

このガイドで学べること
- 百度ウェブスクレイピングを始めるために必要なすべての知識。
- Baiduスクレイピングのための最も一般的で効果的なアプローチ。
- PythonでゼロからカスタムBaiduスクレイパーを構築する方法。
- Bright Data SERP APIを使って検索エンジンの結果を取得する方法。
- Web MCPを介してAIエージェントに百度の検索データにアクセスさせる方法。
さっそく見ていきましょう!
Baidu SERPに慣れる
何か行動を起こす前に、Baidu SERP(検索エンジンの結果ページ)がどのような構造になっているのか、どのようなデータが含まれているのか、どのようにアクセスするのかなどを理解するのに時間をかけましょう。
百度SERPのURLとボット検知システム
ブラウザで百度を開き、いくつかの検索を開始する。例えば、「明るいデータ」と検索する。このようなURLが表示されるはずだ:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358これらのクエリーパラメーターのうち、重要なものは以下の通りである:
- ベースURL
: https://www.baidu.com/s. - 検索クエリーパラメーター:
wd.
言い換えれば、より短いURLでも同じ結果を得ることができる:
https://www.baidu.com/s?wd=bright%20dataまた、百度はpnクエリパラメータによってページネーション用のURLを構造化している。詳細には、2ページ目に&pn=10が追加され、それ以降の各ページではその値が10ずつ増加する。例えば、「明るいデータ」というキーワードで3ページをスクレイピングしたい場合、SERPのURLは次のようになる:
https://www.baidu.com/s?wd=bright%20data -> 1ページ目
https://www.baidu.com/s?wd=bright%20data&pn=10 -> 2ページ目
https://www.baidu.com/s?wd=bright%20data&pn=20 -> 3ページ目さて、PostmanのようなHTTPクライアントで単純なGET HTTPリクエストを使ってこのようなURLに直接アクセスしようとすると、おそらく次のようなものが表示される:
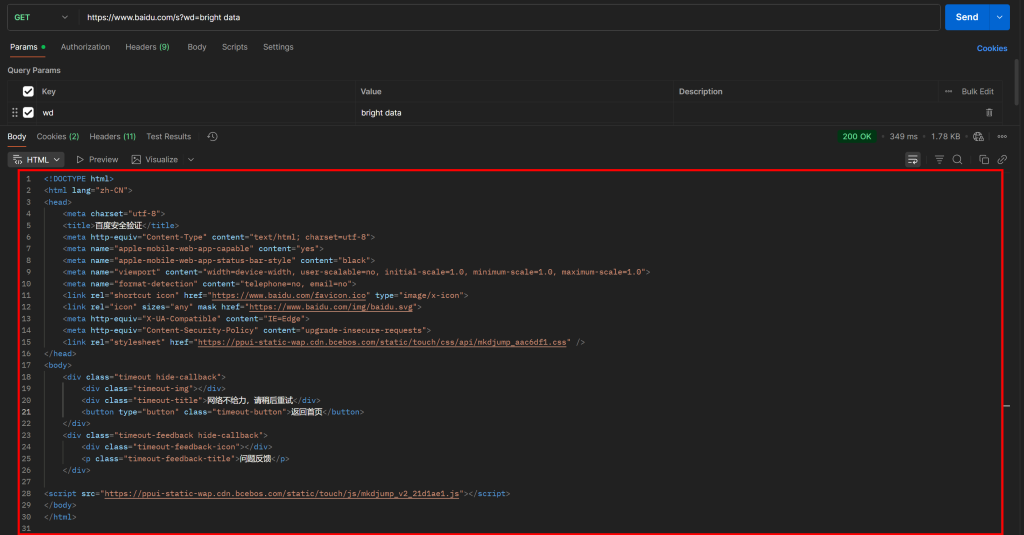
お分かりのように、Baiduは “网络不给力,请稍后重试”(訳すと “ネットワークがうまく機能していないので、後で再試行してください “だが、実際はボット対策ページ)というメッセージのページを返す。
これは、通常ウェブスクレイピング作業に不可欠なUser-Agentヘッダを含んでいても発生する。言い換えれば、Baiduはあなたのリクエストが自動化されたものであることを検知し、それをブロックし、さらに人間による検証を要求しているのだ。
これは、Baiduをスクレイピングするには、(PlaywrightやPuppeteerのような)ブラウザ自動化ツールが必要であることを明確に示している。HTTPクライアントとHTMLパーサーの単純な組み合わせでは、アンチボット・ブロックのトリガーとなってしまうため、十分ではない。
百度SERPで利用可能なデータ
では、ブラウザで表示される「明るいデータ」のBaidu SERPに注目してみよう。このようなものが表示されるはずです:
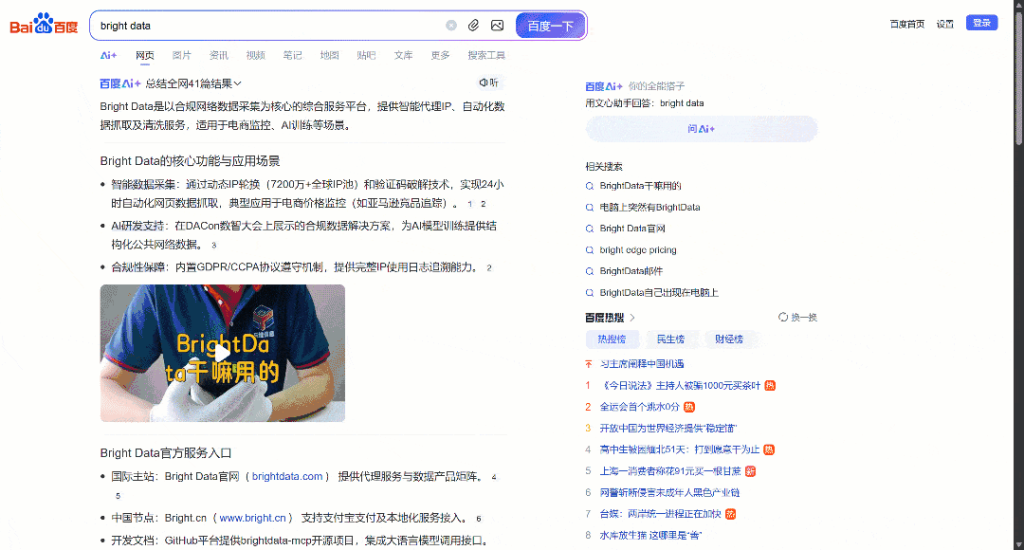
各Baidu SERPページは2つの列に分かれている。左の列にはAIの概要(AIの概要をスクレイピングする方法を参照)があり、検索結果が続く。この列の一番下には「相关搜索」(「関連検索」)セクションがあり、その下にはページネーションのナビゲーション要素がある。
右側の列には「百度热搜索」(「百度ホット検索」)があり、百度でトレンドになっている、あるいは最も人気のあるトピックが表示される。(注:これらのトレンドの結果は、必ずしもあなたの検索語に関連しているわけではありません)。
これで、Baidu SERPからスクレイピングできる主なデータはすべて網羅された。このチュートリアルでは、一般的に最も重要な情報である検索結果のみに焦点を当てます!
