

この記事では以下の内容をご紹介します:
- AutoGenとは何か、その独自性について。
- MCPを介したWebデータ取得・インタラクション機能でエージェントを拡張すべき理由
- – Bright DataのWeb MCPと連携するAutoGen AgentChatエージェントの構築方法
- – 同じエージェントをビジュアルWebアプリケーションAutoGen Studioでテストする方法
それでは始めましょう!
AutoGenとは?
AutoGenは、Microsoftが開発したマルチエージェントAIシステム構築のためのオープンソースフレームワークです。複数のAIエージェントが自律的に、あるいは人間の指導のもとで、複雑なタスクを完了するために相互に連携・通信することを可能にします。
このライブラリはGitHub で 50,000 以上のスターを獲得するなど、大きな人気を博しており、Python と C# (.NET) の両方で利用できます。
主な機能
AutoGenが提供する中核機能は以下の通りです:
- カスタマイズ可能な対話型エージェント:AIエージェントをLLM(大規模言語モデル)、人間の入力、各種ツールと統合します。高水準APIやJSONを使用して、カスタム動作や会話パターンを定義できます。
- ヒューマン・イン・ザ・ループワークフロー:ワークフローの複数ポイントで人間のフィードバックを組み込むことをサポート。例えば
UserProxyAgentは人間のプロキシとして機能し、監視や介入を可能にします。 - ツール統合:エージェントには、Web検索、コード実行、ファイル操作などの機能を装備できます。MCP統合のサポートも含まれます。
- 組み込みエージェントタイプ: AutoGenは以下を含む複数の事前構築済みエージェントタイプを提供します:
UserProxyAgent: 人間ユーザーを代理し、コードを実行可能。AssistantAgent: タスクの実行やツールの使用が可能な汎用LLMベースのアシスタント。CodeExecutorAgent: コードの実行とテストに特化しています。
- 可観測性とデバッグ: エージェントの相互作用やワークフローのトレースとデバッグのための組み込みツールを備え、OpenTelemetryなどの標準をサポートしています。
- AutoGen Studio: マルチエージェントシステムの迅速なプロトタイピング、テスト、デプロイを可能にするグラフィカルでローコードなWebインターフェース。
Bright DataのWeb MCPでAutoGenエージェントを拡張する理由
AutoGenは複数のAIモデルプロバイダーをサポートしています。しかし、OpenAI、Anthropic、Ollama、その他のプロバイダーを問わず、どのLLMを選択しても、すべてのモデルには同じ根本的な制限があります。その知識は静的であるということです。
LLMは特定の時点のスナップショットデータを学習しているため、知識が急速に陳腐化する可能性があります。さらに重要なのは、LLMがネイティブにライブウェブサイトと対話したり、独自にデータソースにアクセスしたりできない点です。
幸い、AutoGenはMCPをサポートしています。つまり、エージェントをBright DataのWeb MCPと組み合わせることが可能です。これによりLLMが拡張され、ウェブから直接新鮮で高品質なデータを取得するツールやその他の機能が追加されます。
具体的には、Web MCPは60以上のAI対応ツールを提供するオープンソースサーバーです。これらはすべて、Bright Dataのウェブインタラクションおよびデータ収集インフラによって駆動されています。
無料プランでも、以下の2つの画期的なツールを利用できます:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得します。 |
scrape_as_markdown |
ボット検出やCAPTCHAを回避し、任意のウェブページをクリーンなMarkdown形式にスクレイピングします。 |
さらに、Web MCPはAmazon、LinkedIn、TikTok、Google Play、App Store、Yahoo Financeなど主要プラットフォーム向けの構造化データ収集用専門ツールを多数提供します。詳細は公式GitHubページでご確認ください。
つまり、AutoGenでWeb MCPを設定することで、ライブウェブサイトと対話し、最新のウェブデータにアクセスして現実世界に根ざしたインサイトを生成できる複雑なAIエージェントを構築できます。
AutoGen AgentChatでPythonを使用したWeb MCPツールによるAIエージェント構築方法
このガイドセクションでは、マルチエージェントアプリケーション作成用の高レベルAPIであるAutoGen AgentChatを使用してエージェントを構築する方法を学びます。具体的には、エージェントがWeb MCPサーバーが公開する全ツールを利用可能となり、基盤となるLLMの機能を拡張します。
注:以下のエージェントはPythonで記述されますが、.NETへ容易に適用可能です。
AutoGenとMCPを統合したPythonエージェントを作成する手順は以下の通りです!
前提条件
このチュートリアルを実行するには、以下の環境が整っていることを確認してください:
- Python 3.10以上がマシンにインストールされていること。
- Node.js がインストールされていること(最新のLTS バージョンを推奨)。
- OpenAI APIキー(またはその他のサポートされているLLMのAPIキー)
また、APIキー付きのBright Dataアカウントも必要ですが、後ほど手順を説明しますのでご安心ください。MCPの基本的な仕組みと Web MCPが公開するツールについての理解があるとさらに役立ちます。
