

このチュートリアルでは、以下のことを学びます:
- ウェブスクレイピングでBilibiliからデータを取得する意義
- Bilibiliからスクレイピング可能なデータの種類
- AIトレーニング(およびその他のユースケース)のためのデータを収集するためのBilibiliスクレイピング・ダウンロードパイプライン構築方法
- 本番環境対応のエンタープライズグレードアプリケーションには、専用のBilibiliスクレイパーが最適な理由
複雑な作業は不要:Bright DataのBilibiliスクレイパーは、組み込みのボット回避機能と99.99%の稼働率を備え、エンタープライズ規模で即利用可能な動画データを提供します。
さっそく見ていきましょう!
Bilibiliをスクレイピングする理由:想定されるユースケース
Bilibiliは上海発の動画プラットフォームで、「中国のYouTube」と称されることが多い。2009年にサービスを開始し、月間アクティブユーザー数2億9400万人以上、1日あたりの動画再生回数30億回以上を誇るZ世代の巨大プラットフォームへと成長した。
当初はACG(アニメ・漫画・ゲーム)中心でしたが、現在ではテクノロジー、教育、ライフスタイル、音楽、eスポーツ、ライブ配信まで多岐にわたります。Bilibiliはリアルタイムの「弾幕」コメント機能と活発なコミュニティで知られ、ユーザー生成コンテンツ、インフルエンサー文化、ゲーム、広告を同一のデジタルエコシステムに統合しています。
Bilibiliの急成長を考慮すると、同プラットフォームのデータへのアクセスは以下のような多様なユースケースを支援します:
- 動画AIトレーニング:大規模なBilibili動画データセットは、コンピュータビジョン、音声認識、マルチモーダルLLM、レコメンデーションシステム、コンテンツモデレーションモデルを強化します。これは豊富なメタデータ、文字起こし、エンゲージメントシグナル、生の視聴覚コンテンツによって可能となります。
- トレンド・コンテンツ分析:カテゴリー、タグ、視聴回数、エンゲージメント指標を分析し、Z世代やACGコミュニティ内で台頭するトピック、急成長中のクリエイター、拡散しやすいフォーマットを特定します。
- クリエイター・インフルエンサー分析:アップローダーのパフォーマンス、フォロワー増加率、エンゲージメント比率、投稿頻度を追跡し、中国におけるKOL(キーオピニオンリーダー)の影響力をベンチマークし、インフルエンサーマーケティング戦略を最適化します。
- 視聴者感情分析:弾幕(弾幕コメント)や標準コメントを分析し、視聴者の反応、感情的トーン、文化的参照、リアルタイムフィードバックパターンを大規模に把握します。
- 競合ベンチマーク:類似分野におけるブランドチャンネル、スポンサードキャンペーン、カテゴリーリーダーを、視聴回数、インタラクション、コンテンツ戦略のモニタリングを通じて比較。
- 市場参入とローカライゼーション調査:コンテンツ嗜好、言語使用、トレンドテーマを評価し、中国のデジタルネイティブ層向けに製品、キャンペーン、メッセージングを最適化。
Bilibiliから取得可能なデータ
Bilibiliをスクレイピングする際、取得可能なデータフィールドは複数存在します。これらは収集対象となるページの種類や全体的な目標によって異なります。したがって、調査価値のある興味深いBilibiliデータカテゴリは複数存在します。
動画メタデータ
特定のBilibili動画を対象とする場合、以下の情報を収集できます:
- 基本情報:タイトル、説明、カバー画像URL、動画ID、動画再生時間など
- アップロード詳細:公開日時とカテゴリ/パーティション(例:「アニメ」、「テック」、「音楽」)。
- 分類情報:タグ、キーワード、動画がオリジナルコンテンツか転載か。
- エンゲージメント統計:総再生回数、高評価数、コイン数、お気に入り登録数、シェア数
- コメント:動画に直接表示されるコメント。コメント本文、タイムスタンプ、色、フォントサイズ、表示モードを含みます。
- 字幕:AI生成またはアップローダー提供の文字起こし。
ユーザーとクリエイターのプロフィール
Bilibiliクリエイターページをスクレイピングする場合、以下の情報を取得可能:
- 本人確認情報:ユーザー名、ユーザーID、性別、プロフィール画像など。
- ソーシャル指標:フォロワー数、フォロー数、全動画の合計いいね数。
- 個人詳細:ユーザー紹介文、誕生日、アカウントレベル。
- アカウントステータス:認証バッジ(例:「公式ミュージシャン」)と会員ランク(例:VIP/ビッグメンバー)。
- 作品リスト:特定クリエイターの公開済み動画全作品
検索および発見データ
Bilibiliの検索システムを活用して以下を取得することも可能です:
- 検索結果:特定のキーワードに一致する動画、ユーザー、またはライブ配信のリスト。
- トレンドデータ:人気検索キーワードと日次/週次ランキング。
- ライブ配信情報:ルームID、配信タイトル、配信状態、同時視聴者数(人気指数)。
PythonでBilibiliスクレイパーと動画ダウンロードパイプラインを構築する:ステップバイステップガイド
このガイドセクションでは、「テック」カテゴリページからBilibili動画メタデータをスクレイピングする方法を学びます:
※これは一例です。同じロジックはホームページを含む他のカテゴリページにも適用可能です。
そのページから抽出した動画URLを使用し、次にそれらを1つずつダウンロードする2つ目のスクリプトを構築します。ダウンロードした動画ファイルは、最終的にAI/MLトレーニングパイプラインに直接投入できるようになります。
以下の手順に従ってください!