百度をスクレイピングする主な方法
百度の検索結果データを取得する方法はいくつかある。以下の表で主なものを比較してみましょう:
| アプローチ | 統合の複雑さ | 必要条件 | 価格設定 | ブロックのリスク | スケーラビリティ |
|---|---|---|---|---|---|
| カスタムスクレイパー構築 | 中/高 | Pythonプログラミングスキル+ブラウザ自動化スキル | 無料(ブロックを避けるためにボット対策ブラウザが必要な場合がある) | 可能 | 限定的 |
| Bright DataのSERP APIを使用する。 | 低い | 任意のHTTPクライアント | 有料 | なし | 無制限 |
| WebMCPサーバーの統合 | 低い | MCPをサポートするAIエージェントフレームワークまたはプラットフォーム | 無料ティアあり、その後有料 | なし | 無制限 |
チュートリアルを進めながら、各アプローチの実装方法を学んでいく!
注1:どの方法を選択しても、このガイドで使用される検索クエリは “明るいデータ “です。つまり、そのクエリに特化したBaiduの検索結果を取得する方法を見ることになる。
注2: ここでは、あなたがすでにPythonをローカルにインストールしており、Pythonウェブスクリプティングに精通していることを前提とします。
アプローチ #1: カスタムスクレイパーを作る
ブラウザオートメーションフレームワークまたはHTTPクライアントとHTMLパーサーを組み合わせて、ゼロから百度スクレイパーを構築する。
👍長所:
- データ解析ロジックを完全に制御でき、必要なものを正確に抽出できる。
- ニーズに合わせて柔軟にカスタマイズ可能。
👎短所:
- セットアップ、コーディング、メンテナンスの労力が必要。
- IP ブロック、CAPTCHA、レート制限、その他のウェブスクレイピングの課題に直面する可能性がある。
アプローチ #2: Bright Data の SERP API を使用する。
Bright Data SERP APIは、簡単に呼び出せるHTTPエンドポイントを介してBaidu(およびその他の検索エンジン)にクエリできるプレミアムソリューションです。ボット対策やスケーリングもすべて行います。これらと他の多くの機能は、市場で最高のSERPと検索APIの一つです。
👍長所
- 150M以上のIPのプロキシ・ネットワークに支えられた高いスケーラビリティと信頼性。
- IPバンやCAPTCHAの問題なし。
- あらゆるHTTPクライアント(PostmanやInsomniaのようなビジュアルツールを含む)で動作。
👎短所:
- 有料サービス。
アプローチ#3: Web MCPサーバーの統合
Bright DataのSERP APIとWeb Unlockerに接続するBright DataのWeb MCPを通して、AIエージェントがBaiduの検索結果に無料でアクセスできるようにします。
👍長所
- AIワークフローとエージェントの統合。
- 無料ティアが利用可能。
- データパースロジックは不要(AIが処理)。
短所:
- LLMの振る舞いの制御が限定的。
アプローチ#1: Playwrightを使ってPythonでカスタムBaiduスクレイパーを構築する。
以下のステップに従い、PythonでカスタムBaiduウェブスクレイピングスクリプトを構築する。
前述したように、単純なHTTPリクエストはブロックされるため、Baiduのスクレイピングにはブラウザの自動化が必要だ。このチュートリアルでは、Pythonでのブラウザ自動化に最適なライブラリの1つであるPlaywrightを使用します。
ステップ #1: スクレイピング・プロジェクトのセットアップ
まずターミナルを開き、Baiduスクレイパー・プロジェクト用の新しいフォルダを作成します:
mkdir baidu-scraperbaidu-scraper/フォルダには、スクレイピングプロジェクトのすべてのファイルが含まれます。
次に、プロジェクトディレクトリに移動し、その中にPython仮想環境を作成します:
cd baidu-scraper
python -m venv .venv次に、お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio Codeか、PyCharm Community Editionを推奨します。
scraper.pyという名前の新しいファイルをプロジェクトディレクトリのルートに追加します。プロジェクトの構造は以下のようになります:
baidu-scraper/
├─ .venv/
└── scraper.py次に、ターミナルで仮想環境を起動します。LinuxやmacOSでは、以下のように実行する:
source .venv/bin/activate を実行する。Windowsの場合は、次のように実行します:
.venv/Scripts/activate仮想環境をアクティブにしたら、playwrightパッケージ経由でpipを使用してPlaywrightをインストールします:
pip install playwright次に、必要なPlaywrightの依存関係(ブラウザバイナリなど)をインストールします:
python -m playwright install完了です!これでPython環境はBaiduウェブスクレイパーを構築する準備が整いました。
ステップ2: Playwrightスクリプトの初期化
scraper.pyで、Playwrightをインポートし、同期APIを使ってChromiumブラウザを起動します:
from playwright.sync_api import sync_playwright
with sync_playwright() as p. # Chromiumインスタンスを初期化する:
# ヘッドレスモードでChromiumインスタンスを初期化する。
browser = p.chromium.launch(headless=True) # デバッグ用のブラウザを表示するには、headless=Falseを設定する。
page = browser.new_page()
