
このガイドで、あなたは発見するだろう:
- ラングフローとは何か、なぜこれほど人気があるのか。
- Langflowアプリで標準的なLLMを使うことの限界と、外部データを使ってそれを克服する方法。
- Bright Dataと統合されたLangflow AIアプリを構築してWebデータアクセスを行う方法。
さあ、飛び込もう!
ラングフローとは?
LangflowはPythonとJavaScriptで構築されたオープンソースのツールで、AIを搭載したエージェントやワークフローを構築、デプロイすることができます。GitHubに92k以上のスターがあり、AIエージェントを開発するための最も人気で広く採用されているライブラリの1つです。
Langflowはローコードのビジュアル開発プラットフォームです。ドラッグ・アンド・ドロップのインターフェイスを通じて、あらかじめ組み込まれたコンポーネントを接続するだけで、複雑なAIアプリケーションを作成することができます。このアプローチにより、大規模なコーディングが不要になります。また、カスタムコードの統合にも対応しているため、最大限の柔軟性を発揮します。
Langflowは、エージェント、LLM、ベクトルストア、あらゆるAPI、モデル、データベースとの統合など、幅広いAI機能を公開しています。
AIアプリにデータアクセスが必要な理由
他のフレームワークと比較して、LangflowはAIアプリを構築するための視覚的なローコードプラットフォームとして輝いています。しかし、他のLLMを搭載したシステムと同様に、Langflowベースのアプリは、アクセスできるデータと同じくらいスマートです。
LLMは静的なデータセットで訓練され、リアルタイムのイベントやプライベートなビジネスデータに対する認識を内蔵していない。そのため、新鮮で関連性のあるデータソースに接続しない限り、現在の世界から切り離されてしまう。そして、ウェブは最も広範な情報源である。
LLMのこれらの制限を克服するために、Langflowは柔軟なウェブデータパイプラインに接続することができます。このパターンは次のような重要なユースケースで基礎となります:
- RAGワークフローでは、検索されたデータがLLMの出力を向上させる。
- 分析前にデータを抽出し、クリーニングするデータパイプライン。
- AIエージェントは、クエリに答えたり、文書を要約したり、ウェブ検索を実行したりするタスクを実行するために、外部の知識を必要とする。
さて、ウェブから正確な公開データを取得するのは、簡単なことではない。以下のようなインフラが必要だ:
- 事実上あらゆるウェブサイト(スクレイピング防止技術で保護されているウェブサイトも含む)に接続できる。
- 必要なデータを確実に抽出します。
- 構造化されたAI対応フォーマットで返却する。
これこそがBright Dataが提供するものです。LangflowとBright Dataのツールを組み合わせることで、AIアプリは以下のような強力な機能を得ることができます:
- ボット対策を回避しながらリアルタイムでウェブスクレイピング。
- Amazon、LinkedIn、Zillowなどの一流プラットフォームからの構造化データ抽出。
- 検索エンジンの検索結果にアクセスし、クエリベースのSERPデータをライブで表示します。
- 自動化された全ページのスクリーンショットによる視覚的なデータキャプチャ。
カスタムLangflowコンポーネントを介して直接Bright Dataに接続できます。つまり、複雑なバックエンドロジックの構築やメンテナンスは必要ありません。コンポーネントをフローに配線するだけで準備は完了です!
