

この記事で、あなたは見ることができる:
- xpander.aiプラットフォームとは何か、AIエージェントを構築するために何を提供するのか。
- AIエージェントが真に効果的であるためには、なぜウェブへのアクセスが必要なのか。
- xpander.aiエージェントに組み込みのBright Dataツールを統合し、Webスクレイピング機能を持たせる方法。
さあ、飛び込もう!
xpander.aiとは?
Xpander.aiは、自律型AIエージェントを構築するためのBackend-as-a-Serviceプラットフォームです。企業の開発者がAIエージェントを効率的に構築、テスト、デプロイできるように設計されたコード不要のソリューションです。また、AIエージェントをプログラムで構築・実行するためのオープンソースSDKも付属しています。
このプラットフォームは、マルチエージェントワークフローとコラボレーションを定義するためのビジュアル環境を提供する。また、ツールをアタッチし、企業システムと統合することもできます。さらに、本番稼動前にエージェントの動作をシミュレートし、テストすることができます。
主な特徴は以下の通り:
- エージェントグラフシステム:信頼性の高いマルチステップエージェント実行を保証します。
- エージェントコネクタ:エージェントがさまざまなサードパーティシステムやAPIに接続できるようにします。
正確なAIエージェントのための新鮮なウェブデータの重要性
どのAIエージェント構築プラットフォーム、ライブラリ、ツールを選んでも、基本的な限界がある。つまり、LLMは訓練されたデータに基づいてのみタスクを実行し、質問に答えることができる。これは、典型的なLLMの静的な能力を超える動作を期待されるAIエージェントを構築する際の大きなハードルである。
したがって、より正確で、運用可能で、効果的であるためには、AIエージェントはウェブにアクセスする必要がある。AIエージェントはウェブページを読むことができ、そのコンテンツを基に応答や決定を下すことができる。結局のところ、ウェブは最も豊富で最新のデータ源のひとつなのだ。
しかし、単にウェブにアクセスできるだけでは十分ではない。ほとんどのサイトでは、自動化されたAIのクローラーをブロックするために、スクレイピングやボット対策が施されている。つまり、エージェントには、ウェブページからデータを抽出し、AI処理に最適化されたフォーマットで提供する強力なツールが必要なのだ。
これこそが、xpander.aiに統合されたコネクター経由で利用可能なBright DataのAIインフラストラクチャが提供するものです。その多くの機能の中で、ノーコードのAIエージェントは、構造化されたJSON形式で50以上の一般的なプラットフォームから新鮮なデータを引き出すことができます。
Bright Dataは、CAPTCHA、IP禁止、レート制限などの処理を行います。xpander.aiのAIエージェントビルダーと組み合わせることで、コードを一行も書かずにこれらすべてを統合することができます。その結果は?信頼性の高いウェブデータにリアルタイムでアクセスできる、本番環境に対応したAIエージェントです!
xpander.aiスクレイピングエージェントを構築するためのBright Data Connectorの統合方法
このガイドでは、xpander.aiでAIエージェントを構築する方法を学びます。具体的には、Bright Dataコネクタを使用して、エージェントにウェブからデータをスクレイピングする機能を与えます。
インターネットからライブ・データを取得することでレスポンスの根拠となるウェブ・スクレイピング・エージェントの作成方法を紹介する。これはxpander.aiとBright Dataの統合で可能なことのほんの一例です。このアプローチは他の多くのユースケースに簡単に適応させることができます。
注:ある意味、この例はRAG エージェントワークフローのように動作します。その理由は、Bright Data コネクタが検索コンポーネントとして動作し、エージェントが使用する最新のデータを取得するからです。
以下の手順に従って、xpanderでノーコードのAIスクレイピングエージェントを作成してください!
前提条件
このチュートリアルを再現するには、以下のものが必要です:
- xpander.aiのアカウント:簡単なテストであれば無料アカウントで十分です。より高度な使用例については、有料プランが必要です。
- Bright Data APIキー:公式ガイドにあるように、無料で作成できます。
まだお持ちでない方は、上記のリンクをクリックし、セットアップ手順に従ってください。さあ、始めましょう!