# スクレイピングロジック...
# ブラウザを閉じてリソースを解放する
ブラウザを閉じる上記のスニペットは、Baiduスクレイパーの基礎を形成する。
headless=TrueパラメータはPlaywrightにChromiumをGUIなしで起動するように指示する。テストによると、この設定はBaiduのボット検出をトリガーしない。そのため、スクレイピングには有効です。しかし、コードの開発中やデバッグ中は、headless=Falseに設定した方が、ブラウザで何が起こっているかをリアルタイムで見ることができます。
素晴らしい!今すぐBaidu SERPに接続し、検索結果の取得を開始しましょう。
ステップ #3: ターゲットのSERPにアクセスする
先に分析したように、Baidu SERP URLの構築は簡単です。Playwrightにユーザーインタラクション(検索ボックスに入力して送信するなど)をシミュレートするように指示する代わりに、プログラムでSERP URLを構築し、Playwrightに直接ナビゲートするように指示する方がはるかに簡単です。
以下は、”bright data “という検索語に対してBaiduのSERP URLを構築するロジックである:
# Baidu検索ページのベースURL
base_url = "https://www.baidu.com/s"
# 検索キーワード/キーワード
search_query = "明るいデータ"
params = {"wd": search_query} # 検索キーワード/キーフレーズ
# BaiduのSERPのURLをビルドする
url = f"{base_url}?{urlencode(params)}"Python標準ライブラリからurlencode()関数をインポートすることを忘れないでください:
from urllib.parse import urlencodeさて、生成されたURLにアクセスするように、Playwrightが制御するブラウザにgoto()で指示します:
page.goto(url)デバッガでheadfulモード(headless=False)でスクリプトを実行すると、ChromiumウィンドウがBaiduのSERPページを読み込むのが見えます:
すごい!すごい!これこそ、あなたが次にスクレイピングするSERPだ。
ステップ #4: すべてのSERP結果をスクレイピングする準備
スクレイピングのロジックに入る前に、Baidu SERPの構造を勉強する必要がある。まず、ページには複数の検索結果要素が含まれているため、抽出したデータを保存するためのリストが必要になる。そのため、空のリストを初期化することから始めます:
serp_results = [].次に、ターゲットのBaidu SERPをブラウザのシークレット・ウィンドウ(クリーンなセッションを確保するため)で開く:
https://www.baidu.com/s?wd=bright%20data検索結果要素の1つを右クリックし、「Inspect」を選択してブラウザのDevToolsを開きます:
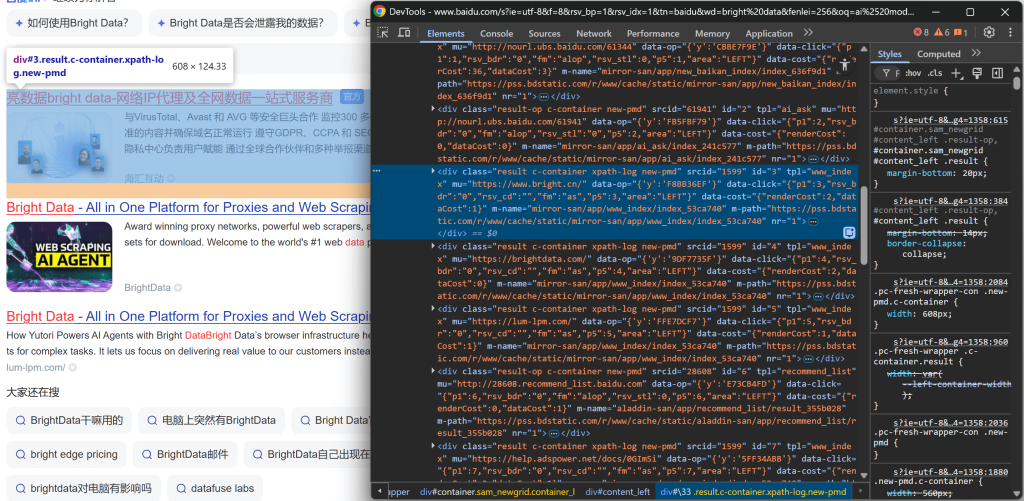
DOM構造を見ると、各検索結果アイテムがresultというクラスを持っていることがわかります。これは、.resultCSS セレクタを使用して、ページ上のすべての検索結果を選択できることを意味します。
このセレクタをPlaywrightスクリプトに適用します:
search_result_elements = page.locator(".result")注:この構文に慣れていない場合は、Playwrightウェブスクレイピングのガイドをお読みください。
最後に、選択した各要素を繰り返し処理する:
for search_result_element in search_result_elements.all():
# データパースロジック...データパースロジックを適用してBaiduの検索結果を抽出し、serp_resultsリストに入力する準備をします:
完璧です!これでBaiduスクレイピングのワークフローは完了です。
ステップ #5: 検索結果データのスクレイピング
百度の検索結果ページのSERP要素のHTML構造を調べます。今回は、抽出したいデータを特定するために、ネストされた要素に注目してください。
まず、タイトルセクションを調べることから始める:
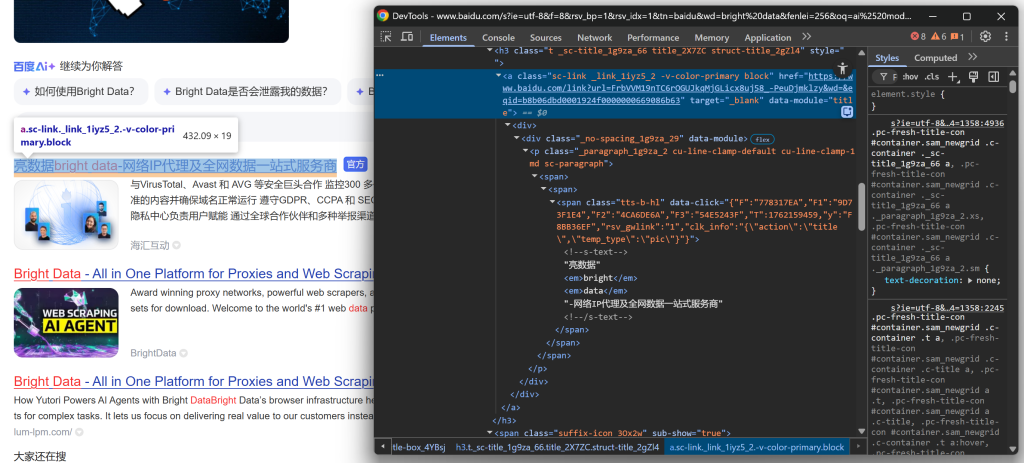
続けて、一部の検索結果には「官方」(「公式」)ラベルが表示されていることに気づく:
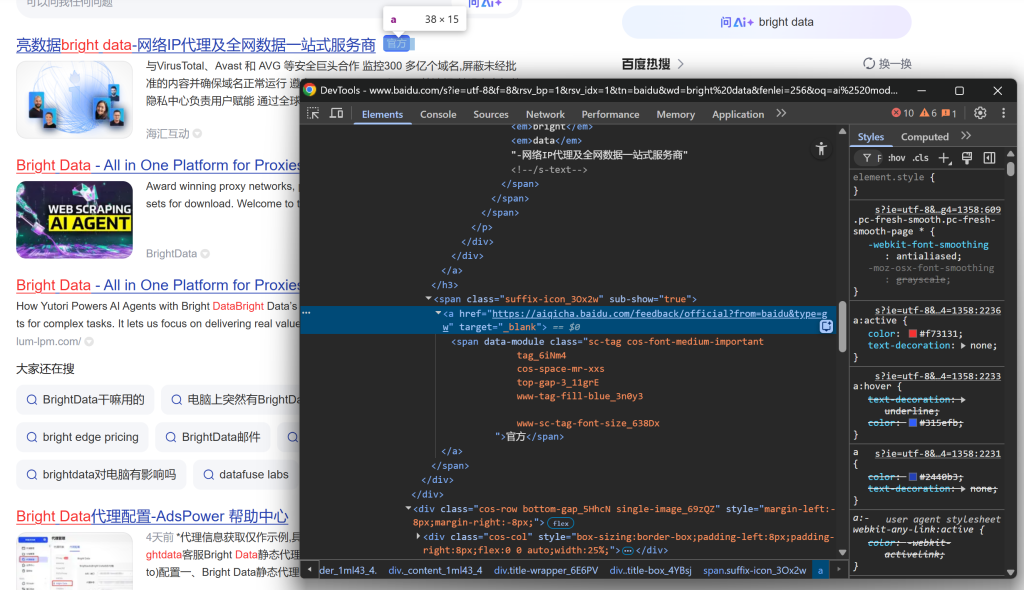
そして、SERPの結果画像に注目する:
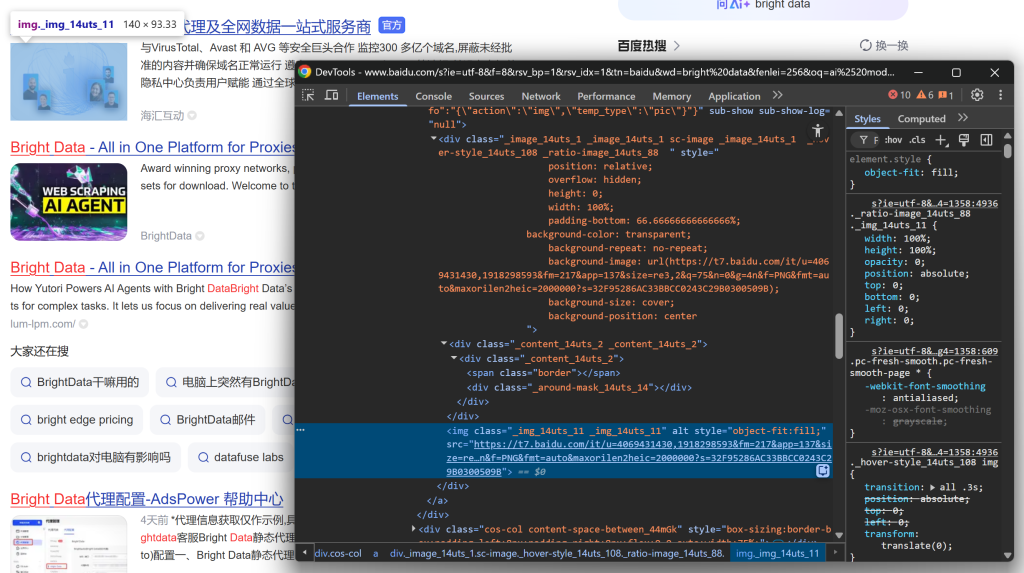
そして最後に、説明文/抄録を見る:
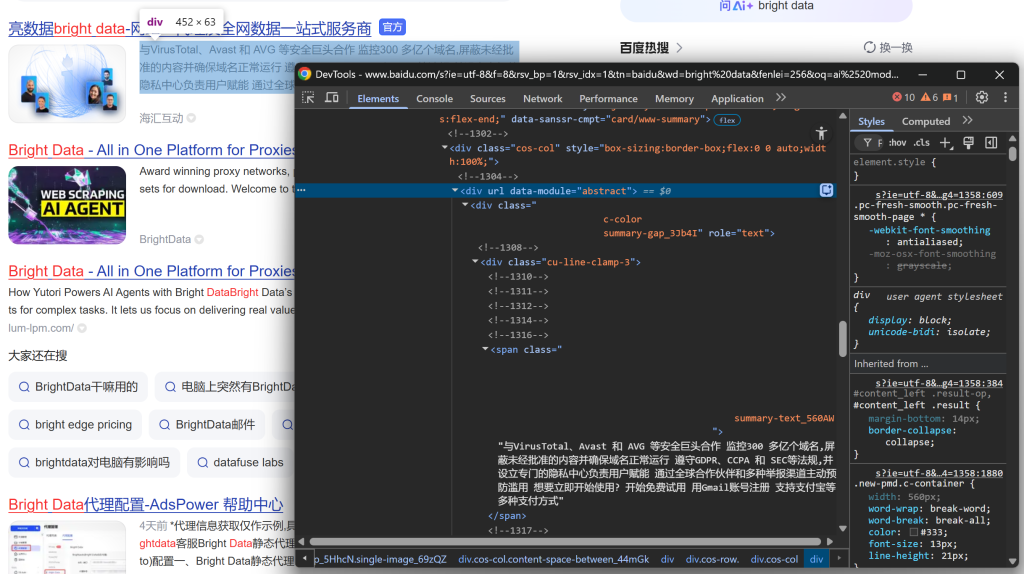
これらの入れ子要素から、以下のデータを抽出することができる:
.sc-link要素のhref属性から結果のURL。.sc-link要素のテキストから結果のタイトル。data-module='abstract']テキストから結果の説明/抄録。.sc-image内のimgのsrc属性から結果画像。.result__snippetテキストからの結果スニペット。https://aiqicha.baidu.com/feedback/officialで始まる<a>要素内の公式ラベル(存在する場合)。
PlaywrightのロケータAPIを使用して要素を選択し、必要なデータを抽出する:
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else なし
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0すべてのSERP項目が同じではないことに留意してください。エラーを防ぐには、属性やテキストにアクセスする前に、必ず要素が存在すること(.count() > 0)を確認してください。
すごい!BaiduのSERPデータパースロジックを定義するだけです。
ステップ #6: スクレイピングされた検索結果データの収集
検索結果ごとに辞書を作成し、serp_resultsリストに追加して、forループを終了します:
serp_result = {
"title": title.strip()、
"href": link.strip()、
"description": description.strip()、
"image": image.strip() if image else ""、
「公式": 公式
}
serp_results.append(serp_result)すばらしい!これでBaiduウェブスクレイピングのロジックは完成です。最後のステップは、スクレイピングしたデータをエクスポートすることです。
