

このチュートリアルでは、Bright Dataと本番環境対応のスクラッピングプロジェクトを用いてAmazonをスクレイピングする方法を学びます。
以下の内容をカバーします:
- AmazonスクレイパーAPIの使用方法
- プロジェクトの設定とAmazonスクレイピング対象の構成
- Amazonページの取得とレンダリング
- 検索結果ページおよび商品ページからの商品データ抽出
- Bright DataのWeb MCPとClaude Desktopを使用したAmazonスクレイピング
Amazonをスクレイピングする理由
Amazonは世界最大の商品マーケットプレイスであり、インターネット上で最も豊富なリアルタイムコマースデータ源の一つです。価格動向から顧客の感情に至るまで、このプラットフォームは他のウェブサイトでは実現困難な規模で市場の動向を反映しています。
Amazonのスクレイピングにより、チームは手動調査や静的なデータセットの枠を超え、大規模な自動化されたデータ駆動型の意思決定が可能になります。
Amazonスクレイピングの一般的なユースケース
企業や開発者がAmazonをスクレイピングする主な理由には以下が含まれます:
- 価格監視と競合情報分析:カテゴリーや販売者横断で、商品価格・割引・在庫状況をほぼリアルタイムで追跡。
- 製品調査:商品リスト、カテゴリー、ベストセラーランキングを分析し、需要動向や新たな機会を特定します。
- レビュー・感情分析:顧客レビューや評価を収集し、購入者の感情、製品パフォーマンス、機能面の不足点を把握します。
- AI駆動型アプリケーション:ショッピングアシスタント、動的価格設定モデル、自動市場分析などのタスク向けに、LLMやAIエージェントへライブAmazonデータを供給。
ユースケースが明確になったところで、Bright Dataを用いたAmazonスクレイピングの実践的な方法を見ていきましょう。
Bright Data Amazon Scraper APIによるAmazonスクレイピング
カスタムスクレイパーの構築やClaudeとのMCP利用に加え、Bright DataはマネージドAmazon Scraper APIも提供しています。認証にはAPIキーが必要です。
Amazonスクレイパーの選択
まずBright Dataスクレイパーライブラリを開きます。
利用可能なスクレイパー一覧から、ユースケースに合致するAmazonスクレイパーを選択します。例:
- ASIN別の商品詳細
- 検索結果
- レビュー
各スクレイパーは特定のAmazonデータタイプ向けに設計されています。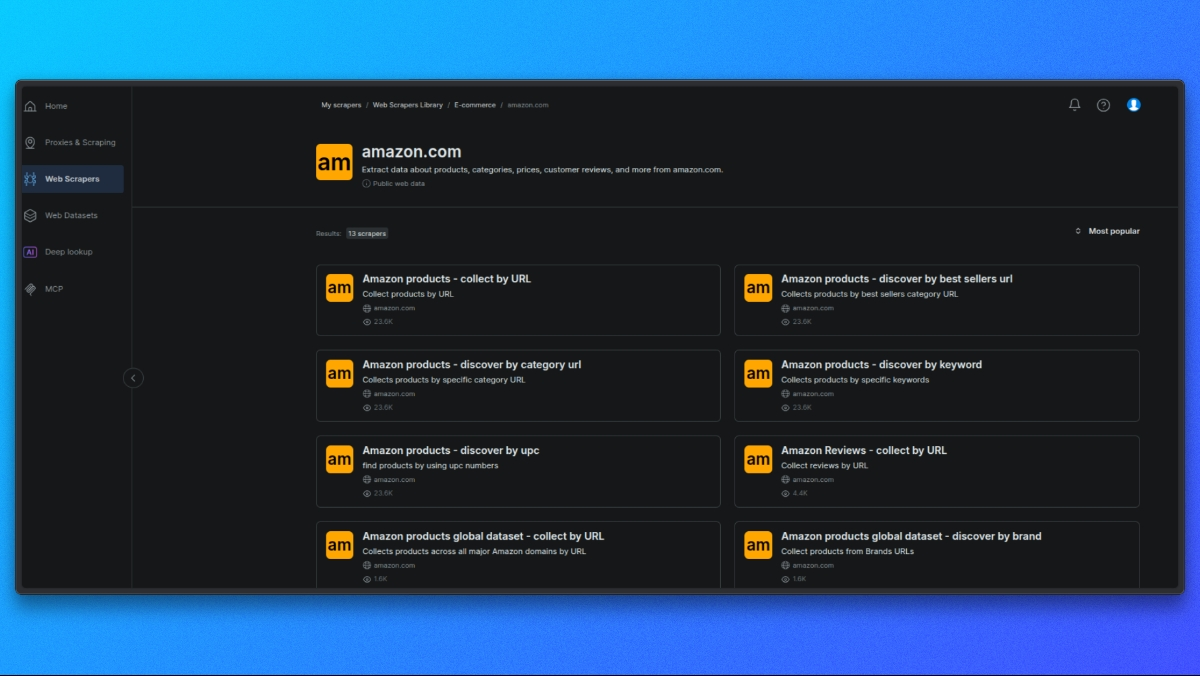
スクレイパーエンドポイントの選択
各スクレイパーは、取得したいデータ(例:商品詳細、検索結果、レビュー)に応じて異なるエンドポイントを提供します。
ユースケースに合ったエンドポイントをクリックしてください。
リクエストを構築
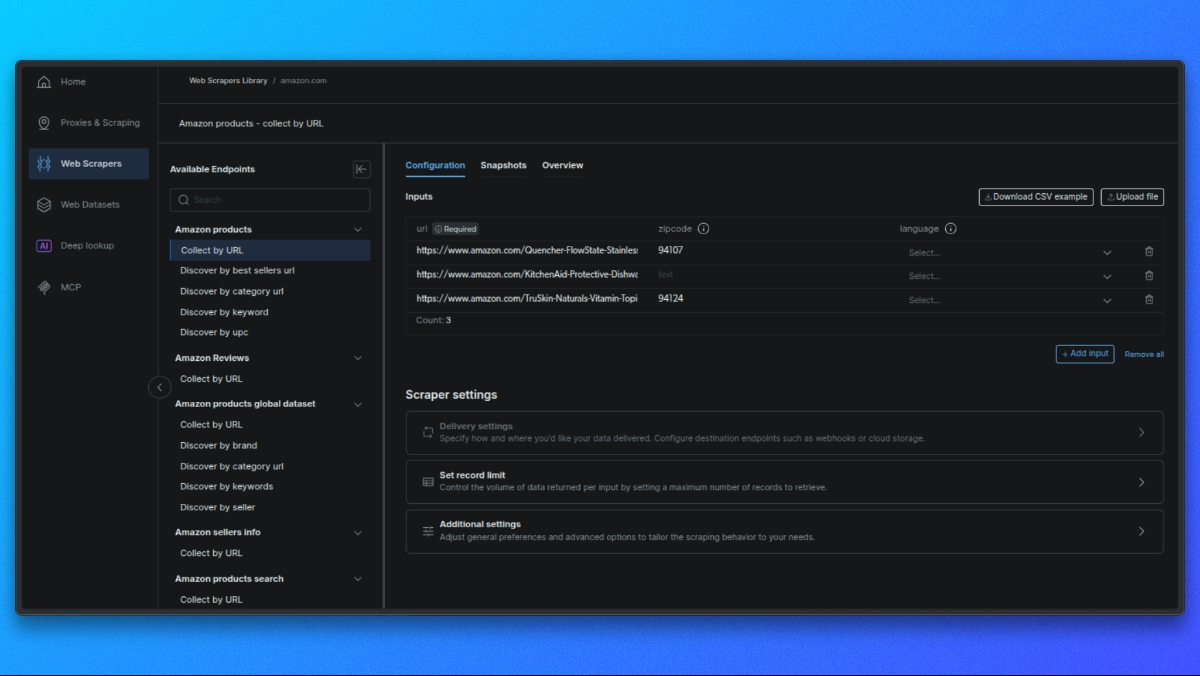
中央パネルにはリクエスト設定フォームが表示されます:
- 単一入力:商品URL、ASIN、またはキーワードを貼り付けます。
- 一括CSV:バッチ処理用の複数入力データをCSVファイルでアップロード。
オプション設定: - 出力スキーマ:必要なフィールドのみを選択してください。
- 外部ストレージ: S3、GCS、またはAzureを設定して直接配信します。
- Webhook URL: 結果を自動受信するためのWebhookを設定します。
APIリクエストを実行
curlを使用した製品ページの基本的な例:
curl -i --silent --compressed "https://api.brightdata.com/dca/trigger?customer=hl_ee3f47e5&zone=YOUR_ZONE_NAME"
-H "Content-Type: application/json"
-H "Authorization: Bearer YOUR_API_KEY"
-d '{
"input": {
"url": "https://www.amazon.com/dp/B08L5TNJHG"
