

あなたのドメインを理解する特殊なモデルを作成するには、多くの場合、プロンプト・エンジニアリングや検索支援生成(RAG)以上のものが必要です。一般に公開されているモデルは強力ですが、最新の知識やユースケースに特化したテイストが欠けています。私たちは、記事、文書、製品リスト、ビデオのトランスクリプトに至るまで、ウェブデータを持っているので、このギャップは微調整によって埋めることができます。
このブログ記事では、次のことを学びます:
- Bright Dataのスクレイパーとデータセットを使ってドメイン固有のウェブデータを収集し、準備する方法。
- 収集したデータを使ってオープンソースのGPTモデルを微調整する方法
- 実際のタスクのために微調整したモデルを評価し、デプロイする方法。
さっそく見ていきましょう!
ファインチューニングとは
簡単に言うと、ファインチューニングとは、大規模で一般的なデータセットで事前に訓練されたモデルを、新しい、多くの場合より特殊なデータセットやタスクでうまく機能するように適応させるプロセスです。ファインチューニングを行う場合、ゼロから構築するのではなく、モデルの重みを変更することになる。重みを変更することで、モデルの振る舞いが変わったり、思い通りになったりするのだ。
ウェブデータは微調整に役立つ:
- 新鮮さ:最新のトレンド、イベント、テクノロジーを把握するために継続的に更新される。
- 多様性:さまざまな文体、情報源、考え方にアクセスできるため、狭いデータセットによるバイアスを減らすことができる。
ファインチューニングのプロセスは次のようになる:
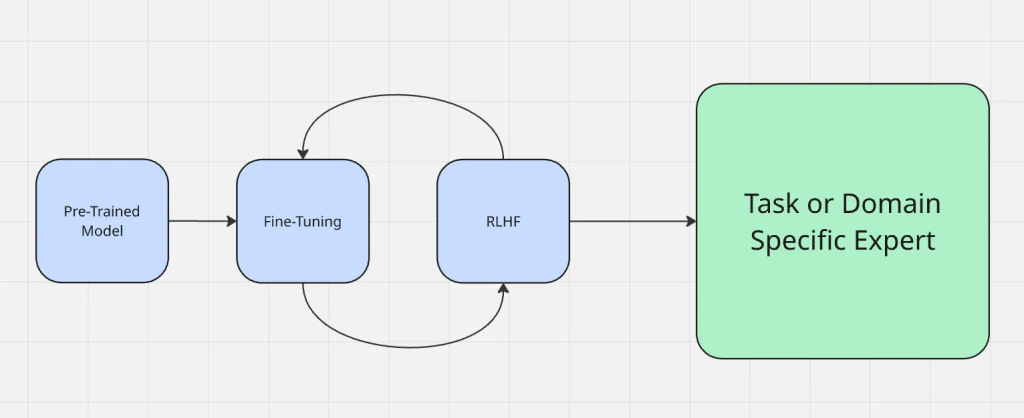
ファインチューニングは、プロンプト・エンジニアリングやリトリーバル・アグメンテッド・ジェネレーションなど、一般的に使用されている他の適応手法とは異なる。プロンプトエンジニアリングは、モデルへの質問方法を変えるが、モデル自体は変えない。RAGは、何か新しい文脈を与えるように、実行時に外部の知識ソースを追加する。一方、Fine-tuningは、モデルのパラメータを直接更新するため、毎回余分なコンテキストを与えることなく、ドメインに忠実な出力を生成することができる。
実行時に外部コンテキストでモデルをエンリッチするRAG(retrieval-augmented generation)とは異なり、ファインチューニングはモデル自体を適応させる。トレードオフについてより深く知りたい場合は、RAG vs Fine-Tuningを参照してください。
ファインチューニングにウェブデータを使う理由
ウェブデータは豊富で最新のフォーマット(記事、商品リスト、フォーラムの投稿、ビデオのトランスクリプト、ビデオ由来のテキストまで)で提供され、静的データセットや合成データセットにはない利点があります。このような多様性は、モデルが異なる入力タイプをより効果的に扱うのに役立ちます。
以下に、ウェブデータが輝くさまざまなコンテキストの例を挙げます:
- ソーシャルメディアデータ:ソーシャル・プラットフォームからのトークンは、センチメント分析やチャット・ボットのようなアプリケーションに不可欠な、インフォーマルな言葉、スラング、リアルタイムのトレンドを理解するのに役立ちます。
- 構造化データセット:製品カタログや財務報告書のような構造化されたソースからのトークンは、推薦システムや財務予測に不可欠な、正確でドメイン固有の理解を可能にします。
- ニッチ・コンテキスト:新興企業や専門的なアプリケーションは、リーガルテック用の法律文書や医療AI用の医療ジャーナルなど、ユースケースに合わせた関連データセットからトークンを調達することで利益を得ることができる。
