

検索拡張生成(RAG)と微調整(ファインチューニング)は、AIにおける全く異なる二つの概念であり、それぞれが異なる目的を果たします。RAGはLLMが実行時に外部情報にアクセスすることを可能にします。微調整はLLMが内部知識を調整し、より深く永続的な学習を実現します。
このガイドを読み終える頃には、以下の質問に答えられるようになります。
- ファインチューニングとは何か?
- RAGとは何か?
- ファインチューニングはいつ使用すべきか?
- RAGはいつ使用すべきか?
- RAGとファインチューニングはどのように補完し合うのか?
ファインチューニングとは?
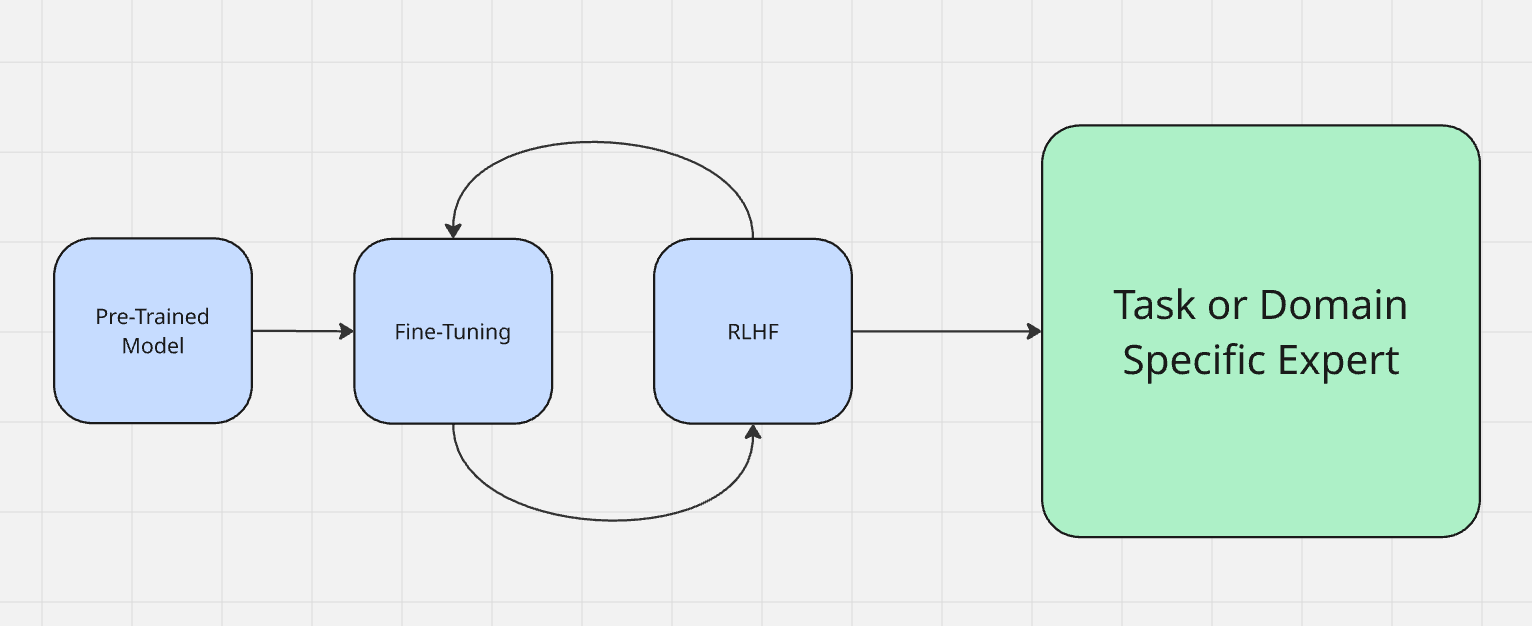
ファインチューニングは、実際のモデルトレーニングプロセスの一部と見なされることが多いです。モデルのトレーニング方法についてはこちらをご覧ください。モデルはまず「事前学習」と呼ばれる段階を経ます。簡単に言えば、これはモデルが入力を取り込み、出力を生成することを学ぶ段階です。事前学習が終了すると、モデルは膨大な知識を蓄えますが、それを適用するにはまだ最適化されていません。
通常、モデルは人間からのフィードバックを用いた強化学習(RLHF)で微調整します。微調整では、モデルの出力テストのために実際にモデルと対話します。例えばモデルが「空は緑色です」と言った場合、「空は青色です」と訂正する必要があります。 微調整では、機械の出力を評価し、意図した行動を強化します。これは、犬の「いい子だね!」という褒め言葉や、悪い行動への新聞紙の巻き上げに似ています。
LLMを微調整するとき、実際の現実世界のタスクに向けて準備しているのです。微調整には主に2つのタイプがあります。