}
}'YOUR_ZONE_NAMEおよびYOUR_API_KEYを実際のゾーン名と API キーに置き換えてください。
### 結果の取得
- リアルタイムジョブ(最大20 URL)の場合、結果が直接取得されます。
- バッチジョブの場合は、結果を取得するためのジョブIDを受け取るか、Webhook/外部ストレージ経由で結果を取得します。
では、Bright Dataのレジデンシャルプロキシを使用したカスタムスクレイパーの構築方法を見ていきましょう。
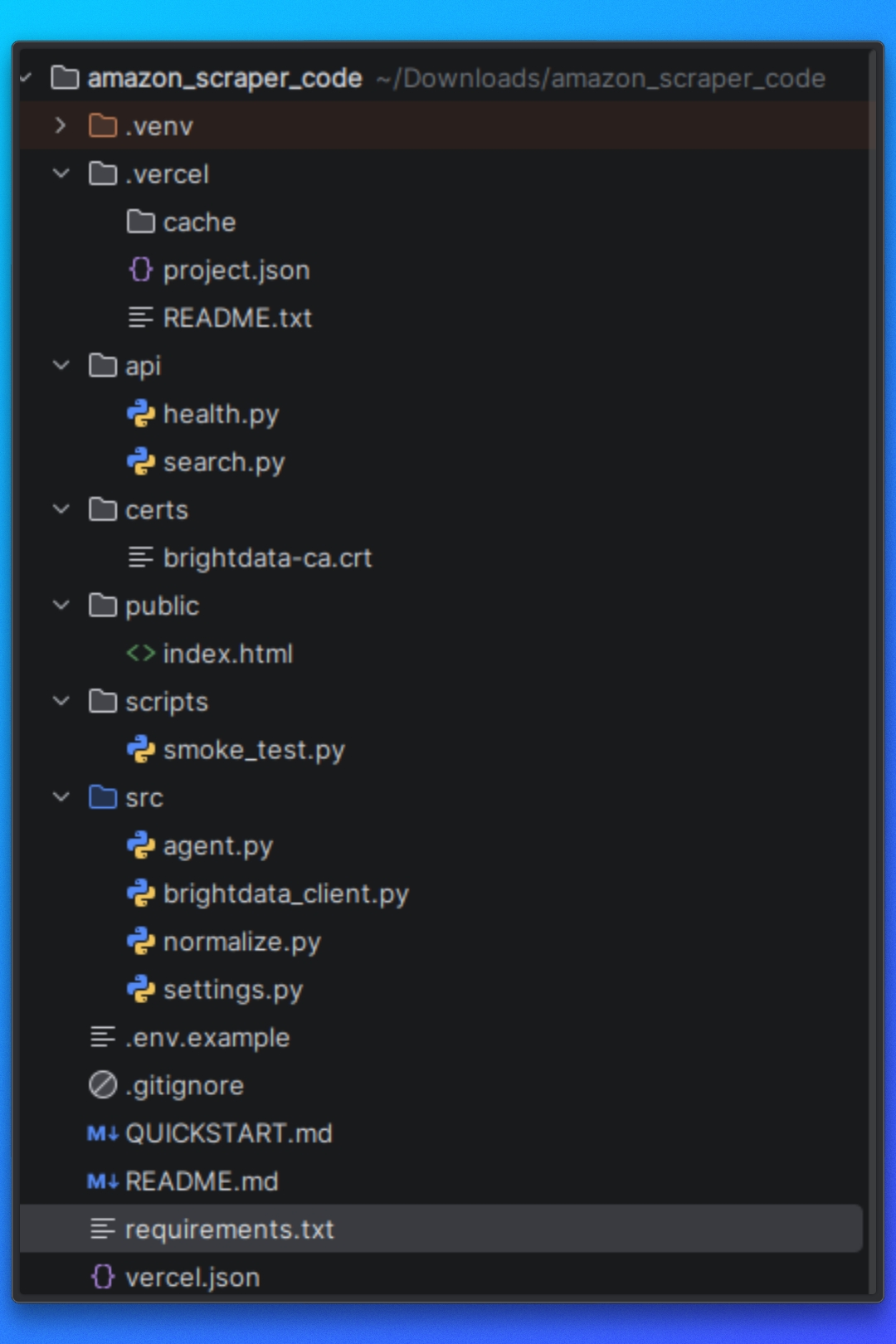
プロジェクトの設定
リポジトリにあるプロジェクトコードを使用して、このチュートリアルを実行できます。
開始する前に、システムに以下の前提条件がインストールされていることを確認してください。
前提条件
このプロジェクトには以下が必要です:
- Python 3.10以上
- 依存関係管理用の pip
- Node.js 18 以上(Vercel が必要とする)
- Vercel CLI
さらに、以下のものも必要です:
- Bright Dataアカウント
- Bright DataのWeb MCPへのアクセス権
- Claude Desktop
依存関係のインストール
提供されたrequirements.txtファイルを使用して必要なPython依存関係をインストールします:
pip install -r requirements.txtこれにより、ページ取得、ブラウザ自動化、HTMLパース、データ抽出に使用されるすべてのライブラリがインストールされます。
Bright Data CA証明書
このプロジェクトは、プロキシ経由でリクエストをルーティングする際のTLS検証にBright Data CA証明書を使用します。
以下のパスに証明書ファイルが存在することを確認してください:
certs/brightdata-ca.crtこのファイルはリクエスト時にHTTPクライアントに渡されます。ファイルが存在しない、または参照が誤っている場合、TLS検証エラーによりAmazonリクエストは失敗します。
Vercel 設定
このプロジェクトはVercelサーバーレス関数として動作するよう設計されています。
api/search.pyファイルはAPIのエントリポイントとして機能し、Vercelが着信HTTPリクエストに応じてこれを実行します。
Vercel CLI がインストールされ認証されていることを確認してください:
vercel login
環境変数
プロジェクトは実行時設定に環境ベースの設定を使用します。
プロジェクトのルートに.envファイルを作成し、リポジトリで指定されている必要な変数を定義してください。これらの値は、スクレイパーが Amazon ページを取得、レンダリング、処理する方法を制御します。
依存関係がインストールされ、環境変数が設定されると、プロジェクトは使用可能な状態になります。
プロジェクト構造の理解
スクレイパーを実行する前に、プロジェクトの構成とスクレイピングパイプラインの開始から終了までの流れを理解する必要があります。
プロジェクトは、責任の明確な分離を中心に構成されています。
設定
プロジェクトのこの部分では、Amazon のターゲット、ランタイムオプション、スクレイパーの動作を定義します。これらの設定により、スクレイピングの対象とスクレイパーの動作を制御します。
ページ取得とレンダリング
プロジェクトのこの部分は、Amazon ページの読み込みと、利用可能な HTML の返送を担当します。ナビゲーション、ページの読み込み、JavaScript の実行を処理し、下流のロジックが完全にレンダリングされたコンテンツで動作するようにします。
抽出ロジック
HTMLが利用可能になると、抽出レイヤーがページをパースし構造化データを抽出します。これにはAmazon検索結果ページと個別商品ページの両方に対するロジックが含まれます。
実行フロー
実行フローはフェッチ、レンダリング、抽出、出力の連携を調整します。各ステップが正しい順序で実行されることを保証します。
出力処理