ウェブデータは自然な多様性とコンテキストを導入し、微調整されたモデルのリアリズムとロバスト性を向上させます。
データ収集戦略
Bright Dataのような大規模なスクレイパーやデータセットプロバイダーは、大量のウェブコンテンツを迅速かつ確実に収集することを可能にします。これにより、手作業での収集に何ヶ月も費やすことなく、ドメイン固有のデータセットを構築することができます。
Bright Dataは、業界で最も多様で信頼性の高いウェブデータ収集インフラを構築し、複数の異なるネットワークアウトレットとソースで構成されています。ウェブデータはプレーンテキストに限りません。ブライト・データは、メタデータ、製品属性、ビデオトランスクリプトのようなマルチモーダル入力をキャプチャすることができ、モデルがより豊かなコンテキストを学習するのに役立ちます。
生のスクレイプを使用したデータ収集は、ほとんどの場合、ノイズ、無関係なコンテンツ、フォーマットのアーチファクトを含むため、避けるべきである。フィルタリング、重複の除去、構造化されたクリーニングは、トレーニングデータセットが混乱をもたらす代わりにパフォーマンスを向上させることを確実にするための重要なステップである。
微調整のためのウェブデータの準備
- 生のスクレイプを構造化された入出力ペアに変換する。未処理のデータがそのままトレーニングに使えることはほとんどありません。最初のステップでは、データを構造化された入出力のペアに変換する。例えば、ファインチューニングに関する文書は、”What is fine-tuning? “のようなプロンプトにフォーマットすることができ、オリジナルの回答はターゲット出力となる。このような構造により、未整理のテキストではなく、明確に定義された例からモデルが学習することが保証される。
- 多様なフォーマットに対応:JSON、CSV、トランスクリプト、ウェブページ。ウェブデータは通常、APIからのJSON、CSVエクスポート、生のHTML、動画のトランスクリプトなど、さまざまなフォーマットで提供される。ウェブデータをJSONLのような一貫性のあるフォーマットに標準化することで、管理やトレーニングパイプラインへの投入が簡単になります。
- 効率的なトレーニングのためのデータセットのパッキング。学習結果とプロセスを改善するために、データセットはしばしば「アレンジ」されます。つまり、複数の短い例を1つのシーケンスにまとめることで、無駄なトークンを減らし、微調整時のGPUメモリ使用量を最適化します。
- ドメイン固有と一般的なウェブデータのバランス。バランスをとることが重要です。単一ドメインのデータが多すぎると、モデルは狭く浅くなり、一般的なデータが多すぎると、ターゲットとする専門的な知識が希薄になる可能性があります。一般的なウェブデータの強力なベースと、ドメインに特化した事例のキュレーションをブレンドすることで、通常、最良の結果が得られます。
ベースモデルの選択
適切なベースモデルを選択することは、微調整したシステムのパフォーマンスに直接影響します。特に、各モデル・ファミリーの中に様々なものがあることを考えると、万能のソリューションはありません。データの種類や希望する結果、予算によって、あるモデルが他のモデルよりもニーズに適している場合もあります。
適切なモデルを選ぶには、以下のチェックリストに従ってください:
- モデルが必要とするモダリティは何か?
- 入力データと出力データの大きさは?
- 実行しようとしているタスクはどの程度複雑か?
- 予算に対する性能の重要度は?
- AIアシスタントの安全性はどの程度重要か?
- 御社はAzureやGCPと既存の契約を結んでいますか?
