

このチュートリアルでは以下を学びます:
- – Langchain MCPアダプターライブラリの概要と提供機能
- Bright Data Web MCPを介してエージェントにウェブ検索、ウェブデータ取得、ウェブ対話機能を提供するために、なぜこれを利用するべきか。
- – ReActエージェント内でLangchain MCPアダプターをWeb MCPに接続する方法
さあ、始めましょう!
LangChain MCPアダプターライブラリとは?
Langchain MCPアダプターは、LangchainおよびLangGraphでMCPツールを利用可能にするパッケージです。オープンソースのlangchain-mcp-adaptersパッケージを通じて利用でき、MCPツールをLangchainおよびLangGraph互換ツールに変換する役割を担います。
この変換により、ローカルまたはリモートサーバー上のMCPツールをLangchainワークフローやLangGraphエージェント内で直接使用できます。これらのMCPツールは、LangGraphエージェント向けに既に公開されている数百のツールと同様に利用可能です。
具体的には、このパッケージには複数のMCPサーバーに接続し、そこからツールをロードできるMCPクライアント実装も含まれています。詳細な使用方法については公式ドキュメントをご覧ください。
LangGraphエージェントをBright DataのWeb MCPと統合する理由
LangGraph AIで構築されたAIエージェントは、基盤となるLLMの制限を継承します。これにはリアルタイム情報へのアクセス不足が含まれ、不正確または古い応答を招く場合があります。
幸い、最新のウェブデータとライブウェブ探索機能をエージェントに装備することで、この制限を克服できます。ここでBright DataのWeb MCPが活躍します!
オープンソースのNode.jsパッケージとして提供されるWeb MCPは、Bright DataのAI対応データ取得ツール群と連携し、エージェントがウェブコンテンツへのアクセス、構造化データセットのクエリ、ウェブ検索の実行、ウェブページとのリアルタイムな対話を可能にします。
特にWeb MCPが提供する2つの人気ツールは:
| ツール | 説明 |
|---|---|
scrape_as_markdown |
単一ウェブページURLから高度な抽出オプションでコンテンツをスクレイピングし、結果をMarkdown形式で返します。ボット検知やCAPTCHAを回避可能です。 |
search_engine |
Google、Bing、Yandexから検索結果を抽出し、SERPデータをJSONまたはMarkdown形式で返します。 |
さらに、Bright DataのWeb MCPは、ウェブページとの対話(例:scraping_browser_click)や、Amazon、TikTok、Instagram、Yahoo Finance、LinkedIn、ZoomInfoなど、幅広いウェブサイトからの構造化データの収集に特化した約60のツールを提供します。
例えば、web_data_zoominfo_company_profileツールは、有効な企業URLを入力として受け取り、ZoomInfoから詳細な構造化された企業プロフィール情報を取得します。公式Web MCPドキュメントで詳細を確認してください!
Langchainツール経由でのBright Data直接連携をお探しの場合は、以下のガイドを参照してください:
Langchain MCPアダプターを使用したAIエージェントでのWeb MCP接続方法
このステップバイステップセクションでは、MCPアダプターライブラリを使用してBright Data Web MCPをLagnGraphエージェントに統合する方法を学びます。結果として、ウェブ検索、データアクセス、ウェブインタラクションのための60以上のツールにアクセス可能なAIエージェントが完成します。
設定が完了すると、AIエージェントはZoomInfoから企業データを取得し、詳細なレポートを生成します。この出力は、企業への投資、応募、さらなる調査の価値を評価するのに役立ちます。
以下の手順に従って始めましょう!
注:このチュートリアルはPython版Langchainに焦点を当てていますが、Langchain JavaScript SDKにも容易に適用可能です。同様に、エージェントはOpenAIに依存しますが、他のサポートされているLLMで置き換えることもできます。
前提条件
このチュートリアルを実践するには、以下の環境が整っていることを確認してください:
- ローカルにPython 3.8以上がインストールされていること。
- ローカルにNode.jsがインストールされていること(最新のLTSバージョンを推奨)。
- Bright Data APIキー。
- OpenAI APIキー(またはLangchainがサポートする他のLLMのAPIキー)
Bright Dataの設定については、次のステップで手順を案内しますので、現時点では心配する必要はありません。
以下の背景知識があると便利です(必須ではありません):
- MCPの動作に関する一般的な理解。
- Bright DataのWeb MCPおよび同ツール群に関する基礎知識。
ステップ #1: Langchainプロジェクトの設定
ターミナルを開き、LangGraph MCP搭載AIエージェント用の新規ディレクトリを作成します:
mkdir langchain-mcp-agentlangchain-mcp-agent/フォルダにはAIエージェントのPythonコードを格納します。
次に、プロジェクトディレクトリに移動し、仮想環境を設定します:
cd langchain-mcp-agent
python -m venv .venvお気に入りのPython IDEでプロジェクトを開きます。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
プロジェクトフォルダ内に、agent.py という名前の新規ファイルを作成します。プロジェクトの構造は次のようになります:
langchain-mcp-agent/
├── .venv/
└── agent.pyここでagent.pyがメインの Python ファイルとなります。非同期コード実行用に初期化します:
import asyncio
async def main():
