

複数のプラットフォームに散在するカスタマーレビューは、企業にとって分析上の課題となります。手作業によるレビュー監視は時間がかかり、本質的な洞察を見落としがちです。このガイドでは、さまざまなソースからレビューを自動的に収集、分析、分類するAIエージェントを構築する方法を紹介します。
以下を学ぶことができます:
- CrewAIとBright DataのWeb MCPを使用したレビューインテリジェンスシステムの構築方法
- 顧客フィードバックに対してアスペクトベースのセンチメント分析を実行する方法
- トピック別にレビューを分類し、実用的なインサイトを生成する方法
GitHubの最終プロジェクトをご覧ください!
CrewAIとは?
CrewAIは、コラボレーションAIエージェントチームを構築するためのオープンソースのフレームワークです。エージェントの役割、目標、複雑なワークフローを実行するためのツールを定義します。各エージェントは共通の目的に向かって協力しながら特定のタスクを処理します。
CrewAIの構成は以下の通りです:
- エージェント定義された責任とツールを持つLLMワーカー
- タスク:明確なアウトプット要件を持つ特定の仕事
- ツール:エージェントがデータ抽出のような専門的な作業に使用する機能
- クルー:一緒に働くエージェントの集まり
MCPとは?
MCP (Model Context Protocol)は、JSON-RPC 2.0標準であり、統一されたインターフェースを介してAIエージェントを外部ツールやデータソースに接続します。
Bright DataのWeb MCPサーバーは、150M以上のローテーションIPによるボット対策、ダイナミックコンテンツのためのJavaScriptレンダリング、スクレイピングされたデータからのクリーンなJSON出力、様々なプラットフォーム用の50以上のレディメイドツールを備えたWebスクレイピング機能への直接アクセスを提供します。
私たちが作っているものマルチソースレビューインテリジェンスエージェント
G2、Capterra、Trustpilot、TrustRadiusなどの複数のプラットフォームから特定の企業のレビューを自動的にスクレイピングし、それぞれの評価とトップレビューをフェッチバックし、アスペクトベースのセンチメント分析を実行し、フィードバックをトピック(サポート、価格、使いやすさ)に分類し、各カテゴリのセンチメントをスコアリングし、実用的なビジネスインサイトを生成するCrewAIシステムを作成します。
前提条件
開発環境のセットアップ
- Python 3.11以上
- Web MCPサーバー用のNode.jsとnpm
- Bright Dataアカウント–サインアップし、APIトークンを作成します(無料トライアルクレジットをご利用いただけます)。
- Nebius APIキー–Nebius AI Studioでキーを作成します。無料で使用できます。課金プロファイルは必要ありません。
- Python仮想環境– 依存関係を隔離します。
環境のセットアップ
プロジェクトディレクトリを作成し、依存関係をインストールします:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv/bin/activate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv pandas textblob