例えば、非常に長いビデオやテキスト(数時間、数十万語)を扱っている場合、Gemini 1.5 proは、最大100万トークンのコンテキストウィンドウを提供する最適な選択かもしれない。
Gemma 3、Llama 3.1、Mistral 7B、Falconモデルなど、いくつかのオープンソースモデルがウェブデータの微調整に適しています。小さいバージョンはほとんどのファインチューニング・プロジェクトで実用的であり、大きいバージョンはあなたのドメインが高いカバレッジと精度を必要とする場合に有効です。Gemma 3をファインチューニングに適応させる方法については、こちらのガイドもご参照ください。
ブライトデータによる微調整
Webデータがどのように微調整を促進するかを示すために、Bright Dataをソースとして使用した例を見てみましょう。この例では、Bright DataのScraper APIを使ってAmazonから商品情報を収集し、Hugging FaceのLlama 4モデルを微調整します。
ステップ #1: データセットの収集
Bright DataのWebスクレイパーAPIを使用すると、Pythonを数行実行するだけで、構造化された商品データ(タイトル、商品、説明、レビューなど)を取得することができます。
このステップのゴールは、以下のような小さなプロジェクトを作成することです:
- Python仮想環境を起動する
- Bright DataのWeb Scraper APIを呼び出す。
- 結果をamazon-data.jsonに保存する。
前提条件
- Python 3.10+
- Bright Data APIトークン
- Bright Data コレクター ID (Bright Data ダッシュボードより) /cp/scrapers
- OPENAI_API_KEY(GPT-4モデルを微調整するため)
プロジェクトフォルダの作成
mkdir web-scraper u0026u0026 cd web-scrapper
仮想環境の作成と有効化
シェルプロンプトの最初に(venv)と表示されるはずです。
//macOS/Linux (bash or zsh):npython3 -m venv venvnsource venv/bin/activatennWindowsnpython -m venv venvn.venvScriptsActivate.ps1
依存関係のインストール
これはHTTPウェブリクエストを行うためのライブラリです。
pip install requests
これが完了すると、Bright DataのスクレイパーAPIを使って目的のデータを取得する準備が整う。
スクレイピングロジックの定義
以下のスニペットは、Bright Dataコレクター(例:Amazon商品)をトリガーし、スクレイピングが終了するまでポーリングし、結果をローカルのJSONファイルに保存します。
ここで api key 文字列の api key を置き換えてください。
import requestsnimport jsonnimport timenndef trigger_amazon_products_scraping(api_key, urls):n url = u0022https://api.brightdata.com/datasets/v3/triggeru0022nn params = {n u0022dataset_idu0022: u0022gd_l7q7dkf244hwjntr0u0022,n u0022include_errorsu0022: u0022trueu0022,n u0022typeu0022: u0022discover_newu0022,n u0022discover_byu0022: u0022best_sellers_urlu0022,n }n data = [{u0022category_urlu0022: url} for url in urls]nn headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022,n u0022Content-Typeu0022: u0022application/jsonu0022,n }nn response = requests.post(url, headers=headers, params=params, json=data)nn if response.status_code == 200:n snapshot_id = response.json()[u0022snapshot_idu0022]n print(fu0022Request successful! Response: {snapshot_id}u0022)n return response.json()[u0022snapshot_idu0022]n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)nndef poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):n snapshot_url = fu0022https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=jsonu0022n headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022n }nn print(fu0022Polling snapshot for ID: {snapshot_id}...u0022)nn while True:n response = requests.get(snapshot_url, headers=headers)nn if response.status_code == 200:n print(u0022Snapshot is ready. Downloading...u0022)n snapshot_data = response.json()nn with open(output_file, u0022wu0022, encoding=u0022utf-8u0022) as file:n json.dump(snapshot_data, file, indent=4)nn print(fu0022Snapshot saved to {output_file}u0022)n returnn elif response.status_code == 202:n print(Fu0022Snapshot is not ready yet. Retrying in {polling_timeout} seconds...u0022)n time.sleep(polling_timeout)n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)n breaknnif __name__ == u0022__main__u0022:n BRIGHT_DATA_API_KEY = u0022your_api_keyu0022n urls = [n u0022https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-productsu0022n ]n snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)n poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, u0022amazon-data.jsonu0022)
コードを実行する
python3 web_scraper.py
すると
- スナップショットIDが表示される
- スクレイプが完了しました。
- amazon-data.jsonに保存された(…アイテム)
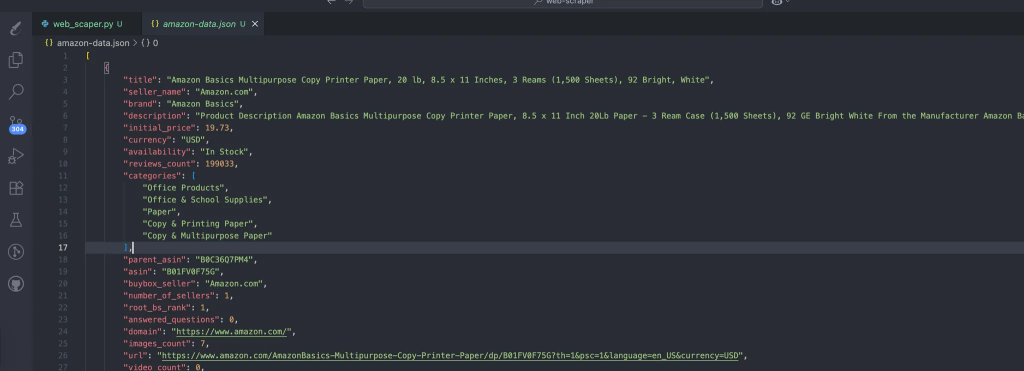
このプロセスは、スクレイピングしたデータを含むデータを自動的に作成する。これが期待されるデータの構造だ:
ステップ #2: JSONをトレーニングペアにする
次のスニペットでprepare_pair.pyをプロジェクトのルートに作成し、JSONL形式でデータを構造化します。
import json, random, osnnINPUT = u0022amazon-data.jsonu0022nOUTPUT = u0022pairs.jsonlu0022nSYSTEM = u0022You are an expert copywriter. Generate concise, accurate product descriptions.u0022nndef make_example(item):n title = item.get(u0022titleu0022) or item.get(u0022nameu0022) or u0022Unknown productu0022n brand = item.get(u0022brandu0022) or u0022Unknown brandu0022n features = item.get(u0022featuresu0022) or item.get(u0022bulletsu0022) or []n features_str = u0022, u0022.join(features) if isinstance(features, list) else str(features)n target = item.get(u0022descriptionu0022) or item.get(u0022aboutu0022) or u0022u0022n user = fu0022Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:u0022n assistant = target.strip()[:1200] # keep it tightn return {u0022systemu0022: SYSTEM, u0022useru0022: user, u0022assistantu0022: assistant}nndef main():n if not os.path.exists(INPUT):n raise SystemExit(fu0022Missing {INPUT}u0022)n data = json.load(open(INPUT, u0022ru0022, encoding=u0022utf-8u0022))n pairs = [make_example(x) for x in data if isinstance(x, dict)]n random.shuffle(pairs)n with open(OUTPUT, u0022wu0022, encoding=u0022utf-8u0022) as out:n for ex in pairs:n out.write(json.dumps(ex, ensure_ascii=False) + u0022nu0022)n print(fu0022Wrote {len(pairs)} examples to {OUTPUT}u0022)nnif __name__ == u0022__main__u0022:n main()
以下のコマンドを実行します:
python3 prepare_pairs.py
ファイルには以下のような出力があるはずです:
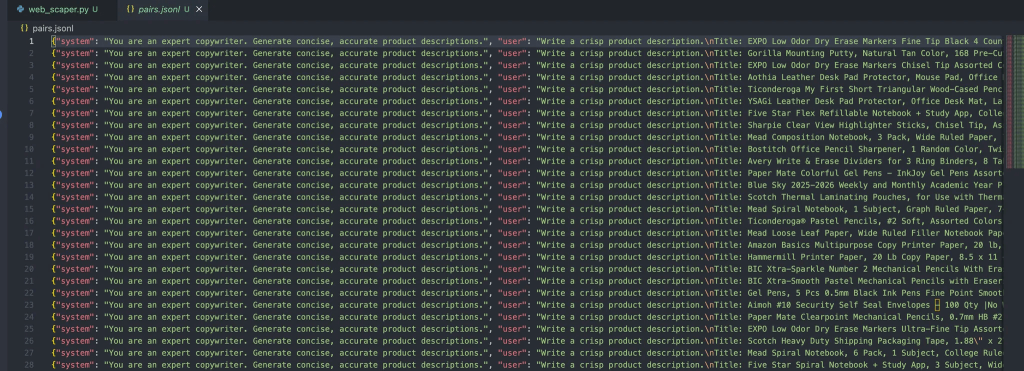
これらのオブジェクトの各メッセージには、3つのロールが含まれています:
- システム:アシスタントに初期コンテキストを提供する。
- User: ユーザーの入力。
- アシスタント: アシスタントのレスポンス。
ステップ3:微調整のためのファイルのアップロード
ファイルの準備ができたら、次のステップは、次のステップでOpenAIの微調整パイプラインに配線するだけです:
OpenAIの依存関係をインストールする
pip install openai
データセットをアップロードするupload.pyを作成します。
このスクリプトは、既にあるpairs.jsonlファイルから読み込みます。
from openai import OpenAInclient = OpenAI(api_key=u0022your_api_key_hereu0022)nnwith open(u0022pairs.jsonlu0022, u0022rbu0022) as f:n uploaded = client.files.create(file=f, purpose=u0022fine-tuneu0022)nnprint(uploaded)
以下のコマンドを実行します:
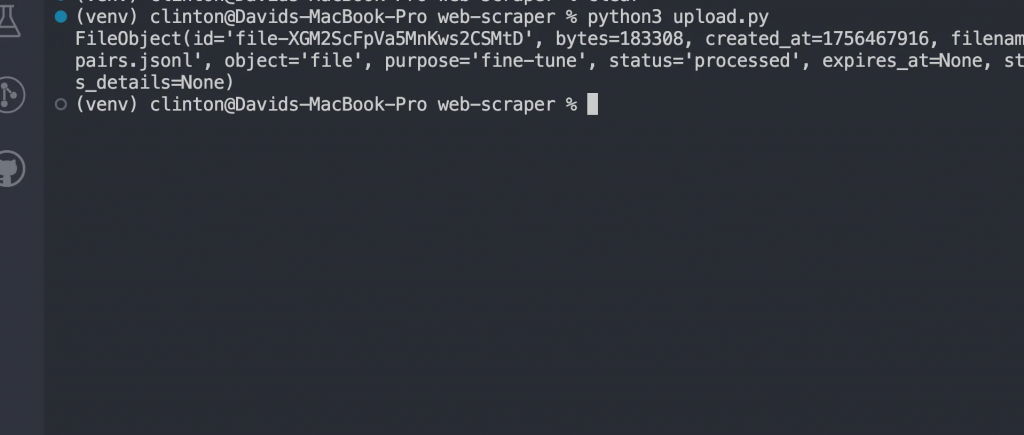
python3 upload.py
のようなレスポンスが表示されるはずです:
モデルの微調整
fine-tune.pyファイルを作成し、FILE_IDをアップロードされたファイルIDに置き換えて実行します:
from openai import OpenAInclient = OpenAI()nn# replace with your uploaded file idnFILE_ID = u0022file-xxxxxxu0022nnjob = client.fine_tuning.jobs.create(n training_file=FILE_ID,n model=u0022gpt-4o-mini-2024-07-18u0022n)nnprint(job)
すると、このようなレスポンスが返ってくるはずです:
トレーニングが終了するまで監視する
ファインチューニングを開始すると、モデルはデータセット上で学習する時間を必要とします。データセットのサイズにもよるが、数分から数時間かかる。
しかし、いつ準備が整うかを推測するのではなく、次のコードをmonitor.pyに書いて実行します。
from openai import OpenAInclient = OpenAI()nnjobs = client.fine_tuning.jobs.list(limit=1)nprint(jobs)
そして、ターミナルでpython3 [manage.py](http://manage.py)を使ってファイルを実行すると、次のような詳細が表示されるはずです:
- トレーニングが成功したか失敗したか。
- 学習されたトークンの数
- 微調整された新しいモデルのID。
このセクションでは、ステータスフィールドに
u0022succeededu0022
微調整したモデルとチャットする
この作業が終わると、カスタム GPT モデルが完成します。これを使うには、chat.pyを開き、MODEL_IDをファインチューニングジョブから返されたもので更新し、ファイルを実行します:
from openai import OpenAInclient = OpenAI()nn# replace with your fine-tuned model idnMODEL_ID = u0022ft:gpt-4o-mini-2024-07-18:your-org::custom123u0022nnwhile True:n user_input = input(u0022User: u0022)n if user_input.lower() in [u0022quitu0022, u0022qu0022]:n breaknn response = client.chat.completions.create(n model=MODEL_ID,n messages=[n {u0022roleu0022: u0022systemu0022, u0022contentu0022: u0022You are a helpful assistant fine-tuned on domain data.u0022},n {u0022roleu0022: u0022useru0022, u0022contentu0022: user_input}n ]n )n print(u0022Assistant:u0022, response.choices[0].message.content)