スクレイピングされたデータは構造化された形式でディスクに書き込まれ、他のワークフローでの検査や利用が容易になります。
この構造によりスクレイパーはモジュール化され、特にチュートリアル後半でBright DataのWeb MCPなどの外部フェッチ手法を統合する際、個々のコンポーネントの再利用が容易になります。
この概要を踏まえ、Amazonターゲットの設定とスクレイパーが収集すべきデータの定義に進みます。
Amazonターゲットの設定
このセクションでは、次の2点を設定します:
- スクレイピング対象のAmazon検索キーワード
- Amazonページを正常に取得するために必要なBright Dataの認証情報
1. Amazon検索キーワードの指定
Amazonキーワードはクエリパラメータ「q」で送信します。
これはapi/search.py で処理されます。API はリクエスト URL から q を読み取り、存在しない場合は直ちに処理を停止します:
# API/search.py
query = query_params.get("q", [None])[0]
if not query:
self._send_json_response(400, {"error": "必須パラメータ q が欠落しています"})
return意味:
エンドポイントには必ず?q=...の形式で呼び出す必要があります
qを忘れると400レスポンスが返され、スクレイパーは実行されません
取得する商品数の設定
オプションのlimitパラメータを使用して、返す商品数を制御することもできます。
引き続きapi/search.py 内で、limit をパースし整数に変換、安全な範囲に制限します:
# api/search.py
limit_str = query_params.get("limit", [None])[0]
limit = DEFAULT_SEARCH_LIMIT
if limit_str:
try:
limit = int(limit_str)
limit = min(limit, MAX_SEARCH_LIMIT)
limit = max(1, limit)
except ValueError:
limit = DEFAULT_SEARCH_LIMITつまり:
制限値を渡さない場合、デフォルト値を使用します。
無効な値が渡された場合、デフォルト値にフォールバックします。
許容値を超える値が渡された場合、上限値が適用される。
デフォルト値と最大値はsrc/settings.py で定義されています:
# src/settings.py
DEFAULT_SEARCH_LIMIT = 10
MAX_SEARCH_LIMIT = 50デフォルト動作を変更したい場合は、ここで設定します。
2. クエリをAmazonの検索エンドポイントへマッピング
クエリ q を取得したら、Bright Data を通じて Amazon の検索結果を取得します。fetch_products(query, limit) を使用します:
# api/search.py
raw_response = fetch_products(query, limit)スクレイピング対象のAmazonエンドポイントはsrc/brightdata_client.pyで定義されています:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"結果を取得する際、kパラメータを使用してキーワードをAmazonに渡します:
# src/brightdata_client.py
r = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)つまり:
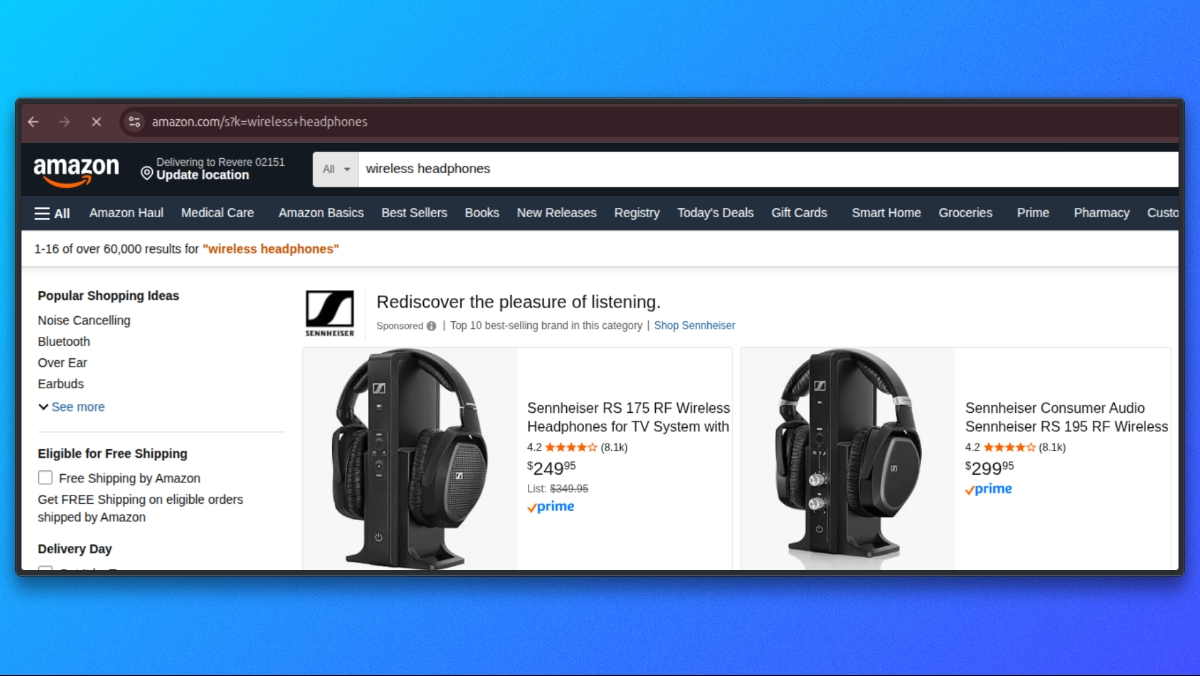
- APIパラメータ
はq - Amazonの検索パラメータは
k - q=wireless headphones を指定した場合、Amazonへのリクエストは
https://www.amazon.com/s?k=wireless+headphonesのように送信されます
3. Bright Dataの認証情報設定