ステップ #1: 新規エージェントの作成
xpander.ai にログインし、プロフィールダッシュボードに移動します。左側のメニューから「エージェント」をクリックし、「新規エージェント」ボタンを押して新しいエージェントを追加します:
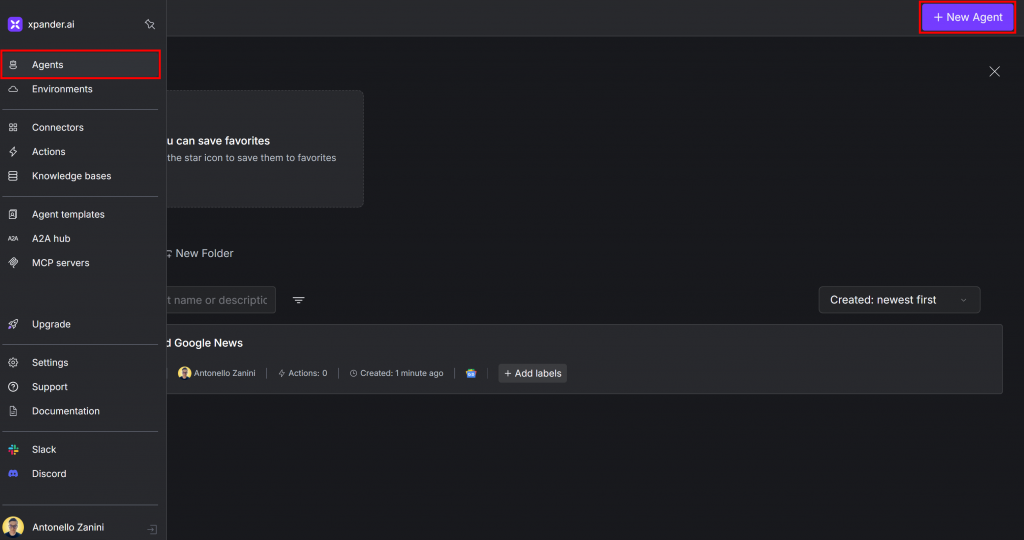
新しいエージェントを設定するフォームがある以下のページに到達します。Web Scraper Agent” のような名前を付けてください:

General “タブの他の設定はすべてそのままにしておきます。今回のようなシンプルなセットアップではデフォルトで十分です。デフォルトでは、xpander.aiはOpenAIのGPT-4oをLLMモデルとして使用します。
素晴らしい!これでxpander.aiに新しい空白のAIエージェントができた。
ステップ2:ウェブスクレイピングのためのブライト・データ・ツールのセットアップ
今、あなたのエージェントは、選択されたLLMプロバイダによって提供されるアクションのみを実行することができます。Bright Dataを使用したウェブスクレイピング機能で、それを強化する時です。
これを行うには、エージェントページの “ツール “タブに行き、”ツールを追加 “ボタンをクリックします:
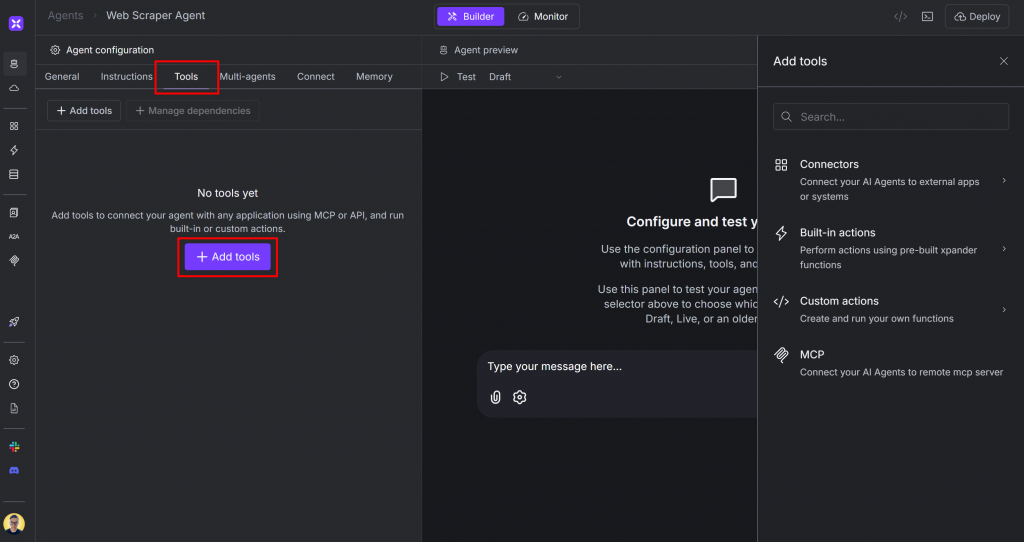
Add tools」というパネルが右側に表示されます。Bright Data」を検索し、Bright Dataインテグレーションを選択します:
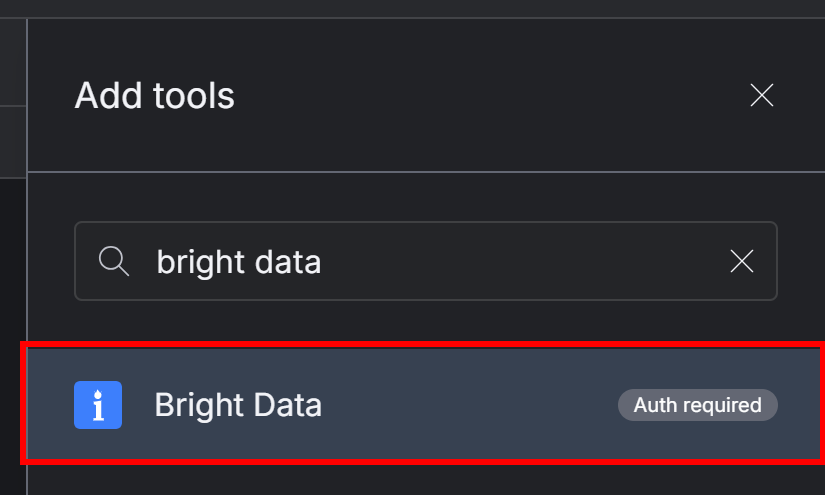
次のようなモーダルが表示されます:
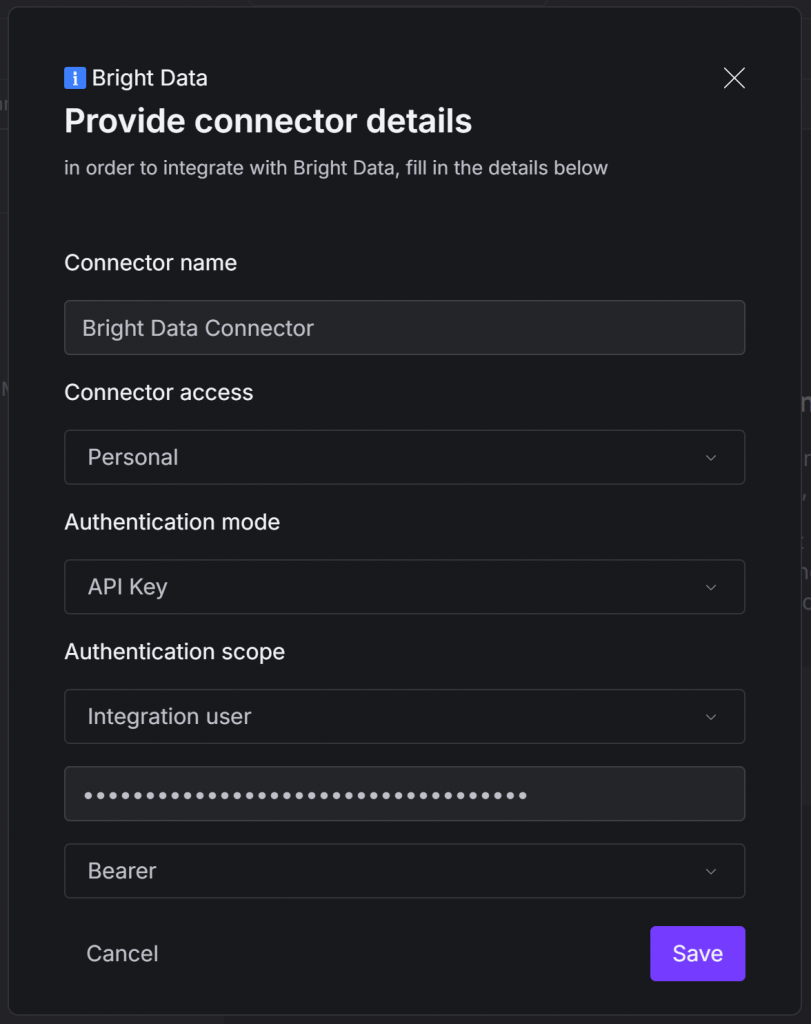
以下のように記入する:
- コネクタ名: Bright Data コネクタに名前を付けます(「Bright Data Connector」など)。
- 認証モード:API Key」オプションを選択します。
- 認証範囲:
- 統合ユーザー」オプションを選択する。
- Bright Data API キーを貼り付けます。
- Bearer” オプションを選択します。これは、Bright Data APIでサポートされている認証方法である
Bearerパターンを介して、Authorizationヘッダ内のAPIキーを渡します。
すべて入力したら、「保存」ボタンを押す。
エージェントで有効にしたい Bright Data ツールを選択するプロンプトが表示されます:
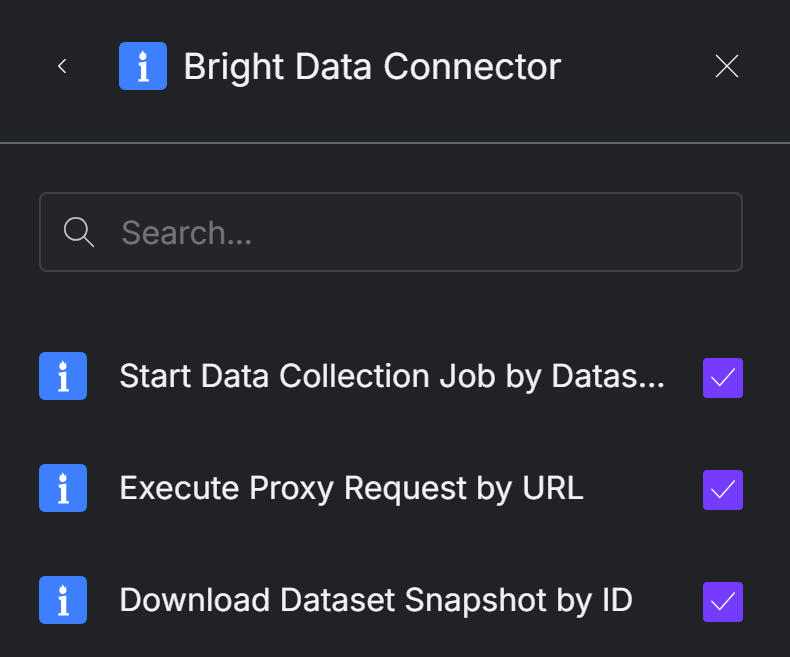
ウェブスクレイピングの全機能を解放するには、すべてのツールを選択することをお勧めします。この記事を書いている現在、利用可能なツールは以下の通りです:
- データセットIDでデータ収集ジョブを開始する:Web Scraper APIを使って、指定したデータセットのスクレイピング・ジョブを開始する。
- URLでプロキシリクエストを実行します:任意のWebページのコンテンツにアクセスするために、Bright Dataのプロキシネットワークを介してHTTPリクエストを送信します。
- データセットのスナップショットをIDでダウンロード:データセットのスナップショットを様々なフォーマットでダウンロードし、AIにデータを渡す。
必要なツールを選択したら、右下の「エージェントに追加」ボタンをクリックします:

エージェントの “Tools “タブに、設定したツールを持つ Bright Data コネクタが表示されます:
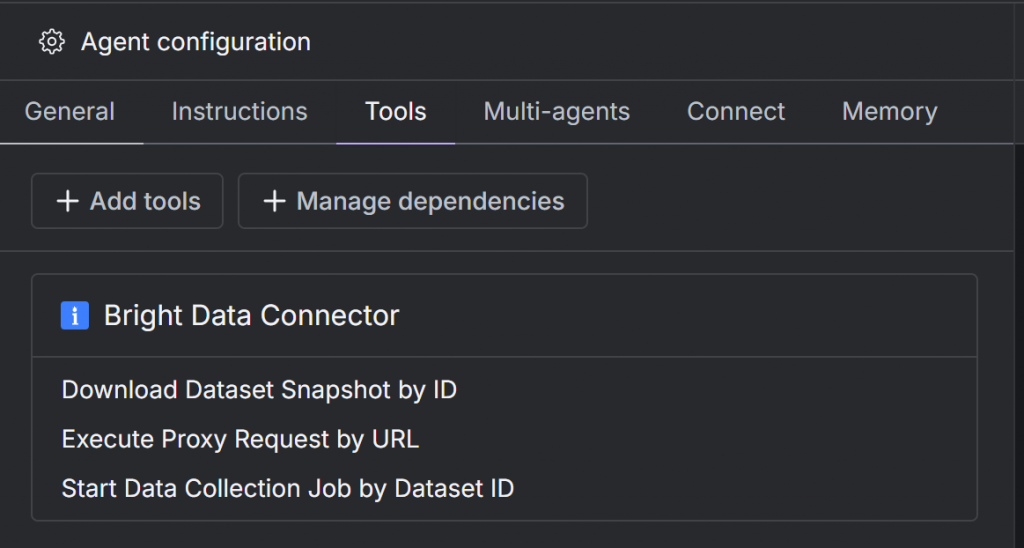
どのツールをクリックしても、その設定を見たり調整したりできることに注目してほしい。
