
この記事では以下の内容を学びます:
- Google ADKとVertex AI RAG Engineを用いた本番環境対応RAGシステムの構築方法
- 意味検索とキーワード検索を組み合わせたハイブリッド検索の実装方法
- – 適切なグラウンディングと引用による幻覚現象の防止方法
- – テキスト、画像、表を含むマルチモーダルコンテンツの処理方法
- Bright Data統合によるリアルタイムWebデータでRAGを強化する方法(オプション)
さあ始めましょう!
現代のナレッジマネジメントが直面する課題
技術文書はWikiに、製品仕様はPDFに、顧客データはデータベースに、組織の知見はメールに分散しています。従業員は情報検索に時間を費やし、古くなった情報や不完全な回答に遭遇することが多々あります。汎用データで訓練された大規模言語モデルは、貴社の独自知識にアクセスできません。企業固有の情報について尋ねられると、しばしば誤った回答を返します。
RAGエージェントは、応答生成前にナレッジベースから関連コンテキストを取得することでこの課題を解決します。これによりAIは事実情報に基づき、幻覚現象を低減し、検証可能な透明な引用を提供します。
構築対象:インテリジェントRAGエージェントシステム
様々なソースから文書を取得し、検索可能な単位に処理、ベクトル表現に変換、ハイブリッド検索で関連コンテキストを抽出、正確な回答を生成するとともに適切な引用を提供し、不正確さを防止する、本番環境対応のRAGエージェントを構築します。
本システムが管理する機能:
- – Cloud Storage、Drive、ローカルファイルからの文書取り込み
- 重複を許容したスマートチャンキングとメタデータ保持
- 意味的類似性とキーワードマッチングを組み合わせたハイブリッド検索
- 画像や表を含むマルチモーダルコンテンツ
- 回答検証のための引用生成
- エラーの検出と防止
前提条件
開発環境のセットアップ:
- Python 3.10 以降– Google ADK 互換性のために必須。
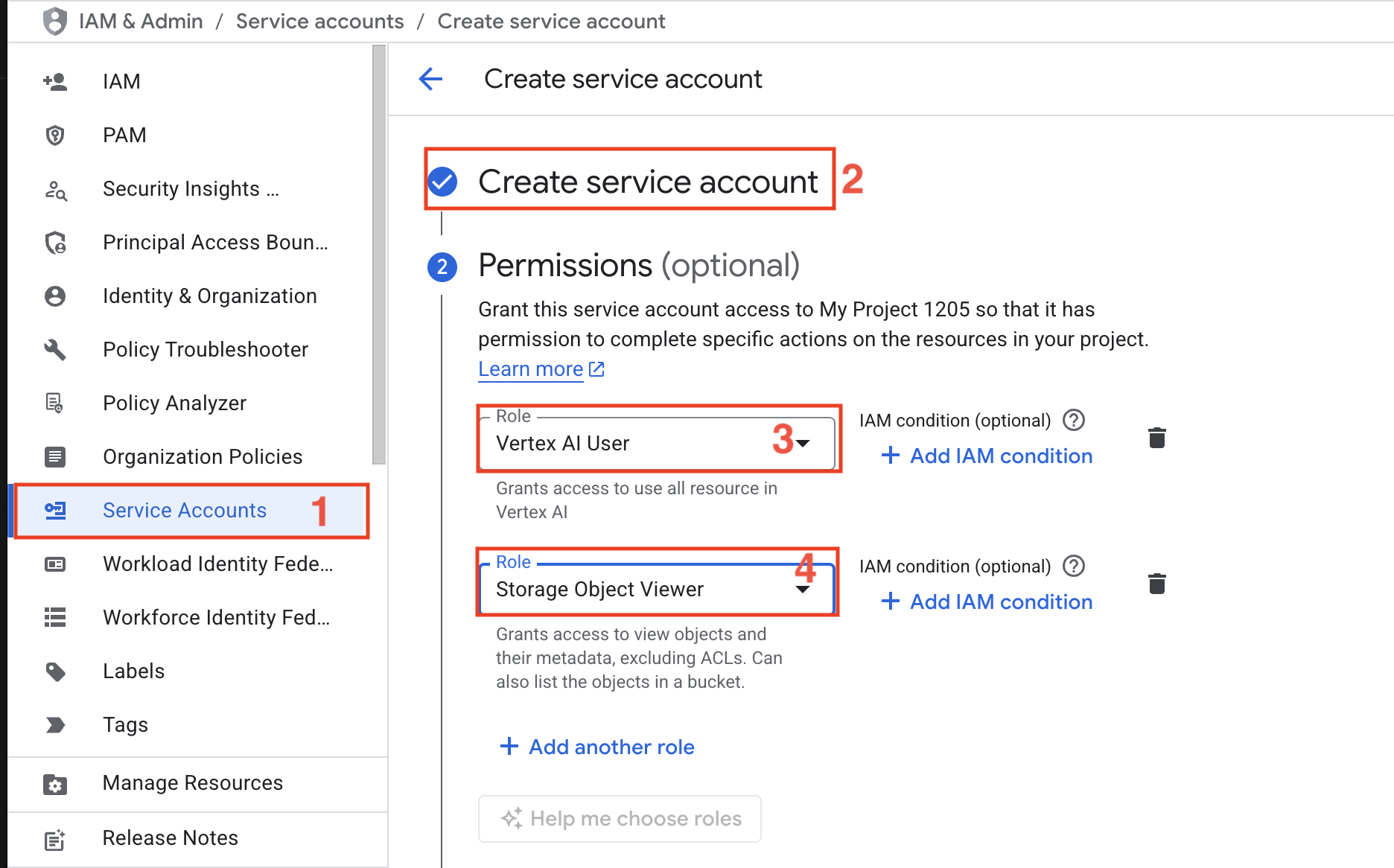
- Google Cloudプロジェクト–Google Cloudコンソールで課金機能を有効にしたプロジェクトを作成してください。
- サービスアカウント– Vertex AI ユーザーおよびストレージオブジェクトビューアーのロールを持つサービスアカウントを作成してください。
- Google ADK– AIエージェント構築用エージェント開発キット。詳細はドキュメントを参照。
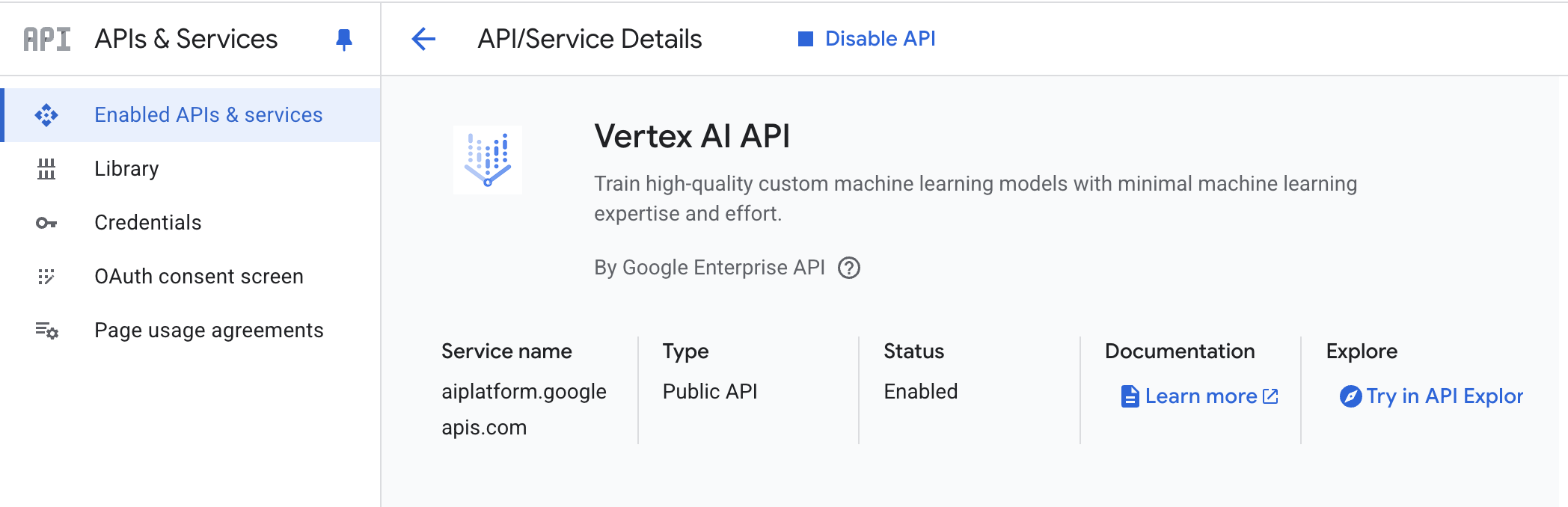
- Vertex AI API– Google CloudプロジェクトでVertex AI APIを有効化
- Python仮想環境– 依存関係を分離します。
venvドキュメントを参照してください。
環境設定
プロジェクトディレクトリを作成し、依存関係をインストールします:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install google-genai google-cloud-aiplatform google-cloud-storage langchain-google-vertexai pypdf python-dotenv pandas pillowrag_agent.pyという新しいファイルを作成し、以下のインポートを追加:
import os
import json
import PyPDF2
import fitz
import time
import vertexai
from google import genai
from vertexai.preview import rag
from pathlib import Path
from vertexai.preview.generative_models import GenerativeModel, Tool
from google.cloud import storage
from typing import List, Dict, Any, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.api_core.exceptions import ResourceExhausted
from google.genai import types
load_dotenv()認証情報を記載した.envファイルを作成:
GOOGLE_CLOUD_PROJECT="your-project-id"
GOOGLE_CLOUD_LOCATION="us-central1"
GOOGLE_APPLICATION_CREDENTIALS="path/to/service-account-key.json"
GENAI_API_KEY="your-genai-API-key"
GCS_BUCKET_NAME="your-bucket-name"必要なもの:
- プロジェクトID: コンソールから取得したGoogle Cloudプロジェクト識別子
- ロケーション: Vertex AIリソースのリージョン(us-east1を推奨)
- サービスアカウントキー: IAM & Admin からダウンロードした JSON キーファイル
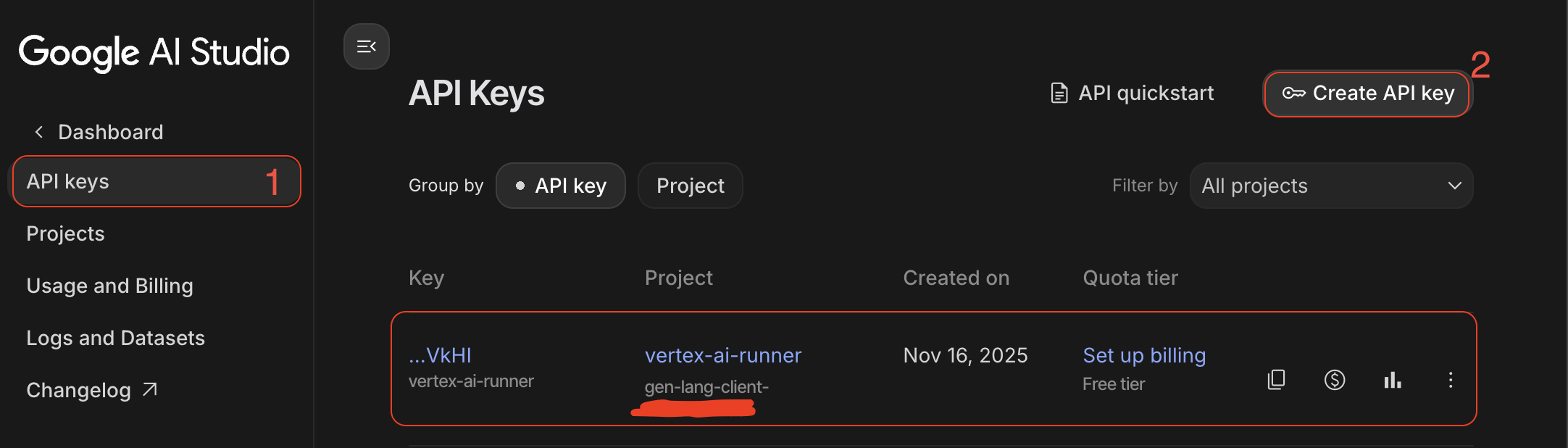
- GenAI API キー:Google AI Studioから作成
- GCS バケット: 文書保存用の Cloud Storage バケット
RAG エージェントシステムの構築
ステップ1: Google ADKの設定
Google ADKクライアントを設定し、適切な認証でVertex AIを初期化します。クライアントはGoogleの生成AIサービスとのすべてのやり取りを処理します。
def initialize_adk():
"""適切な認証情報でVertex AIを初期化します。"""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
vertexai.init(
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
print(f"✓ Vertex AI を初期化しました")
# システムを初期化
initialize_adk()初期化では、エージェント操用用のGenAIクライアントとRAG機能用のVertex AIの両方への接続を確立します。進行前に認証情報を検証し、プロジェクト設定を確認します。
ステップ2: Vertex AI RAGエンジンの設定
ナレッジベースの基盤となるRAGコーパスを作成します。コーパスはインデックス化されたドキュメントを保存し、埋め込みを管理し、検索クエリを処理します。
def create_rag_corpus(corpus_name: str, description: str) -> str:
"""文書保存と検索用の新しいRAGコーパスを作成します。"""
try:
corpus = rag.create_corpus(
display_name=corpus_name,
description=description,
embedding_model_config=rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
)