前提条件
このチュートリアルを実行するには、以下の環境が整っていることを確認してください:
以下のコマンドでFFmpegがインストールされていることを確認してください:
ffmpeg -version以下のような出力が表示されるはずです: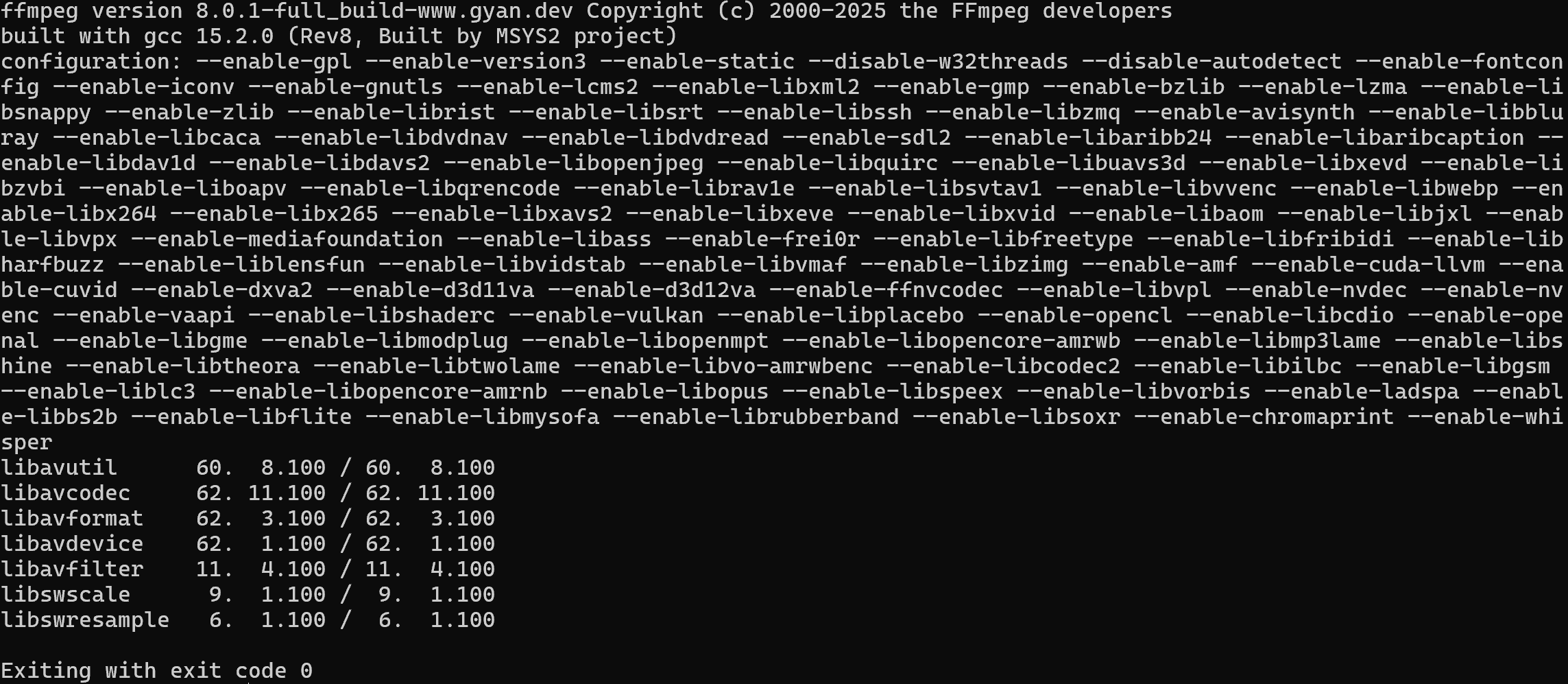
エラーが表示された場合は、お使いのOSの公式インストールガイドに従ってFFmpegをインストールしてください。
ステップ #0: Bilibili を理解する
コードを書く前に、対象サイトを調査する時間を確保してください。静的サイトか動的サイトかを理解する必要があります。ウェブスクレイピングの計画はその判断に依存します。
静的サイトの場合、シンプルなHTTPクライアントとHTMLパースで十分かもしれません。動的サイトの場合は、ブラウザ自動化ツールが必要です。詳細は、ウェブスクレイピングにおける静的コンテンツと動的コンテンツの比較ガイドをご覧ください。
ブラウザで対象ページにアクセスし、操作を開始してください。無限スクロールのUIパターンが採用されている点に注目してください: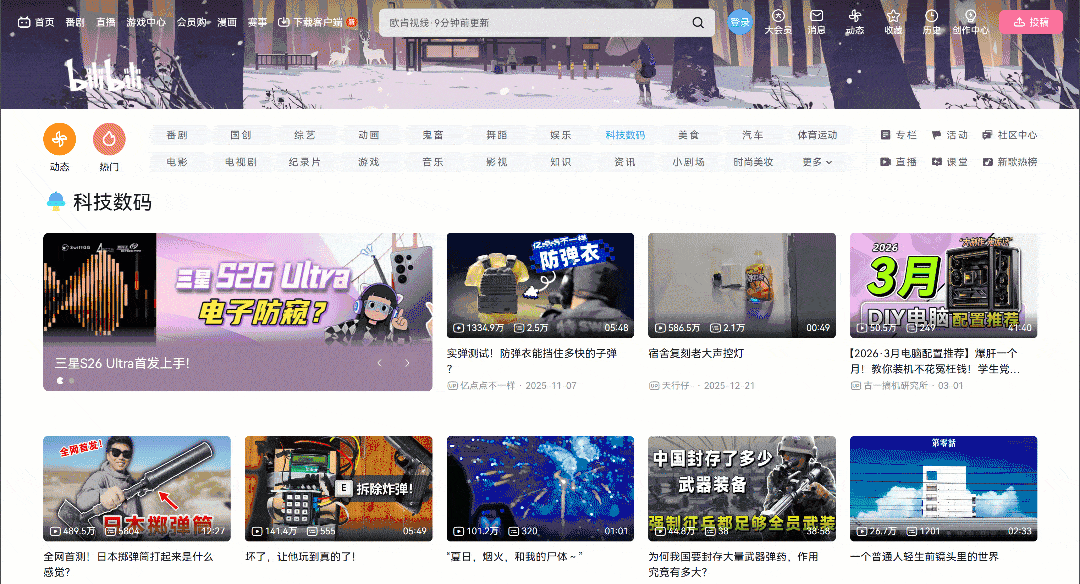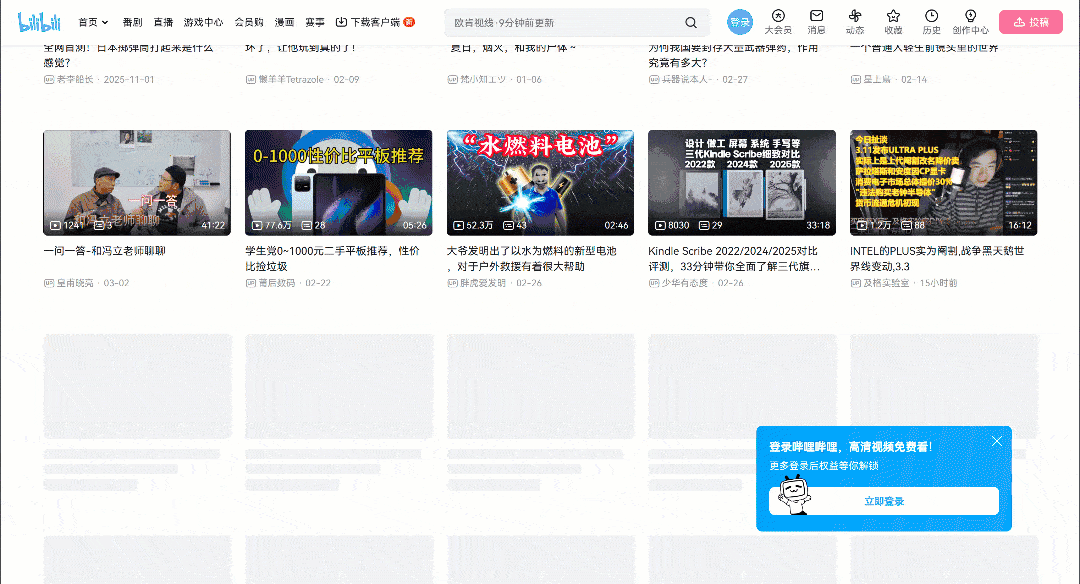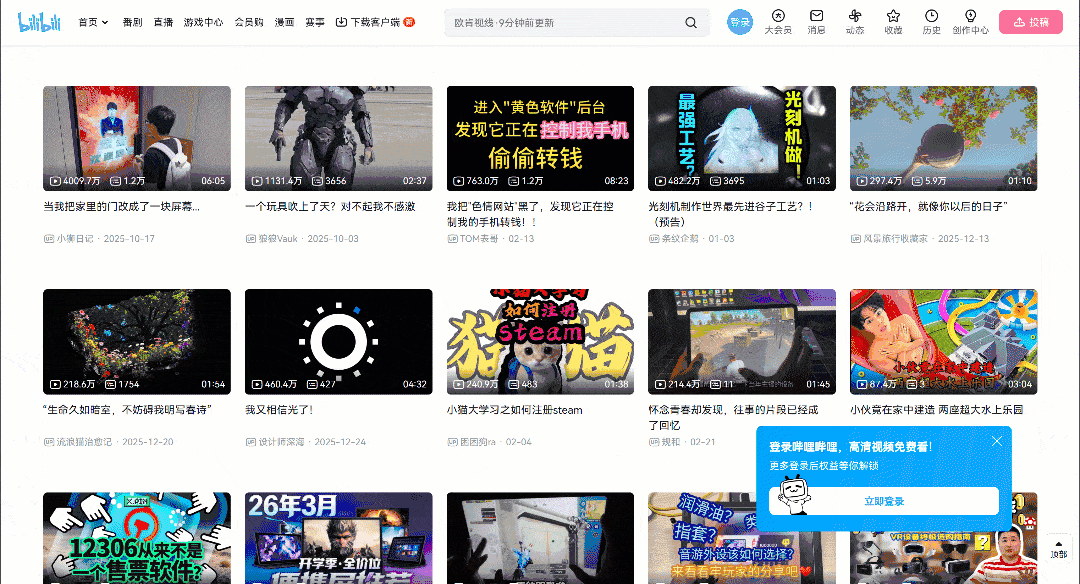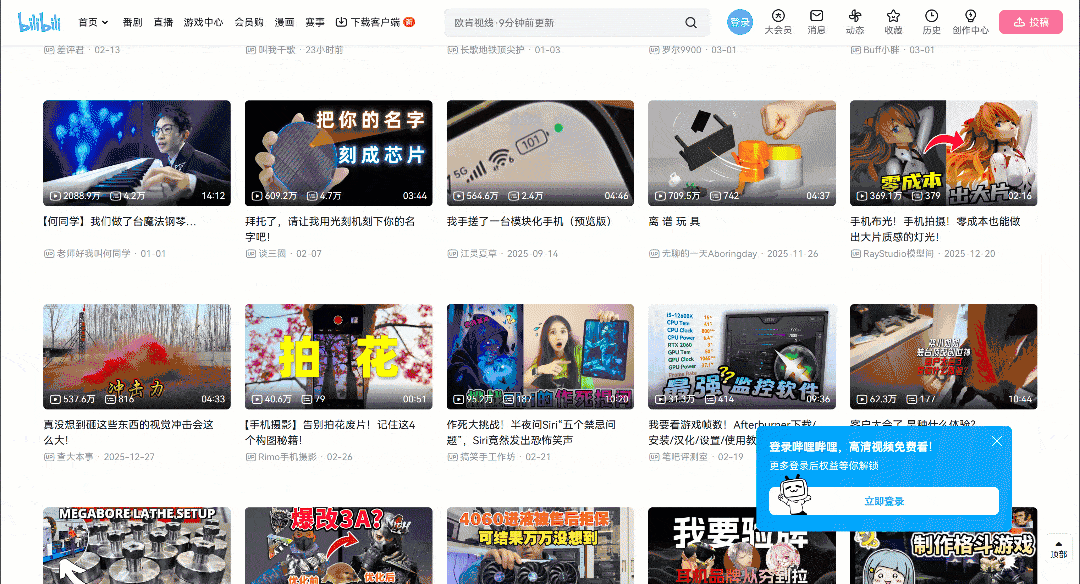
スクロールダウンすると、新しいビデオカードが自動的に読み込まれます。この動作は、ウェブサイトが動的であることを示す指標です。具体的には、ユーザーの操作に基づいて新しいデータを取得・レンダリングするためにJavaScriptに依存しています。
そのため、単純なHTTPリクエストでは不十分です。コンテンツを適切にレンダリングしスクレイピングするにはブラウザ自動化ツールが必要です。本チュートリアルではPlaywrightを使用しますが、Selenium、SeleniumBase、NODRIVERなどのツールでも同様の処理が可能です。
ステップ #1: Playwrightプロジェクトの設定
まずターミナルを起動し、Bilibiliスクレイパー用の新規ディレクトリを作成します:
mkdir bilibili-スクレイパープロジェクトディレクトリに移動し、その中にPython仮想環境を作成します:
cd bilibili-スクレイパー
python -m venv .venv次に、お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionが適しています。
プロジェクトディレクトリのルートにscraper.pyという名前の新規ファイルを作成します。内容は以下のようになります:
bilibili-スクレイパー/
├── .venv/
