

このガイドで、あなたは学ぶだろう:
- LlamaIndexとは何か、なぜこれほど広く使われているのか。
- AIエージェントの開発においてユニークなのは、特にデータ統合のサポートが組み込まれていることだ。
- LlamaIndexを使用して、一般的なサイトと特定の検索エンジンの両方からデータを検索できるAIエージェントを構築する方法。
さあ、飛び込もう!
LlamaIndexとは?
LlamaIndexは、LLMを搭載したアプリケーションを構築するためのオープンソースのPythonデータフレームワークです。
関連情報の検索、洞察の統合、詳細なレポートの作成、自動化されたアクションの実行など、本番環境に即したAIワークフローとエージェントの作成を支援します。
LlamaIndexは、AIエージェントを構築するための最も急成長しているライブラリの1つで、GitHubのスター数は42kを超える:
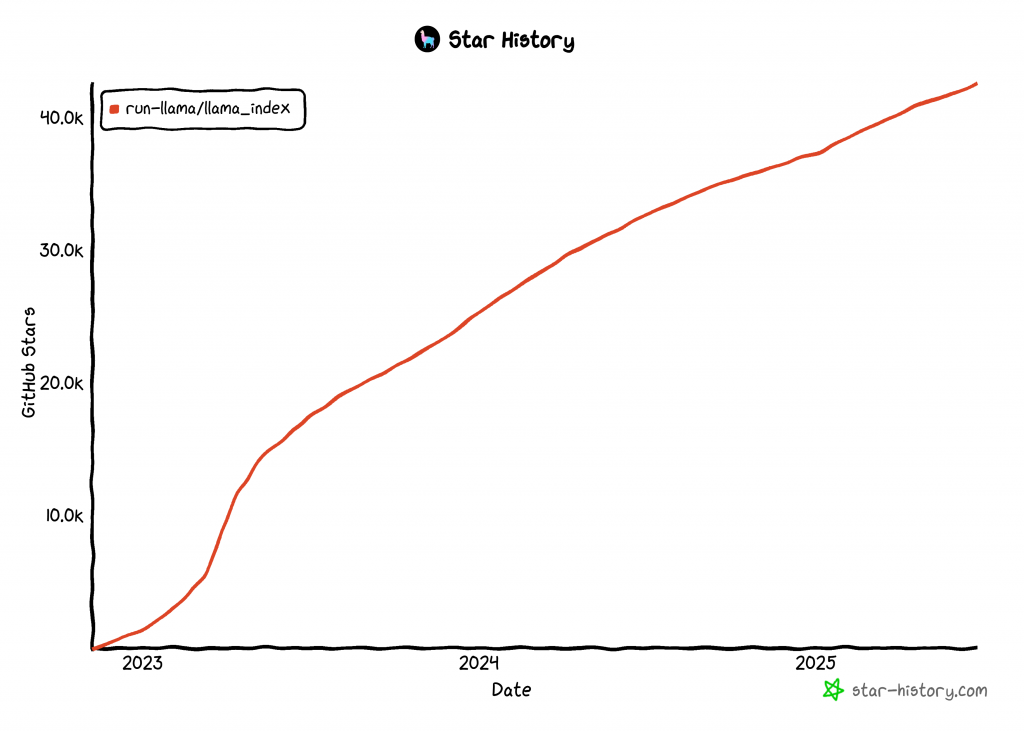
LlamaIndex AIエージェントにデータを統合する
他のAIエージェント構築技術と比べて、LlamaIndexはデータに重点を置いている。そのため、プロジェクトのGitHubリポジトリでは、LlamaIndexを “データフレームワーク “と定義している。
具体的には、LlamaIndexはLLMの最大の限界のひとつに取り組んでいる。それは、現在の出来事やリアルタイムの出来事に関する知識がないことだ。この限界は、LLMが静的なデータセットで訓練され、最新の情報へのアクセスを内蔵していないために生じる。
この問題を解決するために、LlamaIndexは以下のツールのサポートを導入した:
- API、PDF、Word文書、SQLデータベース、Webページなどからデータを取り込むためのデータコネクタを提供します。
- インデックス、グラフ、その他LLMの消費に最適化されたフォーマットを使用してデータを構造化します。
- LLMプロンプトを入力すると、関連するコンテキストに基づいた、ナレッジを補強した応答を受け取ることができるように、高度な検索を有効にします。
- LangChain、Flask、Docker、ChatGPTなどの外部フレームワークとのシームレスな統合をサポート。
言い換えれば、LlamaIndexを使ったビルドとは、コアライブラリと、あなたのユースケースに合わせたプラグインやインテグレーションを組み合わせることを意味します。例えば、LlamaIndexによるウェブスクレイピングのシナリオを考えてみましょう。
今やウェブは、地球上で最大かつ最も包括的なデータ源である。したがって、AIエージェントは、より効果的な応答とタスクの実行のために、ウェブデータにアクセスできることが理想的です。そこでLlamaIndexのブライト・データ・ツールが活躍する!