# エージェント定義ロジック...
if __name__ == "__main__":
asyncio.run(main())仮想環境をアクティブ化します。LinuxまたはmacOSでは以下を実行:
source .venv/bin/activateWindowsでは同等の操作として以下を実行:
.venv/Scripts/activate環境をアクティブ化した状態で、必要な依存関係をインストールします:
pip install langchain["openai"] langchain-mcp-adapters langgraph各パッケージの機能:
langchain["openai"]: OpenAI 統合機能を備えた LangChain コアライブラリ。langchain-mcp-adapters: MCPツールをLangChainおよびLangGraphと互換性を持たせる軽量ラッパーlanggraph: LangChain 上で動作する、長期実行型ステートフルエージェントの構築・管理・デプロイのための低レベルオーケストレーションフレームワーク。
注: LLM統合にOpenAIを使用しない場合は、langchain["openai"]を、ご利用のAIプロバイダーに対応するパッケージに置き換えてください。
完了!Python開発環境は、Bright Data Web MCPに接続するAIエージェントをサポートする準備が整いました。
ステップ #2: LLM の統合
免責事項:OpenAI以外のLLMプロバイダーを使用する場合は、このセクションを適宜調整してください。
まず、環境変数にOpenAI APIキーを設定します:
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"本番環境では、環境変数をより安全かつ信頼性の高い方法(例:python-dotenv経由)で管理し、スクリプト内にシークレットを直接ハードコーディングしないようにしてください。
次に、langchain_openaiパッケージからChatOpenAIをインポートします:
from langchain_openai import ChatOpenAIChatOpenAIは OPENAI_API_KEY環境変数から自動的にAPIキーを読み取ります。
main()関数内で、希望のモデルを使用してChatOpenAIインスタンスを初期化します:
llm = ChatOpenAI(
model="gpt-5-mini",
)この例ではgpt-5-mini を使用していますが、他の利用可能なモデルに置き換えることもできます。この LLM インスタンスが AI エージェントのエンジンとして機能します。素晴らしい!
ステップ #3: Bright Data Web MCP のテスト
エージェントをBright DataのWeb MCPに接続する前に、まずお使いのマシンでMCPサーバーが実際に実行できることを確認してください。
まだお持ちでない場合は、Bright Dataアカウントの作成から始めてください。既にアカウントをお持ちの場合は、ログインするだけで結構です。迅速なセットアップには、アカウント内の「MCP」ページを開き、指示に従ってください:
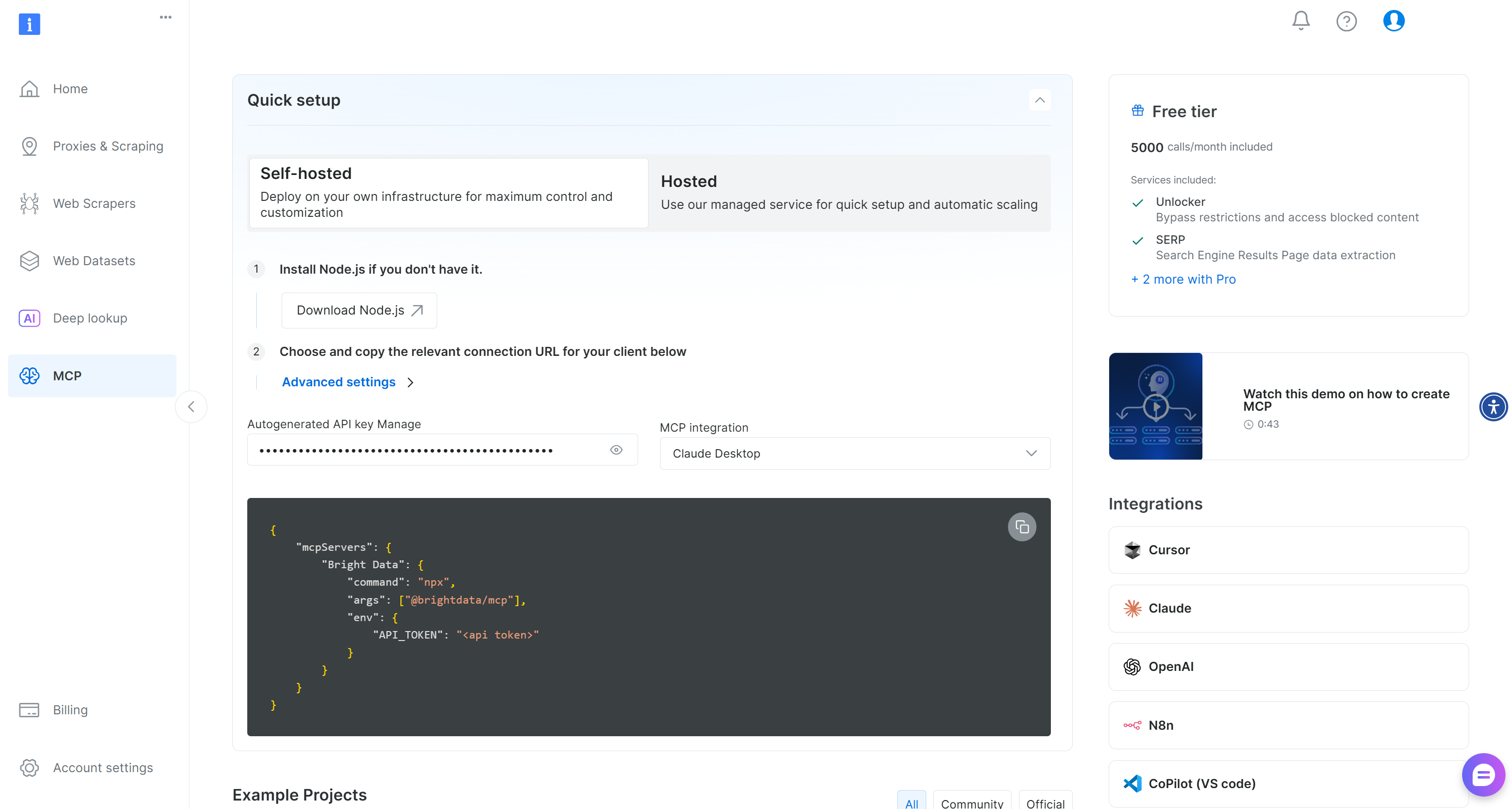
よりガイドに沿った方法をご希望の場合は、以下の手順に従ってください。