└── scraper.py # <-----------IDEの統合ターミナルで仮想環境を有効化します。Linux/macOSでは以下を実行:
source .venv/bin/activateWindowsでは同等の操作として以下を実行します:
.venv/Scripts/activate仮想環境をアクティブ化した状態で、playwrightをインストールします:
pip install playwright必要なブラウザバイナリをダウンロードしてインストールを完了します:
python -m playwright install次に、スクレイパー.pyに以下の基本的なPlaywright設定を追加します:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# ヘッドレスモードで制御されたChromiumインスタンスを起動
browser = await p.chromium.launch(headless=False) # 本番環境ではTrueに設定
context = await browser.new_context()
page = await context.new_page()
# スクラッピングロジック...
# ブラウザを閉じ、リソースを解放
await browser.close()
if __name__ == "__main__":
asyncio.run(main())このスニペットはChromiumブラウザインスタンスを初期化し、Playwrightが制御できるようにします。開発中はheadless=Falseのままにしておくと、ブラウザの動作を視覚的に追跡できるので便利です。本番環境では、headlessモードを有効にしてリソース使用量を削減し、実行速度を向上させるため、headless=Trueに設定することを検討してください。
よくできました!これでブラウザ自動化によるBilibiliのウェブスクレイピングが可能なPython環境が整いました。
ステップ #2: 対象サイトへの接続
Playwrightを使用して、ターゲットとなるBilibiliの「技術」カテゴリページに移動します:
# ターゲット「テクノロジー」Bilibiliページ
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# ターゲットページに移動
await page.goto(target_bilibili_page)goto()関数は制御対象のブラウザに指定URLへのアクセスを指示し、ページ読み込み完了を待機します。
これで完了です!Bilibiliの目的ページに接続されました。
次のステップは、スクロール操作を自動化し、新しい動画カードが動的に読み込まれるようにすることです。追加コンテンツが表示されたら、それらのHTML要素からデータを抽出する準備が整います。
ステップ #3: 新しい動画カードを読み込む