- ドメイン適応: DeepSeekのようなベースモデルでプログラミングの専門家を作りたいと想像してください。十分な基盤を持つ強力なモデルはありますが、まだ何の専門家でもありません。 確かにシェルコマンドやほとんどのPythonコードは理解できますが、専門性が不足しています。ここで StackOverflowやLeetCodeなどを用いて、コンピュータサイエンスやコーディングの細かな技術を教えます。微調整が完了すれば、人間よりも速く優れたコードを書けるモデルが完成するのです。
- タスク適応:タスク適応とは、目の前の課題に適応することを指します。現在のLLMでは、実際のチャットで最もよく見られます。2026年初頭、ChatGPT-4oは対話者の感情に合わせるため、非常に強力な微調整を受けました。 このケースでは、RLHF(強化学習によるヒューマンフィードバック)を用いてボットがユーザーの感情を反映するよう促しました。ユーザーが技術的に話すならGPTも技術的に応答し、法律について話すならGPTは法律用語で応答します。ユーザーが宗教的な口調なら、GPTは宗教的な口調に切り替わります(はい、本当に)。
ファインチューニングは、モデルの実際の意思決定や推論に影響を与えるために使用されます。
RAGとは何か?
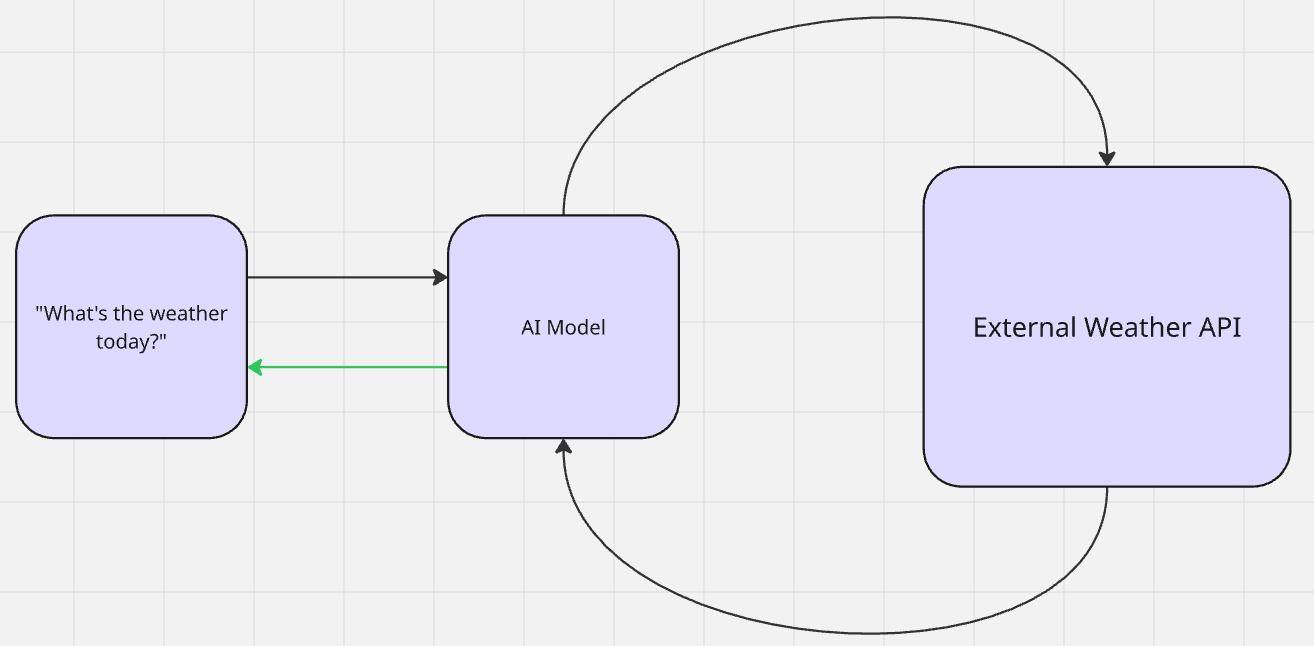
RAGでは実際の学習は行われません。AIが文脈的関連性のために追加データを検索し、出力を生成します。出力生成後、モデルは検索前の状態に戻ります。これはゼロショット学習の一形態です。モデルは事前文脈ゼロで情報を参照し、事前学習を活用して推論を行い出力を生成します。
Geminiに「今日の天気は?」と尋ねると、天気情報を検索(検索)し(知識を拡張)、その後回答(生成)します。
RAGには主に2種類ある:受動型と能動型。これは記憶を保存する最新世代のチャットモデルで最もよく示される。
- パッシブRAG:「記憶」はベクトルデータベース内に保存され、後で文脈参照されます。LLMがあなたの名前や好みを認識している場合、これがパッシブRAGです。参照される情報は静的で永続的なものです。「記憶」を削除する唯一の方法は手動での削除です。