まず、Bright Data APIキーを生成し、安全な場所に保管してください(すぐに必要になります)。このチュートリアルでは、統合プロセスを大幅に簡略化するため、APIキーに管理者権限があるものと仮定します。
ターミナルを開き、@brightdata/mcpパッケージを使用してWeb MCPをグローバルにインストールします:
npm install -g @brightdata/mcpローカルMCPサーバーが動作していることを、以下のBashコマンドで確認してください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpWindows PowerShell では同等の操作で実行できます:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを実際の Bright Data API トークンに置き換えてください。上記の2つのコマンドは、必要なAPI_TOKEN環境変数を設定し、ローカルで MCP サーバーを起動します。
成功した場合、以下のようなログが表示されます:

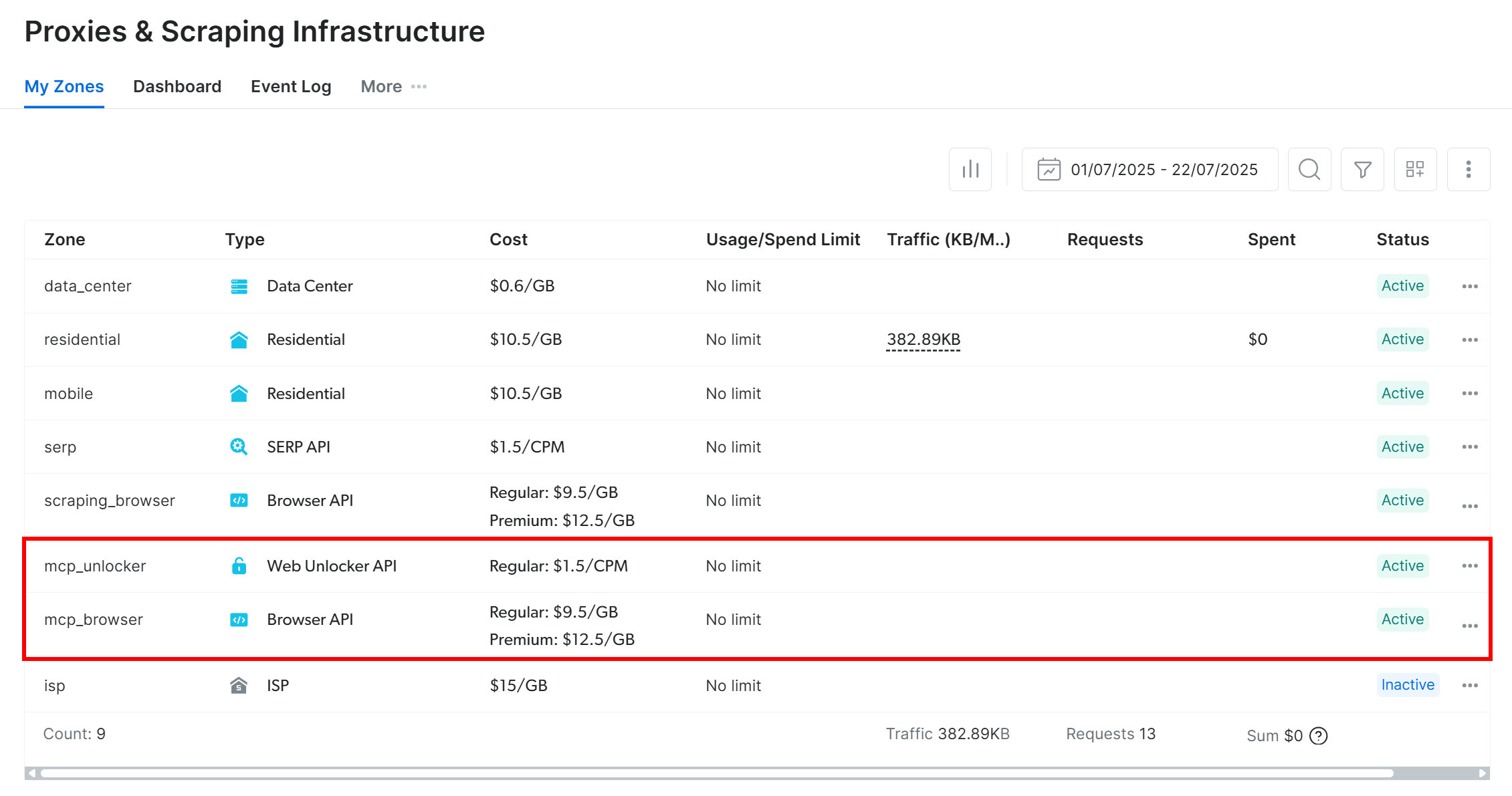
初回起動時、@brightdata/mcpパッケージはBright Dataアカウントに以下の2つのデフォルトゾーンを自動設定します:
mcp_unlocker:Web Unlocker用ゾーンmcp_browser:ブラウザAPI用のゾーン。
これらの2つのゾーンは、Web MCPが60以上の全ツールを公開するために必須です。
上記ゾーンが作成されたことを確認するには、Bright Dataダッシュボードにログインしてください。「プロキシとスクレイピングインフラ」ページに移動すると、テーブルに2つのゾーンがリストされているはずです:
APIトークンに管理者権限がない場合、これらのゾーンは自動設定されません。この場合、パッケージのGitHubページに記載されている手順に従い、ダッシュボードで手動作成し環境変数で名前を指定してください。
注:デフォルトでは、Web MCPサーバーはsearch_engineとscrape_as_markdownツールのみを公開しています(これらは無料でも利用可能です!)。ブラウザ自動化や構造化データ抽出のための高度なツールを利用するには、Proモードを有効にする必要があります。
Proモードを有効化するには、MCPサーバー起動前に環境変数PRO_MODE=trueを設定してください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、PowerShellでは:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp重要: Proモードを選択すると、60以上の全ツールが利用可能になります。ただし、Proモードは無料プランに含まれず、追加料金が発生します。
完了!Web MCPサーバーがマシン上で実行可能であることを確認しました。Langchainが自動的に起動して接続するよう設定するため、サーバープロセスを終了させてください。
ステップ #4: Langchain MCP アダプターによる Web MCP 接続の初期化
まず、Langchain MCP Adaptersパッケージから必要なライブラリをインポートします:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_toolsローカルWeb MCPサーバーを実行できる環境では、SSEやStreamable HTTPではなく stdio(標準入出力)経由で接続するのが最も簡単です。つまり、AIアプリケーションがMCPサーバーをサブプロセスとして起動し、標準入出力で直接通信するよう設定します。
