

このチュートリアルでは以下を探求します:
- – 電子商取引スクレイピングの定義とその有用性
- ECスクレイパーの種類
- ECプラットフォームからスクレイピング可能なデータ
- Pythonを用いたECスクレイピングスクリプトの作成方法
- ECサイトスクレイピングにおける課題
さあ、始めましょう!
eコマースウェブスクレイピングとは?
eコマースウェブスクレイピングとは、Amazon、ウォルマート、eBayなどのオンライン小売プラットフォームからデータを抽出するプロセスです。手動でデータをコピーすることも可能ですが、通常は自動化されたツールやスクリプトを使用して行われます。
ECサイトから抽出されたデータは、企業、研究者、開発者に以下の点で役立ちます:
- 商品価格の変動を分析する
- レビュースコアの追跡
- 市場トレンドの特定
- 競合他社の調査
これらの知見は、情報に基づいた意思決定と戦略的計画立案を可能にします。
eコマースデータスクレイピングツールは、一般にeコマーススクレイパーと呼ばれていることに留意してください。
ECスクレイパーの種類
以下は、最も一般的なECスクレイパーツールの種類の一部です:
- カスタムスクリプト:PythonやJavaScriptなどのウェブスクレイピングプログラミング言語を使用して特定のeコマースデータを抽出するためのカスタマイズされたスクリプト。
- ノーコードスクレイパー:コーディングなしでデータ抽出が可能なユーザーフレンドリーなツール。技術的知識のないユーザーに最適です。最適なノーコードスクレイパーを発見しましょう。
- ウェブスクレイピングAPI:構造化されたeコマースデータをプログラムで提供するインターフェース。リアルタイムまたは大規模な抽出をサポートすることが多い。
- スクレイピング拡張機能:ECウェブページを閲覧しながら直接データ収集を簡素化するブラウザベースのアドオン。
本記事では、カスタムECサイトウェブスクレイピングボットの構築に焦点を当てます。
ECサイトからスクレイピングすべきデータ
ECサイトスクレイパーで一般的に取得可能なデータ:
- 製品詳細:名称、説明、仕様、画像。
- 価格情報:現在の価格、割引、過去の価格推移。
- 顧客レビュー:評価、レビュー内容、顧客フィードバック。
- カテゴリとタグ:商品の分類とカテゴリ分け。
- 販売者情報:販売者名、評価、連絡先詳細。
- 配送詳細:送料、配送時間、配送ポリシー。
- 在庫状況:在庫レベルと品切れ通知。
- マーケティングデータ:商品リスト、価格戦略、プロモーション、季節限定割引。