Bright Data経由でリクエストを送信するには、環境変数としてプロキシ認証情報を用意する必要があります。
src/settings.py で Bright Data 設定を次のように読み込みます:
# src/settings.py
BRIGHTDATA_USERNAME = os.getenv('BRIGHTDATA_USERNAME', '')
BRIGHTDATA_PASSWORD = os.getenv('BRIGHTDATA_PASSWORD', '')
BRIGHTDATA_PROXY_HOST = os.getenv('BRIGHTDATA_PROXY_HOST', 'brd.superproxy.io')
BRIGHTDATA_PROXY_PORT = os.getenv('BRIGHTDATA_PROXY_PORT', 'your_port).envファイルに以下の認証情報を追加してください:
BRIGHTDATA_USERNAME=your_brightdata_username
BRIGHTDATA_PASSWORD=your_brightdata_password
BRIGHTDATA_PROXY_HOST=brd.superproxy.io
BRIGHTDATA_PROXY_PORT=your_portスクレイパーを実行すると、これらの値がsrc/brightdata_client.py 内で Bright Data プロキシ URL を構築するために使用されます:
# src/brightdata_client.py
proxy_url = (
f"http://{BRIGHTDATA_USERNAME}:{BRIGHTDATA_PASSWORD}"
f"@{BRIGHTDATA_PROXY_HOST}:{BRIGHTDATA_PROXY_PORT}")
proxies = {"http": proxy_url, "https": proxy_url}BRIGHTDATA_USERNAMEまたはBRIGHTDATA_PASSWORD を設定していない場合、スクレイパーは明確なエラーで早期に失敗します:
# src/brightdata_client.py
if not BRIGHTDATA_USERNAME or not BRIGHTDATA_PASSWORD:
raise ValueError(
"Bright Data プロキシ認証情報が設定されていません。"
"BRIGHTDATA_USERNAME と BRIGHTDATA_PASSWORD を設定してください。"
)キーワードとBright Dataの認証情報を設定したら、Amazonページの取得準備が整います。
Amazonページの取得
この段階では、入力の検証とBright Dataの設定が完了しています。次に、Amazonリクエストがどこで実行され、どのような最小限の前提条件を必要とするかに焦点を当てます。
すべてのAmazonリクエストはsrc/brightdata_client.pyから送信されます。
Amazon検索エンドポイント
Amazon検索エンドポイントは一度定義し、すべての検索リクエストで再利用します:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"リクエストヘッダー
Amazonが標準的なデスクトップHTMLレイアウトを返すよう、汎用的なブラウザ風ヘッダーを送信します。これらのヘッダーはユーザーのOSに依存しません。
# src/brightdata_client.py
headers = {
"User-Agent": (
"Mozilla/5.0 "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
}リクエストの送信
エンドポイント、ヘッダー、プロキシ設定が既に整っている状態で、Amazonリクエストを実行します:
# src/brightdata_client.py
response = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,)
response.raise_for_status()
