

信頼性の高いWebデータ抽出ソリューションの構築は、適切なインフラストラクチャから始まります。このガイドでは、任意の公開ウェブページURLと自然言語プロンプトを受け付けるシングルページのアプリケーションを作成します。そして、スクレイピング、解析、クリーンで構造化されたJSONを返し、抽出プロセスを完全に自動化します。
このスタックは、Bright Dataのボットスクレイピング対策インフラ、Supabaseの安全なバックエンド、Lovableの迅速な開発ツールを1つのシームレスなワークフローに統合している。
何を作るか
ユーザーの入力から構造化されたJSONの出力と保存まで、あなたが構築する完全なデータ・パイプラインを紹介します:
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
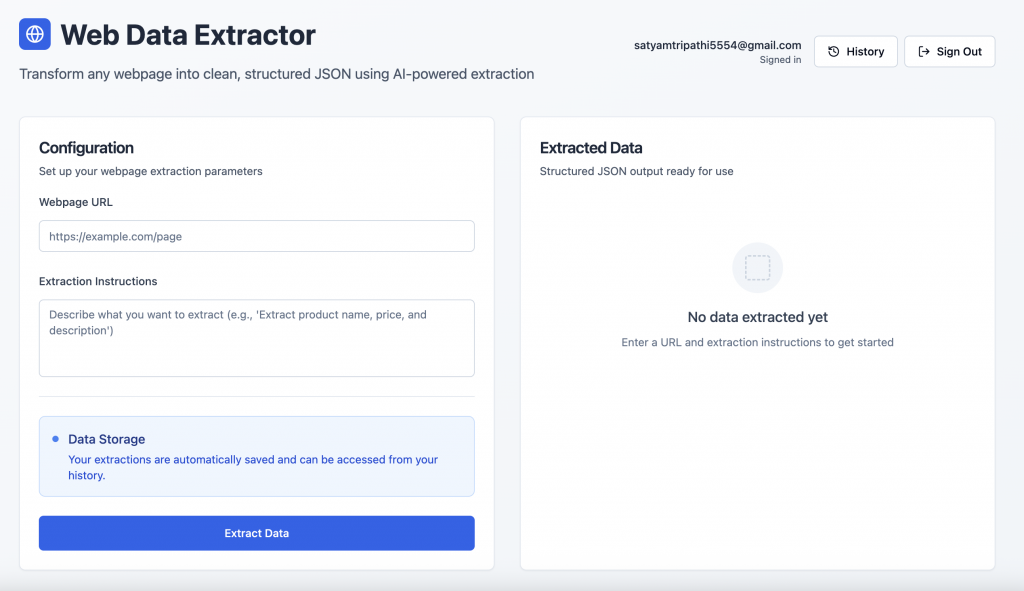
User Export完成したアプリの外観はこんな感じだ:
ユーザー認証:Supabaseの認証画面を使って、安全にサインアップやログインができます。

データ抽出インターフェース:サインイン後、ユーザーはウェブページのURLを入力し、自然言語プロンプトで構造化データを取り出すことができる。
技術スタックの概要
以下は、私たちのスタックの内訳と、各コンポーネントが提供する戦略的優位性である。
- ブライトデータウェブスクレイピングはしばしばブロック、CAPTCHA、高度なボット検知に遭遇します。Bright Dataは、このような課題に対応するために開発されました。以下の機能を提供します:
- 自動プロキシローテーション
- CAPTCHA解決とボット保護
- 一貫したアクセスのためのグローバルインフラ
- 動的コンテンツのためのJavaScriptレンダリング
- レート制限の自動処理
このガイドでは、Bright DataのWeb Unlockerを使用します。この専用ツールは、最も保護されたページからも確実に完全なHTMLを取得します。
- Supabase:Supabaseは、モダンアプリケーションのためのセキュアなバックエンド基盤を提供します:
- 組み込みの認証とセッション処理
- リアルタイム対応のPostgreSQLデータベース
- サーバーレスロジックのためのエッジ関数
- 安全な鍵の保管とアクセス制御
- Lovable Lovableは、AIを搭載したツールとSupabaseとのネイティブな統合により、開発を効率化します。Lovableは以下を提供します:
- AIによるコード生成
- シームレスなフロントエンド/バックエンドの足場作り
- React + TailwindのUIがそのまま使える
- プロダクション対応アプリの迅速なプロトタイピング
- Google Gemini AI:Geminiは自然言語プロンプトを使って生のHTMLを構造化されたJSONに変換します。サポートしています:
- 正確なコンテンツ理解と解析
- 全ページコンテキストのための大きな入力サポート
- スケーラブルでコスト効率の高いデータ抽出
前提条件とセットアップ
開発を始める前に、以下にアクセスできることを確認してください:
- ブライト・データ・アカウント
- 登録はbrightdata.comから
- ウェブアンロッカーゾーンの作成
- アカウント設定からAPIキーを取得する
- Google AI Studioアカウント
- グーグルAIスタジオへ
- 新しいAPIキーを作成する
- スーパーベース・プロジェクト
- supabase.comに登録する
- 新しい組織を作り、新しいプロジェクトを立ち上げる。
- プロジェクトのダッシュボードで、[Edge Functions] →[Secrets] → [Add New Secret]を選択します。
BRIGHT_DATA_API_KEYやGEMINI_API_KEYなどのシークレットをそれぞれの値で追加します。
- 愛すべきアカウント
- lovable.devに登録する
- プロフィール→設定→統合
- Supabase の下にあるConnect Supabaseをクリックします。
- APIアクセスを承認し、作成したSupabase組織にリンクする。
Lovableのプロンプトでステップ・バイ・ステップでアプリケーションを構築する
