
このガイドで、あなたは学ぶだろう:
- エージェント型検索拡張世代(RAG)とは何か、なぜエージェント型機能を追加することが重要なのか
- ブライト・データがRAGシステムのための自律的でライブなウェブデータ検索を可能にした理由
- 埋め込み用にウェブスクレイピングされたデータを処理し、きれいにする方法
- ベクトル検索とLLMテキスト生成をオーケストレーションするエージェントコントローラの実装
- ユーザーの入力を取り込み、検索と生成を動的に最適化するフィードバック・ループの設計
さあ、飛び込もう!
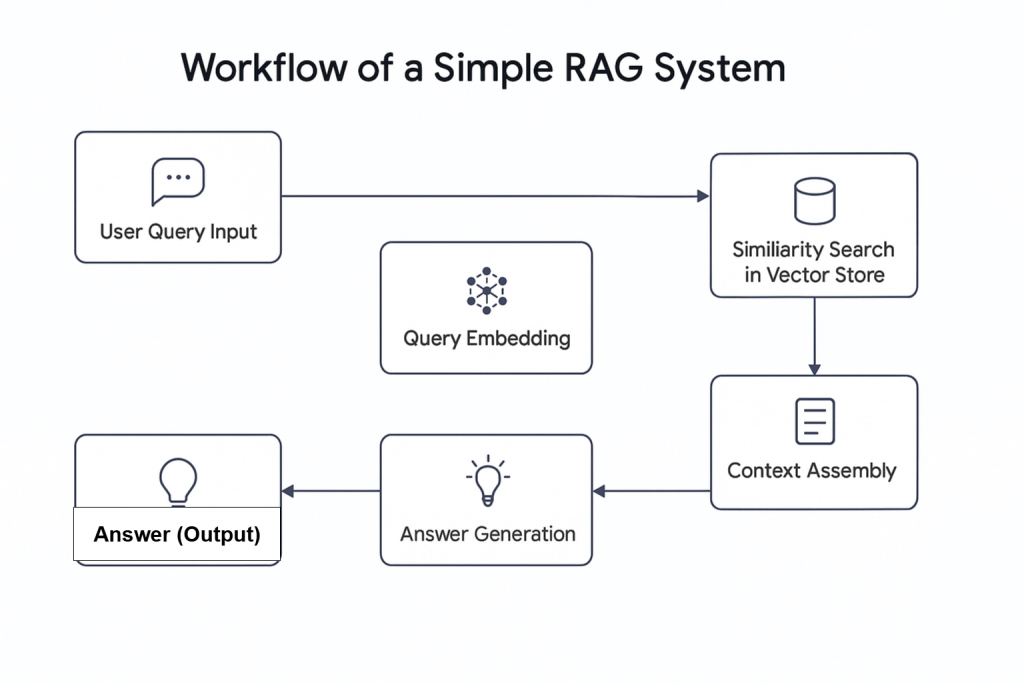
人工知能(AI)の台頭は、エージェント型RAGを含む新しい概念を導入した。簡単に言えば、エージェント型RAGは、AIエージェントを統合した検索拡張世代(RAG)である。その名が示すように、RAGは、クエリを受け取り、関連情報を検索し、応答を生成するという直線的なプロセスに従う情報検索システムである。
なぜAIエージェントとRAGを組み合わせるのか?
最近の調査によると、AIエージェントを使用したワークフローの約3分の2が生産性の向上を報告している。さらに、60%近くがコスト削減を報告しています。このことから、AIエージェントとRAGの組み合わせは、最新の検索ワークフローを大きく変える可能性があります。
Agentic RAGは高度な機能を提供する。従来のRAGシステムとは異なり、データを取得するだけでなく、データベースに埋め込まれたライブウェブデータのような外部ソースから情報を取得することもできます。
この記事では、ウェブデータ収集にBright Data、ベクターデータベースにPinecone、テキスト生成にOpenAI、エージェントコントローラにAgnoを使用し、ニュース情報を取得するエージェント型RAGシステムの構築方法を紹介します。
ブライトデータの概要
ライブデータストリームからソーシングする場合でも、データベースから準備されたデータを使用する場合でも、Agentic RAGシステムからのアウトプットの品質は、受信するデータの品質に依存します。そこでBright Dataが不可欠になります。