html = response.text or ""この呼び出しの終了時、htmlにはAmazon検索ページの生のコンテンツが含まれます。
フェッチフェーズが完了したので、次にHTMLをパースし、Amazon検索結果ページから商品リンクとメタデータを抽出します。
検索結果の抽出
Amazon検索ページを取得したら、次に返されたHTMLから商品リストを抽出します。この全工程はsrc/brightdata_client.py内で実行されます。
リクエスト完了後、生のHTMLを内部パーサーに渡します:
products = _parse_amazon_search_html(html, limit=limit)
return {"products": products}検索結果抽出ロジックはすべて_parse_amazon_search_html 内に実装されています。
HTMLのパース
まず、BeautifulSoupを使用して生のHTMLをDOMツリーにパースします。これにより、ページ構造を確実にクエリできます。
soup = BeautifulSoup(html, "lxml")また、リクエストされた制限値を正規化し、常に少なくとも1つのアイテムを抽出できるようにします:
max_items = max(1, int(limit)) if isinstance(limit, int) else 10検索結果コンテナの特定
Amazonの検索ページには商品リスト以外の要素が多数存在します。実際の検索結果を抽出するため、まずAmazonの主要な検索結果コンテナを特定します:
containers = soup.select('div[data-component-type="s-search-result"]')フォールバックとして、有効なdata-asin属性を持つ要素も検索します:
fallback = soup.select('div[data-asin]:not([data-asin=""])')プライマリセレクタが結果を返さないがフォールバックが結果を返す場合、フォールバックに切り替えます:
if not containers and fallback:
containers = fallbackこれにより、レイアウトの微小な変動に対する耐性を保ちつつ、実際の商品エントリーに抽出範囲を限定できます。
結果の反復処理
選択されたコンテナを反復処理し、要求された上限に達したら停止します:
products = []
for c in containers:
if len(products) >= max_items:
break各コンテナから主要フィールドを抽出します。製品カードにタイトルとURLの両方が含まれていない場合はスキップします。
title = _extract_title(c)
url = _extract_url(c)
if not title or not url:
continue商品フィールドの抽出
各商品カードは、同じファイル内で定義された小さな補助関数を使用してパースされます。
image = _extract_image(c)
rating = _extract_rating(c)
reviews = _extract_reviews_count(c)
price = _extract_price(c)次に構造化された商品オブジェクトを組み立てます:
products.append(
{
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": url,
"image": image,
}
)フィールド抽出ヘルパー
各ヘルパーは1つのフィールドに焦点を当て、欠落または部分的なマークアップを安全に処理します。
タイトル抽出
def _extract_title(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
if a:
t = a.get_text(" ", strip=True)
if t:
return t
img = container.select_one("img.s-image")
