

このガイドでは、以下のことを学びます:
- ウェブスクレイピングがLLMを実世界データで強化する優れた手法である理由
- LangChainワークフローにおけるスクレイピングデータの利点と課題
- LangChainへのスクレイピング統合を簡素化するライブラリ
- ステップバイステップチュートリアルで完全なLangChainウェブスクレイピング統合を作成する方法
さあ、始めましょう!
ウェブスクレイピングでLLMアプリケーションを強化する
ウェブスクレイピングとは、ウェブページからデータを取得する手法です。このデータは、LLM(大規模言語モデル)と統合することで、RAG(検索拡張生成)アプリケーションの基盤として活用できます。
RAGシステムには、購入やオンラインダウンロードが可能な静的データセットでは容易に入手できない、豊富で最新かつリアルタイム、特定分野向け、あるいは大規模なデータへのアクセスが必要です。ウェブスクレイピングは、ニュース記事、商品リスト、ソーシャルメディアなど様々なソースから抽出された構造化情報を提供することで、このギャップを埋めます。
LLMトレーニングデータの収集に関する記事で詳細をご覧ください。
LangChainにおけるスクレイピングデータ活用のメリットと課題
LangChainはAI駆動ワークフロー構築のための強力なフレームワークであり、LLMと多様なデータソースの統合を簡素化します。LLMとリアルタイムのドメイン固有知識を組み合わせることで、データ分析、要約、質問応答に優れています。しかし、高品質なデータの取得は常に課題です。
ウェブスクレイピングはこの問題に対処できますが、ボット対策、CAPTCHA、動的ウェブサイトなど、いくつかの課題が伴います。コンプライアンスに準拠した効率的なスクレイパーの維持も、時間と技術的な複雑さを要します。詳細は、当社のアンチスクレイピング対策ガイドをご覧ください。
こうした障壁は、リアルタイムデータに依存するAIアプリケーションの開発を遅らせる可能性があります。解決策は?Bright DataのWeb Scraper APIです。これは数百のウェブサイト向けにウェブスクレイピングエンドポイントを提供する、すぐに使えるツールです。
IPローテーション、CAPTCHAの解決、JavaScriptレンダリングといった高度な機能により、Bright Dataがデータ抽出を自動化。これにより、信頼性が高く効率的、かつ手間のかからないデータ収集が保証され、すべてシンプルなAPI呼び出しでアクセス可能です。
LangChain Bright Data Tools
Bright DataのウェブスクレイピングAPIやその他のスクレイピングツールをLangChainワークフローに直接統合することも可能ですが、その場合、カスタムロジックや定型コードが必要になります。時間と労力を節約するには、公式のLangChain Bright Data統合パッケージlangchain-brightdataを利用することをお勧めします。
このパッケージにより、LangChainワークフロー内でBright Dataのサービスに接続できます。具体的には以下のクラスを公開しています:
BrightDataSERP: Bright DataのSERP APIと連携し、地域ターゲティングを伴う検索エンジンクエリを実行します。BrightDataUnblocker: Bright DataのWeb Unlockerと連携し、地理的制限やボット対策システムで保護されたウェブサイトにアクセスします。BrightDataWebScraperAPI: Bright DataのWebスクレイパーAPIと連携し、様々なドメインから構造化データを抽出します。
このチュートリアルでは、BrightDataWebScraperAPIクラスの使用に焦点を当てます。さっそく見ていきましょう!
Bright DataによるLangChainウェブスクレイピング:ステップバイステップガイド
このセクションでは、LangChain によるウェブスクレイピングワークフローの構築方法を学びます。目標は、Bright Data の Web Scraper API を使用して LinkedIn プロフィールからコンテンツを取得し、OpenAI を活用して候補者が特定の職務に適しているかどうかを評価することです。
参考として私の公開LinkedInプロフィールページを使用しますが、他のLinkedInプロフィールでも同様に動作します:
注:ここで構築するのは単なる一例です。これから書くコードは様々なシナリオに容易に適応可能です。つまり、LangChainの追加機能で拡張することもできます。例えば、SERPデータに基づくRAGチャットボットを作成することも可能です。
以下の手順に従って始めましょう!