- 能動型RAG:先ほどの天気例を思い出してください。天気は日々変化します。モデルは(おそらくAPIを介して)能動的に天気情報を検索します。天気を理解したと確信すると、独自の「個性」でそれを吐き出して返します。
RAGパイプラインはこの正確なワークフローに従います:データの取得 → 推論の拡張 → 出力の生成。
ファインチューニングはいつ行うべきか?
ファインチューニングは、モデルの思考方法を定義したい場合に最適です。知識と推論を恒久的にしたい場合はファインチューニングすべきです。LLMがデータを真に理解する必要がある場合も同様です。
モデルの生成結果が不適切だったり、思考プロセスにわずかな違和感がある場合——ファインチューニングが必要です。
- トーンとパーソナリティ:モデルに特定の態度やイントネーションを持たせたい場合、ファインチューニングを行う。これはカスタマイズされたチャットボットで特に有用である。Grok 3がユーザー定義のパーソナリティで世界を驚かせたのも、主にファインチューニングによるものだった。
- エッジケースと精度:モデルがエッジケースで問題を起こす場合、またはトレーニングデータを適切に表現できない場合、微調整が必要です。これは特に医療診断に用いられるモデルに当てはまります。法律を妄想するモデルは訴訟につながる可能性があります。病状を妄想するモデルは患者にとって危険です。
- モデルサイズとコスト削減:ファインチューニングはモデルのサイズと運用コストを大幅に削減できる。例えばLlamaチームはGPT-4の出力をGPT-3.5に蒸留することに成功した。詳細は彼らのファインチューニングドキュメントを参照されたい。
- 新規タスクと機能:事前学習済みモデルに存在しない真の能力を追加したい場合、ファインチューニングが必要です。例えば、英語のみ使用するように訓練されたモデルをスペイン語出力に活用したい場合、プロンプトエンジニアリングやRAGでは解決できず、ファインチューニングが必須となります。
RAGはいつ使うべきか?