ブライト・データ・ツールを使用することで、LlamaIndexのAIエージェントは得をします:
- あらゆるウェブページからのリアルタイム・スクレイピング機能。
- Amazon、LinkedIn、Zillow、Facebook、その他多くのサイトからの構造化された製品とプラットフォームデータ。
- あらゆる検索クエリに対する検索エンジンの結果を取得する機能。
- 要約や視覚的な分析に便利な、全ページのスクリーンショットによる視覚的なデータキャプチャ。
この統合がどのように機能するかは次章で!
ブライト・データ・ツールを使ってウェブを検索できるLlamaIndexエージェントを構築する
このステップバイステップのセクションでは、LlamaIndexを使用して、Bright Dataツールに接続するPython AIエージェントを構築する方法を学びます。
この統合により、エージェントは強力なウェブデータアクセス機能を得ることができます。具体的には、AIエージェントは、あらゆるウェブページからコンテンツを抽出したり、検索エンジンの結果をリアルタイムで取得したりすることができるようになります。詳細については、公式ドキュメントをご参照ください。
以下の手順に従って、LlamaIndexを使用してブライトデータを活用したAIエージェントを構築してください!
前提条件
このチュートリアルに従うには、以下のものが必要です:
- Python 3.9以上がインストールされていること(最新版を推奨)。
BrightDataToolSpecと統合するための Bright Data API キー。- サポートされているLLMプロバイダーのAPIキー(このガイドでは、API経由で無料で利用できるGeminiを使用します。LlamaIndexがサポートしているプロバイダーであれば、ご自由にお使いください。)
GeminiまたはBright DataのAPIキーをまだお持ちでない方もご安心ください。次のステップで両方の作成方法を説明します。
ステップ #1: Pythonプロジェクトの作成
まずターミナルを開き、LlamaIndex AIエージェントプロジェクト用の新しいフォルダを作成します:
mkdir llamaindex-bright-data-agentllamaindex-bright-data-agent/には、Bright Dataによるウェブデータ検索機能を備えたAIエージェントのコードが含まれます。
次に、プロジェクト・ディレクトリに移動し、その中に仮想環境を作成する:
cd llamaindex-bright-data-agent
python -m venv venvプロジェクトフォルダをお気に入りのPython IDEで開きます。Visual Studio Code(Python拡張機能付き)か PyCharm Community Editionをお勧めします。
フォルダのルートにagent.pyという新しいファイルを作成します。プロジェクトの構造は次のようになります:
llamaindex-bright-data-agent/
├── venv/
└── agent.pyターミナルで仮想環境を有効にする。LinuxまたはmacOSでは、次のコマンドを実行する:
source venv/bin/activate同様に、Windowsでは、実行する:
venv/Scripts/activate次のステップでは、必要なパッケージのインストール方法を説明する。それでも、今すぐすべてをインストールしたい場合は、実行してください:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-gemini llama-indexNote: このチュートリアルではLLMプロバイダとしてGeminiを使用しているため、llama-index-llms-geminiをインストールしています。他のプロバイダを使用する場合は、対応するLlamaIndexインテグレーションをインストールしてください。
