

自律型研究アシスタントからワークフロー全体を管理するエージェントまで、AIエージェントは単なるトレンドを超えつつあります。それらは仕事の未来、開発、意思決定を形作っています。しかし、あらゆる高性能エージェントの背後には、慎重に構築された技術スタックが存在します。これはエージェントが推論し、行動し、適応することを可能にする多層的なツールシステムです。
次世代自動化を支える基盤
開発者にとって、このスタックを理解することは不可欠です。単に流行のツールを選ぶことではなく、それらの連携方法、真の価値がどこにあるか、エージェントが確実に機能するために必要な基盤要素が何であるかを理解することが重要です。
Bright Dataでは、様々な業界のAIチームと協業していますが、一つ明らかなことがあります。それは、あらゆるエージェントはデータから始まるということです。本記事では、最も重要な要素である「データ収集と統合」から始め、AIエージェント技術スタックの中核となる層を順を追って解説します。
データ収集と統合
より賢いエージェント構築の第一歩
AIエージェントが推論し、計画し、行動する前に、まずそのエージェントが活動する世界を理解する必要があります。その理解は、現実世界から得られるリアルタイムで、しばしば非構造化であるデータから始まります。モデルのトレーニングであれ、検索拡張生成(RAG)システムの駆動であれ、エージェントがライブ市場の変動に対応できるようにするものであれ、データは燃料です。
ここでBright Dataの出番です。
当社は、AIチームがパブリックウェブを大規模に、正確に、コンプライアンスを遵守しながら活用できるインフラを提供します。当社のツールは、データ収集を単に可能にするだけでなく、シームレスに実現するよう設計されています。
スタックにおけるBright Dataの役割
- Search API – 関連するウェブコンテンツをリアルタイムで抽出。RAGやLLM強化型検索に最適。
- アンロック API – 公開データソースへの確実なアクセスを確保するため、ボット対策機能をバイパスします。
- WebスクレイパーAPI – 12万以上のウェブサイトから構造化データを抽出、即時利用可能。
- カスタムスクレイパー – ニッチな分野や特定のエージェントニーズに合わせたソリューション。
- データセットマーケットプレイス – 迅速なプロトタイピングやモデルの微調整に最適な事前収集済みデータセット。
- AIアノテーション – ラベリングとトレーニングデータの精緻化のためのヒューマン・イン・ザ・ループサービス。
「AIエージェントが頭脳なら、Bright Dataは目である」
ユースケース:Eコマースインテリジェンスエージェント
小売企業が競合他社の価格と商品在庫を監視するAIエージェントを構築。Bright DataのWebスクレイパーAPIとWeb Unlocker APIを活用し、エージェントが競合サイトからリアルタイムデータを収集。そのデータを価格エンジンにフィードし、オファーを動的に調整します。
AIエージェントのフルテックスタック
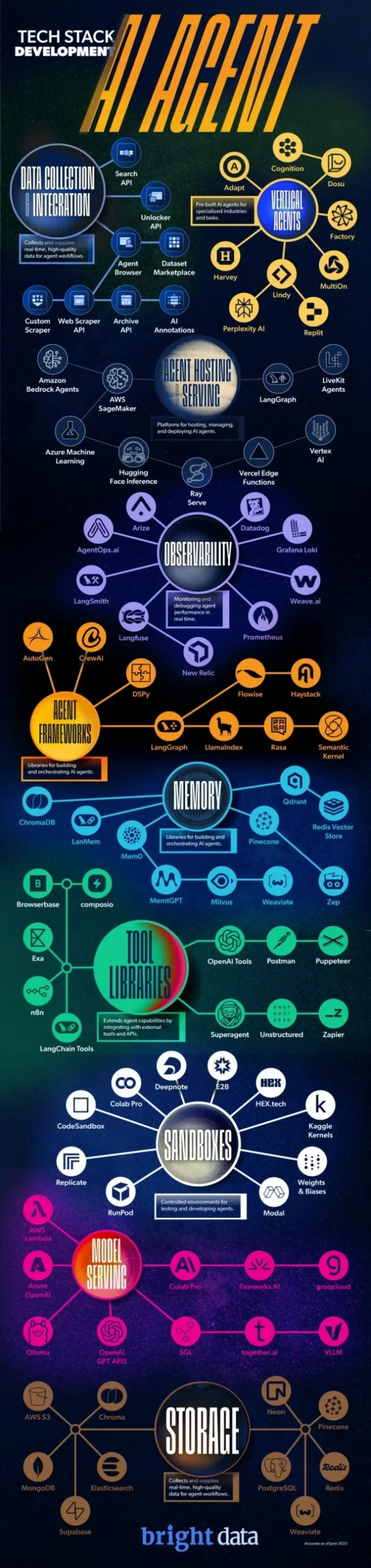
エージェントホスティングサービス
AIエージェントが活動する場
エージェントがデータにアクセスできるようになったら、推論、意思決定、行動を実行できるデジタル環境を運用する場所が必要です。それがエージェントホスティングサービスの役割です。静的なモデルを動的で自律的なシステムに変えるインフラストラクチャを提供します。
これらのプラットフォームは、オーケストレーションから実行まであらゆることを管理し、エージェントがスケーリング、APIとの対話、継続的な運用を確実に実行できるようにします。
開発者が実際に使用しているもの
- LangGraph– ステートフルなマルチステップエージェントワークフロー構築のためのグラフベースランタイム。
- Hugging FaceInference Endpoints – モデルやエージェントをホスト・提供し、Transformers Agentsなどのツールでリアルタイム対話を実現。
