
このガイドで、あなたは学ぶだろう:
- Pydantic AIとは何か、AIエージェントを構築するためのフレームワークとして何がユニークなのか。
- Pydantic AIがBright DataのWeb MCPサーバーとうまく組み合わされ、ウェブにアクセスできるエージェントを構築できる理由。
- PydanticをBright DataのWeb MCPと統合し、実データに裏打ちされたAIエージェントを作成する方法。
さあ、飛び込もう!
パイダンティックAIとは何か?
Pydantic AIは、Python用のデータ検証ライブラリとして最も広く使われているPydanticの開発者によって開発されたPythonエージェントフレームワークです。
他のAIエージェントフレームワークと比較して、Pydantic AIは型の安全性、構造化された出力、実世界のデータやツールとの統合を重視しています。その主な特徴は以下の通りである:
- OpenAI、Anthropic、Gemini、Cohere、Mistral、Groq、HuggingFace、Deepseek、Ollama、その他のLLMプロバイダーをサポート。
- Pydanticモデルによる構造化出力検証。
- Pydantic Logfireによるデバッグとモニタリング。
- ツール、プロンプト、バリデータの依存性注入(オプション)。
- オンザフライのデータ検証でLLM応答をストリーミング。
- 複雑なワークフローをマルチエージェントとグラフでサポート。
- MCPを介したツール統合とHTTPコールを含む。
- 標準的なPythonアプリのようにAIエージェントを構築するための、使い慣れたPythonicフロー。
- 単体テストと反復開発のための組み込みサポート。
このライブラリはオープンソースで、GitHub上ではすでに11kスターを超えている。
Pydantic AIとMCPサーバーを組み合わせてウェブデータを検索する理由
Pydantic AIで作られたAIエージェントは、基礎となるLLMの限界を受け継いでいる。これにはリアルタイムの情報へのアクセス不足が含まれ、不正確な応答につながる可能性があります。幸いなことに、この問題はエージェントに最新のデータとライブのウェブ探索機能を装備することで簡単に解決できます。
そこでBright DataのWeb MCPの登場です。Node.js上に構築されたこのMCPサーバーは、Bright DataのAI対応データ検索ツール群と統合されています。これらのツールは、ウェブコンテンツへのアクセス、構造化されたデータセットへのクエリ、ウェブの検索、ウェブページとのオンザフライでの対話をエージェントに可能にします。
現在のところ、サーバーのMCPツールには以下のものがある:
| 工具 | 説明 |
|---|---|
scrape_as_markdown |
高度な抽出オプションを使用して、単一のWebページのURLからコンテンツをスクレイピングし、結果をMarkdownとして返します。ボット検知やCAPTCHAを回避することができます。 |
検索エンジン |
Google、Bing、またはYandexから検索結果を抽出し、SERPデータをマークダウン形式で返します(URL、タイトル、スニペット)。 |
scrape_as_html |
高度な抽出オプションでURLからウェブページのコンテンツを取得し、完全なHTMLを返します。ボット検出やCAPTCHAをバイパスすることができます。 |
セッション統計 |
現在のセッション中のツール使用に関する統計を提供する。 |
スクレイピング_ブラウザ_ゴーバック |
スクレイピング・ブラウザのセッションで前のページに戻る。 |
スクレイピング_ブラウザ_ゴーフォワード |
スクレイピング・ブラウザのセッションで次のページに進む。 |
スクレイピング_ブラウザ_クリック |
セレクタで指定した要素に対してクリックアクションを実行する。 |
スクレイピング_ブラウザリンク |
現在のページのテキストとセレクタを含むすべてのリンクを取得する。 |
スクレイピング・ブラウザ・タイプ |
スクレイピング・ブラウザ内の指定された要素にテキストを入力する。 |
スクレイピング・ブラウザ・ウェイト・フォー |
特定の要素がページ上に表示されるまで待ってから処理を進める。 |
スクレイピング_ブラウザ_スクリーンショット |
現在のブラウザページのスクリーンショットをキャプチャします。 |
スクレイピング_ブラウザ_get_html |
ブラウザの現在のページのHTMLコンテンツを取得する。 |
スクレイピング_ブラウザ_テキスト取得 |
現在のページから可視テキストコンテンツを抽出する。 |
そして、ウェブスクレーパーAPIを使用して、幅広いウェブサイト(例えば、Amazon、Yahoo Finance、TikTok、LinkedInなど)から構造化データを収集するための40以上の専門ツールがあります。例えば、web_data_amazon_productツールは、有効な商品URLを入力として受け取ることで、Amazonから詳細で構造化された商品情報を収集する。
では、これらのMCPツールをPydantic AIでどのように使うことができるかを見てみましょう!