それでは、Pythonでeコマーススクレイパーを構築する方法を学びましょう!
eコマーススクレイパーの構築方法
eコマーススクレイパーを手動で構築するには、まず対象サイトに精通する必要があります。開発者ツールで対象ページを検査し、以下のことを行います:
- 構造の理解
- 抽出可能なデータの特定
- 使用するスクレイピングライブラリを決定する
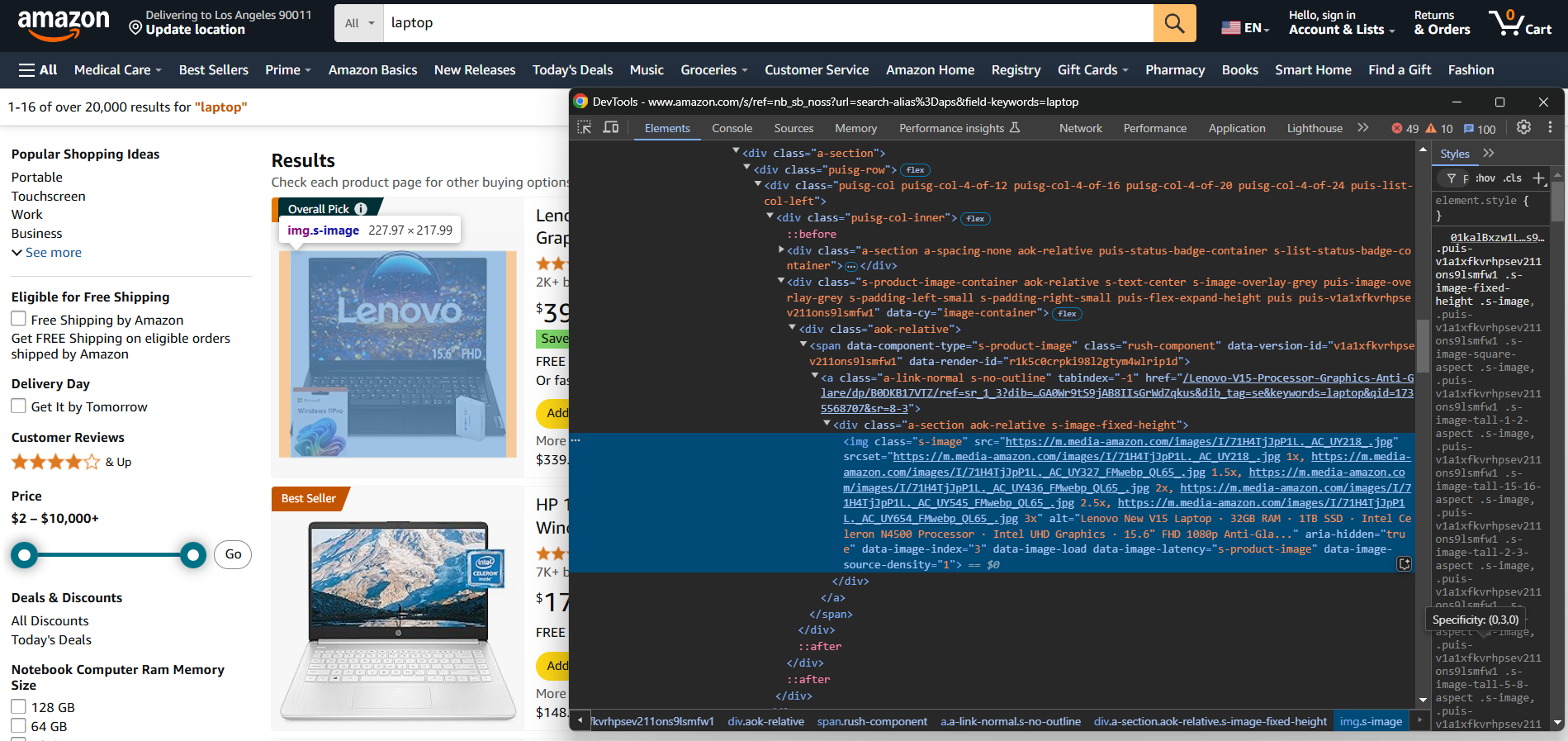
シンプルなeコマースサイトの場合、以下の2つのPythonライブラリで十分です:
- Requests: HTTPリクエスト送信用。ウェブページの生のHTMLコンテンツを取得するのに役立ちます。
- Beautiful Soup: HTMLおよびXMLドキュメントのパース用。ページのHTML構造からのナビゲーションとデータ抽出を簡素化します。詳細はBeautiful Soupスクレイピングガイドをご覧ください。
両ライブラリは以下でインストール可能:
pip install requests beautifulsoup4
データを動的に読み込む、またはJavaScriptレンダリングに大きく依存するeコマースプラットフォームでは、Seleniumのようなブラウザ自動化ツールが必要になります。詳細はSeleniumスクレイピングチュートリアルをご覧ください。
Seleniumのインストール方法:
pip install selenium
次に、ウェブスクレイピングのプロセスは以下の通りです:
- 対象サイトに接続:RequestsまたはSeleniumを使用してページのHTMLを取得し、パースします。
- 関心のある要素を選択:HTML構造内の特定要素(例:商品画像、価格、説明)を特定し、CSSセレクタまたはXPath式で選択します。
- データの抽出: これらのHTML要素から必要な情報を取得します。
- データのクリーニング:抽出されたデータを処理し、不要なコンテンツを削除したり、必要に応じて再フォーマットします。
- データのエクスポート:クリーンアップしたデータをJSONやCSVなど希望の形式で保存する。
この手法の利点には、データ抽出プロセスを完全に制御できること、特定の要件に合わせてカスタマイズできることが含まれます。ただし、設計と保守には技術的な専門知識が必要です。さらに、各ECサイトごとに独自のスクリプトが必要となります。
次の章では、Amazon、Walmart、eBayからデータを抽出するためのPython eコマーススクレイピングスクリプトの例を紹介します!
