

このチュートリアルの終わりまでに、以下の点を理解できるようになります:
- PyTorchがマルチモーダル機械学習ワークフロー構築に最適な選択肢である理由
- Bright Dataが提供するような数百万件のレコードを含むデータセットから、信頼できるデータソースの必要性。
- – PyTorchでBright Dataデータセットを活用し、マルチモーダルプロセスにおける製品画像分類用MLモデルの微調整を行う方法
それでは始めましょう!
マルチモーダル機械学習にPyTorchを使用する理由
データの価値は、そこから得られる洞察によって決まります。企業にとって、適切なアプローチでデータを活用することは、より賢明な意思決定を促進し、戦略を洗練させ、顧客維持率やマーケティングパフォーマンスなどの成果向上につながります。
現代の機械学習では、評価や売上高といった構造化データだけでなく、画像、テキスト、さらには動画といった非構造化データも処理できます。これによりマルチモーダルな洞察が可能になります。例えば、レビュー画像とテキストを組み合わせることで、顧客エンゲージメントを促進する要因についてより深い理解が得られます。
本記事はPyTorchを基盤としています。PyTorchは深層ニューラルネットワークの構築・学習に広く用いられるPython機械学習フレームワークです。このライブラリは画像分類、自然言語処理、複数データタイプの統合分析など、多様なタスクをサポートします。
PyTorchの代表的な応用例:
- 製品画像の品質評価:画像が視覚的に魅力的で顧客の関心を引く可能性を自動的に判定します。
- 顧客感情分析:テキストレビューから洞察を抽出し、ユーザーの意見や満足度を把握します。
- レコメンデーションシステムの構築:テキストと画像の特徴を組み合わせて、より正確でパーソナライズされた商品提案を生成。
- マルチモーダルデータを用いた予測モデリング:視覚情報とテキスト情報を併用し、トレンド・売上・顧客行動を予測。
企業向け高品質マルチモーダルデータの調達方法
開発する機械学習やAIアプリケーションの種類にかかわらず、これらのシステムの有効性は、トレーニングに使用するデータの質に依存することを忘れてはなりません。
マルチモーダルアプリケーションでは、テキストとビジュアルの両方の形式で情報を収集する必要があるため、データ調達は特に困難です。ここでBright Dataのような信頼できるデータプロバイダーが役立ちます。
Bright Dataは、スタートアップから大企業まであらゆる規模のビジネス向けに、AIおよび機械学習対応のソリューション群を提供しています:
- WebスクレイパーAPI:数百の人気ウェブサイトから構造化データへのプログラムによるアクセスを提供し、大規模な最新ウェブデータの自動収集を可能にします。
- データセットマーケットプレイス:画像、テキスト、構造化フィールドを含む数十億件のエントリーからなる、すぐに使用可能なマルチモーダルデータセットを提供します。
- マネージドデータ取得サービス:スクレイピングパイプラインの構築・維持を不要とする、完全管理型のエンタープライズグレードソリューション。
- データアノテーションサービス:NLP、コンピュータビジョン、音声認識タスク向けのスケーラブルでカスタマイズ可能なアノテーションソリューション。
これらのソリューションにより、研究者、中小企業、大企業は公開ウェブデータを効率的に収集・統合できます。これにより、マルチモーダル機械学習ワークフローの推進、高度なAIモデルのトレーニング、インテリジェントエージェントの開発、分析およびビジネスインテリジェンスシステムの構築が可能になります。
Bright Dataデータセットを用いたPyTorchによるマルチモーダル機械学習分析パイプライン構築方法
このガイドセクションでは、テキストデータと画像データの両方を含むBright Dataの「Amazon製品」データセットを使用して、機械学習モデルをトレーニングする方法を学びます。
オンライン製品を販売しており、適切な画像で製品を展示することの重要性を理解していることを前提とします。目標は、PyTorchを使用して、eコマース製品画像とその評価情報に基づいて機械学習モデルを訓練することです。このモデルは、製品画像が「良い」か「悪い」かを自動的に評価します。
このマルチモーダル機械学習ワークフローにより、貴社ビジネスは製品画像が顧客を惹きつけエンゲージメントを促進する可能性をプログラム的に評価できるようになります。
注:これは単なる一例です。PyTorchとBright Dataのデータセット・データフィードを組み合わせることで、他にも多くのユースケースやシナリオに対応できます。
以下の手順に従ってください!