ブライトデータによるウェブデータアクセスでLangflowでAIアプリを構築する
このステップバイステップのチュートリアルでは、Langflowを使用して、Bright Dataと統合することで、ライブのウェブデータを取得できるAIエージェントを構築します。
ここで紹介したAIエージェントのセットアップは、この統合によって構築できるものの簡単な一例に過ぎないことを覚えておいてください。Bright Data × Langflowの統合を利用して構築できるAIアプリは他にも無数にあります。インスピレーションを得るために、可能なユースケースのリストをご覧ください。
以下のガイドに従って、LangflowでBright Dataを利用したAIエージェントを作成してください!
前提条件
このチュートリアルに従うには、以下の条件を満たしていることを確認してください:
- デュアルコアCPUと2GB以上のRAM(推奨:マルチコアCPUと4GB以上のRAM)。
- WindowsではPythonバージョン3.10~3.12、macOS/Linuxでは3.10~3.13をローカルにインストール。
uvパッケージがローカルにインストールされている。- Bright Data APIキー。
- サポートされているLLMの1つに接続するためのAPIキー(ここでは、API経由で無料で利用できるGeminiを使用する)。
Bright DataのAPIキーをお持ちでない方も、チュートリアル中に設定方法をご案内しますのでご安心ください。
uvをインストールするには、以下のコマンドを実行する:
pip install uvWindowsをお使いの場合は、Microsoft Visual C++ 14.0以上が必要です。ダウンロードし、サポートガイドに従ってインストールを完了してください。
ステップ1:ラングフローの設定
まず、Langflowプロジェクト用のフォルダを作成し、その中に移動します:
mkdir langflow-agent
cd langflow-agentlangflow-agentフォルダはLangflowプロジェクトのディレクトリとなります。
プロジェクトフォルダー内で、uvを使って Pythonの仮想環境を作成する:
uv venv venv次に、macOS/Linux上で、以下の方法でアクティベートする:
source venv/bin/activate同様に、Windowsでは、実行する:
venvScriptsactivate有効化された仮想環境で、プロジェクト環境にLangflowをインストールします:
uv pip install langflow少し時間がかかるので、辛抱してね。
インストールが完了したら、次のコマンドでアプリケーションを実行して、セットアップが機能することを確認します:
uv run langflow runLangFlowがローカルサーバーを初期化するのを待ちます。準備ができたら、ブラウザのこのページで利用できるはずです:
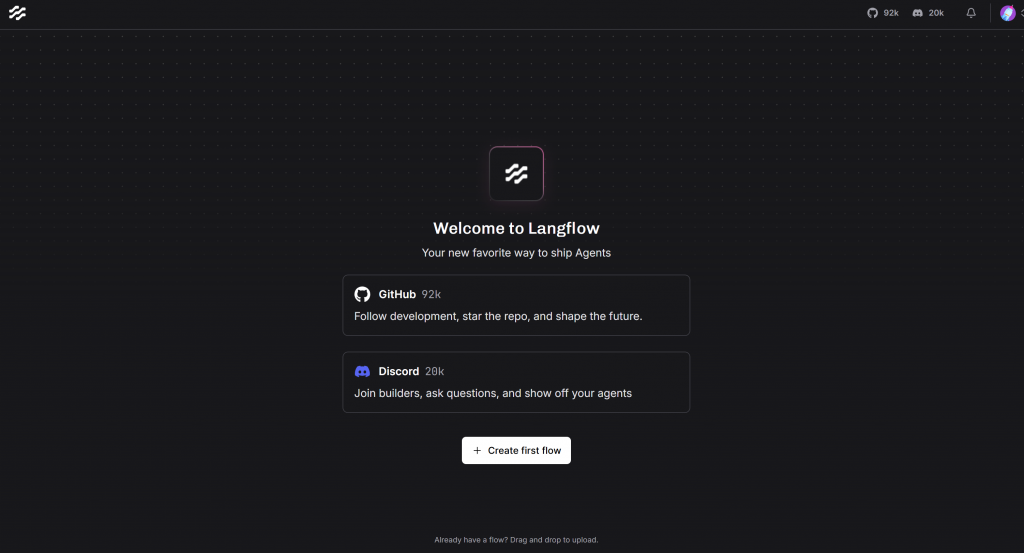
http://localhost:7860Langflowを開くと、このようなインターフェイスが表示されます:
エラーが発生した場合は、公式のインストールガイドを参照してください。
驚いた!LangFlowのセットアップが完了しました。
ステップ2:ブライト・データの設定