Amazonスクレイピング
- 対象ページ:Amazonの「ノートパソコン」検索ページ
- 対象ページURL:https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
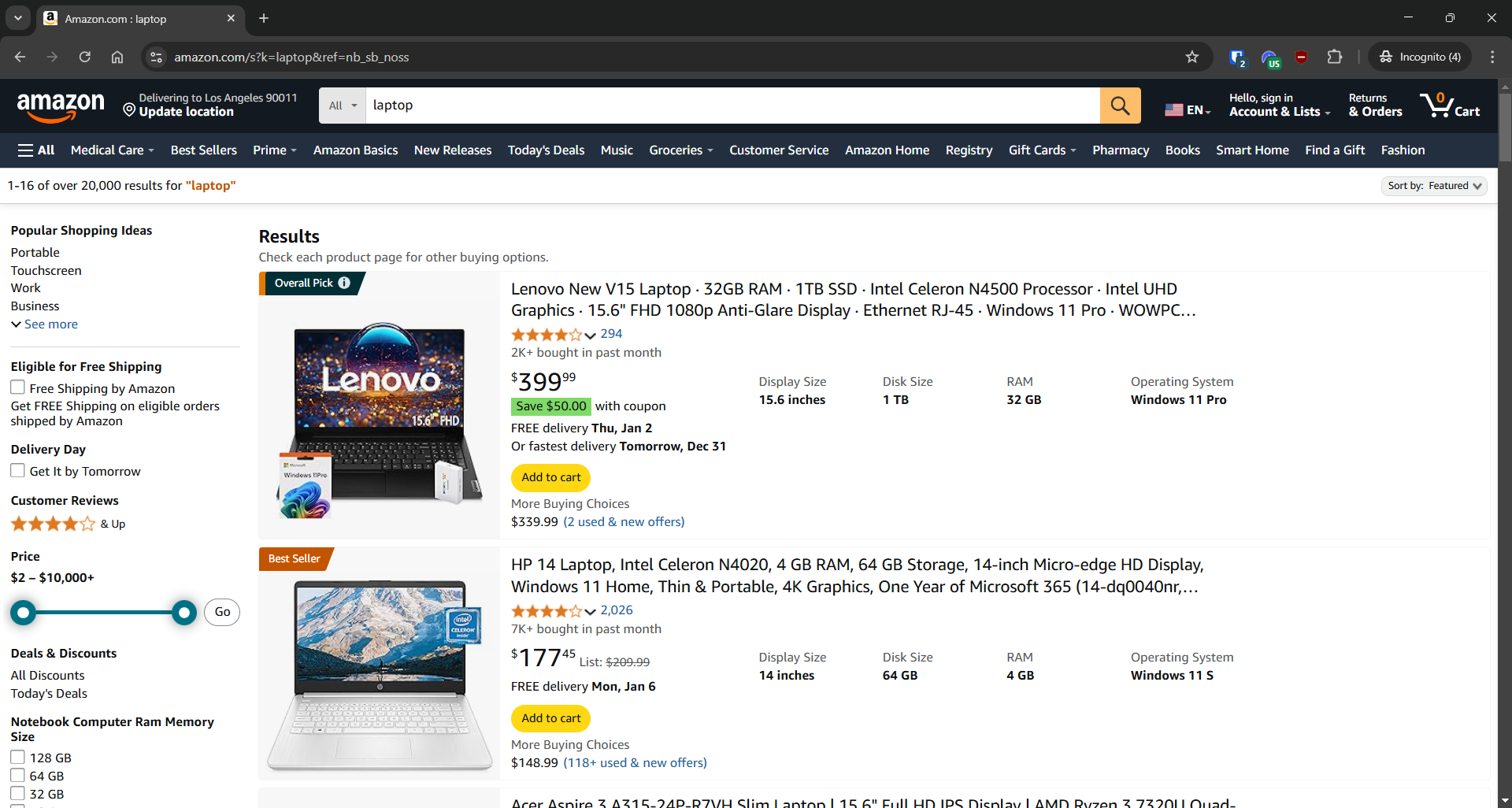
Amazonはブラウザ発の要求以外をブロックするスクレイピング対策を実施しています。この制限を回避するには、Seleniumのようなブラウザ自動化ツールを使用する必要があります:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# WebDriverの初期化
driver = webdriver.Chrome(service=Service())
# ブラウザでAmazonホームページを開く
driver.get("https://amazon.com/")
# 検索フォームに入力
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# 検索ボタンを探してクリック
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# これで対象ページに移動しました
# スクレイピングしたデータの保存先
products = []
# ページ上の全商品要素を選択
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# それらを反復処理
for product_element in product_elements:
# スクレイピング処理
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-image-load]")
image = image_element.get_attribute("src")
# スクレイピングしたデータで新しいオブジェクトを作成
product = {
"url": url,
"name": name,
"image": image
}
# スクレイピングした商品リストに追加
products.append(product)
# JSONファイルへのデータエクスポート
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
上記のAmazon eコマーススクレイパーを実行すると、AmazonがCAPTCHAを表示しない場合、以下の結果が生成されます:
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
"name": "Acer Aspire 3 A315-24P-R7VH スリムノートパソコン | 15.6インチ フルHD IPSディスプレイ | AMD Ryzen 3 7320U クアッドコアプロセッサー | AMD Radeonグラフィックス | 8GB LPDDR5 | 128GB NVMe SSD | Wi-Fi 6 | Windows 11 Home in Sモード",