前提条件
このセクションを実践するには、以下の環境が整っていることを確認してください:
- ローカルにPython 3.9以上がインストールされていること。
- Bright Dataアカウント。
また、ResNet-18モデルとファインチューニングの仕組みに関する知識があると、マルチモーダルPyTorch画像分類ロジックを完全に理解するのに役立ちます。
ステップ #1: JupyterLabプロジェクトの作成
マルチモーダルデータを扱う際には、データセットを可視化することが有効です。このため、開発環境としてJupyterLabは最適な選択肢です。ワークフローの開発が完了したら、コードを本番環境対応の機械学習パイプラインへ容易に変換できます。
専用のプロジェクトフォルダを作成し、そのフォルダに移動することから始めます:
mkdir pytorch-brightdata-product-image-analysis
cd pytorch-brightdata-product-image-analysis次に、その中に仮想環境を初期化します:
python -m venv .venvmacOS/Linuxでは仮想環境を以下で有効化:
source .venv/bin/activateWindowsの場合は以下を実行:
.venvScriptsactivate仮想環境をアクティブにした状態で、 jupyterlabパッケージを通じてJupyterLabをインストールします:
pip install jupyterlabJupyterLabを起動するには:
jupyter labブラウザでhttp://localhost:8888/lab/にアクセスすると JupyterLab インターフェースが開きます。「Notebook」セクションの「Python 3 (ipykernel)」ボタンをクリックして新しいノートブックを作成します:
Untitled.ipynbファイルが表示されます:
新しいノートブックに「Bright Data + PyTorch」などの名前を付けて保存します。
完了!これでPyTorchを用いたマルチモーダル機械学習ワークフローの開発が可能な、完全にセットアップされたPython環境が整いました。
ステップ #2: 必要な依存関係をインストールしてインポートする
ノートブックに新しいコードセルを追加し、以下のpipコマンドを入力します
!pip install pillow tqdm requests scikit-learn torch torchvision pandasこのブロックを実行して必要なライブラリをすべてインストールします:
pillow: 画像の読み込みと処理用。tqdm: ループの進行状況バーを表示し、データの読み込みやトレーニングの追跡に便利です。requests: HTTPリクエスト経由でURLから画像をダウンロードします。scikit-learn: データセット分割用のtrain_test_splitなどのツールを提供します。torch: 機械学習モデルの構築とトレーニングのためのPyTorchコアライブラリ。torchvision: データセット、事前学習済みモデル、画像変換を提供します。pandas: CSVファイルなどの構造化データを扱い、データ操作を容易にします。
別のコードセルで必要なモジュールをすべてインポート:
import os
import io
import json
import requests
from PIL import Image, ImageStat