review_intelligence.pyという新しいファイルを作成し、以下のインポートを追加します:
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
インポート json
import pandas as pd
from datetime import datetime
from dotenv import load_dotenv
from textblob import TextBlob
load_dotenv()
Bright Data Web MCPの設定
あなたの認証情報で.envファイルを作成します:
BRIGHT_DATA_API_TOKEN="あなたの_api_token_here"
WEB_UNLOCKER_ZONE="your_web_unlocker_zone"
BROWSER_ZONE="あなたのブラウザゾーン"
NEBIUS_API_KEY="YOUR_NEBIUS_API_KEY"
必要です:
- APIトークン:Bright Dataのダッシュボードから新しいAPIトークンを生成します。
- Web Unlockerゾーン:不動産サイト用の新しいWeb Unlockerゾーンを作成します。
- ブラウザAPIゾーン:JavaScriptを多用する不動産サイト用に新しいBrowser APIゾーンを作成します。
- Nebius APIキー:前提条件で作成済み
review_intelligence.py で LLM と Web MCP サーバーを設定します:
llm = LLM(
model="nebius/Qwen/Qwen3-235B-A22B",
api_key=os.getenv("NEBIUS_API_KEY")
)
server_params = StdioServerParameters(
command="npx"、
args=["@brightdata/mcp"]、
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN")、
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE")、
"BROWSER_ZONE": os.getenv("BROWSER_ZONE")、
},
)
エージェントとタスクの定義
レビュー分析の異なる側面に特化したエージェントを定義します。レビュースクレイパーエージェントは、複数のプラットフォームからカスタマーレビューを抽出し、レビューテキスト、評価、日付、プラットフォームソースを含むクリーンで構造化されたJSONデータを返します。このエージェントは、ウェブスクレイピングの専門知識を持ち、レビュープラットフォームの構造を深く理解し、ボット対策を回避する能力を持ちます。
def build_review_scraper_agent(mcp_tools):
return エージェント(
role="Review Data Collector"、
ゴール=(
"複数のプラットフォームからカスタマーレビューを抽出し、クリーンで"
"レビューテキスト、評価、日付、プラットフォームソースを含む構造化されたJSONデータを返す。"
),
バックストーリー=(
"レビュープラットフォームの構造に関する深い知識を持つウェブスクレイピングのエキスパート。"