ステップ #7: スクレイピングした検索結果をCSVにエクスポートする
この段階では、Baiduの検索結果はPythonのリストに保存されています。データを他のチームやツールで使えるようにするには、Pythonの組み込みcsvライブラリを使ってCSVファイルにエクスポートします:
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# 最初の項目からフィールド名を動的に読み込む
fieldnames = list(serp_results[0].keys())
# CSV ライターを初期化する
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# ヘッダーを書き、出力CSVファイルに入力する
writer.writeheader()
writer.writerows(serp_results)csvのインポートを忘れずに:
インポートcsvこのようにして、あなたのBaiduスクレイパーは、すべてのスクレイピング結果をCSV形式で含むbaidu_serp_results.csvという名前の出力ファイルを生成します。ミッション達成
ステップ #8: すべてをまとめる
scraper.pyに含まれる最終的なコードは次の通りです:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
インポート csv
# スクレイピングされたデータの保存場所
serp_results = [] # スクレイピングされたデータを保存する場所
with sync_playwright() as p:
# ヘッドレスモードでChromiumインスタンスを初期化する。
browser = p.chromium.launch(headless=True) # デバッグ用のブラウザを表示するには、headless=Falseを設定する
page = browser.new_page()
# 百度検索ページのベースURL
base_url = "https://www.baidu.com/s"
# 検索キーワード
search_query = "明るいデータ"
params = {"wd": search_query} # 検索キーワード/キーフレーズ
# BaiduのSERPのURLをビルドする
url = f"{base_url}?{urlencode(params)}"
# ブラウザでターゲットページにアクセス
page.goto(url)
# 全ての検索結果要素を選択する
search_result_elements = page.locator(".result")
for search_result_element in search_result_elements.all():
# データパースロジック
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else なし
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# スクレイピングされたデータで新しい検索結果オブジェクトを生成する
serp_result = { { "title": title.strip()
"title": title.strip()、
"href": link.strip()、