前提条件
このチュートリアルを進めるには、以下の環境が必要です:
- Python 3+ がマシンにインストールされていること
- OpenAI APIキー
- Bright Dataアカウント
これらのいずれかが不足していても心配はいりません。PythonのインストールからOpenAIおよびBright Dataの認証情報の取得まで、全プロセスをガイドします。
ステップ #1: プロジェクト設定
まず、お使いのマシンにPython 3がインストールされているか確認してください。インストールされていない場合は、ダウンロードしてインストールしてください。
プロジェクト用フォルダを作成するため、ターミナルで次のコマンドを実行してください:
mkdir langchain-scrapinglangchain-scrapingフォルダにはPython LangChainスクレイピングプロジェクトが格納されます。
次に、プロジェクトフォルダに移動し、その内部でPython仮想環境を初期化します:
cd langchain-scraping
python3 -m venv venv注: Windowsではpython3の代わりにpythonを使用してください。
お気に入りのPython IDEでプロジェクトディレクトリを開きます。PyCharm Community Editionや Python拡張機能付きのVisual Studio Codeが適しています。
langchain-scraping ディレクトリ内にscript.pyファイルを追加します。これは空の Python スクリプトですが、すぐに LangChain によるウェブスクレイピングロジックが記述されます。
IDEのターミナルで(Linux/macOSの場合)、以下のコマンドで仮想環境をアクティブ化します:
source venv/bin/activateWindowsの場合は以下を実行:
venv/Scripts/activate素晴らしい!これで準備は完了です。
ステップ #2: 必要なライブラリのインストール
Python LangChainスクレイピングプロジェクトは以下のライブラリに依存しています:
python-dotenv:.envファイルから環境変数をロードします。Bright DataとOpenAIのAPIキー管理に使用されます。langchain-openai:OpenAISDKを介したLangChainのOpenAI統合ライブラリ。langchain-brightdata: Bright DataスクレイピングサービスとのLangChain統合。
アクティブ化された仮想環境で、以下のコマンドで全ての依存関係をインストールします:
pip install python-dotenv langchain-openai langchain-brightdata素晴らしい!これでスクレイピングロジックを記述する準備が整いました。
ステップ #3: プロジェクトの準備
script.pyに以下のインポートを追加:
from dotenv import load_dotenv次に、プロジェクトフォルダ内に.envファイルを作成し、すべての認証情報を保存します。現在のプロジェクトファイル構造は次のようになります:

script.pyに次の行を追加し、python-dotenvに .envから環境変数をロードするよう指示します:
load_dotenv()よし! Bright DataのWebスクレイパーAPIソリューションを設定しましょう。
ステップ #4: Web スクレイパー API の設定
本記事の冒頭で述べたように、ウェブスクレイピングにはいくつかの課題が伴います。幸いなことに、Bright DataのWeb Scraper APIのようなオールインワンソリューションを利用すれば、作業は大幅に簡素化されます。これらのAPIを使用すれば、120以上のウェブサイトからパース済みコンテンツを簡単に取得できます。
langchain_brightdata を使用して LangChain で Web Scraper API を設定するには、以下の手順に従ってください。Bright Data のウェブスクレイピングソリューションに関する一般的な紹介については、公式ドキュメントを参照してください。
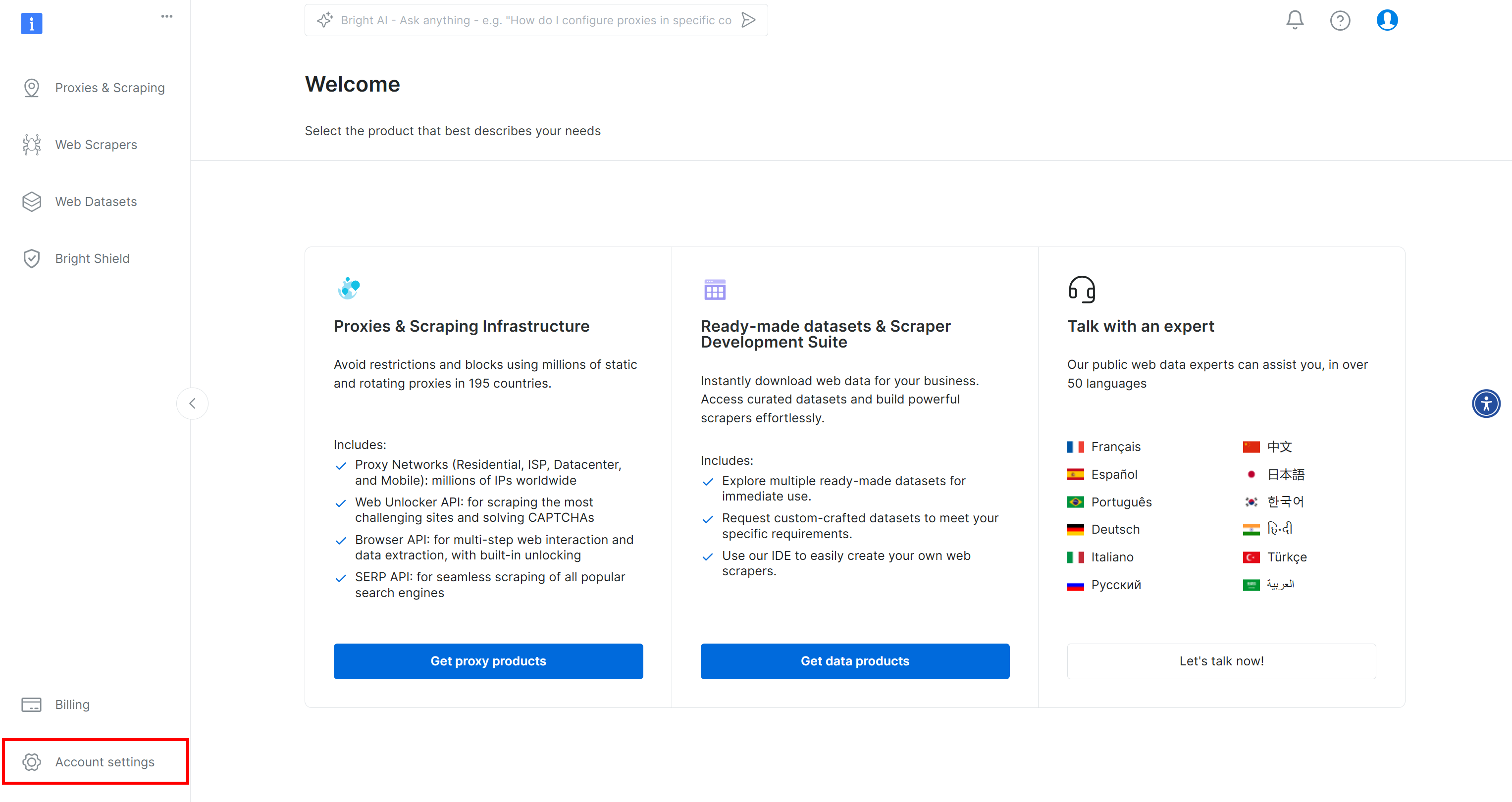
まだお持ちでない場合は、Bright Dataアカウントを作成してください。ログイン後、アカウントダッシュボードが表示されます。左下にある「アカウント設定」ボタンをクリックします:
「アカウント設定」ページで、既にBright Data APIトークンを作成済みの場合は「…」をクリックし、「トークンをコピー」オプションを選択してください:
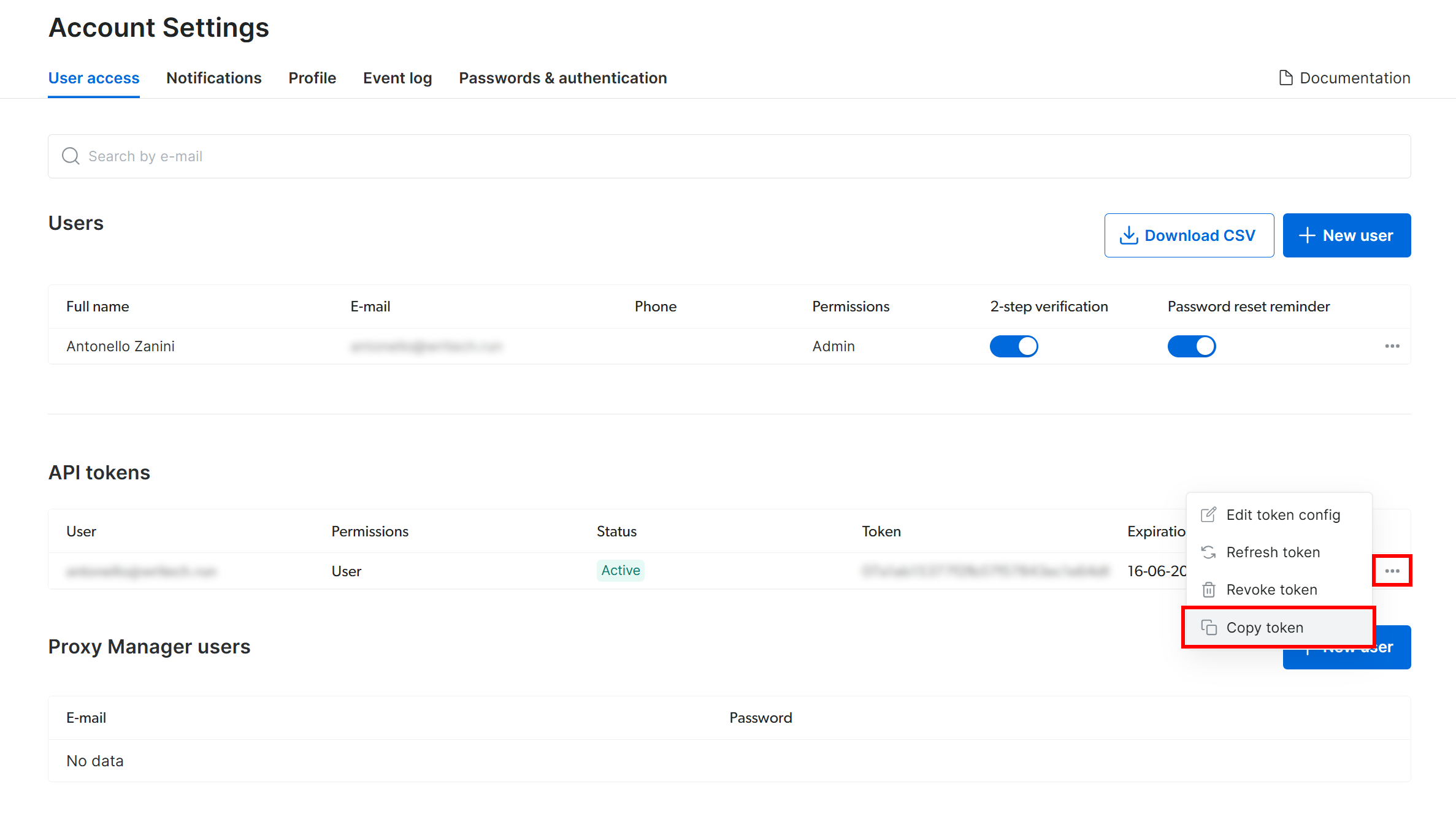
まだ作成していない場合は、「トークンを追加」ボタンをクリックしてください:
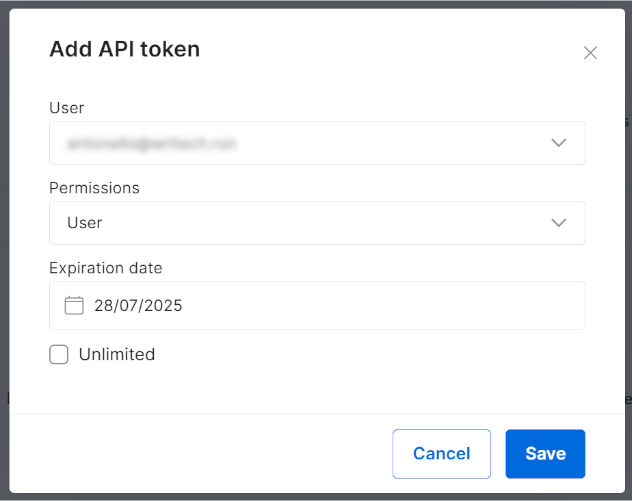
以下のモーダルが表示されます。Bright Data APIトークンを設定し、「保存」ボタンを押してください:
新しいAPIトークンが発行されます:
Bright Data APIキーの値をコピーしてください。
.envファイル内で、この情報をBRIGHT_DATA_API_KEY環境変数として保存します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"<YOUR_BRIGHT_DATA_API_KEY>をモーダル/テーブルからコピーした値で置き換えてください。
次に、script.py でlangchain_brightdata をインポートします:
from langchain_brightdata import BrightDataWebScraperAPIlangchain_brightdata は自動的にBRIGHT_DATA_API_KEY環境変数から Bright Data API キーを読み取ろうとするため、これ以上の操作は不要です。
これで完了です!LangChainでWebスクレイパーAPIが使用可能になりました。
ステップ #5: Bright Data を使用したウェブスクレイピング
langchain_brightdata は BrightDataWebScraperAPIクラスを通じて Bright Data の Web スクレイパー API との連携をサポートしています。
このクラスの動作の概要は以下の通りです:
- 設定済みのウェブスクレイパーAPIに対して同期リクエストを発行し、スクレイピング対象ページのURLを受け取ります。
- クラウドベースのスクラッピングタスクが起動され、指定されたURLからデータを取得・パースします。
- ライブラリはスクレイピングタスクの終了を待機し、スクレイピングされたデータをJSON形式で返します。