前述の通り、Bilibiliのホームページとカテゴリページは無限スクロールのUIパターンを採用しています。初期状態では、表示される動画カードはわずかです。スクロールダウンすると、JavaScriptを介して動的に追加コンテンツが読み込まれます。
具体的には、ページは最初に.head-cardsHTML要素内に固定数の動画カード要素をロードします: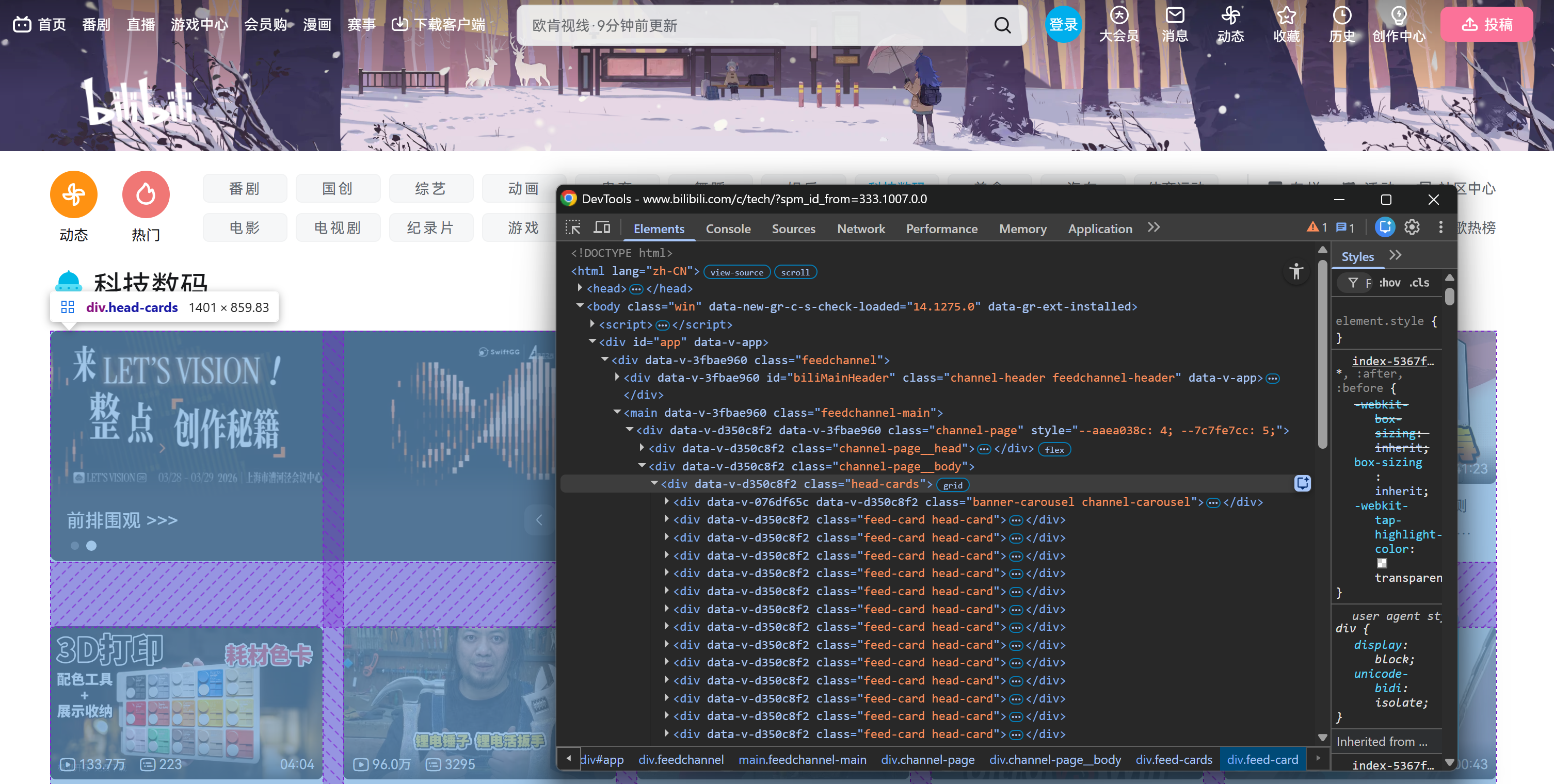
スクロール後、ページに.feed-cardsコンテナが追加されます。このセクションはスクロールを続けると新しい動画カードで動的に埋まっていきます: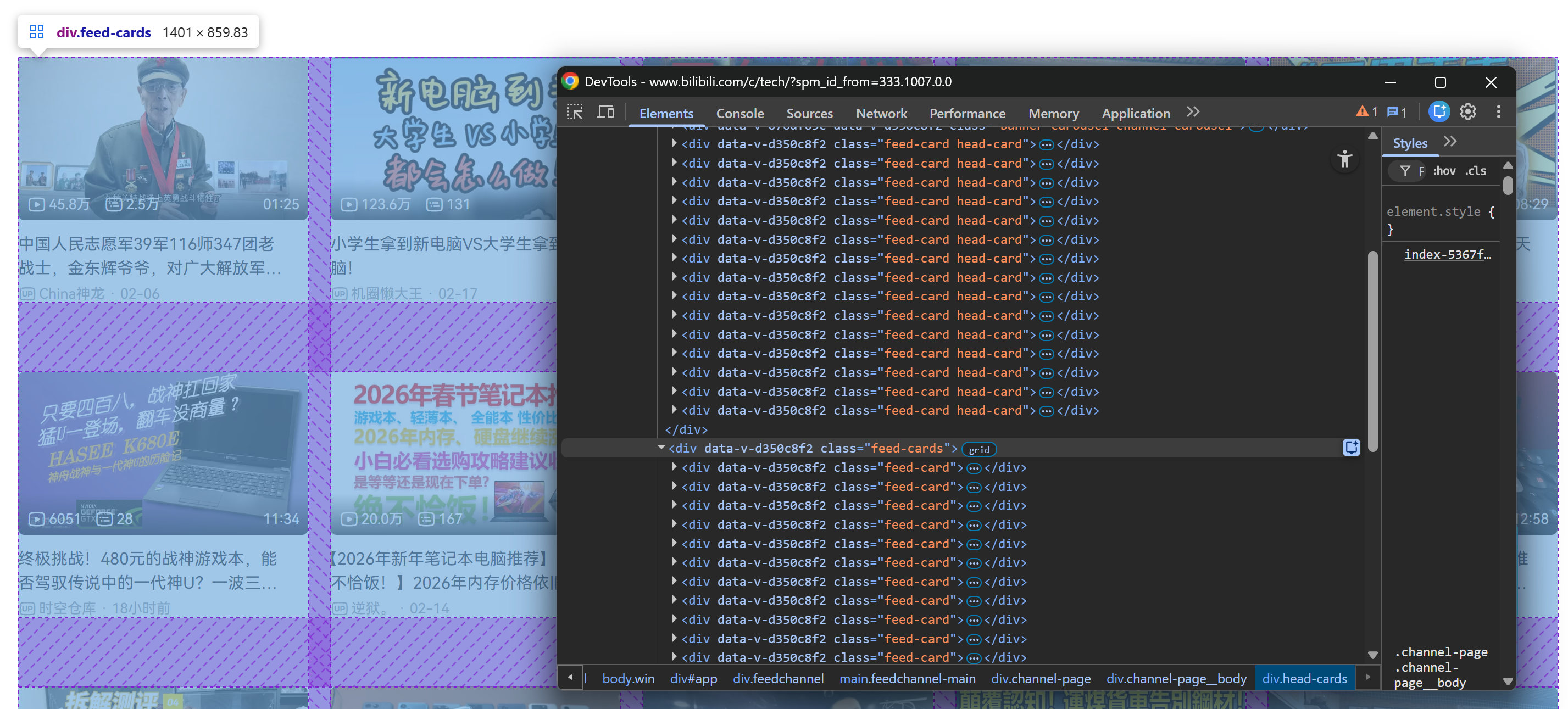
ここで重要なのは、すべての動画カード(初期ページ読み込み時に静的に存在するものも、スクロール中に動的に読み込まれるものも)が、以下のCSSセレクタで選択可能である点です:
.feed-cardこのBilibiliスクレイピングチュートリアルでは、少なくとも50本の動画を取得したいと仮定します。これを実現するには、複数のスクロール操作をシミュレートする必要があります。Playwrightはスクロール専用のAPIを提供していないため、ページコンテキスト内で直接シンプルなJavaScriptスクリプトを実行します:
for _ in range(3):
# 遅延読み込みを許可
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# 遅延読み込みを許可
await asyncio.sleep(2) このループはwindow.scrollTo()を3回実行し、各反復でページの上部から下部へスクロールします。asyncio.sleep()の呼び出しが重要な理由は以下の通りです:
- スクロール動作をより自然に見せるため。
- ボット対策メカニズムが作動するリスクを低減します。
- 次のスクロール前に遅延読み込みコンテンツが完全にレンダリングされる時間を確保する。
ビデオカードは動的に読み込まれるため、スクロール直後に存在すると仮定できません。代わりに、50枚目のカードがDOMにアタッチされるまで明示的に待機する必要があります。Playwrightでは次のように実装します:
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="attached")このコードは50番目の.feed-card要素(インデックスは0から始まるためnth(49))に対するPlaywrightロケーターを作成します。その後、wait_for()でその要素がDOMにアタッチされるまで待機します。
ここで、headfulモード(headless=False)でスクリプトを実行すると、ブラウザが自律的に3回スクロールする様子が確認できます:
意図通り、各スクロール後に新しいビデオカードが読み込まれます。
このステップを終えれば、ページ上に少なくとも50枚のビデオカードが存在すると確信できます。素晴らしい!