これで準備完了です!これで、LlamaIndexとBright Dataツールを使ってAIエージェントを構築するためのPython開発環境が整いました。
ステップ2:環境変数の設定 読み込み
LlamaIndexエージェントは、APIキーを介してGeminiやBright Dataのような外部サービスに接続します。セキュリティ上の理由から、APIキーを直接Pythonコードにハードコードしないでください。その代わりに、環境変数を使用してAPIキーを非公開にしてください。
環境変数を扱いやすくするために、python-dotenvライブラリをインストールしてください。起動した仮想環境で
pip install python-dotenv次に、agent.pyファイルを開き、.envファイルから変数を読み込むために、先頭に以下の行を追加します:
from dotenv import load_dotenv
load_dotenv()load_dotenv()関数は、プロジェクトのルート・ディレクトリにある.envファイルを探し、その値を環境に自動的にロードする。
.envファイルをagent.pyファイルと一緒に作成します:
llamaindex-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.py完璧だ!これで、サードパーティ・サービスの機密API認証情報を安全に管理する方法がセットアップされた。Timは、.envファイルに必要なenvを入力して初期設定を続行します。
ステップ3:ブライト・データを使い始める
本稿執筆時点では、BrightDataToolSpecはLlamaIndex内で以下のツールを公開している:
scrape_as_markdown:任意のウェブページの生のコンテンツをスクレイピングし、Markdownフォーマットで返します。get_screenshot:ウェブページの全ページのスクリーンショットを取得し、ローカルに保存する。search_engine:Google、Bing、Yandexなどの検索エンジンで検索クエリを実行します。SERP全体、またはそのデータのJSON構造化バージョンを返します。web_data_feed:よく知られたプラットフォームから構造化された JSON データを取得する。
最初の3つのツール-scrape_as_markdown、get_screenshot、search_engine-は Bright DataのWeb Unlocker APIを 使用しています。このソリューションは、厳重なボット対策が施されたサイトであっても、あらゆるサイトからのウェブスクレイピングとスクリーンショットへの扉を開きます。さらに、すべての主要検索エンジンからの SERP ウェブデータアクセスをサポートしています。
対照的に、web_data_feedは Bright DataのWeb Scraper APIを活用している。このエンドポイントは、Amazon、Instagram、LinkedIn、ZoomInfoなどのサポートされているプラットフォームの定義済みリストから、構造化済みのデータを返します。
これらのツールを統合するには、以下のことが必要となる:
- Bright DataダッシュボードでWeb Unlockerソリューションを有効にします。
- Bright Data API トークンを取得し、Web Unlocker と Web Scraper API の両方にアクセスできるようにします。
以下の手順に従ってセットアップを完了してください!
まず、Bright Dataのアカウントをお持ちでない場合は、[作成]() してください。すでにアカウントをお持ちの場合は、ログインしてダッシュボードを開きます。プロキシ製品を取得]ボタンをクリックします:
プロキシとスクレイピング・インフラストラクチャ」ページにリダイレクトされます:
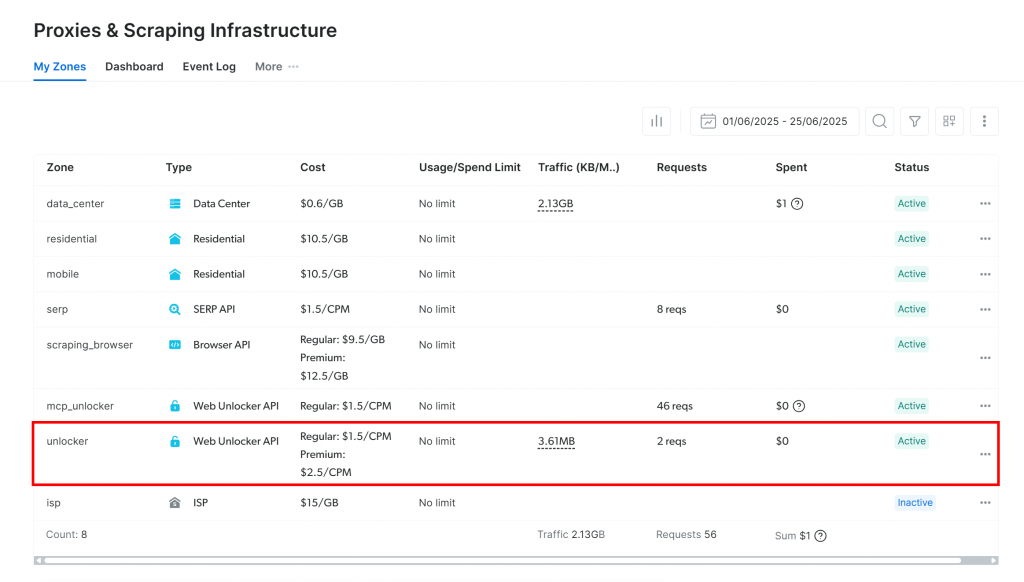
すでにアクティブな Web Unlocker API ゾーンが表示されていれば (上図のように)、問題ありません。ゾーン名(この場合、unlocker)は重要です。