そのためには、次のようにStdioServerParameters設定オブジェクトを定義します:
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
)この設定は、Web MCP をテストするために以前手動で実行したコマンドを反映しています。アプリケーションはこの設定を使用して、必要な環境変数(PRO_MODEはオプションです)と共にnpxを実行し、Web MCP をサブプロセスとして起動します。
次に、MCPセッションを初期化し、公開されているツールをロードします:
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await load_mcp_tools(session)load_mcp_tools()関数が主要な処理を担当します:MCPツールを自動的にLangchainおよびLangGraph互換ツールに変換します。
素晴らしい!これでLangGraphエージェント定義に渡す準備が整ったツールのリストが得られました。
ステップ #5: ReAct エージェントの作成と質問
内側のwithブロック内で、LLM エンジンと MCP ツールのリストを使用してcreate_react_agent() で LangGraph エージェントを作成します:
agent = create_react_agent(llm, tools) 注: ツールを扱う際は、ReActアーキテクチャに従うAIエージェントに依存するのが最善です。このアプローチにより、プロセスをより徹底的に推論し、タスクを完了するための適切なツールを選択できるようになるためです。
LangGraphからcreate_react_agent()をインポート:
from langgraph.prebuilt import create_react_agent次にAIエージェントに質問します。応答全体を待って一括出力する代わりに、出力を直接コンソールにストリーミングする方が効果的です。ツール使用には時間がかかるため、エージェントがタスクを処理する過程で有用なフィードバックが得られます:
input_prompt = """
ZoomInfoの企業ページ 'https://www.zoominfo.com/c/nike-inc/27722128' からデータをスクレイピングしてください。その後、取得したデータを用いて、企業の主要情報を要約した簡潔なMarkdown形式のレポートを作成してください。
"""
# エージェントの応答をストリーム出力
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()この例では、エージェントに以下の処理を依頼します:
“ZoomInfoの企業ページ(‘https://www.zoominfo.com/c/nike-inc/27722128’)からデータをスクレイピングしてください。その後、取得したデータを用いて、企業の主要情報を要約した簡潔なレポートをMarkdown形式で作成してください。”
注: ZoomInfo企業ページURLはNikeを指していますが、任意の企業に変更したり、プロンプト全体を別のデータ取得シナリオに合わせて修正したりできます。