AIアプリケーションにウェブからデータを取得する機能を持たせるには、Bright DataのAIインフラに接続する必要があります。
Bright Dataは、多くのデータ収集ソリューションを提供していますが、このチュートリアルでは、以下の点に焦点を当てます:
- ウェブアンロッカー:ボットによる保護を回避し、あらゆるウェブページをHTMLまたはMarkdown形式で返す高度なスクレイピングAPI。
注:Web Scraper APIsのような他のBright Dataツールとの統合も可能ですが、このガイドでは汎用のWeb Unlockerに焦点を当てています。
あなたのLangflowアプリでWeb Unlockerを使うには、まず次のことが必要です:
- Bright DataアカウントでWeb Unlockerゾーンを設定します。
- リクエストを認証するための Bright Data API トークンを生成します。
その両方を行うには、以下の指示に従ってください!参考までに、公式ドキュメントもご覧ください。
まず、Bright Dataのアカウントをまだお持ちでない場合は、無料でサインアップしてください。アカウントをお持ちの場合は、ログインしてダッシュボードを開きます。Proxies & Scraping “ボタンをクリックします:
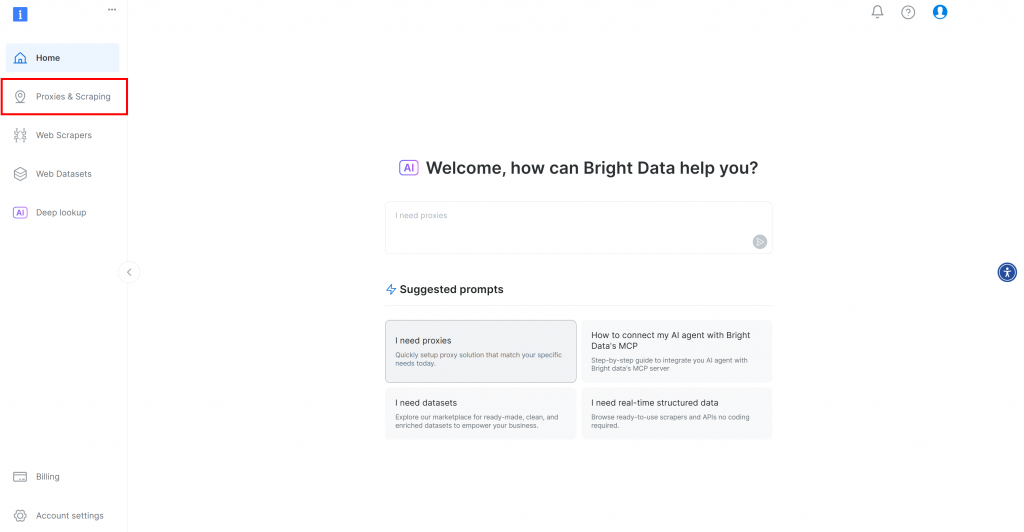
プロキシとスクレイピング・インフラストラクチャ」ページにリダイレクトされます:

すでにWeb Unlockerゾーンがある場合は、このページに表示されます。この例では、ゾーンはすでに存在し、「unblocker」という名前になっています(この名前は後で必要になるので覚えておいてください)。
必要なゾーンがまだない場合は、”Web Unlocker API “カードまでスクロールダウンし、”Create zone “をクリックします:
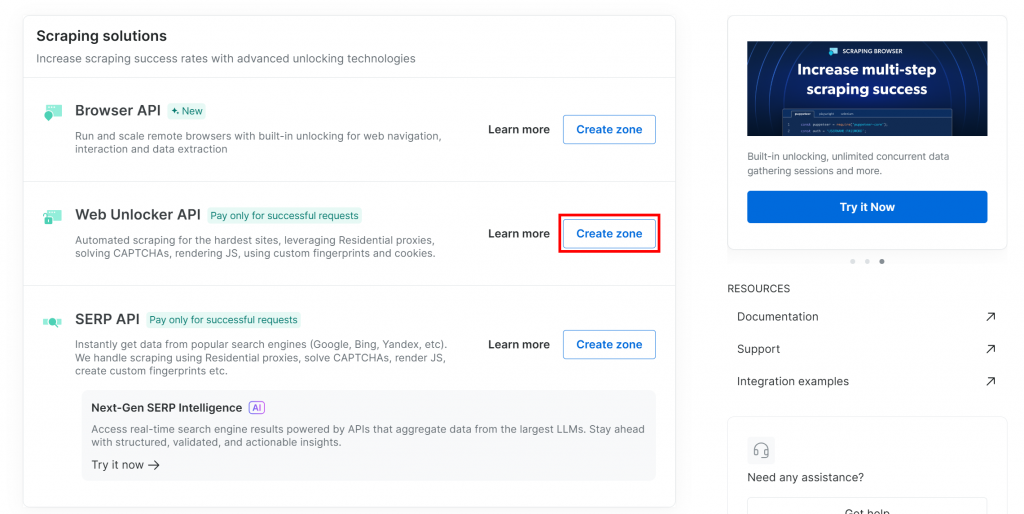
ゾーンに名前(”unlocker “など)をつけ、最高のパフォーマンスを発揮するために高度な機能を有効にし、”Add “ボタンを押す:
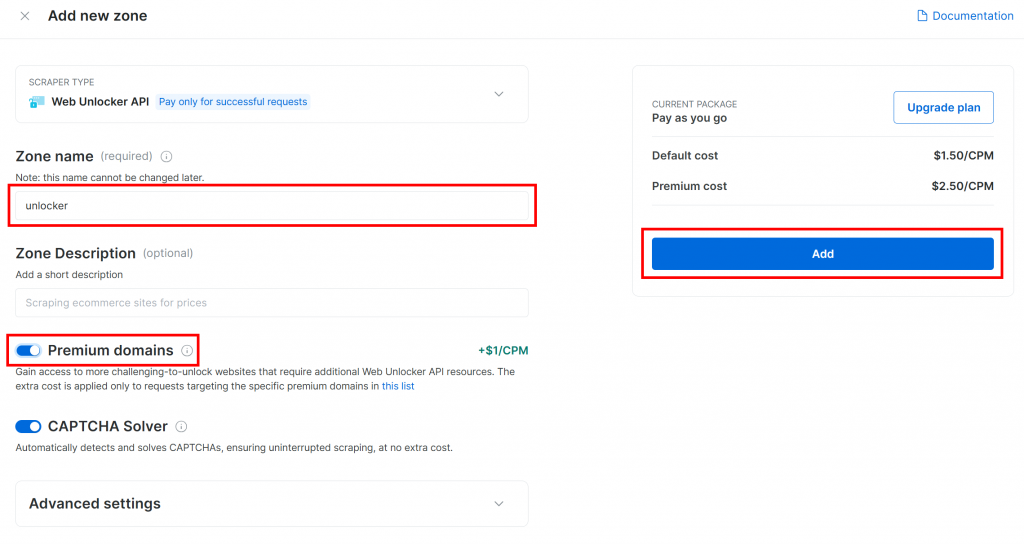
作成が完了すると、ゾーンの詳細ページが表示されます。トグルが “Active “になっていることを確認してください:
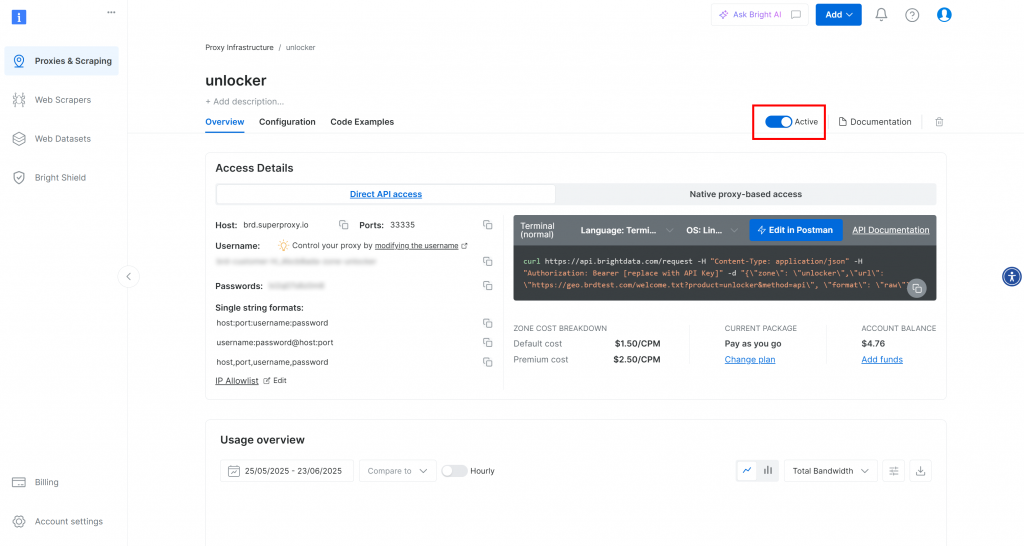
Bright Dataの公式ドキュメントに従ってAPIキーを生成してください。APIキーを取得したら、安全な場所に保管してください。
完璧です!カスタムコンポーネントを使用してBright DataとLangflowを統合する準備ができました。
ステップ#3: 新しいブランクフローの初期化
続行する前に、新しいLangflowフローを作成する必要があります。Langflowローカルサーバーに戻り、”Create first flow “ボタンをクリックしてください:

以下のモーダルが表示されます。右下の「Blank Flow」ボタンを押してください:
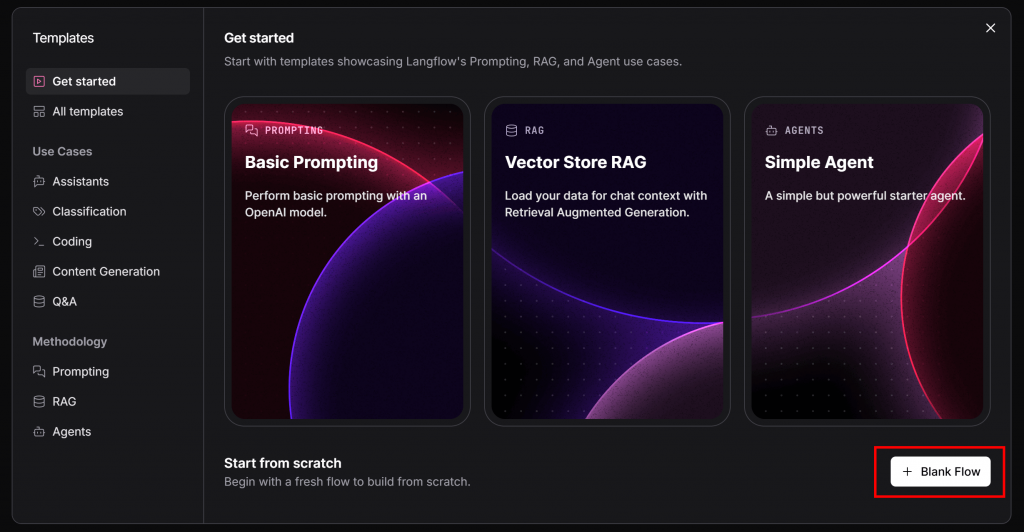
Langflow x Bright Data AI App」のように、フローに名前を付けます。作成すると、このように真っ白なキャンバスが表示されます:
上のキャンバスは、AIアプリケーションを定義するためにコンポーネントを追加したり接続したりする場所です。よくできました!