以下は、フロントエンドからバックエンド、データベース、インテリジェントな解析まで、Webデータ抽出アプリを開発するための構造化されたプロンプトベースのフローです。
ステップ1 – フロントエンドのセットアップ
クリーンで直感的なユーザーインターフェイスをデザインすることから始める。
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingステップ2 – Supabaseに接続し、認証を追加する。
Supabaseプロジェクトをリンクする:
- Lovableの右上にあるSupabaseアイコンをクリックします。
- コネクト・スーパーベースを選択
- 以前に作成した組織とプロジェクトを選択する
LovableはあなたのSupabaseプロジェクトを自動的に統合します。リンクが完了したら、以下のプロンプトを使用して認証を有効にしてください:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovableが必要なSQLスキーマとトリガーを生成します。
ステップ #3 – Supabaseデータベーススキーマの定義
抽出ア ク テ ィ ビ テ ィ を ロ グ ・ 格納す る ために必要なテーブルをセ ッ ト ア ッ プ し ます:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataステップ4 – Supabase Edge Functionの作成
この関数は、核となるスクレイピング、変換、抽出ロジックを処理する:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);Gemini AIに送信する前に生のHTMLをMarkdownに変換することには、いくつかの重要な利点がある。不要なHTMLのノイズを除去し、よりクリーンで構造化された入力を提供することでAIのパフォーマンスを向上させ、トークンの使用量を削減することで、より高速でコスト効率の高い処理につながります。
重要な考慮事項:Lovableは自然言語からアプリを構築することに長けていますが、Bright Dataや Geminiのような外部ツールを適切に統合する方法を必ずしも認識しているとは限りません。正確な実装を保証するために、プロンプトにサンプルコードを含めてください。例えば、上記のプロンプトのfetchContentViaBrightDataメソッドは、Bright Data の Web Unlocker の簡単な使用例を示しています。
Bright Dataは、Web Unlocker、SERP API、Scraper APIなど複数のAPIを提供しており、それぞれにエンドポイント、認証方法、パラメータがあります。Bright Dataのダッシュボードで製品やゾーンを設定すると、概要タブに設定に合わせた言語固有のコードスニペット(Node.js、Python、cURL)が表示されます。これらのスニペットをそのまま使用するか、Edge Functionのロジックに合わせて変更してください。
ステップ #5 – フロントエンドをEdge Functionに接続する
Edge関数の準備ができたら、Reactアプリに統合します:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesステップ6 – 抽出履歴の追加
ユーザーに過去のリクエストを確認する方法を提供する:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutステップ#7 – UIの磨き上げと最終的な機能強化
便利なUIタッチで体験を洗練させる:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the page結論
この統合は、Supabaseによる安全なユーザーフロー、Bright Dataによる信頼性の高いスクレイピング、Geminiによる柔軟でAIを活用した解析など、最新のウェブオートメーションのベストを結集したものである。
ご自分で構築する準備はできていますか?brightdata.comで始めましょう。インフラに頭を悩ませることなく、どんなサイトにもスケーラブルにアクセスできるBright Dataのデータ収集ソリューションをご覧ください。