これは本章の冒頭で説明した内容を完全に再現しています。重要なのは、このタスクがエージェントにWeb MCPツールを活用して実データを取得・構造化させる点です。つまり統合機能の完璧な実証となるのです!
素晴らしい!Web MCP + Langchain LangGraph AIエージェントの準備が整いました。あとは実際に動作を確認するだけです。
ステップ #6: 全てを統合する
agent.pyの最終コードは以下の通りです:
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # OpenAI APIキーに置き換えてください
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# LLMエンジンの初期化
llm = ChatOpenAI(
model="gpt-5-mini",
)
# ローカルのBright Data Web MCPサーバーインスタンスへの接続設定
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Bright Data APIキーに置き換えてください
"PRO_MODE": "true"
}
)
# MCPサーバーに接続
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# MCPクライアントセッションを初期化
await session.initialize()
# MCPツールを取得
tools = await load_mcp_tools(session)
# ReActエージェントを作成
agent = create_react_agent(llm, tools)
# エージェントタスクの説明
input_prompt = """
ZoomInfoの企業ページ 'https://www.zoominfo.com/c/nike-inc/27722128' からデータをスクレイピングしてください。取得したデータを用いて、企業の主要情報を要約した簡潔なMarkdown形式のレポートを作成してください。
"""
# エージェントの応答をストリーム出力
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())すごい!Langchain MCPアダプターのおかげで、たった約50行のコードでMCP統合済みのReActエージェントを構築できました。
エージェントを起動するには:
python agent.pyターミナルにはすぐに以下が表示されるはずです:

これはLangGraphエージェントが意図したプロンプトを受け取ったことを証明します。 その後、LLMエンジンがプロンプトを処理し、タスクを完了するために呼び出すべきWeb MCPの正しいMCPツールが「web_data_zoominfo_company_profile」であると即座に判断します。具体的には、プロンプトから推測された正しいZoomInfo URL引数(https://www.zoominfo.com/c/nike-inc/27722128)を指定してツールを呼び出します。
ツール呼び出しの結果は以下の通りです:

web_data_zoominfo_company_profileツールは、ZoomInfoの企業プロファイルデータをJSON形式で返します。これはGPT-5 miniモデルによる幻覚(虚構)コンテンツではないことに注意してください!