ステップ #1: AutoGenプロジェクトの設定
ターミナルを開き、AutoGen AIプロジェクト用の新規ディレクトリを作成します:
mkdir autogen-mcp-agentautogen-mcp-agent/フォルダには、MCP統合エージェント用のPythonコードが含まれます。
次に、プロジェクトディレクトリに移動し、その内部で仮想環境を初期化します:
cd autogen-mcp-agent
python -m venv .venv仮想環境を有効化します。LinuxまたはmacOSでは以下を実行:
source .venv/bin/activateWindows では同等の操作として以下を実行します:
.venv/Scripts/activateプロジェクトにagent.pyという新しいファイルを追加し、以下のように記述します:
autogen-mcp-agent/
├── .venv/
└── agent.pyagent.pyはメインの Python ファイルとして機能し、AI エージェントのロジックを含みます。
お好みのPython IDE(Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionなど)でプロジェクトフォルダを読み込みます。
仮想環境をアクティブ化した状態で、必要な依存関係をインストールします:
pip install autogen-agentchat "autogen-ext[openai]" "autogen-ext[mcp]" python-dotenvインストールしたライブラリは以下の通りです:
autogen-agentchat: autogen-core 上に構築された使いやすい API を通じて、単一エージェントまたはマルチエージェントアプリケーションを開発するためのライブラリ。"autogen-ext[openai]": OpenAIモデルを活用したエージェント構築のためのAutoGen拡張機能。"autogen-ext[mcp]":AutoGenエージェントをMCPサーバーに接続するための拡張機能。python-dotenv: ローカルの.envファイルから環境変数をロードします。
注: OpenAIモデルを使用しない場合は、ドキュメントの説明に従い、お好みのLLMプロバイダーに対応するパッケージをインストールしてください。
完了!これでAutoGenを用いたAIエージェント開発のためのPython環境が整いました。
ステップ #2: 環境変数読み込みの設定
エージェントはOpenAIやBright Dataなどのサードパーティサービスへの接続に依存します。これらの接続を認証するにはAPIキーの提供が必要です。セキュリティ上の問題を引き起こす可能性のある悪しき慣行であるagent.pyファイルへのハードコーディングではなく、環境変数からシークレットを読み取るようスクリプトを設定してください。
これが、最初にpython-dotenvパッケージをインストールした理由です。agent.pyファイルでライブラリをインポートし、load_dotenv()を呼び出して環境変数をロードします:
from dotenv import load_dotenv
load_dotenv()これでアシスタントはローカルの.envファイルから変数を読み込めるようになります。
したがって、プロジェクトディレクトリのルートに.envファイルを追加します:
autogen-mcp-agent/
├── .venv/
├── .env # <------
└── agent.pyこれでコード内で環境変数にアクセスできます:
import os
os.getenv("ENV_NAME")素晴らしい!スクリプトが環境変数を使用してサードパーティ連携のシークレットを読み込みました。
ステップ #3: Bright Data の Web MCP を開始する
エージェントをBright DataのWeb MCPに接続する前に、まずお使いのマシンでサーバーを実行できることを確認してください。これは、AutoGenにWeb MCPをローカルで起動するよう指示し、エージェントがそれに接続するためです。
Bright Dataアカウントをお持ちでない場合は新規作成してください。既にアカウントをお持ちの場合はログインしてください。迅速なセットアップには、アカウント内の「MCP」セクションを参照してください:
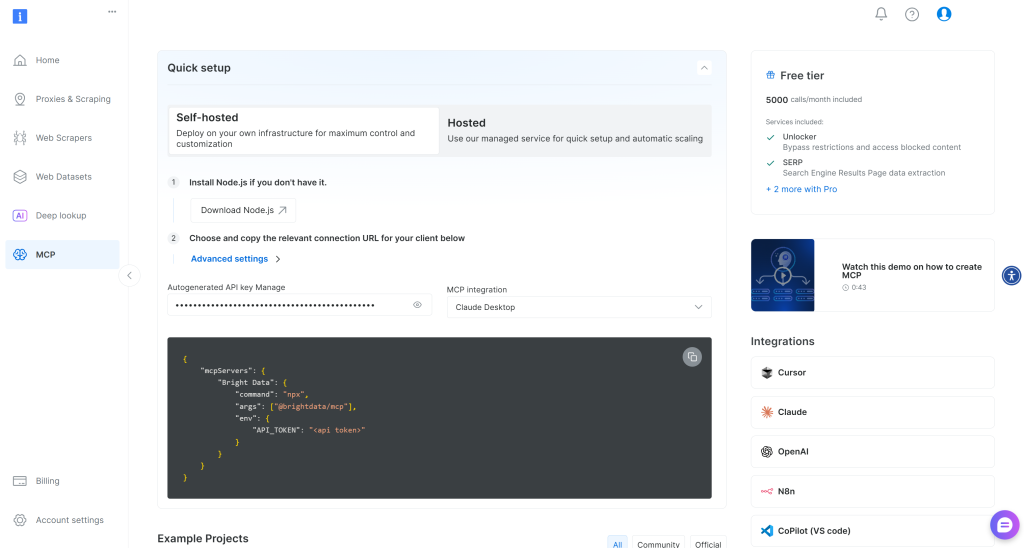
詳細な手順については、以下の指示に従ってください。
まずBright Data APIキーを生成します。すぐに必要となるため、安全な場所に保管してください。ここではWeb MCP統合プロセスを簡略化するため、APIキーに管理者権限が付与されているものと仮定します。
次に、@brightdata/mcpnpmパッケージを使用して、システムにWeb MCPをグローバルにインストールします:
npm install -g @brightdata/mcp次に、ローカルMCPサーバーを起動して動作を確認します:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpLinux/macOSでは同等のコマンドを実行します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを実際の Bright Data API トークンに置き換えてください。どちらのコマンドも必要なAPI_TOKEN環境変数を設定し、Web MCP をローカルで起動します。
正常に実行されると、以下のような出力が表示されます:

初回起動時、Web MCPはBright Dataアカウント内に以下の2つのデフォルトゾーンを自動作成します:
mcp_unlocker:Web Unlocker用ゾーンmcp_browser:ブラウザAPI用のゾーン。