- AWS(Bedrock、Lambda、SageMaker) – エージェントを大規模にデプロイ・管理するための柔軟でスケーラブルなインフラを提供。
ホスティングプラットフォームはエージェント世界のオペレーティングシステムですが、最高のホスティング環境で動作するエージェントでさえ、その基盤となるデータの質に依存します。
可観測性
AIエージェントの透明性、追跡可能性、信頼性の確保
エージェントの自律性が高まるにつれ、その動作内容と理由を理解することが不可欠となります。可観測性ツールは、開発者がパフォーマンスの監視、意思決定の追跡、リアルタイムでの問題のデバッグを支援します。
開発者が活用しているツール
- LangSmith(LangChain) – LLM駆動ワークフローのトレース、デバッグ、評価を実現。
- Weights & Biases– モデルのパフォーマンス、実験、エージェントの挙動を時間軸で追跡。
- WhyLabs– 実稼働環境におけるデータドリフトとモデルの異常を監視。
可観測性はエージェントをブラックボックスからガラス張りの箱に変え、開発者に信頼を構築し安全に反復するための可視性を提供します。
エージェントフレームワーク
より賢く、より能力の高いエージェント構築のための設計図
フレームワークは、エージェントの構造、推論方法、ツールとの相互作用、他のエージェントとの連携方法を定義します。エージェントの複雑さが増すにつれ、フレームワークはマルチエージェントシステム、タスク分解、動的計画をサポートするように進化しています。
開発者が実際に使用しているもの
- Crew AI– 役割と責任が定義されたエージェントのチームが連携することを可能にします。
- LangGraph– 分岐ロジックと状態保持型ワークフローをサポートし、複雑なエージェント行動を実現。
- DSPy– LLMパイプラインの最適化と微調整のための宣言型フレームワーク。
フレームワークはエージェントに構造とロジックを与えるが、効果的に機能するには正確なリアルタイムデータに依存している。
記憶
エージェントの記憶・学習・文脈認識の仕組み
メモリシステムにより、エージェントはコンテキストを保持し、過去のやり取りを想起し、長期的な理解を構築できます。通常ベクトルデータベースで駆動されるメモリは、パーソナライゼーション、継続性、複雑な推論に不可欠です。
開発者が実際に使用しているもの
- ChromaDB– 軽量でローカルファースト開発に最適。
- Qdrant– ハイブリッドフィルタリングを備えたスケーラブルで本番環境対応のベクトル検索。
- Weaviate– モジュール式で機械学習対応、エンタープライズグレードの展開で頻繁に使用される。
メモリはエージェントの学習と適応を可能にしますが、その有用性は保存されるデータの質に依存します。これは、最初から高品質な入力データが不可欠であることを改めて示しています。
ツールライブラリ
エージェントが現実世界でどのように行動するか
ツールライブラリは、エージェントに外部システム(API、データベース、検索エンジンなど)との連携能力を与えます。これが言語モデルを実用的なエージェントに変える要素です。
開発者が実際に使用しているもの
- LangChain– LLMとツール、記憶、ワークフローを連携させる堅牢なエコシステム。
- OpenAI Functions– エージェントがGPTモデル内から直接外部ツールを呼び出せるようにする。
- Exa – リアルタイムWeb検索を実現し、研究エージェントやRAGシステムで頻繁に利用される。
ツールライブラリはエージェントを有用なものにしますが、その効果は相互作用するデータの質に依存します。
サンドボックス
エージェントが安全にコードを実行しアイデアをテストする場所
データ分析、シミュレーション、動的な意思決定など、エージェントがコードを記述・実行する必要性は高まっています。サンドボックスは、まさにそのための安全で隔離された環境を提供します。
開発者が活用しているツール
- OpenAI Code Interpreter– データ集約型タスク向けに、GPT-4内でPythonを安全に実行。