"ボット対策を回避し、完全なレビューデータセットを抽出することに長けている"
"Amazon、Yelp、Googleレビュー、その他のプラットフォームから"
),
tools=mcp_tools、
llm=llm、
max_iter=3、
verbose=True、
)
センチメントアナライザーエージェントは、3つの主要な側面にわたってレビューのセンチメントを分析します:サポート品質、価格満足度、使いやすさ。各カテゴリについて、数値スコアと詳細な理由を提供します。このエージェントは、自然言語処理と顧客センチメント分析を専門としており、感情的な指標とアスペクト特有のフィードバックパターンを特定することに精通しています。
def build_sentiment_analyzer_agent():
return エージェント(
role="Sentiment Analysis Specialist"、
ゴール=(
"3つの重要な側面にわたってレビューのセンチメントを分析する:サポートの質、"
「価格満足度、使いやすさ。各カテゴリーについて数値スコアと"
"各カテゴリーの詳細な理由を提供する。"
),
バックストーリー=(
"自然言語処理と顧客" "感情分析を専門とするデータサイエンティスト。
"感情分析を専門とするデータサイエンティスト。顧客レビューにおける感情的指標、文脈の手がかり、局面特有のフィードバックパターンを"
"顧客レビューにおけるアスペクト特有のフィードバックパターンを特定する専門家。"
),
llm=llm、
max_iter=2、
verbose=True、
)
インサイトジェネレータエージェントは、センチメント分析結果を実用的なビジネスインサイトに変換します。傾向を特定し、重要な問題を強調し、改善のための具体的な推奨事項を提供します。このエージェントは、カスタマーエクスペリエンスの最適化とフィードバックデータを具体的なビジネスアクションに変換するスキルを持つ戦略的分析の専門知識をもたらします。
def build_insights_generator_agent():
return エージェント(
role="Business Intelligence Analyst"、
ゴール=(
"センチメント分析結果を実用的なビジネスインサイトに変換する。"
"傾向を特定し、重要な問題を浮き彫りにし、具体的な"
"改善のための提案を行う。"
),
バックストーリー=(
"カスタマー・エクスペリエンスの最適化を専門とする戦略アナリスト。"
「顧客からのフィードバックデータを具体的なビジネス"
"アクションと優先順位のフレームワーク"
),
llm=llm、
max_iter=2、
verbose=True、
)
クルーの組み立てと実行
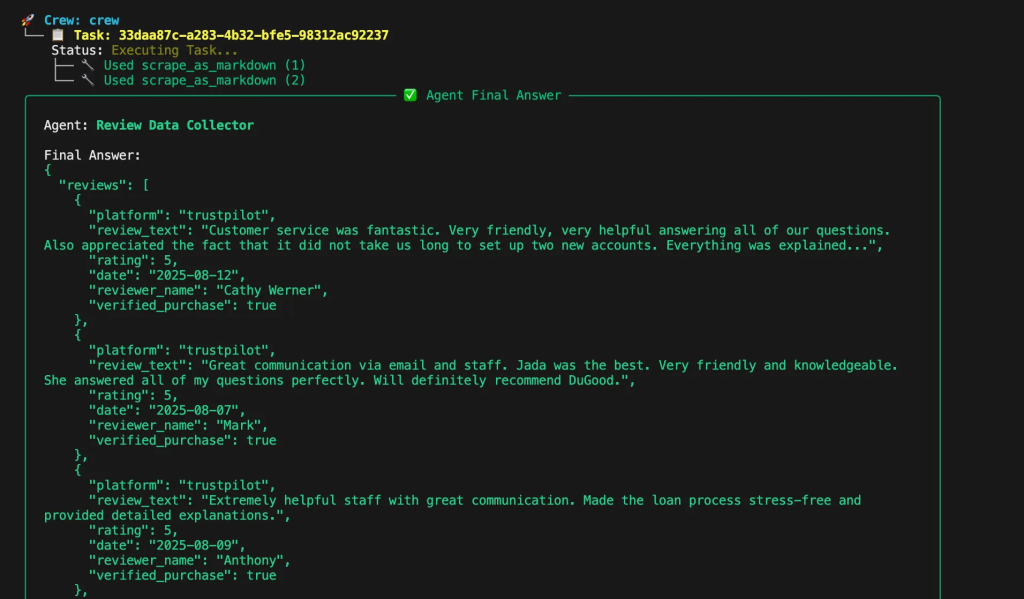
分析パイプラインの各ステージのタスクを作成します。スクレイピングタスクは、指定された商品ページからレビューを収集し、プラットフォーム情報、レビューテキスト、評価、日付、検証ステータスを含む構造化されたJSONを出力します。
def build_scraping_task(agent, product_urls):
return Task(
description=f "Scrape reviews from these product pages:{product_urls}"、