"description": description.strip()、
"image": image.strip() if image else ""、
「公式": 公式
}
# スクレイピングされたBaidu SERPの結果をリストに追加する
serp_results.append(serp_result)
# ブラウザを閉じ、リソースを解放する
ブラウザを閉じる
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# 最初の項目からフィールド名を動的に読み込む
fieldnames = list(serp_results[0].keys())
# CSV ライターを初期化する
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# ヘッダーを書き、出力CSVファイルに入力する
writer.writeheader()
writer.writerows(serp_results)すごい!わずか70行ほどのコードで、Baiduのデータスクレイピングスクリプトが完成しました。
スクリプトをテストしてみましょう:
python scraper.py出力はプロジェクトフォルダにあるbaidu_serp_results.csvファイルになります。このファイルを開くと、Baiduの検索結果から抽出された構造化データを見ることができます:

Note: さらに検索結果をスクレイピングするには、ページ分割を処理するためにpnクエリパラメータを使用して処理を繰り返します。
出来上がり!構造化されていないBaiduの検索結果を構造化されたCSVファイルに変換することに成功しました。
[おまけ】リモートブラウザサービスを使ってブロックを回避する
上に示したスクレイパーは、小規模な実行には問題なく機能するが、うまくスケールしない。Baiduは、同じIPからのトラフィックが多すぎるとリクエストをブロックし始め、エラーページやチャレンジを返す。また、多くのローカルChromiumインスタンスを実行することは、リソースを大量に消費し(多くのRAM)、調整が難しい。
よりスケーラブルで管理しやすいソリューションは、PlaywrightインスタンスをBright DataのブラウザAPIのようなリモートブラウザ・アズ・ア・サービススクレイピングソリューションに接続することである。これにより、自動的なプロキシローテーション、CAPTCHA処理とアンチボットバイパス、フィンガープリント問題を避けるための実際のブラウザインスタンス、無制限のスケーリングが提供されます。
Bright Data Browser API セットアップガイドに従うと、WSS 接続文字列は次のようになります:
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222のようになります。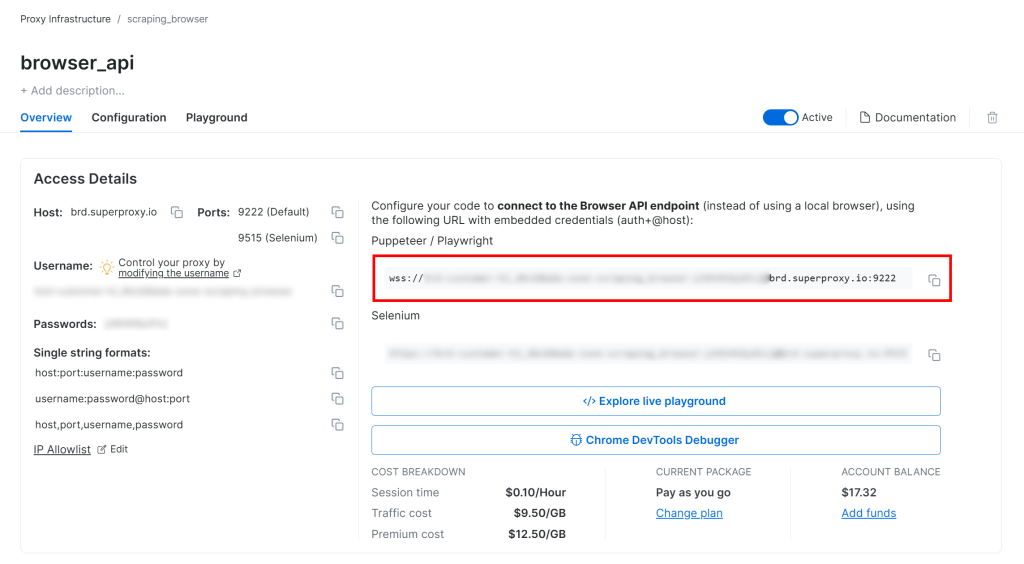
このWSS URLを使用して、CDP(Chrome DevTools Protocol)を介してリモートブラウザインスタンスにPlaywrightを接続します:
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
