

AIに意識はない。AIは、”考える “ことも “感じる “こともできない、はるかに単純なアルゴリズムを組み合わせている。この単純化されたプロセスは “モデル “と呼ばれる。新しいトレーニング方法のおかげで、モデルはより賢く、より効率的になり、ますます私たちの日常生活に溶け込んでいる。
もしあなたが独自のAIをトレーニングすることに興味があるなら、そのプロセスを理解するために読んでみてほしい。
AIトレーニングとは何か?
私たちは訓練プロセスを通じてAIモデルに教える。人間はまず、食べること、歩くこと、話すことを学ぶ。LLMはまず、数学、読解、文章構成などの基本を学びます。学校を卒業すると、数学や読解といった日常的なスキルを学ぶことになる。そして、決して必要としない他のスキルを学ぶ。AIも同様のプロセスをたどる。入力を処理して出力を生成できるようになると、あなたや私の想像を超える大規模なデータセットを使ってモデルが訓練される。
新しい手法のおかげで、これらのデータセットは縮小している。データセットが小さくなれば、モデルも小さくなる。より良いデータは、よりスリムで意地悪なAIを生む。グーグルやマイクロソフトは現在、AI内蔵のノートパソコンを出荷している。コンピューティングが向上すれば、モデルはより効率的になる。近い将来、AIはスマートフォンのハードウェア上でネイティブに動作するようになるだろう。2050年までには、トースターと哲学的な深い会話ができるようになるかもしれない。
実世界でのAIトレーニング
AIモデルは、あなたが思いもよらないような多くの場所ですでに使われている。チャットボットや画像ジェネレーターはもうお馴染みだ。AIと機械学習の実世界での応用は、皆さんが思っているよりもずっと遠くまで広がっている。
- ヘルスケア医療データに対するモデルのトレーニングはますます増えている。診断のスピードアップや、医師がめったに遭遇しないような稀な健康状態の検出に使われることが多い。
- 医薬品:モデルは仮想の化合物を作成し、その有効性を分析する。このような擬似試験によって、従来の方法と比較して、何年も–何十年も–試行錯誤を省くことができる。
- 金融2010年代後半、人々はAIモデルがいかに効率的に取引パターンを分析できるかに気づいた。現在では、AIを活用した取引は暗号と株式の両方で業界標準となっている。
- エンターテインメントNetflix、Spotify、そしてYouTubeでさえも、学習済みのモデルを使って新しいコンテンツを推薦している。これらのモデルは、あなたが次に何を楽しむかを正確に予測するために、あなたのメディア消費を分析しているのだろう。Netflixのレコメンデーションがゴミだった頃を覚えているだろうか?その改善は、AIの台頭と直結している。
- 航空宇宙:NASAは惑星データの分析にAIモデルを使用している。これにより、地球だけでなく、遠くの惑星についてもより良い研究が可能になる。
上記のリストは氷山の一角に過ぎない。ゼロショット学習により、AIは見たこともないデータで意思決定を行うことができるようになった。新しい学習方法が登場するにつれ、高品質のモデルは着実に日常生活に溶け込んでいる。料理を完璧に調理する方法を知っているオーブンを想像してみてほしい!
AIモデル学習プロセス
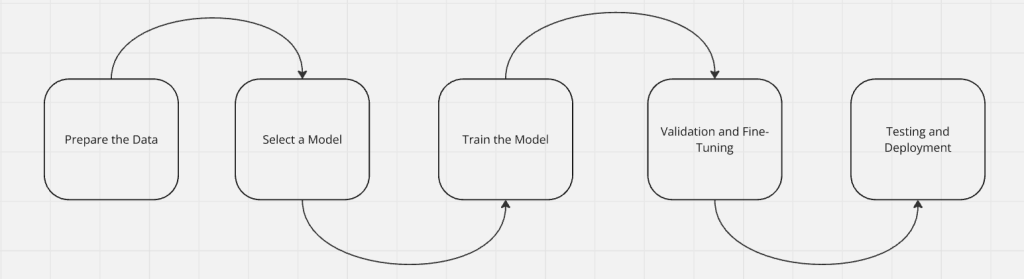
子供に文字を教えるとき、百科事典を渡して立ち去ることはしない。まず文字を教える。そして単語、最終的には文章へと進む。文章から段落、そして完全な本へと進む。これと同じ段階がAIモデルにも当てはまる。まず、モデルは入力(読み取ったデータ)を処理することを学習する。次に、出力を生成することを学習する。十分な学習が終わると、モデルは独自に学習を始めることができる。微調整が完了したら、モデルをテストし、実世界で使用するために配備する。
ステップ1:データの準備
モデルにはデータが必要だ。モデルを選ぶ前に、まずどのようなデータでモデルを訓練するかを決める必要がある。データはきれいで、フォーマットが整っており、実世界のパターンを反映したものでなければならない。
生データはしばしばノイズが多く、一貫性がなく、不完全である。モデルに投入する前に、データをクリーニングし、フォーマットする必要がある。スプレッドシートのような構造化データでも、テキストやビデオのような完全な非構造化データでも、品質と関連性が重要です。自炊用のオーブンにゴルフをさせるようなトレーニングはしないでしょう!