まだお持ちでない場合は、”Web Unlocker API “セクションまでスクロールダウンし、”Create zone “をクリックしてください:
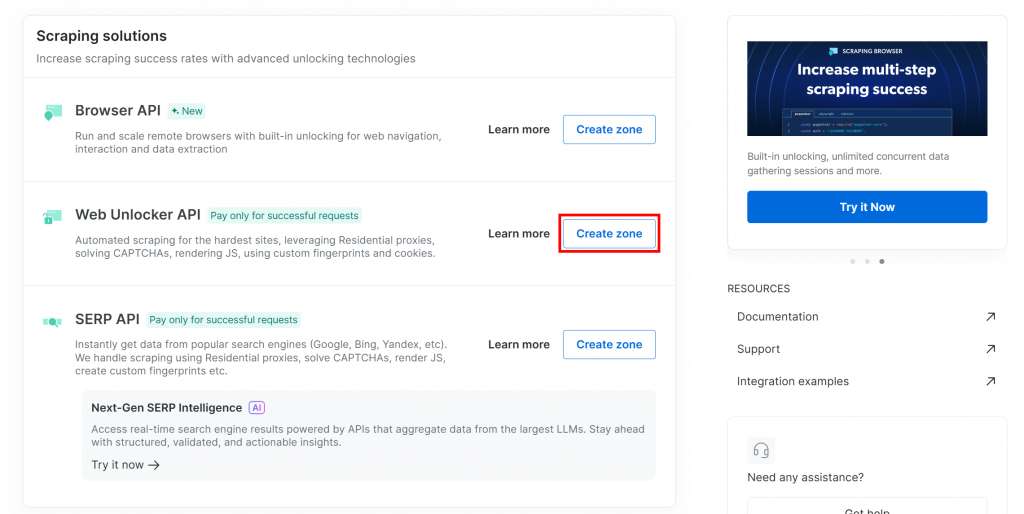
新しいゾーンにアンロッカーなどの名前を付け、より良いパフォーマンスのために高度な機能を有効にし、”Add “をクリックします:
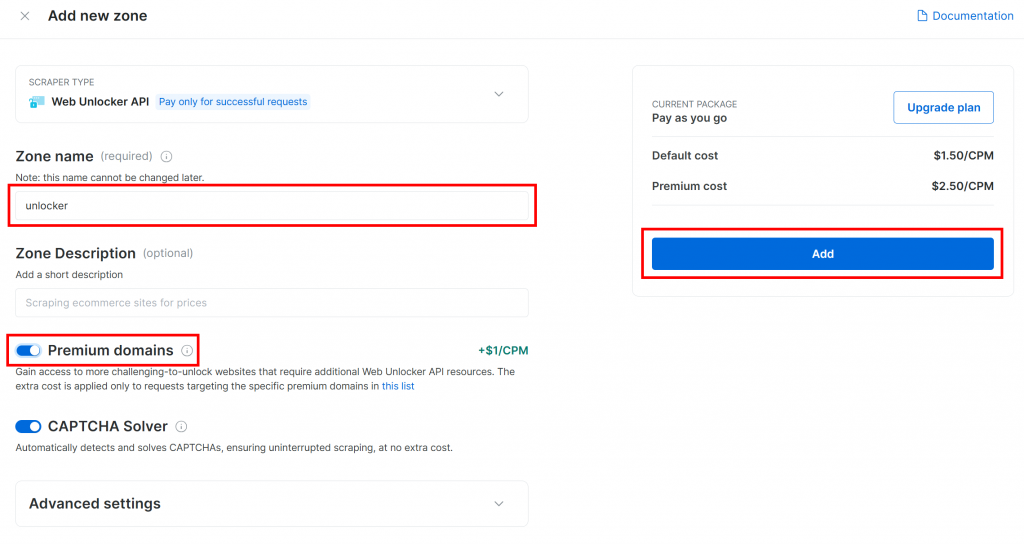
ゾーンが作成されると、ゾーンの設定ページにリダイレクトされます:
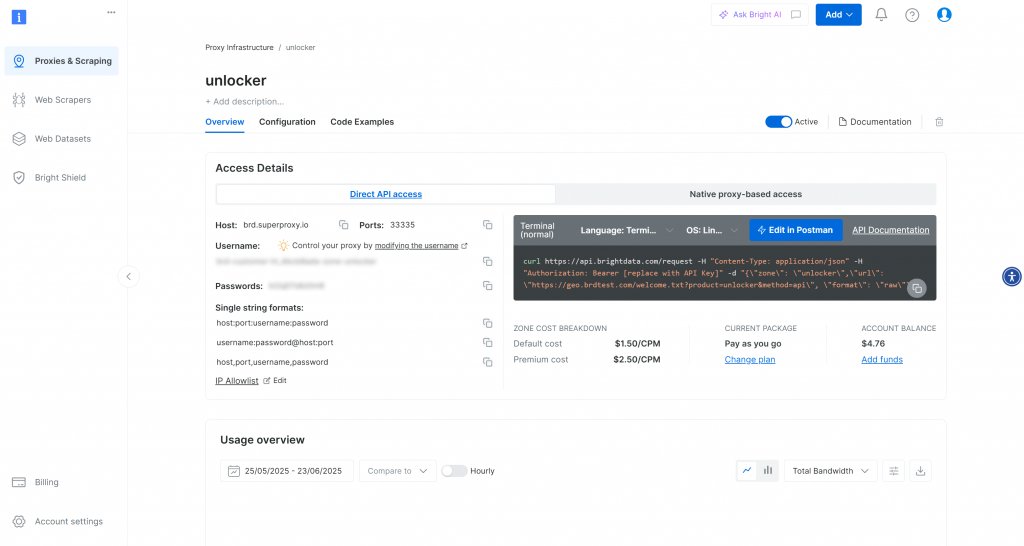
有効化トグルが “Active “になっていることを確認する。これでゾーンが正しく設定され、使用できる状態になったことが確認できます。
次に、Bright Dataの公式ガイドに従ってAPIキーを生成します。取得したら、以下のように.envファイルに安全に保存してください:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"プレースホルダを プレースホルダを実際のAPIキー値に置き換える。
驚いた!Bright DataツールをLlamaIndexエージェントスクリプトに統合する時が来た。
ステップ #4: LlamaIndex Bright データツールのインストールと設定
agent.pyで、Bright Data APIキーを環境から読み込みます:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Python標準ライブラリからosをインポートするのを忘れないこと:
import os仮想環境をアクティブにした状態で、LlamaIndex Bright Data ツールパッケージをインストールします:
pip install llama-index-tools-brightdataagent.pyファイルで、BrightDataToolSpecクラスをインポートします:
from llama_index.tools.brightdata import BrightDataToolSpec次に、API キーとゾーン名を使用してBrightDataToolSpecのインスタンスを作成します:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="<BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>", # Replace with the actual value
verbose=True, # Useful while developing
)プレースホルダを プレースホルダを、先ほど設定した Web Unlocker API ゾーンの名前に置き換えてください。この場合、unlockerです:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True,
)verboseオプションがTrueに設定されていることに注意してください。LlamaIndex エージェントが Bright Data 経由でリクエストを行う際に、何が起こっているのかについての有用な情報が表示されるので、開発中に役立ちます。
次に、ツールスペックをエージェントで使用可能なツールのリストに変換する:
brightdata_tools = brightdata_tool_spec.to_tool_list()素晴らしい!Bright Dataツールは統合され、LlamaIndexエージェントを動かす準備が整いました。次のステップはLLMを接続することです。
ステップ5:LLMモデルの準備
Gemini(選択されたLLMプロバイダ)を使用するには、必要な統合パッケージをインストールすることから始める:
pip install llama-index-llms-google-genai次に、インストールしたパッケージからGoogleGenAIクラスをインポートする:
from llama_index.llms.google_genai import GoogleGenAIさて、ジェミニLLMを次のように初期化する:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)この例では、gemini-2.5-flashモデルを使用しています。必要に応じて、サポートされている他のGeminiモデルと交換することができます。
舞台裏では、GoogleGenAIは自動的にGEMINI_API_KEYという環境変数を探します。これを設定するには、.envファイルを開き、以下の行を追加します:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"プレースホルダを プレースホルダを実際のGemini APIキーに置き換えてください。お持ちでない場合は、公式ガイドに従って無料で取得してください。
注:別のLLMプロバイダーを使用したい場合、LlamaIndexは多くのオプションをサポートしています。設定方法については、LlamaIndexの公式ドキュメントを参照してください。
よくやった!これで、Webデータ検索機能を持つLlamaIndexエージェントを構築するための、すべてのコアコンポーネントが揃いました。
ステップ6:LlamaIndexエージェントの作成
まず、メインのLlamaIndexパッケージをインストールする:
pip install llama-index次に、agent.pyファイルでFunctionCallingAgentクラスをインポートします:
from llama_index.core.agent import FunctionCallingAgentFunctionCallingAgentは LlamaIndex AI エージェントの特別なタイプで、先に設定した Bright Data ツールなどの外部ツールと対話することができます。
このように、LLM と Bright Data ツールでエージェントを初期化します:
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)これは、LLMを使用してユーザー入力を処理し、必要に応じてBright Dataツールを呼び出して情報を取得するAIエージェントを設定します。verbose=Trueフラグは、エージェントが各リクエストでどのツールを使用しているかを表示するので、開発中に便利です。
よくやったLlamaIndex + Bright Dataの統合は完了した。次のステップは、対話的に使用するためのREPLを構築することです。
ステップ#7: REPLの実装
REPLとは “Read-Eval-Print Loop “の略で、コマンドを入力して評価し、その結果をすぐに見ることができるインタラクティブなプログラミング・パターンである。この文脈では
- コマンドまたはタスクを入力する。
- AIエージェントに評価させ、処理させる。
- 回答をご覧ください。
このループは、「exit」と入力するまで無限に続く。
AI エージェントを扱う場合、REPL は孤立したプロンプトを送信するよりも実用的な傾向があります。それは、LlamaIndex エージェントがセッションのコンテキストを保持し、以前のインタラクションから学習して応答を改善することを可能にするからです。
次に、agent.pyに以下のようにREPLロジックを実装します:
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")このREPL:
input()でコマンドラインからユーザーの入力を読み込む。- GeminiとBright Dataが提供するLlamaIndexエージェントを使用して、
agent.chat()で評価します。 - 応答をコンソールに表示する。
すごい!LlamaIndex AIエージェントの準備が整いました。