"image": "https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg"
},
// 簡略化のため省略...
{
"url": "https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
"name": "レノボ最新フラッグシップChromebook、14インチFHDタッチスクリーン搭載スリム軽量ノートパソコン、8コアMediaTek Kompanio 520プロセッサ、4GB RAM、64GB eMMC、WiFi 6、Chrome OS+Hubxcelアクセサリ付属、アビスブルー",
"image": "https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg"
}
]
Amazonでは、Selenium経由でリクエストを行っても、CAPTCHAが表示されリクエストがブロックされる場合があります。その場合は代替手段としてSeleniumBaseをご検討ください。そうでない場合は、本記事を読み進めてください。決定的な解決策を提示します。
包括的な手順については、Amazonウェブスクレイピングの詳細なチュートリアルをご覧ください。
ウォルマートスクレイピング
- 対象ページ:Walmartの「キーボード」検索ページ
- 対象ページURL:https://www.walmart.com/search?q=keyboard
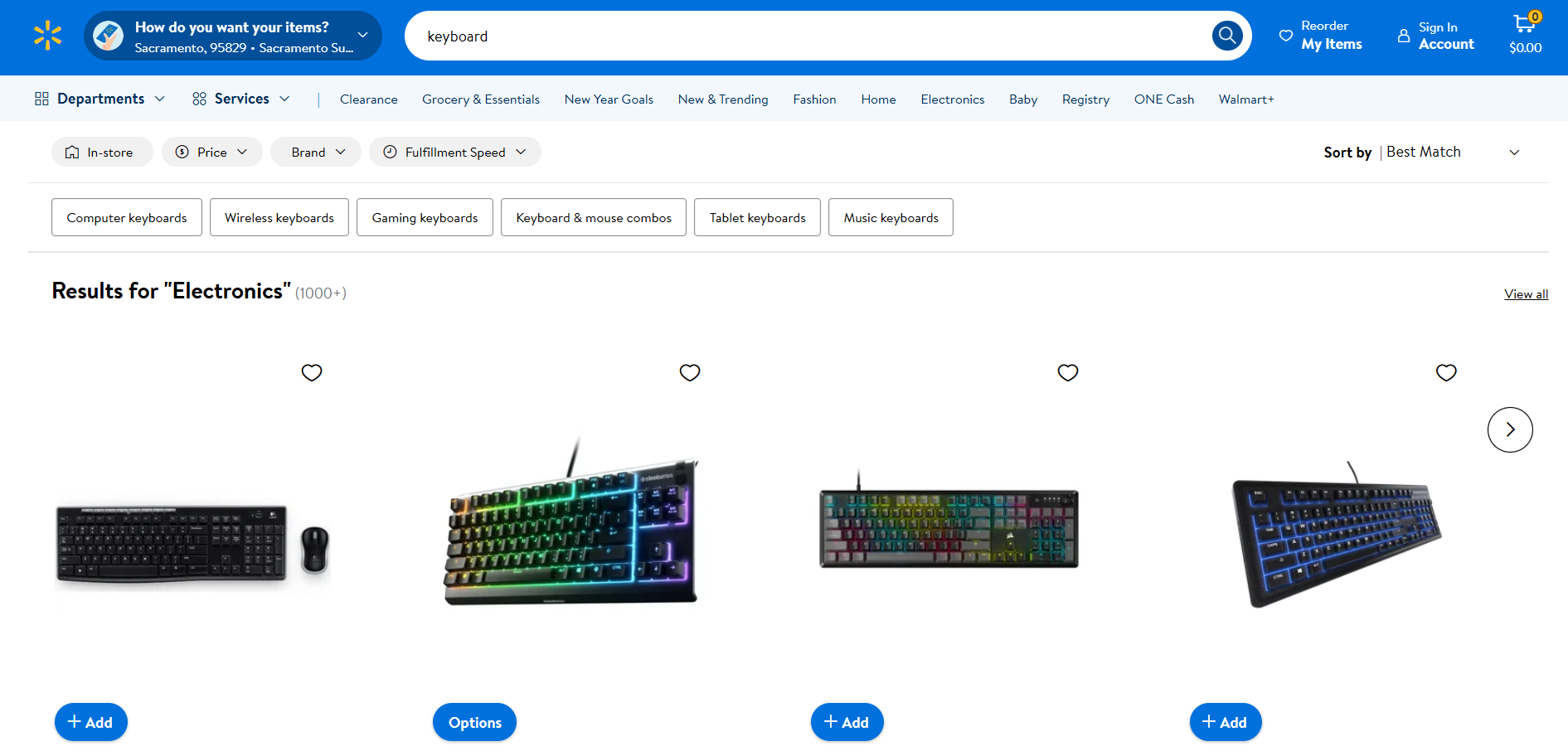
Amazonと同様に、Walmartも自動化されたHTTPクライアントからのリクエストをブロックするボット対策ソリューションを採用しています。そのため、以下のSeleniumを使用したスクレイピングが可能です:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# WebDriverの初期化
driver = webdriver.Chrome(service=Service())
# 対象ページへ移動
driver.get("https://www.walmart.com/search?q=keyboard")
# スクレイピングしたデータの保存先
products = []
# ページ上の全商品要素を選択
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# それらを反復処理
for product_element in product_elements:
# スクレイピングロジック
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# スクレイピングしたデータで新しいオブジェクトを作成
