

このガイドの中で、あなたは見ることができる:
- 微調整とは何か。
- n8nによるウェブスクレーパーAPIでGPT-4oを微調整する方法。
- 微調整アプローチの比較。
- なぜ高品質なデータが微調整の中心なのか?
さあ、飛び込もう!
微調整とは何か?
ファインチューニングは、教師ありファインチューニング(SFT)とも呼ばれ、事前訓練されたLLMの特定の知識や能力を向上させるための手順である。LLMの文脈では、事前トレーニングとは、AIモデルをゼロからトレーニングすることを指します。
微調整が重要なのは、モデルが訓練データを模倣するからである。つまり、トレーニング後にLLMをテストすると、その出力は何らかの形でトレーニングデータに従うことになる。LLMは一般論的なモデルであるため、特定の知識を獲得させたい場合は、特定のデータに合わせて微調整する必要がある。
SFTについてもっと知りたい方は、LLMにおけるスーパーバイズド・ファインチューニングについてのガイドをお読みください。
Bright Data n8nとの統合でGPT-4oを微調整する方法
最近のチュートリアルで取り上げたように、Web Scraper APIを使ってスクレイピングされたデータを使って、クラウドを使用してLlama 4を微調整する方法はお分かりいただけたと思います。このガイドセクションでは、人気のワークフロー自動化プラットフォームであるn8nを使用してGPT-4oを微調整することで、同じ結果を達成します。
詳しくは、同じターゲット・ウェブページ、つまりアマゾンのベストセラー・オフィス用品ページを参照する:
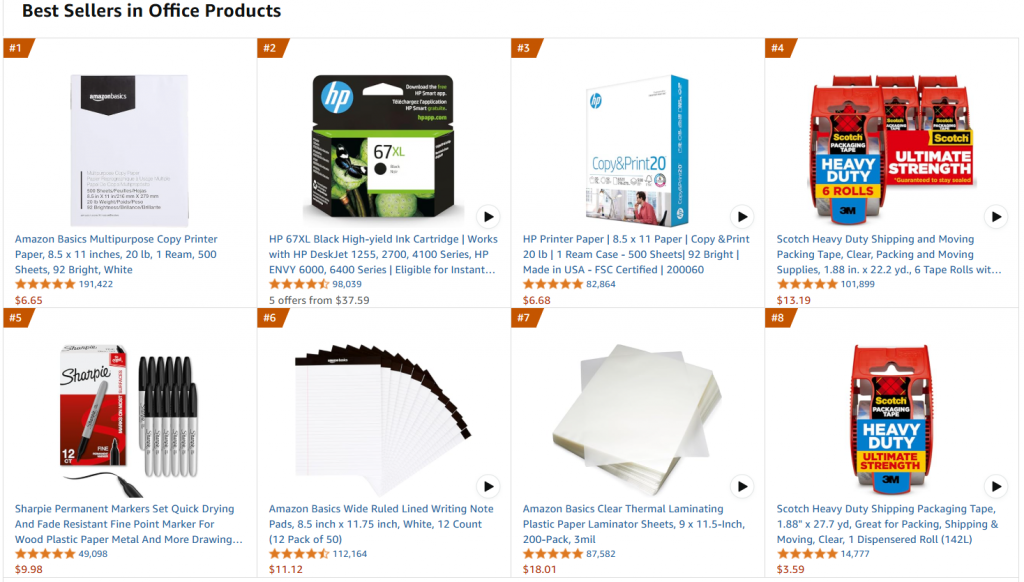
このプロジェクトの目標は、GPT-4o-miniを微調整して、プロンプトにいくつかの特徴を入力すると、オフィスライクな商品説明を作成できるようにすることである。
以下のステップに従って、Bright Dataのソリューションでスクレイピングしたトレーニングデータセットを使用して、n8nを使用してGPT-4o-miniを微調整する方法を学んでください!
必要条件
この微調整を再現するには、以下のものが必要だ:
- アクティブなBright Data API トークン。
- アクティブなn8nアカウント。
- OpenAI APIトークン。
素晴らしい!これでGPT-4oの微調整を始める準備が整った。
ステップ#1: 新しいn8nワークフローを作成し、Bright Data Nodeをインストールする。
n8nにログインすると、ダッシュボードは以下の画像のようになる:
新しいワークフローを作成するには、”Create Workflow “ボタンをクリックします。次に「ノードパネルを開く」をクリックします:
ノードパネルでBright Dataのノードを検索する。n8nでは、”ノード “は自動化されたワークフローの構成要素であり、データ処理パイプラインの明確なステップやアクションを表します。
Bright Data n8nノードをクリックしてインストールします:

詳しくは、n8nのBright Dataの設定方法に関する公式ドキュメントのページをご参照ください。
よくできました!あなたは最初のn8nワークフローを初期化した。
ステップ2:ブライト・データ・ノードのセットアップとデータのスクレイピング
UIで “Add first step “をクリックし、”Trigger manually “を選択する:
このノードでは、ワークフロー全体を手動でトリガーすることができます。
手動トリガーノードの右側にある “+”をクリックし、Bright Dataを検索する。Web scraper actions “セクションから、”scrape data synchronously by URL “をクリックします:
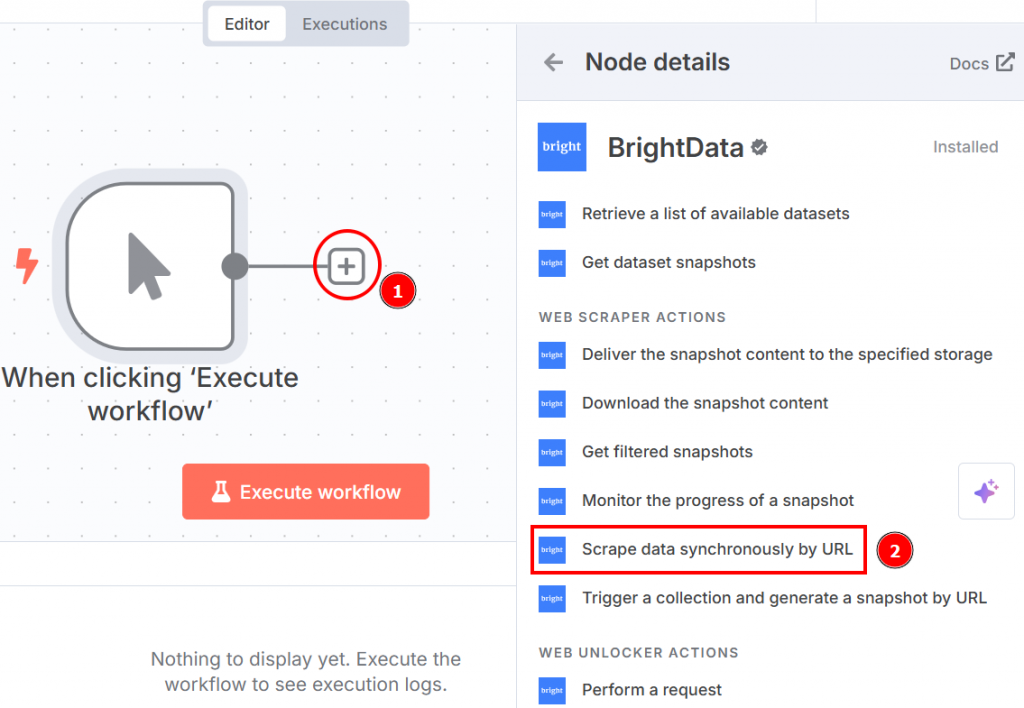
以下は、ノードをクリックしたときに表示されるノードの設定です:

以下のように設定する:
- “Credential to connect with “をクリックします:それをクリックし、Bright Data API トークンを追加します。認証情報が保存されます。
- “操作”:URLでスクレイピング」オプションを選択する。これにより、ウェブスクレイパーAPIがデータを抽出するターゲットページとして使用するURLのリストを渡すことができる。
- “データセット”:Amazon best seller products “オプションを選択する。これは、アマゾンのベストセラー商品からデータを抽出するために最適化されています。
- “URL”:アマゾンのベストセラーのオフィス用品ページに行き、少なくとも10個のURLのリストをコピー&ペーストしてください。OpenAI Chatノードは少なくとも10個のURLを必要とするからです。10個未満を渡すと、OpenAIノードはターゲットLLMの微調整中にエラーを返します。
- 「フォーマットWeb Scraper APIは複数の出力形式をサポートしているので、「JSON」データ形式を選択します。
以下は、これまでのワークフローの様子である:

Execute workflow “ボタンを押すと、スクレイピングされたデータがBright Dataのノード内のoutputセクションに表示されます:
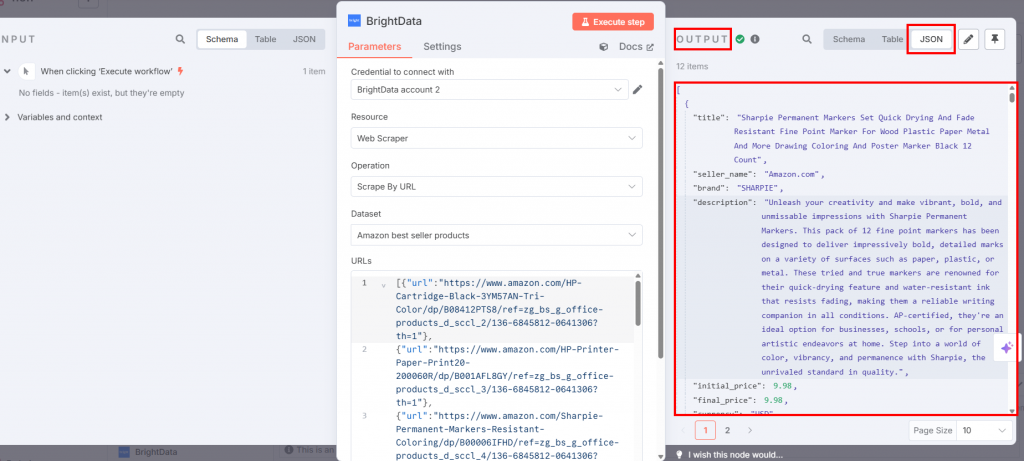
素晴らしい!Bright DataのWeb Scraper APIを使って、コードを一行も書くことなく、必要なターゲットデータをスクレイピングしました。
ステップ3:コードノードのセットアップ
Bright DataノードのCodeノードを接続し、”Language “ボックスでJavaScriptを選択します:

JavaScript」フィールドに、以下のコードを貼り付ける:
// get all incoming items
const allInputItems = $input.all();
let jsonlString = "";
// define the training prompt
const systemMessage = "You are an expert marketing assistant specializing in writing compelling and informative product descriptions.";
// loop through each item retrieved from the input
for (const item of allInputItems) {
const product = item.json;
// validate if the product data exists and is an object
if (!product || typeof product !== 'object') {
console.warn('Skipping an item because product data is missing or not an object:', item);
continue;
}
// extract product data
const title = product.title || "N/A";
const brand = product.brand || "N/A";
let featuresString = "Not specified";
if (product.features && Array.isArray(product.features) && product.features.length > 0) {
featuresString = product.features.slice(0, 5).join(', ');
}
// create a snippet of the original product description for training
const originalDescSnippet = (product.description || "No original description available.").substring(0, 250) + "...";
// create prompt with specific details about the product
const userPrompt = `Generate a product description for the following item. Title: ${title}. Brand: ${brand}. Key Features: ${featuresString}. Original Description Snippet: ${originalDescSnippet}.`;
// create template for the kind of description the AI should generate
let idealDescription = `Discover the ${title} from ${brand}, a top-choice for discerning customers. `;
idealDescription += `Key highlights include: ${featuresString}. `;
if (product.rating) {
idealDescription += `Boasting an impressive customer rating of ${product.rating} out of 5 stars! `;
}
idealDescription += `This product, originally described as "${originalDescSnippet}", is perfect for anyone seeking quality and reliability. `;
idealDescription += `Don't miss out on the ${product.availability === "In Stock" ? "readily available" : "upcoming"} ${title} – enhance your collection today!`;
// create a training example object in the format expected by OpenAI
const trainingExample = {
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userPrompt },
{ role: "assistant", content: idealDescription }
