

このガイドでは、PythonでローカルのMCPサーバーを構築し、Amazonの商品データをオンデマンドでスクレイピングする方法を説明します。MCPの基礎、独自のサーバーの書き方と実行方法、Claude DesktopやCursor IDEのような開発者ツールとの接続方法を学びます。最後に、リアルタイムのAI対応ウェブデータのための、実際のBright Data MCPインテグレーションを紹介します。
さあ、飛び込もう。
ボトルネックなぜLLMは実社会との交流に苦労するのか(そしてMCPがそれを解決する方法)
大規模言語モデル(LLM)は、膨大な学習データセットからテキストを処理・生成する上で非常に強力です。しかし、LLMには重要な制限事項があります。つまり、ローカルファイルへのアクセスも、カスタムスクリプトの実行も、ウェブからのライブデータの取得もできません。
簡単な例を挙げよう。クロードにアマゾンのライブページから商品の詳細を引き出すように頼んでも、それはできない。なぜか?クロードにはウェブをブラウズしたり、外部アクションをトリガーしたりする機能が組み込まれていないからです。

外部ツールなしでは、LLMはリアルタイムデータや外部システムとの統合に依存する実用的なタスクを実行できない。
そこでAnthropicのモデルコンテキストプロトコル(MCP)の登場です。これにより、LLMはスクレイパーやAPI、スクリプトのような外部ツールと安全かつ標準化された方法で会話することができます。
その違いを実際に見てみましょう。カスタムMCPサーバーを統合した後、構造化されたAmazon商品データをClaudeを通して直接抽出することができました:

仕組みについてはまだ心配しないでください。ガイドの後半で順を追って説明します。
なぜMCPが重要なのか?
- 標準化:MCPは、LLMベースのシステムが外部のツールやデータと接続するための標準化されたインターフェイスを提供した。これにより、カスタム統合の必要性が大幅に減少し、開発のスピードが向上しました。
- 柔軟性と拡張性:開発者は、ツールの統合を書き換えることなく、LLMやホスティングプラットフォームを交換することができます。MCPは複数の通信トランスポート(
stdioなど)をサポートしているため、さまざまなセットアップに対応できます。 - LLM機能の強化:LLMをライブデータと外部ツールに接続することで、MCPはLLMが静的なレスポンスを超えることを可能にする。現在、LLMは最新の関連情報を返し、コンテキストに基づいて実際のアクションを引き起こすことができます。
例え:MCPは、LLMのためのUSBインターフェイスだと考えてください。USBが様々なデバイス(キーボード、プリンタ、外付けドライブ)を特別なドライバを必要とせずに互換性のあるマシンに接続できるように、MCPはLLMが標準化されたプロトコルを使用して様々なツールに接続できるようにします。
モデル・コンテキスト・プロトコル(MCP)とは?
モデルコンテキストプロトコル(MCP)は、Anthropicによって開発されたオープンスタンダードで、大規模言語モデル(LLM)が一貫性のある安全な方法で外部ツール、API、データソースとやり取りできるようにします。MCPはユニバーサルコネクターとして機能し、LLMがウェブサイトのスクレイピング、データベースへのクエリ、スクリプトのトリガーのような実世界のタスクを実行することを可能にします。
AnthropicはMCPを導入したが、MCPはオープンで拡張可能である。もしあなたがRAG(Retrieval-Augmented Generation)を使ったことがあれば、このコンセプトを理解できるだろう。MCPは、軽量なJSON-RPCインターフェイスを通じてインタラクションを標準化することで、モデルがライブデータにアクセスしてアクションを起こせるようにすることで、そのアイデアを構築している。
MCPアーキテクチャ仕組み
MCPの核心は、AIモデルと外部機能との間のコミュニケーションを標準化することである。
核となる考え方標準化されたインターフェイス(通常はstdioのようなトランスポート上のJSON-RPC 2.0)によって、LLMは(クライアントを介して)外部サーバーによって公開されたツールを発見し、呼び出すことができます。
MCPは、3つの主要なコンポーネントを持つクライアント・サーバー・アーキテクチャーによって運営されている:
- MCPホスト:LLMと外部ツール間のインタラクションを開始し、管理する環境またはアプリケーション。例えば、Claude DesktopのようなAIアシスタントやCursorのようなIDEなど。
- MCPクライアント:ホスト内のコンポーネントで、MCPサーバとの接続を確立および維持し、通信プロトコルを処理し、データ交換を管理する。
- MCPサーバー:MCPプロトコルを実装し、特定の機能を公開するプログラム(開発者が作成)。MCPサーバーは、データベースやウェブサービス、あるいは私たちの場合はウェブサイト(Amazon)と連携します。サーバは標準化された方法でその機能を公開
します。
これがMCPのアーキテクチャ図だ:

画像ソースモデル・コンテキスト・プロトコル
このセットアップでは、ホスト(Claude DesktopまたはCursor IDE)がMCPクライアントを起動し、MCPクライアントは外部のMCPサーバーに接続します。サーバーはツール、リソース、プロンプトを公開し、AIが必要に応じてそれらと対話できるようにします。
要するに、ワークフローは以下のように動作する:
- ユーザーは“このアマゾンのリンクから商品情報を取得する “というようなメッセージを送る。
- MCPクライアントは、そのタスクを処理できる登録済みのツールをチェックします。
- クライアントはMCPサーバーに構造化されたリクエストを送信する。
- MCPサーバーが適切なアクションを実行(例:ヘッドレス・ブラウザの起動)
- サーバは構造化された結果をMCPクライアントに返す。
- クライアントは結果をLLMに転送し、LLMは結果をユーザーに提示する。
カスタムMCPサーバーの構築
Amazonの商品ページをスクレイピングするPython MCPサーバーを構築してみよう。

このサーバーは、HTMLをダウンロードするツールと、構造化された情報を抽出するツールの2つを公開する。CursorまたはClaude DesktopのLLMクライアントを介してサーバーとやりとりすることになる。
ステップ1:環境設定
まず、Python 3がインストールされていることを確認してください。次に、仮想環境を作成してアクティブにします:
python -m venv mcp-amazon-scraper
# On macOS/Linux:
source mcp-amazon-scraper/bin/activate
# On Windows:
.mcp-amazon-scraperScriptsactivate必要なライブラリ(MCP Python SDK、Playwright、LXML)をインストールします。
pip install mcp playwright lxml
# Install browser binaries for Playwright
python -m playwright installこれはインストールする:
- mcp:すべてのJSON-RPC通信の詳細を処理するモデルコンテキストプロトコルサーバとクライアントのためのPython SDK
- playwright:JavaScriptを多用するウェブサイトのレンダリングとスクレイピングのためのヘッドレスブラウザ機能を提供するブラウザ自動化ライブラリ
- lxml:高速な XML/HTML 解析ライブラリ。XPath クエリを使ってウェブページから特定のデータ要素を簡単に抽出できる。
要するに、MCP Python SDK(mcp)はプロトコルの詳細をすべて処理し、ClaudeやCursorが自然言語のプロンプトで呼び出せるツールを公開できる。Playwrightはウェブページを完全に(JavaScriptコンテンツを含めて)レンダリングできるようにし、lxmlは強力なHTMLパース機能を提供する。
ステップ2:MCPサーバーの初期化
amazon_scraper_mcp.py という Python ファイルを作成します。必要なモジュールをインポートし、FastMCPサーバを初期化します:
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")これでMCPサーバーのインスタンスが作成されます。これからツールを追加します。
ステップ3:fetch_pageツールの実装
このツールは、URLを入力として受け取り、Playwrightを使ってページに移動し、コンテンツがロードされるのを待ち、HTMLをダウンロードし、一時ファイルに保存する。
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_messageこの非同期関数は、Playwrightを使用してAmazonページのJavaScriptレンダリングの可能性を処理します。mcp.tool()デコレータは、この関数をサーバ内で呼び出し可能なツールとして登録します。
ステップ4:extract_infoツールの実装
このツールは、fetch_pageによって保存されたHTMLファイルを読み込み、LXMLとXPathセレクタを使って解析し、抽出された商品詳細を含む辞書を返します。
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}この関数は、LXMLのfromstringを使ってHTMLを解析し、ロバストなXPathセレクタを使って目的の要素を見つけます。
ステップ5:サーバーの実行
最後に、以下の行をamazon_scraper_mcp.pyスクリプトの最後に追加して、Claude DesktopやCursorのようなクライアントと通信するローカルMCPサーバの標準であるstdioトランスポートメカニズムを使用してサーバを起動します。
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")完全なコード(amazon_scraper_mcp.py)
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")カスタムMCPサーバーの統合
サーバースクリプトの準備ができたので、Claude DesktopやCursorなどのMCPクライアントに接続してみましょう。
クロードデスクトップへの接続
ステップ 1:クロードデスクトップを開く。
ステップ2: 設定->開発者->設定を編集に移動します。デフォルトのテキストエディタでclaude_desktop_config.jsonファイルを開きます。