ステップ4: カスタムブライトデータコンポーネントの定義
LangflowとBright Dataを統合する最も簡単な方法は、カスタムコンポーネントを作成することです。これにより、AIエージェントがBright DataのWeb Unlocker APIを使ってWebデータを収集できるようになります。
ラングフローでは、カスタム・コンポーネントはPythonのクラスで定義される:
- 入力:コンポーネントが必要とするデータやパラメータ。
- 出力:コンポーネントが下流のノードに返すデータ。
- ロジック:入力を出力に変換する内部処理。
具体的には、Langflow x Bright Dataカスタムコンポーネントが必要です:
- Bright Data API キーと Web Unlocker ゾーン名を入力します(認証用)。
- スクレイピングしたいウェブページのターゲットURLを受け取る。
- Web Unlocker APIへのリクエストを実行し、ページをMarkdown形式(AIでの利用に最適)で返すように設定する。
- 取得したコンテンツを出力として返す。
以下のカスタムPythonコンポーネントで、上記のすべてを実装することができます:
from langflow.custom import Component
from langflow.io import SecretStrInput, StrInput, Output
from langflow.schema import Data
import httpx
# A Langflow custom component must extend Component
class BrightDataComponent(Component):
# The component name shown in the Langflow UI
display_name = "Bright Data"
# The description in the component details
description = "Retrieve data from the web in Markdown format using Bright Data"
icon = "sparkles" # UI icon identifier
name = "BrightData" # Internal name used by Langflow
# --- INPUTS ---
# Define the inputs required by the component
inputs = [
SecretStrInput(
name="api_key",
display_name="Bright Data API Key",
required=True,
info="Your Bright Data API key from the dashboard"
),
StrInput(
name="zone",
display_name="Web Unlocker Zone Name",
info="The name of the Web Unlocker zone to connect to (e.g., 'web_unlocker')",