PythonでPydantic AIとBright MCP Serverを統合する方法
このセクションでは、Pydantic AIを使ってAIエージェントを構築する方法を学びます。このエージェントは、Web MCPサーバからのライブデータスクレイピング、検索、対話機能を備えています。
例として、エージェントがAmazonから商品データをその場で取得する方法を示します。これは、可能性のある多くのユースケースの一つに過ぎないことを覚えておいてください。AIエージェントは、MCPサーバーを通じて利用可能な50以上のツールのいずれかを利用し、幅広いタスクを実行することができます。
このガイド付きウォークスルーに従って、Pydantic AIを使用してGemini + Bright Data MCP搭載AIエージェントを構築してください!
前提条件
コード例を再現するには、以下のものがローカルにインストールされていることを確認してください:
- Python 3.10以上。
- Node.js(最新のLTSバージョンをお勧めします)。
これも必要だ:
- ブライトデータのアカウント。
- Gemini APIキー(またはOpenAI、Anthropic、Deepseek、Ollama、Groq、Cohere、Mistralなど、サポートされている他のLLMプロバイダーのAPIキー)。
APIキーの設定はまだ心配しないでください。以下の手順で、Bright DataとGeminiの両方の認証情報を設定することができます。
厳密には必須ではありませんが、この予備知識はチュートリアルに従うのに役立ちます:
- MCPの仕組みについての一般的な理解。
- AIエージェントがどのように動作するかについての基本的な知識
- Web MCPサーバーとその利用可能なツールに関するある程度の知識。
- Pythonによる非同期プログラミングの基礎知識。
ステップ #1: Pythonプロジェクトの作成
ターミナルを開き、プロジェクト用の新しいフォルダを作成する:
mkdir pydantic-ai-mcp-agentpydantic-ai-mcp-agentフォルダには、Python AIエージェントのすべてのコードが格納されます。
新しく作成したフォルダに移動し、その中に仮想環境をセットアップする:
cd pydantic-ai-mcp-agent
python -m venv venvプロジェクトフォルダをお好みのPython IDEで開きます。Python拡張機能付きのVisual Studio Codeか、PyCharm Community Editionをお勧めします。
プロジェクトのルートにagent.pyという名前のファイルを作成します。この時点で、フォルダ構造は以下のようになっているはずです:
pydantic-ai-mcp-agent/
├── venv/
└── agent.pyagent.pyファイルは現在空ですが、近日中にPydantic AIとBright Data Web MCPサーバーを統合するロジックが含まれる予定です。
IDEのターミナルを使用して仮想環境をアクティブにします。LinuxまたはmacOSでは、次のコマンドを実行する:
source venv/bin/activate同様に、Windowsでは、起動します:
venv/Scripts/activateこれで準備完了です!これで、ウェブデータアクセスを持つAIエージェントを構築するためのPython環境が整いました。
ステップ2: Pydantic AIをインストールする
起動した仮想環境に、必要なPydantic AIパッケージをすべてインストールします:
pip install "pydantic-ai-slim[google,mcp]" これはpydantic-ai-slim をインストールします。pydantic-ai- slim は完全なpydantic-aiパッケージの軽量版で、不要な依存関係を引き込まないようにします。
この場合、エージェントを Bright Data Web MCP サーバと統合する予定ですので、mcp拡張機能が必要になります。また、LLMプロバイダとしてGeminiを統合するため、googleエクステンションも必要です。
注:他のモデルやプロバイダーについては、どのオプションの依存関係が必要であるか、モデルのドキュメントを参照してください。
次に、これらの import をagent.pyファイルに追加します:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderかっこいい!エージェント構築にPydantic AIが使えるようになりました。