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from tqdm import tqdm
from PIL import Image素晴らしい!この2つのセルで、ノートブックはBright Dataのマルチモーダルデータセットを扱い、PyTorchを用いた画像・テキスト処理を実行する準備が整いました。
ステップ #3: Bright Data データセットのダウンロード
PyTorch開発用のノートブックが設定されたので、このワークフローで最も重要な要素である入力データを取得しましょう!
このチュートリアルでは、Bright Dataで利用可能な数多くのeコマースデータセットの一つである「Amazon製品」データセットを使用します。執筆時点で、このデータセットには3億1100万件以上のエントリーが含まれており、各エントリーには87のデータフィールドがあります。各製品について、これらのフィールドには画像のURL、レビュー評価、製品ASIN、その他多くの情報が記載されています。
注:Bright DataeCommerceスクレイパーを使用すれば、Amazon、eBay、Walmartなど多数のプラットフォームから最新の構造化データを収集できます。
開始するには、Bright Dataアカウントをお持ちでない場合は新規作成してください。既にアカウントをお持ちの場合はログインし、アカウントの「データセットマーケットプレイス」ページに移動します:
「人気ランキング」から「Amazon製品」データセットを選択:
データセットページが表示されます: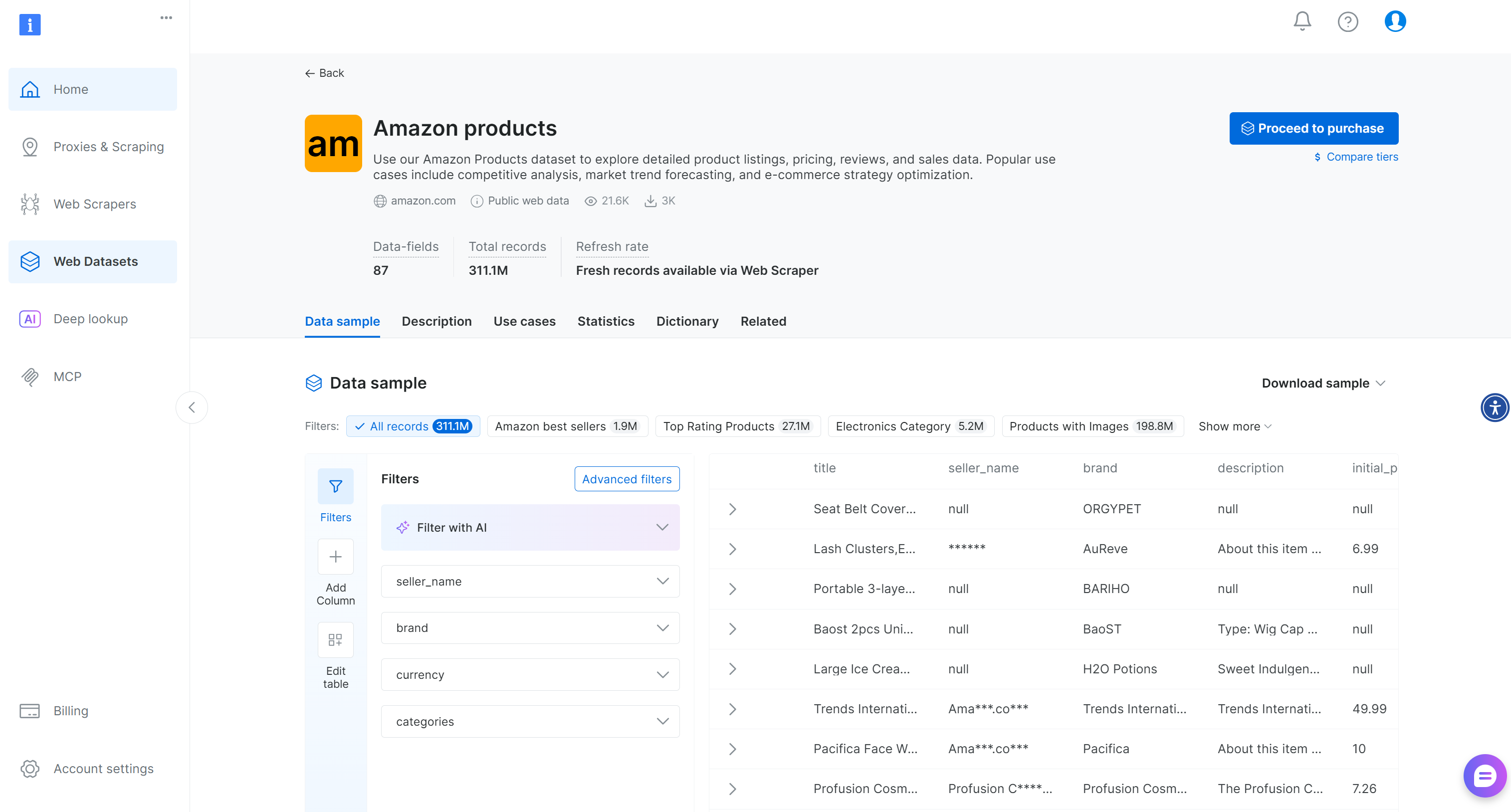
ここでは、手動でエントリをフィルタリングするか、AI搭載フィルターを使用してニーズに合わせたサブセットを作成できます。これらのフィルターはFilter APIを介してプログラムで適用することも可能で、特定の基準に基づくデータセットのスナップショットを作成できます。
このチュートリアルでは、マルチモーダル機械学習ワークフローを実証するための小さなサンプルデータセットのみが必要ですので、無料のサンプルデータセットで十分です。本番環境や企業向けワークフローには、特定のニーズに合わせて構築されたフルデータセットをダウンロードする必要があります。
サンプルデータセットをダウンロードするには、「Dataset sample」ドロップダウンを開き、「Download as CSV」を選択します: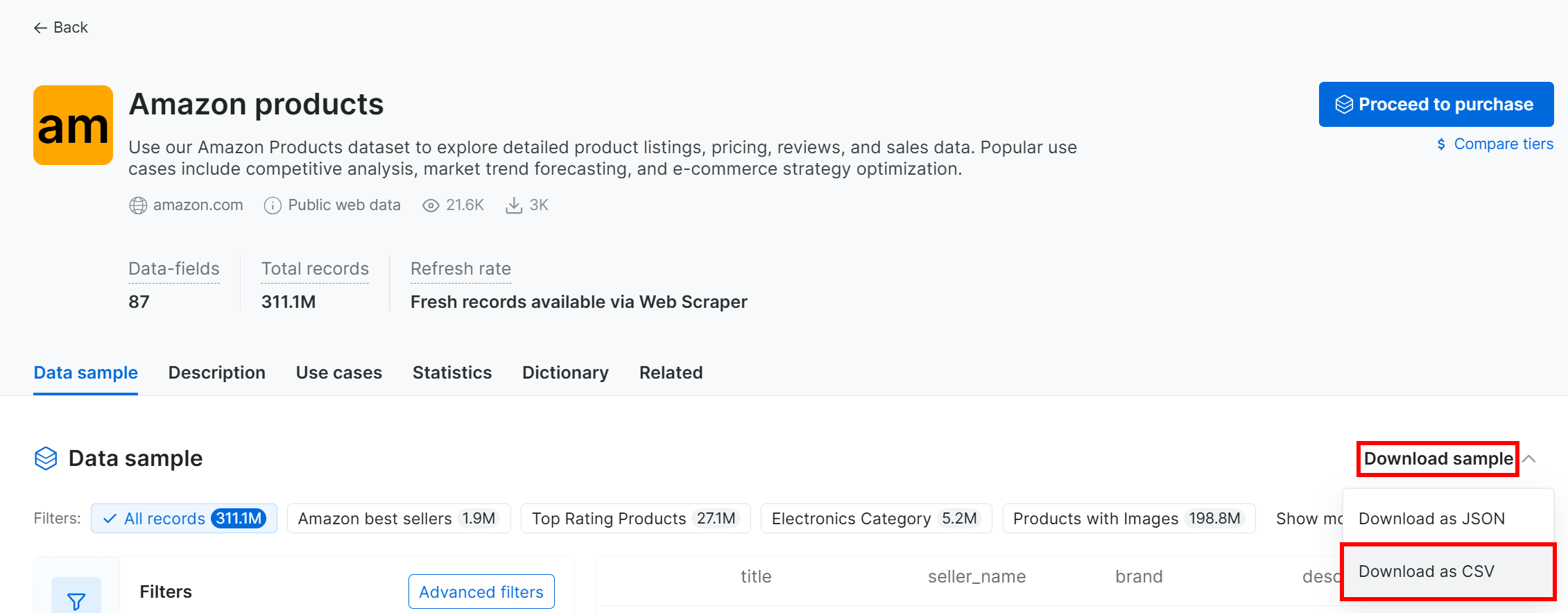
Amazon products.csv という名前のファイル(1,000商品分、約7.3 MB)が提供されます。これをamazon_products.csvにリネームし、プロジェクトフォルダに配置してください:
利用可能な87のフィールドのうち、このマルチモーダルワークフローに関連するものは以下の通りです:
asin: Amazon上での製品固有識別子。image_url: 商品のメイン画像URL。images: 商品の追加画像URLを格納したJSON形式の配列。rating: 1~5段階の顧客レビュー平均評価。
これらのフィールドにより、マルチモーダルPyTorch機械学習ワークフローにおいて、視覚データ(画像)と構造化数値データ(評価)を統合できます。素晴らしい!これで入力データセットが揃いました。
ステップ #4: 商品画像のダウンロードとラベル付けロジックの定義
