

ウェブスクレイピングは転換期を迎えている。従来の方法は洗練されたボット対策に阻まれ、開発者は常に脆弱なスクリプトにパッチを当てているからだ。それらはまだ機能するものの、その限界は明らかで、特に回復力とスケーラビリティを提供する最新のAIネイティブ・スクレイピング・インフラストラクチャと比較すると、その限界は明らかだ。AIエージェント市場は2030年までに78億4,000万ドルから526億2,000万ドルに成長すると言われており、データアクセスの未来はインテリジェントで自律的なシステムにある。
CrewAIの自律型エージェントフレームワークとBright Dataの堅牢なインフラストラクチャを組み合わせることで、ボット対策の障壁を理由付けして克服するスクレイピングスタックを手に入れることができます。このチュートリアルでは、信頼性の高いリアルタイムデータを提供するAIを搭載したスクレイピングエージェントを構築します。
旧式のスクレイピングの限界
従来のスクレイピングは脆く、静的なCSSやXPathセレクタに依存しているため、フロントエンドに手を加えると壊れてしまいます。主な課題は以下の通りです:
- ボット対策。CAPTCHA、IPスロットリング、フィンガープリンティングは、単純なクローラーをブロックします。
- JavaScriptを多用するページ。React、Angular、Vueはブラウザ内でDOMを構築するため、生のHTTP呼び出しはほとんどのコンテンツを見逃す。
- 構造化されていないHTML。一貫性のないHTMLと散在するインライン・データは、使用前に大量の解析と後処理を必要とする。
- スケーリングのボトルネック。プロキシ、再試行、継続的なパッチ適用をオーケストレーションすることは、疲弊し、終わりのない運用負担となります。
CrewAIとBright Dataがスクレイピングを効率化する方法
自律型スクレーパーの構築は、適応力のある「頭脳」と弾力性のある「身体」という2つの柱にかかっている。
- CrewAI (The Brain)。オープンソースのマルチエージェントランタイムで、エンドツーエンドのスクレイピングジョブを計画、推論、調整できるエージェントの “クルー “をスピンアップする。
- Bright Data MCP(本体)。各リクエストをBright DataのUnlockerスタック(IPのローテーション、CAPTCHAの解決、ヘッドレスブラウザの実行)に通すライブデータゲートウェイで、LLMはクリーンなHTMLまたはJSONを一発で受け取ることができる。Bright Dataの実装は、AIエージェントのための信頼できるデータソースとして業界をリードしています。
この頭脳と肉体のコンボにより、エージェントはあらゆる現場で思考し、検索し、適応することができる。
CrewAIとは何か?
CrewAIは、協調的なAIエージェントをオーケストレーションするためのオープンソースのフレームワークです。各エージェントの役割、目標、ツールを定義し、それらをクルーにグループ分けしてマルチステップワークフローを実行します。
コア・コンポーネント
- エージェント。 役割、目標、オプションのバックストーリーを持つLLM駆動のワーカーで、モデルのドメインコンテキストを与える。
- タスク。1つのエージェントのための、十分にスコープされた1つのジョブと、品質ゲートとして機能するexpected_output。
- ツール。HTTPフェッチ、DBクエリ、Bright Dataのスクレイピング用MCPエンドポイントなど、エージェントが呼び出すことができる呼び出し可能なもの。
- クルー。1つの目的に向かって働くエージェントの集合体とそのタスク。
- プロセス。タスクの順序、委譲、再試行を制御する、逐次的、並列的、階層的な実行計画。
スペシャリストがそれぞれのスライスを処理し、結果を伝え、必要に応じてエスカレーションする。
モデル・コンテキスト・プロトコル(MCP)とは?
