

このガイドでは、n8n、OpenAI、Bright Data MCP Serverを使って自動ニューススクレーパーを構築する方法を学びます。このチュートリアルの終わりには、以下のことができるようになります。
- セルフホストn8nインスタンスを作成する
- n8nにコミュニティ・ノードをインストールする
- n8nで独自のワークフローを構築する
- OpenAIとn8nを使ったAIエージェントの統合
- Bright DataのMCPサーバーを使用して、AIエージェントをWeb Unlockerに接続します。
- n8nを使った自動メール送信
はじめに
開始するには、n8nのセルフホストインスタンスを起動する必要があります。起動したら、n8n Community Nodeをインストールする必要がある。また、スクレイピングのワークフローを実行するために、OpenAIとBright DataからAPIキーを取得する必要がある。
n8nの立ち上げ
n8n用に新しいストレージボリュームを作成し、Dockerコンテナで起動する。
# Create persistent volume
sudo docker volume create n8n_data
# Start self-hosted n8n container with support for unsigned community nodes
sudo docker run -d
--name n8n
-p 5678:5678
-v n8n_data:/home/node/.n8n
-e N8N_BASIC_AUTH_ACTIVE=false
-e N8N_ENCRYPTION_KEY="this_is_my_secure_encryption_key_1234"
-e N8N_ALLOW_LOADING_UNSIGNED_NODES=true
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
-e N8N_HOST="0.0.0.0"
-e N8N_PORT=5678
-e WEBHOOK_URL="http://localhost:5678"
n8nio/n8nブラウザでhttp://localhost:5678/。サインインまたはログインのプロンプトが表示されます。

ログイン後、設定から “コミュニティ・ノード “を選択してください。そして、”コミュニティノードをインストールする “というタイトルのボタンをクリックしてください。

npm Package Name “に “n8n-nodes-mcp “と入力します。

APIキーの取得
OpenAI APIキーとBright Data APIキーの両方が必要です。OpenAIキーにより、n8nインスタンスはGPT-4.1のようなLLMにアクセスできます。Bright Data APIキーにより、LLMはBright DataのMCPサーバーを通してリアルタイムのウェブデータにアクセスできます。
OpenAI APIキー
OpenAIの開発者プラットフォームへ行き、アカウントを作成してください。API keys “を選択し、”Create new secret key “というタイトルのボタンをクリックします。キーを安全な場所に保存します。

ブライトデータAPIキー
すでにブライトデータのアカウントをお持ちかもしれません。その場合でも、新しいWeb Unlockerゾーンを作成してください。Bright Dataのダッシュボードから “Proxies and Scraping “を選択し、”Add “ボタンをクリックします。

他のゾーン名を使用することもできますが、このゾーンには “mcp_unlocker “という名前を付けることを強くお勧めします。この名前にすることで、MCPサーバーとすぐに連携できるようになります。
アカウント設定でAPIキーをコピーし、安全な場所に保管してください。このキーでBright Dataのすべてのサービスにアクセスできます。

n8nのセルフホスト・インスタンスと適切な認証情報を手に入れたので、ワークフローを構築しよう。
ワークフローの構築

それでは、実際にワークフローを作成していきます。新しいワークフローを作成」ボタンをクリックする。これで真っ白なキャンバスが出来上がります。
1.トリガーを作る

まず、新しいノードを作成します。検索バーで “chat “と入力し、”Chat Trigger “ノードを選択します。

チャットトリガーは恒久的なトリガーにはなりませんが、デバッグが非常に簡単になります。AIエージェントはプロンプトを受け取ります。チャットトリガーノードがあれば、ノードを編集することなく、簡単に様々なプロンプトを試すことができます。
2.エージェントの追加
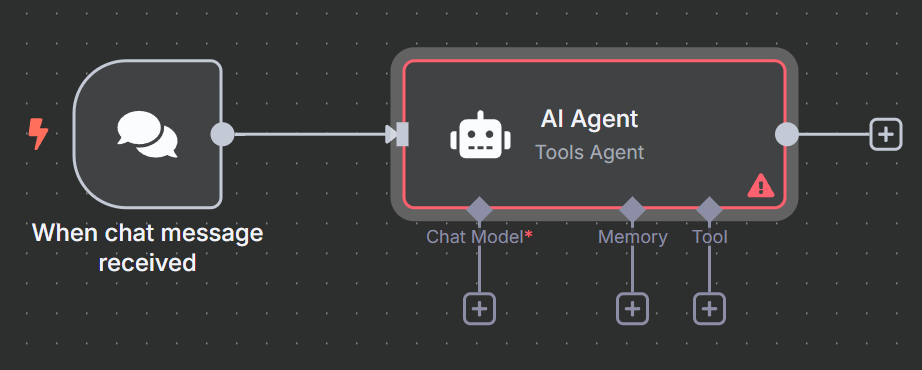
次に、トリガー・ノードをAIエージェントに接続する必要があります。別のノードを追加し、検索バーに “ai agent “と入力します。AI Agentノードを選択します。