LangChainワークフローにウェブスクレイピングを統合するには、以下のコードで再利用可能な関数を定義します:
def get_scraped_data(url, dataset_type):
# LangChain Bright Data スクレイパー API 統合クラスの初期化
web_scraper_api = BrightDataWebScraperAPI()
# Web Scraper APIに接続して対象データを取得
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return resultsこの関数は以下の引数を受け取ります:
url: データを取得するページのURL。dataset_type: ページからデータを抽出するために使用するウェブスクレイパーAPIのタイプを指定します。例えば、"linkedin_person_profile"は、指定された公開LinkedInプロフィールURLからデータをスクレイピングするようウェブスクレイパーAPIに指示します。
この例では、以下のように呼び出します:
url = "https://linkedin.com/in/antonello-zanini"
scraped_data = get_scraped_data(url, "linkedin_person_profile")scraped_data には以下のようなデータが含まれます:
{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
# 簡略化のため省略...
"about": "私はフリーランスのソフトウェアエンジニア、テクニカルエディター、テクニカルライターとして数百件の...",
"current_company": {
"name": "Freelance"
},
"current_company_name": "Freelance",
# 省略...
"languages": [
{
"title": "イタリア語",
"subtitle": "母語またはバイリンガルレベル"
},
{
"title": "英語",
"subtitle": "完全な業務レベル"
},
{
"title": "スペイン語",
"subtitle": "完全な業務レベル"