このステップで、微調整がうまくいったことが証明されました。このステップで、微調整がうまくいったことが証明されます。汎用のベースモデルを使う代わりに、あなたのデータに対して特別にトレーニングされたモデルと会話することになります。
このステップで、結果が現実のものとなります。
次のような結果が期待できます:
u002du002d- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data u002du002d-nnPROMPT for item: ErgoPro-EL100nGENERATED (Fine-tuned):n**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**nnExperience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.nnThe breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.nnBuilt to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simplynu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002dnnPROMPT for item: HeightRise-FD20nGENERATED (Fine-tuned):n**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**nnTake your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.nn**Experience the Benefits of Standing**nnThe HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.nn**Durable and Reliable**nnWith a sturdy construction and non-slip rubber feetnu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002d
結論
ウェブスケールでファインチューニングを行う場合、制約とワークフローについて現実的に考えることが重要です:
- リソース要件:大規模で多様なデータセットでのトレーニングには、計算機とストレージが必要です。実験する場合は、スケーリングする前にデータのスライスを小さくすることから始めましょう。
- 徐々に反復する:最初の試みで数百万レコードをダンプするのではなく、より小さなデータセットで改良を加えましょう。その結果から、前処理パイプラインのギャップやエラーを発見する。
- 展開ワークフロー:微調整したモデルを他のソフトウェア成果物と同様に扱う。バージョンアップし、可能であればCI/CDに統合し、新しいモデルのパフォーマンスが低下した場合に備えてロールバックオプションを維持します。
幸いなことに、Bright Dataはデータセットの取得や作成のための数多くのAI対応サービスであなたをカバーしています:
- スクレイピング・ブラウザ:スクレイピング・ブラウザ: Playwright、Selenium、Puppeter互換のブラウザで、ロック解除機能を内蔵しています。
- ウェブスクレーパーAPI:100以上の主要ドメインから構造化データを抽出するための設定済みAPI。
- ウェブアンロッカー:ボット対策が施されたサイトのロック解除を処理するオールインワンAPI。
- SERP API:検索エンジンの検索結果のロックを解除し、完全な SERP データを抽出する専用 API。
- 基盤モデル用データ:準拠したウェブスケールのデータセットにアクセスし、事前学習、評価、微調整を行います。
- データプロバイダー:信頼できるプロバイダーと接続し、高品質でAIに対応したデータセットを大規模に調達します。
- データパッケージ:構造化、エンリッチ化、アノテーションが施された、すぐに使えるデータセットを入手できます。
ウェブデータを使用して大規模な言語モデルを微調整することで、強力なドメイン特化が可能になります。ウェブは、記事やレビューからトランスクリプトや構造化メタデータまで、キュレーションされたデータセットだけでは対応できない、新鮮で多様なマルチモーダルコンテンツを提供します。
Bright Dataのアカウントを無料で作成して、AI対応のデータインフラをお試しください!