- Replit – AI統合を備えたクラウドベースのコーディング環境。
- Modal – セキュアなコード実行レイヤーを兼ね備えたサーバーレスインフラストラクチャ。
サンドボックスはエージェントが問題を推論し実行可能な出力を生成することを可能にしますが、その出力の品質は入力の品質に依存します。
モデルサービング
セカンドブレイン:意思決定が行われる場所
データがAIエージェントの第一の頭脳であるならば、エージェントが知るモデルサービングは第二の思考方法です。
ここでは大規模言語モデル(LLM)がホストされアクセスされ、あらゆるエージェントの意思決定を支える推論と言語生成を提供します。このレイヤーのパフォーマンス、レイテンシー、精度はエージェントの有効性に直接影響します。
開発者が利用しているもの
- OpenAI (GPT-4, GPT-4o)– 汎用推論とマルチモーダル機能における業界標準。
- Anthropic (Claude)– 長文コンテキスト処理とアラインメント重視設計で知られる。
- Mistral – 低コストで高性能を実現するオープンウェイトモデル。
- Groq – リアルタイムエージェント応答のための超低遅延推論。
- AWS ( SageMaker, Bedrock) – 独自モデルとオープンモデルの双方に対応するスケーラブルなインフラストラクチャ。
モデルサービングは洞察を行動に変える場であるが、優れたモデルでさえ効果的に推論するには高品質なリアルタイムデータが必要である。
ストレージ
エージェントが履歴・知識・状態を保持する場所
ストレージシステムは、長期的な永続性、対話の記録、出力の保存、セッション間の状態維持をサポートします。再現性、コンプライアンス、継続的改善に不可欠です。
開発者が実際に使用しているもの
- Amazon S3– スケーラブルなオブジェクトストレージの定番。
- Google Cloud Storage (GCS) – セキュアでGoogleのAIツールと統合済み。
- ベクトルDB(例:Qdrant、Weaviate)– 埋め込み表現と意味的コンテキストを保存し、検索を可能にします。
ストレージはエージェントが過去の経験から学習し、時間とともにスケールすることを保証しますが、保存されるデータの価値は収集されるデータの品質から始まります。
エージェントの知能はデータ次第
AIエージェントの能力は、構築基盤となる情報の質に依存します。適切なデータを適切なタイミングで利用できれば推論・計画・実行が可能ですが、それがなければ最先端の技術スタックも閉じたループに陥ります:強力ではあるが現実世界から切り離された状態です。
だからこそデータは単なる技術スタックの一部ではなく、基盤そのものです。そして現代のAIエコシステムにおいて、最も価値あるデータソースはパブリックウェブなのです。
ブライトデータでは、そのデータへのアクセスを実現します。
当社のツールは、AIエージェントワークフローにおける最初かつ最も重要なステップであるデータ収集と統合を支えます。エージェントをパブリックウェブにリアルタイムで接続し、世界を理解し、情報に基づいた意思決定を行い、意味のある行動を取るために必要な構造化され、信頼性が高く、スケーラブルなデータを提供します。
技術スタックのあらゆる層——エージェントフレームワーク、メモリシステム、ツールライブラリ、モデルサービング——はこの基盤に依存しています。正確で最新の情報を得られなければ、エージェントは適応もパーソナライズも実行もできないからです。
ある意味で、エージェントには二つの頭脳があります:
- データ:彼らが「知る」もの。
- モデル:思考方法。
エージェントが行動する前に、理解する必要があります。
理解する前に、彼らは見る必要があります。
Bright Dataは、エージェントが世界を見る方法です。
次のステップ
Bright DataがAIエージェントスタックを強化する方法を探る:https://brightdata.com/ai/products-for-ai