MCPは、オープンなJSON-RPC 2.0標準であり、AIエージェントは、単一の構造化されたインターフェースを介して、外部のツールやデータソースを呼び出すことができます。モデル用のUSB-Cポートと考えてください。
Bright DataのMCPサーバーは、Bright Dataのスクレイピングスタックにエージェントを直接配線することで、この標準を実践に移し、MCPによるウェブスクレイピングを従来のスタックよりも強力にするだけでなく、はるかにシンプルにしています:
- ボット対策バイパス。リクエストは、Web Unlockerと195カ国にまたがる1億5千万以上の回転する住宅用IPのプールを介して流れます。
- 動的サイトのサポート。専用のスクレイピングブラウザがJavaScript をレンダリングするため、エージェントは完全にロードされた DOM を見ることができます。
- 構造化された結果。多くのツールはクリーンなJSONを返し、カスタムパーサーをカットする。
サーバーは、一般的なURLフェッチからサイト固有のスクレイパーまで、50以上の既製ツールを公開しているため、CrewAIエージェントは1回の呼び出しで商品価格、SERPデータ、またはDOMスナップショットを取得することができます。
初めてのAIスクレイピング・エージェントの構築
Amazonの商品ページから詳細を抽出し、構造化されたJSONとして返すCrewAIエージェントを作ってみよう。いくつかの行を調整するだけで、同じスタックを別のサイトに簡単にリダイレクトすることができます。
前提条件
- Python 3.11– 安定性のために推奨。
- Node.js + npm– Bright Data MCPサーバーの実行に必要です。
- Python仮想環境– 依存関係を隔離しておく。
- Bright Dataアカウント–サインアップしてAPIトークンを作成します。
- Google Gemini APIキー–Google AI Studioでキーを作成します(クリック+ APIキーを作成)。無料ティアでは、1分あたり15リクエスト、1日あたり500リクエストが可能です。課金プロファイルは必要ありません。
アーキテクチャの概要
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON Outputステップ1.環境のセットアップとインポート
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .envステップ 2.APIキーとゾーンを設定する
プロジェクトのルートに.envファイルを作成する:
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"必要だ:
- APIトークン。新しいAPIトークンを生成します。
- ウェブアンロッカーゾーン新しいWeb Unlockerゾーンを作成します。省略すると、
mcp_unlockerというデフォルト・ゾーンが作成されます。 - ブラウザAPIゾーン。新しいブラウザAPIゾーンを作成する。JavaScriptを多用するターゲットにのみ必要です。ゾーンのOverviewタブに表示されているユーザー名文字列をコピーする。
- Google Gemini APIキー。Prerequisites で作成済み。
ステップ3.LLMの設定(ジェミニ)
LLM(Gemini1.5フラッシュ)を決定論的出力用に設定する:
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)ステップ 4.Bright Data MCPのセットアップ
Bright Data MCPサーバーを設定します。これはCrewAIにサーバーの起動方法と認証情報の渡し方を指示します:
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)これは、*npx @brightdata/mcp*をサブプロセスとして起動し、MCP標準を介して50以上のツール(執筆時点では≈57)を公開する。
ステップ 5.エージェントとタスクの定義
ここでは、エージェントのペルソナと、エージェントが行う必要のある具体的な仕事を定義します。効果的なCrewAIの実装は80/20ルールに従います:80%の労力をタスクの設計に、20%の労力をエージェントの定義に費やします。
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)各パラメーターの役割は以下の通り:
- 役割 –CrewAIがすべてのシステムプロンプトに注入する短い役職名。
- ゴール –北極星の目標。CrewAIは各ループの後にこれを比較し、停止するかどうかを決定する。
- バックストーリー –ドメインの文脈は、トーンを導き、幻覚を減らす。
- tools –
BaseToolオブジェクトのリスト(例:MCPsearch_engine、scrape_as_markdown)。 - llm –CrewAIが思考→計画→行動→回答の各サイクルで使用するモデル。