required=True
),
StrInput(
name="url",
display_name="Target URL",
info="The URL to transform into Markdown data",
tool_mode=True
),
]
# --- OUTPUT ---
# Define the output returned by the component
outputs = [
Output(
name="web_data",
display_name="Web Data Result",
method="get_web_data" # The name of the method used to generate the output
)
]
# --- LOGIC ---
# This method retrieves web data from Bright Data and returns it
def get_web_data(self) -> Data:
try:
# Bright Data Web Unlocker API endpoint
url = "https://api.brightdata.com/request"
# Request headers including API key for authentication
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Payload specifying the zone, URL, and output format
payload = {
"zone": self.zone,
"url": self.url,
"format": "raw",
"data_format": "markdown"
}
# Send the POST request with a 180-second timeout
with httpx.Client(timeout=180.0) as client:
response = client.post(url, json=payload, headers=headers)
# Raise an error if HTTP status code is not 2xx
response.raise_for_status()
# Extract contains the Markdown-formatted web data
markdown_data = response.text
return Data(data={"data": markdown_data})
# Handle timeout errors
except httpx.TimeoutException:
error_msg = "The Web Unlocker request timed out"
return Data(data={"error": error_msg, "data": None})
# Handle other HTTP errors (e.g., 4xx, 5xx)
except httpx.HTTPStatusError as e:
error_msg = f"Request failed with status {e.response.status_code}: {e.response.text}"
return Data(data={"error": error_msg, "data": None})BrightDataComponentは以下の入力を受け付ける:
- Bright Data APIキー。
- Web Unlockerゾーン名。
- スクレイピングしたいページのURL。
その後、HTTPX Pythonクライアントを使用してWeb Unlocker APIにリクエストを送信し、Markdown形式でレスポンスを返すように設定します。APIから返されたページのMarkdown表現がコンポーネントの出力になります。
注意:HTTPXはLangflowのデフォルトのHTTPクライアントライブラリなので使用しました。詳しくは、HTTPXをWebスクレイピングに使う方法をご覧ください。
素晴らしい!このコンポーネントをフローに追加し、AIエージェントにその出力を消費させる方法をご覧ください。
ステップ5: カスタムブライトデータコンポーネントの追加
先ほど定義したコンポーネントを登録するには、左下にある「New Custom Component」ボタンをクリックします。新しい一般的な “Hello, World “カスタムコンポーネントがキャンバスに表示されます。その上にカーソルを置き、”Code “セクションをクリックしてロジックをカスタマイズします:
表示されたコードエディタに、BrightDataComponentクラスのソースコード全体を貼り付けます:
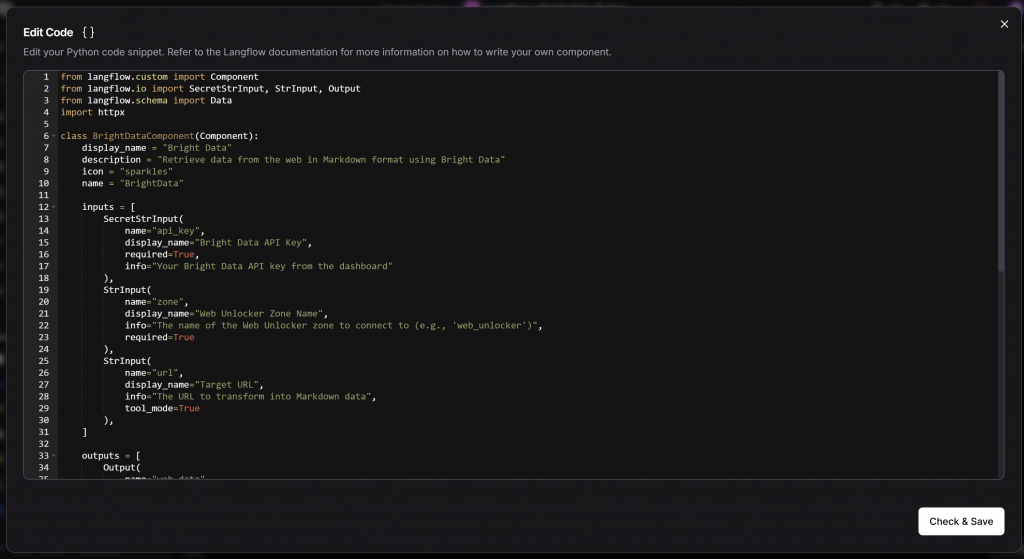
Check & Save “ボタンを押します。一般的な “Custom Component “がBright Dataコンポーネントに置き換わります:
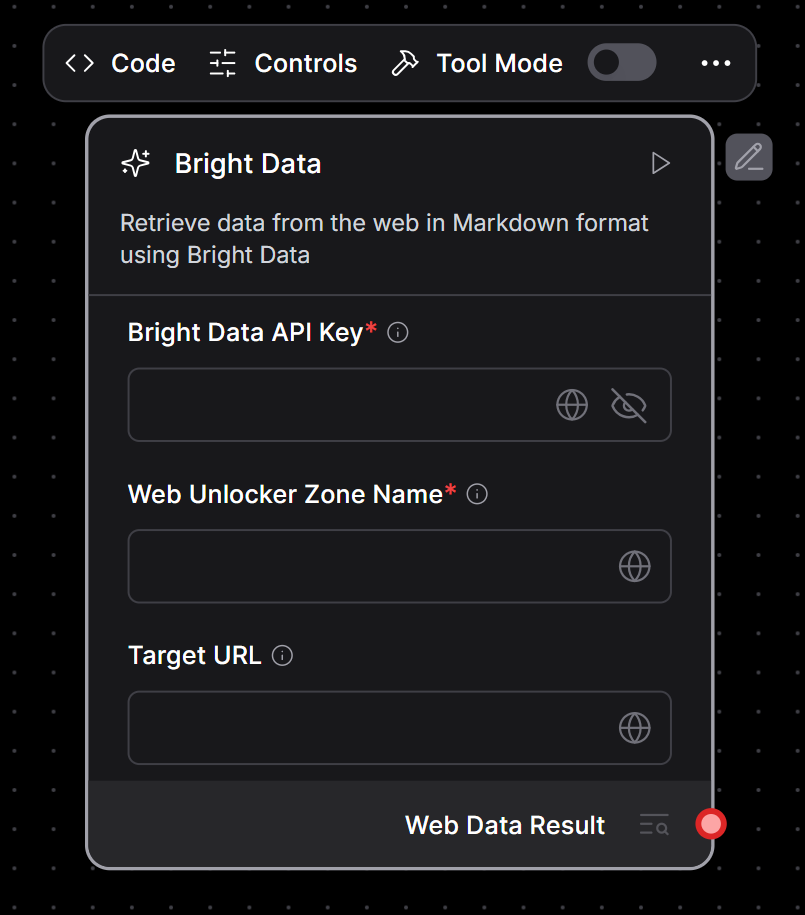
ご覧のように、プレースホルダのカスタムコンポーネントは、Bright Dataと統合するためのカスタムコンポーネントで更新されています。
注意:全てのフローでBright Dataコンポーネントを手動で再作成する必要はありません。
カスタムコンポーネントをPythonファイルに保存し、Langflowドキュメントに記載されている方法で自動的にロードするだけです。
素晴らしい!あなたのAIフローは、Bright Dataと統合してウェブデータを取得できるようになりました。
ステップ#6:AIエージェントをブライトデータに接続する
Bright DataコンポーネントをLangflowアプリ内で直接使用することも、AIエージェントが対話できるツールに変えることもできます。ツール化することで、エージェントにAIフレンドリーなMarkdownフォーマットであらゆるウェブページからライブコンテンツをフェッチする能力を与えることになります。言い換えれば、AIがあらゆるサイトからリアルタイムの情報にアクセスして取得できるようになります。