このAIエージェントは、基本的に我々のランタイム全体を含んでいる。エージェントはプロンプトを受信し、スクレイピングロジックを実行します。以下にプロンプトを示します。チャットトリガーを追加したのはそのためです。以下のスニペットには、このワークフローで使用するプロンプトが含まれています。
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.3.モデルの接続

チャットモデル “の下にある “+”をクリックし、検索バーに “openai “と入力します。OpenAIのチャットモデルを選択します。

クレデンシャルを追加するプロンプトが表示されたら、OpenAI API キーを追加し、クレデンシャルを保存します。

次に、モデルを選択する必要がある。様々なモデルから選ぶことができるが、これは一人のエージェントのための複雑なワークフローであることを覚えておいてほしい。GPT-4oでは、限られた成功しか得られなかった。GPT-4.1-NanoとGPT-4.1-Miniはどちらも不十分であることがわかった。GPT-4.1のフルモデルはより高価だが、信じられないほど有能であることがわかった。

4.メモリの追加

コンテキスト・ウィンドウを管理するには、メモリを追加する必要がある。複雑なものは必要ない。シンプルなメモリーのセットアップが必要なだけだ。
モデルにメモリーを持たせるには、「シンプルメモリー」を選びます。
5.Bright DataのMCPへの接続

ウェブを検索するには、Bright DataのMCPサーバーに接続する必要があります。Tool “の下にある “+”をクリックし、”Other Tools “セクションの一番上に表示されるMCP Clientを選択します。

プロンプトが表示されたら、Bright Data MCPサーバーの認証情報を入力します。Command “ボックスにnpxと入力し、NodeJSが自動的にMCPサーバーを作成し実行するようにします。Arguments” の下に@brightdata/mcp を追加します。Environments “に、API_TOKEN=YOUR_BRIGHT_DATA_API_KEY(これを実際のキーに置き換えてください)と入力します。

このツールのデフォルト・メソッドは “リスト・ツール “だ。これこそ、私たちがやるべきことだ。あなたのモデルが接続できれば、MCPサーバーにpingを打ち、利用可能なツールをリストアップします。

準備ができたら、チャットにプロンプトを入力します。利用可能なツールをリストアップするよう求めるシンプルなものを使用してください。
List the tools available to youモデルで使用可能なツールのリストが表示されるはずです。この場合、MCPサーバーに接続されています。以下のスニペットは、応答の一部のみを含んでいます。モデルで使用可能なツールは全部で21個あります。
Here are the tools available to me:
1. search_engine – Search Google, Bing, or Yandex and return results in markdown (URL, title, description).
2. scrape_as_markdown – Scrape any webpage and return results as Markdown.
3. scrape_as_html – Scrape any webpage and return results as HTML.
4. session_stats – Show the usage statistics for tools in this session.
5. web_data_amazon_product – Retrieve structured Amazon product data (using a product URL).6.スクレイピングツールの追加