代わりに、データはBright Dataインフラストラクチャで利用可能なZoomInfoスクレイパーから直接取得されます。これは、選択されたweb_data_zoominfo_company_profileWeb MCPツールによってバックグラウンドで呼び出されます。
ZoomInfoスクレイパーは全てのボット対策機能を回避し、企業の公開プロフィールページからリアルタイムでデータを収集し、構造化されたJSON形式で返します。実際のZoomInfoページで確認できるように、取得されるデータは正確で対象ページから直接取得されています:
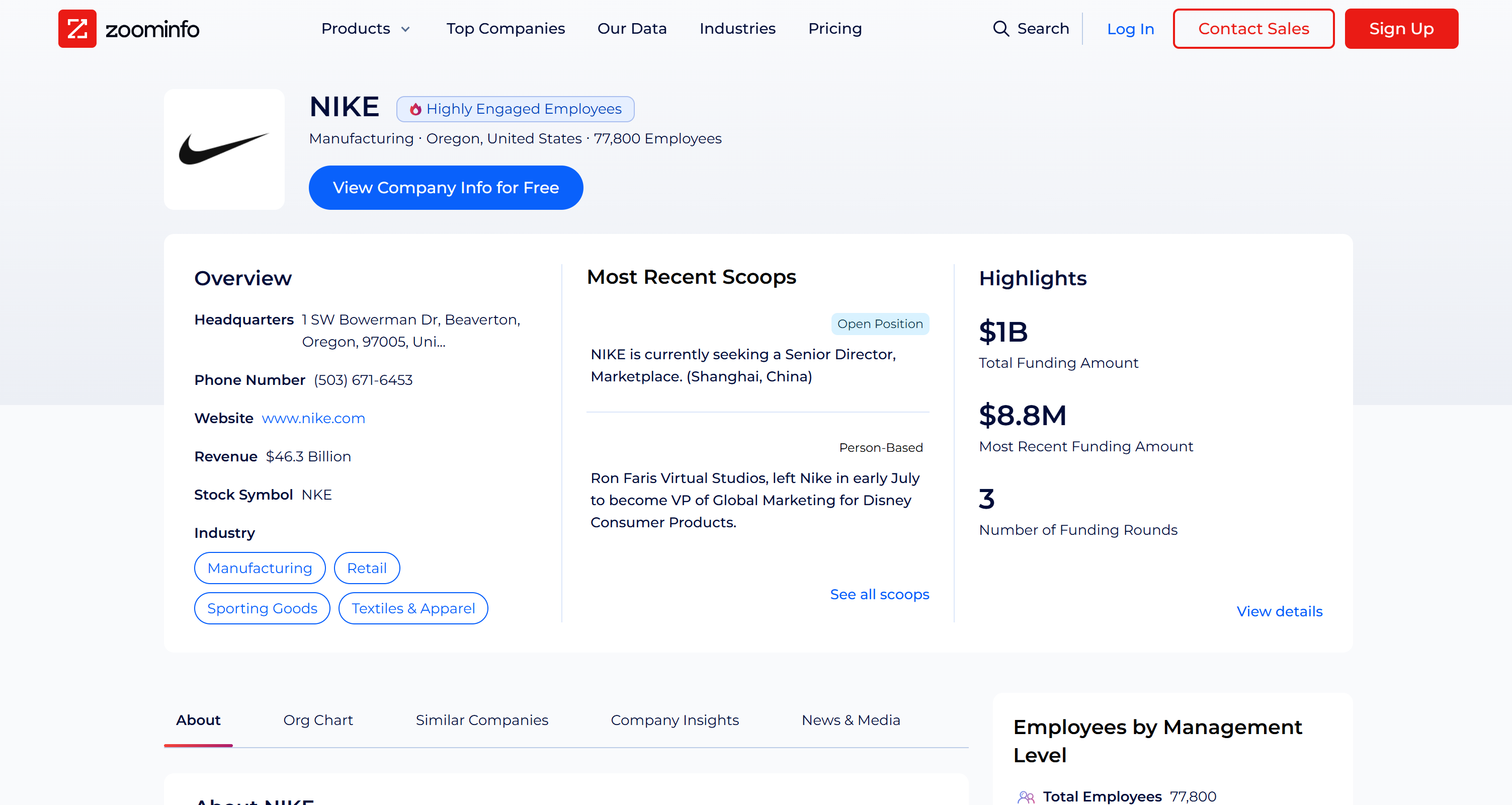
ZoomInfoのスクレイピングは、高度なCAPTCHAを含むアンチスクレイピング技術のため容易ではありません。したがって、これは任意のLLMが実行できるタスクではありません。むしろ、専用のWebデータ取得ツールにアクセスできるエージェントのみが実行可能です。
このシンプルな例が、LangchainとBright Data Web MCPの連携の威力を示しています!