- max_iter –エージェントの内部ループのハードキャップ(v0.30 +ではデフォルト20)。
- verbose –すべてのプロンプト、思考、ツールコールを標準出力にストリームする(デバッグに便利)。
- 説明 –アクション志向の指示が毎ターン注入される。
- expected_output –有効な回答の形式的な契約 (厳密な JSON を使用し、末尾にコンマは付けません)。
- agent –
Crew.kickoff()の特定のエージェントインスタンスにこのタスクをバインドします。
ステップ6.クルーの集合と実行
このパートは、エージェントとタスクをCrewに組み立て、ワークフローを実行します。
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
print(f"n[ERROR] Scraping failed: {str(e)}")ステップ7.スクレーパーを動かす
ターミナルからスクリプトを実行する。エージェントがタスクを計画し、実行するまでの思考過程がコンソールに表示されます。
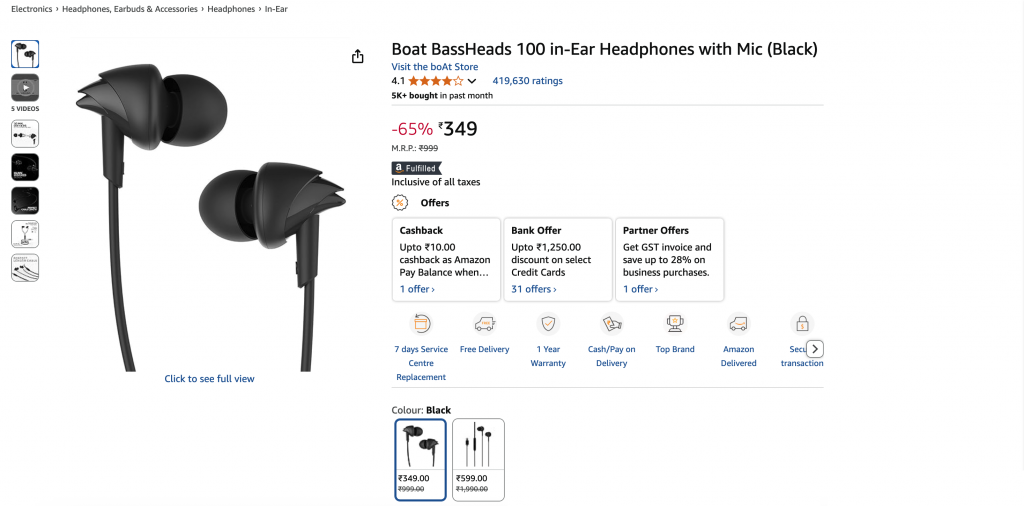
最終的な出力は、きれいなJSONオブジェクトになる:
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}他のターゲットへの適応
エージェントベースの設計の本当の強みは、その柔軟性である。Amazonの商品の代わりにLinkedInの投稿をスクレイピングしたいですか?エージェントの役割、ゴール、バックストーリー、タスクの説明と 期待されるアウトプットを更新するだけです。基礎となるコードとインフラを含め、他のすべては全く同じままです。
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""出力はきれいなJSONオブジェクトになる:
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2026-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}コストの最適化
ブライトデータのMCPは使用量ベースなので、リクエストが増えるたびに請求額が増えます。いくつかの設計上の選択により、コストを抑えることができます:
- ターゲットを絞ったスクレイピング。ページやデータセット全体をクロールするのではなく、必要なフィールドのみをリクエストします。
- キャッシュCrewAIのツールレベルのキャッシュ
(cache_function)を有効にすると、コンテンツが変更されていない場合に呼び出しをスキップし、時間とクレジットの両方を節約できます。 - 効率的なツール選択。 Web Unlockerゾーンをデフォルトとし、JavaScriptレンダリングが不可欠な場合のみBrowser APIゾーンに切り替える。
-
max_iterを設定する。すべてのエージェントに適切な上限値を与えて、壊れたページで永遠にループしないようにします。(max_rpmでリクエストをスロットルすることもできます)。
これらのプラクティスに従うことで、CrewAIエージェントは安全性、信頼性、コスト効率を維持し、Bright Data MCP上の本番ワークロードに対応することができます。
次の記事
MCPエコシステムは拡大を続けている:OpenAIのResponses APIと Google DeepMindのGemini SDKは、現在MCPをネイティブにサポートしており、長期的な互換性と継続的な投資を保証しています。
CrewAIはマルチモーダル・エージェント、よりリッチなデバッグ、エンタープライズRBACを展開しており、Bright DataのMCPサーバーは60以上の既製ツールを公開し、現在も成長を続けている。
エージェントフレームワークと標準化されたデータアクセスは、AIを搭載したアプリケーションのためのウェブインテリジェンスの新しい波を解き放ちます。MCPをOpenAI Agents SDKにプラグインするためのガイドは、強固なデータパイプがいかに不可欠であるかを示しています。
結局のところ、あなたは単なるスクレーパーを構築しているのではなく、未来のウェブのために構築された適応性のあるデータワークフローを編成しているのだ。
もっとスケールが必要ですか?スクレーパーの維持やブロックとの戦いをスキップして、構造化データをリクエストするだけです:
- Crawl API– フルサイト抽出を大規模に。
- ウェブスクレーパーAPI– 120以上のドメイン固有のエンドポイント。
- SERP API– 手間のかからない検索エンジンのスクレイピング。
- データセット・マーケットプレイス– 新鮮で検証済みのデータセットをオンデマンドで提供。
次世代のAIアプリケーションを構築する準備はできましたか?ブライトデータのAI製品群をご覧いただき、シームレスなライブウェブアクセスがエージェントにもたらす効果をご確認ください。Qwen-AgentとGoogle ADK の MCP ガイドをご覧ください。