ブラウザ = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...これで、BaiduへのPlaywrightリクエストは、1億5千万IPのレジデンシャルプロキシネットワークと実際のブラウザインスタンスに支えられたBright DataのブラウザAPIリモートインフラを通してルーティングされる。これにより、各セッションの新鮮なIPと現実的なブラウザフィンガープリントが保証されます。
アプローチ #2: Bright Data の SERP API の使用
この章では、Bright DataのオールインワンBaidu SERP APIを使用して検索結果をプログラムで取得する方法を説明します。
注意: ここでは説明の簡略化のため、すでにPythonプロジェクトにrequestsライブラリがインストールされているものとします。
ステップ #1: Bright DataアカウントにSERP APIゾーンを設定する
Baiduの検索結果をスクレイピングするために、Bright DataのSERP APIプロダクトをセットアップすることから始めます。まず、Bright Dataアカウントを作成するか、既にアカウントをお持ちの場合はログインします。
より早く設定するには、Bright Dataの公式SERP API “クイックスタート “ガイドを参照してください。そうでなければ、以下のステップを続けてください。
ログイン後、Bright Dataアカウントの「プロキシ&スクレイピング」に移動し、製品ページに移動します:
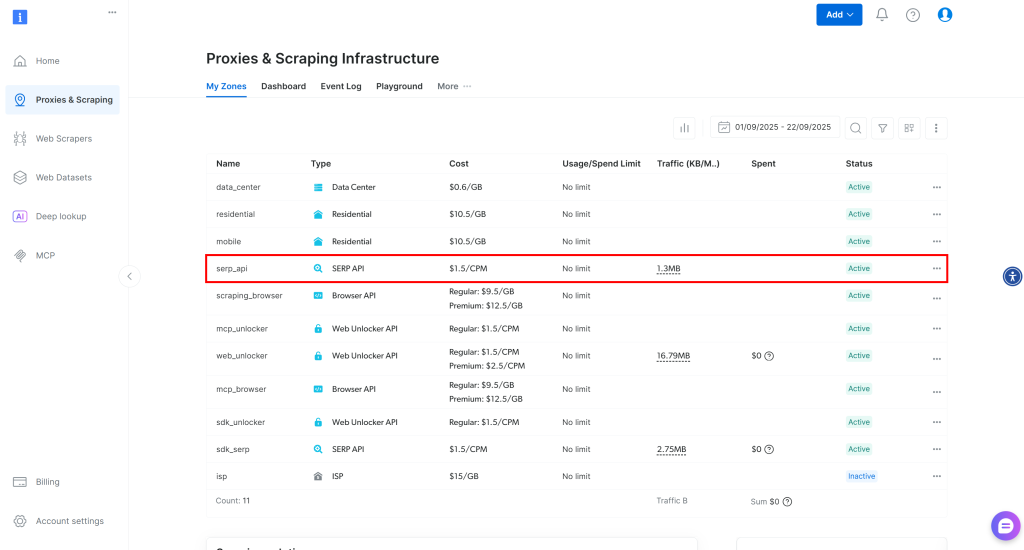
My Zones” テーブルをご覧ください。ここには、設定済みの Bright Data 製品がリストされています。アクティブな SERP API ゾーンが既に存在する場合は、準備は完了です。ゾーン名(例:serp_api)をコピーしてください。
SERP APIゾーンが存在しない場合は、”Scraping Solutions “セクションまでスクロールダウンし、”SERP API “カードの “Create Zone “をクリックします:
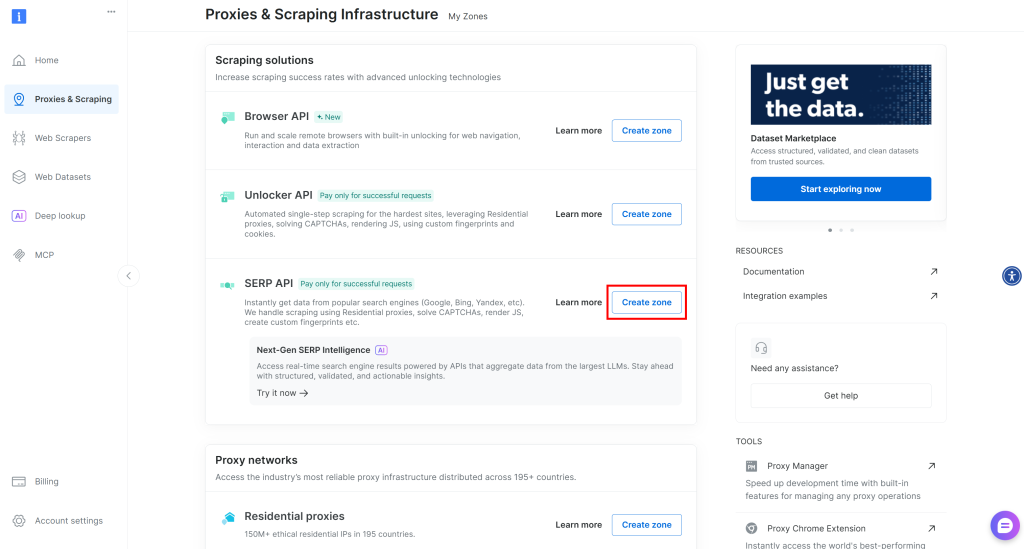
ゾーンに名前(例えばserp-api)を付け、”Add “ボタンをクリックする:
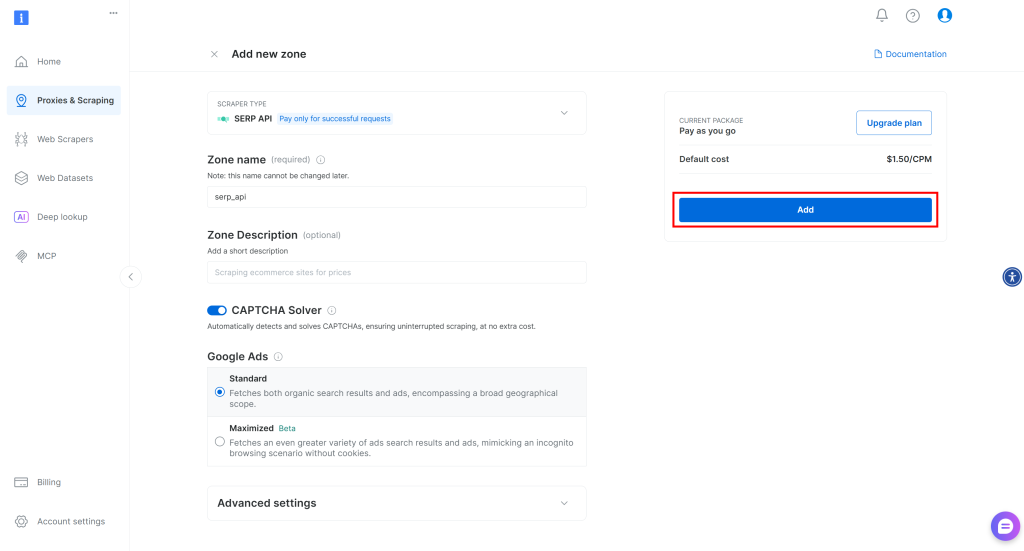
次に、ゾーンの製品ページに行き、スイッチを “Active “に切り替えて、ゾーンが有効になっていることを確認する:
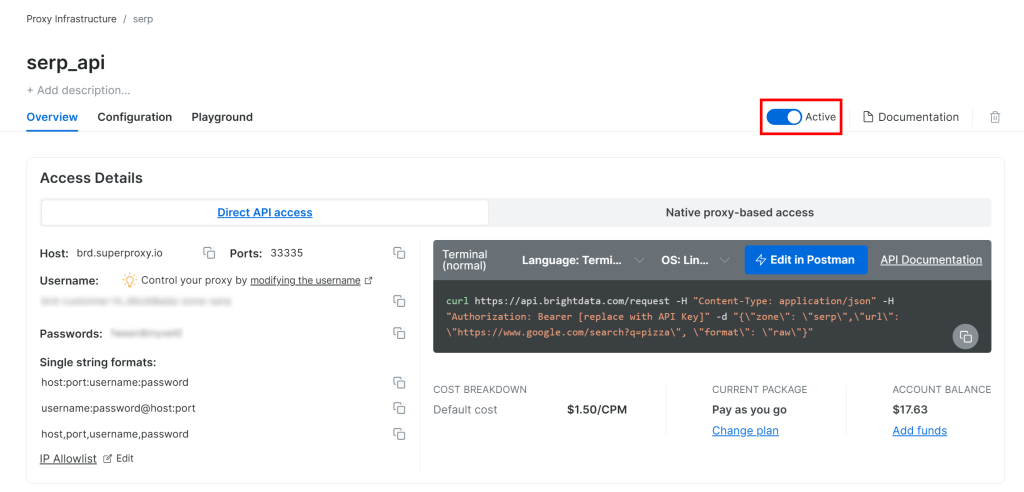
完了です!これでBright Data SERP APIゾーンの設定が完了し、使用できるようになりました。
ステップ #2: Bright Data APIキーの取得
SERP APIへのリクエストを認証するには、Bright Data APIキーを使用することをお勧めします。まだ作成していない場合は、Bright Dataの公式ガイドに従ってAPIキーを作成してください。
SERP API に POST リクエストを行う場合、API キーをAuthorizationヘッダーに以下のように記述してください:
"Authorization:ベアラ <YOUR_BRIGHT_DATA_API_KEY>"すごい!これでBright DataのSERP APIをPythonスクリプトから呼び出すために必要なものがすべて揃いました。
では、すべてをまとめてみましょう!