ZoomInfoの企業プロフィールデータに基づき、エージェントが生成する根拠に基づくMarkdownレポートは以下のような形式になります:
# NIKE, Inc. — 会社概要
## 概要
NIKE, Inc.は、スポーツシューズ、アパレル、用具、アクセサリーを世界中で設計、開発、マーケティング、販売しています。
## 基本情報
- **名称:** NIKE, Inc.
- **ウェブサイト:** [https://www.nike.com/](https://www.nike.com/)
- **本社所在地:** 1 SW Bowerman Dr, Beaverton, OR 97005, United States
- **電話番号:** (503) 671-6453
- **株式ティッカー:** NYSE: NKE
- **収益:** 463億ドル(報告値)
- **従業員数:** 77,800名
- **業種:** 製造業; 小売業; スポーツ用品; 繊維・アパレル; アパレル・アクセサリー小売
- **ZoomInfoタイムスタンプ:** 2026-09-02T08:47:19.789Z
## 財務・資金調達
- **報告売上高:** 463億ドル
- **資金調達(ZoomInfo):** 3回のラウンドで総額10億ドル *(数値は過去のデータや非公開データに基づく場合あり;ナイキは上場企業)*
## 従業員数と企業文化
- **従業員総数:** 77,800名
- **従業員内訳 (ZoomInfo):**
- Cレベル: 23名
- 副社長: 約529名
- 部長: 約6,115名
- マネージャー: 約13,289名
- 非管理職: 約29,578名
- **eNPSスコア:** 20 *(推奨者 50% / 中立者 20% / 批判者 30%)*
## 経営陣(抜粋/組織図より)
- エイミー・モンターニュ — 社長
- ニコール・グラハム — 執行副社長兼最高マーケティング責任者
- チェリアン・ジェイコブ — 最高情報責任者
- ムゲ・ドガン — 執行副社長兼最高技術責任者
- クリス・ジョージ — 副社長兼最高財務責任者(地域担当...)
- サラ・メンサ — ジョーダンブランド社長
> *注:ZoomInfoプロファイルでは、取得データ内にCEOの記載が一切見られなかった。*
## 技術・ツール(例)
- SolidWorks(ダッソー・システムズ)
- EventPro(プロフィット・システムズ)
- Microsoft IIS(マイクロソフト)
- SAP Sybase RAP(SAP)
## 最近のスクープ/メディアハイライト(要約)
- **採用情報:** シニアディレクター、マーケットプレイス(上海)。
- **人事異動:** ロン・ファリス氏がナイキを退社し、ディズニー・コンシューマー・プロダクツ(グローバルマーケティング担当副社長)に加入。
- **事業動向:** 関税・地政学的な逆風が短期業績に影響。同社は緩和策と「即効性のある対策」を実施中。
- **人員削減:** 企業部門で小規模な人員削減(従業員の約1%)の報告あり。
## 比較対象企業(例)
- ANTAスポーツプロダクツ
- アディダスAG
- フットロッカー
- ゲス
- ティンバーランド