Web MCPは60以上のツールを動作させるために、これら2つのBright Data製品に依存しています。
ゾーンが作成されたことを確認するには、Bright Dataダッシュボードにログインし、「プロキシ&スクレイピングインフラストラクチャ」ページに移動してください。テーブル内に以下の2つのゾーンが確認できるはずです:
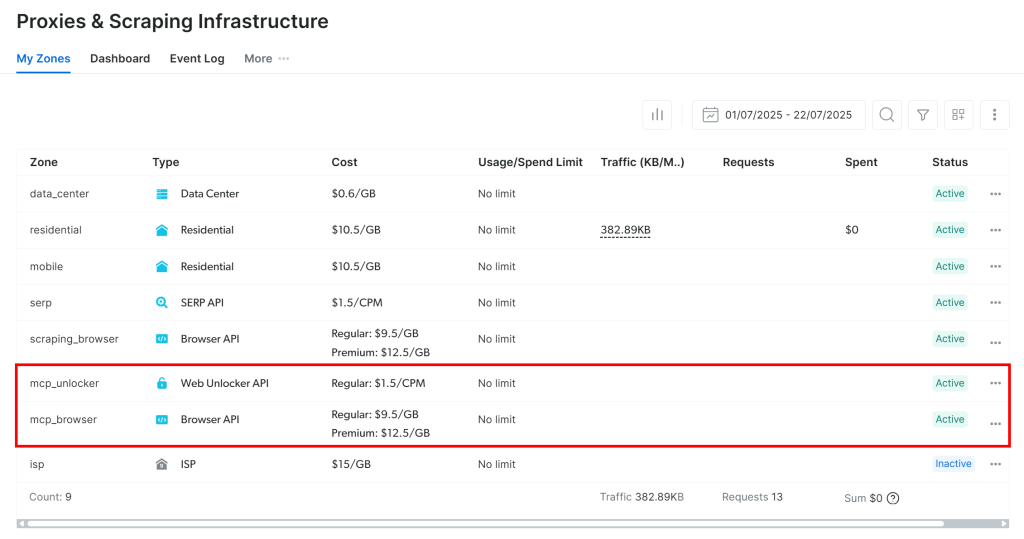
注意: APIトークンに管理者権限がない場合、これらのゾーンは作成されません。この場合、ダッシュボードで手動で定義し、環境変数を通じてコマンド内でゾーン名を設定する必要があります(詳細はGitHubページを参照)。
デフォルトでは、MCPサーバーが公開するのはsearch_engineとscrape_as_markdownツール(およびそれらのバッチ版)のみです。これらのツールはWeb MCPの無料プランに含まれるため、無料で利用できます。
ブラウザ自動化や構造化データフィードなどの高度なツールを利用するには、Proモードを有効にする必要があります。Web MCP起動前に環境変数PRO_MODE="true"を設定してください:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpLinux/macOSの場合:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpプロモードでは60以上のツールがすべて利用可能になりますが、無料プランには含まれず追加料金が発生します。
完了!これでWeb MCPサーバーがご自身のマシン上で動作することを確認しました。次のステップでAutoGen AgentChatエージェントを起動し接続する設定を行うため、MCPプロセスを停止してください。
ステップ #4: Web MCP接続の設定
Web MCPがマシンで実行可能になったので、スクリプトにサーバー接続を指示します。
まず、以前に取得したBright Data APIキーを.envファイルに追加します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"<YOUR_BRIGHT_DATA_API_KEY>を実際のAPIキーに置き換えてください。
agent.py 内で、Bright Data API キーの値を以下のように読み込みます:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")次に、非同期関数を定義し、ローカルWeb MCPプロセスへのMCP接続を設定します:
from autogen_ext.tools.mcp import (
StdioServerParams,
mcp_server_tools
)
async def main():
# Bright Data Web MCP 接続設定
bright_data_mcp_server = StdioServerParams(
command="npx",
args=[
"-y",
"@brightdata/mcp"
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # オプション
}
)
# Bright Data Web MCPサーバーが公開するツールを読み込み
bright_data_tools = await mcp_server_tools(bright_data_mcp_server)
# エージェント定義...この設定は、APIトークンに環境変数を使用する前のステップのnpxコマンドを反映しています。PRO_MODEはオプションですが、API_TOKENは必須であることに注意してください。
基本的に、agent.pyスクリプトはWeb MCPプロセスを起動し、STDIO経由で接続します。その結果、AutoGenエージェントに渡せるツールの配列が得られます。
利用可能なツールを一覧表示して接続を確認します:
for bright_data_tool in bright_data_tools:
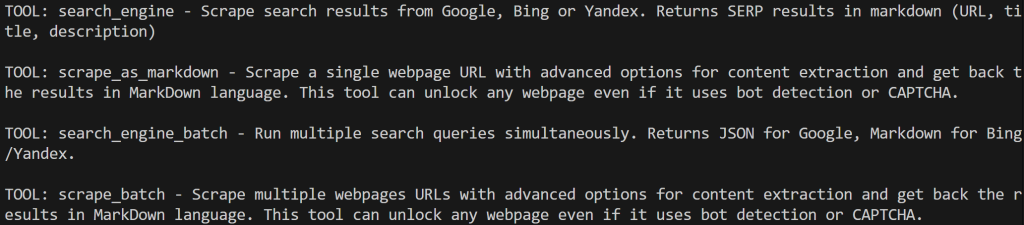
print(f"TOOL: {bright_data_tool.name} - {bright_data_tool.description}n")スクリプトをProモード無効で実行すると、以下のような出力が表示されます:
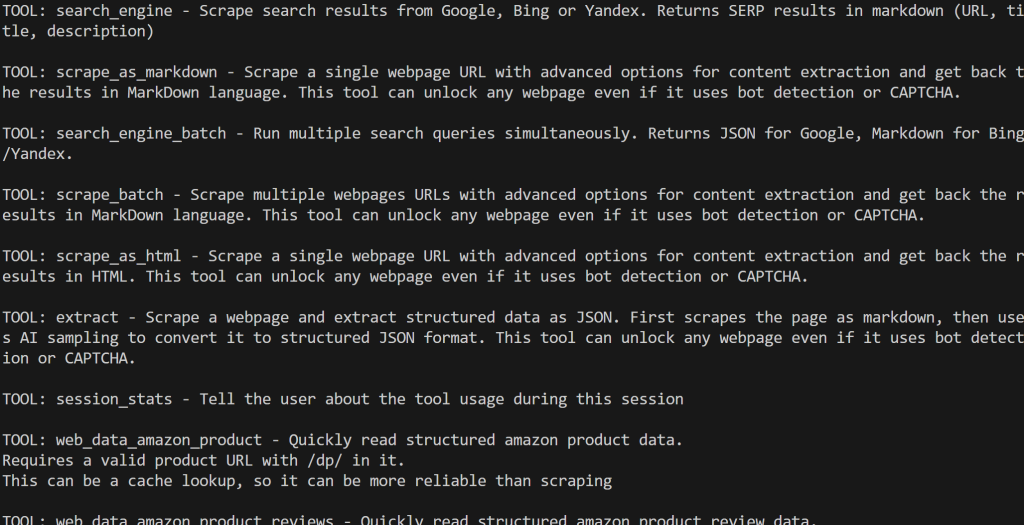
Proモードを有効にした場合は、60以上の全ツールが表示されます:
これで完了です!出力結果から、Web MCP 統合が正常に機能していることが確認できます。
ステップ #5: AutoGenエージェントの定義
AutoGen AgentChatには、それぞれ異なる応答スタイルで設計されたプリセットエージェントが用意されています。このケースでは汎用的なAssistantAgentが最適です。
エージェントを定義する前に、LLM(大規模言語モデル)の統合を設定する必要があります。エージェントは基盤となるAIモデルなしでは機能しないためです。
まず、.envファイルにOpenAI APIキーを追加します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"次に、コード内でOpenAI統合を設定します:
from autogen_ext.models.openai import OpenAIChatCompletionClient
model_client = OpenAIChatCompletionClient(
model="gpt-4o-mini",
)OpenAIChatCompletionClientは OPENAI_API_KEY環境変数を 自動的に読み込むため、コード内で明示的に読み込む必要はありません。この環境変数はOpenAIへのAPI呼び出し認証に使用されます。