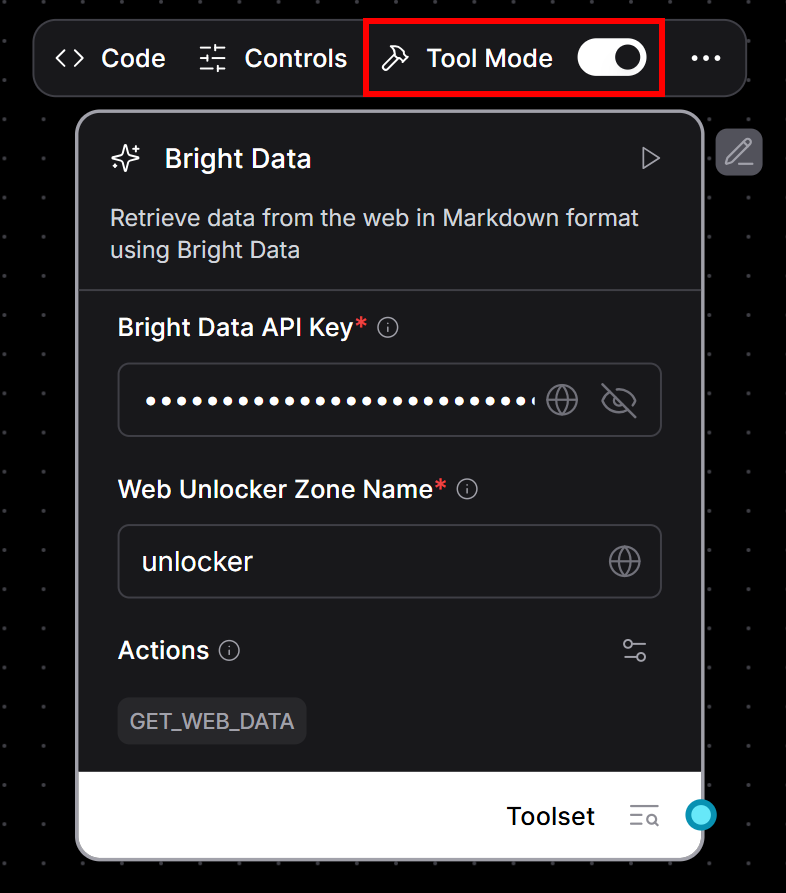
ブライト・コンポーネントをツールにする:
- Bright Dataコンポーネントにカーソルを合わせる。
- ツールモード」スイッチを切り替えて有効にする。
- 必要事項を記入してください:
- Bright Data APIキー。
- Web Unlockerゾーン名(例:
"unlocker")。
これが今見えるはずのものだ:
ブライト・データ・コンポーネントがツールとして準備できたら、AIエージェントに接続する:
- 左サイドバーで、”Agent > Agent “コンポーネントを見つける。
- キャンバスにドラッグする。
- お好みのLLMを使用するようにエージェントを設定します(この例ではGeminiを使用します。
gemini-2.5-flashのような無料のモデルを選択し、Gemini APIキーを貼り付けます)。 - Bright Dataコンポーネントの出力をAgentコンポーネントの “Tools “入力に接続します:
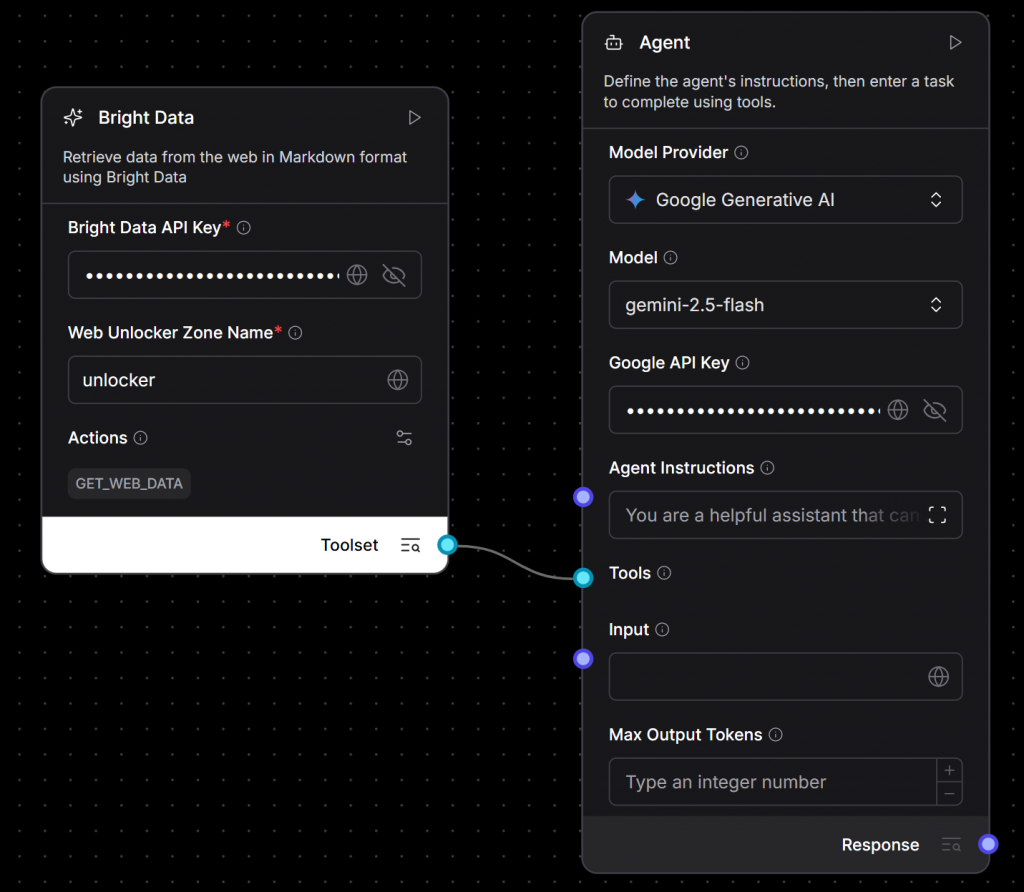
さあ、始めよう!あなたのAIアプリケーションのコアは完全に配線されました。あなたは、Bright Dataのスクレイピングインフラストラクチャを使用して、ライブウェブコンテンツを動的に取得できるGeminiを搭載したエージェントを構築しました。
ステップ7:流れを完成させる
AIフローが完全に機能するためには、入力と出力の両方のコンポーネントが必要です。そこで、AI エージェントに入力チャット コンポーネントを接続し、その応答を受け取るために出力チャット コンポーネントを接続します。
その後、流れは次のようになるはずだ:
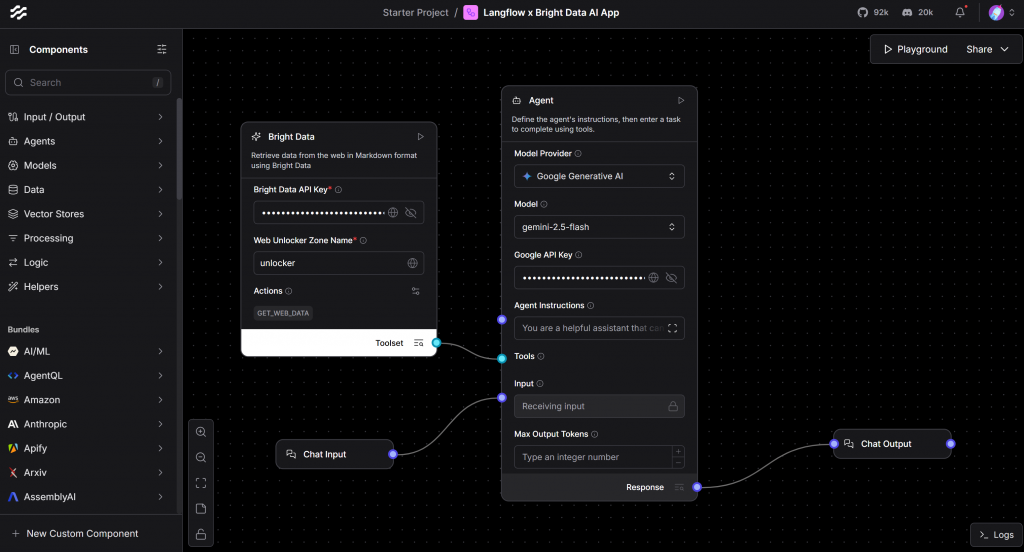
上記の設定は、AIエージェントと対話するためのチャットのようなインターフェイスを提供します。
いよいよです!ラングフロー×ブライトデータのAIアプリが完成しました。
ステップ#8:AIアプリのテスト
AIアプリを起動するには、Langflowインターフェースの右上にある「Playground」ボタンをクリックします:

これが見るべきものだ:
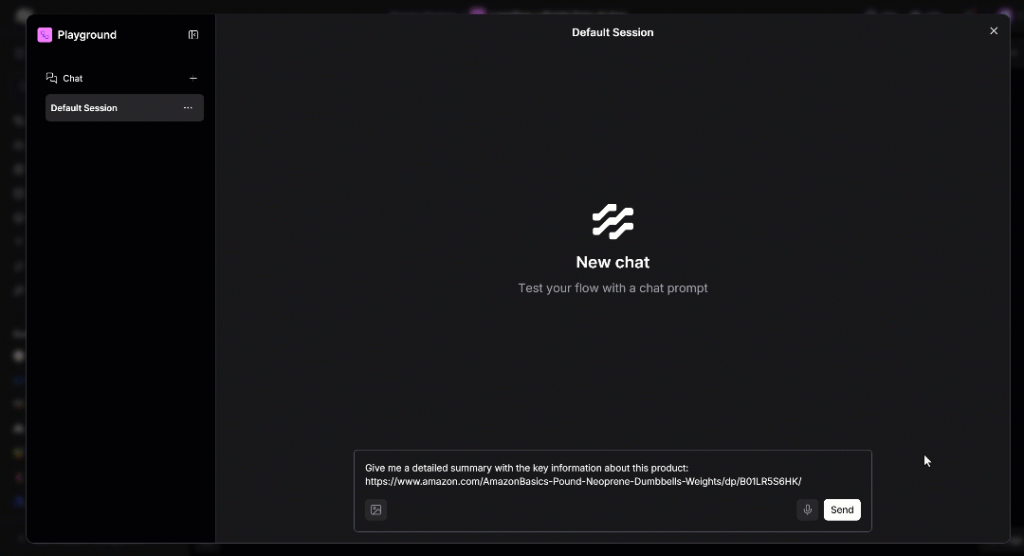
得られるのはChatGPTスタイルの体験だが、あなた自身のAIエージェントによって動かされる。すべての機能を確認するには、次のようなプロンプトを入力してみてください:
Give me a detailed summary with the key information about this product:
https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/以下はその舞台裏である:
- プロンプトはチャット入力からAIエージェントコンポーネントに送られます。
- エージェントは、設定されたLLM(この場合はGemini)を使用し、Bright Dataコンポーネントから来る必要なツールをトリガーする。