ステップ #4: ビデオカードの構造を理解する
正しいデータを抽出するには、まず各ビデオカードがDOM内でどのように構造化されているかを理解する必要があります。
まず、.head-cardsセクション内のビデオカードの一つを右クリックし、ブラウザの開発者ツールで検査します: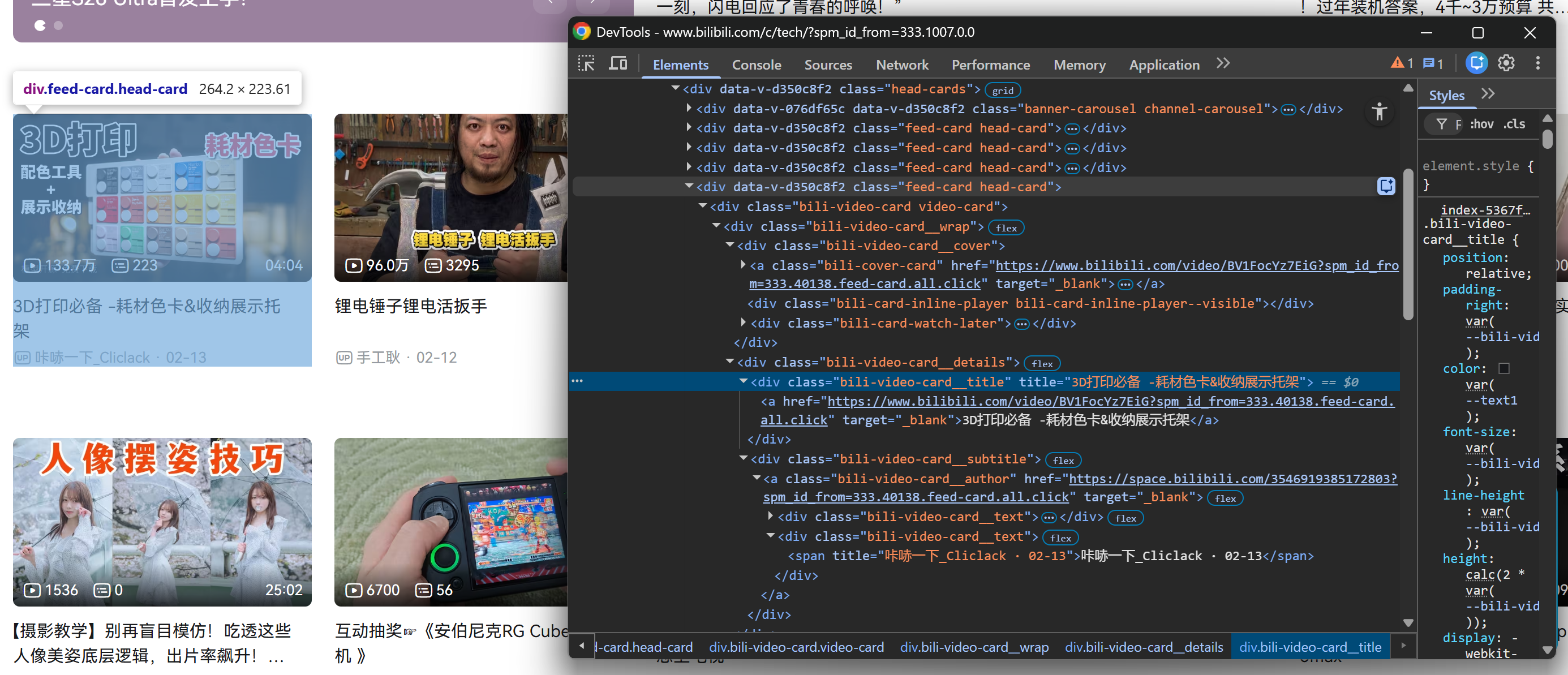
次に、読み込まれた.feed-cardsセクション内のビデオカードに対しても同じ手順を繰り返します: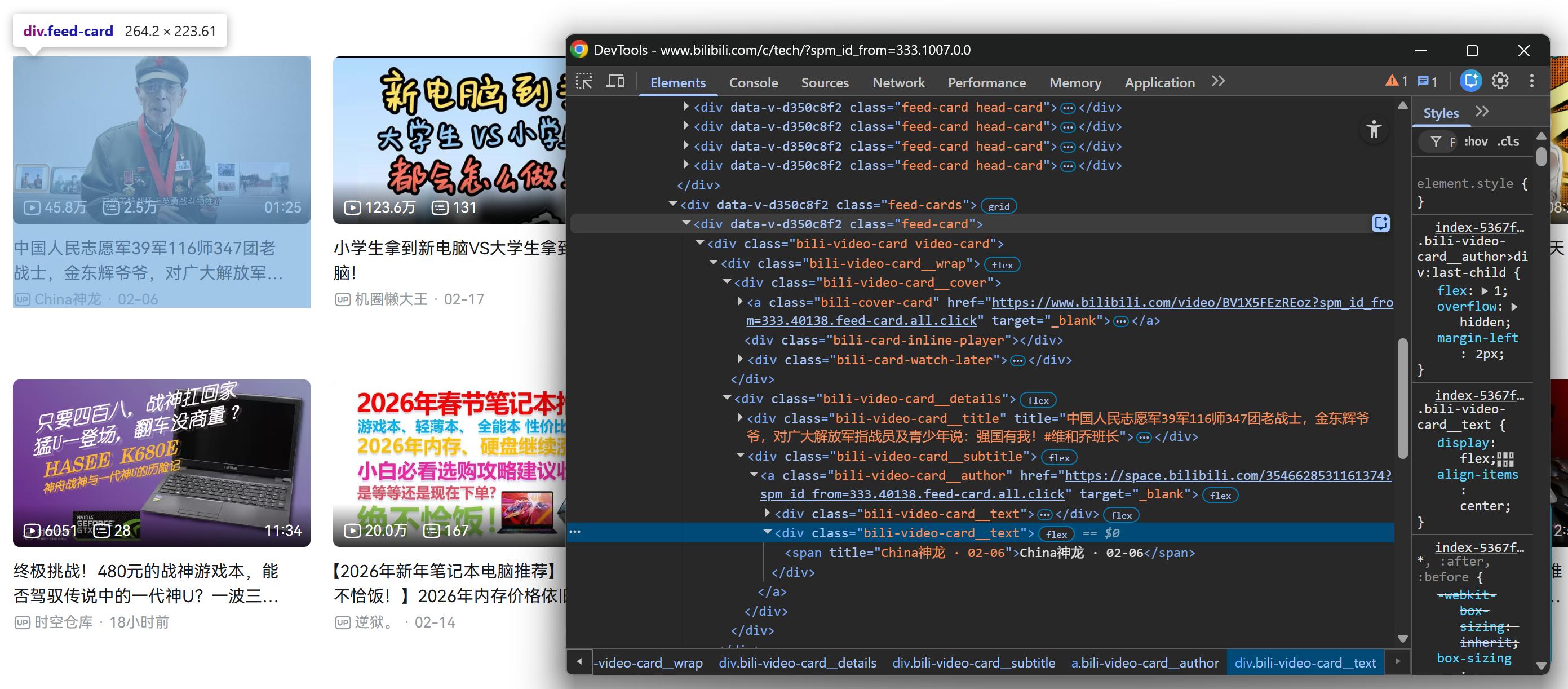
幸いなことに、すべての.feed-card要素は同じ内部構造を共有しています。つまり、初期ページレンダリング時に読み込まれたビデオカードと、スクロール後に動的に読み込まれたビデオカードを区別する必要はありません。同じセレクターで全てを対象にできます!