上記の例ではエージェントをOpenAIのGPT-4oモデルに接続しています。他のモデルやLLMプロバイダーを使用する場合は、各ドキュメントを確認し適宜調整してください。
注記: 本文執筆時点では、autogen-ext[openai]ではGPT-5モデルは未対応です。
では、先に読み込んだ MCP ツールとモデルを組み合わせてアシスタントエージェントを作成しましょう:
from autogen_agentchat.agents import AssistantAgent
agent = AssistantAgent(
name="web_agent",
model_client=model_client,
tools=bright_data_tools,
)素晴らしい!これでOpenAIを基盤とし、Bright DataのMCPツールと連携した初のAutoGen AgentChatエージェントが完成しました。
ステップ #6: AutoGen チームの作成
エージェントに直接タスクを渡して実行することも可能です。ただし、ツールの実行が1回で終了するため、最適な体験は得られません。max_tool_iterations引数でこの動作を調整することもできますが、通常はチームを定義する方が望ましいです。
AutoGenにおけるチームとは、目標達成に向けて協力するエージェントのグループです。今回のケースではエージェントは1体のみ(有効な設定です)ですが、チームを定義しておくことで、後でエージェントを追加してマルチエージェントワークフローを構築する際の拡張が容易になります。
一般的な設定として、エージェントが順番に発言するラウンドロビン方式のRoundRobinGroupChatチームがあります。また、ループを終了させる終了条件も必要です。ここではTextMentionTerminationを使用し、エージェントの応答に「TERMINATE」という単語が出現した時点でプロセスを終了するように設定します:
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
# ループの終了条件を定義
text_termination = TextMentionTermination("TERMINATE")
# 唯一のエージェントを含むチームを作成
team = RoundRobinGroupChat([agent], termination_condition=text_termination)これはAutoGenのほとんどの例で示される標準的な設定であることに注意してください。
エージェントが1人しかいなくても、タスクが完了するまでチームは繰り返し呼び出しを続けます。これは、完了までに複数のツール呼び出し(つまり複数のインタラクションラウンド)を必要とする複雑なタスクにおいて特に有用です。
よし!あとはチームを実行して結果を取得するだけです。
ステップ #7: タスクの実行
AutoGen AgentChatアプリケーションを実行するには、エージェントが所属するチームにタスクを渡します。拡張されたWebデータ取得機能をテストするには、次のようなプロンプトを実行してみてください:
task = """
App Storeの以下のアプリから情報を取得してください:
"https://apps.apple.com/us/app/brave-browser-search-engine/id1052879175"
ユーザーレビュー、価格、入手可能な全情報に基づき、このアプリはインストールする価値があり信頼できるか判断してください。
"""当然ながら、OpenAIモデルだけではこのタスクを実行できません。App Storeの全データを取得できないためです。ここでBright Dataツールとの連携が役立ちます。この設定により、エージェントはアプリページをスクレイピングし、レビューや価格詳細を分析した後、LLMが情報を明確で人間が読めるレポートに加工できます。
これは、インストール前にアプリを評価し、潜在的な問題やユーザーの懸念点を指摘するエージェントを構築する実践的な例です。結局のところ、十分な調査なしにアプリをインストールすることは、セキュリティの観点からリスクを伴う可能性があります。
では、タスクを実行し、ターミナルで直接応答をストリーム出力しましょう:
from autogen_agentchat.ui import Console
await Console(team.run_stream(task=task))すばらしい!これでチームが起動し、タスクが設定済みのエージェントに引き継がれます。エージェントは目標達成のために複数回の反復処理を実行する可能性があります。期待される結果は、エージェントがBright DataのWeb MCPツールを使用してApp Storeからデータをスクレイピングし、LLMがそのデータを統合して選択したアプリのインストール価値を評価することです。
最後のステップとして、スクリプト終了時に選択したモデルへの接続を閉じることを忘れないでください:
await model_client.close()ステップ #8: 全てを統合する
agent.pyファイルには以下を含める必要があります:
# pip install autogen-agentchat "autogen-ext[openai]" "autogen-ext[mcp]" python-dotenv
import asyncio
from dotenv import load_dotenv
import os
from autogen_ext.tools.mcp import (
StdioServerParams,
mcp_server_tools
)