- エージェントは、スクレイピングされたウェブコンテンツを受信し、それを処理し、最終的なレスポンスをチャット出力に渡します(チャットで表示される回答に対応します)。
上記のプロンプトは、GeminiだけではAmazonのようなサイトをボット対策のためにスクレイピングできないため、素晴らしいテストである。Bright DataのWeb Unlockerは、AmazonのCAPTCHAをバイパスし、ページからデータを抽出し、AIに対応したMarkdown形式で提供することで、それを解決する。
プロンプトを実行すると、これが表示されるはずだ:
Bright Data を使用しているエージェントを確認するには、”Accessing web_get_data” ドロップダウンを展開します:
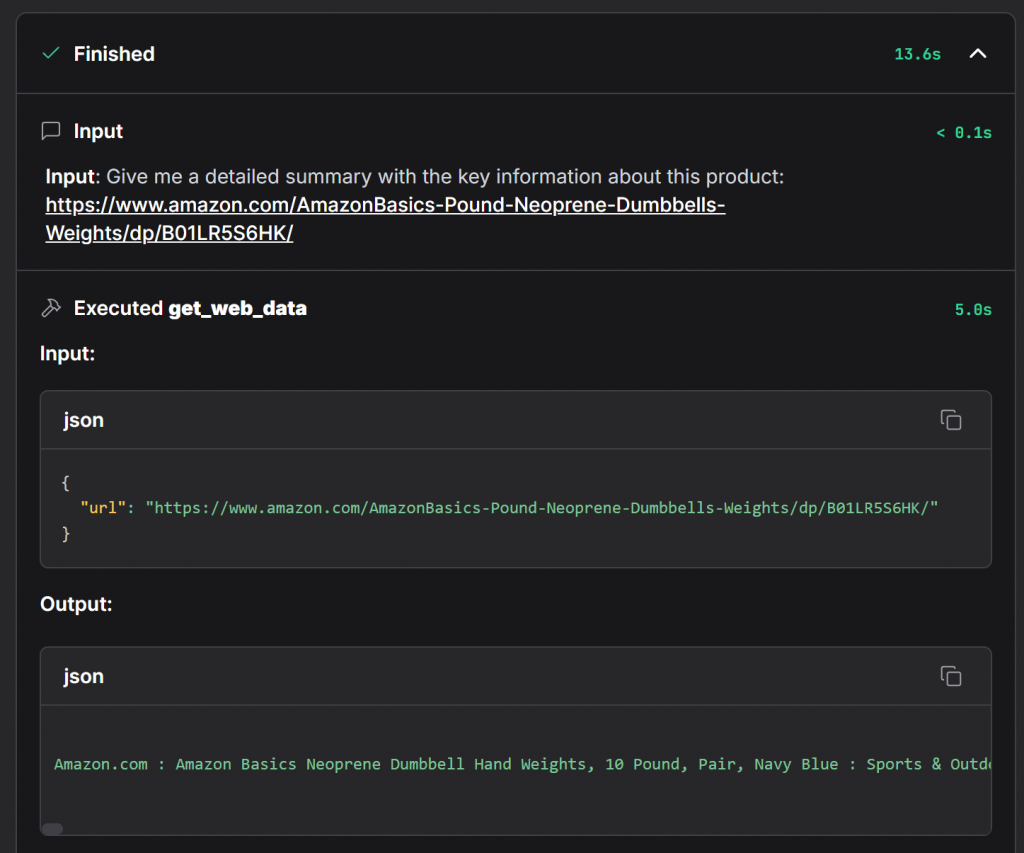
これは、Bright Dataコンポーネントのコアメソッドであるget_web_data関数呼び出しの全詳細を示しています。Amazonの商品ページからデータが正常に取得されたことが確認できます。
以下は、AIエージェントが実際に出力したスクリーンショットの一部である:

このAIが作成した要約の情報はすべて本物であり、幻覚ではない:
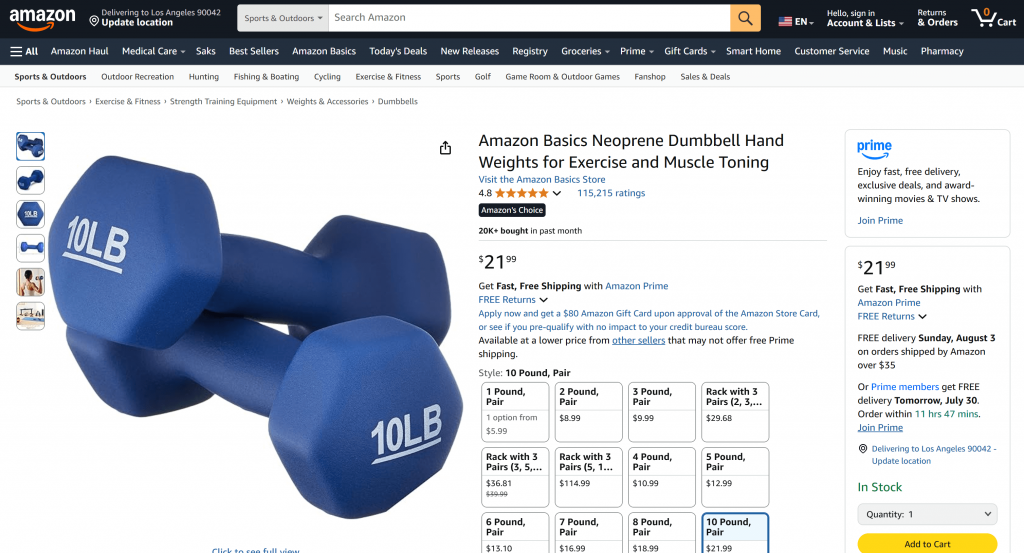
どうですか!LangflowとBright Dataを使って、ウェブデータアクセスが可能なAIアプリの構築とテストが完了しました。
次のステップ
統合が完了したら、次のステップに進みましょう:
- 公式にサポートされている方法のいずれかを使用して、クラウドまたは独自のサーバにエージェントをデプロイします。
- Web Scraper API や SERP API など、他の Bright Data 製品を接続して、統合を拡張します。これを行うには、公式ドキュメントに記載されているように、
BrightDataComponentのロジックを変更して、異なるBright Data APIを呼び出すだけです。 - コンポーネントを組み替えて、RAGパイプライン、データワークフロー、AI自動化フローなど、より高度なユースケースを作成できます。
- AIエージェントをBright Data MCPサーバーに接続すると、50以上のツールとすぐに統合できます。
結論
この記事では、Langflowを使ってウェブデータアクセスが可能なAIエージェントを構築する方法を学びました。これはBright Dataツールとのカスタム統合によって可能になりました。このセットアップにより、LLMは事実上あらゆるウェブサイトからリアルタイムでデータを取得し、処理することができるようになります。
ここで紹介したのは、あくまでも基本的な例であることに留意してほしい。より高度なエージェントの構築を目指すのであれば、ライブのウェブデータを取得し、検証し、AIの消費に最適化された情報に変換するツールが必要です。それが、Bright DataのAIインフラストラクチャです。
無料のBright Dataアカウントを作成し、当社のAI対応データ検索ツールの実験を開始してください!