ステップ 3: mcpServersキーの下にサーバのエントリを追加します。argsのパスをamazon_scraper_mcp.pyファイルの絶対パスに置き換えてください。
{
"mcpServers": {
"amazon_product_scraper": {
"command": "python", // Or python3 if needed
"args": ["/full/path/to/your/amazon_scraper_mcp.py"], // <-- IMPORTANT: Use the correct absolute path
}
}
}ステップ4: claude_desktop_config.jsonファイルを保存し、変更を有効にするためにClaude Desktopを完全に終了して再度開きます。
ステップ 5:クロードデスクトップで、チャット入力エリアに小さなツールアイコン(ハンマー🔨のようなもの)が表示されているはずです。
ステップ6:クリックすると、「Amazon Product Scraper」とそのfetch_pageツール、extract_infoツールが表示されます。

ステップ7:例えば、プロンプトを送信する:「このアマゾンの商品の現在の価格、元の価格、評価を取得します: https://www.amazon.com/dp/B09C13PZX7″。
ステップ 8:Claudeは外部ツールを必要とすることを検知し、まずfetch_pageを実行し、次にextract_infoを実行する許可を求めます。それぞれのツールの “Allow for this chat “をクリックしてください。

ステップ9:許可を与えた後、MCPサーバーはツールを実行する。クロードは構造化データを受信し、チャットに表示する。

🔥 素晴らしい、最初のMCPサーバーの構築と統合に成功しました!
カーソルへの接続
Cursor(AIファーストのIDE)のプロセスも同様だ。
ステップ1:カーソルを開く。
ステップ2: Settings(設定)⚙️、MCPセクションに移動する。

ステップ3:「+新しいグローバルMCPサーバーを追加」をクリックします。mcp.json構成ファイルが開きます。スクリプトの絶対パスを使用して、サーバーのエントリーを追加します。
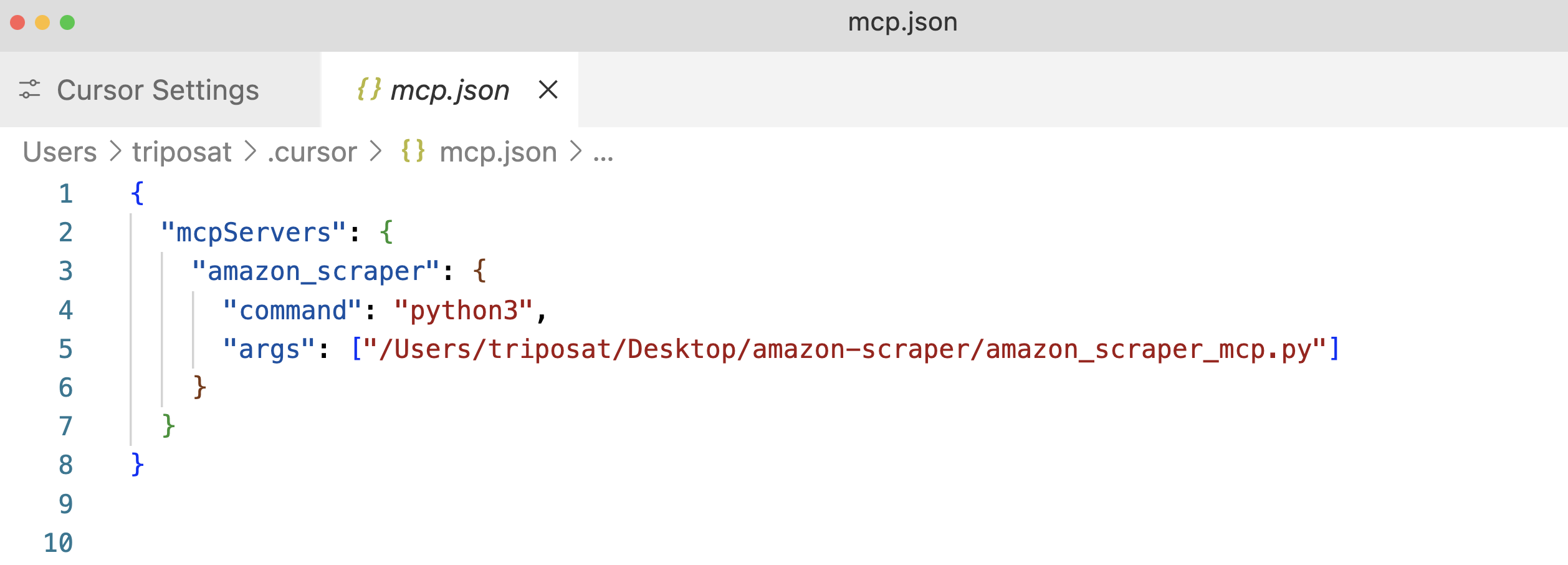
ステップ4: mcp.jsonファイルを保存すると、”amazon_product_scraper “がリストアップされ、うまくいけば緑色のドットで実行中と接続中であることを示すはずです。