corpus_id = corpus.name.split('/')[-1]
print(f"✓ RAGコーパス作成完了: {corpus_name}")
print(f"✓ コーパスID: {corpus_id}")
print(f"✓ 埋め込みモデル: text-embedding-004")
return corpus_id
except Exception as e:
print(f"コーパス作成エラー: {str(e)}")
raise
def configure_retrieval_parameters(corpus_id: str) -> Dict[str, Any]:
"""最適な検索パフォーマンスのための検索パラメータを設定します。"""
retrieval_config = {
"corpus_id": corpus_id,
"similarity_top_k": 10,
"vector_distance_threshold": 0.5,
"filter": {},
"ranking_config": {
"rank_service": "default",
"alpha": 0.5
}
}
print(f"✓ 検索パラメータを設定しました")
print(f" - トップK件の結果: {retrieval_config['similarity_top_k']}")
print(f" - 距離閾値: {retrieval_config['vector_distance_threshold']}")
print(f" - ハイブリッド検索アルファ: {retrieval_config['ranking_config']['alpha']}")
return retrieval_configコーパス作成には高品質な意味的埋め込みのためGoogleのtext-embedding-004モデルを使用します。検索設定はアルファパラメータを通じて意味的類似性とキーワード一致のバランスを調整し、0.5で等重量配分となります。
ステップ3: ドキュメント取り込みパイプライン
複数のファイル形式を処理し、クリーンなテキストを抽出し、検索性能向上のために重要なメタデータを保持する堅牢な文書取り込みパイプラインを構築する。
def extract_text_from_pdf(file_path: str) -> Dict[str, Any]:
"""PDF文書からテキストとメタデータを抽出します。"""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
metadata = {
'source': file_path,
'num_pages': len(pdf_reader.pages),
'title': pdf_reader.metadata.get('/Title', ''),
'author': pdf_reader.metadata.get('/Author', ''),
'created_date': str(datetime.now())
}
text_content = []
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
text_content.append({
'page': page_num + 1,
'text': page_text,
'char_count': len(page_text)
})
return {
'metadata': metadata,
'content': text_content,
'full_text': ' '.join([p['text'] for p in text_content])
}
def preprocess_document(text: str) -> str:
"""文書テキストをクリーンアップし正規化して、最適なインデックス作成を実現します。"""
text = ' '.join(text.split())
text = text.replace('x00', '')
text = text.replace('rn', 'n')
lines = text.split('n')
cleaned_lines = [
line for line in lines
if len(line.strip()) > 3
and not line.strip().isdigit()
]
return 'n'.join(cleaned_lines)チャンキング戦略では、文の境界を用いて思考の途切れを回避し、チャンク間の文脈を保持するために重複を実装し、正確な引用のためにチャンク位置に関するメタデータを維持します。1000文字のチャンクサイズは、検索精度と文脈の完全性のバランスを取っています。
ステップ4: 埋め込みとインデックス化
文書をRAGコーパスにアップロードし、意味検索用のベクトル埋め込みを生成します。埋め込み生成とインデックス最適化はシステムが自動処理します。
def chunk_document(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[Dict[str, Any]]:
"""最適な検索のために文書を重複するチャンクに分割します。"""
chunks = []
start = 0
text_length = len(text)
chunk_id = 0
while start < text_length:
end = start + chunk_size
if end < text_length:
last_period = text.rfind('.', start, end)
if last_period != -1 and last_period > start:
end = last_period + 1
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append({
'chunk_id': chunk_id,
'text': chunk_text,
'start_char': start,
'end_char': end,
'char_count': len(chunk_text)
})
chunk_id += 1
start = end - overlap
print(f"✓ {len(chunks)} 個のチャンクを作成しました。文字重複は {overlap} 文字です")
return chunks
def upload_file_to_gcs(local_path: str, gcs_bucket: str) -> str:
"""ドキュメントをGoogle Cloud Storageにアップロードし、RAG取り込み用に準備します。"""
storage_client = storage.Client()
bucket = storage_client.bucket(gcs_bucket)
blob_name = f"rag-docs/{Path(local_path).name}"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_path)
gcs_uri = f"gs://{gcs_bucket}/{blob_name}"
print(f"✓ GCSにアップロード完了: {gcs_uri}")
return gcs_uri
def import_documents_to_corpus(corpus_id: str, file_uris: List[str]) -> str:
"""文書をRAGコーパスにインポートし、埋め込みを生成します。"""
print(f"⚡ {len(file_uris)} ファイルのインポートを開始します...")
response = rag.import_files(
corpus_name=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}",
paths=file_uris,
chunk_size=1000,
chunk_overlap=200
)
try:
if hasattr(response, 'result'):
print("⏳ インポート操作の完了待ち (数分かかる場合があります)...")
response.result()
else:
print("✓ インポートリクエスト送信完了。")
except Exception as e:
print(f"⚠️ 待機中の注意: {e}")
print(f"✓ ドキュメントのインポートとインデックス作成が開始されました。")
return getattr(response, 'name', 'unknown_operation')
def create_vector_index(corpus_id: str, index_config: Dict[str, Any]) -> str:
"""高速類似性検索のための最適化されたベクトルインデックスを作成します。"""
index_settings = {
'corpus_id': corpus_id,
'distance_measure': 'COSINE',
'algorithm': 'TREE_AH',
'leaf_node_embedding_count': 1000,
'leaf_nodes_to_search_percent': 10
}
print(f"✓ TREE_AHアルゴリズムでベクトルインデックスを作成")
print(f"✓ 距離測定: COSINE類似度")
print(f"✓ {index_settings['leaf_nodes_to_search_percent']}%の検索カバレッジ向けに最適化")
return corpus_idインポート処理は、文書のパース、チャンキング、埋め込み生成を自動的に処理します。TREE_AHアルゴリズムは、高い再現率を維持しながら高速な近似最近傍検索を提供します。コサイン類似度は、埋め込みベクトル間の角度距離を測定し、意味的マッチングを実現します。
ステップ5: ADKを用いたエージェント開発
コンテキスト管理、ユーザークエリ処理、検索と応答生成の連携を統括するコアエージェントアーキテクチャを作成します。
class RAGAgent:
"""文脈管理とグラウンディングを備えたインテリジェントなRAGエージェント"""
def __init__(self, corpus_id: str, model_name: str = "gemini-2.5-flash"):
self.corpus_id = corpus_id
self.model_name = model_name
self.conversation_history = []
self.rag_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"],
similarity_top_k=5,
vector_distance_threshold=0.3
)
)
)
self.model = GenerativeModel(
model_name=model_name,
tools=[self.rag_tool]
)
print(f"✓ {model_name} で RAG エージェントを初期化しました")
print(f"✓ コルパスに接続: {corpus_id}")
def manage_context(self, query: str, max_history: int = 5) -> List[Dict[str, str]]:
"""履歴の切り捨てによる会話コンテキストの管理"""
self.conversation_history.append({
'role': 'user',
'content': query,
'timestamp': datetime.now().isoformat()
})
if len(self.conversation_history) > max_history * 2:
self.conversation_history = self.conversation_history[-max_history * 2:]
formatted_history = []
for msg in self.conversation_history:
formatted_history.append({
'role': msg['role'],
'parts': [msg['content']]
})
return formatted_history
def build_grounded_prompt(self, query: str, retrieved_context: List[Dict[str, Any]]) -> str:
"""明示的なグラウンディング指示を含むプロンプトを生成する。"""
context_text = "nn".join([
f"[Source {i+1}]: {ctx['text']}"
for i, ctx in enumerate(retrieved_context)
])
prompt = f"""あなたは知識ベースにアクセスできる有用なAIアシスタントです。
以下の質問に、下記コンテキストに提供された情報のみを使用して回答してください。
重要な指示:
1. 回答は厳密に提供されたコンテキストに基づいてください
2. コンテキストに十分な情報が含まれていない場合は、明示的にその旨を伝えてください
3. [出典X]表記で具体的な情報源を明記すること
4. 自身の一般知識から情報を追加しないこと
5. 不明な場合はその旨を伝えること
コンテキスト:
{context_text}
質問:
{query}
回答:"""
return promptエージェントは複数ターン対話のための会話履歴を維持し、トークン制限を防ぐためコンテキストウィンドウサイズを管理し、幻覚を低減するため明示的なグラウンディング指示付きプロンプトを構築します。RAGツールの統合により生成時の自動検索が可能となります。
ステップ6: クエリ処理と検索
最適な検索精度を実現するため、意味理解とキーワードマッチングを組み合わせたハイブリッド検索を実装する。
def hybrid_search(
self,
corpus_id: str,
query: str,
semantic_weight: float = 0.7,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""クォータ制限時に自動再試行するハイブリッド検索を実行"""
rag_resource = rag.RagResource(
rag_corpus=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"
)
max_retries = 3
base_delay = 90
for attempt in range(max_retries):
try:
print(f"🔍 コーパスを検索中 (試行 {attempt + 1})...")