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.ui import Console
# .envファイルから環境変数をロード
load_dotenv()
# envsからBright Data APIキーを読み込み
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
async def main():
# Bright Data Web MCP 接続設定
bright_data_mcp_server = StdioServerParams(
command="npx",
args=[
"-y",
"@brightdata/mcp"
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # オプション
}
)
# Bright Data Web MCPサーバーが公開するツールを読み込み
bright_data_tools = await mcp_server_tools(bright_data_mcp_server)
# LLM統合
model_client = OpenAIChatCompletionClient(
model="gpt-4o-mini",
)
# Web MCPツールで駆動されるAIアシスタントエージェントを定義
agent = AssistantAgent(
name="web_agent",
model_client=model_client,
tools=bright_data_tools,
)
# ループの終了条件を定義
text_termination = TextMentionTermination("TERMINATE")
# エージェントのみのチームを作成
team = RoundRobinGroupChat([agent], termination_condition=text_termination)
# チームが実行するタスク
task = """
App Storeの以下のアプリから情報を取得してください:
"https://apps.apple.com/us/app/brave-browser-search-engine/id1052879175"
ユーザーレビュー、価格、入手可能な全情報に基づき、このアプリはインストールする価値があり信頼できるか教えてください。
"""
# チームの応答をターミナルにストリーム出力
await Console(team.run_stream(task=task))
# AI接続を閉じる
await model_client.close()
if __name__ == "__main__":
asyncio.run(main())すごい!わずか70行ほどのコードで、App Storeへのインストールを分析する単一エージェントのチームを構築しました。
エージェントの実行:
python agent.pyターミナルには以下のように表示されるはずです:

ご覧の通り、エージェントはWeb MCPのweb_data_apple_app_storeがこのタスクに適したツールであると正しく識別しました。これは「構造化されたApple App Storeデータを迅速に取得する」ためのProツールです。したがって、これは間違いなく適切な選択でした。Proモードを有効にしていない場合、エージェントは代わりにscrape_as_markdownツールを利用します。
ツールの実行には少し時間がかかる場合があります。結果は期待通り、App Storeページから抽出された構造化データ(JSON形式)です:

この構造化出力はLLMによって分析・処理され、Markdown形式のレポートが生成されます:
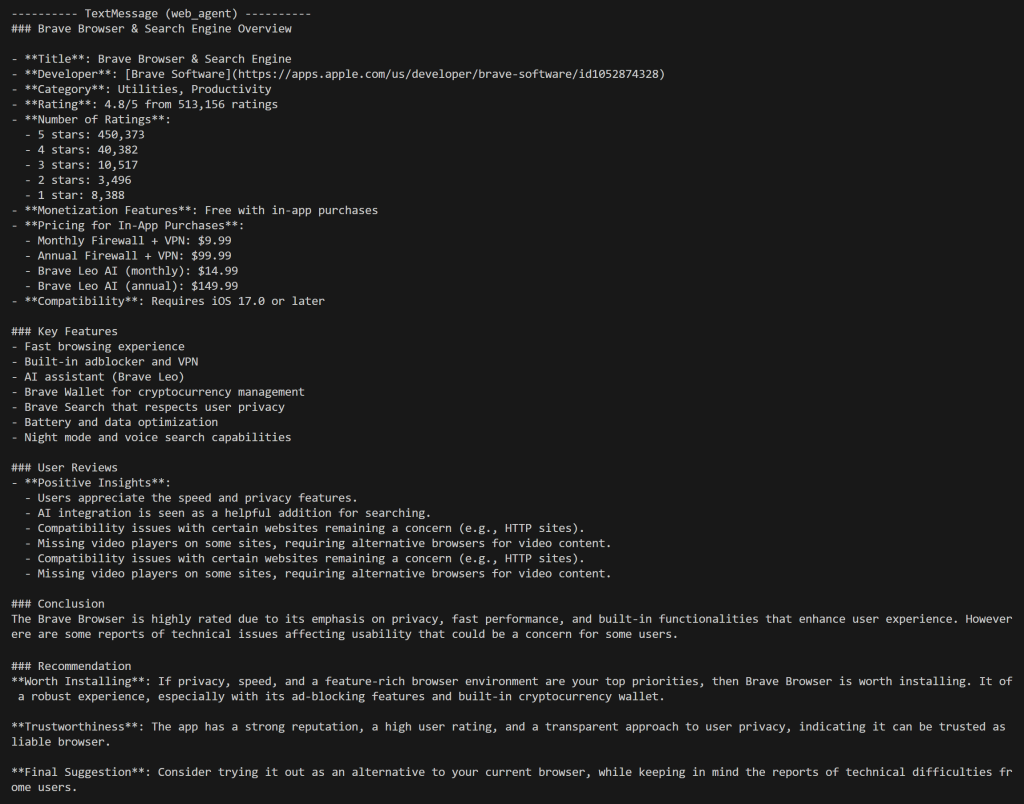
生成されたレポート冒頭の詳細情報に注目してください。これは対象App Storeページに表示されている内容と完全に一致しています:
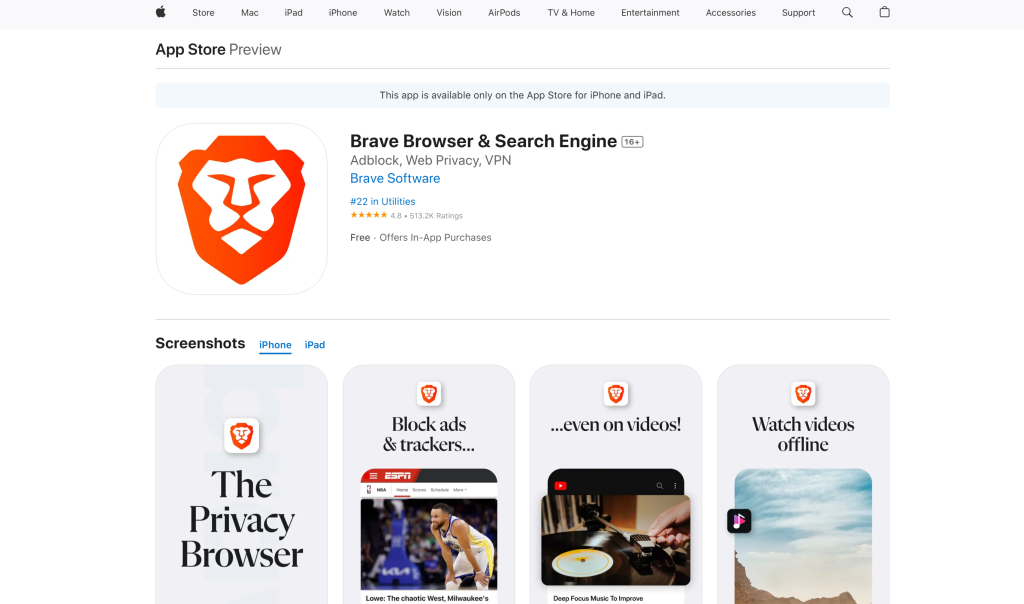
ミッション完了!エージェントはウェブからデータを取得し、意味のあるタスクを実行するために処理できるようになりました。
これは単純な例に過ぎないことを覚えておいてください。AutoGen AgentChatで利用可能なBright Data Web MCPツールの幅広いラインナップを活用すれば、様々な実世界のユースケースに合わせた、より高度なエージェントを設計できます。
さあ、これで完了です!PythonでBright DataのWeb MCPをAutoGen AgentChat AIエージェントに統合する力を目の当たりにしました。
Agent StudioでWeb MCP強化エージェントを視覚的にテスト
AutoGenはまた、エージェントを視覚的に作成・実験できるローコードのブラウザベースツール「Studio」を提供しています。MCP統合されたエージェントを簡便にテストするのに活用できます。その方法をご覧ください!
前提条件
このオプションセクションを実行する唯一の前提条件は、AutoGen Studioがインストールされていることです。プロジェクトディレクトリ内のアクティブ化された仮想環境から、以下でインストールしてください:
pip install -U autogenstudioAutoGen Studioは.envファイルからOPENAI_API_KEYを自動読み込みするため、ツール内で手動設定する必要はありません。
ステップ #1: チーム JSON 設定ファイルの取得
AutoGenでは、チーム設定内のあらゆるコンポーネントをJSONファイルとして表現できます。AutoGen StudioはAgentChatを基盤としているため、AgentChatコンポーネントをJSONにエクスポートし、AutoGen Studioに読み込むことが可能です。まさにそれをここで実行します!