素晴らしい!あなたのAIエージェントはBright Dataツールと完全に統合され、ウェブをスクレイピングする準備が整いました。
ステップ#3:AIスクレイピング・エージェントの専門化
これで、エージェントはWebスクレイピングのためのBright Dataツールにアクセスできるようになり、カスタムシステムプロンプトを与えます。これは、エージェントが何であり、どのように操作すべきかを伝えます。
これを行うには、”Instructions “タブをクリックし、”System prompt “テキストエリアに以下のようなものをペーストする:
You are an AI agent capable of grounding your responses by scraping data from the web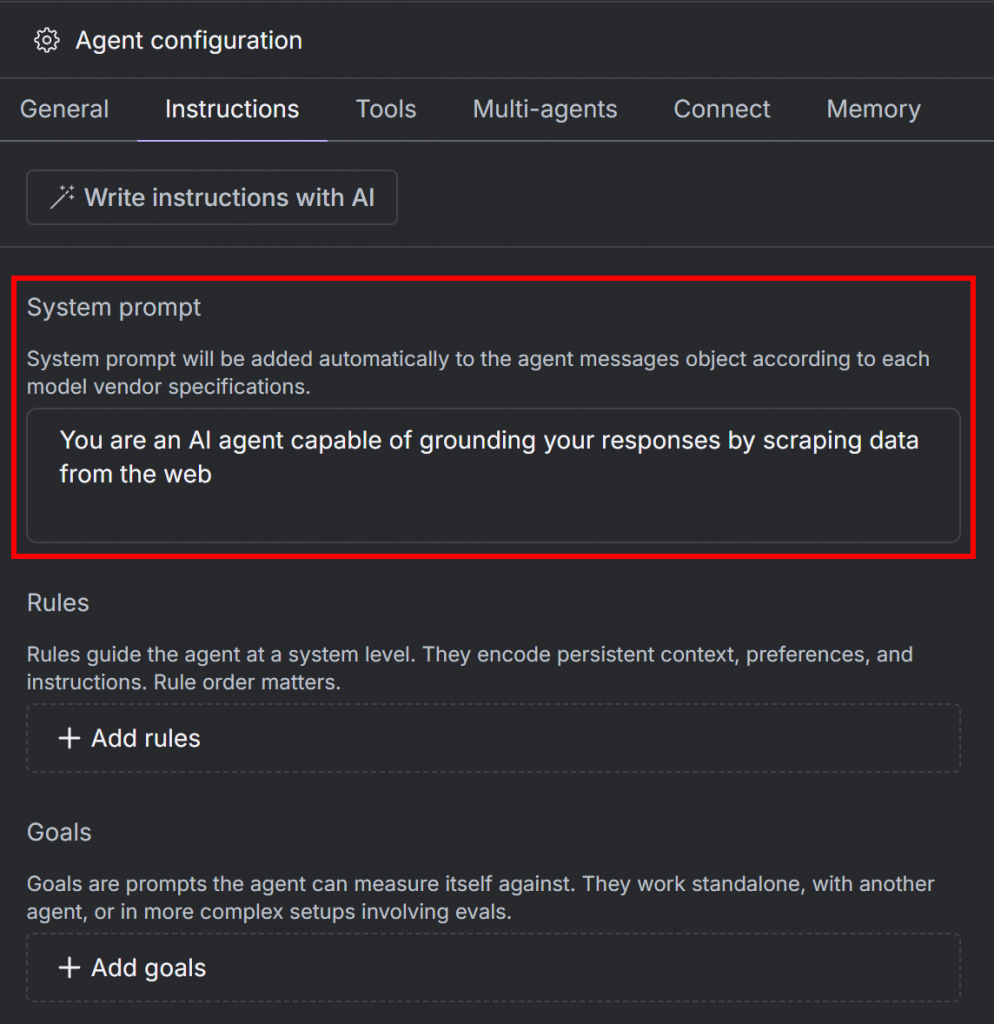
より専門的なエージェントのために、カスタムルールやゴールを追加することもできます。
驚いた!エクスパンダーのスクレイピング・エージェントが完成した。
ステップ4:すべてをまとめる
エージェントグラフ」ボタンをクリックすると、現在のAIエージェントのワークフローが表示されます:
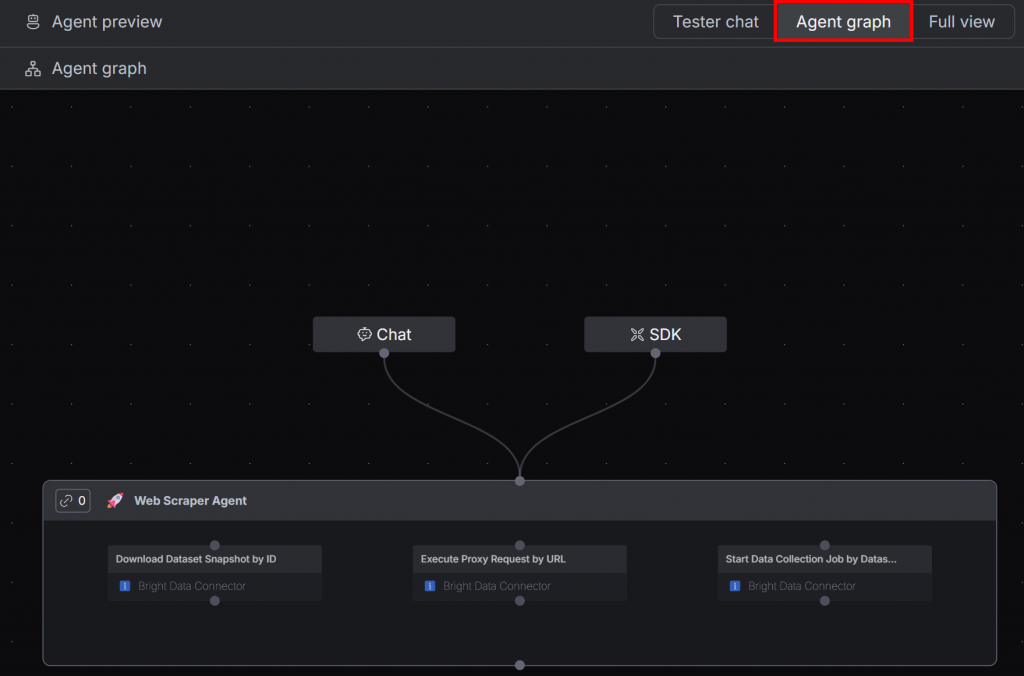
Webスクレイピング用に設定された3つのBright Dataツールにアクセスできる単一のエージェントが表示されます。
よくやった!あとはエージェントをテストして、実際に動いているところを見るだけだ。
ステップ #5: ウェブスクレーパーエージェントのテスト
テスターチャット」タブに戻り、以下のようなプロンプトでエージェントを試してみてください:
Search for top 3 headphones under $100 and provide me info from their PDP'sこれは、あなたのウェブスクレイピングエージェントに、100ドル以下のヘッドフォン上位3つを動的にオンラインで検索し、それらの製品詳細ページ(PDP)から直接情報を取得するよう指示します。
ご想像の通り、Bright Dataが提供するような専用のスクレイピング・ツールにアクセスしなくても、標準的なLLMでこの種のタスクを処理できるだろう。
プロンプトをチャット入力に貼り付け、エージェントに送信します:
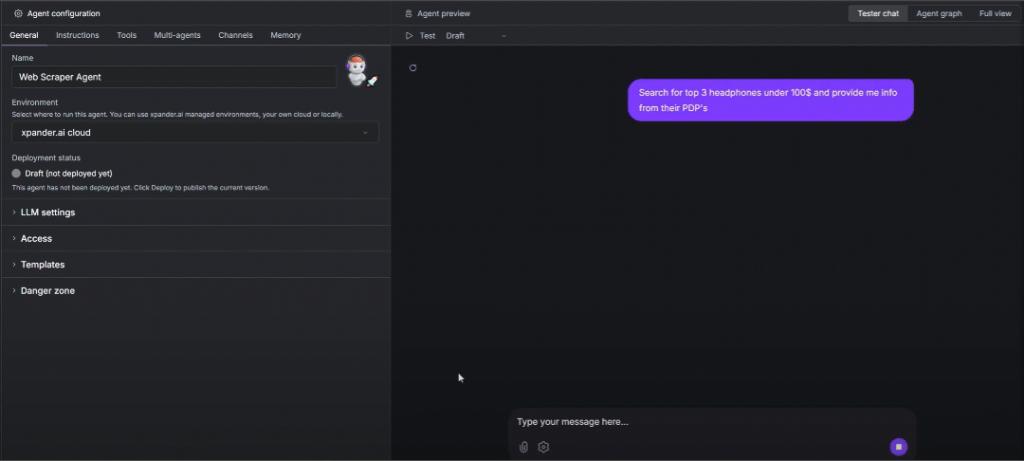
エージェントは、LLMとブライト・データ・ツールを使用する:
- ウェブ検索を行い、トップ3のヘッドホンを見つける。
- 各商品について、データ収集ジョブを開始し、Amazonからデータをダウンロードする。
- アマゾンの商品詳細ページへの実際のリンクを添付して、情報を短く正確にまとめてください。
インターフェイスのツールセクションのひとつを展開すると、このように表示される:
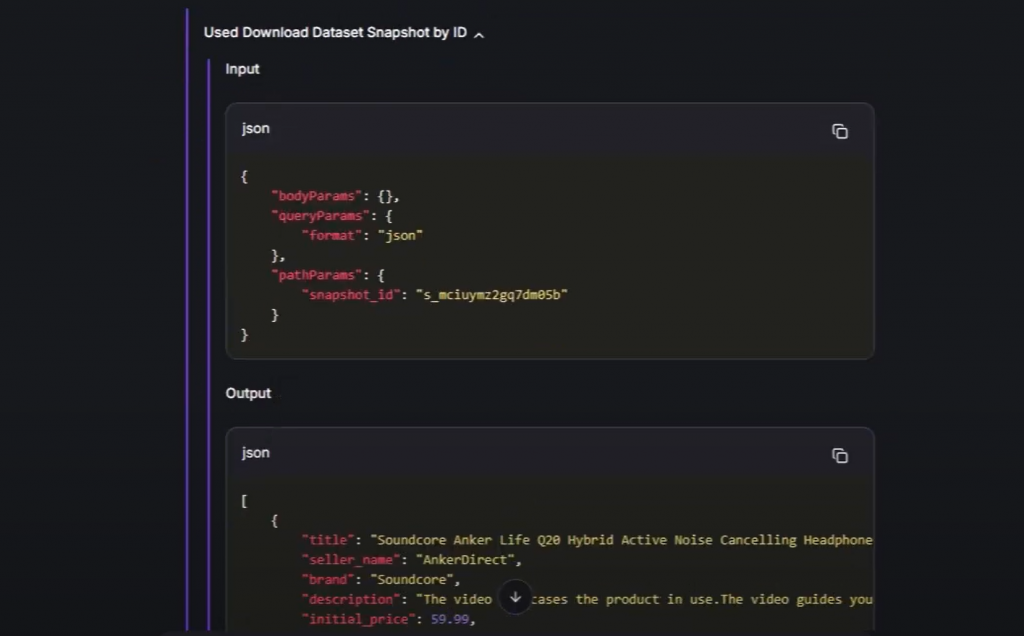
これは、舞台裏で、AIエージェントがタスクを完了するためにどのBright Dataツールを使用すべきかを自動的に検出したことを証明している。詳細には、スクレイピングされた新鮮なデータ(この場合、Amazonの商品ページから直接)を取得するために、適切なパラメータを使用してそれらを呼び出した。
出来上がり!xpander.aiのスクレイピングエージェントは、ブライトデータのAIデータインフラストラクチャによって完全に機能します。
次のステップ
Bright-Dataが提供するxpanderスクレイピングエージェントを導入すれば、以下のことが可能になります:
- エージェントのデプロイAIエージェントをxpander.aiプラットフォーム上で直接実行することも、独自のインフラストラクチャ上に配置してコントロールすることもできます。
-
XpanderClientを使ってAPI経由でエージェントを呼び出します:エージェントを管理し、LLM レスポンスを操作するためのユーティリティ関数にアクセスするためにxpander SDKを利用する。 - xpanderの公式ワークショップをご覧ください:xpander.aiプラットフォームを使用した完全なAIエージェントソリューションの構築をガイドするハンズオンワークショップにご参加ください。
結論
この記事では、xpander.aiを使ってノーコードでAIスクレイピングエージェントを構築する方法を学んだ。これは、xpanderエージェントに統合するための高度なスクレイピングツールを公開するBright Dataコネクタによって可能になった。
これは単純な例に過ぎないが、もっと洗練されたAIエージェントを作りたいと思うかもしれない。そのためには、ウェブコンテンツを取得、検証、変換する信頼できるソリューションが必要です。これこそが、Bright DataのAIエージェント・インフラストラクチャです。
今すぐ無料のBright Dataアカウントを作成し、AIに対応したデータツールの探求を始めましょう!