ステップ#8:すべてをまとめてエージェントを実行する
これがあなたのagent.pyファイルの内容です:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent import FunctionCallingAgent
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True, # Useful while developing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")以下のコマンドを使用してエージェント・スクリプトを実行する:
python agent.pyスクリプトがスタートすると、次のような画面が表示される:

ターミナルに以下のプロンプトを入力する:
Generate a report summarizing the most important information about the product "Death Stranding 2" using data from its Amazon page: "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"結果はこうなる:
かなり早かったので、何が起こったかを説明しよう:
- エージェントは、タスクがアマゾンの商品データを必要とすることを特定し、この入力で
web_data_feedツールを呼び出します:{"source_type":"amazon_product", "url":"https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"}. - このツールは、Bright DataのAmazon Web Scraper APIに非同期で問い合わせ、構造化された商品データを取得する。
- JSONレスポンスが返されると、エージェントはそれをGemini LLMに送る。
- ジェミニは新鮮なデータを処理し、明確で正確な要約を作成する。
言い換えれば、プロンプトが与えられれば、エージェントは最適なツールをスマートに選択する。この場合、それはweb_data_feedです。これは、非同期アプローチで指定されたアマゾンのページからリアルタイムの商品データを取得する。そして、LLMはそれを使って意味のある要約を生成する。
この場合、AIエージェントは戻ってきた:
Here's a summary report for "Death Stranding 2: On The Beach - PS5" based on its Amazon product page:
**Product Report: Death Stranding 2: On The Beach - PS5**
* **Title:** Death Stranding 2: On The Beach - PS5
* **Brand/Manufacturer:** Sony Interactive Entertainment
* **Price:** $69.99 USD
* **Release Date:** June 26, 2026
* **Availability:** Available for pre-order.
**Description:**
"Death Stranding 2: On The Beach" is an upcoming PlayStation 5 title from legendary game creator Hideo Kojima. Players will embark on a new journey with Sam and his companions to save humanity from extinction, traversing a world filled with otherworldly enemies and obstacles. The game explores the question of human connection and promises to once again change the world through its unique narrative and gameplay.