expected_output="""{
"reviews": [
{
"プラットフォーム":"amazon"、
"review_text":"素晴らしい製品、迅速な配送..."、
"rating":5,
"date":"2024-01-15",
"reviewer_name":"ジョンD."、
"verified_purchase": true
}
],
"total_reviews":150,
"platforms_scraped": ["amazon", "yelp"].
}""",
agent=agent、
)
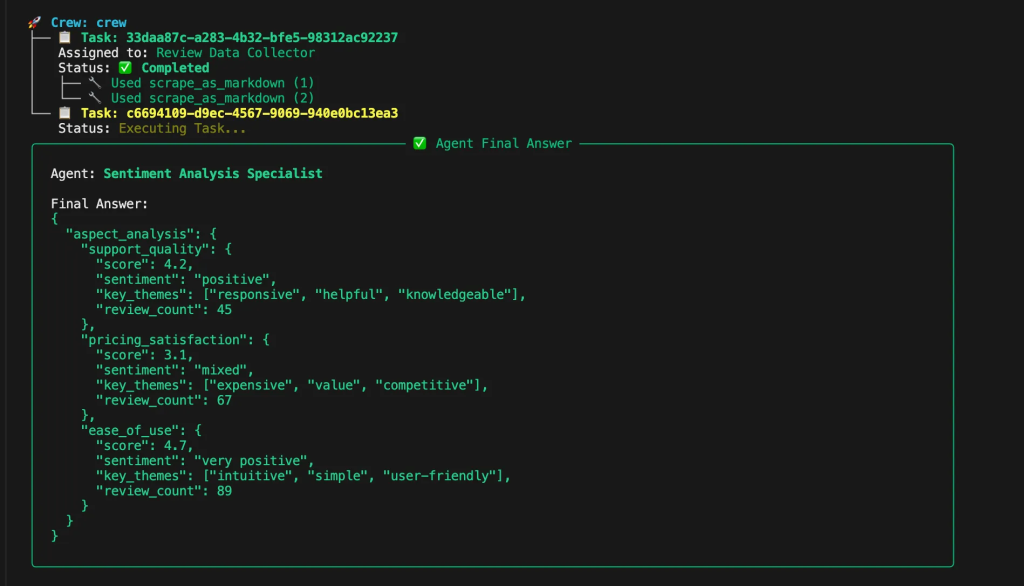
センチメント分析タスクは、サポート、価格、使いやすさの側面を分析するためにレビューを処理します。各カテゴリの数値スコア、センチメント分類、主要なテーマ、レビュー数を返します。
def build_sentiment_analysis_task(agent):
return Task(
description="サポート、価格、使いやすさのセンチメントを分析する"、
期待される出力
"aspect_analysis":{
"support_quality":{
"スコア":4.2,
"センチメント":「ポジティブ
"key_themes": ["responsive", "helpful", "knowledgeable"]、
「レビュー数45
},
「価格満足度":{
「スコア3.1,
"センチメント":「混合」、
"key_themes": ["expensive", "value", "competitive"]、
「レビュー数67
},
「使いやすさ{
「スコア4.7,
"センチメント":「非常にポジティブ
"key_themes": ["intuitive", "simple", "user-friendly"]、
「レビュー数89
}
}
}""",
agent=agent、
)
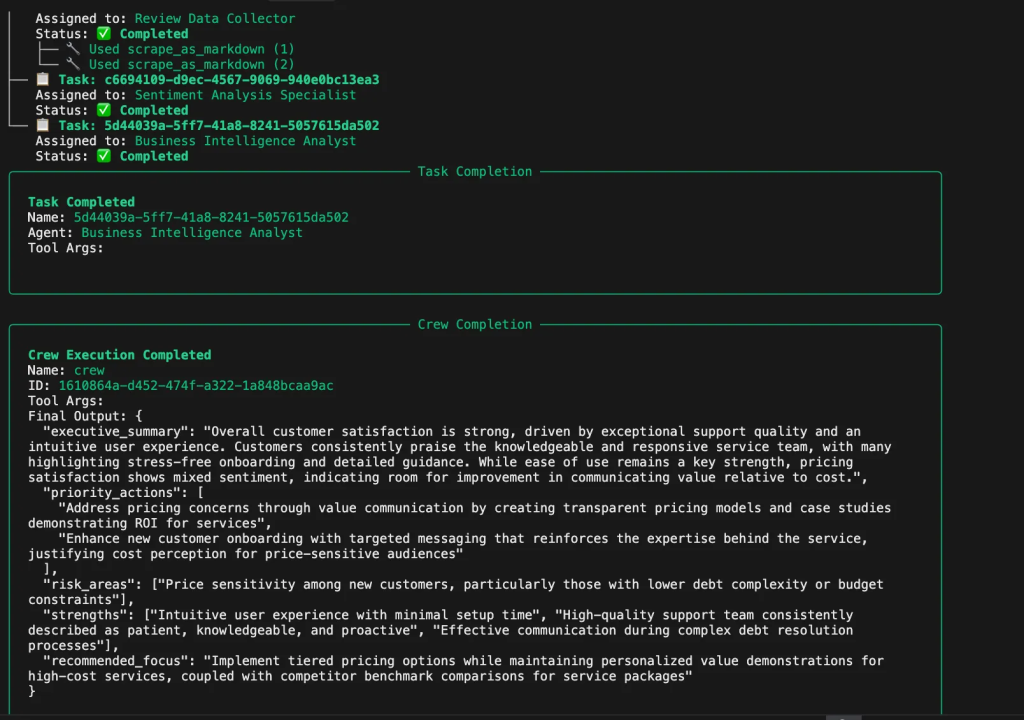
insights タスクは、センチメント分析結果から実用的なビジネスインテリジェンスを生成します。エグゼクティブサマリー、優先アクション、リスク領域、強みの特定、戦略的推奨を提供します。
def build_insights_task(agent):
return Task(
description="Generate actionable business insights from sentiment analysis"、
期待される出力
"executive_summary":"全体的な顧客満足度は高い..."、
「priority_actions": [
"バリュー・コミュニケーションを通じて価格に関する懸念に対処する", "priority_actions": ["顧客満足度が高い、
"優れた使いやすさの基準を維持する"
],
「risk_areas": ["新規顧客の価格感応度"]、
「strengths": ["直感的なユーザーエクスペリエンス", "質の高いサポートチーム"]、
"recommended_focus":「価格戦略の最適化
}""",
agent=agent、
)
アスペクトベースのセンチメント分析