}
],
"recommendations_count": 32,
"recommendations": [
# 省略...
],
"posts": [
# 省略...
],
"activity": [
# 省略...
],
# 省略...
}詳細には、対象LinkedInプロフィールページの公開版で入手可能な全情報を格納しています—ただしJSON形式で構造化されています。このデータを取得するため、Web Scraper APIはあらゆるボット対策やウェブスクレイピング対策機能を回避しました。
すごい!これでLangChainでのウェブスクレイピングにBright Data WebスクレイパーAPIを使う方法を習得しました。
ステップ #6: OpenAIモデルの使用準備
この例では、LangChain内でのLLM統合にOpenAIモデルを利用します。これらのモデルを使用するには、環境変数にOpenAI APIキーを設定する必要があります。
したがって、.envファイルに次の行を追加してください:
OPENAI_API_KEY="<YOUR_OPEN_API_KEY>"<YOUR_OPENAI_API_KEY>を実際のOpenAI API キーに置き換えてください。取得方法がわからない場合は、公式ガイドに従ってください。
次に、script.py でlangchain_openai を以下のようにインポートします:
from langchain_openai import ChatOpenAIこれ以外の操作は不要です。langchain_openaiは 自動的にOPENAI_API_KEY環境変数からOpenAIAPIキーを検索します。
素晴らしい! LangChainスクレイピングスクリプトでOpenAIモデルを使用する準備が整いました。
ステップ #7: LLMプロンプトを生成する
スクレイピングしたデータを受け取り、LLM用のプロンプトを生成するf-string変数を定義します。この場合、プロンプトには人事リクエストとスクレイピングした候補者データが含まれます:
prompt = f"""
"この候補者はリモート勤務のソフトウェアエンジニア職に適していると思いますか?その理由を150語以内で回答してください。
候補者情報:
'{scraped_data}'
"""この例では、LangChainを使用して人事アドバイザーAIワークフローを構築しています。Web Scraper API(120以上のドメインをサポート)とLLMの柔軟性により、このアプローチを他の多様なLangChainワークフローに応用することが容易です。
💡 アイデア:さらに柔軟性を高めるには、プロンプトを.envファイルから読み込むことを検討してください。
現在の例における完全なプロンプトは以下の通りです:
この候補者はリモート勤務のソフトウェアエンジニア職に適任だと思いますか?その理由を150語以内で回答してください。
候補者情報:
'{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
// 省略...
"about": "私はフリーランスのソフトウェアエンジニア、テクニカルエディター、テクニカルライターとして数百件の...",
},
[省略...]'これをChatGPTに渡せば、期待通りの結果が得られるはずです:
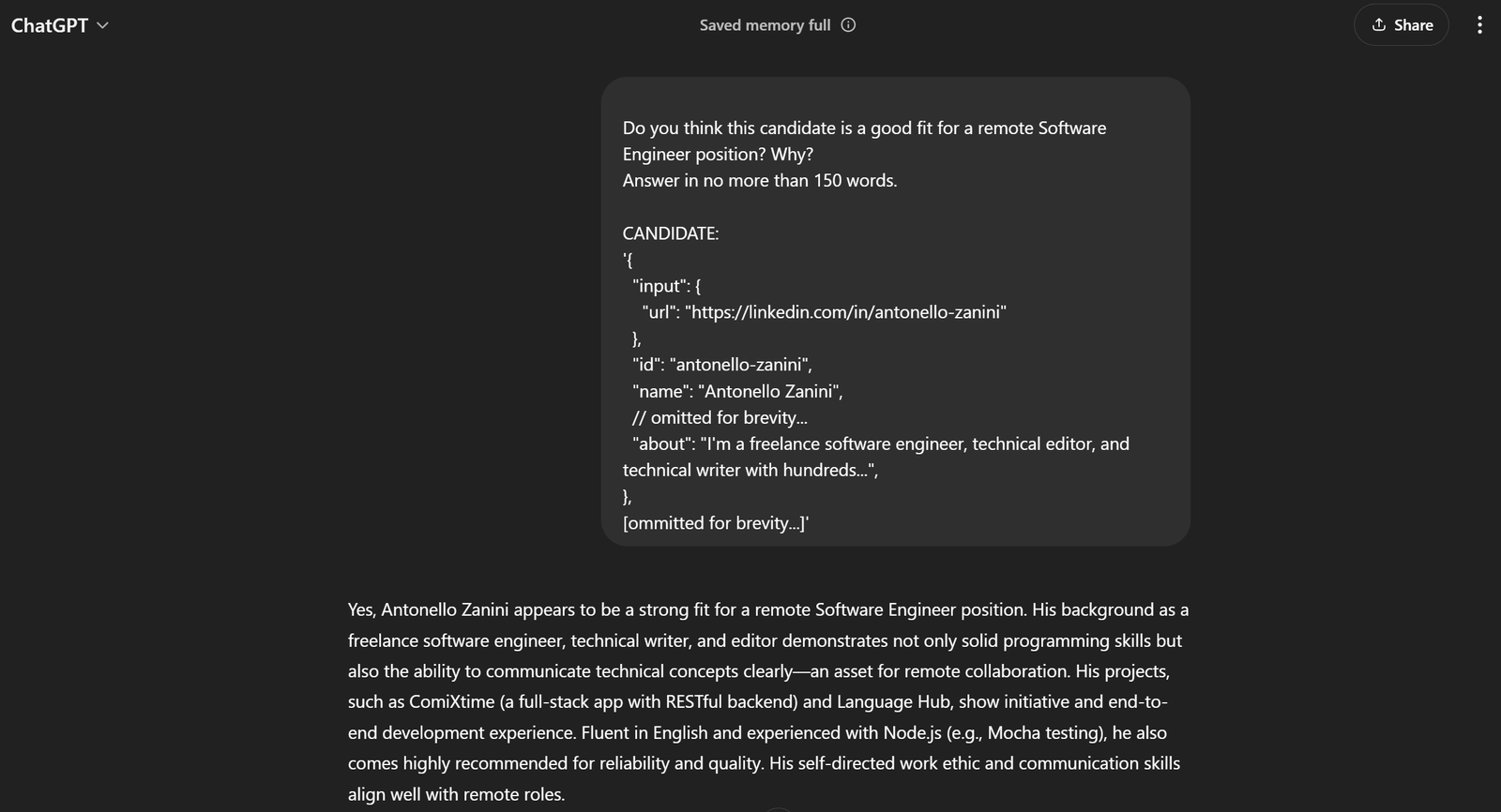
これでプロンプトが完璧に機能することがわかります!
ステップ #8: OpenAIの統合
先に生成したプロンプトを、GPT-4o miniAIモデルで設定されたChatOpenAILangChainオブジェクトに渡します:
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)AI処理終了時、response.contentには前手順でChatGPTが生成した評価結果と同様の内容が含まれるはずです。そのテキスト応答は以下で取得できます:
evaluation = response.contentすごい!LangChainによるウェブスクレイピングロジックが完成しました。
ステップ #9: AI処理済みデータのエクスポート
次に、選択したAIモデルがLangChain経由で生成したデータを、JSONファイルなど人間が読める形式でエクスポートします。
まず、必要なデータで辞書(ディクショナリ)を初期化します。次に、以下のようにエクスポートしてJSONファイルとして保存します:
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)Python標準ライブラリのjsonをインポートします:
import jsonおめでとうございます!スクリプトの準備が完了しました。
ステップ #10: ログの追加
ウェブスクレイピング AIとChatGPT分析を用いたスクレイピング処理には時間がかかる場合があります。これはサードパーティサービスからのデータ取得・処理に伴うオーバーヘッドによる正常な動作です。そのため、スクリプトの進捗を追跡するログ記録を含めることが推奨されます。
スクリプトの主要なステップにprint文を追加することで実現します。例:
url = "https://linkedin.com/in/antonello-zanini"
print(f"{url}からWeb Scraper APIでデータをウェブスクレイピング中...")
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("データのウェブスクレイピングに成功しました")
print("AIプロンプトを作成中...")
prompt = f"""
"この候補者はリモート勤務のソフトウェアエンジニア職に適任だと思いますか?その理由を150語以内で回答してください。
候補者情報:
'{scraped_data}'
"""
print("プロンプト作成完了n")
print("プロンプトをChatGPTに送信中...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
evaluation = response.content
print("ChatGPTからの応答を受信しました")
print("データをJSON形式でエクスポート中...")
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Data exported to '{file_name}'")LangChainのウェブスクレイピングワークフローの各ステップが明確にログ記録されることに注意してください。ターミナルでの実行が追跡しやすくなります。
ステップ #11: 全てを統合する
最終的なscript.pyファイルには以下を含める必要があります:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_openai import ChatOpenAI
import json
# .envファイルから環境変数をロード
load_dotenv()
def get_scraped_data(url, dataset_type):
# LangChain Bright DataスクレイパーAPI統合クラスの初期化
web_scraper_api = BrightDataWebScraperAPI()
# Web Scraper API に接続して対象データを取得
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results
# 指定されたウェブページからコンテンツを取得
url = "https://linkedin.com/in/antonello-zanini"
print(f"{url}からWeb Scraper APIでデータをスクレイピング中...")