results = rag.retrieval_query(
rag_resources=[rag_resource],
text=query,
similarity_top_k=top_k,
vector_distance_threshold=0.5
)
# 成功した場合、結果を処理して返す
retrieved_chunks = []
for i, context in enumerate(results.contexts.contexts):
retrieved_chunks.append({
'rank': i + 1,
'text': context.text,
'source': context.source_uri if hasattr(context, 'source_uri') else 'unknown',
'distance': context.distance if hasattr(context, 'distance') else 0.0
})
print(f"✓ 関連するチャンク {len(retrieved_chunks)} 個を取得しました")
return retrieved_chunks
except ResourceExhausted:
wait_time = base_delay * (2 ** attempt)
print(f"⚠️ クォータ制限に達しました (制限: 5/分)。 {wait_time}秒間待機中...")
time.sleep(wait_time)
except Exception as e:
print(f"❌ 取得エラー: {str(e)}")
raise
print("❌ 最大再試行回数に達しました。取得に失敗しました。")
return []
def rerank_results(
self,
results: List[Dict[str, Any]],
query: str,
model_name: str = "gemini-2.5-flash"
) -> List[Dict[str, Any]]:
"""クエリとの関連性に基づいて取得結果を再ランク付けします。"""
if not results:
return []
rerank_prompt = f"""クエリに対する各パッセージの関連性を0~10のスケールで評価してください。
クエリ: {query}
パッセージ:
{chr(10).join([f"{i+1}. {r['text'][:200]}..." for i, r in enumerate(results)])}
コンマ区切りのスコアリストのみを返す(例: 8,6,9,3,7)"""
model = GenerativeModel(model_name)
response = model.generate_content(rerank_prompt)
if response.text:
try:
scores = [float(s.strip()) for s in response.text.strip().split(',')]
for i, score in enumerate(scores[:len(results)]):
results[i]['rerank_score'] = score
results.sort(key=lambda x: x.get('rerank_score', 0), reverse=True)
print(f"✓ LLMスコアリングによる再ランク付け結果")
except Exception as e:
print(f"警告: 再ランク付け失敗、元の順序を使用: {str(e)}")
return resultsハイブリッド検索はベクトル類似度で候補を取得し、再ランク付けではLLMを用いてクエリ固有の文脈に基づく関連性をスコアリングします。この二段階アプローチは効率と精度を両立させます。
ステップ7: 応答生成とグラウンディング
適切な引用付きで応答を生成し、厳格なグラウンディング検証を通じて幻覚防止を実装する。
def generate_grounded_response(
self,
agent: 'RAGAgent',
query: str,
retrieved_context: List[Dict[str, Any]],
temperature: float = 0.2
) -> Dict[str, Any]:
"""引用付き応答を生成し、幻覚を防止する。"""
grounded_prompt = agent.build_grounded_prompt(query, retrieved_context)
chat = agent.model.start_chat()
response = chat.send_message(
grounded_prompt,
generation_config={
'temperature': temperature,
'top_p': 0.8,
'top_k': 40,
'max_output_tokens': 1024
}
)
return {
'answer': response.text,
'sources': retrieved_context,
'query': query,
'timestamp': datetime.now().isoformat()
}
def verify_grounding(
self,
response: str,
sources: List[Dict[str, Any]],
model_name: str = "gemini-2.5-flash"
) -> Dict[str, Any]:
"""回答がソース資料に基づいて主張されているか検証する。"""
verification_prompt = f"""以下の回答が提供されたソースによって完全に裏付けられているかを分析してください。
SOURCES:
{chr(10).join([f"Source {i+1}: {s['text']}" for i, s in enumerate(sources)])}
ANSWER:
{response}
回答の各主張を確認してください。JSON形式で応答してください:
{{
"is_grounded": true/false,
"unsupported_claims": ["主張1", "主張2"],
"confidence_score": 0.0-1.0
}}"""
model = GenerativeModel(model_name)
verification_response = model.generate_content(verification_prompt)
try:
json_text = verification_response.text.strip()
if '```json' in json_text:
json_text = json_text.split('```json')[1].split('```')[0].strip()
verification_result = json.loads(json_text)
print(f"✓ 接地検証完了")
print(f" - 接地状態: {verification_result.get('is_grounded', False)}")
print(f" - 信頼度: {verification_result.get('confidence_score', 0.0):.2f}")
return verification_result
except Exception as e:
print(f"警告: 根拠検証に失敗しました: {str(e)}")
return {'is_grounded': True, 'confidence_score': 0.5}接地検証は、応答内の各主張がソース文書に遡れることを確認します。低温生成(0.2)は創造的な装飾を減らし、事実の正確性を向上させます。
ステップ8: マルチモーダルRAGの実装
RAGシステムを拡張し、画像、表、その他の非テキストコンテンツを処理して包括的な知識検索を実現します。
def extract_images_from_pdf(self, pdf_path: str, output_dir: str) -> List[Dict[str, Any]]:
"""マルチモーダル索引付け用にPDF文書から画像を抽出します。"""
doc = fitz.open(pdf_path)
images = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# 画像を保存
image_filename = f"page{page_num + 1}_img{img_index + 1}.png"
image_path = os.path.join(output_dir, image_filename)
with open(image_path, "wb") as img_file:
img_file.write(image_bytes)
images.append({
'page': page_num + 1,
'image_path': image_path,
'format': base_image['ext'],
'size': len(image_bytes)
})
print(f"✓ PDFから{len(images)}枚の画像を抽出しました")
return images
def process_table_content(self, table_text: str) -> Dict[str, Any]:
"""テーブルデータを処理・構造化し、検索性を向上させる"""
lines = table_text.strip().split('n')
if not lines:
return {}
headers = [h.strip() for h in lines[0].split('|') if h.strip()]
rows = []
for line in lines[1:]:
cells = [c.strip() for c in line.split('|') if c.strip()]
if len(cells) == len(headers):
row_dict = dict(zip(headers, cells))
rows.append(row_dict)
return {
'headers': headers,
'rows': rows,
'row_count': len(rows),
'column_count': len(headers)
}
def create_multimodal_embedding(
self,
text: str,
image_path: Optional[str] = None,
table_data: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""マルチモーダルコンテンツ用の統合埋め込みを作成します。"""
combined_text = text
if table_data and table_data.get('rows'):
table_desc = f"n{table_data['row_count']}行と{table_data['headers']}列のテーブル: {', '.join(table_data['headers'])}n"
combined_text += table_desc
if image_path:
combined_text += f"n[画像: {Path(image_path).name}]"
return {
'text': combined_text,