RAGは、既に正しく推論できるモデルに最適です。ファインチューニング後にモデルが正しい出力を生成できる場合、外部データアクセスにRAGを追加するタイミングと言えるでしょう。適切なコンテキストがなければ、モデルは多くのタスクで無力化されがちです——どれほど賢くても変わりません。
先ほどの天気の例を思い出してください。地球上で最も賢いモデルを持っていても、ライブデータにアクセスできなければ、そのモデルは天気予報——あるいはリアルタイム情報を提供できません。RAGは以下のデータニーズに有効です。
- リアルタイムデータ:気象例で既に説明しました。ニュース、財務予測、システム監視、その他の高速データストリームが含まれます。
- 研究支援/図書館アシスタント:適切な情報源への誘導が必要な場面。GeminiやBrave Searchに質問すると直接回答が得られる。モデルが文書を精査し関連リソースを指し示す。
- カスタマーサポート:ヘルプデスクを担当し一般的な質問に回答するLLMが必要な場合、RAGは迅速かつ効果的です。AIモデルは既に質問への回答方法やドキュメントの読み方を理解しており、適切なコンテンツへのアクセスさえ必要とします。
- カスタマイズ出力:GPTのユーザーに反映されたトーンについて先述したのを覚えていますか?これは中世の魔術ではありません。モデルはデータベースに保存された事実を参照しているのです。OpenAIがユーザーごとにモデルを再トレーニングしなければならなかったら、存在していません。
選択方法
モデルに高度な推論能力が必要な場合はファインチューニングを、外部情報が必要な場合はRAGを活用すべきです。現実的にはハイブリッドシステムへの移行が進んでいます。実運用環境では、モデルは明確な推論と適切なデータアクセスが求められます。下記表はプロジェクトにおける各手法の適用判断を支援します。
| 状況 | 最適な選択肢 | 理由 |
|---|---|---|
| 出力内容が不適切または整合性がない場合 | 微調整 | 推論・口調・行動を修正中 |
| 出力は正確だが詳細が不足している | RAG | 外部またはドメイン固有の事実が不足しています |
| 更新された事実やリアルタイムデータが必要です | RAG | 静的モデルは学習後に学習できません |
| 新しい領域で高い性能を求めます | 微調整 | 深い専門知識を内部化して追加したい |
| 精度と最新性の両方が必要 | 両方 | 論理処理には微調整、外部知識にはRAGを活用 |
RAGと微調整のためのBright Dataツール
Bright Dataでは、ファインチューニングとRAGの両方のニーズを満たす堅牢なツールセットを提供しています。トレーニングデータセットからリアルタイムパイプラインまで、あらゆる要件に対応します。
微調整
- データセット:インターネット全域から取得した履歴データを毎日更新。ソーシャルメディア、商品リスト、Wikipediaに至るまで、トレーニング用に準備済みです。
- アーカイブAPI:マルチモーダルデータやその他のソースでトレーニング可能。毎日ペタバイト規模のデータが追加されます。
- アノテーション: AI支援型と人間による監督型ラベリングから選択可能な柔軟なアノテーションサービスでトレーニングを加速。
RAG
- 検索 API:画像やショッピングなどカスタムパラメータを指定し、主要検索エンジンでリアルタイムのウェブ検索を実行。
- Unlocker API:当社のマネージドプロキシサービスを利用し、ウェブ上のほぼ全てのサイトをスクレイピング。
- Agent Browser: AI エージェントのためのフルスケールのブラウザ自動化。
- MCPサーバー:シームレスな統合により、AIエージェントを当社のツールに接続。
結論
ファインチューニングはモデルに思考方法を教えます。RAGはモデルを再トレーニングしたり肥大化させたりせずに外部データへのアクセスを提供します。実際には、開発の異なる段階で両方を併用すべきです。
ファインチューニングとRAGの使用タイミングと理由を理解することで、自社AIモデルに関する適切な判断が可能になります。ドメイン特化型エキスパートの構築でも、リアルタイムデータへのアクセス提供でも、当社のツールとサポートが常に皆様を支えます。
無料トライアルに登録して、今すぐ始めましょう!