product = {
"url": url,
"name": name,
"image": image
}
# スクレイピングした製品リストに追加
products.append(product)
# データをJSONファイルにエクスポート
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Walmart ecommerceスクレイパーを実行すると、以下の結果が得られます:
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-キーボード-マウス-USB-ワイヤレス-コンボ-ブラック%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "Logitech Wireless Combo MK270",
"image": "https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-ゲーミングキーボード-テンキーレス-防水防塵-PCおよびUSB-A対応-996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "SteelSeries Apex 3 TKL RGB Gaming Keyboard - Tenkeyless - Water & Dust Resistant - PC and USB-A",
"image": "https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
// 簡略化のため省略...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "ドナー ポータブル デジタルピアノ 88鍵 シンセアクション キーボード Xスタンド・ペダル付属 初心者向け自動伴奏機能 128音色 83リズム USB/MIDI/Melodics対応 ワイヤレス接続",
"image": "https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
}
]
詳細なガイダンスについては、ウォルマートのウェブスクレイピングに関する記事をお読みください。
eBayスクレイピング
- 対象ページ:eBayの「マウス」検索結果ページ
- 対象ページURL:https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
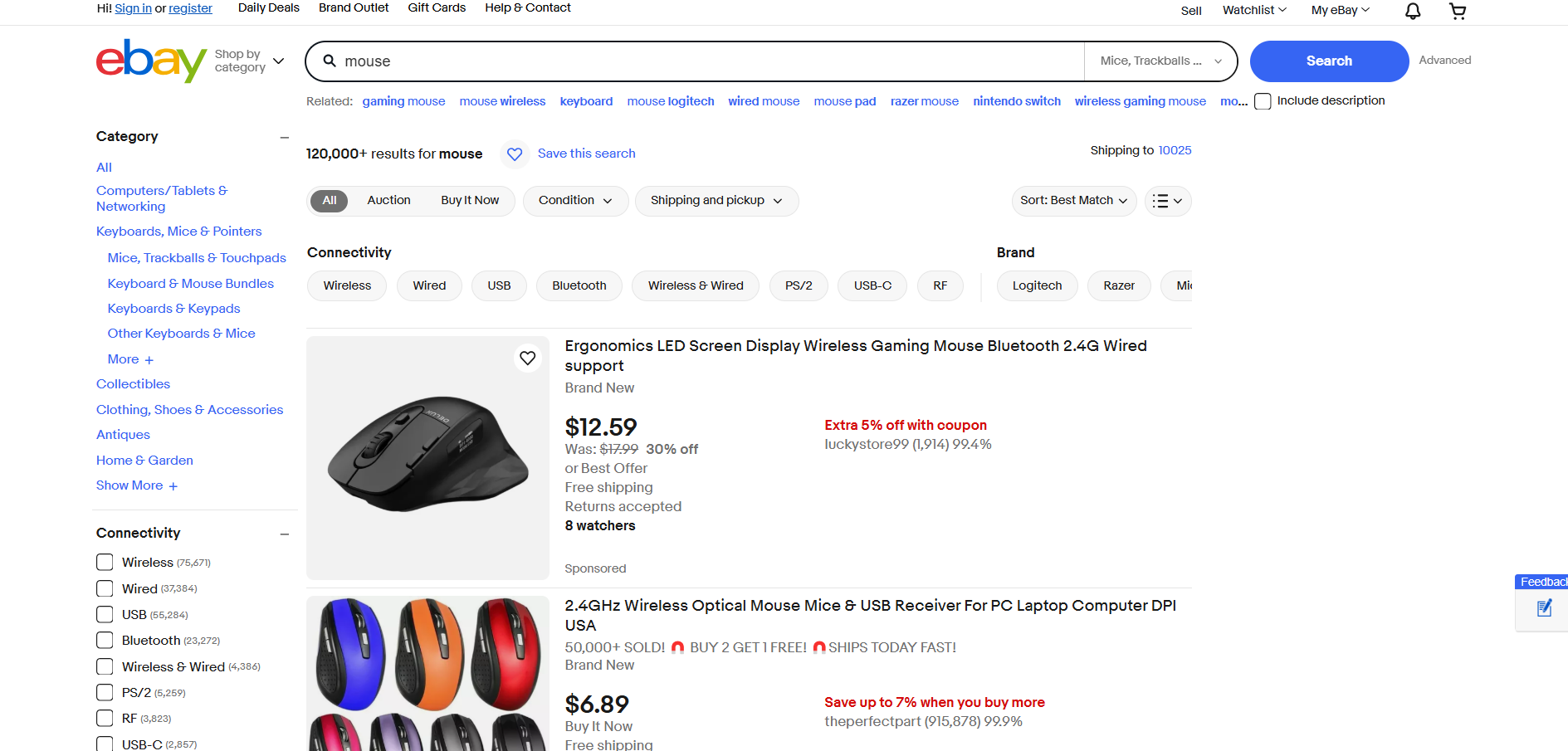
eBayは商品のレンダリングや動的データ読み込みにJavaScriptを使用していません。したがって、RequestsとBeautiful Soupを用いて以下のようにスクレイピングできます:
import requests
from bs4 import BeautifulSoup
import json
# 対象ページ
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# eBay検索ページへのGETリクエスト送信
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# BeautifulSoupでページ内容を解析
soup = BeautifulSoup(response.text, "html.parser")
# スクレイピングしたデータの保存先
products = []
# ページ上の全商品要素を選択
product_elements = soup.select("li.s-item")
# それらを反復処理
for product_element in product_elements:
# スクラッピングロジック
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
image_element = product_element.select("img")[0]
image = image_element["src"]
# スクレイピングしたデータで新しいオブジェクトを作成
product = {
"url": url,
"name": name,
"image": image
}
# スクレイピングした製品リストに追加
products.append(product)(product)
# データをJSONファイルにエクスポート
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)eBayのECサイトウェブスクレイピングスクリプトを実行すると、以下の結果が生成されます:
[
{
"url": "https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f:g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "2.4GHz ワイヤレス光学式マウス パソコン/ノートパソコン用 DPI USA",
"image": "https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp"
},
{
"url": "https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "人間工学設計 LED スクリーン表示 ワイヤレスゲーミングマウス Bluetooth 2.4G 有線接続対応",
"image": "https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp"
},
// 簡略化のため省略...