alt = img.get("alt") if img else ""
return alt.strip() if isinstance(alt, str) else ""Product URL
def _extract_url(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
href = a.get("href") if a else ""
if isinstance(href, str) and href:
return "https://www.amazon.com" + href if href.startswith("/") else href
return ""画像
def _extract_image(container) -> Optional[str]:
img = container.select_one("img.s-image")
src = img.get("src") if img else None
return src if isinstance(src, str) and src else None評価
def _extract_rating(container) -> Optional[float]:
el = container.select_one("span.a-icon-alt")
text = el.get_text(" ", strip=True) if el else ""
if not text:
el = container.select_one('span:contains("out of 5 stars")')
text = el.get_text(" ", strip=True) if el else ""
if not text:
return None
m = re.search(r"(d+(?:.d+)?)", text)
return float(m.group(1)) if m else Noneレビュー数
def _extract_reviews_count(container) -> Optional[int]:
el = container.select_one("span.s-underline-text")
text = el.get_text(" ", strip=True) if el else ""
m = re.search(r"(d[d,]*)", text)
return int(m.group(1).replace(",", "")) if m else None価格
def _extract_price(container) -> str:
whole = container.select_one("span.a-price-whole")
frac = container.select_one("span.a-price-fraction")
whole_text = whole.get_text(strip=True).replace(",", "") if whole else ""
frac_text = frac.get_text(strip=True) if frac else ""
if not whole_text:
return ""
return f"${whole_text}.{frac_text}" if frac_text else f"${whole_text}"このステップの終了時点で、Amazon検索結果から直接抽出された構造化された商品エントリのリストが得られます。
各項目には以下が含まれます:
- title
- 価格
- 評価
- レビュー
- 商品URL
- 画像URL
検索結果の抽出が完了したら、レスポンスの正規化と返却に移ります。これはsrc/normalize.py で処理されます。
レスポンスの正規化
この時点では、検索抽出は製品オブジェクトを返しますが、フィールドはまだ標準化されていません。例えば、価格は依然として文字列(例:「$129.99」)であり、レビュー数はカンマを含む可能性があり、カードによっては一部のフィールドが欠落している場合があります。