'has_image': image_path is not None,
'has_table': table_data is not None,
'modalities': sum([bool(text), bool(image_path), bool(table_data)])
}マルチモーダル処理では、テキストに加えて画像と表を抽出・インデックス化します。統一埋め込みアプローチにより、全モダリティの記述的メタデータが検索可能なテキストに統合されます。これにより「第3四半期レポートの価格表を表示」といったクエリで、表データと周辺文脈の両方を取得可能になります。
ステップ9: Google ADKエージェントの統合
Google Agent Development Kit (ADK) を統合し、Vertex AI RAG Engine バックエンドに接続する優れたエージェントインターフェースを構築します。ADK は、ツール呼び出し、マルチターン会話、構造化応答など、強化されたエージェント機能を提供します。
class ADKRAGAgent:
"""Vertex AI RAG Engineをバックエンドとして使用するGoogle ADKエージェントラッパー"""
def __init__(self, corpus_id: str, project_id: str, location: str):
"""RAG機能を備えたADKエージェントを初期化します。"""
self.corpus_id = corpus_id
self.project_id = project_id
self.location = location
self.rag_agent = RAGAgent(corpus_id)
self.client = genai.Client(
vertexai=True,
project=project_id,
location=location
)
self.model_name = "gemini-2.0-flash-001"
print(f"✓ Google ADK Agent の初期化完了")
print(f" - フレームワーク: Google ADK (genai.Client)")
print(f" - バックエンド: Vertex AI RAG Engine")
print(f" - プロジェクト: {project_id}")
print(f" - ロケーション: {location}")
print(f" - RAGコーパス: {corpus_id}")
def create_rag_search_tool(self) -> types.Tool:
"""ADKエージェント用のRAG検索ツールを作成します。"""
def rag_search(query: str) -> str:
"""
RAGコーパスを検索し、根拠に基づく回答を返します。
引数:
query: 検索対象のユーザー質問
戻り値:
ナレッジベースからの引用付き根拠付き回答
"""
try:
results = self.rag_agent.hybrid_search(
self.corpus_id,
query,
semantic_weight=0.7,
top_k=10
)
if not results:
return "ナレッジベースに関連情報が見つかりませんでした。"
reranked = self.rag_agent.rerank_results(results, query)
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
reranked[:5]
)
verification = self.rag_agent.verify_grounding(
response['answer'],
response['sources']
)
answer = response['answer']
if not verification.get('is_grounded', True):
answer += f"nn[Confidence: {verification.get('confidence_score', 0):.0%}]"
return answer
except Exception as e:
return f"ナレッジベース検索エラー: {str(e)}"
rag_tool = types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="rag_search",
description="RAG(検索強化生成)を用いて企業ナレッジベースを検索し、技術文書、製品仕様書、ユーザーガイドに関する質問に対して正確で根拠のある回答を見つける。",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "ユーザーの質問または検索クエリ"
}
},
"required": ["query"]
}
)
]
)
self.rag_search_function = rag_search
return rag_tool
def create_agent(self) -> Dict[str, Any]:
"""RAGツールを使用したGoogle ADKエージェント設定を作成します。"""
rag_tool = self.create_rag_search_tool()
agent_instructions = """あなたは、企業向けナレッジベースにアクセス可能なインテリジェントなRAG(Retrieval-Augmented Generation)エージェントです。
あなたの能力:
- 技術文書、製品仕様書、ユーザーガイドを検索する
- 引用付きで正確かつ根拠に基づいた回答を提供する
- コンテキストを認識したマルチターン対話を処理する
- 応答前に情報の正確性を確認する
ガイドライン:
1. 回答前に必ずrag_searchツールで情報検索を行う
2. 検索した文書に基づき具体的かつ詳細な回答を提供する
3. 関連する引用元と出典を明記する
4. 情報が見つからない場合は明確に伝える
5. 複数クエリにわたる会話の文脈を維持する
すべての回答において、有用性・正確性・専門性を保つこと。"""
agent_config = {
'model': self.model_name,
'instructions': agent_instructions,
'tools': [rag_tool],
'display_name': 'Vertex AI 搭載 RAG エージェント (Google ADK + Vertex AI RAG Engine)'
}
print(f"✓ Google ADK エージェント設定を作成")
print(f" - モデル: {self.model_name}")
print(f" - ツール: RAG 検索 (Vertex AI RAG エンジン)")
return agent_config
def chat(self, agent_config: Dict[str, Any], query: str, session_id: str = "default") -> str:
"""Google GenAIを使用してADKエージェントにメッセージを送信し、応答を取得します。"""
self.rag_agent.manage_context(query)
try:
response = self.client.models.generate_content(
model=agent_config['model'],
contents=query,
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
if response.candidates and len(response.candidates) > 0:
candidate = response.candidates[0]
if candidate.content and candidate.content.parts:
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_name = part.function_call.name
function_args = part.function_call.args
print(f" → ADK Agent calling tool: {function_name}")
if function_name == "rag_search":
query_arg = function_args.get("query", query)
tool_result = self.rag_search_function(query_arg)
response = self.client.models.generate_content(
model=agent_config['model'],
contents=[
types.Content(role="user", parts=[types.Part(text=query)]),
types.Content(role="model", parts=[part]),
types.Content(
role="function",
parts=[types.Part(
function_response=types.FunctionResponse(
name=function_name,
response={"result": tool_result}
)
)]
)
],
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
elif hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
if response.candidates and response.candidates[0].content.parts:
for part in response.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
return "応答が生成されませんでした。"
except Exception as e:
error_msg = f"ADKエージェントチャットでエラーが発生しました: {str(e)}"
print(f"❌ {error_msg}")
return error_msgADK統合は、既存のRAGエージェントにGoogleのエージェントフレームワークを追加します。ADKRAGAgentクラスはエージェント操作用のgenai.Clientを設定し、検索にはRAGAgentを使用します。create_rag_search_toolメソッドはエージェントが呼び出せる関数を定義し、Vertex AI RAG Engineを用いたナレッジベース検索を可能にします。
ツール呼び出しメカニズムにより、エージェントはユーザークエリに基づいてナレッジベースを検索するタイミングを自動的に判断します。検索が必要な場合、ハイブリッド検索パイプラインを実行し、結果を再順序付け、根拠に基づく応答を生成し、正確性を確認してから回答を提供します。chatメソッドは、ツール実行やマルチターンコンテキスト管理を含む会話フロー全体を管理します。
ステップ10: Bright DataのリアルタイムWebデータでRAGを強化
RAGシステムは内部ナレッジベースからの情報取得に優れていますが、エンタープライズAIアプリケーションでは外部ソースからの最新リアルタイムデータが求められることが多々あります。ここでBright Dataのウェブデータプラットフォームが真価を発揮し、RAGエージェントがウェブ全体からライブ情報にアクセスできるようにすることで、ナレッジベースを常に最新かつ包括的な状態に保ちます。