レビューで言及された特定のアスペクトを識別し、関心のある各領域のセンチメントスコアを計算するセンチメント分析関数を追加します。
def analyze_aspect_sentiment(reviews, aspect_keywords):
"""レビューで言及された特定の側面のセンチメントを分析する。"""
aspect_reviews = []
for review in reviews:
text = review.get('review_text', '').lower()
if any(keyword in text for keyword in aspect_keywords):
blob = TextBlob(review['review_text'])
sentiment_score = blob.sentiment.polarity
aspect_reviews.append({
'text': review['review_text']、
'sentiment_score': sentiment_score、
'rating': review.get('rating', 0)、
'platform': review.get('platform', '')
})
return aspect_reviews
レビューをトピックに分類する(サポート、価格、使いやすさ)
分類機能は、キーワードのマッチングに基づいて、レビューをサポート、価格、使いやすさのトピックに整理します。サポートキーワードには、カスタマーサービスやアシスタンスに関する用語が含まれます。価格に関するキーワードは、コスト、価値、手頃な価格に関する言及をカバーします。
def categorize_by_aspects(reviews):
"""レビューをサポート、価格、使いやすさのトピックに分類する"""
support_keywords = ['サポート', 'ヘルプ', 'サービス', '顧客', '対応', 'アシスタンス'].
pricing_keywords = ['価格', 'コスト', '高い', '安い', '価値', 'お金', '手頃な価格']"
usability_keywords = ['簡単', '難しい', '直感的', '複雑', 'ユーザーフレンドリー', 'インターフェイス']。
カテゴライズ = {
'サポート': analyze_aspect_sentiment(reviews, support_keywords)、
'pricing': analyze_aspect_sentiment(reviews, pricing_keywords)、
使いやすさ」:analyze_aspect_sentiment(レビュー、usability_keywords)
}
分類して返す
トピックごとのセンチメントのスコアリング
センチメント分析を数値評価と意味のあるカテゴリに変換するスコアリングロジックを実装します。
def calculate_aspect_scores(categorized_reviews):
"""各アスペクトカテゴリの数値スコアを計算する"""
スコア = {}
for aspect, reviews in categorized_reviews.items():
if not reviews:
scores[aspect] = {'score': 0, 'count': 0, 'sentiment': 'neutral'}.