APIレスポンスの一貫性を保つため、src/normalize.py内で全データを正規化します。
api/search.pyでは、生の結果を取得した直後に正規化が行われます:
# api/search.py
normalized = normalize_response(raw_response, query)この単一の呼び出しにより、Bright Dataの生の出力が常に以下の形式のクリーンなレスポンス形状に変換されます:
items: 正規化された製品オブジェクトのリストcount: 返されたアイテム数
辞書形式レスポンスの正規化
normalize_responseは複数の入力タイプをサポートします。APIフローでは、fetch_products(...)から{"products": [...]}のような辞書型を渡します。
以下が辞書ブランチの実装です:
# src/normalize.py
if isinstance(raw_response, dict):
products = raw_response.get("products", []) or raw_response.get("items", [])
normalized_items = [normalize_product(p) for p in products if isinstance(p, dict)]
return {"items": normalized_items[:limit], "count": len(normalized_items[:limit])}動作説明:
- products(または存在する場合items)から製品を読み込み
- 各商品を normalize_product で正規化
- 一貫性のある
{"items": [...], "count": N}ペイロードを返す
単一商品の正規化
各商品はnormalize_product(...) で正規化されます。
価格はparse_price(...)で数値と通貨コードにパースされる:
# src/normalize.py
price_str = raw_product.get("price", "")
price, currency = parse_price(price_str)評価は可能な場合浮動小数点数に変換されます:
# src/normalize.py
rating = raw_product.get("rating")
if rating is not None:
try:
rating = float(rating)
except (ValueError, TypeError):
rating = None
else:
rating = Noneレビュー数は整数に正規化され、reviewsとreviews_countの両方のキーをサポートします:
# src/normalize.py
reviews_count = raw_product.get("reviews") or raw_product.get("reviews_count")
if reviews_count is not None:
try:
reviews_count = int(str(reviews_count).replace(",", ""))
except (ValueError, TypeError):
reviews_count = None
else:
reviews_count = None最後に、標準化された製品オブジェクトを返します:
# src/normalize.py
return {
"title": raw_product.get("title", ""),
"price": price,
"currency": currency,
"rating": rating,
"reviews_count": reviews_count,
"url": raw_product.get("url", ""),
"image": raw_product.get("image"),
"source": "brightdata",
}正規化が完了したことで、APIから安全に返却でき、クライアントが容易に利用可能な一貫性のあるアイテムリストが得られました。