ツール」の下にある「+」をもう一度クリックします。もう一度、「その他のツール」から同じ「MCPクライアント・ツール」を選択します。

今回は、”Execute Tool” を使うように設定する。

ツール名」の下に、以下のJavaScript式を貼り付ける。fromAI “関数を呼び出し、toolname、description、datatypeを渡す。
{{ $fromAI("toolname", "the most applicable tool required to be executed as specified by the users request and list of tools available", "string") }}パラメーターの下に以下のブロックを追加する。これは、お好みの検索エンジンと一緒にモデルへのクエリを与えます。
{
"query": "Return the top 5 world news headlines and their links."
,
"engine": "google"
}次に、AIエージェント自体のパラメータを調整する。以下のシステムメッセージを追加します。
You are an expert web scraping assistant with access to Bright Data's Web Unlocker API. This gives you the ability to execute a specific set of actions. When using tools, you must share across the exact name of the tool for it to be executed.
For example, "Search Engine Scraping" should be "search_engine"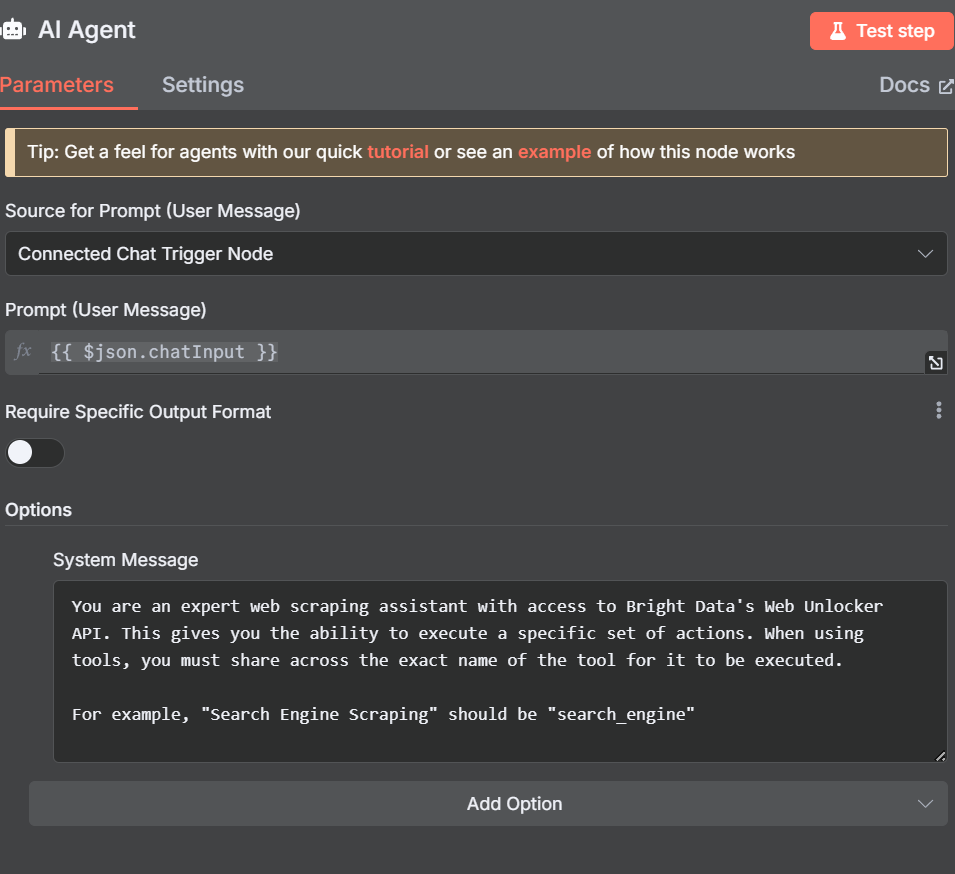
スクレイパーを実際に実行する前に、リトライをオンにする必要がある。AIエージェントは賢いが、完璧ではない。ジョブが失敗することもあり、それを処理する必要がある。手動でコード化されたスクレーパーのように、一貫して動作する製品を望むのであれば、リトライ・ロジックはオプションではない。

以下のプロンプトを実行してください。
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.すべてがうまくいっていれば、以下のような応答が返ってくるはずだ。
Here are real global news headlines for today, each with a direct source link:
1. Reuters
Headline: Houthi ceasefire followed US intel showing militants sought off-ramp
Source: https://www.reuters.com/world/
2. CNN
Headline: UK police arrest man for arson after fire at PM Starmer's house
Source: https://www.cnn.com/world
3. BBC
Headline: Uruguay's José Mujica, world's 'poorest president', dies
Source: https://www.bbc.com/news/world
4. AP News
Headline: Israel-Hamas war, Russia-Ukraine War, China, Asia Pacific, Latin America, Europe, Africa (multiple global crises)
Source: https://apnews.com/world-news
5. The Guardian
Headline: Fowl play: flying duck caught in Swiss speed trap believed to be repeat offender
Source: https://www.theguardian.com/world
These headlines were selected from the main headlines of each trusted global news outlet’s world section as of today.7.始まりと終わり

AIエージェントが仕事をするようになったので、ワークフローの開始と終了を追加する必要がある。ニューススクレーパーは、個々のプロンプトではなく、スケジューラから動作する必要があります。最後に、出力はSMTPを使ってメールを送信する。
適切なトリガーを加える
Schedule Trigger “ノードを探し、ワークフローに追加します。