# Web Scraper APIを使用してスクレイピングされたデータを取得
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("データのスクレイピングに成功しましたn")
print("AIプロンプトを作成中...")
# スクレイピングしたデータをコンテキストとしてプロンプトを定義
prompt = f"""
"この候補者はリモート勤務のソフトウェアエンジニア職に適していると思いますか?その理由を150語以内で回答してください。
CANDIDATE:
'{scraped_data}'
"""
候補者:
'{scraped_data}'
"""
print("プロンプト作成完了")
# ChatGPTにプロンプトのタスクを実行させる
print("ChatGPTにプロンプト送信中...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
# AIの結果を取得
evaluation = response.content
print("ChatGPTからの応答を受信しましたn")
print("データをJSONにエクスポート中...")
# 生成されたデータをJSONにエクスポート
export_data = {
"url": url,
"evaluation": evaluation
}
# 出力辞書をJSONファイルに書き込む
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"データを'{file_name}'にエクスポートしました")信じられますか?わずか50行ほどのコードで、AIベースのLangChainウェブスクレイピングスクリプトを構築しました。
動作確認は次のコマンドで:
python3 script.pyWindowsの場合は:
python script.pyターミナルの出力は次のようになります:
https://linkedin.com/in/antonello-zanini... の Web Scraper API によるデータスクレイピング...
データのスクレイピングに成功しました
AI プロンプトを作成中...
プロンプトが作成されました
ChatGPT にプロンプトを送信中...
ChatGPT から応答を受信しました
データを JSON にエクスポート中...
データが 'analysis.json' にエクスポートされましたプロジェクトディレクトリに生成されたanalysis.jsonファイルを開くと、以下のような内容が表示されます:
{
"url": "https://linkedin.com/in/antonello-zanini",
"evaluation": "Antonello Zaniniはリモートソフトウェアエンジニア職の有力候補と見受けられます。フリーランスソフトウェアエンジニアとしての経験は、リモートワークに不可欠な適応力と自主性を示しています。技術文書作成や編集の経歴は、リモートチームとの協業に必須の優れたコミュニケーション能力を暗示しています。 さらに、ユニットテストやJavaScriptバンドラーに関する投稿からも明らかなように、多様なプログラミング知識が技術的専門性を裏付けています。クライアントからは高い評価を得ており、成果物の信頼性と明瞭さが強調されています。これは効果的なリモート協業において重要な特性です。加えて、イタリア語・英語・スペイン語の多言語能力は、多様な国際チームにおけるコミュニケーションを強化するでしょう。 総合的に見て、アントネッロの技術的熟練度、コミュニケーション能力、そして好意的な推薦文の組み合わせは、リモートポジションに最適な人材であることを示しています。」
}さあ、完成です!ライブデータで強化されたHR LangChainワークフローが完成しました。
結論
このチュートリアルでは、AIのためのデータ収集にウェブスクレイピングが効果的な理由と、LangChainを用いたデータ分析手法を学びました。
具体的には、PythonベースのLangChainウェブスクレイピングスクリプトを作成し、LinkedInプロフィールページからデータを抽出し、OpenAI APIを使用して処理しました。このLangChainワークフローはHRタスクの支援に最適ですが、示されたコードは他のワークフローやシナリオにも容易に拡張できます。
LangChainにおけるウェブスクレイピングの主な課題は以下の通りです:
- オンラインサイトは頻繁にページ構造を変更する。
- 多くのサイトが高度なボット対策を実施している。
- 大量のデータを同時に取得することは複雑でコストがかかる場合があります。
Bright DataのWebスクレイパーAPIは、主要ウェブサイトからのデータ抽出においてこれらの課題を容易に克服する効果的なソリューションです。LangChainとのシームレスな連携により、RAGアプリケーションやその他のLangChainを活用したソリューションを支える貴重なツールとなります。
AIおよびLLM向けの追加サービスもぜひご覧ください。
Bright Dataのプロキシサービスやスクレイピング製品の中から、ご自身のニーズに最適なものを見つけるために今すぐ登録しましょう。無料トライアルから始められます!