ステップ5:カーソルのチャット機能(Cmd+lまたはCtrl+l)を使う。
ステップ6:例えば、プロンプトを送信する:「このAmazon URLから利用可能なすべての商品データを抽出します: https://www.amazon.com/dp/B09C13PZX7。構造化されたJSONオブジェクトとして出力をフォーマットしてください。
ステップ 7:Claude Desktop と同様に、Cursor はfetch_pageとextract_infoツールの実行許可を要求します。これらの要求を承認してください (“Run Tool”)。
ステップ8:カーソルはインタラクション・フローを表示し、MCPツールへの呼び出しを表示し、最後にextract_infoツールから返された構造化JSONデータを表示します。

以下は、CursorからのJSON出力の例である:
{
"title": "Razer Basilisk V3 Customizable Ergonomic Gaming Mouse: Fastest Gaming Mouse Switch - Chroma RGB Lighting - 26K DPI Optical Sensor - 11 Programmable Buttons - HyperScroll Tilt Wheel - Classic Black",
"price": 39.99,
"original_price": 69.99,
"discount_percent": 43,
"rating_stars": 4.6,
"review_count": 7782,
"features": [
"ICONIC ERGONOMIC DESIGN WITH THUMB REST — PC gaming mouse favored by millions worldwide with a form factor that perfectly supports the hand while its buttons are optimally positioned for quick and easy access",
"11 PROGRAMMABLE BUTTONS — Assign macros and secondary functions across 11 programmable buttons to execute essential actions like push-to-talk, ping, and more",
"HYPERSCROLL TILT WHEEL — Speed through content with a scroll wheel that free-spins until its stopped or switch to tactile mode for more precision and satisfying feedback that's ideal for cycling through weapons or skills",
"11 RAZER CHROMA RGB LIGHTING ZONES — Customize each zone from over 16.8 million colors and countless lighting effects, all while it reacts dynamically with over 150 Chroma integrated games",
"OPTICAL MOUSE SWITCHES GEN 2 — With zero unintended misclicks these switches provide crisp, responsive execution at a blistering 0.2ms actuation speed for up to 70 million clicks",
"FOCUS+ 26K DPI OPTICAL SENSOR — Best-in-class mouse sensor with intelligent functions flawlessly tracks movement with zero smoothing, allowing for crisp response and pixel-precise accuracy",
// ... (other features)
],
"availability": "In Stock"
}これはMCPの柔軟性を示すもので、同じサーバーが異なるクライアント・アプリケーションとシームレスに動作する。
ブライトデータのMCPを統合してAI主導のウェブデータ抽出を実現
カスタムMCPサーバーは完全な制御を提供しますが、プロキシインフラストラクチャの管理、高度なアンチボットメカニズムの処理、スケーラビリティの確保などの課題を伴います。Bright Dataは、AIエージェントやLLMとシームレスに統合できるように設計された、プロダクショングレードの事前構築済みMCPソリューションでこれらの問題に対処します。
Bright Dataとのモデルコンテキストプロトコル(MCP)の統合は、LLMとAIエージェントに、AIワークフローに合わせた公開ウェブデータへのシームレスなリアルタイムアクセスを提供します。Bright DataのMCPに接続することで、アプリやモデルはすべての主要な検索エンジンからSERP結果を取得し、アクセスしにくいウェブサイトへのアクセスをシームレスに解除することができます。
Bright Dataのモデルコンテキストプロトコル(MCP)ソリューションは、Web Unlocker、SERP API、Web Scraper API、Scraping Browserなどの強力なWebデータ抽出ツール群にお客様のアプリケーションを接続し、以下のような包括的なインフラを提供します:
- AIに適したデータを提供ウェブコンテンツを自動的に取得・整形し、余分な前処理ステップを削減します。
- スケーラビリティと信頼性を確保:堅牢なインフラストラクチャを活用し、パフォーマンスを損なうことなく大量のリクエストを処理します。
- ブロックとCAPTCHAをバイパスします:高度なアンチボット戦略を使用して、最も保護されたWebサイトでもナビゲートし、コンテンツを取得します。
- グローバルIPカバレッジを提供します:195カ国にまたがる広大なプロキシネットワークを使用して、地域制限のあるコンテンツにアクセスします。
- 統合を簡素化:あらゆるMCPクライアントとシームレスに動作することで、設定の手間を最小限に抑えます。
Bright Data MCPの前提条件
Bright Data MCPの統合を開始する前に、以下を確認してください:
- ブライトデータのアカウント: brightdata.comからサインアップしてください。新規ユーザーにはテスト用の無料クレジットを差し上げます。
- APIトークン:ブライトデータのアカウント設定(ユーザー設定ページ)からAPIトークンを取得します。
- Web Unlockerゾーン:Bright DataコントロールパネルにWeb Unlockerプロキシゾーンを作成します。
mcp_unlocker のような覚えやすい名前を付けてください(必要であれば、後で環境変数で上書きできます)。 - (オプション)スクレイピング・ブラウザ・ゾーン:高度なブラウザ自動化機能(複雑なJavaScriptインタラクションやスクリーンショットなど)が必要な場合は、スクレイピング・ブラウザ・ゾーンを作成してください。このゾーン(「概要」タブ内)に提供される認証詳細(ユーザー名とパスワード)に注意してください(通常、
brd-customer-ACCOUNT_ID-zone-Zone_NAME:PASSWORDの形式)。
クイックスタートBright Data MCP for Claude Desktopの設定
ステップ1:Bright Data MCPサーバーは通常、Node.jsに付属するnpxを使用して実行されます。公式ウェブサイトからNode.jsをインストールしてください。
ステップ 2:Claude Desktop ->Settings->Developer->Edit Config(claude_desktop_config.json) を開きます。
ステップ 3:Bright Data サーバー設定をmcpServers の下に追加します。プレースホルダーを実際の認証情報で置き換えます。
{
"mcpServers": {
"Bright Data": { // Choose a name for the server
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_TOKEN", // Paste your API token here
"WEB_UNLOCKER_ZONE": "mcp_unlocker", // Your Web Unlocker zone name
// Optional: Add if using Scraping Browser tools
"BROWSER_AUTH": "brd-customer-ACCOUNTID-zone-YOURZONE:PASSWORD"
}
}
}
}ステップ 4:設定ファイルを保存し、Claude Desktop を再起動します。
ステップ 5:クロードデスクトップのハンマーアイコン(🔨)にカーソルを合わせます。複数のMCPツールが表示されます。