ノートブックに戻り、画像ダウンロードとラベリングの関数を追加してコアロジックを初期化します。これらの2つの関数は、以下のステップを必要とするML画像分類プロセス実装の基盤となります:
- Bright Dataの「Amazon products」
データセットからimage_url、images配列、rating、asinを含む製品データを収集する。 - 各商品エントリから画像URLを抽出し重複を除去する。
- 全URLから画像をダウンロードしローカルに保存する。
- 視覚的特徴(白背景、解像度)とレビュー評価を組み合わせて画像にラベルを付ける。
- ラベリング済み画像を用いて、CNN(畳み込みニューラルネットワーク)モデルのトレーニングに適したPyTorchデータセットを準備する。
- ラベル付け済みデータセットを用いて、画像品質(「GOOD」対「BAD」)を予測するCNNを微調整する。
- テストセットでモデルを評価する。
- モデルを使用して新規製品画像を自動的に評価する。
ノートブックの新しいコードセルで、製品画像のダウンロードとラベル付けを行う関数を記述する:
def download_image(url):
# 画像のURLにGETリクエストを送信
response = requests.get(url)
# レスポンスの内容をBytesIOオブジェクトに読み込み
image_bytes = io.BytesIO(response.content)
# PILで画像を開きRGBモードに変換
image = Image.open(image_bytes).convert("RGB")
return image
def label_image(image, rating):
# 画像の幅と高さを取得
w, h = image.size
# 境界線の輝度を分析するため、上端10ピクセルを切り取る
border = image.crop((0, 0, w, 10))
# 境界線の統計量(平均)を計算
stat = ImageStat.Stat(border)
# RGB各チャンネルの輝度を平均化
brightness = sum(stat.mean) / 3
# 画像が白背景かどうか判定
is_white_bg = brightness > 240
# 画像が低解像度かどうか判定(最小辺 < 400px)
is_low_res = min(image.size) < 400
# ヒューリスティックラベル: 1=良好(白背景かつ低解像度でない)、0=不良
heuristic_label = 1 if (is_white_bg and not is_low_res) else 0
# 評価が欠損またはゼロの場合、ヒューリスティックのみに依存
if rating is None or rating == 0:
return heuristic_label
# 評価を0-1の範囲に正規化
r = rating / 5
# 極端な評価に基づくラベル調整(弱い教師付き学習)
if heuristic_label == 1 and r < 0.5: # 非常に低い評価 → 不良と判定
return 0
if heuristic_label == 0 and r > 0.9: # 非常に高い評価 → 良品と判定
return 1
# それ以外の場合はヒューリスティックラベルを維持
return heuristic_labeldownload_image()関数は、指定されたURLから画像をダウンロードし、PIL Imageインスタンスとして返すだけのシンプルな関数です。一方、label_image()関数は、視覚的手がかりと顧客評価のようなテキスト/数値データを組み合わせた、商品画像のマルチモーダル評価を実装しています。
label_image()はまずヒューリスティック(白背景と十分な解像度のチェック)を適用し、初期の「良」または「悪」ラベルを割り当てます。その後、評価が利用可能な場合、関数は以下の通りラベルを調整します:
- 非常に低い評価は視覚的に良好な画像を上書きします。
- 優れた評価は見た目が悪い画像を救済する。
このロジックは合理的です。なぜなら、見た目が良くても低評価であれば有益ではないことを示すからです。逆に、優れた評価は見た目が悪くても成功した画像を浮き彫りにします。したがって、最終的なラベルを割り当てる際には視覚情報と数値情報の両方が考慮されます。
いいね! ではデータセットをインポートし、製品エントリーを準備して、これら2つの関数を全画像に適用しましょう。
ステップ #5: データセットを読み込み、全画像のダウンロード準備
amazon_products.csvファイルを確認すると、商品画像は2つのデータフィールドに保存されていることがわかります:
image_url: メイン商品画像へのURL。images: 追加商品画像の配列を含むJSON形式の文字列。
新しいコードブロックで、CSVを読み込み、ヘルパー関数を使用して各商品の全画像を取得します:
def extract_image_list(row):
image_urls = []
# メイン画像URLが単一で存在し、空でない場合追加
if isinstance(row.get("image_url"), str) and row["image_url"].strip():
image_urls.append(row["image_url"].strip())
# "images"フィールドを確認(JSON文字列またはPythonリストの可能性あり)
images_field = row.get("images")
if isinstance(images_field, str):
# JSON文字列をPythonリストに変換
decoded = json.loads(images_field)
if isinstance(decoded, list):
# リスト内の全画像を image_urls に追加
image_urls.extend(decoded)
# URL をセットに変換後リストに戻し重複を除去
return list(set(image_urls))
# Amazon商品CSVをDataFrameに読み込み
df = pd.read_csv("amazon_products.csv")
# 必須フィールドが欠落している行を削除
df = df.dropna(subset=["asin", "image_url", "images", "rating"])
# extract_image_list関数を各行に適用し、全一意画像URLのリストを生成
df["all_image_urls"] = df.apply(extract_image_list, axis=1)インポートされたデータセットには、all_image_urls という新しい列が追加されました。この列には、メイン画像と追加画像を組み合わせた、重複を除いた全画像URLのリストが格納されています。次のステップでは、このフィールドにアクセスして、各商品の全画像をダウンロードし処理します!