Bright DataをRAGシステムに統合する理由
1. ナレッジベースを常に最新の状態に保つ
- 最新の製品情報、価格データ、競合他社の情報、市場動向でRAGコーパスを自動更新
- 古いデータによる時代遅れのAI応答を排除
- 定期的なデータ更新をスケジュールし正確性を維持
2. 内部文書を超えた情報収集
- ECプラットフォーム、ニュースサイト、ソーシャルメディア、業界特化ソースなど120以上の人気サイトからリアルタイムデータにアクセス
- 技術文書をライブAPIドキュメント、コミュニティディスカッション、更新された仕様で強化
- 顧客レビュー、フィードバック、感情データを収集し、製品ナレッジベースを強化
3. ダイナミックなクエリ強化を実現
- RAGエージェントが最新情報(価格・在庫状況・最新ニュース)を必要とするクエリを検知すると、自動的に最新データを取得
- 内部知識と外部ウェブデータを組み合わせて包括的な回答を提供
- ユーザーに歴史的背景と最新情報の両方を提供
4. データ収集を容易に拡張
- プロキシ管理、CAPTCHA対応、ボット対策システムの処理は不要
- Bright Dataがインフラ、ブロック解除、データ品質を全て管理
- AI開発に集中しながら、Bright Dataがデータ取得を担当
実装:RAGパイプラインへのBright Data追加
Bright Dataの機能でRAGシステムを拡張しましょう。3つの統合パターンを追加します:事前収集データ用の「データセット統合」、リアルタイムウェブスクレイピング用の「WebスクレイパーAPI」、AI生成の強化インサイト用の「AIスクレイパー」です。
パターン1:履歴データ向けデータセット統合
Bright Dataのデータセットマーケットプレイスを活用し、高品質で構造化されたデータを迅速にRAGコーパスに追加します。
import requests
from typing import List, Dict
import json
class BrightDataRAGEnhancer:
"""Bright Dataのウェブデータ機能でRAGシステムを強化"""
def __init__(self, api_key: str, rag_agent: RAGAgent):
self.api_key = api_key
self.rag_agent = rag_agent
self.base_url = "https://api.brightdata.com"
def fetch_dataset_data(
self,
dataset_id: str,
filters: Dict[str, Any] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""Bright Data Dataset Marketplace からデータを取得します。"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/データセット/v3/snapshot/{データセット_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
print(f"✓ データセット {dataset_id} から {len(response.json())} 件のレコードを取得しました")
return response.json()
def ingest_dataset_to_rag(
self,
corpus_id: str,
dataset_records: List[Dict[str, Any]],
text_fields: List[str]
) -> None:
"""データセットレコードを処理し、RAGコーパスに追加する。"""
processed_chunks = []
for record in dataset_records:
# 指定されたテキストフィールドを検索可能なコンテンツに結合
combined_text = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if combined_text.strip():
# メタデータを追加して検索性を向上
metadata = {
"source": "bright_data_dataset",
"record_id": record.get("id", "unknown"),
"ingestion_date": datetime.now().isoformat(),
"data_type": "external_web_data"
}
# コンテンツをチャンク化
chunks = chunk_document(combined_text, chunk_size=1000, overlap=200)
for chunk in chunks:
chunk['metadata'] = metadata
processed_chunks.append(chunk)
print(f"✓ データセットから {len(processed_chunks)} 個のチャンクを処理完了")
# アップロード用一時ファイル作成
temp_file = "temp_dataset_content.txt"
with open(temp_file, 'w') as f:
for chunk in processed_chunks:
f.write(chunk['text'] + "nn")
# GCSへのアップロードとコーパスへのインポート
gcs_uri = upload_file_to_gcs(temp_file, os.getenv('GCS_BUCKET_NAME'))
import_documents_to_corpus(corpus_id, [gcs_uri])
os.remove(temp_file)
print(f"✓ データセット内容をRAGコーパスに追加完了")ユースケース例: 製品データでeコマースRAGを構築
# まずRAGコーパスを作成
corpus_id = create_rag_corpus(
corpus_name="bright_data_corpus",
description="Bright Data強化型RAG用コーパス")
# コーパスでRAGエージェントを初期化
rag_agent = RAGAgent(corpus_id=corpus_id)
# エンハンサーを初期化
enhancer = BrightDataRAGEnhancer(
api_key=os.getenv("BRIGHT_DATA_API_KEY"),
rag_agent=rag_agent)
print("✓ BrightDataRAGEnhancer の初期化に成功しました!")
# Amazon商品データを取得
amazon_data = enhancer.fetch_dataset_data(
dataset_id="gd_l7q7dkf244hwxr90h", # Amazon商品データセット
filters={"category": "Electronics"},
limit=5000
)
# RAGコーパスに取り込み
enhancer.ingest_dataset_to_rag(
corpus_id=corpus_id,
dataset_records=amazon_data,
text_fields=["title", "description", "features", "reviews"]
)パターン2: リアルタイムWebスクレイパーAPI統合
動的で最新の情報を得るには、Bright DataのWebスクレイパーAPIをRAGエージェントのクエリパイプラインに直接統合します。
def scrape_real_time_data(
self,
scraper_id: str,
inputs: List[Dict[str, Any]],
wait_for_completion: bool = True)
-> List[Dict[str, Any]]:
"""Bright Dataスクレイパーを使用したリアルタイムウェブスクレイピングを実行します。"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# スクレイパーをトリガー
trigger_url = f"{self.base_url}/dca/trigger"
params = {
"スクレイパー": スクレイパー_id,
"queue_next": 1
}
response = requests.post(
trigger_url,
headers=headers,
params=params,
json=inputs
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
print(f"✓ スクレイパー起動完了。スナップショットID: {snapshot_id}")
if not wait_for_completion:
return {"snapshot_id": snapshot_id, "status": "processing"}
# 結果のポーリング
results_url = f"{self.base_url}/dca/データセット"
params = {"id": snapshot_id}
max_retries = 30
for i in range(max_retries):
time.sleep(10) # ポーリング間隔10秒待機
results_response = requests.get(results_url, headers=headers, params=params)
if results_response.status_code == 200:
data = results_response.json()
print(f"✓ スクレイピング完了。{len(data)}件のレコードを取得")
return data
elif results_response.status_code == 202:
print(f"⏳ 処理中... ({i+1}/{max_retries})")
continue
else:
print(f"❌ 結果取得エラー: {results_response.status_code}")
break
return []
def create_dynamic_rag_tool(self) -> types.Tool:
"""リアルタイムWebデータ拡張機能付きRAGツールを作成"""
def augmented_rag_search(query: str, include_live_data: bool = False) -> str:
"""
オプションでリアルタイムWebデータを強化したナレッジベース検索
引数:
query: ユーザーの質問
include_live_data: 最新Webデータを取得するかどうか
戻り値:
内部データと外部データを統合した根拠に基づく回答
"""
# まず内部ナレッジベースを検索
internal_results = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=5
)
combined_results = internal_results
# クエリが最新情報を必要とする場合、ライブデータを取得
if include_live_data or self._requires_fresh_data(query):
print("🌐 リアルタイムWebデータを取得中...")