好きな時間にトリガーするように設定する。私たちは午前9時を選んだ。

さて、トリガーロジックにもう一つノードを追加する必要があります。このノードは、ダミーのプロンプトをチャットモデルに注入します。
Edit Fields” ノードをスケジュールトリガーに追加します。

編集フィールドノードにJSONとして以下を追加します。”sessionId “は単なるダミーの値で、sessionIdなしではチャットを開始できません。”chatInput “はLLMに注入するプロンプトを保持します。
{
"sessionId": "google",
"chatInput": "Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite."
}最後に、これらの新しいステップをAIエージェントに接続します。これでエージェントはスケジューラによってトリガーされるようになります。

結果をメールで出力する
AIエージェントノードの右側にある「+」をクリックします。ワークフローの最後に “メール送信 “ノードを追加します。SMTP認証情報を追加し、パラメータを使用してメールをカスタマイズします。

電子メール
ワークフローのテスト」ボタンをクリックしてください。ワークフローが正常に実行されると、現在のすべての見出しが記載されたメールが届きます。GPT-4.1

もっと先へ:実際のウェブサイトのスクレイピング
現在の状態では、AIエージェントはMCPサーバーの検索エンジンツールを使ってGoogleニュースからヘッドラインを見つけます。検索エンジンのみを使用しているため、結果に一貫性がないことがあります。AIエージェントが本物のヘッドラインを見つけることもあります。また、“CNNから最新のヘッドラインを入手!”といったサイトのメタデータしか表示されないこともあります。
抽出を検索エンジン・ツールに限定する代わりに、スクレイピング・ツールを追加してみよう。ワークフローに別のツールを追加することから始めます。下の画像のように、AIエージェントに3つのMCPクライアントが接続されているはずです。
スクレイピング・ツールの追加

さて、この新しいツールの設定とパラメーターを開く必要がある。今回、「ツールの説明」を手動で設定したことに注目してください。これはエージェントが混乱しないようにするためです。
説明では、AIエージェントにこのツールを使ってURLをスクレイピングするように伝えます。ツール名は先ほど作成したものと同様です。
{{ $fromAI("toolname", "the most applicable scraping tool required to be executed as specified by the users request and list of tools available", "string") }}パラメータでは、クエリーや検索エンジンの代わりにurlを指定します。
{
"url": "{{$fromAI('URL', 'url that the user would like to scrape', 'string')}}"
}他のノードとツールの調整
検索エンジンツール
スクレイピングツールでは、AIエージェントが混乱しないように説明文を手動で設定します。検索エンジンツールも調整します。このMCPクライアントを実行するときに、検索エンジンツールを使用するように手動で指示するだけです。

フィールドを編集するダミープロンプト
Edit Fieldsノードを開き、ダミーのプロンプトを調整する。
{
"sessionId": "google",
"chatInput": "get the latest news from https://www.brightdata.com/blog and https://www.theguardian.com/us with your scrape_as_markdown and Google News with your search engine tool to find the latest global headlines--pull actual headlines, not just the site description."
}パラメータは下の画像のようになるはずです。

当初はガーディアンの代わりにRedditを使っていました。しかし、OpenAIのLLMはrobots.txtファイルに従います。Redditは簡単にスクレイピングできるにもかかわらず、AIエージェントはそれを拒否する。

新しいキュレーション・フィード
別のツールを追加することで、検索エンジンの結果だけでなく、実際にウェブサイトをスクレイピングする力をAIエージェントに与えました。下のメールを見てください。各ソースからのニュースの非常に詳細な内訳を持つ、よりクリーンなフォーマットになっています。

結論
n8n、OpenAI、Bright DataのMCP(Model Context Protocol)サーバーを組み合わせることで、強力なAI主導のワークフローでニュースのスクレイピングと配信を自動化することができます。MCPによって、最新の構造化されたウェブデータにリアルタイムで簡単にアクセスできるようになり、AIエージェントがあらゆるソースから正確なコンテンツを引き出せるようになります。AIの自動化が進化するにつれ、ブライトデータのMCPのようなツールは、効率的でスケーラブルかつ信頼性の高いデータ収集に不可欠なものとなるでしょう。
Bright Dataでは、MCPサーバーを使ったウェブスクレイピングについての記事を読むことをお勧めしています。今すぐサインアップして無料クレジットを入手し、弊社製品をお試しください。