高品質なデータはトレーニング時間を短縮し、小さくてもスマートなモデルを生み出します。当社のデータセットマーケットプレイスは、クリーンですぐに使えるデータをすぐに提供します。
ステップ2:トレーニングモデルの選択
作成したいAIに適したトレーニングモデルを選択する必要があります。以下のモデルのうちの1つ、あるいはそれらを組み合わせて使用することができます。
- 大規模な言語モデル:チャットボットによく使われる。膨大なデータセットで訓練され、人間の言葉を自然に処理するように設計されている。LLMは、学習データに基づいて予測を行うことで、テキストを読み取り、生成する。ChatGPT、Claude、DeepSeekはすべてLLMの例です。
- 畳み込みニューラルネットワーク:これらのモデルは画像や動画の解析に使用される。実際の例としては、ResNet、EfficientNet、YOLO(You Only Look Once)などがあります。
- リカレント・ニューラル・ネットワークとトランスフォーマー:これらのモデルは予測、音声認識、シーケンシャルデータに優れている。GPTやBERTはこの例として広く使われている。LLMは実はトランスフォーマーの分家である。
- 決定木とランダムフォレスト決定木とランダムフォレストは、データの分類と予測モデリングに最適です。このタイプは金融モデルやリスク評価に最適です。XGBoost、CatBoost、Scikit-learnのDecisionTreeClassifierなどがその例です。
- 強化学習モデル:Deep Q-Networks(DQN)、AlphaGo、PPO(Proximal Policy Optimization)はすべて強化学習を使用している。これは、AIモデルが時間をかけて戦略を学習する必要がある場合に最適である。ルンバは強化学習によってリビングルームを移動し、家具を避ける。
ステップ3:モデルのトレーニング
トレーニングはゆっくりとしたプロセスである。新しい技術を習得するのと同じように、練習、フィードバック、調整の継続的なループである。モデルは、その目的を果たせるようになるまで改善し続ける。
- 入力と処理:モデルにはデータ(ラベル付きまたはラベルなし)が入力され、処理される。
- 学習と調整:モデルがデータを処理するにつれ、関係を発見し、一般化を行う。私たちはモデルにフィードバックを与え、その精度と意思決定に磨きをかけます。
- チューニング:調整が形になり始めたら、より詳細な調整、チューニングに集中することができる。この段階で、モデルはすでに多くのタスクを効率的にこなせるようになっていますが、まだ本番用とは言えません。
ステップ4:検証と微調整
自動車を運転したことがないのに運転免許試験を受けることを想像してみてほしい。運転免許の筆記試験には合格したが、運転経験はない。アクセルペダルで車が加速し、ブレーキで車が止まることは知っている。ハンドルで曲がることも知っている。ハンドルを握ってみて、すぐに自分の準備が整っていないことを知る。ペダルを踏むタイミングが合わず、急ハンドルを切ってしまい、バーン! 初めての交通事故を起こしてしまったのだ。運転には理論だけでなく経験が必要なのだ。
検証と微調整の間、モデルは実世界のシナリオでテストされる。これには、深い会話、財務モデリング、画像生成などが含まれる。モデルは、実世界での能力を練習し、洗練させる必要がある。この段階において、開発者はモデルが適切に動作するように正確な調整を行う。自動車を停止させるとき、ただブレーキを踏むのではなく、スムーズにペダルを踏み、緩やかに停止させる。同じように、AIモデルもあなたの目標に正確に沿った出力を生成するように学習します。
ステップ5:テストと配備
一度もテストされたことのない薬を使うだろうか?紙の上ではすべて良さそうに見えるが、副作用はまったく不明で、効能も証明されていない。これはちょっと危険な感じがしませんか?
テストされていないモデルを配備することもないだろう。2010年代後半、不十分な訓練を受けたAIがソーシャルメディア上で訓練された後、本番環境に配備された。適切なテストが行われていれば、その後の企業の恥や社会的非難を防げたかもしれない。
「火を起こせば、その人は一日暖かく過ごせる。火をつければ、その人は一生暖かく過ごせる。–テリー・プラチェット
モデルが厳密にテストされれば、配備の準備は整う。テストが失敗した場合は、改良を加えて再試行する。
モデルトレーニングの課題
AIのトレーニングは太陽と虹ばかりではない。避けなければならない落とし穴がたくさんある。AIトレーニングにおける最大の問題は、実はソフトウェア開発全般を悩ませるものと同じだ。
- 粗悪または汚染されたデータ:ゴミを使ってモデルを訓練すると、ゴミのようなモデルが出来上がる。
- テストが弱い、あるいは存在しない:ありとあらゆるシナリオをテストする必要がある。さもなければ、テリー・プラチェットの引用に出てくる男のようになってしまう。
- ブラックボックス問題:ニューラルネットワークはしばしば “ブラックボックス “と呼ばれる。どのように機能するのか、まだ完全には解明されていない。あるニューロンが発火し、他のニューロンと会話することは分かっている。ニューラルネットワークのデバッグは、ネアンデルタール人に脳外科手術を頼むようなものだ…棍棒で。
モデルトレーニングの未来
AIのトレーニングは、私たちが考えもしなかった方法で進化している。今日、LLMにLLMの作り方を聞けば教えてくれる。近い将来、AIモデルは他のAIモデルを直接トレーニングするようになるだろう。彼らに感情がないのは良いことだ。
数発学習のおかげで、トレーニングデータとAIモデルは縮小している。より効率的な新しい手法が日々登場している。より賢いモデルは、より弱いハードウェアで動作している。トレーニングが飛躍的に進歩するたびに、我々は哲学的に啓発されたトースターに近づいている……そして他のもっと便利なものにも。
結論
適切なトレーニングがなければ、AIモデルは墜落し、燃え尽きる。われわれは長い道のりを歩んできたが、まだ表面しか見ていない。AIが私たちの日常生活により深く関わるようになるにつれ、今後10年間に私たちが目にするイノベーションは計り知れない。数年前、ChatGPT 3.5が世界を覆したが、これはほんの始まりに過ぎない。独自のAIモデルのトレーニングをお考えなら、私たちのAIツールをご覧ください。
独自のデータを調達したい場合は、ウェブスクレイパーをご覧ください。今すぐ無料トライアルをお試しください!