- ジェネスコ
## 連絡先・情報提供窓口
- **コーポレートサイト:** [https://www.nike.com/](https://www.nike.com/)
- **標準的なメールアドレス形式(確認済み):** `[email protected]`(関連ブランドは `@converse.com` も使用)
## データソース
- ZoomInfoのNIKE, Inc.企業プロファイル
[https://www.zoominfo.com/c/nike-inc/27722128](https://www.zoominfo.com/c/nike-inc/27722128)
**スナップショット日時:** 2026-09-02T08:47:19.789ZMarkdownビューアで表示すると、次のようになります:
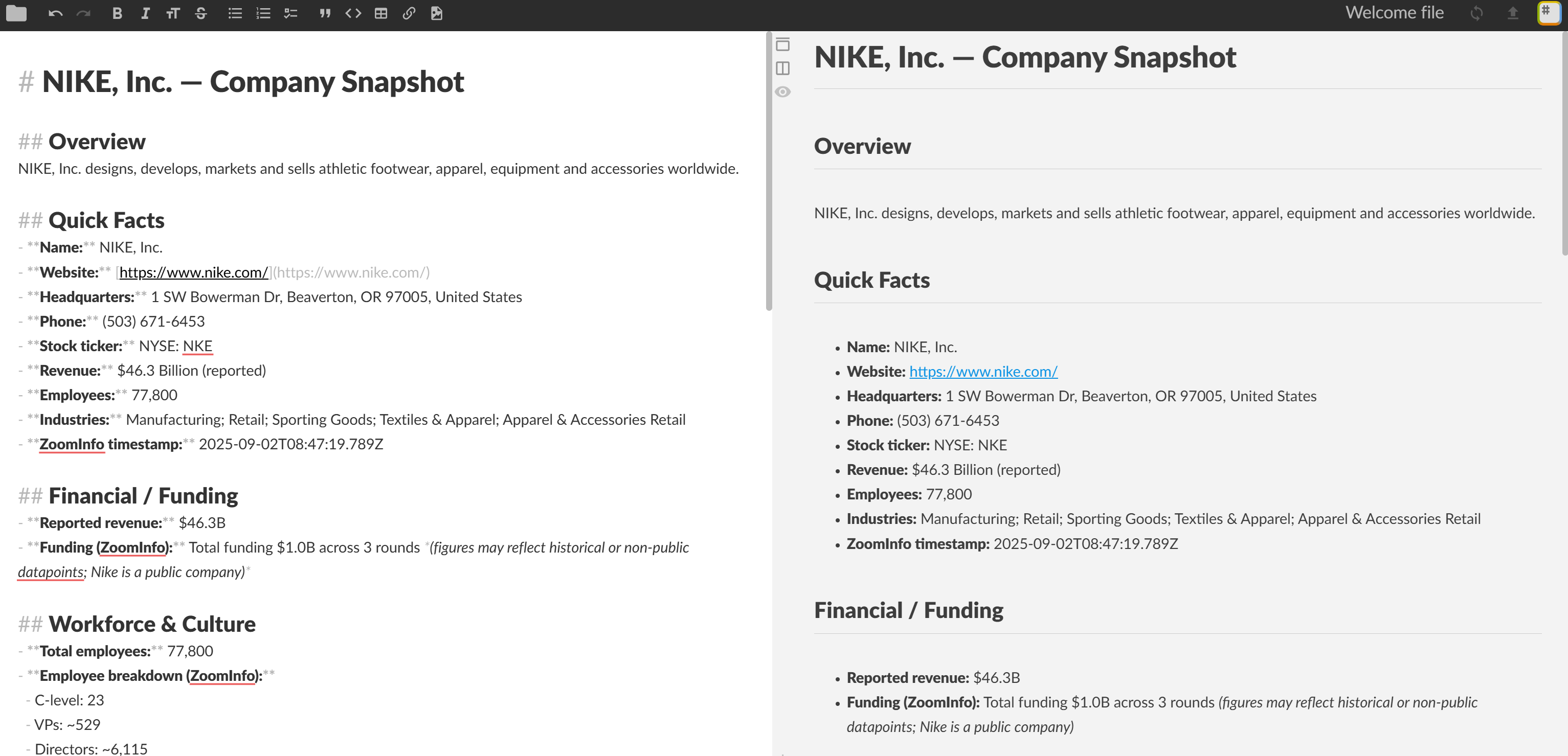
さあ、どうぞ!ReActエージェントがタスクに適したツールを選択し、ZoomInfoから抽出した実在企業のデータを用いて情報豊富なMarkdownレポートを生成しました。
Web MCPの統合がなければ、これは実現できませんでした。LangchainではMCPアダプターライブラリにより、この統合がサポートされています。
次のステップ
ここで開発したLangchain MCP搭載エージェントはシンプルながら機能的な例です。本番環境対応にするには、以下の次のステップを検討してください:
- REPLの実装: リアルタイムでエージェントと対話できるようにREPL(Read-Eval-Print Loop)を追加します。コンテキストを維持し過去のやり取りを追跡するため、メモリ層を導入します(一時データベースまたは永続ストレージへの保存が理想的です)。
- 出力のファイル保存: 出力ロジックを修正し、生成された出力(例: レポート)をローカルファイルに保存できるようにします。これにより、他のチームメンバーと結果を簡単に共有できます。
- エージェントのデプロイ:Langchainドキュメントで説明されている通り、AIエージェントをクラウド、ハイブリッドクラウド環境、またはセルフホスト型オプションでデプロイします。
様々なプロンプトでLangchain + Web MCPエージェントを試行し、その他の高度なエージェント駆動型ワークフローを探求してください!
まとめ
本記事では、Bright DataのWeb MCP(無料プランで利用可能!)を活用し、LangGraphでAIエージェントを構築する方法を学びました。これはLangchainとLangGraphの両エコシステムにMCPサポートを追加するLangchain MCPアダプターライブラリによって実現されています。
本記事で示したタスクは一例に過ぎませんが、同じ統合を活用してマルチエージェント構成を含むより複雑なワークフローを設計できます。Web MCPが提供する60以上のツールとBright DataのAIインフラストラクチャの全ソリューションを活用すれば、AIエージェントがライブWebデータを効果的に取得・検証・変換できるようになります。
Bright Dataアカウントを無料で作成し、AI対応のウェブデータソリューションを今すぐお試しください!