続ける
# 平均センチメントスコアを計算する
sentiment_scores = [r['sentiment_score'] for r in reviews] # 平均センチメントスコアを計算する
avg_sentiment = sum(sentiment_scores) / len(sentiment_scores)
# 1-5スケールに変換
正規化されたスコア = ((avg_sentiment + 1) / 2) * 5
# センチメントカテゴリーを決定する
if avg_sentiment > 0.3:
センチメントカテゴリー = 'ポジティブ
elif avg_sentiment < -0.3:
センチメントカテゴリー = 'ネガティブ
それ以外の場合
センチメントカテゴリー = 'ニュートラル
スコア[アスペクト] = {
'score': round(normalized_score, 1)、
'count': len(reviews)、
'sentiment': sentiment_category、
'raw_sentiment': round(avg_sentiment, 2)
}
スコアを返す
最終インサイトレポートの生成
すべてのエージェントとタスクを順番にオーケストレーションすることで、ワークフローの実行を完了する。プライマリ機能は、スクレイピング、センチメント分析、インサイト生成に特化したエージェントを作成します。これらのエージェントを順番にタスク処理するクルーに組み立てる。
def analyze_reviews(product_urls):
"""レビューインテリジェンスワークフローを編成するメイン関数"""
with MCPServerAdapter(server_params) as mcp_tools:
# エージェントの作成
scraper_agent = build_review_scraper_agent(mcp_tools)
sentiment_agent = build_sentiment_analyzer_agent()
insights_agent = build_insights_generator_agent()
# タスクを作成する
スクレイピングタスク = build_scraping_task(scraper_agent, product_urls)
sentiment_task = build_sentiment_analysis_task(sentiment_agent)
insights_task = build_insights_task(insights_agent)
# クルーを組み立てる
crew = Crew(
agent=[scraper_agent, sentiment_agent, insights_agent]、
タスク=[scraping_task, sentiment_task, insights_task]、
process=Process.sequential、
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
product_urls = ["<>
"<https://www.amazon.com/product-example-1>"、
"<https://www.yelp.com/biz/business-example>"
]
try:
result = analyze_reviews(product_urls)
print("レビューインテリジェンス分析完了!")
print(json.dumps(result, indent=2))
except Exception as e:
print(f "分析に失敗しました:{str(e)}")。
分析を実行します:
python review_intelligence.py
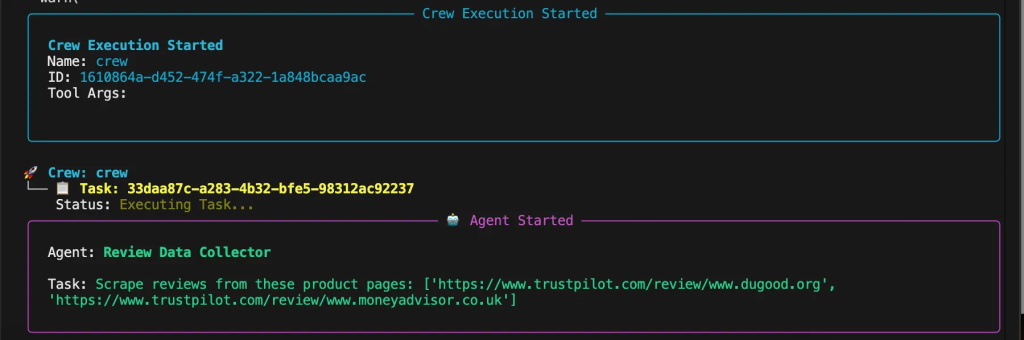
各エージェントがタスクを計画し実行するとき、エージェントの思考プロセスがコンソールに表示されます。システムがどのようなものかを示してくれる:
- 複数のプラットフォームから包括的なレビューデータを抽出
- 競合とのギャップと市場でのポジショニングの分析
- センチメントパターンの処理とレビューの品質スコアリング
- 機能に関する言及と価格インテリジェンスの特定
- 戦略的提言とリスク警告の提供
結論
CrewAIとブライトデータの強力なウェブデータプラットフォームでレビューインテリジェンスを自動化することで、より深い顧客インサイトを引き出し、競合分析を合理化し、よりスマートなビジネス上の意思決定を行うことができます。ブライトデータの製品と業界をリードするアンチボットウェブスクレイピングソリューションにより、あらゆる業界のレビュー収集とセンチメント分析を拡張することができます。最新の戦略や最新情報については、ブライトデータのブログをご覧いただくか、詳細なウェブスクレイピングガイドをご覧ください。