まず、以前に作成したチーム定義をローカルのJSONファイルにエクスポートします:
config = team.dump_component()
with open("bd_mcp_team.json", "w", encoding="utf-8") as f:
f.write(config.model_dump_json())これによりプロジェクトフォルダ内にbd_mcp_team.jsonファイルが生成されます。これを開いてください。
このファイルには、Bright DataのWeb MCPツールに接続するために必要な詳細情報を含む、エージェントのJSON表現が含まれています。
ステップ #2: AutoGen Studio で JSON ファイルを読み込む
ローカルで AutoGen Studio を起動します:
autogenstudio ui --port 8080アプリケーションはブラウザでhttp://127.0.0.1:8080 にアクセス可能です。開くと以下のWebアプリが表示されます:
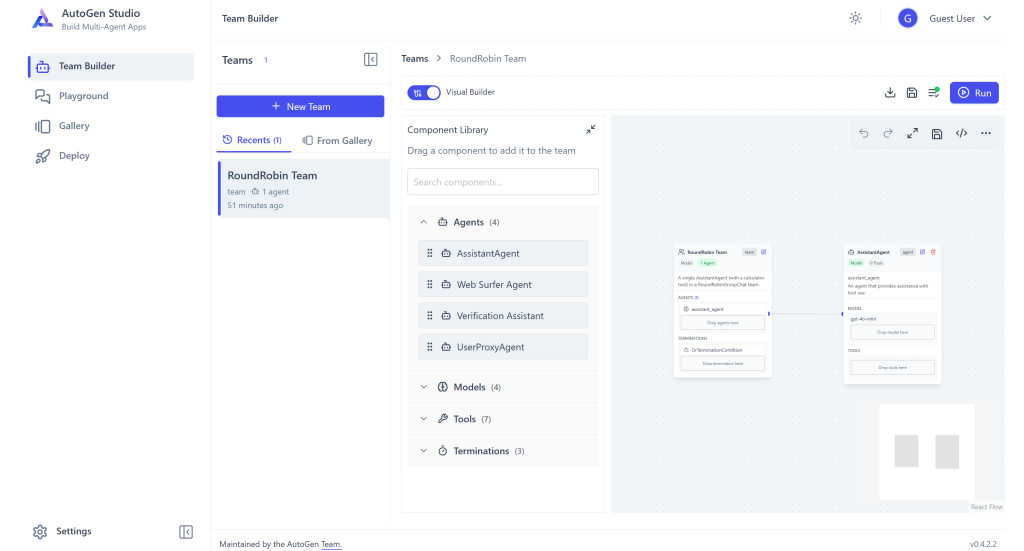
デフォルトでは「RoundRobin Team」というチームが設定されています。これをMCP拡張エージェントとして設定するには、「Visual Builder」スイッチを切り替えて「View JSON」モードにします:
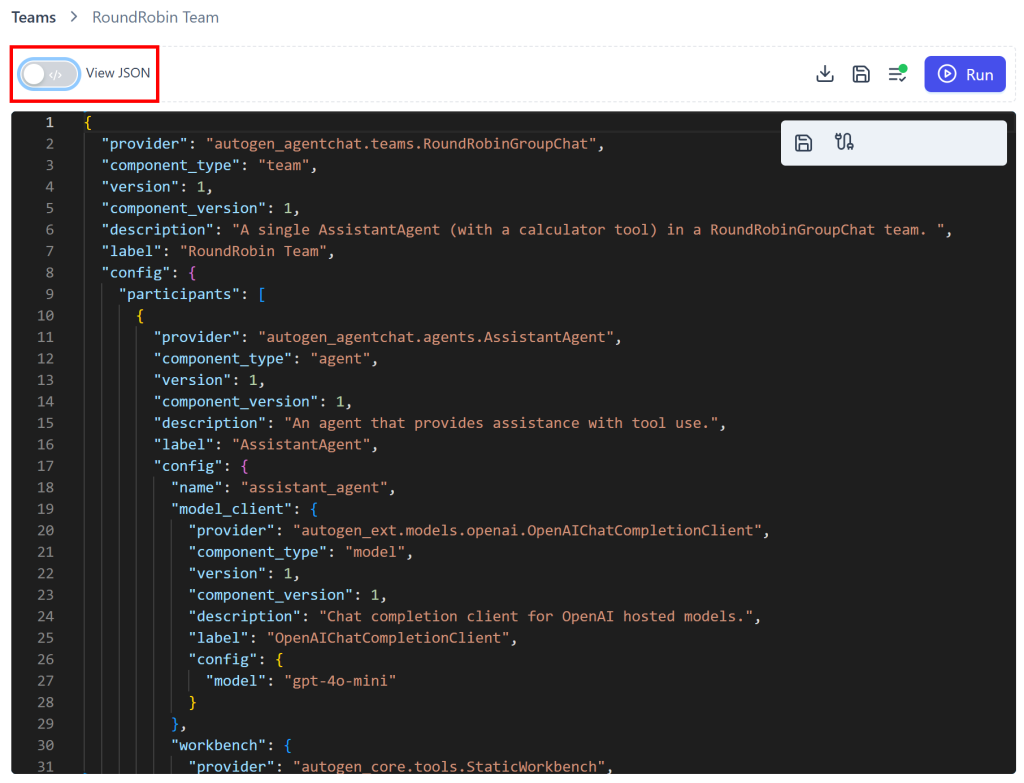
JSONエディタにbd_mcp_team.jsonファイルの内容を貼り付け、「変更を保存」ボタンを押します:
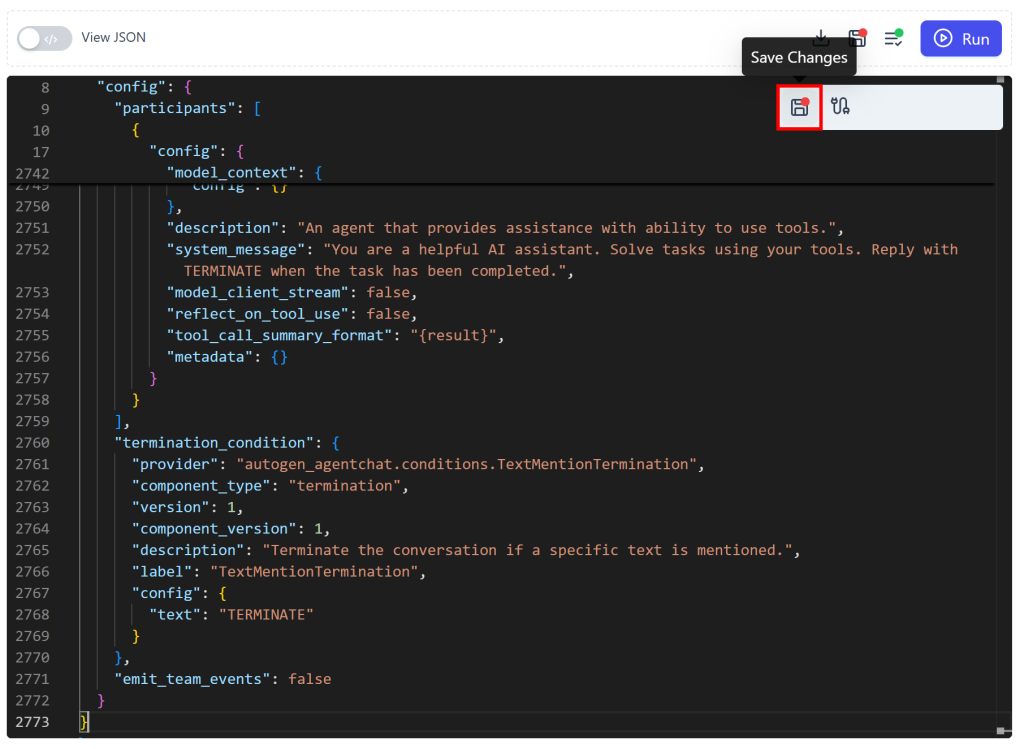
更新後の「RoundRobin Team」は次のようになります:
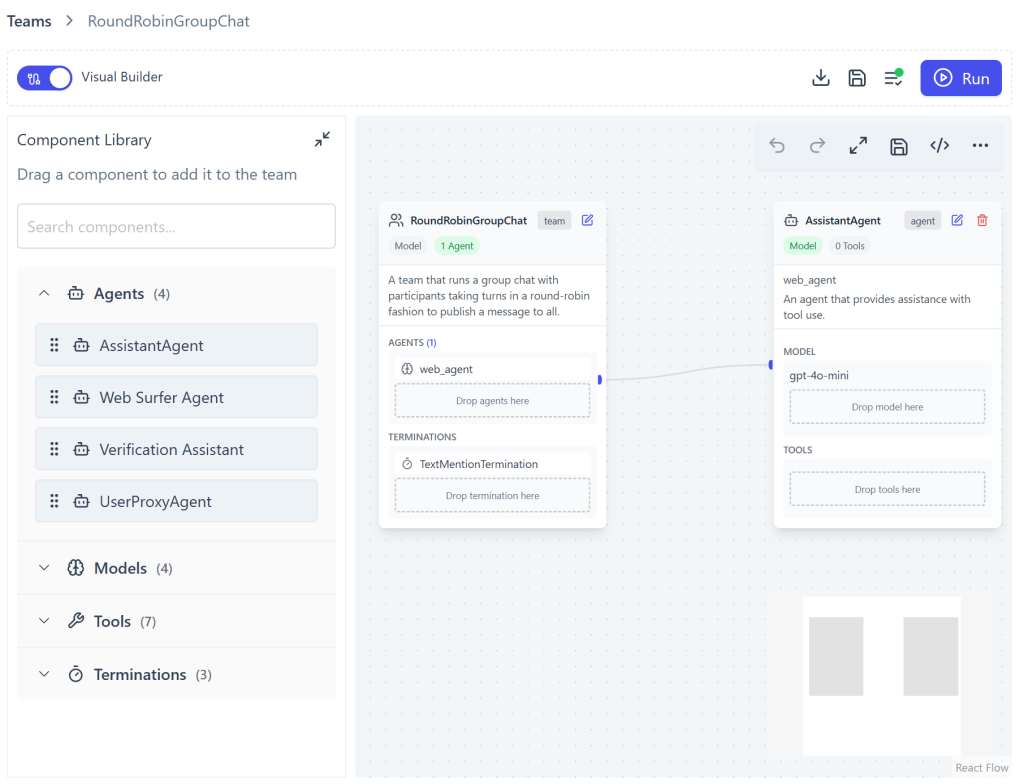
エージェント名がコードで定義した通り「web_agent」に変更されていることに注意してください。これでAutoGen Studio内でWeb MCPと統合されたエージェントを直接テストできるようになります。
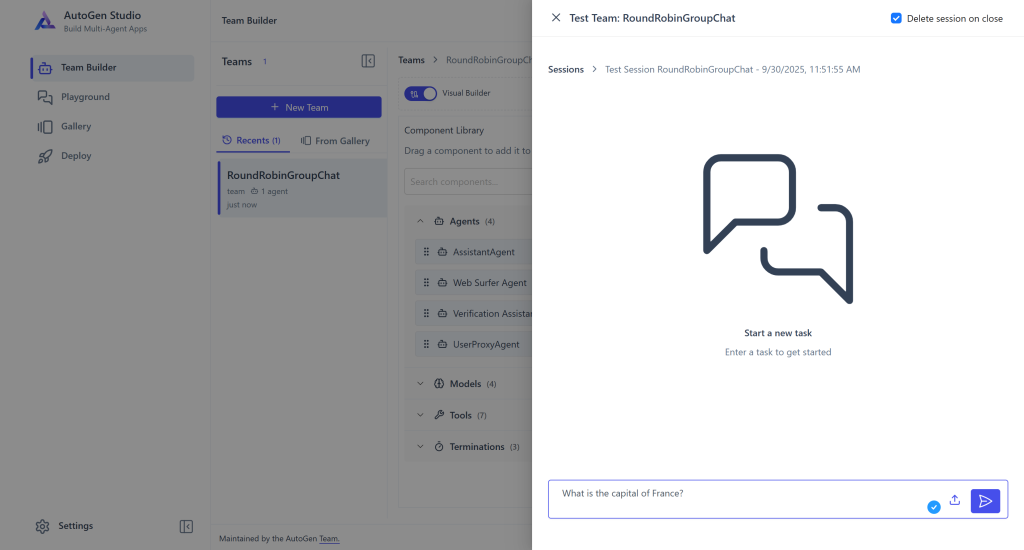
ステップ #3: エージェントの視覚的テスト
右上の「実行」ボタンを押します。チームテスト用のチャットセクションが表示されます:
以前と同じタスクプロンプトを貼り付けて実行します:
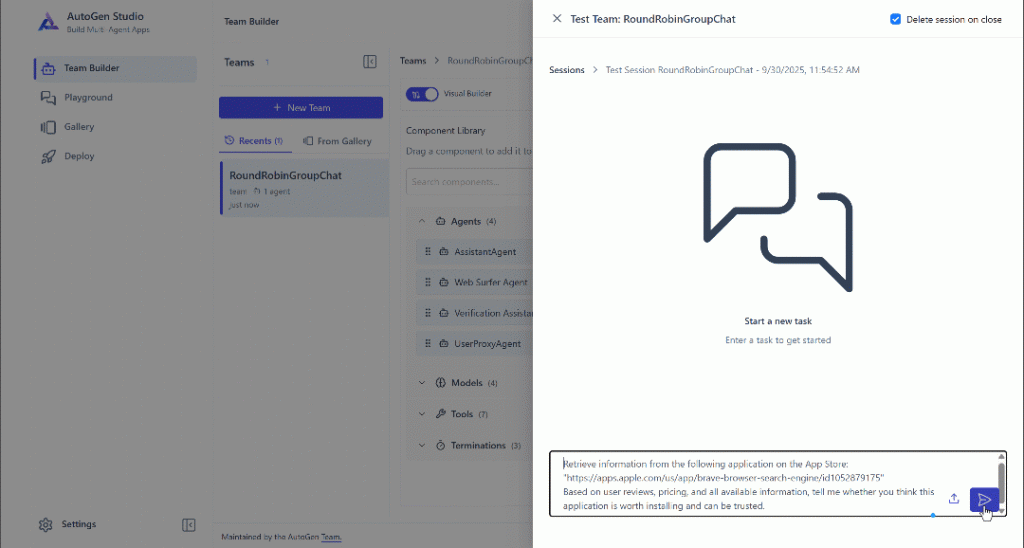
前回と同様に、エージェントはweb_data_apple_app_storeツールを選択して実行します。最終的な出力は次のようになります:
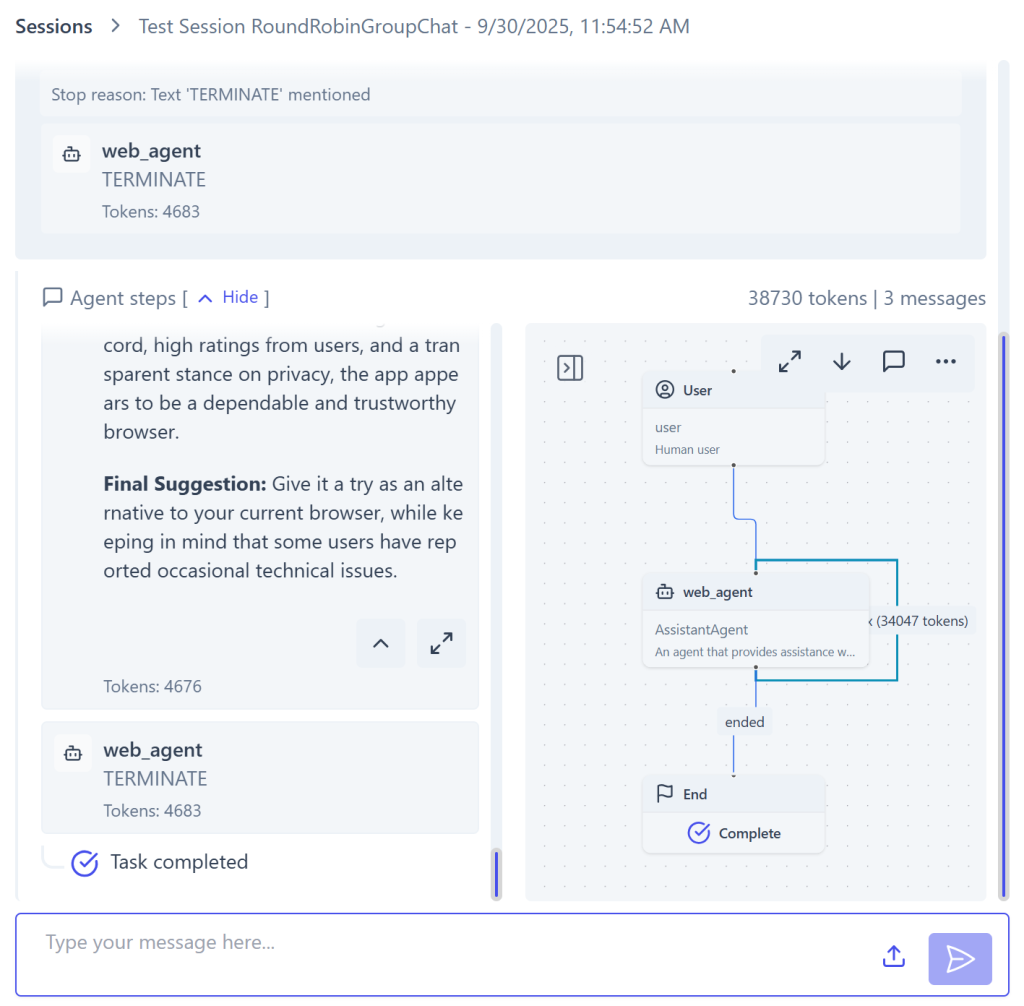