{
"url": "https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
"name": "Razer x Sanrio Kuromi DeathAdder Gaming Mouse and Mouse Pad Combo",
"image": "https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp"
}
]
すごい!Pythonを使ったECサイトデータスクレイピングスクリプトの例をいくつか見ましたね!
eコマースウェブスクレイピングの課題とその克服方法
上記の例では、いくつかのECサイトから商品名、URL、画像URLといった基本情報を抽出することに焦点を当てました。この単純さからECスクレイピングは容易に思えるかもしれませんが、実際にはいくつかの理由によりはるかに複雑です:
- 動的なページ構造:eコマースプラットフォームは頻繁にページデザインを更新するため、スクリプトの継続的なメンテナンスが必要となります。
- 多様な商品ページ:商品によって表示されるデータセットが異なり、レイアウトも全く異なる場合があります。
- 動的な価格設定:期間限定セール、割引、地域限定オファーなどにより、正確な価格データのスクレイピングは困難です。
さらに、Amazonなどの主要ECサイトはCAPTCHAなどの高度なスクレイピング対策を採用しています:
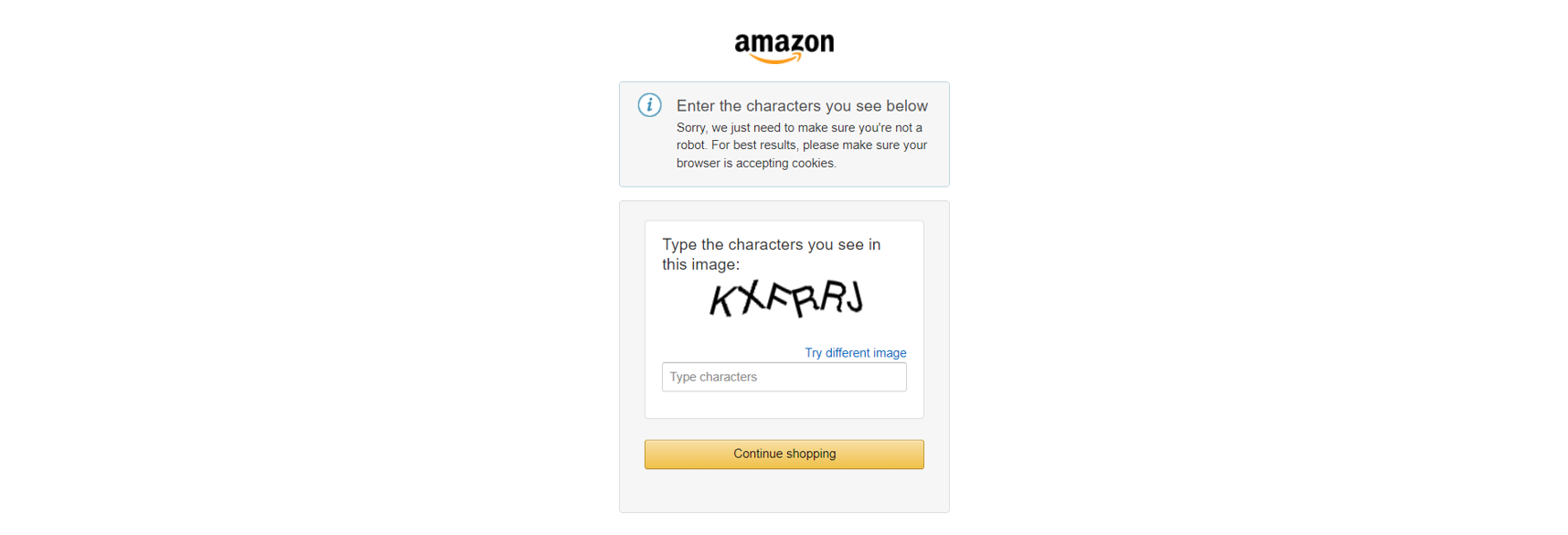
あるいは、同様にJavaScriptによる妨害も存在します:

これらの障壁を克服するには:
- 高度なスクレイピング技術を習得する:PythonによるCAPTCHA回避ガイドを参照し、実践的なヒントを得るための詳細なスクレイピングチュートリアルを確認してください。
- 高度な自動化ツールの活用:Playwright Stealthのような堅牢なツールを活用し、ボット対策機能を持つサイトのスクレイピングを実現します。
それでも最も効率的な解決策は、専用のeコマーススクレイパーAPIを利用することです。
Bright DataのeコマーススクレイパーAPIは、Amazon、Target、Walmart、Lazada、Shein、Shopeeなどのeコマースプラットフォームからデータを抽出する信頼性の高いソリューションです。主な利点は以下の通りです:
- 商品タイトル、販売者名、ブランド、説明、レビュー、初期価格、通貨、在庫状況、カテゴリなどの構造化された詳細情報を取得。