Vercelでのスクレイパーの実行
このスクレイパーはVercelのサーバーレス関数として動作します。ローカル環境ではVercel開発サーバーを使用して実行し、api/ルートが本番環境と同様に動作することを確認します。
Vercelでローカル実行
リポジトリのルートディレクトリから開発サーバーを起動します:
vercel dev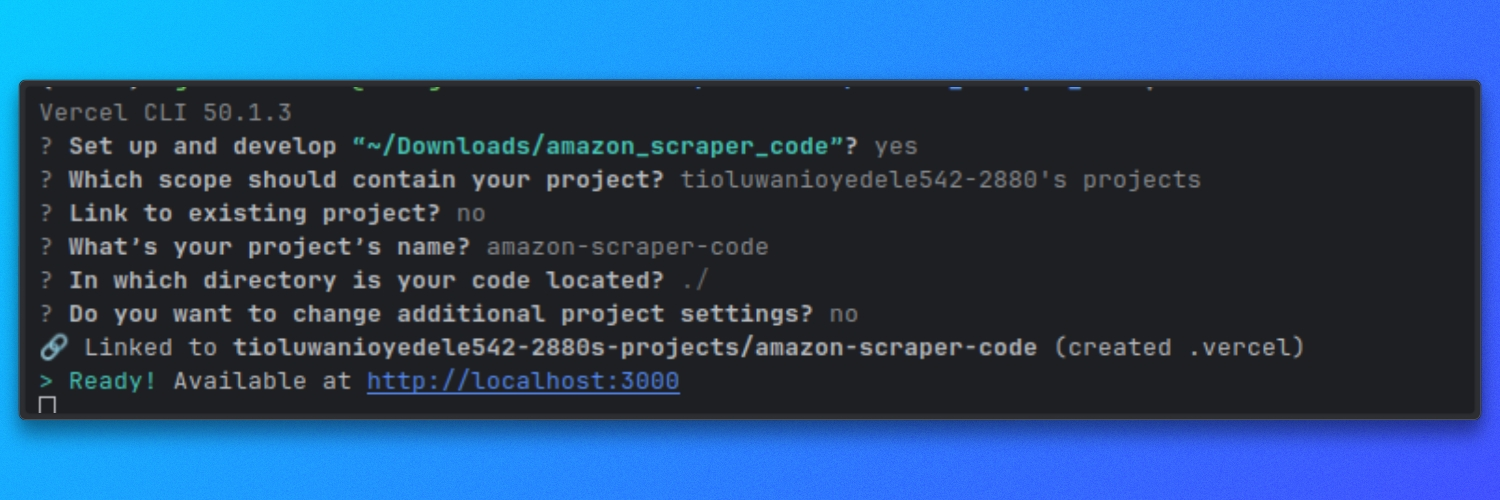
デフォルトでは、サーバーは以下で起動します:
http://localhost
これでスクレイパープロジェクトが完全に整いました。さまざまなAmazon製品をスクレイピングして試すことができます。
さらに、Bright DataのMCPとAIエージェントを使用したスクレイピングも可能です。その方法を簡単にご紹介します。
Claude DesktopとBright DataのWeb MCPの接続
Claude DesktopはBright DataのWeb MCPサーバーを起動するよう設定する必要があります。
Claude Desktopの設定ファイルを開きます。
設定に移動し、開発者アイコンをクリックして「設定編集」を選択します。これによりClaude Desktopで使用される設定ファイルが開きます。

以下の設定を追加し、YOUR_TOKEN_HERE をBright Data API トークンに置き換えてください:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_TOKEN_HERE"
}
}
}
}ファイルを保存し、Claude Desktopを再起動してください。
Claudeが再起動すると、Bright DataのWeb MCPがツールとして利用可能になります。
ClaudeでAmazon商品リストを抽出する
Bright DataのWeb MCPを接続すれば、ClaudeにAmazon検索結果の取得と抽出をワンステップで依頼できます。
以下のようなプロンプトを使用します:
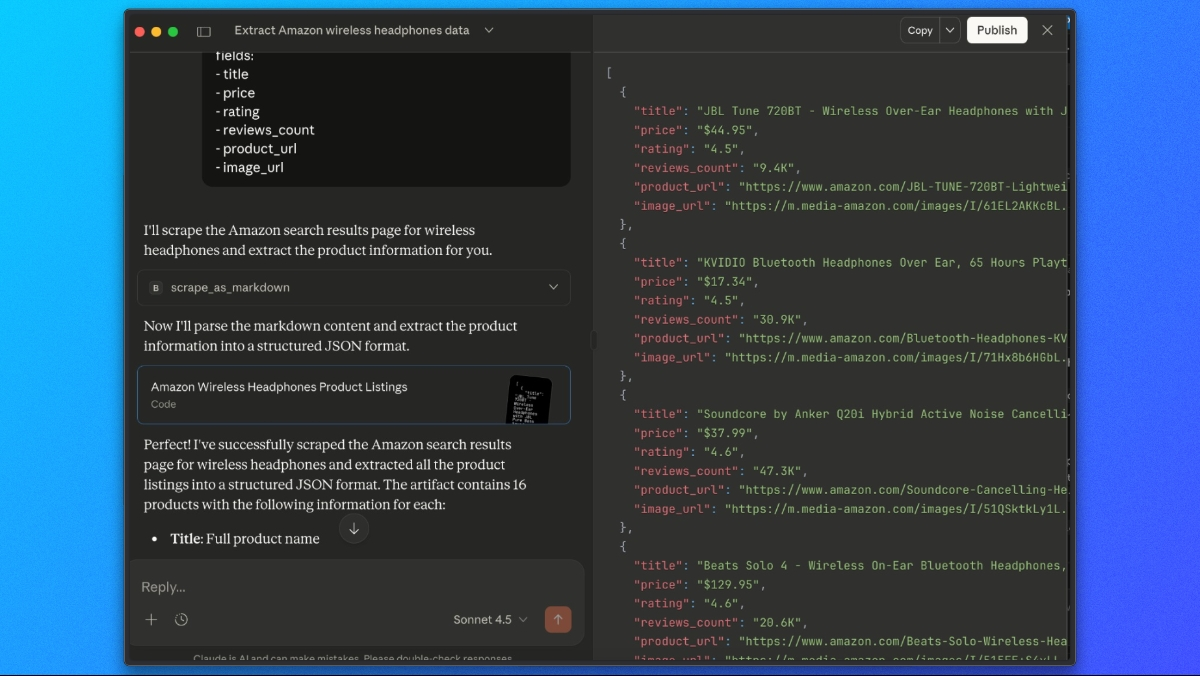
scrape_as_markdown ツールを使用して以下のURLにアクセスしてください:
https://www.amazon.com/s?k=wireless+headphones
次に、マークダウン出力から以下のフィールドを含むJSONリストへ全商品リストを抽出してください:
- title
- price
- rating
- reviews_count
- product_url
- image_urlClaudeはBright DataのWeb MCP経由でページを取得し、レンダリングされたコンテンツを解析して、抽出されたAmazon商品データを含む構造化されたJSONレスポンスを返します。
まとめ
このチュートリアルでは、Bright Data を使用した Amazon のスクレイピング方法を 3 つ紹介しました:
- Amazon API– 最速で始められる方法。スクレイピングコードを一切書かずに、商品詳細、検索結果、レビュー用の事前構築済みエンドポイントを利用できます。
- Bright Dataプロキシを使用したカスタムスクレイパー– Vercel Serverless Functionとして本番環境対応のスクレイパーを構築。取得、抽出、正規化を完全に制御可能。
- Web MCP搭載Claude Desktop– コードを書かずにAI駆動の抽出機能でAmazonをインタラクティブにスクレイピング。
スクレイピングを完全に回避
インフラ構築なしで大規模な本番環境対応のAmazonデータが必要な場合は、Bright DataのAmazonデータセットをご検討ください。以下にアクセスできます:
- 事前収集済み商品リスト、価格、レビュー
- トレンド分析用の履歴データ
- 定期的に更新されるすぐに使えるデータセット
- 複数のAmazonマーケットプレイスを網羅
リアルタイムスクレイピングから既製データセットまで、Bright DataはAmazonデータへの信頼性の高い大規模アクセスを実現するインフラを提供します。