ステップ3:環境変数のセットアップ 読み込み
あなたのAIエージェントは、APIを介してBright DataやGeminiのようなサードパーティのサービスと対話します。APIキーをPythonコードにハードコードしないでください。代わりに、より良いセキュリティと保守性のために、環境変数からそれらをロードします。
プロセスを単純化するために、python-dotenvライブラリを利用してください。仮想環境を起動した状態で、python-dotenv ライブラリをインストールします:
pip install python-dotenv次に、agent.pyファイルでライブラリをインポートし、load_dotenv() で環境変数をロードします:
from dotenv import load_dotenv
load_dotenv()これにより、スクリプトはローカルの.envファイルから環境変数を読み込むことができる。ですから、プロジェクトフォルダー内に.envファイルを作成してください:
pydantic-ai-mcp-agent/
├── venv/
├── agent.py
└── .env # <---------------このように環境変数にアクセスできるようになった:
env_value = os.getenv("<ENV_NAME>")Python標準ライブラリからosモジュールをインポートすることを忘れないでください:
import osさあ、始めよう!これで、.envファイルからApiキーを安全に読み込むためのセットアップは完了です。
ステップ#4: Bright Data MCPサーバーを使い始める
まだの方は、Bright Dataアカウントを作成してください。すでにお持ちの場合は、ログインしてください。
その後、公式の指示に従ってBright Data API キーを設定してください。簡単のため、ここではAdmin権限を持つトークンを使用するものとします。
Bright DataのWeb MCPを npm経由でグローバルにインストールする:
npm install -g @brightdata/mcp次に、以下のBashコマンドですべてが動作することをテストする:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpあるいは、Windowsの場合、同等のPowerShellコマンドは次のようになる:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp上記のコマンドで プレースホルダーを先ほど取得した実際のBright Data APIに置き換えてください。どちらのコマンドも必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpnpmパッケージを通してMCPサーバーを起動します。
すべてが正しく動作していれば、ターミナルには次のようなログが表示される:

MCPサーバーを初めて起動すると、Bright Dataアカウントに2つのデフォルトゾーンが自動的に作成されます:
mcp_unlocker:Web Unlockerのゾーン。mcp_browser:ブラウザAPIのゾーン。
この2つのゾーンによって、MCPサーバーは公開されているすべてのツールを実行できる。
それを確認するには、Bright Dataのダッシュボードにログインし、“Proxies & Scraping Infrastructure“ページに移動します。以下のゾーンが自動的に作成されていることが確認できます:
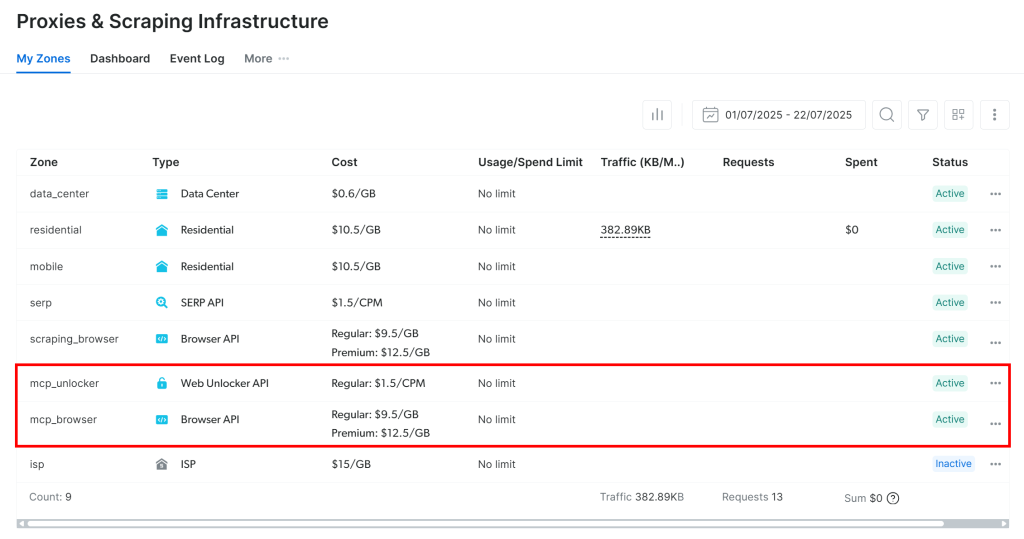
注:管理者権限を持つAPIトークンを使用していない場合は、手動でゾーンを作成する必要があります。いずれにせよ、公式ドキュメントで説明されているように、いつでもenvsでゾーン名を指定することができます。
デフォルトでは、Web MCPはsearch_engineと scrape_as_markdownツールだけを公開します。ブラウザ自動化や構造化データ抽出のような高度な機能をアンロックするには、環境変数PRO_MODE=trueを設定してProモードを有効にする必要があります。
素晴らしい!Web MCPは魅力的に機能する。
ステップ#5: ウェブMCPへの接続
マシンがWeb MCPを実行できることを確認したら、接続してください!