スクレイパーをブロックする可能性のあるサイトとして知られているZillowからデータを抽出してみよう。claude に “Extract key property data in JSON format from this Zillow URL:https://www.zillow.com/apartments/arverne-ny/the-tides-at-arverne-by-the-sea/ChWHPZ/” と促す。

クロードが必要な Bright Data MCP ツールを使用できるようにします。Bright DataのMCPサーバーは、基礎となる複雑な処理(プロキシローテーション、必要に応じてスクレイピングブラウザ経由のJavaScriptレンダリング)を行います。
ブライト・データのサーバーが抽出を行い、構造化されたデータを返す。

以下は、潜在的な出力の断片である:
{
"propertyInfo": {
"name": "The Tides At Arverne By The Sea",
"address": "190 Beach 69th St, Arverne, NY 11692",
"propertyType": "Apartment building",
// ... more info
},
"rentPrices": {
"studio": { "startingPrice": "$2,750", /* ... */ },
"oneBed": { "startingPrice": "$2,900", /* ... */ },
"twoBed": { "startingPrice": "$3,350", /* ... */ }
},
// ... amenities, policies, etc.
}これはすごい!
もう一つの例ハッカーニュースの見出し
もっと簡単なクエリ:「ハッカーニュースの最新ニュース記事5本のタイトルを教えてください」。

これは、Bright DataのMCPサーバーが、AIワークフローの中で、ダイナミックなWebコンテンツや厳重に保護されたWebコンテンツへのアクセスをいかに簡素化するかを示しています。
結論
このガイドを通して探求してきたように、Anthropicのモデルコンテキストプロトコルは、AIシステムが外部世界とどのように相互作用するかの根本的な変化を表しています。これまで見てきたように、Amazonスクレイパーのような特定のタスクのためにカスタムMCPサーバーを構築することができます。Bright DataのMCP統合は、ボット対策を回避し、AIに対応した構造化データを提供するエンタープライズグレードのウェブスクレイピング機能を提供することで、これをさらに改善します。
また、AIと大規模言語モデル(LLM)に関する最高のリソースを厳選しました。より深く学ぶために、ぜひチェックしてみてください:






