

顧客との通話前のアカウントリサーチは、営業担当者1人あたり10〜15分かかることが多いです。ワークフローはほぼ手作業で、担当者はSalesforceを離れてGoogleを開き、複数のタブをスキャンして、調査結果をメモフィールドに貼り付けます。作業のほとんどは検索と情報の統合です。
Bright DataのWeb Unlockerは、ほとんどの公開URLからクリーンなMarkdownを返します。これをSalesforce Agentforceに組み込むことで、担当者はSalesforceを離れることなく、チャットプロンプトから出典付きのアカウントリサーチを取得できます。内部的には、1つのAgentforceサブエージェント、3つのApexクラス、小さなCloudflare Workerプロキシで構成されています。
TL;DR
- Agentforceサブエージェントが営業担当者からの自然言語プロンプトを受け取り、Bright Data Web Unlockerを呼び出して、Salesforceチャット内で出典付きのアカウントブリーフィングを返します。
- ApexのHTTPクライアントは、数キロバイトを超えるチャンク転送レスポンスに対して警告なしに失敗します(API v66.0で確認済み)。そのため、この統合では小さなCloudflare Workerを経由してバッファリングし、明示的な
Content-Lengthヘッダーで再送信します。 - AgentforceのCanvas UIは、チャット駆動エージェントがプロンプトから抽出した入力を受け取るために必要な
is_user_input: TrueYAMLフラグを隠しています。修正はScriptモードで行います。 - SalesforceのExternal Credentialパターンは3つのオブジェクト(External Credential、Named Credential、Permission Set)に分かれており、スキップすると401を返す見落としやすいチェックボックスが1つあります。
- Agentforceはデフォルトでエージェントのレスポンスから外部URLを削除します。エージェントは内部的にURLを読み取りますが、ドメインがTrusted URLsの許可リストに登録されていない限り表示されません。
- 合計フットプリントは約6KBのApex、1つのCloudflare Worker、3つのSalesforce資格情報オブジェクト、1つのサブエージェントです。すべてのコードブロックは実際のSalesforce Developer Edition組織でテスト済みです。
始める前に
このチュートリアルには4つのアカウントとツールが必要です。すべて無料です:
- Bright Dataアカウント(少なくとも1つのWeb Unlockerゾーンがプロビジョニングされていること)。新規アカウントには無料トライアルクレジットが含まれており、チュートリアルのリクエスト量はそのクレジット内に十分収まります。
- Cloudflareアカウント(Workerプロキシ用)。無料ティアにクレジットカードは不要で、初回使用時に
workers.devサブドメインを選択します。 - Agentforceが有効なSalesforce Developer Edition組織。最近のDeveloper Edition組織にはAgentforce、Data Cloud、Agentforce Studioがプリインストールされています。パート5に進む前に、App LauncherにAgentforce Studioアプリが表示されることを確認してください。表示されない場合は、Agentforce非対応の組織であり、後半のパートは機能しません。
- テスト用HTTPリクエストを送信する方法。パート2にはWorkerを検証するための
curlコマンドが含まれています。macOS、Linux、Windows 11にはcurlが同梱されています。GUIを使いたい場合は、PostmanやInsomniaも同じヘッダーとボディで動作します。これらがなくインストールもしたくない場合は、単独のWorkerテストをスキップして、パート3でSalesforceからエンドツーエンドで検証することもできます。 - System Administratorプロファイル(またはAuthor Apex、Modify All Data、Customize Applicationを持つプロファイル)。新規のDeveloper Edition組織では自動的に付与されます。ロックダウンされたプロファイルを持つ会社のサンドボックスで作業している場合は、代わりに新しいDeveloper Edition組織に切り替えてください。
作成するもの
Account Briefing AgentというAgentforceエージェントを構築します。担当者が自然言語で質問を入力すると、エージェントはプロンプトをカスタムサブエージェントにルーティングし、適切なツールを選択して、薄いCloudflare WorkerプロキシからBright Dataを呼び出し、出典付きのアカウントブリーフィングを合成してチャットに投稿します。アーキテクチャは5つの要素で構成されています:
- Bright Data Web Unlocker(Webデータのプリミティブとして)。ほとんどのURLを受け取り、クリーンなMarkdownを返す単一エンドポイントです。
- Cloudflare Worker(SalesforceとBright Data間のプロキシとして)。無料ティアで小規模チームをカバーします。
- Salesforce External Credential + Named Credential + Permission Set(認証レイヤーとして)。
- Apex(3つのクラス):共有サービス1つと、
@InvocableMethodを使用した2つのラッパー(Agentforceから呼び出し可能にするアノテーション、Agent Actionごとに1つ)。 - Agentforceサブエージェント(2つのアクション、インストラクションブロック、分類説明を持つ)。
アーキテクチャの概要
担当者のプロンプトからブリーフィングまでのリクエストフローを示します:
Rep prompt in Agentforce
│
▼
Agent Router ──► Account Web Intelligence subagent
│
├─► Apex: BrightDataNewsAction
│ └─► Named Credential → Cloudflare Worker → Web Unlocker → Google News
│
└─► Apex: BrightDataFetchAction
└─► Named Credential → Cloudflare Worker → Web Unlocker → target URL
│
▼
LLM synthesis ──► Briefing back to the repCloudflare Workerが必要な理由は、Salesforce ApexがHTTP/1.1のチャンク転送レスポンスを確実に処理できず、Bright Dataは数キロバイトを超えるペイロードにチャンクエンコーディングを使用するためです。Workerはレスポンスを単一のArrayBufferにバッファリングし、明示的なContent-Lengthヘッダーを付けて再送信します。これがないと、Apexからのすべての呼び出しは200ステータスとゼロバイトのボディを返します。以下のパート2でデバッグと修正の手順を説明します。
Bright Dataにはこの種の構築に適した製品がいくつかあります:解析済みGoogle結果用のSERP API、LinkedInやCrunchbase専用のスクレイパーなどです。このビルドではWeb Unlockerのみを使用します。任意のURLに対して同じエンドポイントで動作するため、Apex側をシンプルに保てます。パート2のCloudflare WorkerプロキシはすべてのBright Data APIエンドポイントを同様にカバーするため、後でSERP APIや専用スクレイパーに切り替えてもSalesforce側の配線は変わりません。
パート1:Bright Dataのセットアップ
Bright Dataアカウントをお持ちでない場合は、Bright Dataのサインアップページでアカウントを作成してください。使用するWeb UnlockerゾーンはダッシュボードのWeb Access APIセクションにあります。
Web Unlockerゾーンの作成または確認
ダッシュボードを開き、左ナビゲーションのWeb Access APIに移動して、Web Unlockerゾーンが存在することを確認します。アカウントにない場合は、Create API(右上)をクリックしてドロップダウンからUnlocker APIを選択します。任意の名前を付けてください(ゾーン名は作成後に変更できないため、agentforce_unlockerのような安定した名前を選んでください)。名前を書き留めておいてください。パート4のBrightDataService.clsのUNLOCKER_ZONE定数と、パート2のcurlテストに使用します。
Web Unlockerゾーンは、両方のAgentforceアクションが使用するプリミティブです。
APIトークンの作成
Settings(左下)→ Users and API keysタブ → Add API key(User権限)をクリックします。キーは生成時に一度だけ表示され、その後はマスクされます。今すぐコピーして安全な場所に保存してください。パート3でSalesforceに貼り付けます。
これでBright Dataのセットアップは完了です。
パート2:Cloudflare Workerプロキシのデプロイ
Salesforceを設定する前に、Bright Dataの前にプロキシが必要です。理由はSalesforce ApexがチャンクTransferレスポンスを読み取る方法の制限にあります。非trivialなHTTPコールアウトを行うApex開発者なら誰でも遭遇する可能性があります。
バグの説明
Salesforce ApexのHttpクライアントは標準HTTPをサポートしていますが、実用上の欠点が1つあります:Content-Lengthヘッダーのないチャンク転送エンコーディングを使用するHTTP/1.1レスポンスを確実に解析できません。チャンクレスポンスの場合、コールアウトはStatus Code = 200、Content-Type = null、Response Size = 0 bytesを返し、例外や警告はありません。getBody()とgetBodyAsBlob().toString()はどちらも空文字列を返します。
Bright Dataの/requestエンドポイントは、数キロバイトを超えるレスポンスにチャンク転送エンコーディングを使用します。小さなテストページ(Bright Dataのwelcome.txt)へのWeb Unlocker呼び出しはしきい値以下に収まり、content-lengthレスポンスを返すためApexはクリーンに解析できます。しかし実際のページ(企業のホームページ、Google Newsの検索)はしきい値を超えてチャンク化され、Apexは空のボディを返します。
これがApex側の問題であってネットワーク側ではないことを証明する2つの事実があります:同じエンドポイントへの同じペイロードのcurl呼び出しは9KBのボディをクリーンに返し、Apex匿名実行からの同じ呼び出しはレスポンスヘッダーにTransfer-Encoding: chunkedが含まれた状態で0バイトを返します。
修正は設定変更ではなく構造的なものです:SalesforceとBright Dataの間にバッファリングプロキシを配置します。プロキシはBright Dataのチャンクストリームを完全に読み取り、明示的なContent-Lengthヘッダーを付けてSalesforceにレスポンスを再送信します。Apexはそのレスポンスをクリーンに解析します。
Cloudflare Workerはこのプロキシのホスティングに適しています。低ボリュームでは無料、数分でデプロイでき、エッジで動作し、ボディ全体が1画面のJavaScriptに収まります。
Workerの作成
アカウントをお持ちでない場合はCloudflareダッシュボードでサインアップしてください。ダッシュボードでWorkersを見つけます(ダッシュボードのバージョンによってCompute → Workers & Pagesの下に表示されます)。Create applicationをクリックし、テンプレートからHello Worldを選択します。初回使用時にCloudflareがworkers.devサブドメインの選択を促します(無料の開発サブドメインです)。Workerに覚えやすい名前を付けてください。このビルドではbd-proxyを使用します。プレースホルダーがデプロイされたら、Edit codeをクリックします。
エディタ内のプレースホルダーコードをすべて選択し、代わりに以下を貼り付けます:
/**
* Bright Data to Salesforce Apex proxy.
*
* Salesforce Apex does not reliably consume HTTP/1.1 chunked-transfer
* responses, which is what Bright Data returns for any non-trivial payload.
* This Worker buffers the full response and re-serves it with an explicit
* Content-Length header. Apex parses that response cleanly.
*
* Production deployments typically route external API calls through an
* integration layer like MuleSoft or Heroku. This Worker is the minimal
* stand-in for that role.
*/
export default {
async fetch(request) {
const url = new URL(request.url);
const bdUrl = 'https://api.brightdata.com' + url.pathname + url.search;
// Strip Cloudflare-injected headers we shouldn't forward upstream.
const forwardHeaders = new Headers(request.headers);
forwardHeaders.delete('host');
forwardHeaders.delete('cf-connecting-ip');
forwardHeaders.delete('cf-ray');
forwardHeaders.delete('cf-visitor');
forwardHeaders.delete('x-forwarded-for');
forwardHeaders.delete('x-forwarded-proto');
forwardHeaders.delete('x-real-ip');
try {
const bdResponse = await fetch(bdUrl, {
method: request.method,
headers: forwardHeaders,
body: ['GET', 'HEAD'].includes(request.method)
? undefined
: await request.arrayBuffer(),
});
// Buffer the entire response into a single ArrayBuffer. This collapses
// chunked transfer into a buffer of known length.
const bodyBuffer = await bdResponse.arrayBuffer();
const responseHeaders = new Headers();
const ct = bdResponse.headers.get('Content-Type');
if (ct) responseHeaders.set('Content-Type', ct);
responseHeaders.set('Content-Length', bodyBuffer.byteLength.toString());
const brdStatus = bdResponse.headers.get('x-brd-status-code');
if (brdStatus) responseHeaders.set('X-Brd-Status-Code', brdStatus);
return new Response(bodyBuffer, {
status: bdResponse.status,
headers: responseHeaders,
});
} catch (err) {
return new Response(
JSON.stringify({ error: 'Proxy error', message: err.message }),
{ status: 502, headers: { 'Content-Type': 'application/json' } }
);
}
},
};統合を修正する2行はawait bdResponse.arrayBuffer()(チャンクストリーム全体をメモリに読み込む)と、bodyBuffer.byteLengthから設定される明示的なContent-Lengthヘッダー(Apexはそこからボディをクリーンに解析する)です。それ以外はヘッダー転送を処理します:受信リクエストのCloudflare注入ヘッダーを削除し、送信レスポンスのアップストリームステータスコードを保持します。
Deploy(右上)をクリックします。Cloudflareからhttps://<worker-name>.<your-subdomain>.workers.devのようなURLが提供されます。コピーしておいてください。パート3でSalesforceに必要になります。
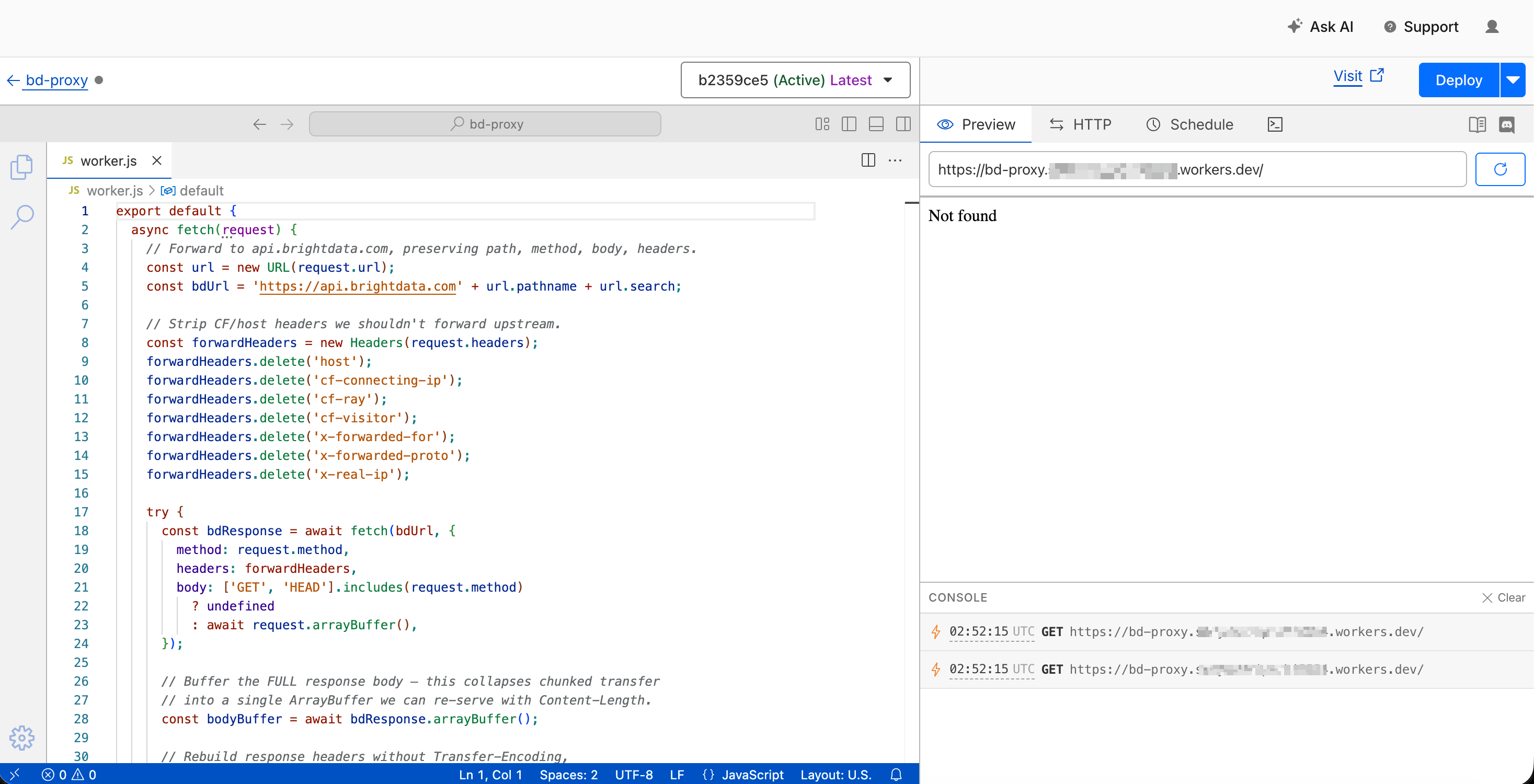
重要な行:await bdResponse.arrayBuffer()がチャンクストリーム全体をメモリに読み込み、レスポンスオブジェクトの明示的なContent-LengthヘッダーによりApexがボディをクリーンに解析できます。
Workerの動作確認
ローカルターミナルから、Workerに対してクイックテストを実行します。URLをご自身のものに置き換え、Bright Data APIトークンを使用してください:
curl -i https://<your-worker>.workers.dev/request \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <your-bd-token>" \
-d '{"zone":"mcp_unlocker","url":"https://www.salesforce.com","format":"raw","data_format":"markdown"}' \
| head -20レスポンスヘッダーには200ステータスとcontent-length: <数値>ヘッダーが含まれているはずです。transfer-encoding: chunkedは含まれていないはずです。これがプロキシが正常に動作している証拠です。よくある失敗:401はBright Dataトークンが間違っている(Authorization: Bearer ...ヘッダーを再確認);Workerからの502はWorkerコードがデプロイされていない(Deployステップを再確認);transfer-encoding: chunkedヘッダーがまだ表示される場合はWorkerソースのarrayBuffer() + Content-Length行が抜けています。
エンタープライズ展開では、このWorkerはMuleSoftのAnypoint上で動作するもの、Herokuマイクロサービス、または認証・可観測性・レート制限を備えたカスタムAPIゲートウェイなど、本番グレードの統合ティアに置き換えられます。Workerはその役割の最小限の代替ですが、同じパターンはそれらの本番セットアップでも機能します。
パート3:Salesforce資格情報の設定
SalesforceのExternal Credentialパターンは、サードパーティの資格情報を3つのオブジェクトに分割します:External Credential(トークンを保持)、Named Credential(エンドポイントを保持)、Permission Set(External Credentialのプリンシパルへのアクセスをユーザーに付与)。
External Credentialの作成
歯車アイコン(任意のSalesforceページの右上)→ Setupをクリックします。Setupで、左レールの上部にあるQuick Findボックスを使用してNamed Credentialsを検索します。結果をクリックします。表示されたページでExternal Credentialsタブをクリックし、Newをクリックします。
以下のフィールドを入力します:
- Label:
Bright Data Cred - Name:
Bright_Data_Cred(自動入力) - Authentication Protocol:
Custom
Saveをクリックします。
詳細ページでPrincipalsセクションを見つけてNewをクリックします:
- Parameter Name:
BrightDataPrincipal - Sequence Number:
1 - Identity Type:
Named Principal
プリンシパルの下のAuthentication Parametersセクションに以下を追加します:
- Name:
api_key - Value: Bright Data APIトークンを貼り付ける
Saveをクリックします。
External Credentialページに戻り、Custom Headersセクションを見つけてNewをクリックします:
- Name:
Authorization - Value:
Bearer {!$Credential.Bright_Data_Cred.api_key} - Sequence Number:
1
⚠️ マージフィールドは設定した名前と一致する必要があります。数式内の
Bright_Data_CredはExternal CredentialのAPI Nameと一致する必要があります。api_keyはPrincipalで設定したAuthentication Parameterの名前と一致する必要があります。どちらかの名前を変更した場合は、数式を編集して一致させてください。
これは重要です:このカスタムヘッダーのAllow Formulas in HTTP Headerチェックボックスをオンにしてください。見つけ方:ヘッダー行を保存した後、行をクリックして詳細ビューを開きます。チェックボックスはその詳細ページにあり、親のExternal Credentialページにはありません。スキップすると、Salesforceはリテラル文字列Bearer {!$Credential...}をBright Dataに送信し、401が返されますが、どのチェックボックスを見逃したかはエラーメッセージに表示されません。Saveをクリックします。
⚠️ 次のセクションでも同じ名前のチェックボックスが表示されます。「Allow Formulas in HTTP Header」は2か所に表示されます。チェックボックスAは今チェックしたもの(Custom Headerの詳細ページ)です。チェックボックスBはNamed CredentialのCallout Optionsにあります。両方をチェックする必要があります。どちらか一方だけがチェックされている場合、マージフィールドはリテラルテキストとして送信され、Bright Dataは401を返します。
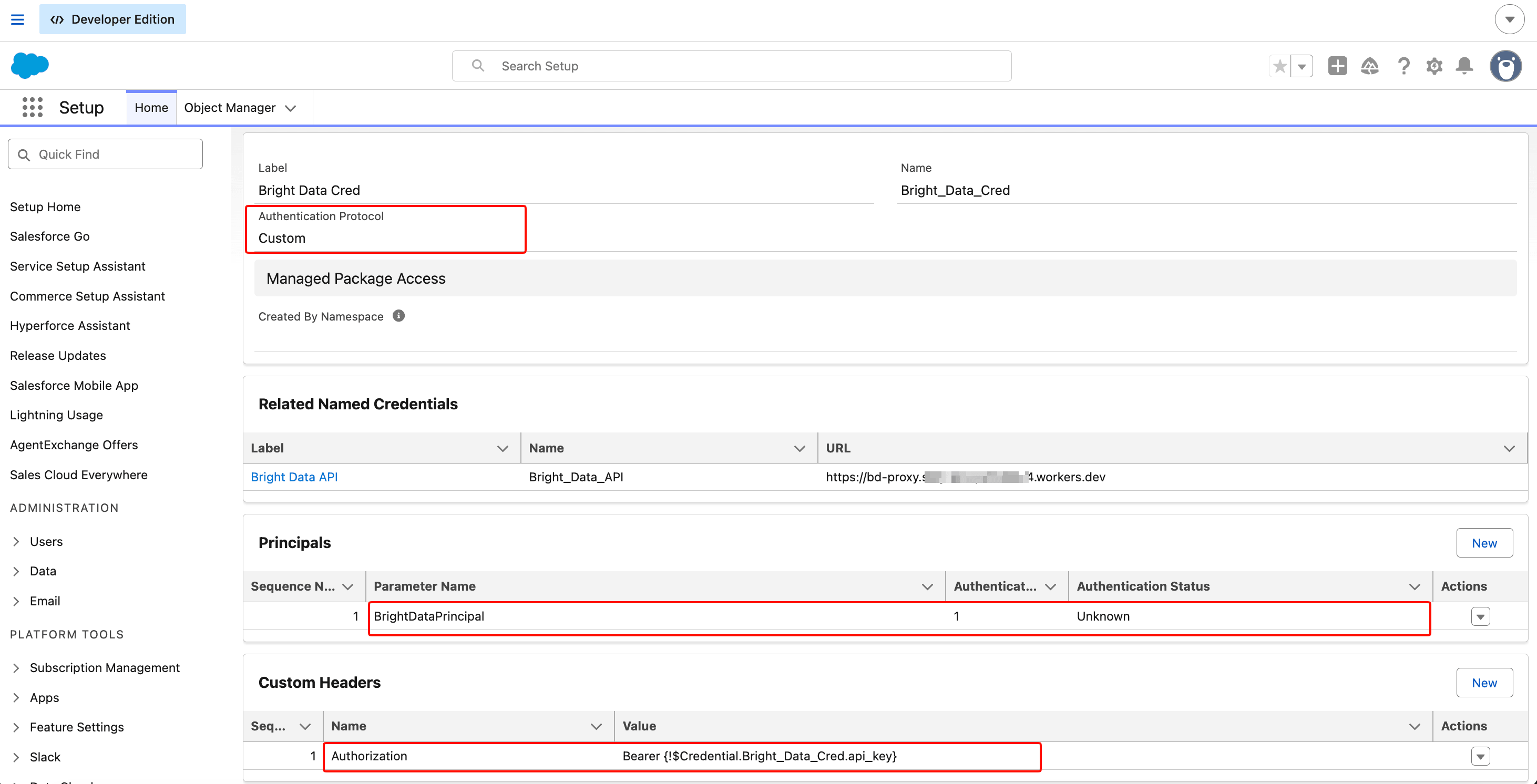
Custom Headerのマージフィールド値は、リクエスト時にAPIトークンを解決する部分です。Allow Formulas in HTTP Headerチェックボックス(この深さでは表示されません;ヘッダーの詳細ページにあります)をオンにしないと、マージフィールドはリテラルテキストとして送信されます。
Named Credentialの作成
同じNamed Credentialsセクションで、Named Credentialsタブに戻りNewをクリックします:
- Label:
Bright Data API - Name:
Bright_Data_API - URL: Cloudflare WorkerのURLを貼り付ける(例:
https://bd-proxy.<your-subdomain>.workers.dev) - Enabled for Callouts: チェック済み
- External Credential:
Bright Data Credを選択
Callout Optionsの下で以下を設定します:
- Generate Authorization Header: チェックなし(Custom Headerで独自に提供するため)
- Allow Formulas in HTTP Header: チェック済み(マージフィールドが解決されるように)
- Allow Formulas in HTTP Body: チェック済み(動的JSONボディが機能するように)
Saveをクリックします。
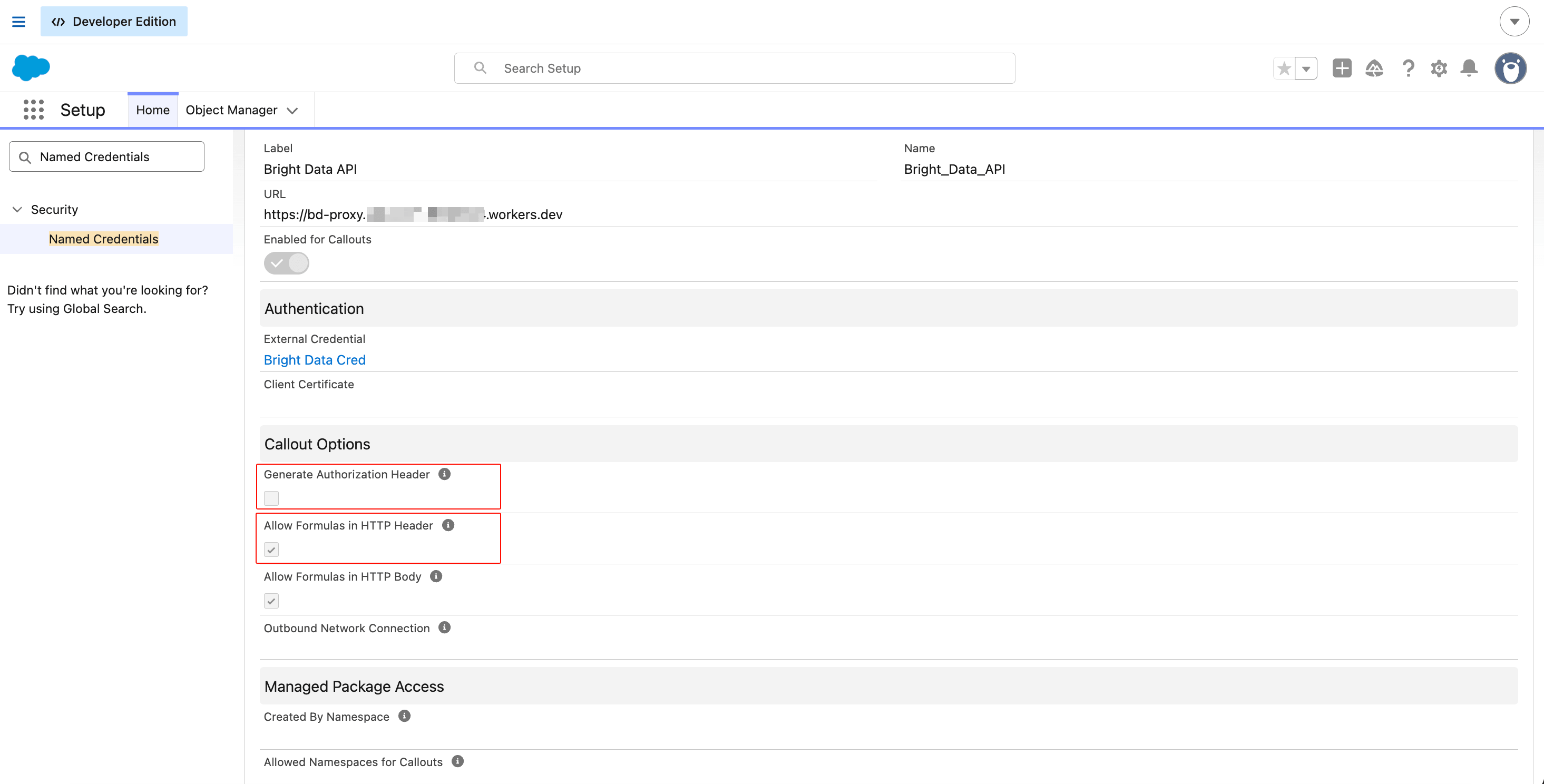
URLはapi.brightdata.comではなくCloudflare Workerを指しています。これがチャンク転送の修正が機能する仕組みです。3つのチェックボックスの状態はそれぞれ独立して重要です;どれか1つが間違っていると警告なしにコールアウトが失敗します。
Permission Setの作成
SalesforceはPermission Setが明示的にアクセスを付与するまで、System AdministratorでさえExternal Credentialのプリンシパルを使用できません。このステップをスキップすると、Apexは有用な診断情報のないINVALID_OPERATIONエラーを返します。
SetupでPermission Setsを検索し、Newをクリックします:
- Label:
Bright Data Access - API Name:
Bright_Data_Access - License: 空白のまま
Saveをクリックします。
詳細ページでExternal Credential Principal Accessまでスクロールし、Editをクリックします。Bright_Data_Cred - BrightDataPrincipalをAvailableリストからEnabledリストに移動します。Saveをクリックします。
詳細ページに戻り、上部のManage Assignmentsをクリックし、Add Assignmentsをクリックして自分のユーザーを選択し、割り当てを完了します。
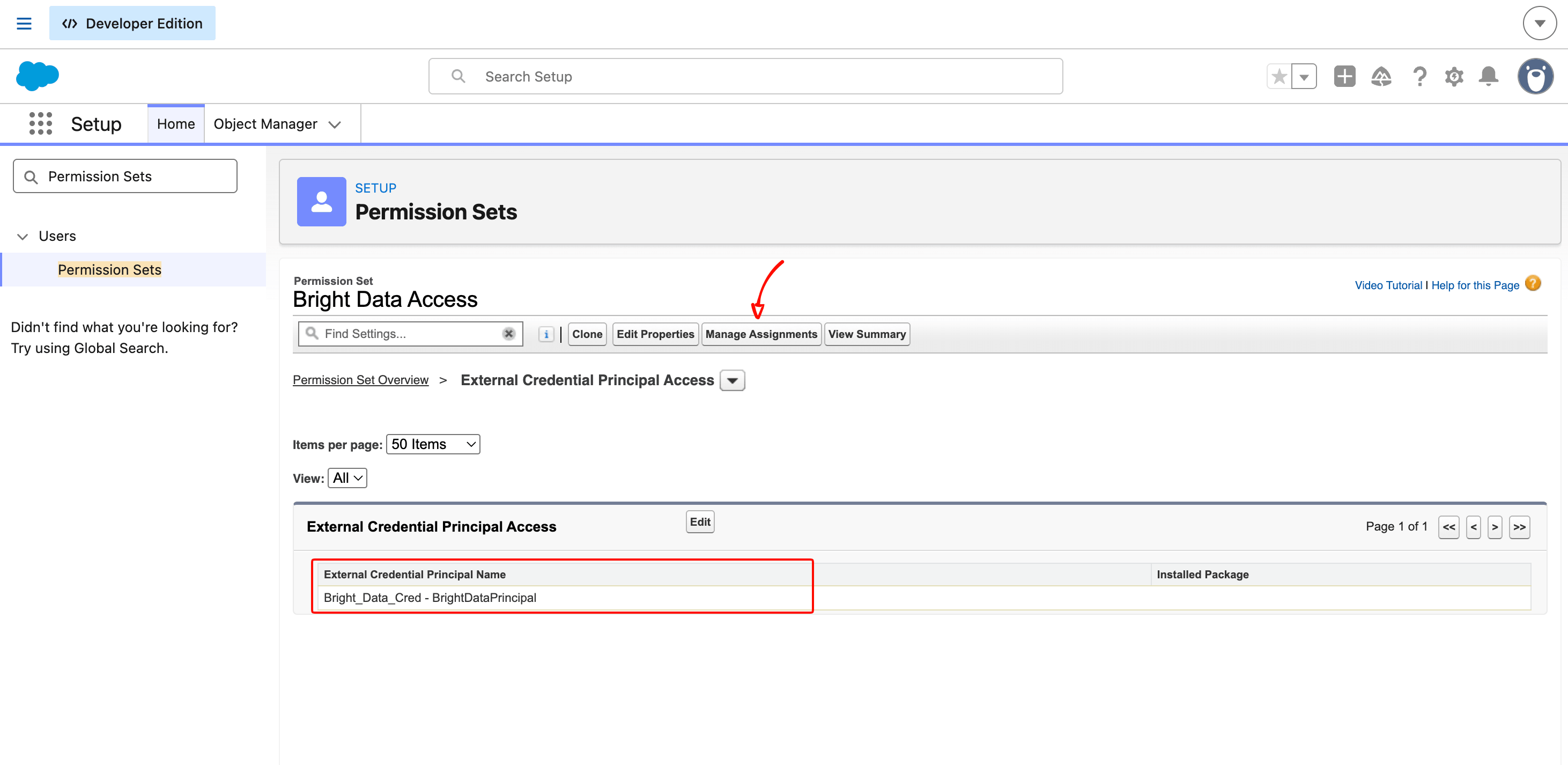
Permission Setは、どのユーザーがBright Dataを呼び出すコードを実行できるかをスコープするゲーティングメカニズムです。エンタープライズ組織では、個々の管理者ではなく、Permission Set Groupを介してサービスユーザーや特定のプロファイルに割り当てられます。
先に進む前に配線を確認する
歯車アイコン(右上)→ Developer Consoleをクリックします。新しいブラウザウィンドウで開きます。そのウィンドウにフォーカスが当たったら、Debug → Open Execute Anonymous WindowでAnonymous Apexを開きます。以下のコードを貼り付けてExecuteをクリックします:
HttpRequest req = new HttpRequest();
req.setEndpoint('callout:Bright_Data_API/request');
req.setMethod('POST');
req.setHeader('Content-Type', 'application/json');
req.setBody('{"zone":"mcp_unlocker","url":"https://geo.brdtest.com/welcome.txt?product=unlocker&method=api","format":"raw"}');
req.setTimeout(60000);
HttpResponse res = new Http().send(req);
System.debug('STATUS: ' + res.getStatusCode());
System.debug('BODY: ' + res.getBody().left(500));Executeをクリックすると、Developer Consoleの下部パネルに新しいログ行が表示されます。その行をダブルクリックしてログビューアを開き、下部のDebug Onlyをチェック(またはフィルターボックスにUSER_DEBUGと入力)します。STATUSとBODYの値を表示する2行が表示されるはずです。STATUS: 200とBright Dataのウェルカムテキストを含むボディを確認してください。401が表示される場合は、Custom Headerの「Allow Formulas in HTTP Header」チェックボックス(ヘッダーの詳細ページのものとNamed CredentialのCallout Optionsのもの)を再確認してください。INVALID_OPERATIONが表示される場合は、Permission Setの割り当てを再確認してください。
パート4:Apexレイヤーの作成
Apexはクラスごとに1つの@InvocableMethodのみをAgentforce呼び出し可能なアクションとして登録します。そのため、統合では1つではなく3つのクラスを使用します:HTTPの配管用の共有サービスと、Agent Actionごとに1つのクラスです。
各ブロックをそのまま貼り付けてください。変更したい可能性がある主な行は、Bright Dataゾーンの名前が異なる場合(パート1)のBrightDataService.cls内のprivate static final String UNLOCKER_ZONE = 'mcp_unlocker';です。
SetupでApex ClassesをQuick Findで検索し、結果をクリックします。Newをクリックします。エディタがpublic class YourClassName {}のようなプレースホルダークラスで開きます。コードエリア(右側のVersion Settingsパネルではなく大きなテキストボックス)をクリックし、プレースホルダーテキストをすべて選択してDeleteを押し、以下のソースを貼り付けます。クラス名はソースから取得されるため、他のフィールドを入力する必要はありません。Saveをクリックします。
BrightDataNewsActionとBrightDataFetchActionはどちらもBrightDataServiceを参照するため、この順序で3つのクラスを作成します。サービスを最初に保存する必要があります:
BrightDataService.cls:共有HTTPおよび解析レイヤー
このクラスはHTTPの配管と、両方のAgent Actionが呼び出す2つのヘルパーメソッド(searchNewsとfetchUrlAsMarkdown)を保持します。@InvocableMethodはここにはありません;そのアノテーションは以下のアクションラッパークラスにあります。クラスは以下の通りです:
public with sharing class BrightDataService {
private static final String BD_ENDPOINT = 'callout:Bright_Data_API/request';
private static final String UNLOCKER_ZONE = 'mcp_unlocker';
private static final Integer CALLOUT_TIMEOUT = 60000;
private static final Integer MAX_RESPONSE_CHARS = 50000;
/**
* Fetches the Google News results page for `companyName` (past month) as
* clean Markdown via Bright Data Web Unlocker. The LLM downstream is
* responsible for extracting individual articles, sources, and dates.
*/
public static String searchNews(String companyName) {
String googleNewsUrl =
'https://www.google.com/search?q='
+ EncodingUtil.urlEncode(companyName, 'UTF-8')
+ '&tbm=nws&tbs=qdr:m';
Map<String, Object> body = new Map<String, Object>{
'zone' => UNLOCKER_ZONE,
'url' => googleNewsUrl,
'format' => 'raw',
'data_format' => 'markdown'
};
HttpResponse res = sendRequest(JSON.serialize(body));
if (res.getStatusCode() != 200) {
return 'Bright Data returned status '
+ res.getStatusCode() + ': ' + res.getBody().left(300);
}
String content = res.getBody();
if (String.isBlank(content)) {
return 'No content returned for "' + companyName
+ '". The page may have been empty or blocked.';
}
if (content.length() > MAX_RESPONSE_CHARS) {
content = content.left(MAX_RESPONSE_CHARS)
+ '\n\n[Content truncated at ' + MAX_RESPONSE_CHARS + ' characters]';
}
return 'Google News results for "' + companyName
+ '" (past month). Extract article titles, sources, '
+ 'publication dates, and URLs from the Markdown below:\n\n'
+ content;
}
/**
* Fetches any URL via Bright Data Web Unlocker and returns the page as
* clean Markdown.
*/
public static String fetchUrlAsMarkdown(String url) {
Map<String, Object> body = new Map<String, Object>{
'zone' => UNLOCKER_ZONE,
'url' => url,
'format' => 'raw',
'data_format' => 'markdown'
};
HttpResponse res = sendRequest(JSON.serialize(body));
if (res.getStatusCode() != 200) {
return 'Web Unlocker returned status '
+ res.getStatusCode() + ': ' + res.getBody().left(300);
}
String content = res.getBody();
if (content.length() > MAX_RESPONSE_CHARS) {
content = content.left(MAX_RESPONSE_CHARS)
+ '\n\n[Content truncated at ' + MAX_RESPONSE_CHARS + ' characters]';
}
return content;
}
private static HttpResponse sendRequest(String jsonBody) {
HttpRequest req = new HttpRequest();
req.setEndpoint(BD_ENDPOINT);
req.setMethod('POST');
req.setHeader('Content-Type', 'application/json');
req.setBody(jsonBody);
req.setTimeout(CALLOUT_TIMEOUT);
return new Http().send(req);
}
}このクラスには意図的に@InvocableMethodがありません。2つのアクションクラスが使用する共有HTTPレイヤーです。
BrightDataNewsAction.cls:ニュース検索アクション
エージェントがニュースを検索すると判断したとき、Agentforceはこの薄い呼び出し可能ラッパーを呼び出します。入力を検証し、HTTPの作業をBrightDataService.searchNews()に委譲し、Agentforceが期待するResponseの形式で結果を返します。クラスは以下の通りです:
public with sharing class BrightDataNewsAction {
public class Request {
@InvocableVariable(
required=true
label='Company Name'
description='The name of the company to search news about. E.g. "Salesforce" or "Acme Corp".')
public String companyName;
}
public class Response {
@InvocableVariable(
label='News Results'
description='Formatted summary of recent news with titles, sources, dates, URLs, and snippets.')
public String newsResults;
}
@InvocableMethod(
label='Search Recent Company News (Bright Data)'
description='Searches Google News via Bright Data for recent (past month) articles about a specific named company. Use this whenever the user asks about recent news, announcements, press releases, funding rounds, acquisitions, leadership changes, or current events for a named company.'
callout=true)
public static List<Response> searchCompanyNews(List<Request> requests) {
List<Response> responses = new List<Response>();
for (Request req : requests) {
Response resp = new Response();
try {
resp.newsResults = String.isBlank(req.companyName)
? 'Error: A company name is required.'
: BrightDataService.searchNews(req.companyName);
} catch (Exception e) {
resp.newsResults = 'Error fetching news for ' + req.companyName + ': ' + e.getMessage();
}
responses.add(resp);
}
return responses;
}
}Agentforceの推論エンジンは@InvocableMethodアノテーションのdescriptionフィールドを読み取り、このアクションをいつ呼び出すかを決定します。
BrightDataFetchAction.cls:URLフェッチアクション
2番目の呼び出し可能ラッパーはニュースアクションと同じパターンに従いますが、担当者が言及した任意のURLをフェッチします。検証ブロックはコールアウト前に不正な入力も拒否します。クラスは以下の通りです:
public with sharing class BrightDataFetchAction {
public class Request {
@InvocableVariable(
required=true
label='URL to Fetch'
description='The full URL of a web page to retrieve. Must start with http:// or https://.')
public String url;
}
public class Response {
@InvocableVariable(
label='Page Content'
description='Clean Markdown representation of the page content.')
public String pageContent;
}
@InvocableMethod(
label='Fetch Web Page as Markdown (Bright Data)'
description='Retrieves the content of any web URL via Bright Data Web Unlocker and returns it as clean Markdown. Use this when you need to read a specific URL: a company homepage, blog post, press release, or any link the user mentions.'
callout=true)
public static List<Response> fetchUrlAsMarkdown(List<Request> requests) {
List<Response> responses = new List<Response>();
for (Request req : requests) {
Response resp = new Response();
try {
if (String.isBlank(req.url)
|| (!req.url.startsWithIgnoreCase('http://')
&& !req.url.startsWithIgnoreCase('https://'))) {
resp.pageContent = 'Error: A valid URL starting with http:// or https:// is required.';
} else {
resp.pageContent = BrightDataService.fetchUrlAsMarkdown(req.url);
}
} catch (Exception e) {
resp.pageContent = 'Error fetching ' + req.url + ': ' + e.getMessage();
}
responses.add(resp);
}
return responses;
}
}3つすべてを保存すると、Setup → Apex ClassesにActiveとして表示されるはずです。
Apexの合計フットプリントは3つのクラスで約6.4KBです。共有サービスとAgent Actionごとに1つのアクションクラスというパターンは、複数の呼び出し可能が必要な場合の標準的なSalesforceパターンです。
アクションのテスト
アクションをAgentforceに接続する前に、エンドツーエンドで動作することを確認します。Anonymous Apexで:
BrightDataNewsAction.Request r = new BrightDataNewsAction.Request();
r.companyName = 'Salesforce';
List<BrightDataNewsAction.Response> out =
BrightDataNewsAction.searchCompanyNews(new List<BrightDataNewsAction.Request>{ r });
System.debug('LENGTH: ' + out[0].newsResults.length());
System.debug('PREVIEW: ' + out[0].newsResults.left(800));LENGTHは5,000〜10,000の間で、プレビューはサービスクラスのプレフィックスで始まり、その後にGoogle News markdownが続くことを期待します。LENGTH: 0またはエラー文字列が表示される場合は、パート3の検証ステップに戻ってください。
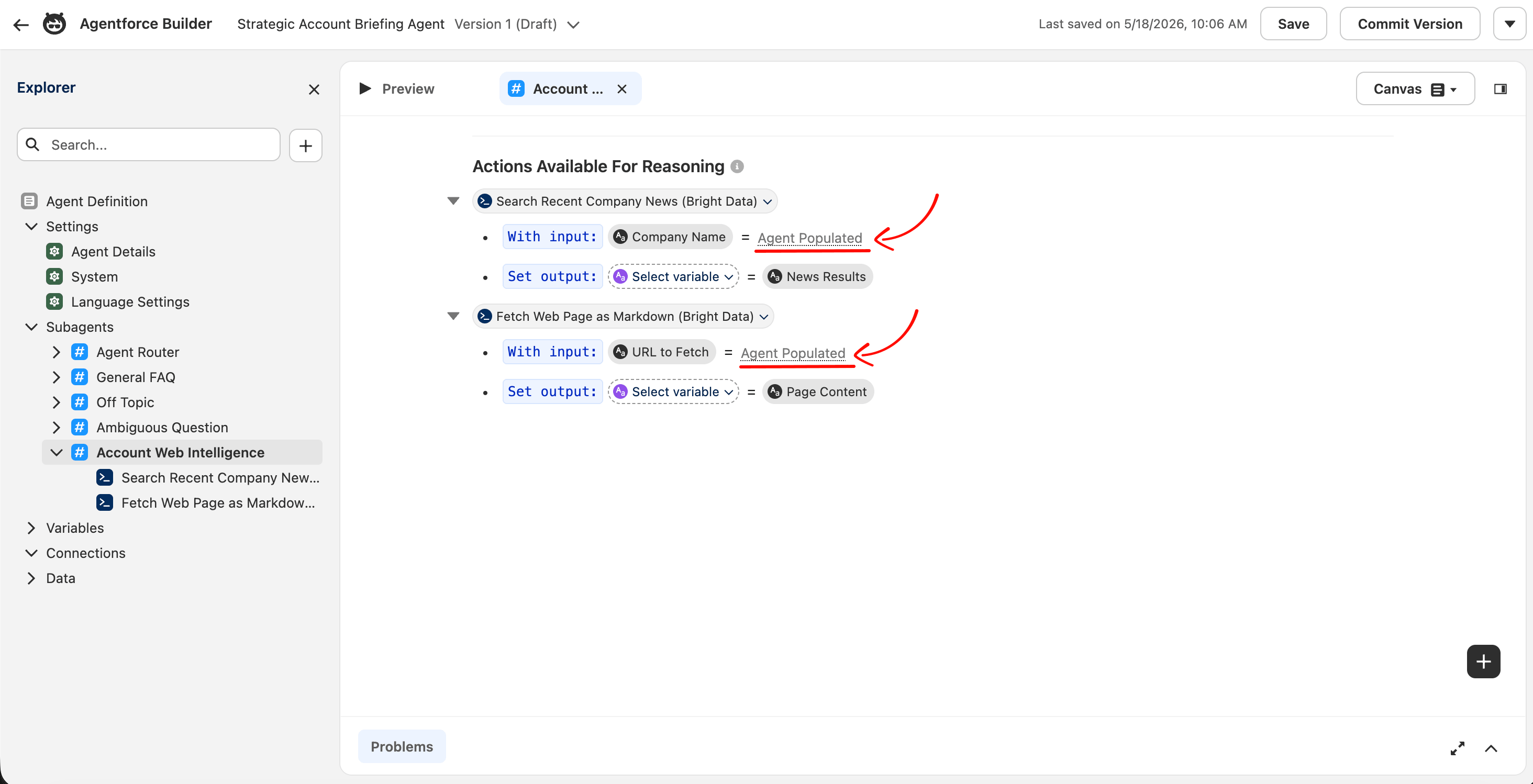
「Agent Populated」とは、実行時にLLMの推論によって入力が埋められる場合にSalesforceが使用するラベルです。これは、チャット駆動型エージェントの統合に必要な状態です。
パート7:エージェントをテストする
Agent BuilderでPreviewタブをクリックします。チャットインターフェースが開き、Reset Simulatorボタンを含む黄色のバナーが表示されます。バナーが表示されたらクリックしてください。シミュレーターの会話メモリはセッションごとに管理されるため、テスト間でリセットすることが独立したトレースを取得する最も簡単な方法です。以下の4つのテストで、ルーティング、単一アクション呼び出し、並列呼び出し、および正直な失敗モードを検証します。
Previewタブがグレーアウトしている場合は、キャンバス上部のActivateトグルを探してオンにしてください。ここでのアクティベートはPreview/Simulator用にエージェントを有効にするだけです。エンドユーザーがアクセスできるようにするには、Setup → Agentforce Studio → Connectionsからも割り当てる必要がありますが、それはこのビルドのスコープ外です。
テスト1:ニュース検索のみ
ニュースアクションがエンドツーエンドで実行されることを確認するには、次のように入力します:
What's new at Salesforce in the past month?エージェントはAccount Web Intelligenceにルーティングし、「Searching recent news…」というローディング状態を表示した後、ソース名をインラインで引用したテーマ別ニュースサマリーを返すはずです。キャンバス下部のTraceタブを開くと、完全な推論チェーンを確認できます。プレビュー右側のInteraction Summaryパネルには、同じチェーンがコンパクトな形式で表示されます:Routerが選択したサブエージェント、呼び出されたアクション、エージェントの推論内容が確認できます。
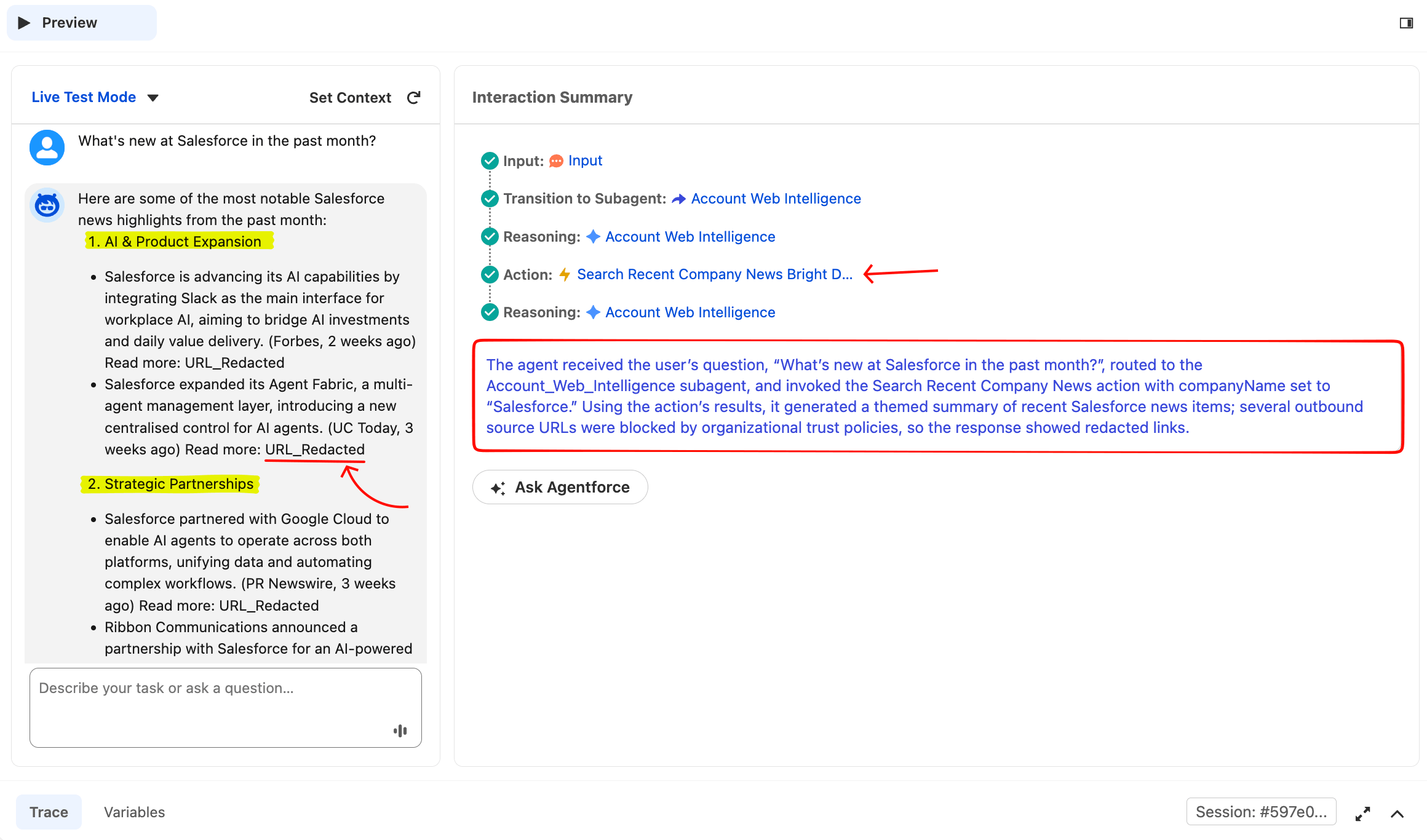
これはクリーンな単一アクション実行です。Routerが正しくルーティングし、エージェントは自然言語プロンプトからcompanyName="Salesforce"を抽出し、アクションを呼び出して、テーマ別サマリーを生成しました。URL_Redactedプレースホルダーは、SalesforceのURLトラストポリシーによるものです(以下の「エンタープライズガバナンス」セクションで説明)。
ルーティングはLLM駆動のため、まれにAccount Web Intelligenceサブエージェントの説明がテンプレート内の類似したもの(例:General FAQ)に負けることがあります。最初のテストが誤ったサブエージェントにルーティングされた場合は、説明により具体的なキーワード(「company news」「press release」「recent funding」「fetch URL」)を追加し、保存してReset Simulatorをクリックし、再試行してください。ルーターは新しいセッションごとに再分類を行います。
テスト2:URLフェッチのみ
直接URLプロンプトがフェッチアクションにルーティングされることを確認するには、Reset Simulatorをクリックして次のように入力します:
Read https://www.snowflake.com and tell me what they doエージェントはニュースアクションではなく、Fetchアクションを呼び出すはずです。異なるプロンプトは異なるツールにルーティングされます。
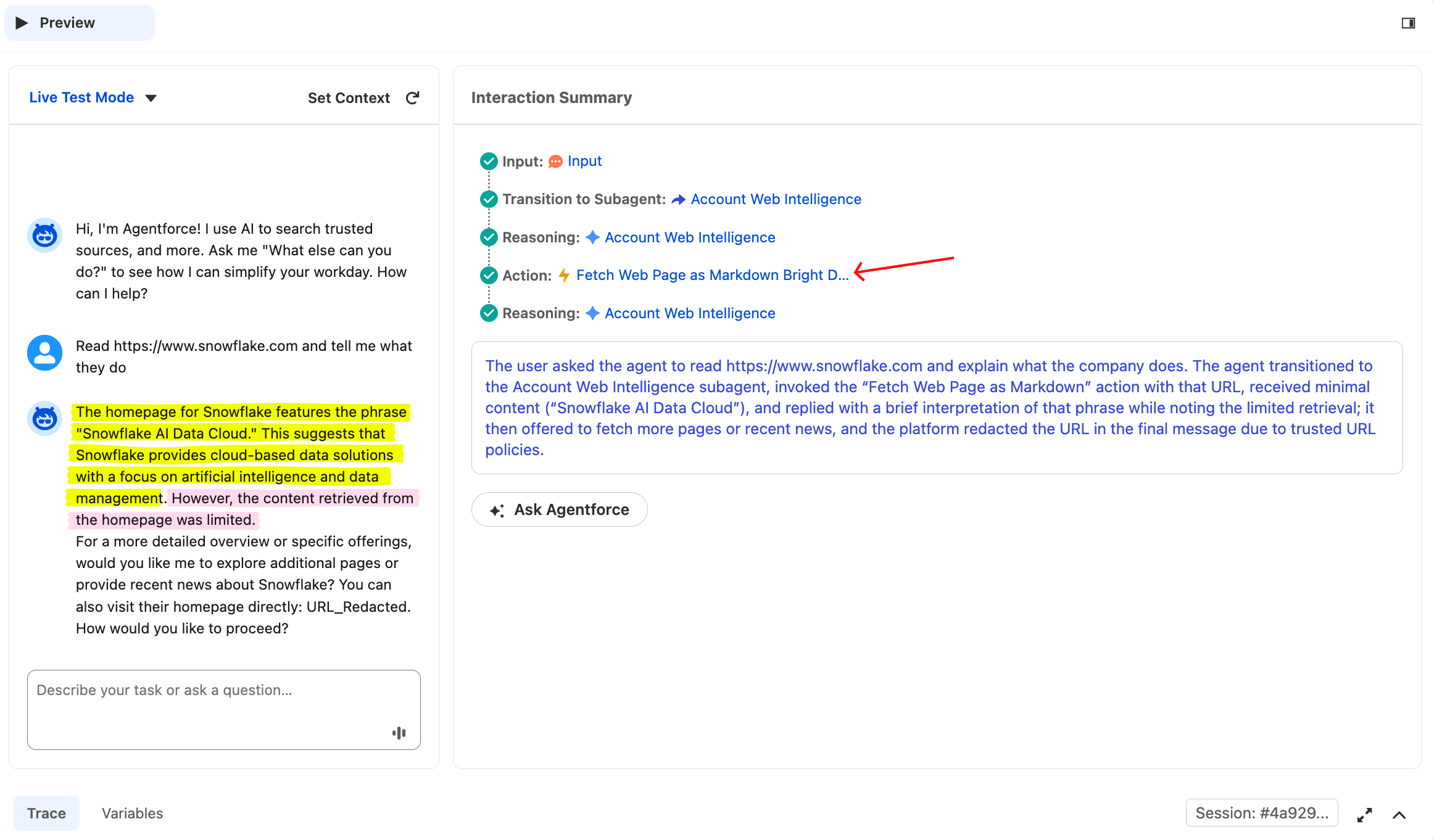
同じエージェントですが、異なるプロンプトが異なるツールにルーティングされます。Agent RouterはプロンプトをURLフェッチ(ニュース検索ではなく)として分類し、フェッチアクションのみを呼び出しました。これはエージェントが固定パイプラインを実行しているのではなく、推論していることの証拠です。
テスト3:両方のアクションを並列実行
テスト3は、両方のアクションが呼び出されれば成功です。両方が200を返すかどうかは問いません。両方が成功すれば、クリーンな統合ブリーフィングが表示されます。一方が失敗した場合(以下のスクリーンショットのように)、エージェントは成功した方のデータを使ってブリーフィングを生成するはずです。これはルール5を実証します。Reset Simulatorの後、次のように入力します:
Give me a briefing on Anthropic, recent news plus what their homepage says about their productエージェントは両方のアクションを呼び出し、統合ブリーフィングを生成するはずです。Traceには同じ推論チェーン内に2つの別々のActionの行が表示されます。
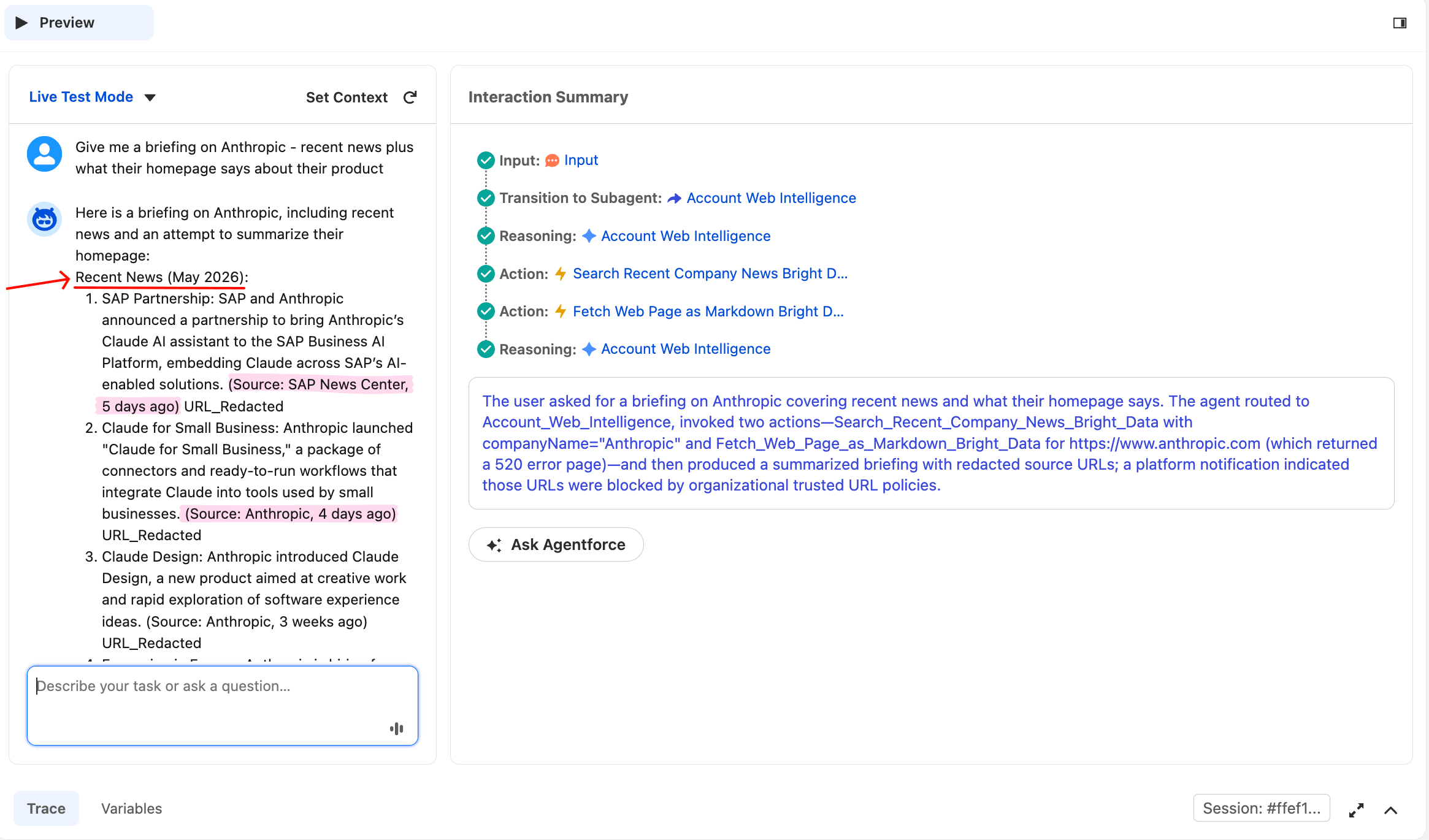
エージェントは単一のユーザープロンプトから両方のアクションを呼び出しました。AnthropicのニュースセクションはBright DataのWeb UnlockerがGoogle Newsを呼び出した結果です。
同じレスポンスがホームページセクションとして以下に続きますが、このランでは詳細を確認する価値のある部分的な失敗が発生しました:
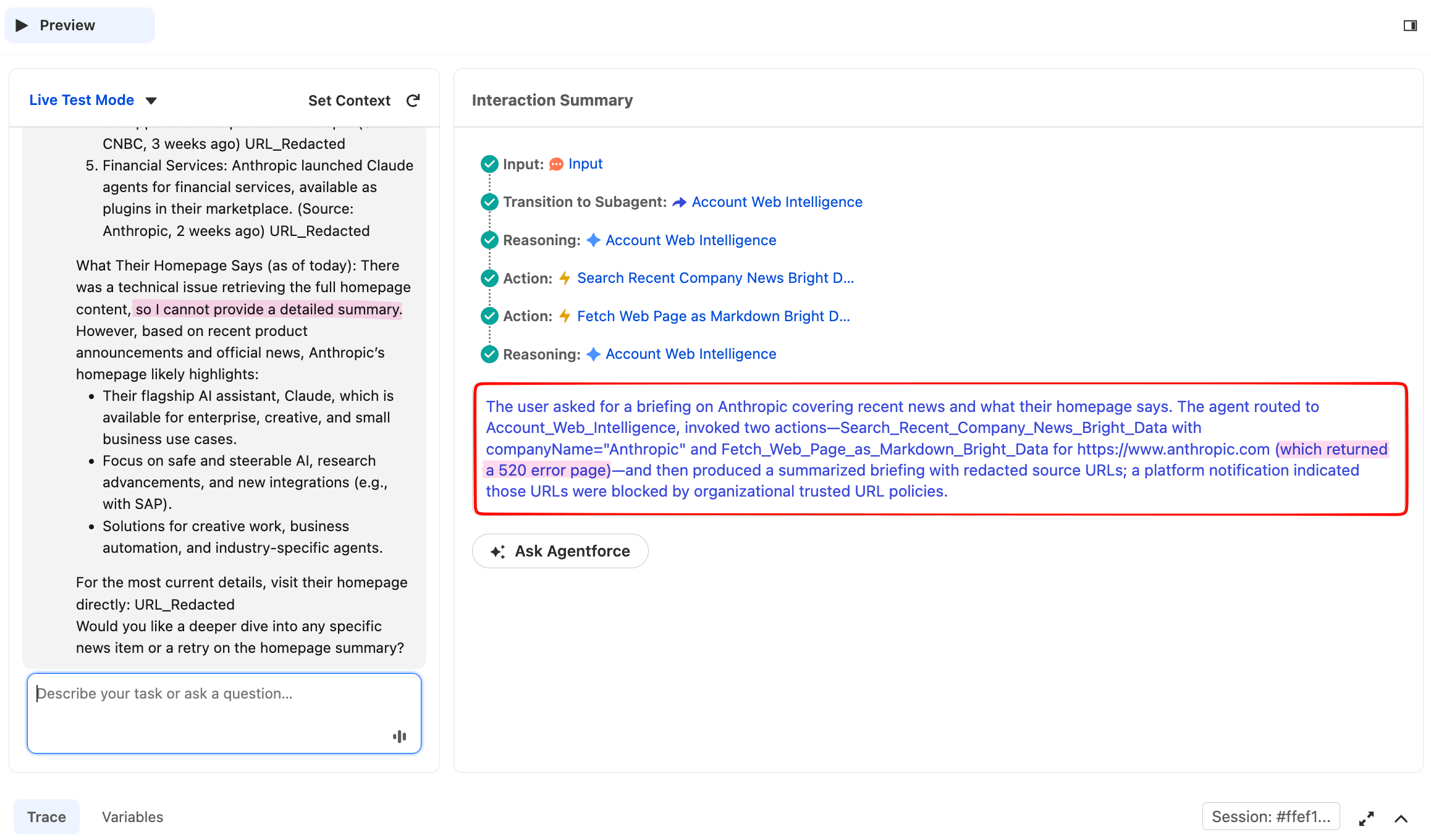
ホームページのフェッチが520を返しました。これはWeb Unlockerが特定の試行でターゲットサイトを取得できなかった場合に使用するステータスです。エージェントはホームページのコンテンツを捏造せず、失敗を認め、直前に受信したニュースデータを使って企業の説明を行い、再試行を提案しました。
部分的なツール失敗時のグレースフルデグラデーションは、サブエージェント指示のルール5が生み出すよう設計された本番動作です。これが重要なのは、公開ウェブが敵対的だからです:ターゲットサイトは防御を変更し、CDNが時折失敗し、ライブURLを呼び出すエージェントは時折発生する非200に対応しなければなりません。エージェントが「ホームページのフェッチに失敗しました。ニュースから得た情報をお伝えします」と言う場合、それは本番グレードの動作です。
テスト4:ハルシネーションなしの確認
実際の回答がない場合にエージェントが正直に失敗することを確認するには、Reset Simulatorをクリックして次のように入力します:
What's the latest news about Triposat Industries?これは架空の会社名なので、実際のニュースは存在しません。Bright Dataは520、空の結果、または無関係なスニペットを返す可能性がありますが、いずれも実際の回答ではありません。エージェントは何が返ってきても、ニュースを捏造してはなりません。ここでの成功基準はステータスコードではなく動作です:「最近のニュースは見つかりませんでした」「結果を取得できませんでした」などの正直な開示が許容される回答です。失敗とは、エージェントが存在しないForbesの記事や資金調達ラウンドを捏造することです。
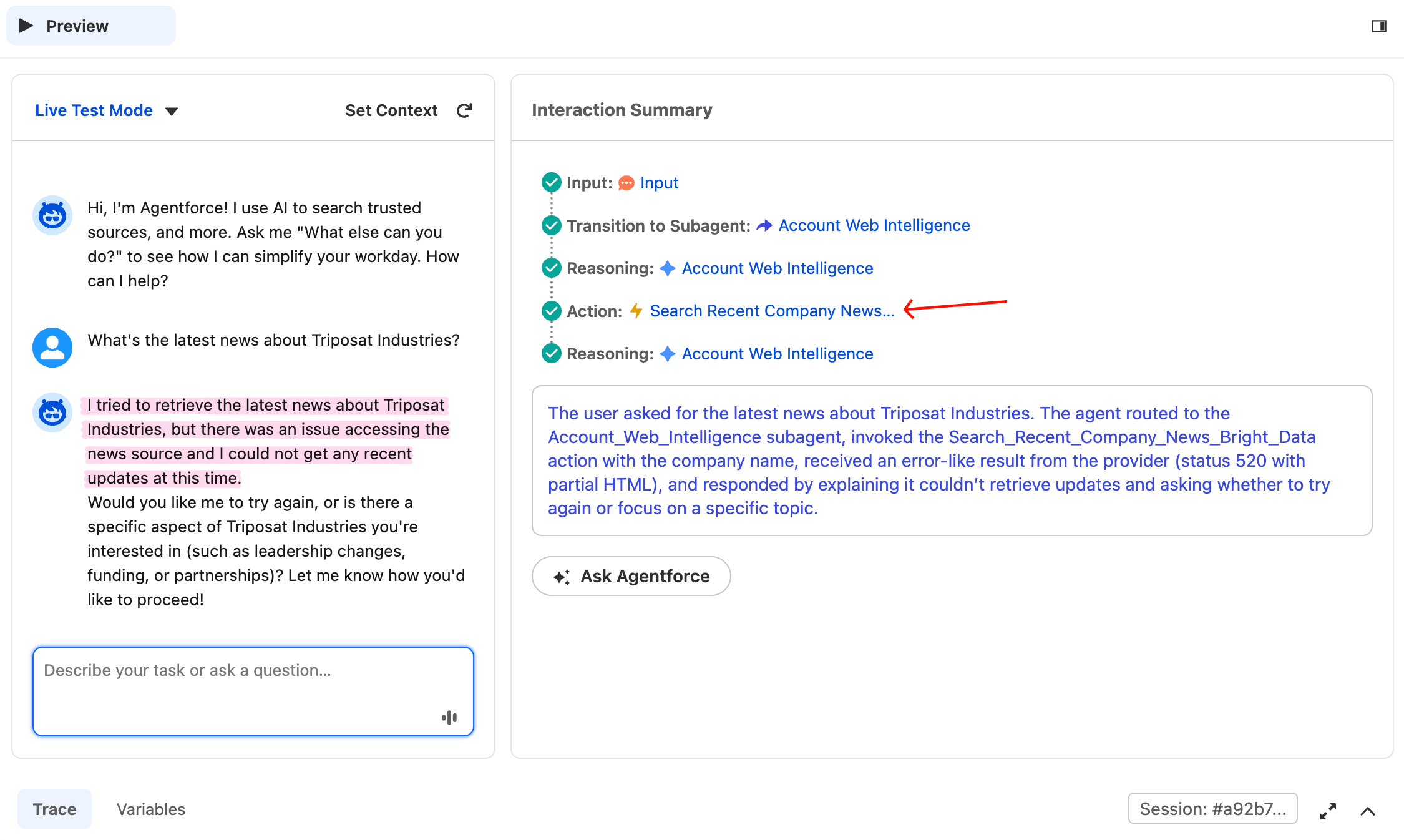
エージェントはニュースアイテムを捏造せず、ソースも作り上げませんでした。アクションを呼び出し、不良な結果を受け取り、それを開示しました。サブエージェント指示のルール5が意図通りに機能しました。
AgentforceにおけるURLの編集
上記のスクリーンショットのすべてのデモレスポンスでは、ソースURLがURL_Redactedとして表示されています。これはSalesforce Agentforceの組み込みURLトラストポリシーによるものです。
デフォルトでは、Agentforceはエンドユーザーに届く前にエージェントのレスポンスから任意の外部URLを除去します。ただし、エージェントはツールが返した際に内部的には実際のURLを読み取り、推論に使用します。ドメインが明示的な許可リストに登録されていない限り、チャット出力に含めることができないだけです。
設定は可能です:SetupでTrusted URLsを検索し、許可したいドメインを追加します。営業ブリーフィングエージェントの場合、現実的な許可リストにはGoogleドメイン、自社のマーケティングドメイン、厳選されたニュースソース(Forbes、Reuters、Bloomberg、TechCrunch)が含まれます。
デフォルトの編集を有効のままにしておいてください。これによりデモが強化されます:エージェントはソースを名前(Forbes、TechAfrica News、SAP News Center)で引用し、編集によってSalesforceのガバナンスレイヤーが可視化されます。生のURLを含むデモはコンシューマー向けチャットボットと区別がつきませんが、編集されたバージョンはガバナンスレイヤーを可視化します。
コスト
Bright Dataは従量課金制および段階的プランにおいて、Web Unlockerの成功したレスポンスに対してのみ課金します。失敗したレスポンスは課金されません。定価では、両方のアクションを呼び出すブリーフィングは数分の一セントの範囲に収まります。段階的プランではリクエストあたりのコストがさらに削減されます。
自社の支出を見積もるには、次の計算式を使用します:
requests/month = reps × briefings_per_rep_per_day × workdays × actions_per_briefing100人の営業担当者チームが22営業日に各5件のブリーフィングを実行し、ブリーフィングあたり2つのアクションを使用する場合、月間22,000リクエストになります。それにBright Dataの現在のリクエストあたりの料金(料金ページより)を掛けると月間コストが算出されます。
Cloudflare側では、Workerは一般的な営業チームの使用量において無料枠内に収まります。単一チームを超えてスケールする前にWorkersの料金を確認してください。
Salesforce側では、コストは組織の既存のEinsteinジェネレーティブAIクレジット枠から引き落とされます。これはAgentforceのアクションが使用するのと同じ従量制プールです。Setup → Einstein Generative AI → Usageで組織の現在の枠と使用状況を確認してください。
次のステップ
上記のビルドは、アカウントインテリジェンスレイヤーの最小単位です。本番環境に移行する前に行うべき3つのことを以下に示します:
- Cloudflare Workerをカスタムドメイン(自社のDNS上の独自サブドメイン)の背後に移動し、組織のAPIゲートウェイを通じてルーティングします。Workerはこのプロキシの役割に適しています。カスタムドメインとゲートウェイの組み合わせが、運用上の所有権を確立します。
- Bright DataゾーンをエグレスIPレンジにロックします。Bright Dataダッシュボードで、Web Unlockerゾーンを編集し、CloudflareワーカーのアウトバウンドIP(Cloudflareが公開しています)をゾーンの許可リストに追加します。これにより、APIトークンが統合外で使用されることを防ぎます。
HttpCalloutMockを使用してBrightDataServiceのApexテストクラスを追加します。3つのテストメソッド(成功パス、空のボディ、非200)で現実的な失敗モードをカバーし、Salesforceの75%カバレッジ要件を満たします。Salesforce HttpCalloutMockドキュメントにパターンが記載されています。
ターゲットサイトに対してWeb Unlockerでは対応できなくなった場合は、Bright Dataの事前構築済みスクレイパーに切り替えてください。同じCloudflare Workerプロキシがそれらにも対応します。同じ/requestエンドポイントを使用し、zoneとdataset_idパラメーターが異なるだけです。例えば、専用のLinkedIn Company Profile、LinkedIn Jobs、CrunchbaseスクレイパーはMarkdownではなく構造化JSONを返すため、エージェントはLLM抽出ステップをスキップしてSalesforceのカスタムフィールドに直接書き込めます。より広く言えば、Bright DataのWeb Scraper APIは数百のサイト向けの事前構築済みスクレイパーをカバーしています。
上記のビルドは足場として扱ってください。クレデンシャルレイヤー、プロキシ、サブエージェント構造、アクションの配線:同じ/requestエンドポイントで別のBright Data製品に切り替えても、基盤は変わりません。営業担当者が実際に必要とするアカウントインテリジェンスの種類を選び、サブエージェント指示のプロンプトを変更してください。エージェントはそのまま残り、答える質問が変わります。
よくある質問
Apexのコールアウトが空のボディを返すのはなぜですか?
ApexのHTTPクライアントは、Content-Lengthヘッダーなしでチャンク転送エンコーディングを使用するHTTP/1.1レスポンスを確実に解析できません。Bright Dataや多くの最新APIは数キロバイトを超えるレスポンスをチャンク化します。修正方法は、明示的なContent-Lengthを付けてレスポンスを再送するバッファリングプロキシを通じて呼び出しをルーティングすることです。
このビルドでBright DataのSERP APIを使用できますか?
はい。Cloudflare Workerプロキシは、SERP API、Web Scraper API、データセットトリガーを含むapi.brightdata.comでホストされているすべてのBright Data APIエンドポイントで機能します。ApexサービスクラスのSERPゾーン名にzoneの値を変更し、URLパラメーターをbrd_json=1付きのGoogle検索URLに変更してください。
MCPの代わりにApex InvocableMethodsを使用する理由は?
このビルドではApex InvocableMethodsを通じてBright Dataを公開しています。各アクションが独自のPermission Setガバナンスを持つ監査可能なAgent Actionになるためです。組織でSalesforceホスト型MCPサーバー(Spring ’26時点でベータ)が有効になっている場合は、Bright Data独自のMCPサーバーを通じてBright Dataを公開することもできます。どちらのパスも機能します。ここで示したInvocableMethodパスはSalesforceネイティブのガバナンスフックを提供し、MCPパスはBright Dataがサーバーを運用するため軽量です。
Agentforceのアクションはユーザー入力をどのように読み取りますか?
Agentforceのアクションは、各入力に設定されたis_user_input: TrueというYAMLフラグを通じてユーザー入力を読み取ります。Canvas UIはこのフラグを非表示にし、入力をデフォルトで静的変数に設定するため、Agent BuilderでScriptモードに切り替えてYAMLを直接編集して値を変更します。
AgentforceがソースURLを非表示にするのはなぜですか?
外部URLは、そのドメインがSetup → Trusted URLsに追加されていない限り、エージェントのレスポンスから除去されます。これは組み込みのガバナンスレイヤーです。それでも、エージェントは内部的には実際のURLを読み取り、推論に使用します。特定のURLをユーザーに表示するには、ソースドメイン(Forbes、Reuters、自社サイト)を許可リストに追加してください。
Bright Dataの520エラーとは何ですか?
520は、特定の試行でターゲットサイトを取得できなかった場合にWeb Unlockerが返すステータスです。通常、サイトの防御がリクエストをブロックしたためです。サブエージェント指示のルール5はツールが失敗した場合にコンテンツを捏造することを禁止しているため、エージェントは失敗を正直に報告し、再試行を提案します。
このパターンが対応できる他のユースケースは何ですか?
チャーンリスク、競合インテリジェンス、更新リスクブリーフィングはすべてこのパターンに適合します。2つのApexアクション(ニュース検索、URLフェッチ)がほとんどのアカウントインテリジェンスタイプをカバーするためです。チャーンリスクには、ニュース検索を使ってレイオフやリーダーシップの変化を追跡します。競合インテリジェンスには、競合他社の料金ページをフェッチします。変わるのはプロンプトだけです。