# 例: 価格情報をスクレイピング
if "price" in query.lower() or "cost" in query.lower():
live_data = self.scrape_real_time_data(
scraper_id="your_product_scraper_id",
inputs=[{"url": "https://example.com/products"}],
wait_for_completion=True
)
# ライブデータを検索可能なチャンクに変換
for record in live_data[:3]: # トップ3の結果
combined_results.append({
'rank': len(combined_results) + 1,
'text': f"{record.get('title', '')}: {record.get('price', '')} - {record.get('description', '')}",
'source': f"Live web data: {record.get('url', 'unknown')}",
'distance': 0.3 # 新鮮なデータへの高関連性
})
# 利用可能な全コンテキストで応答を生成
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
combined_results
)
return response['answer']
return types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="augmented_rag_search",
description="内部ナレッジベースを検索し、必要に応じて最新情報を取得するためリアルタイムWebデータを取得",
parameters={
"type": "object",
"properties": {
"query": {"type": "string", "description": "ユーザーの質問"},
"include_live_data": {"type": "boolean", "description": "最新のウェブデータを取得する"}
},
"required": ["query"]
}
)
]
)
def _requires_fresh_data(self, query: str) -> bool:
"""クエリがリアルタイムデータを必要とするかどうかを判定する"""
fresh_data_keywords = [
"最新", "現在", "本日", "今", "最近",
"価格", "コスト", "在庫あり", "在庫あり"
]
return any(keyword in query.lower() for keyword in fresh_data_keywords)パターン3: 強化されたインテリジェンスのためのAIスクレイパー統合
Bright DataのAIスクレイパー(ChatGPT、Perplexity、Gemini)を活用し、AI生成の洞察と包括的なウェブコンテキストでRAGを強化します。
def query_ai_scraper(
self,
scraper_type: str,
prompt: str,
country_code: str = "us"
) -> Dict[str, Any]:
"""AIスクレイパー(ChatGPT、Perplexityなど)に問い合わせて強化されたコンテキストを取得します。"""
scraper_ids = {
"chatgpt": "chatgpt_scraper_id",
"perplexity": "perplexity_scraper_id",
"gemini": "gemini_scraper_id"
}
inputs = [{
"prompt": prompt,
"country": country_code
}]
results = self.scrape_real_time_data(
scraper_id=scraper_ids.get(scraper_type),
inputs=inputs,
wait_for_completion=True
)
if results:
return {
"answer": results[0].get("answer", ""),
"sources": results[0].get("sources", []),
"citations": results[0].get("citations", [])
}
return {}
def create_hybrid_intelligence_agent(self) -> Dict[str, Any]:
"""RAGとAIスクレイパー知能を組み合わせたエージェントを作成する。"""
def hybrid_search(query: str) -> str:
"""
内部RAGと外部AIスクレイパー知能を統合する。
これにより以下を提供:
1. 内部ナレッジベースの文脈
2. ウェブからのリアルタイムAI生成インサイト
3. 包括的で出典明記された回答
"""
# 内部ナレッジ取得
internal_answer = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=3
)
internal_context = "n".join([r['text'][:200] for r in internal_answer])
# AIスクレイパーによる強化情報の取得
print("🤖 AI強化ウェブインテリジェンスを取得中...")
ai_insight = self.query_ai_scraper(
scraper_type="perplexity", # 信頼性の高い回答で知られる
prompt=query
)
# 両ソースを統合
synthesis_prompt = f"""内部知識と外部AIインサイトの両方を用いて包括的な回答を合成してください。
内部ナレッジベース:
{internal_context}
外部AIインサイト:
{ai_insight.get('answer', '外部インサイトは利用不可')}
情報源:
{json.dumps(ai_insight.get('citations', []), indent=2)}
質問: {query}
完全な回答を提供し、以下の条件を満たすこと:
1. 企業固有の情報については内部知識を優先する
2. 広範な文脈や最新動向については外部インサイトを活用する
3. 全ての情報源を明確に引用する
4. 外部情報と内部情報の出所を明示する"""
model = GenerativeModel("gemini-2.0-flash-001")
response = model.generate_content(synthesis_prompt)
return response.text
return {
'search_function': hybrid_search,
'description': 'ハイブリッドRAG + AIスクレイパー知能システム'
}RAGエージェントシステムの運用
文書処理、クエリ対応、根拠に基づく応答生成を包括的に行うワークフローを構築します。また、処理対象のPDF文書をダウンロードし、docs/フォルダに配置することで、製品に関するAIのコンテキスト構築を可能にします。
def main():
"""RAGエージェントシステムのメイン実行フロー"""
print("=" * 60)
print("RAG Agent System - Initialization")
print("=" * 60)
initialize_adk()
corpus_id = create_rag_corpus(
corpus_name="enterprise-knowledge-base-3",
description="マルチモーダル企業文書・ナレッジリポジトリ"
)
retrieval_config = configure_retrieval_parameters(corpus_id)
print(f"n✓ top_k={retrieval_config['similarity_top_k']} を使用した検索設定を使用中")
print("n" + "=" * 60)
print("ドキュメント取り込みパイプライン")
print("=" * 60)
document_paths = [
"docs/technical_manual.pdf",
"docs/product_specs.pdf",
"docs/user_guide.pdf"
]
gcs_uris = []
all_chunks = []
extracted_images = []
for doc_path in document_paths:
if os.path.exists(doc_path):
extracted = extract_text_from_pdf(doc_path)
print(f"n✓ {Path(doc_path).name} から {extracted['metadata']['num_pages']} ページを抽出完了")
cleaned_text = preprocess_document(extracted['full_text'])
print(f"✓ 前処理済みテキスト: {len(cleaned_text)} 文字")
chunks = chunk_document(cleaned_text, chunk_size=1000, overlap=200)
all_chunks.extend(chunks)
print(f"✓ 文書を {len(chunks)} セグメントに分割")
gcs_uri = upload_file_to_gcs(doc_path, os.getenv('GCS_BUCKET_NAME'))
gcs_uris.append(gcs_uri)
print(f"n✓ 作成されたチャンクの総数: {len(all_chunks)}")
print(f"✓ 抽出済み画像総数: {len(extracted_images)}")
if gcs_uris:
import_documents_to_corpus(corpus_id, gcs_uris)
index_config = {"distance_measure": "COSINE", "algorithm": "TREE_AH"}
create_vector_index(corpus_id, index_config)
time.sleep(180)
# ========================================================================
# Vertex AI RAG Engine を使用した Google ADK Agent の初期化
# ========================================================================
print("n" + "=" * 60)
print("Google ADK Agent Initialization")
print("=" * 60)
adk_agent = ADKRAGAgent(
corpus_id=corpus_id,
project_id=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
agent = adk_agent.create_agent()
for doc_path in document_paths:
if os.path.exists(doc_path):
try:
images = adk_agent.rag_agent.extract_images_from_pdf(doc_path, "extracted_images")
extracted_images.extend(images)
if images:
print(f"✓ マルチモーダル処理用に {len(images)} 枚の画像を抽出しました")
except Exception as e:
print(f"⚠️ 画像抽出をスキップしました: {str(e)}")
queries = [
"インストールに必要なシステム要件は何ですか?",
"認証設定をどのように構成しますか?",
"価格プランとその機能は?"
]
print("n" + "=" * 60)
print("Google ADK Agent - クエリ処理")
print("=" * 60)
print("使用環境: Google ADK + Vertex AI RAG Engine")
print("=" * 60)
session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
for idx, query in enumerate(queries):
print(f"n📝 クエリ {idx + 1}: {query}")
print("-" * 60)
try:
answer = adk_agent.chat(agent, query, session_id)
print(f"n💬 ADK Agent Response:n{answer}n")
print(f"✓ Conversation history: {len(adk_agent.rag_agent.conversation_history)} messages")
except Exception as e:
print(f"❌ エラー: {str(e)}")
import traceback
traceback.print_exc()
print("-" * 60)
if idx < len(queries) - 1:
time.sleep(90)
if extracted_images:
print("n" + "=" * 60)
print("マルチモーダル処理デモ")
print("=" * 60)
sample_table = """機能 | ベーシック | プロ | エンタープライズ
ストレージ | 10GB | 100GB | 無制限
ユーザー数 | 1 | 10 | 無制限
価格 | $10 | $50 | カスタム"""
table_data = adk_agent.rag_agent.process_table_content(sample_table)
print(f"n✓ {table_data.get('row_count', 0)} 行のテーブルを処理完了")
if all_chunks and extracted_images:
multimodal_embed = adk_agent.rag_agent.create_multimodal_embedding(
text=all_chunks[0]['text'][:500],
image_path=extracted_images[0]['image_path'] if extracted_images else None,
table_data=table_data
)
print(f"✓ {multimodal_embed['modalities']} モーダリティでマルチモーダル埋め込みを作成しました")
print(f" - 画像あり: {multimodal_embed['has_image']}")
print(f" - テーブルあり: {multimodal_embed['has_table']}")
print("n" + "=" * 60)
print(f"Google ADK RAG Agent System - Complete")
print(f"✓ Architecture: Google ADK + Vertex AI RAG Engine")
print(f"✓ Total conversation turns: {len(adk_agent.rag_agent.conversation_history)}")
print("=" * 60)
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"n❌ エラー: {str(e)}")
import traceback
traceback.print_exc()RAGエージェントシステムを実行:
python3 rag_agent.pyコンソールにエージェントの処理パイプラインが表示されます。
- Google ADKクライアントとVertex AI接続を初期化します。
- 埋め込みモデル設定でRAGコーパスを作成。
- ドキュメントを抽出、クリーニング、チャンク化して処理します。
- ファイルをCloud Storageにアップロードしコーパスにインポート
- ベクトル埋め込みを生成し、検索インデックスを構築します。
- 拡張、検索、再ランク付けを伴うクエリを実行します。
- 引用と検証を含む根拠に基づく応答を生成します。
- 関連性、完全性、正確性、明瞭性に基づいて応答品質をスコアリングします。
コンソール出力には各ステップの詳細な進捗が表示されます。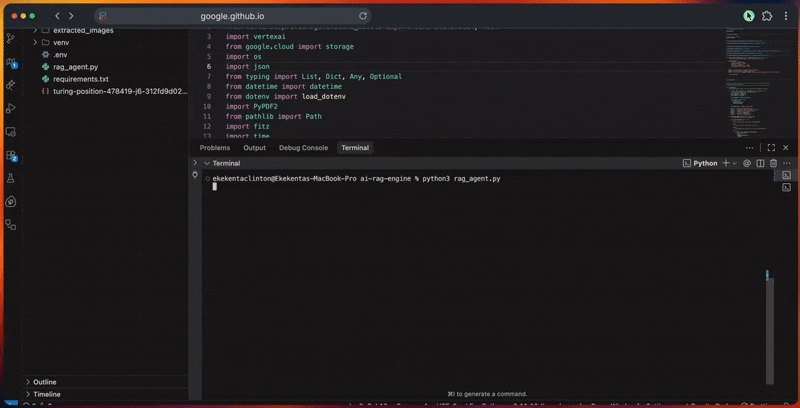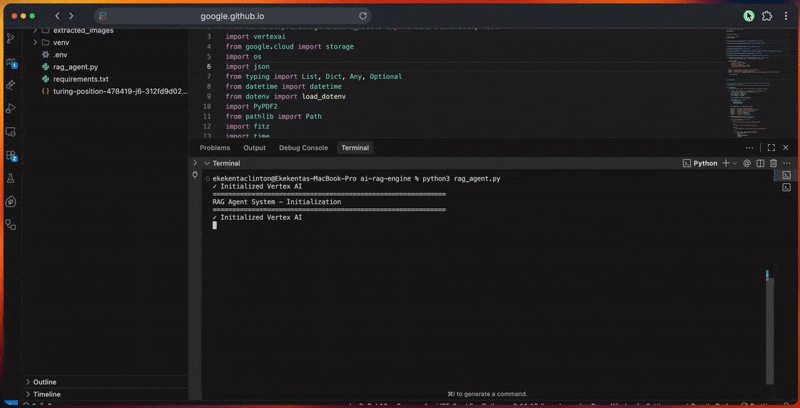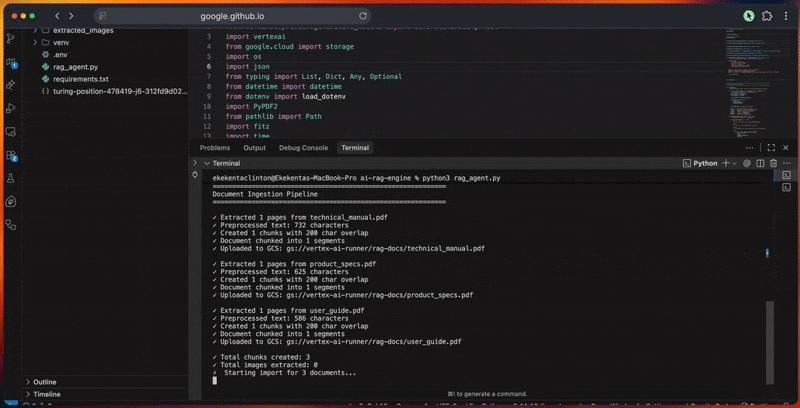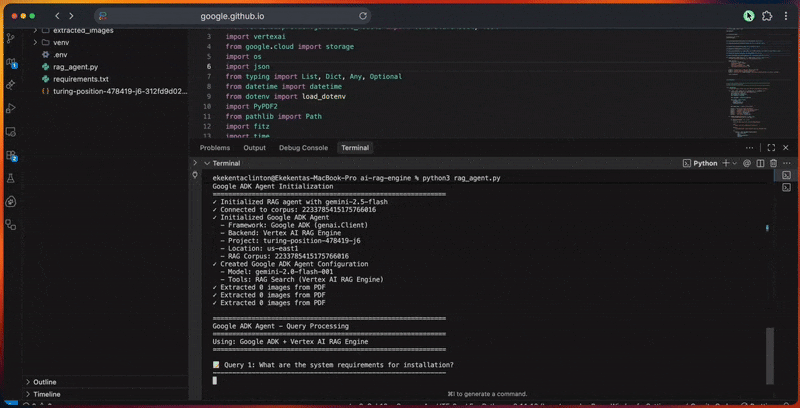
まとめ
GoogleのAgent Development KitとVertex AIを組み合わせた、本番環境対応のRAGエージェントシステムが完成しました。このシステムは文書を取り込み、ハイブリッド検索で関連コンテキストを取得し、引用付きで正確な応答を生成します。
チャンキング戦略の改善、フィードバックループの追加、追加データソースの統合、リアルタイムモニタリングの有効化などで機能を強化できます。モジュール設計により容易なカスタマイズが可能です。
高度なAIワークフローとBright DataのAIインフラストラクチャを活用して、さらなる機能を探求してください。
無料アカウントを作成して構築を開始しましょう。