左側のメッセージの最後から2番目に、エージェントが生成した応答が表示されます。今回は、自動的に送信される「TERMINATE」メッセージを使用してエージェントが終了することも確認できます。右側には実行の視覚的表現が表示され、ステップごとの動作を理解するのに役立ちます。
エージェントが終了しても、そのコンテキストはチームと共有されたままです。つまり、ChatGPTやその他のチャット型AIインターフェースと同様に、別のタスクを渡すことでシームレスに会話を継続できます。
これはAutoGen Studioでエージェントをテストする真の利点の一つを示しています。エージェントの動作を視覚的に追跡し、出力を確認し、複数のやり取りにわたってコンテキストを維持できるのです。素晴らしい!
まとめ
本記事では、AutoGen AgentChatを用いたAIエージェント構築方法と、Bright DataのWeb MCP(無料プランあり!)による機能強化手法を紹介しました。さらにAutoGen Studioを通じた視覚的テストとチャット型体験の実行も検証しました。
この統合により、エージェントはウェブ検索、構造化データ抽出、ウェブデータフィードへのアクセス、ウェブインタラクション機能などを拡張できます。より高度なAIエージェントを構築するには、Bright DataのAIインフラストラクチャ内の幅広い製品・サービス群を探索してください。
今すぐBright Dataの無料アカウントに登録し、AI対応のウェブデータツールで実験を始めましょう!