まず、.envファイルに Bright Data API キーを追加します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"プレースホルダを プレースホルダーを先ほど取得した実際の Bright Data API キーに置き換えてください。
そして、agent.pyファイルでそれを読みます:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Pydantic AIはMCPサーバーに接続する3つの方法をサポートしています:
- Streamable HTTPトランスポートの使用。
- HTTP SSEトランスポートを使用する。
- サーバーをサブプロセスとして実行し、
stdio経由で接続する。
最初の2つの方法についてよくご存知でない方は、SSE vs Streamable HTTPのガイドをお読みください。
この場合、サーバーをサブプロセスとして実行したい(3番目の方法)。そのためには、以下のようにMCPServerStdioインスタンスを初期化する:
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)これらのコード行で行うことは、基本的に先ほど実行したのと同じnpxコマンドを使用してWeb MCPを起動することです。認証のためにBright Data APIキーを使用してAPI_TOKEN環境変数を設定します。さらに、PRO_MODEを有効にし、高度なものを含むすべての利用可能なツールにアクセスできるようにします。
素晴らしい!これで、ローカルのWeb MCPへの接続をコードで設定できました。
ステップ6:LLMの設定
注:このセクションは、チュートリアルのために選ばれたLLMであるGeminiを参照しています。しかし、公式ドキュメントに従うことで、OpenAIや他のサポートされているLLMに簡単に適応させることができます。
まずGemini APIキーを取得し、.envファイルに以下のように追加する:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"プレースホルダを プレースホルダを実際のAPIキーに置き換えてください。
次に、Geminiとの統合に必要なPydantic AIライブラリをインポートする:
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderこれらのインポートにより、Google APIに接続し、Geminiモデルを設定することができます。.envファイルからGOOGLE_API_KEYを手動で読み込む必要がないことに注目してください。なぜなら、GoogleProviderは google-genaiを使用しており、自動的にGOOGLE_API_KEYenvからAPIキーを読み込むからです。
次に、プロバイダとモデルのインスタンスを初期化します:
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)驚いた!これにより、PydanticのAIエージェントは、無料で利用できるGoogle API経由でgemini-2.5-flashモデルに接続できるようになる。
ステップ#7: Pydantic AIエージェントの定義
事前に設定したLLMを使用し、Web MCPサーバーに接続するPydantic AIエージェントを定義します:
agent = Agent(model, toolsets=[server])完璧です!たった1行のコードで、Agentオブジェクトをインスタンス化しました。これは、Web MCPサーバによって公開されたツールを使用してタスクを処理できるAIエージェントを表しています。
ステップ#8: エージェントを立ち上げる
AIエージェントをテストするには、ウェブデータ抽出(インタラクション)タスクを含むプロンプトを書く必要があります。これは、エージェントがBright Dataツールを期待通りに使用するかどうかを検証するのに役立ちます。
手始めに、アマゾンのページから商品データを取得するように頼むといいだろう:
“https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/”の製品データをください。
通常、このようなリクエストをジェミニに直接送ると、2つのうちの1つが起こる:
- このリクエストは、Amazonのアンチボットシステム(Amazon CAPTCHAなど)により、ジェミニがページのコンテンツにアクセスできないため、失敗する。
- ライブのページにアクセスできないため、幻覚やでっち上げの製品情報を返すことになる。
ジェミニで直接プロンプトを試してみてください。以下のように、アマゾンのページにアクセスできませんでしたというメッセージが表示され、その後に加工された商品の詳細が表示されるはずです:

Web MCPサーバとの統合のおかげで、このようなことは起こりません。あなたのエージェントは、失敗したり推測したりする代わりに、web_data_amazon_productツールを使用して、Amazonページからリアルタイムの構造化された商品データを取得し、きれいで読みやすいフォーマットで返す必要があります。
Pydantic AIエージェントに質問する方法は非同期なので、実行ロジックを以下のように非同期関数でラップします:
async def main():
async with agent:
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Python標準ライブラリからasyncioをインポートすることをお忘れなく:
import asyncioミッションは完了した!あとは、フルコードを実行し、エージェントが期待に応えてくれるかどうかを見るだけだ。
ステップ9:すべてをまとめる
これがagent.pyの最後のコードです:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider
from dotenv import load_dotenv
import os
import asyncio
# Load the environment variables from the .env file
load_dotenv()
# Read the API key from the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Connect to the Bright Data Web MCP server
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)
# Configure the Google LLM model
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)
# Initialize the AI agent with Gemini and Bright Data's Web MCP server integration
agent = Agent(model, toolsets=[server])
async def main():
async with agent:
# Ask the AI Agent to perform a scraping task
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
# Get the result produced by the agent and print it
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())すごい!Pydantic AIとBright Dataのおかげで、50行程度のコードで、強力なMCPを搭載したAIエージェントを構築できました。
でAIエージェントを実行する:
python agent.pyターミナルには、以下のような出力が表示されるはずだ:

プロンプトに記載されているアマゾンの商品ページを確認すればわかるように、AIエージェントが返す情報は正確である:
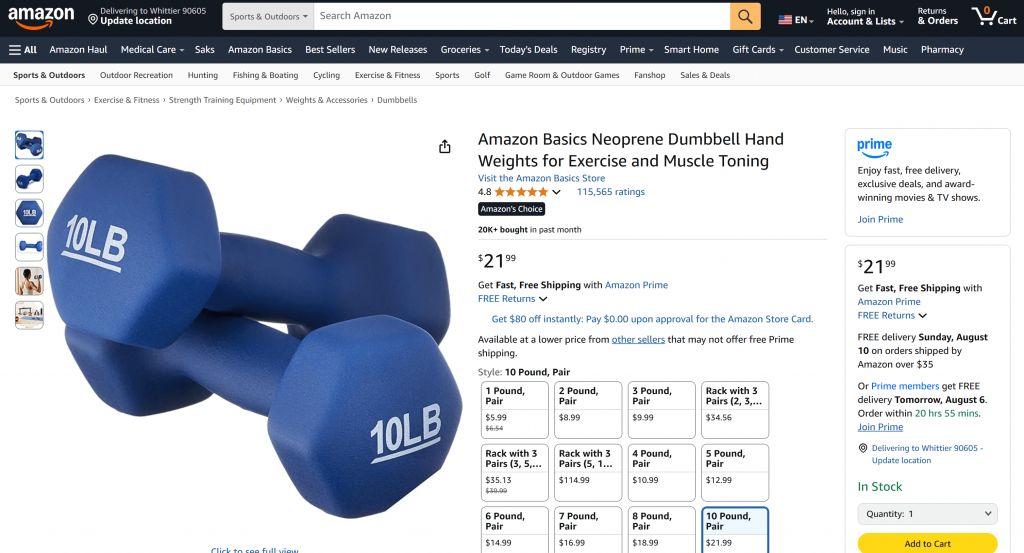
これは、エージェントがウェブMCPサーバーが提供するweb_data_amazon_productツールを使って、アマゾンから新鮮で構造化された商品データをJSON形式で取得したためである。
やった!PydanticのAIとMCPの統合は意図したとおりに機能しました。
次のステップ
ここで作られたAIエージェントは機能的だが、出発点としての役割しか果たしていない。次のレベルへのステップアップを考えてみよう:
- CLIでエージェントとチャットするREPLループを実装するか、GradioのようなGUIチャットツールと統合する。
- 独自のカスタムツールを定義することで Bright Data MCP ツールを拡張。
- Pydantic Logfireを使用したデバッグとモニタリングの追加。
- マルチエージェントワークフローの中で、エージェントをRAG自律型エージェントに変換します。
- 出力データの整合性のためのカスタム関数バリデータの定義。
結論
この記事では、Pydantic AIとBright DataのWeb MCPサーバーを統合し、WebにアクセスできるAIエージェントを構築する方法を学びました。この統合はPydantic AIに組み込まれたMCPのサポートによって可能になりました。
より洗練されたエージェントを構築するには、Bright DataのAIインフラストラクチャで利用可能なあらゆるサービスをご利用ください。これらのソリューションは、さまざまなエージェントシナリオを支援します。
Bright Dataのアカウントを無料で作成し、AIに対応したウェブデータツールの実験を開始しましょう!