ステップ3: SERP API の呼び出し
PythonでBright Data SERP APIを利用して、キーワード “bright data “のBaidu検索結果を取得します:
# pip install requests
import requests
from urllib.parse import urlencode
# Bright Dataの認証情報 (TODO: あなたの値に置き換える)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"# (例:"serp_api")
# 百度検索ページのベースURL
ベースURL = "https://www.baidu.com/s"
# 検索キーワード/キーワード
search_query = "明るいデータ"
params = {"wd": search_query} # 検索キーワード/キーフレーズ
# BaiduのSERP URLを構築する
url = f"{base_url}?{urlencode(params)}"
# Bright DataのSERP APIにPOSTリクエストを送信する
response = requests.post(
"https://api.brightdata.com/request"、
headers={
"Authorization": f "Bearer {bright_data_api_key}"、
"Content-Type":"application/json"
},
json={
"zone": bright_data_serp_api_zone_name、
"url": url、
"format":"raw"
}
)
# 完全にレンダリングされたHTMLを取得する
html = response.text
# パースロジックはここにある...別の例として、GitHub の“Bright Data SERP API Python Project”を見てみましょう。
Bright Data SERP APIはJavaScriptのレンダリングを処理し、自動IPローテーションのためのプロキシネットワークと統合し、ブラウザフィンガープリントやCAPTCHAなどのスクレイピング対策を管理する。このため、リクエストのような基本的なHTTPクライアントで百度をスクレイピングする際に通常表示される「网络不给力,请稍后重试」(ネットワークがうまく機能していません。
もっと簡単に言うと、html変数には完全にレンダリングされた百度の検索結果ページが含まれている。そのHTMLを
print(html)下のような出力が得られる:
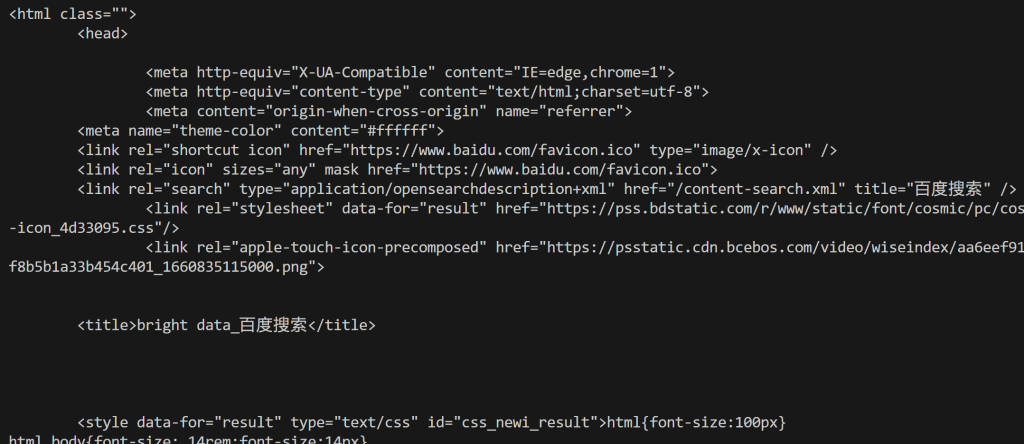
ここから、最初の方法で示したようにHTMLを解析して、必要な百度の検索データを抽出することができます。お約束したように、Bright Data SERP APIはブロックを防ぎ、無制限のスケーラビリティを実現します!
アプローチ #3: Web MCPサーバーを統合する
SERP API(および他の多くのBright Data製品)は、Bright Data Web MCPの search_engineツールからもアクセスできることを覚えておいてください。
このオープンソースのウェブMCPサーバーは、Baiduスクレイピングを含むBright Dataのウェブデータ検索ソリューションにAIのためのアクセスを提供します。特に、search_engineと scrape_as_markdownツールは、Web MCPのフリーティアで利用可能で、AIエージェントやワークフローで無料で使用できます。
Web MCPをAIソリューションに統合するには、Node.jsをローカルにインストールし、次のような設定ファイルが必要です:
{
"mcpServers":{
"Bright Data Web MCP":{
"command":"npx"、
"args": ["-y", "@brightdata/mcp"]、
"env":{
"API_TOKEN":"<your_bright_data_api_key>"
}
}
}
}例えば、この設定はClaude DesktopやCode(その他多くのAIライブラリやソリューション)で動作します。その他のインテグレーションについてはドキュメントをご覧ください。
また、Bright Data リモートサーバー経由で接続することもできます。
この統合により、AIを搭載したワークフローやエージェントは、Baidu(または他のサポートされている検索エンジン)からSERPデータを自律的に取得し、オンザフライで処理できるようになります。
まとめ
このチュートリアルでは、Baiduをスクレイピングするために推奨される3つの方法を探りました:
- カスタムスクレイパーを使用する。
- Baidu SERP APIを活用する。
- Bright Data Web MCPを利用する。
実証されたように、Baiduをブロックを回避しながら大規模にスクレイピングする最も信頼できる方法は、構造化されたスクレイピングソリューションを使用することです。これは、高度なアンチボットバイパス技術とBright Data製品のような堅牢なプロキシネットワークによって支えられている必要があります。
Bright Dataの無料アカウントを作成して、今すぐスクレイピングソリューションをお試しください!