**Key Features:**
* **Pre-order Bonus:** Includes Quokka Hologram, Battle Skeleton Silver (LV1,LV2,LV3), Boost Skeleton Silver (LV1,LV2,LV3), and Bokka Silver (LV1,LV2,LV3).
* **Open World:** Features large, varied open-world environments with unique challenges.
* **Gameplay Choices:** Offers multiple approaches to combat and stealth, allowing players to choose between aggressive tactics, sneaking, or avoiding danger.
* **New Story:** Continues the narrative from the original Death Stranding, following Sam on a fresh journey with unexpected twists.
* **Player Interaction:** Player actions can influence how other players interact with the game's world.
**Category & Ranking:**
* **Categories:** Video Games, PlayStation 5, Games
* **Best Sellers Rank:** #10 in Video Games, #1 in PlayStation 5 Games
**Sales Performance:**
* **Bought in past month:** 7,000 unitsブライト・データのツールがなければ、AIエージェントはこのような結果を得ることができなかっただろう。それは
- 選ばれたアマゾンの商品は新しい商品であり、LLMはそのような新鮮なデータでは訓練されない。
- LLMは、自分でリアルタイムのウェブページをスクレイピングしたり、アクセスしたりすることはできないかもしれない。
- アマゾンの商品をスクレイピングするのは、悪名高いアマゾンCAPTCHAのような厳格なボット対策システムのために難しい。
重要: 他のプロンプトを試してみると、エージェントは自動的に適切な設定されたツールを選択して使用し、接地された応答を生成するために必要なデータを取得することがわかります。
出来上がり!Bright Dataとの統合により、一流のウェブデータアクセス機能を備えたLlamaIndex AIエージェントの完成です。
結論
この記事では、LlamaIndexを使用して、Bright DataツールのおかげでウェブデータにリアルタイムでアクセスできるAIエージェントを構築する方法を学んだ。
この統合により、エージェントは公開されているウェブコンテンツをMarkdown形式、構造化されたJSON形式、さらにはスクリーンショットで取得することができます。これは、ウェブサイトと検索エンジンの両方に当てはまります。
ここで見た統合は、基本的な例に過ぎないことを心に留めておいてください。より高度なエージェントの構築を目指すのであれば、ライブのウェブデータを取得、検証、変換するための信頼できるツールが必要です。ブライトデータのAIインフラはまさにそのために構築されています。
無料のBright Dataアカウントを作成し、今すぐAI対応データツールの検索を開始しましょう!