ステップ #6: 全画像のダウンロードとラベル付け
セル内で、すべての商品画像をローカルのimages/フォルダにダウンロードし、ラベル付けするロジックを実装します:
# "images"フォルダが存在しない場合は作成
os.makedirs("images", exist_ok=True)
# ダウンロード・ラベル付け済み画像のメタデータを格納するリストを初期化
records = []
# 進行状況バー付きでDataFrameの各商品行を反復処理
for idx, row in tqdm(df.iterrows(), total=len(df)):
# 必要な商品データフィールドを取得
url_list = row["all_image_urls"]
rating = float(row["rating"])
asin = row.get("asin")
# この商品の各画像URLを反復処理し、ダウンロードとラベル付けを実行
for i, url in enumerate(url_list):
# 画像をダウンロード
image = download_image(url)
if image is None:
continue
# ASINと画像インデックスでファイル名を構成
filename = f"{asin}_{i}.jpg"
path = os.path.join("images", filename)
# ダウンロードした画像をディスクに保存
image.save(path)
# マルチモーダル情報を使用して画像にラベルを付ける
label = label_image(image, rating)
# この画像に関連するメタデータを保存
records.append({
"asin": asin,
"image_path": path,
"image_url": url,
"label": label
})
# レコードリストをDataFrameに変換しCSVファイルにエクスポート
labeled_df = pd.DataFrame(records)
labeled_df.to_csv("labeled_images.csv", index=False)このコードブロックをノートブックで実行すると、ダウンロードプロセスが開始されます。2,500枚以上の画像をダウンロードするため、数分間お待ちください。
完了後、コードセルの出力には100%までの進捗バーが表示されるはずです:
これで、プロジェクトディレクトリのimages/フォルダに、データセットからダウンロードされた全製品画像が保存されます:
さらに、ラベル付け情報を含むlabeled_images.csvファイルがローカルに作成されます:
素晴らしい!これでマルチモーダル処理における機械学習モデルのトレーニングに必要な、全てのローカル画像とラベル付け情報が揃いました。
ステップ #7: トレーニングデータセットとテストデータセットの準備
新しいブロックを追加し、labeled_images.csvファイルから画像のラベル情報を読み取り、MLモデルの微調整に使用するトレーニングデータセットとテストデータセットを生成します:
# 製品画像用のカスタムPyTorch Datasetクラスを定義
class ProductImageDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
# データセット内のサンプル総数を返す
return len(self.df)
def __getitem__(self, idx):
# 指定されたインデックスの画像パスとラベルを取得
path, label = self.df.iloc[idx]["image_path"], self.df.iloc[idx]["label"]
# 画像を読み込み、RGBに変換
image = Image.open(path).convert("RGB")
# 変換が指定されている場合(例:リサイズ、テンソル変換)を適用
if self.transform:
image = self.transform(image)
# 画像テンソルとラベルを torch.Tensor として返す
return image, torch.tensor(label, dtype=torch.long)
# ラベル付き画像CSVを読み込み
labeled_df = pd.read_csv("labeled_images.csv")
# ラベル分布を均等化しつつ、データセットを訓練用とテスト用に分割
train_df, test_df = train_test_split(
labeled_df,
test_size=0.2,
stratify=labeled_df["label"]
)
# 画像を224x224にリサイズしテンソル変換する処理を定義
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# データセットオブジェクトを初期化
train_ds = ProductImageDataset(train_df, transform)
test_ds = ProductImageDataset(test_df, transform)
# バッチ処理とシャッフル用にデータセットをDataLoaderでラップ
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=32)このスニペットは、PyTorch CNNのトレーニング用にラベル付き製品画像を準備します。カスタムデータセットを定義し、以下の画像変換を適用することで実現します:
transforms.Resize((224, 224)): 画像を224×224にリサイズします。これは重要な処理です。なぜなら、データセット内の画像は様々な解像度やアスペクト比で存在しますが、CNNは全ての入力が同じ固定サイズであることを前提とするためです。transforms.ToTensor():PyTorchモデルは生のPIL画像ではなくテンソルを操作します。これにより各画像は正規化された(C, H, W)形状(チャンネル、高さ、幅)のテンソルに変換され、CNNと互換性を持つようになります。
これらの変換を組み合わせることで、全画像のサイズと形式が標準化され、モデルは不整合な入力処理ではなく視覚パターンの学習に集中できるようになります。その後、データセットはラベル分布を維持したまま訓練用とテスト用セットに分割され、DataLoaderオブジェクトでラップされて画像とラベルのデータバッチが生成されます。
全体として、このステップによりCNNが適切にフォーマットされたデータを受け取ることを保証し、効果的なマルチモーダル機械学習トレーニングの基盤を築きます。素晴らしい!
ステップ #8: マルチモーダル機械学習モデルの訓練
トレーニングおよびテストデータセットの準備が整ったら、以下のコードでPyTorchのCNNを画像分類用にファインチューニングします:
# トレーニング用デバイスを選択(利用可能ならGPU、そうでない場合はCPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# torchvisionから事前学習済みResNet-18モデルを読み込み
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# 最終全結合層を2クラス(GOOD/BAD)出力用に置換
model.fc = nn.Linear(model.fc.in_features, 2)
# モデルを選択したデバイスに移動
model = model.to(device)
# 分類用の損失関数を定義
criterion = nn.CrossEntropyLoss()
# 小さな学習率を持つオプティマイザーを定義
opt = torch.optim.Adam(model.parameters(), lr=1e-4)
# 3エポックのトレーニングループ
for epoch in range(3):
model.train()
total_loss = 0
# 画像とラベルのバッチを反復処理
for images, labels in tqdm(train_dl, desc=f"Epoch {epoch+1}"):
images, labels = images.to(device), labels.to(device)
opt.zero_grad()
out = model(images)
loss = criterion(out, labels)
loss.backward()
opt.step()
total_loss += loss.item()
# エポックの平均損失を出力
print(f"Epoch {epoch+1}: Average Loss={total_loss/len(train_dl):.4f}")上記のセルでは、事前学習済みのResNet-18 CNN(18層の畳み込みニューラルネットワーク)を微調整します。このモデルは主に画像を様々なカテゴリに分類するために使用されます。
この場合、MLモデルは製品画像を「良品」または「不良品」に分類します。ImageNetの重みを使用することで収束が加速され、何百万もの自然画像から既に学習された特徴を活用できます。その後、最終的な全結合層を置き換え、意図した通り2つのクラス(「GOOD」対「BAD」)を出力するようにします。
ループ内では、CrossEntropyLossインスタンスが分類誤差を測定し、Adamオプティマイザーがモデル重みを更新します。各エポックはバッチを反復処理し、順伝播、損失計算、逆伝播、重み更新を実行します。
コードブロックを実行すると、以下のような出力が得られます: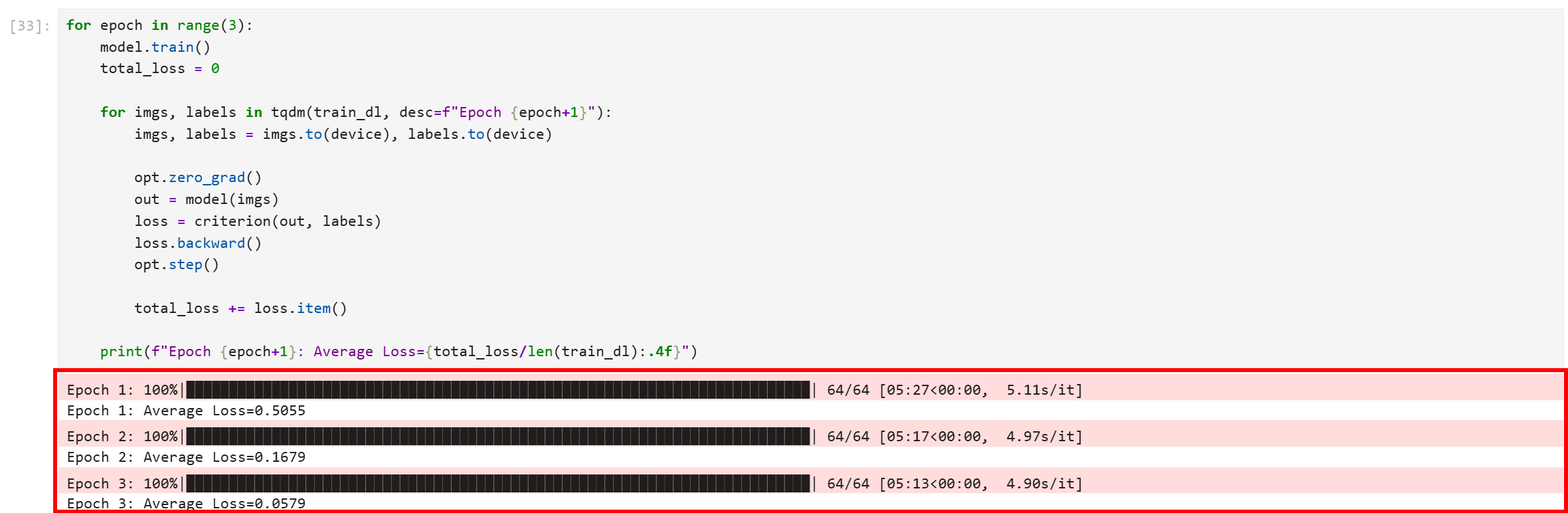
3つのエポック全てが正常に完了したことに注目してください。最終的な平均損失は0.0579と非常に低く、モデルが良好に収束し、高い信頼度でトレーニング画像の区別を学習したことを示しています。
さあ、完了です!EC向け画像品質判別用のCNNをファインチューニングしました。
ステップ #9: モデル性能の評価
モデルの性能を検証するため、評価ステップを実行します:
# 評価用モデルを読み込み
model.eval()
# 処理済み画像の進捗管理
correct = 0
total = 0
# テストデータセットに対するモデル評価
with torch.no_grad():
for images, labels in test_dl:
images, labels = images.to(device), labels.to(device)
out = model(images)
prediction = out.argmax(dim=1)
correct += (prediction == labels).sum().item()
total += len(labels)
# 結果を出力
print("テスト精度:", correct / total)これは、微調整されたモデルがこれまで見たことのないデータ(テストデータセット)に対してどれだけ一般化できるかを測定します。具体的には、推論によるモデル評価を行います。
コードセルはまずモデルを評価モードに切り替え、速度最適化と一貫した動作確保のため勾配追跡を無効化します。次にループでテストデータセットを反復処理し、モデルの予測結果と実際のラベルを比較します。最後に総合精度を計算し、トレーニングセットを超えたモデルの汎化能力を明確に示す指標を提供します。