各ビデオカードから以下の情報を収集できる点に注目してください:
.bili-video-card__title a要素から動画タイトルを取得。- 同じタイトル
<a>ノードのhref属性から動画URLを取得。 .bili-video-card__subtitle span[title]から生のサブタイトル(著者名 + 公開日を含む)。.bili-video-card__author要素から著者のプロフィールURLを取得。
完璧です!DOM構造を理解したところで、次のステップはこの知識をプログラムによるBilibiliデータスクレイピングロジックに変換することです。
ステップ #5: 動画データのスクレイピング
対象ページには複数の動画カードが含まれていることを忘れないでください。したがって、スクレイピング結果を保存するためのデータ構造を最初に用意する必要があります。リストが最適です:
videos = []次に、すべての動画カードに対して前述の抽出ロジックを適用します:
for i in range(feed_card_count):
# データを抽出する現在の動画カードを取得
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# スクレイピングしたデータを保存
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)上記のスニペットは各動画カードに対して以下の処理を行います:
- タイトル、動画URL、生の字幕、および作者プロフィールURLを抽出します。
- サブタイトル文字列(
「<AUTHOR_NAME> · <DATE>」形式)をパースし、作者名と動画公開日を個別に抽出します。 - 構造化された
動画辞書を作成し、videosリストに追加します。
forループ終了時、videosリストには50以上の構造化されたBilibili動画オブジェクトが含まれます。素晴らしい!
ステップ #6: スクレイピングしたデータのエクスポート
スクレイピングしたデータを処理しやすくするため、videos.jsonファイルにエクスポートします:
import json
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)これでスクレイパー.pyを実行すると、以下のような構造化されたBilibili動画データを含むvideos.jsonファイルが生成されます: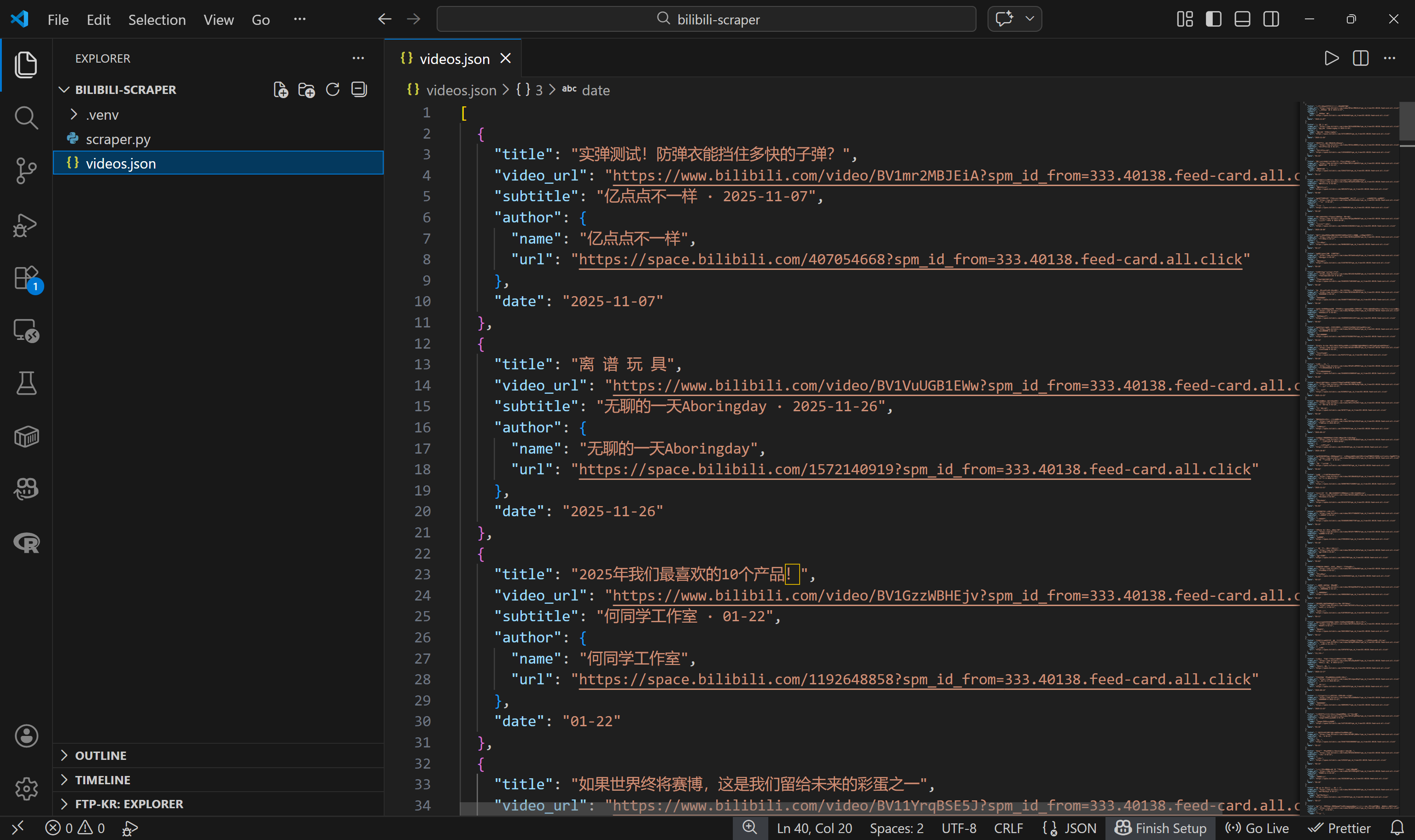
ミッション完了!多数の動画カードを含むページから始め、今ではそれらのメタデータが構造化されたJSONファイルに保存されました。
Bilibiliのスクレイピングが目的であれば、チュートリアルはここで終了しても構いません(完全なスクリプトは最終ステップを確認してください)。さらに一歩進んで動画自体をダウンロードしたい場合は、読み進めてください…
ステップ #7: Bilibili動画のダウンロード準備
先にスクレイピングしたURLからBilibili動画をダウンロードする最も簡単な方法は、yt-dlpを利用することです。
yt-dlpはBilibiliを含む数百のウェブサイトに対応した多機能なオーディオ/ビデオダウンローダーです。コマンドラインとPython APIの両方から利用可能で、ここではPython API経由でプログラム的に操作します。
仮想環境を有効にした状態で、yt-dlpをインストールします:
pip install yt-dlp次に、プロジェクトルートにvideo-downloader.pyという新しいファイルを追加します:
bilibili-スクレイパー/
├── .venv/
├── scraper.py
└── video-downloader.py # <-----------このファイルには、yt-dlpを利用したBilibili動画ダウンロードロジックを記述します。
video-downloader.pyスクリプトは以下の処理を行います:
videos.jsonファイルを読み込む。- 各動画の
video_urlを抽出する。 yt_dlpのYoutubeDLクラスを使用して動画ファイルをダウンロードする。
実装は以下の通りです:
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# 入力 JSON ファイルから動画データをロード
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"{INPUT_FILE}から{len(videos)}本の動画をロードしましたn")
# 出力フォルダの存在を確認
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] ダウンロード中: {video.get('title')}")
try:
ydl.download([video_url])
print(f"動画 #{index} ダウンロード完了n")
except Exception as e:
print(f"動画 #{index} ダウンロード失敗: {e}n")すごい!35行未満のコードで目的を達成できました。
ステップ #8: 動画ファイルのダウンロード
ffmpegがローカルにインストールされていることを確認し、video-downloader.pyスクリプトを実行します。ターミナルには以下のような出力が表示されるはずです: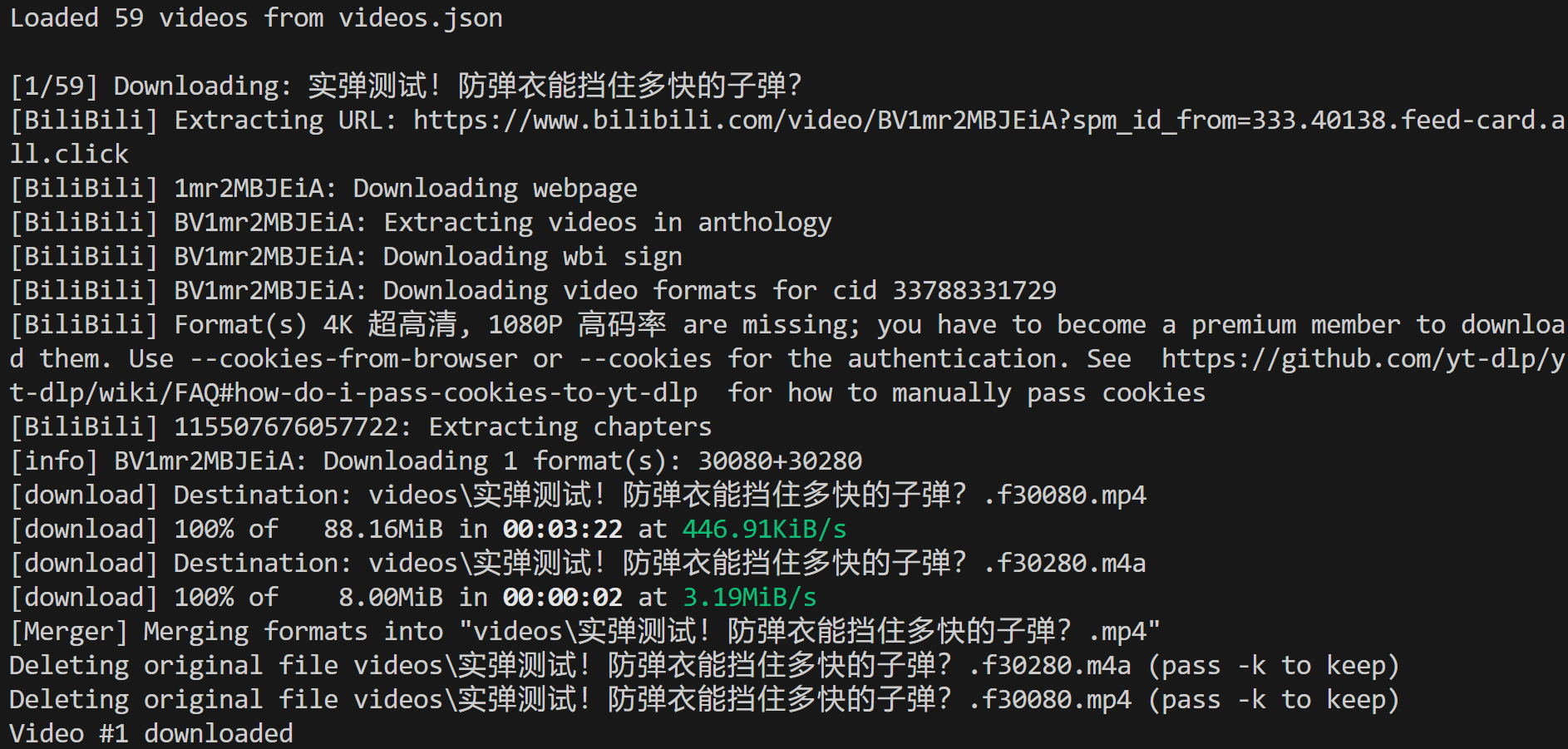
これは、videos.json入力ファイルから59本の動画が読み込まれ、最初の動画がローカルパスに正常にダウンロードされたことを示しています:
./videos/実弾テスト!防弾チョッキはどれほどの速さの弾丸を防げる?.mp4Visual Studio Codeでは、MP4動画ファイルが正確にこのパスに表示されます: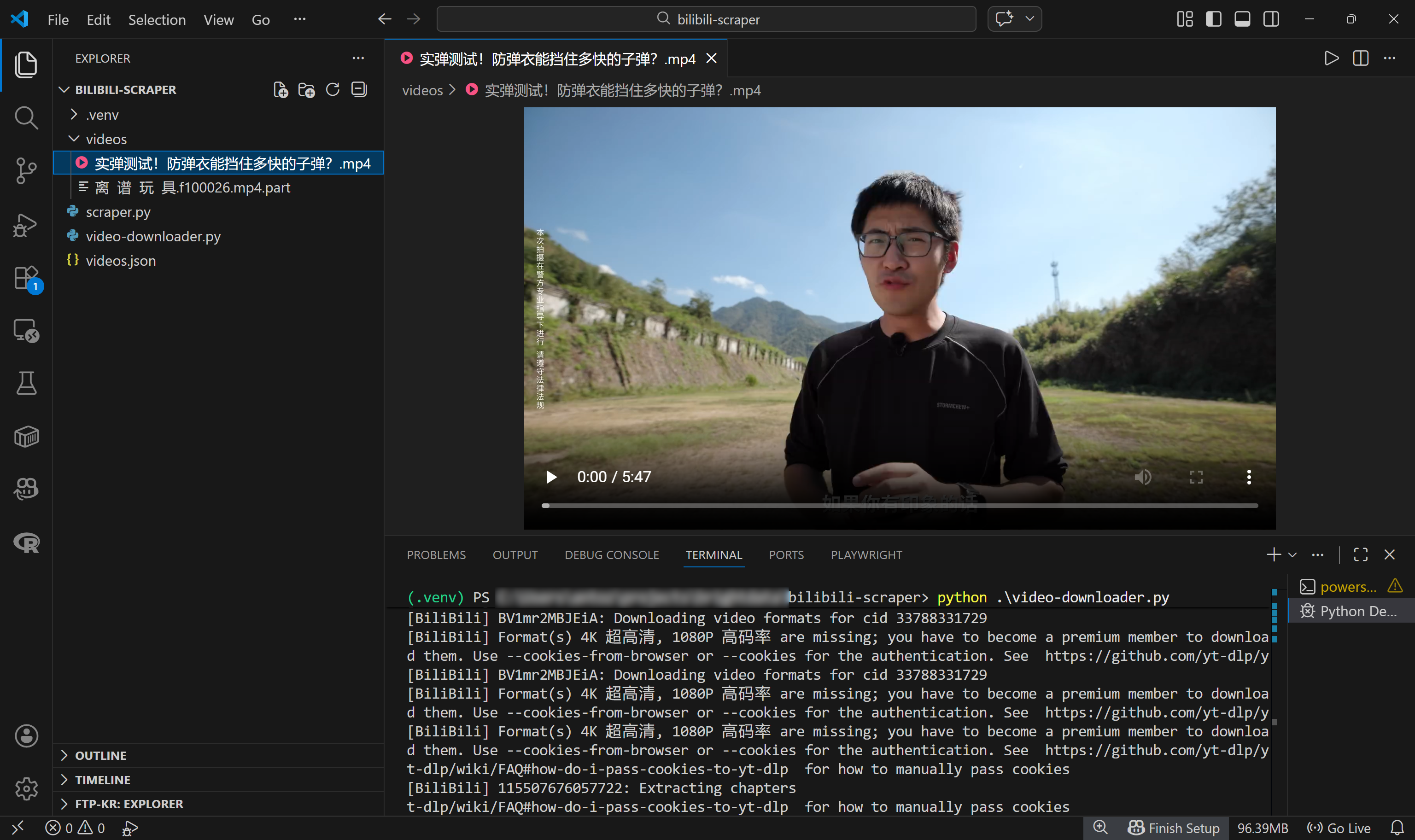
素晴らしい!これで新しい動画を発見するだけでなくダウンロードも行う、完全に自動化されたBilibiliシステムが完成しました。これらのファイルを使えば、マルチモーダル機械学習パイプラインによるAIモデルのトレーニングも可能です。
ステップ #9: 最終コード
scraper.pyファイルには以下のコードが含まれます:
# scraper.py
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
import json
async def main():
async with async_playwright() as p:
# ヘッドフルモードで制御されたChromiumインスタンスを起動
browser = await p.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
# 対象の「Tech」Bilibiliページ
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# 対象ページに移動
await page.goto(target_bilibili_page)
# ページ全体を3回スクロールダウン
for _ in range(3):
# 遅延読み込みを許可
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# 遅延読み込みを許可
await asyncio.sleep(2)
# DOMに50番目の動画カード要素が追加されるまで待機
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="visible")
# ロケーターで全てのフィードカードを選択
feed_cards = page.locator(".feed-card")
feed_card_count = await feed_cards.count()
print(f"{feed_card_count}個のフィードカードを読み込みました。")
# スクレイピングしたデータの保存先
videos = []
# 各動画カードにBilibiliデータスクレイピングロジックを適用
for i in range(feed_card_count):
# データを抽出する現在の動画カードを取得
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# スクレイピングしたデータを保存
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)
# ブラウザを閉じてリソースを解放
await browser.close()
# スクレイピングしたデータをJSONファイルにエクスポート
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)
print(f"{len(videos)}本のBilibili動画をvideos.jsonにエクスポートしました")
if __name__ == "__main__":
asyncio.run(main())以下のコマンドで実行:
python スクレイパー.pyこれにより、スクレイピングしたBilibili動画データを含むvideos.jsonファイルが生成されます。その後、以下のvideo-downloader.pyスクリプトを使用してそれらの動画をダウンロードできます:
# video-downloader.py
# pip install yt-dlp
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# 入力JSONファイルから動画データをロード
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"{INPUT_FILE}から{len(videos)}本の動画をロードしましたn")
# 出力フォルダが存在することを確認
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] ダウンロード中: {video.get('title')}")