]
};
jsonlString += JSON.stringify(trainingExample) + "n";
}
// remove any leading or trailing whitespace
const fileContentString = jsonlString.trim();
// check if any product data was actually processed
if (fileContentString.length === 0) {
console.warn("No product data was processed, outputting empty file content.");
return [{
json: { error: "No products processed", fileNameToUse: "data.jsonl" },
binary: {}
}];
}
// convert the final JSONL string into a Buffer (raw binary data)
const buffer = Buffer.from(fileContentString, 'utf-8');
// define the filename that will be used when this data is sent to OpenAI
const actualFileNameForOpenAI = "data.jsonl";
// define the MIME type for the file
const mimeType = 'application/jsonl';
// prepare the binary data for output
const binaryData = await this.helpers.prepareBinaryData(buffer, actualFileNameForOpenAI, mimeType);
// return the processed data
return [{
json: {
processedFileName: actualFileNameForOpenAI
},
binary: {
// the "Input Data Field Name" in the OpenAI node
"data.jsonl": binaryData
}
}];このノードの入力は、Bright Dataからスクレイピングされたデータを含むJSONファイルである。しかし、OpenAIノードはJSONLファイルを必要とする。このJavaScriptコードは、以下のようにJSONをJSONLに変換する:
- このメソッドは、
$input.all()というメソッドを使って、前のノードから来たすべてのデータを取得します。 - 商品を反復処理する。特に、各商品アイテムに対して
タイトル、ブランド、機能、説明、評価、在庫などの商品詳細を抽出します。特定のデータが欠落している場合のフォールバック値も含まれています。- LLMが商品説明を生成するためのリクエストにこれらの詳細をフォーマットすることで、
userPromptを構築します。 - 商品の属性を組み込んだテンプレートを使用して
idealDescriptionを生成します。これは、トレーニングデータで望ましい「アシスタント」応答として機能します。 - システムメッセージ、
userPrompt、idealDescriptionを1つのtrainingExampleオブジェクトにまとめ、会話型LLMトレーニング用にフォーマットします。 - この
trainingExampleをJSONストリングにシリアライズし、各JSONオブジェクトを新しい行(JSONLフォーマット)にして、成長しているストリングに追加します。
- すべての項目を処理した後、蓄積されたJSONL文字列をバイナリデータの
Bufferに変換する。 data.jsonlというファイルが返される。
Codeノードで “Execute step “をクリックすると、出力セクションにJSONLが表示されます:
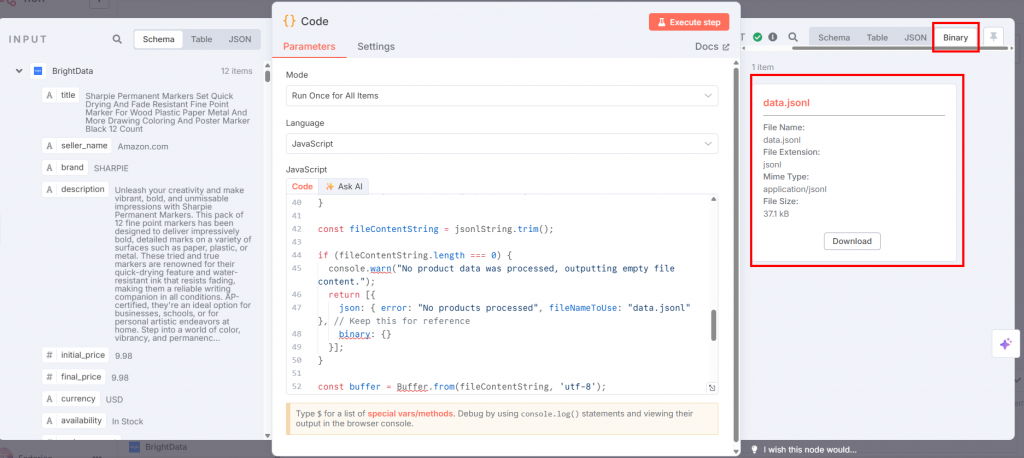
以下は、これまでのワークフローの様子である:
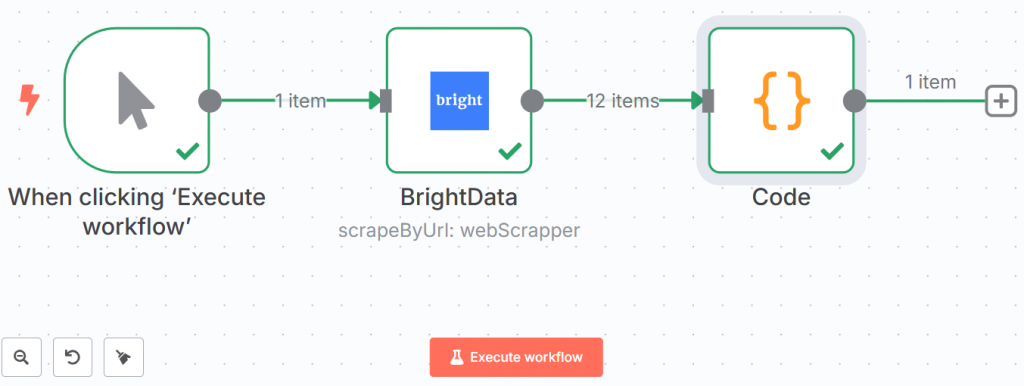
緑色の線と目盛りは、すべてのステップが正常に完了したことを示している。
万歳!Bright Dataを使ってデータを取得し、JSONL形式で保存しました。これでLLMにプッシュする準備ができました。
ステップ #4: OpenAIチャットノードに微調整データをプッシュする
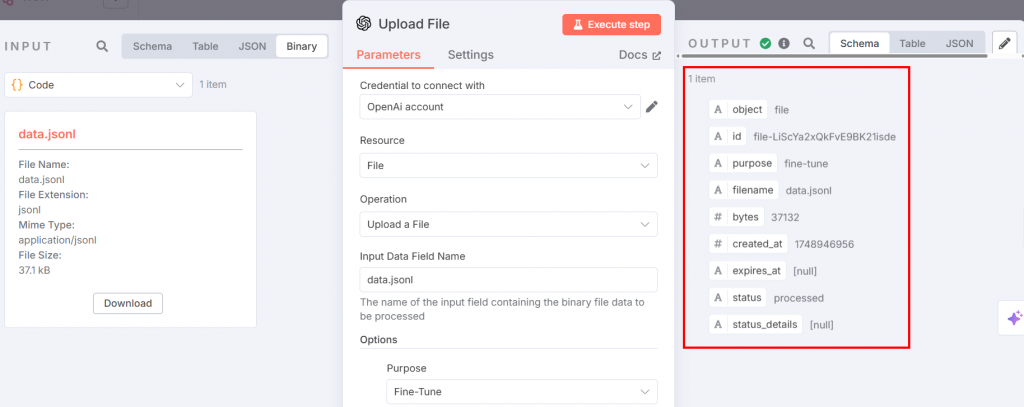
微調整用のJSONLファイルは、微調整のためにOpenAIプラットフォームにアップロードする準備ができています。これを行うには、OpenAIのノードを追加します。File actions “セクションで “Upload a file “を選択します:

以下は、必要な設定です:

上記のノードは、微調整プロセスの入力を与える。パラメータは以下のように設定する:
- “Credential to connect with “をクリックします:OpenAI APIトークンを追加します。設定すると、認証情報が保存されます。
- 「リソースFile “を選択する。これは、プラットフォームにJSONLファイルをアップロードするためです。
- “操作 “を選択します:ファイルのアップロード」を選択します。
- “入力データ・フィールド名”:微調整ファイルの名前は
data.jsonl。 - Options “セクションで、”Purpose “を追加し、”Fine-tune “を選択する。
ステップ実行後、出力は以下のようになる:
これで、ワークフローは次のようになる:
驚いた!微調整のための準備はすべて整った。いよいよ本番だ。
ステップ5:LLMの微調整
実際の微調整を行うには、OpenAIのノードにHTTP Requestノードを接続します:

設定は以下の通り:
- トレーニングデータファイルをアップロードするため、”Method “は “POST “でなければなりません。
- URL “フィールドは、
https://api.openai.com/v1/fine_tuning/jobsエンドポイントでなければなりません。これは OpenAI プラットフォームでジョブを微調整するための標準的な URL です。 - Authentication “フィールドでは、”Predefined Credential Type “を選択し、OpenAI APIトークンを使用するようにします。
- ノードが OpenAI に接続するように、”Credential Type “で “OpenAi “を選択する。
- OpenAI “ボックスでは、OpenAIのアカウント名を選択します。
- Send Body “トグルを有効にする。”Body Content Type “と “Specify Body “フィールドで、それぞれ “JSON “と “Using JSON “を選択する。
JSONフィールドは以下を含む必要がある:
{
"training_file": "{{ $json.id }}",
"model": "gpt-4o-mini-2024-07-18"
} このJSON:
- トレーニングデータの名前を
$json.idで指定します。 - 微調整に使用するモデルを定義します。この場合、2024-07-18にリリースされたバージョンのGPT-4o-miniを使用します。
以下は、あなたが受け取る出力です:
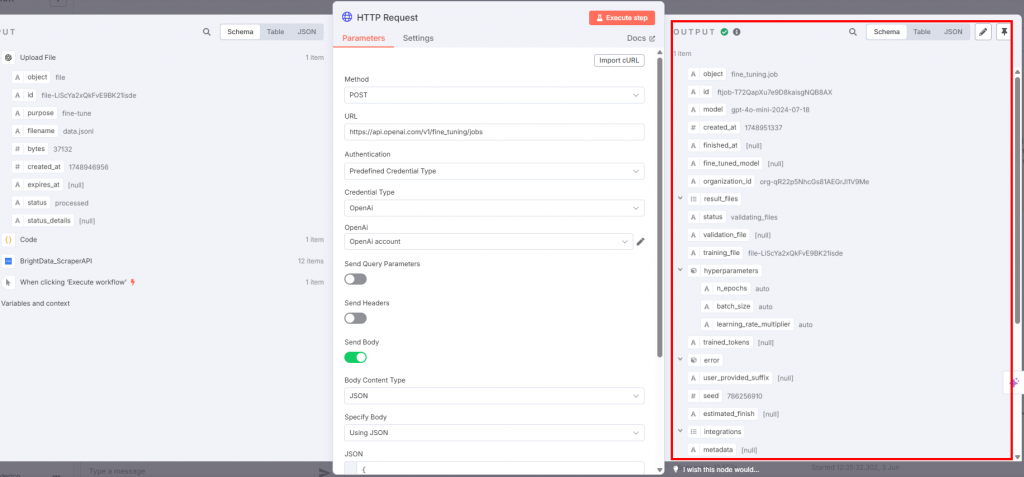
HTTP Requestノードがトリガーされると、ファインチューニングプロセスが始まります。OpenAIプラットフォームのファインチューニングセクションで、その進捗を見ることができます。ファインチューニングプロセスが正常に完了すると、OpenAIはステップ#7で使用するファインチューニングされたモデルを提供します:

n8nのワークフローは以下のようになるはずだ:

おめでとうございます!n8nを通じてBright DataのScraper APIで取得したデータを使用して、最初のGPTモデルをトレーニングしました。
これは、ワークフロー全体の前半の最後のノードである。
ステップ6: チャットノードの追加
ワークフロー全体の後半は、チャット・トリガー・ノードから始める必要があります。そこに、微調整されたLLMをテストするプロンプトを挿入します:

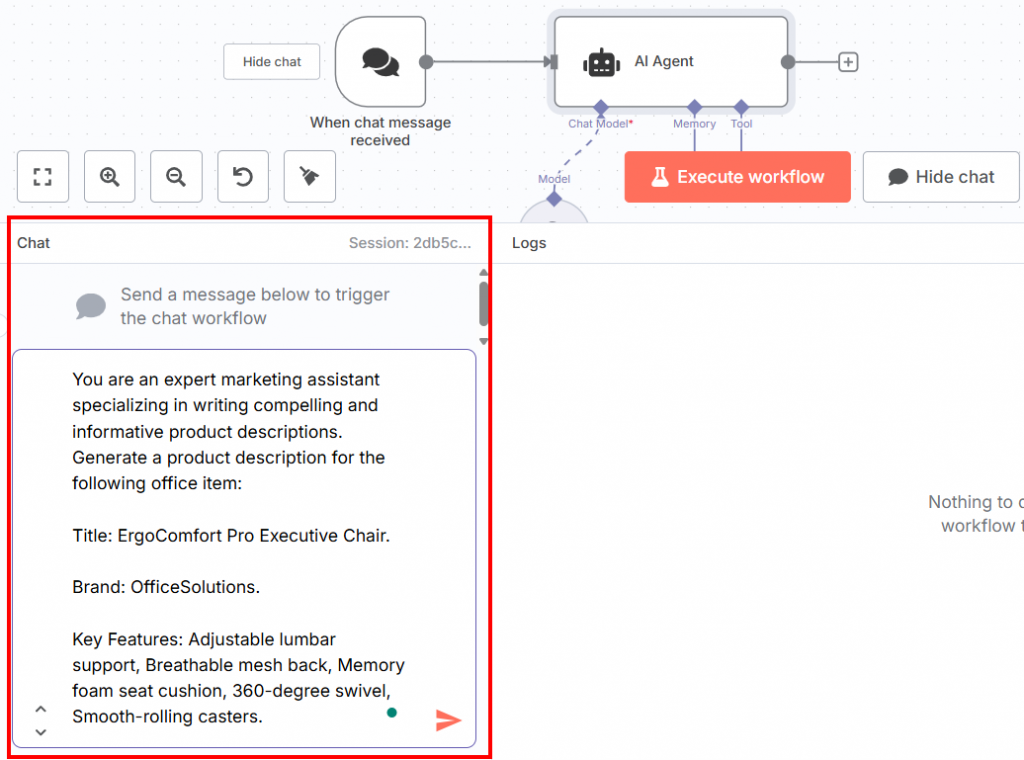
以下は、チャットに挿入できるプロンプトです:
You are an expert marketing assistant specializing in writing compelling and informative product descriptions. Generate a product description for the following office item:
Title: ErgoComfort Pro Executive Chair.
Brand: OfficeSolutions.
Key Features: Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters.ご覧の通り、このプロンプトは
- トレーニングの段階で使われた、マーケティング・アシスタントの専門家であることに関する同じフレーズを報告する。
- で定義された必要なオフィスアイテムの情報が与えられた場合、商品説明を生成するよう求める:
- タイトルだ。
- ブランドだ。
- オフィス製品の主な特徴。
プロンプトの構造がそのようになっていることが重要である。この段階では、モデルはトレーニングデータを模倣するからだ。そのため、学習フェーズで使用したものと同様のプロンプトとデータを与える必要がある。そうすると、微調整されたLLMが、それらの要素に基づいて商品の説明を書いてくれる。
UIの下部にあるチャットセクションにプロンプトを挿入することができます:
これが現在のn8nのワークフローだ:
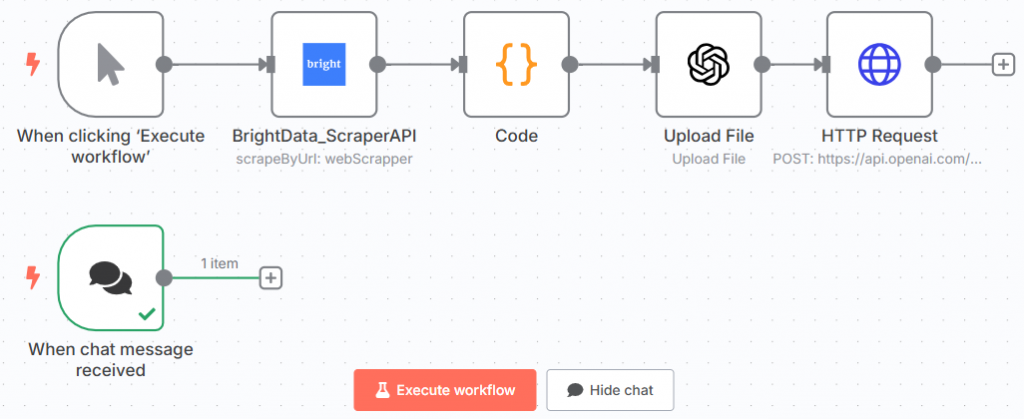
素晴らしい!あなたは微調整モデルをテストするためのプロンプトを定義した。
ステップ #7: AI エージェントと OpenAI チャットノードを追加する
AIエージェントノードをチャットトリガーに接続する必要があります:

設定はこうでなければならない:
- “エージェント”:”会話エージェント “を選択します。これにより、他の会話エージェントと同じように、チャットトリガーノードを使って何でも変更することができます。
- チャットから直接プロンプトをインジェストできるように、”プロンプトのソース(ユーザーメッセージ)”を “接続されたチャットトリガーノード “に設定します。
チャットモデル “接続オプションを使って、OpenAIチャットモデルノードをAIエージェントに接続します:

下の図は OpenAI Chat Model ノードの設定です:

以下のようにノードを設定する:
- “Credential to connect with “を選択します:保存したOpenAIの認証情報を選択します。
- “モデル”:OpenAIプラットフォームの微調整セクションから微調整された出力モデルを貼り付けます。
AI Agentノードに戻り、”Execute step “ボタンをクリックします。製品の説明文が表示されます:
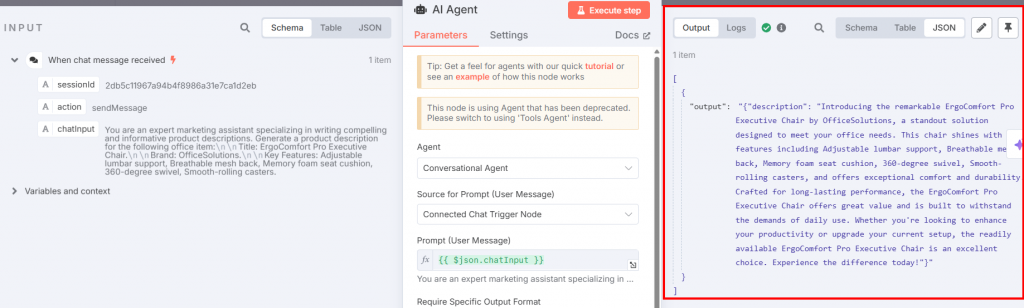
以下は、その結果のプレーンテキストでの説明である:
Introducing the remarkable ErgoComfort Pro Executive Chair by OfficeSolutions, a standout solution designed to meet your office needs. This chair shines with key features including Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters, and offers exceptional comfort and durability. Crafted for long-lasting performance, the ErgoComfort Pro Executive Chair offers great value and is built to withstand the demands of daily use. Whether you're looking to enhance your productivity or upgrade your current setup, the readily available ErgoComfort Pro Executive Chair is an excellent choice. Experience the difference today!ご覧のように、この説明文は、対象物のタイトル名(「ErgoComfort Pro Executive Chair」)、ブランド名(「OfficeSolutions」)、およびすべての機能を活用して、製品の説明文を生成しています。特に、説明文は入力されたデータをただ羅列するのではなく、それを活用して魅力的な説明文を作成している。最後のフレーズが鍵だ:
- 「長持ちするように作られたエルゴコンフォート・プロ・エグゼクティブ・チェアは、日々の使用に耐えるように作られています。
- 「エルゴコンフォート・プロエグゼクティブチェアは、生産性を高めたい方にも、今お使いのチェアをアップグレードしたい方にも最適です。今すぐその違いを体験してください。”
出来上がり!あなたは微調整したGPT-4o-miniモデルをテストし、与えられたプロンプト(ステップ#6で定義)に答える商品説明を生成しました。
ステップ8:すべてをまとめる
最終的なGTP-4o n8nの微調整ワークフローは次のようになる:

ワークフローの設定が完了したので、「ワークフローを実行」をクリックすると、再度最初からワークフローが実行される。ただし、結果は各ステップで保存される。つまり、微調整されたモデルをテストするために異なるプロンプトを試したい場合、チャットトリガーノードにそれらを書き込み、そのノードとAIエージェントノードを実行するだけでよい。
微調整アプローチの比較:クラウドインフラとワークフローの自動化
このガイドが作られた理由は2つある:
- n8nのようなワークフロー自動化ツールを使って、LLMを微調整する方法を教える。
- LLMを微調整するこの方法を、我々の記事 “Fine-Tuning Llama 4 with Fresh Web Data for Better Results“で使用した方法と比較する。
2つのアプローチを比較する時が来た!
微調整法の比較
ラマ4を微調整するには、前回の記事で紹介したアプローチが必要だ:
- クラウドインフラを使用するため、設定に時間がかかり、コストがかかる。
- Bright DataのスクレイパーAPIを使ってデータを取得するコードを書く。
- ハギング・フェイスをセットアップする。
- 微調整のためにPythonコードでノートブックを開発する必要があるが、これには時間と技術的スキルが必要である。
必要な技術的能力を見積もることはできない。しかし、インフラ全体をセットアップするのに必要な全時間と、費やされる資金を見積もることはできる:
- 時間:丸一日
- お金:25ドル。クラウド・サービスに25ドル使用すると、1時間あたりの使用量になります。同時に、開始前に25ドルを支払う必要がある。つまり、これがクラウドを利用するための最低価格となる。
このガイドで学んだアプローチが必要なのだ:
- n8nは無料で使用でき、技術的な専門知識もあまり必要としない。
- GPT-4oや他のモデルにアクセスするためのOpenAI APIトークン。
- 基本的なコーディングスキル、特にCodeノード用のJavaScriptスニペットを書くことができる。
この場合、技術的な能力ははるかに低い。JavaScriptのスニペットは、LLMであれば誰でも簡単に作ることができる。それ以外には、ワークフロー全体で他のコード・スニペットを書く必要はない。
この場合、インフラを整えるのに必要な時間と必要な資金は次のように見積もることができる:
- 時間:約半日
- お金:OpenAIのAPIトークンが10ドル。この場合でも、APIリクエストごとに支払うことになる。それでも10ドルから始められる。n8nのライセンスは現在、ベーシックプランで月額25ドル、セルフホストバージョンを利用する場合は完全無料です。つまり、始めるには約10ドル必要なのだ。
どのアプローチを選ぶべきか?
| アスペクト | クラウド・インフラ・アプローチ | ワークフロー自動化のアプローチ |
|---|---|---|
| テクニカル・スキル | 高い(Python、クラウド、データ検索のコーディングスキルが必要) | 低い(基本的なJavaScript) |
| 準備期間 | 丸一日 | 約半日 |
| 初期費用 | ~クラウドサービス最低25ドル+時間給 | ~OpenAI APIトークン10ドル + n8nライセンス24ドル/月 またはセルフホスト無料 |
| 柔軟性 | 高い(高度なカスタマイズや様々なユースケースに適している) | 中程度(ワークフローの自動化やローコードカスタマイズに適している) |
| 最適 | 強力で柔軟なインフラを必要とする高い技術力を持つチーム | 迅速なセットアップを求めるチームや、コーディングの専門知識が乏しいチーム |
| その他の特典 | 環境とプロセスの微調整を完全にコントロール | 事前構築されたテンプレート、低い参入障壁、他のワークフローとの統合 |
この2つのアプローチは、時間的にも金銭的にも同じような初期投資を必要とする。では、どちらを選ぶべきか?ここにいくつかのガイドラインがある:
- n8n他のワークフローを自動化する必要がある場合、また、あなたのチームが高度な技術的スキルを持っていない場合、LLMを微調整するために、n8nまたは類似のワークフロー自動化ツールを選択します。このローコードアプローチは、他のワークフローを自動化するのに役立ちます。カスタマイズが必要な場合にのみコードを書く必要があります。また、無料で使用できる構築済みテンプレートも提供されているため、ツールを使用するための参入障壁が低くなっている。
- クラウドサービス:LLMの微調整を複数の目的で必要とし、高度な技術を持つチームがある場合は、クラウドサービスを選択する。クラウド環境の構築や微調整用ノートの開発には、高度な技術的専門知識が必要です。
微調整プロセスの核心:質の高いデータ
どちらのアプローチを選択しても、ブライト・データはその両方の重要な仲介役であり続けます。理由は簡単で、高品質のデータが微調整プロセスの基礎となるからです!
ブライト・データは、お客様のAIアプリケーションをサポートする様々なサービスとソリューションを提供し、データ用AIインフラでお客様をカバーします:
- MCPサーバー:AIエージェントのデータ検索のための20以上のツールを公開するオープンソースのNode.js MCPサーバー。
- ウェブスクレーパーAPI:100以上の主要ドメインから構造化データを抽出するための設定済みAPI。
- ウェブアンロッカー:ボット対策が施されたサイトのロック解除を行うオールインワンAPI。
- SERP API:検索エンジンの結果をアンロックし、完全なSERPデータを抽出する特別なAPIです。
- 基礎モデルLLMの事前学習、評価、微調整のために、準拠したウェブスケールのデータセットにアクセスできます。
- データプロバイダー:信頼できるプロバイダーと接続し、高品質でAIに対応したデータセットを大規模に調達。
- データパッケージ:構造化、エンリッチ化、アノテーションが施された、すぐに使えるデータセットを入手。
このガイドでは、Web Scraper APIを使用してデータをスクレイピングするGPT-4o-miniを微調整する方法を説明しましたが、当社のサービスを使用して別のアプローチを選択することもできます。
結論
この記事では、Amazonからスクレイピングしたデータを使ってGPT-4o-miniを微調整する方法を学びました。あなたは2つの分岐からなるプロセス全体を経験しました:
- データをスクレイピングした後、微調整を行う。
- チャットトリガーを介してプロンプトを挿入することにより、微調整されたモデルをテストする。
また、ワークフロー自動化ツールを使用するこのアプローチと、クラウドサービスを使用する別のアプローチを比較しましたね。
貴社のニーズとチームに最適なアプローチに関わらず、高品質のデータがプロセスの中核であることに変わりはありません。この点に関して、ブライト・データはAI向けのデータ・サービスを提供しています。
ブライトデータのアカウントを無料で作成し、AI対応のデータインフラをお試しください!