結果は以下のような形式になります:

テスト精度スコア0.924XXXは、微調整したResNet-18モデルが未見のテストデータセット内の商品画像の92.4%以上を「GOOD」または「BAD」として正しく分類したことを意味します。
これは、eコマース製品画像のような実世界のデータにおける二値分類としては優れた結果と言えます。モデルが単に訓練データを暗記しているのではなく、良好な画像品質と不良な画像品質の特徴の違いを効果的に学習したことを強く示唆しています。
よくできました!では、微調整したモデルを新しい画像数点に適用し、期待通りに動作するか確認しましょう。
ステップ #10: MLモデルを用いた画質予測
微調整済みモデルが期待通りに機能するかを真に検証するには、これまで遭遇したことのない画像に対してその性能をテストする必要があります。このモデルはあらゆるEC商品画像に対応するよう訓練されているため、eBay、ウォルマート、アリババなどのプラットフォームや、自社内部の商品データベースの画像でテストできます。
このデモでは、eBayから取得した以下の2つの商品画像でモデルをテストします:
専用ブロックに以下のコードを追加します:
def predict_image_quality(img: Image.Image) -> str:
# モデルを評価モードに設定
model.eval()
# 変換を適用しバッチ次元を追加
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
# フォワードパス実行、予測クラスインデックスを取得しスカラーとして抽出
prediction = model(x).argmax().item()
# 結果文字列を返す
return "GOOD" if prediction == 1 else "BAD"
# テスト画像
image_urls = ["https://i.ebayimg.com/images/g/N5kAAOSwTlplqFTa/s-l500.webp", "https://i.ebayimg.com/images/g/yUsAAOSweMJd67Jd/s-l1600.webp"]
# 画像URLをループ処理し、ダウンロード、予測、表示
for image_url in image_urls:
# HTTPリクエストで画像コンテンツをダウンロード
response = requests.get(image_url)
image = Image.open(io.BytesIO(response.content)).convert("RGB")
# 予測関数を呼び出す
quality = predict_image_quality(image)
# ノートブックに画像とモデル結果を表示
display(image)
print(image_url, "→", quality)セルを実行すると、以下の分類結果が確認できます:
モデルが画像を「BAD」と分類したことに注意してください。これは正しい結果です。画像が明らかに低品質でぼやけており、背景のコントラストが不鮮明で製品を適切に強調できていないためです。
一方、2枚目の画像では以下の結果が得られます:
今回は「GOOD」と判定されました。視覚的に魅力的で鮮明、照明も適切であり、製品が明確に写っていることを考慮すると納得のいく結果です。
これで完了です!Bright Dataの豊富なデータセットを活用し、eコマース製品データ(本例ではAmazon)を取得しました。その後、マルチモーダル機械学習データ分析アプローチに従い、PyTorchを用いて画像認識用CNNの微調整を適用しました。
結論
本ブログ記事では、マルチモーダル機械学習システムの実装方法を紹介しました。数億点に及ぶAmazon商品と対応画像を含む製品データセットを活用しました。
Pythonノートブック内のPyTorchワークフローにこのデータを投入することで、EC商品画像を「良品」または「不良品」に分類するCNN(畳み込みニューラルネットワーク)のファインチューニングに成功しました。
このプロジェクトは、特にeコマース目的で商品表現の画像品質を迅速に評価する方法を求める中小企業から大企業までのニーズに直接応えるものです。
Amazon、Walmart、LinkedIn、Zillow、Airbnb、Yahoo Financeなど100以上のドメインからデータを収集できるBright Dataのエンタープライズデータサービスがなければ、これらすべては実現できませんでした。
Bright Dataアカウントを今すぐ登録し、データソリューションを無料で試してみてください!