- サーバーやプロキシの管理、ウェブサイトブロック回避に関する懸念を解消。
- CAPTCHAやJavaScriptによる妨害を回避。
今すぐeコマーススクレイピングプロセスを効率化しましょう!
まとめ
本記事では、eコマーススクレイパーの定義と、eコマースウェブページから抽出可能なデータの種類について解説しました。eコマースウェブスクレイピングスクリプトがどれほど高度であっても、ほとんどのサイトは自動化された活動を検知し、アクセスをブロックします。
解決策は、様々なプラットフォームから確実にeコマースデータを取得するために特別に設計された強力なeコマーススクレイパーAPIです。これらのAPIは、以下のような構造化され包括的なデータを提供します:
- AmazonスクレイパーAPI:Amazonからタイトル、販売者名、ブランド、説明、レビュー、初期価格、通貨、在庫状況、カテゴリ、ASIN、販売者数などのデータを収集します。
- eBayスクレイパーAPI:ASIN、販売者名、マーチャントID、URL、画像URL、ブランド、商品概要、説明、サイズ、カラー、最終価格などのデータを収集。
- ウォルマートスクレイパーAPI:URL、SKU、価格、画像URL、関連ページ、配送・店頭受取可否、ブランド、カテゴリー、商品ID、説明などのデータを収集。
- Target スクレイパー API:URL、商品ID、タイトル、説明、評価、レビュー数、価格、割引、通貨、画像、販売者名、オファー、配送ポリシーなどのデータを収集します。
- Lazada スクレイパー API:URL、タイトル、評価、レビュー、初期価格と最終価格、通貨、画像、販売者名、商品説明、SKU、カラー、プロモーション、ブランドなどのデータをスクレイピングします。
- Shein スクレイパー API:商品名、説明、価格、通貨、色、在庫状況、サイズ、レビュー数、メイン画像、国コード、ドメインなどのデータを取得します。
- Shopee スクレイパー API: URL、ID、タイトル、評価、レビュー、価格、通貨、在庫状況、お気に入り、画像、ショップURL、評価数、登録日、フォロワー数、販売状況、ブランドなどのデータをスクレイピングします。
特定商品のデータスクレイピングには、当社のウェブスクレイピングAPIをご検討ください。スクレイパー構築が得意でない場合は、すぐに使えるECデータセットをご活用ください。
Bright Dataの無料アカウントを今すぐ作成し、スクレイパーAPIをお試しいただくか、データセットをご覧ください。