try:
ydl.download([video_url])
print(f"動画 #{index} ダウンロード完了n")
except Exception as e:
print(f"動画 #{index} ダウンロード失敗: {e}n")以下のコマンドで実行:
python video-downloader.py結果として、発見されたBilibili動画のMP4ファイルが格納された./videosフォルダが生成されます。
これで完了です!Bilibiliスクレイパーの作成方法と、スクレイピングした動画データをダウンローダーに供給する方法を学びました。このプロセスにより、AIのためのデータやその他の用途向けに実際の動画ファイルを取得できます。
次のステップ
構造化されたメタデータと実際の動画ファイルの両方を取得できたので、そのデータをAIトレーニングパイプラインに渡すことができます。例えば、コンピュータビジョンタスク用のフレーム抽出、NLPモデルの微調整用トランスクリプト生成、音声信号の分析、動画コンテンツとメタデータに基づくレコメンデーションシステムの構築などが可能です。タイトル、作者、日付、生の動画ファイルを組み合わせることで、実験にすぐ使える豊富なマルチモーダルデータセットが得られます。
また、ダウンロードフェーズを高速化するには、複数の動画を同時にダウンロードする並列処理を検討してください。このアプローチにより利用可能な帯域幅を最大限活用でき、ダウンロード時間の短縮につながります。
Bilibiliスクレイピングの実用ソリューション:AIのための動画データの取得
多数の動画に対してダウンロードスクリプトを実行すると、最終的に以下のようなエラーが発生する可能性があります:
ウェブページをダウンロードできません: HTTP エラー 412: 事前条件失敗 (<HTTPError 412: Precondition Failed> によって引き起こされる)これはBilibiliのボット対策機能によるものです。プラットフォームが不審なトラフィック(同一IPからの自動リクエスト過多など)を検知すると、412 Precondition Failedレスポンスを返すようになります。
エラーページは以下のような表示になります:
これはBilibiliスクレイピングにおける課題の一例に過ぎません。その他の一般的な問題には、対象ページの構造変更、フィンガープリントベースの検知などがあります。カスタムのPlaywright +yt-dlp環境は小規模プロジェクトでは有効ですが、長期的な運用では複雑で脆弱になりがちです。
大規模で信頼性の高いBilibiliスクレイピングには、IPローテーション、ブラウザフィンガープリント対策、CAPTCHAの解決、自動リトライを処理する堅牢なインフラが必要です。Bright DataのBilibiliスクレイパーはまさにそれを実現します。
このウェブスクレイピングAPI(ノーコードスクレイパーとしても利用可能)は、動画タイトル、アップロード日時、再生回数、高評価数、コメント数、お気に入り登録数、再生時間、アップローダー名、説明文、URLなどを取得します。その全てを、自動でボット対策機能を回避しながら行います。
Bilibiliスクレイパーの独自性は、195カ国に1億5000万以上のIPを擁するプロキシインフラ上で動作する点にあります。99.99%の稼働率、99.95%の成功率、無制限の同時接続をサポートし、大規模なエンタープライズレベルのスクレイピングシナリオを実現します。マルチモーダルAIトレーニングには膨大な動画データが必要であることを考慮すると、これは極めて重要です。
動画URLを取得後、Bright DataのWeb Unlocker APIを自動化されたyt-dlpワークフローに統合すれば、412エラーを回避しブロックなしで動画をダウンロード可能です。Bright Dataを活用すれば、レート制限やブロック、yt-dlpの失敗を気にせず、AI/MLモデル訓練用の動画データをより多く取得できます。
結論
本記事では、Bilibiliからスクレイピング可能なデータの種類と主な活用事例を紹介しました。特に注目すべきは動画データを用いたAIトレーニングです。数億本もの動画が存在するBilibiliは、公開されているマルチメディアコンテンツの巨大な供給源と言えます。
プロセスは、段階的に構築方法を学んだBilibiliスクレイパーから始まります。これにより動画URLを含む構造化された動画メタデータが収集されます。その後、このガイドで示したように、yt-dlpを活用したワークフローにそれらのURLを渡すことで、実際の動画ファイルをダウンロードできます。
Bright Dataは、専用のスクレイパーとyt-dlpの直接統合オプションを通じてBilibiliスクレイピングをサポートし、信頼性の高い中断のないダウンロードを実現します。詳細については、LLMトレーニング向け大規模動画データアクセスソリューションをご覧ください。
Bright Dataに今すぐ登録し、動画データ収集ソリューションをご確認ください!





