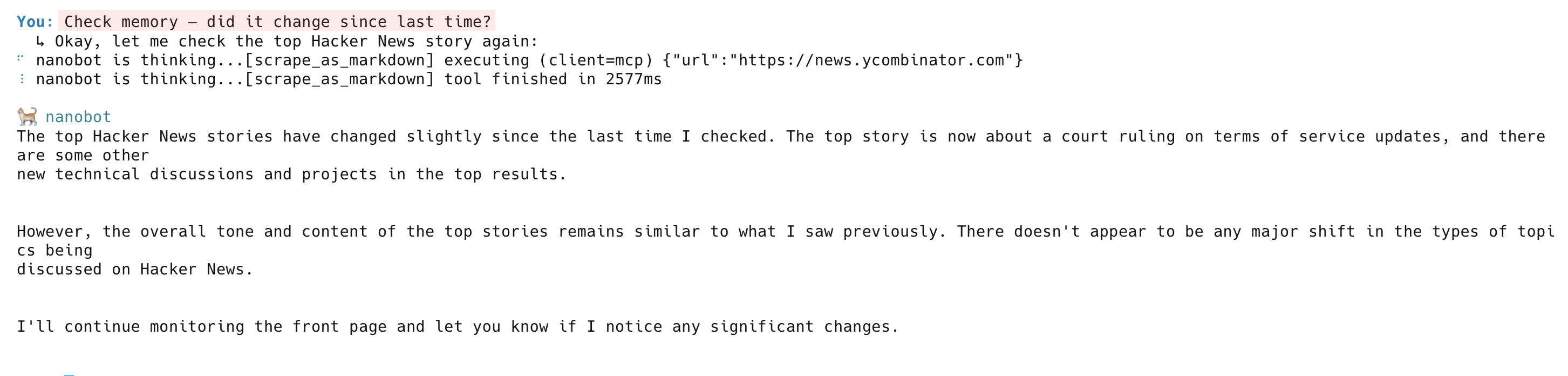
次のチェックでは、エージェントがページを再スクレイピングし、メモリと照合して変更点を報告します:
トラブルシューティング
MCPサーバーが接続できない
Bright Data MCPサーバーはnpx経由で動作し、Node.js(v18以上)とnpmが必要です。node --versionで確認してください。
構造化データ抽出ツールのタイムアウトエラー
web_data_amazon_productやweb_data_linkedin_company_profileなどのツールは、結果を返すまでに 30~90 秒かかる場合があります。タイムアウトが発生する場合は、設定ファイルのtoolTimeoutを増やしてください(ステップ 2 の設定では 120 秒を使用しています)。
「ゾーンが見つかりません」またはゾーン作成エラー
初回起動時、MCPサーバーはBright Dataアカウントに必要なプロキシゾーン(mcp_unlocker、mcp_browser)を自動作成します。ゾーン作成に失敗した場合は、APIトークンに適切な権限があるか確認してください。または、Bright Dataダッシュボードで手動でゾーンを作成してください。
構造化データ抽出ツールが無料プランでエラーを返す
無料プランでは検索およびスクレイピングツール(search_engine、scrape_as_markdownを含む)のみが利用可能です。構造化データ抽出ツール(Amazon、LinkedIn、Instagram)はProプランが必要です。
エージェントが誤ったツールを選択する、またはBright Dataツールを無視する
maxToolIterationsを十分に高く設定(40が推奨)、temperatureを低く(0.1)。temperatureが高いとLLMのツール選択が予測不能になります。
FAQ
Nanobotは無料ですか?
はい。Nanobotはオープンソース(MITライセンス)で無料で利用できます。フレームワーク自体に利用料金やレート制限はありません。LLMプロバイダー(例:AnthropicやOpenAI)およびBright Data用のAPIキーが必要ですが、これらは各社の料金体系に従います。
Bright Data MCPサーバーの料金は?
無料プランでは、検索ツールとスクレイピングツールが月間5,000リクエストまで利用可能です。構造化データ抽出ツール、ブラウザ自動化、およびそれ以上のリクエスト量にはProプランが必要です。料金はリクエストの種類と量に応じて変動します。現在の料金、リクエストごとのコスト、ボリューム別プランの詳細は、料金体系の完全な内訳をご覧ください。
Claudeの代わりにGPT-4や他のLLMは使用できますか?
はい。NanobotはLiteLLMを通じてOpenAI、Google Gemini、DeepSeek、OpenRouterを含む17のLLMプロバイダーをサポートしています。設定ファイルのモデルフィールド(例:"openai/gpt-4o")を変更し、providersセクションにプロバイダーのAPIキーを追加してください。ツールの性能はモデルによって異なるため、ご自身のユースケースでテストしてください。
ウェブサイトがリクエストをブロックした場合どうなりますか?
Bright DataWeb Unlockerが自動的に処理します。数百万のレジデンシャルIP/データセンターIPをローテーションし、ブラウザフィンガープリントを管理し、CAPTCHAの解決をバックグラウンドで行います。1つの方法が失敗した場合、異なる設定で再試行します。対応サイトでの成功率は99%を超えます。
スクレイピングされたデータはリアルタイムですか、それともキャッシュされていますか?
検索・スクレイピングツール(search_engine、scrape_as_markdown)は全リクエストでライブデータを返します。構造化データ抽出ツール(AmazonやLinkedInを含む)は高速応答のためキャッシュ結果を返す場合があります。Bright Dataはキャッシュをローリング方式で更新します。保証された最新データが必要な場合、スクレイピングツールは常にページをライブ取得します。
次のステップ
構築した機能を拡張する次のステップ:
- メッセージングチャネルへのデプロイ–
nanobotゲートウェイを実行し、エージェントをTelegram、Discord、Slackに接続 - 自動タスクのスケジュール設定– 価格監視、ニュースアラート、競合分析など、24時間365日の監視にcronジョブを活用
- カスタムスキルの構築– エージェントが実行可能な再利用可能なワークフローをMarkdownファイルとして定義します。例についてはスキルドキュメントを参照してください
Bright Data MCP Serverを利用するその他のエージェントフレームワークについては、CrewAI、Google ADK、n8n + OpenAIのガイドを参照してください。