Bright Dataは、信頼性が高く、構造化された最新のウェブデータを幅広いユースケースに提供しています。120以上のドメインにアクセスできるBright DataのWeb Scraper APIにより、ウェブスクレイピングはかつてないほど効率的になります。IP禁止、CAPTCHA、クッキー、その他のボット検出など、スクレイピングの一般的な課題に対応します。
まずは無料トライアルにサインアップし、スクレイピングしたいドメインのAPIキーとdataset_idを取得してください。これらを手に入れたら、準備は完了です。
以下は、BBCニュースのような人気ドメインから新鮮なデータを取得する手順である:
- ブライトデータのアカウントをまだお持ちでない場合は、作成してください。無料トライアルをご利用いただけます。
- ウェブスクレイパーのページに行く。Web Scrapers Libraryの下にある、利用可能なスクレイパー・テンプレートを調べる。
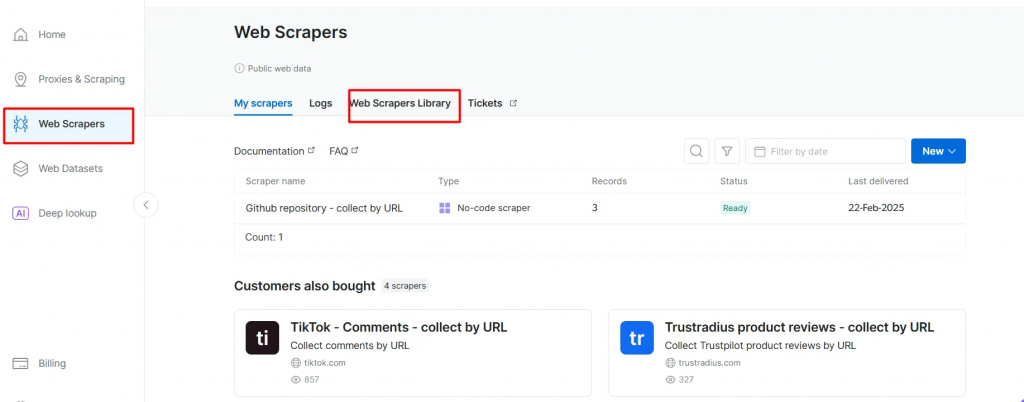
- BBCニュースなど、対象となるドメインを検索し、選択する。
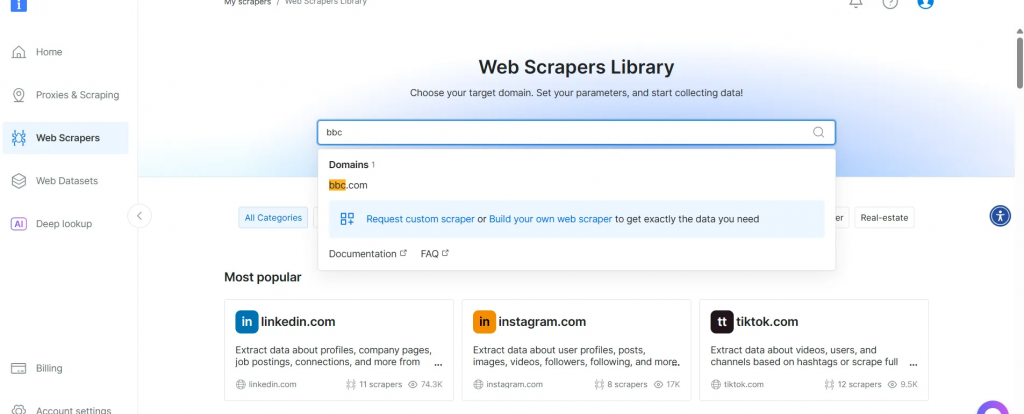
- BBC Newsスクレイパーのリストから、BBC News – collect by URLを選択する。このスクレイパーを使えば、ドメインにログインせずにデータを取得できる。
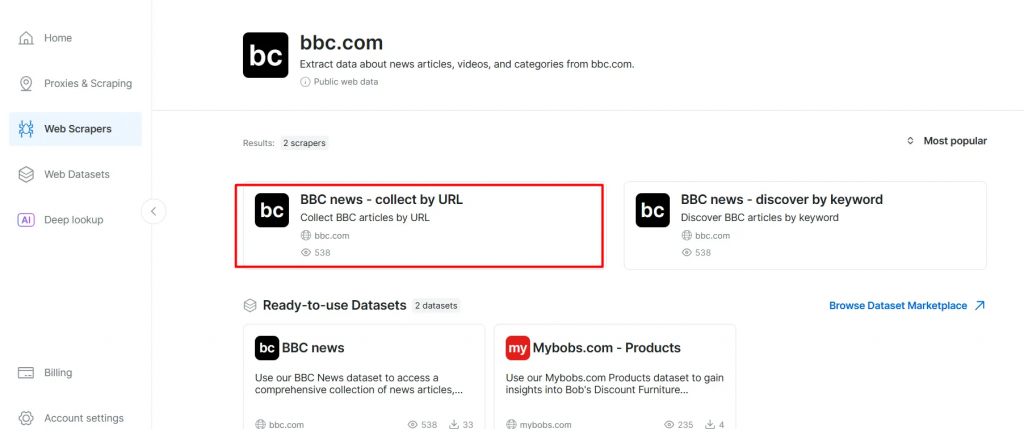
- スクレイパーAPIオプションを選択します。ノーコードスクレーパーは、コードなしでデータセットを取得するのに役立ちます。

- API Request Builderをクリックし、
API-key、BBC Dataset URL、dataset_idをコピーします。これらは、次のセクションでAgentic RAGワークフローを構築する際に使用します。
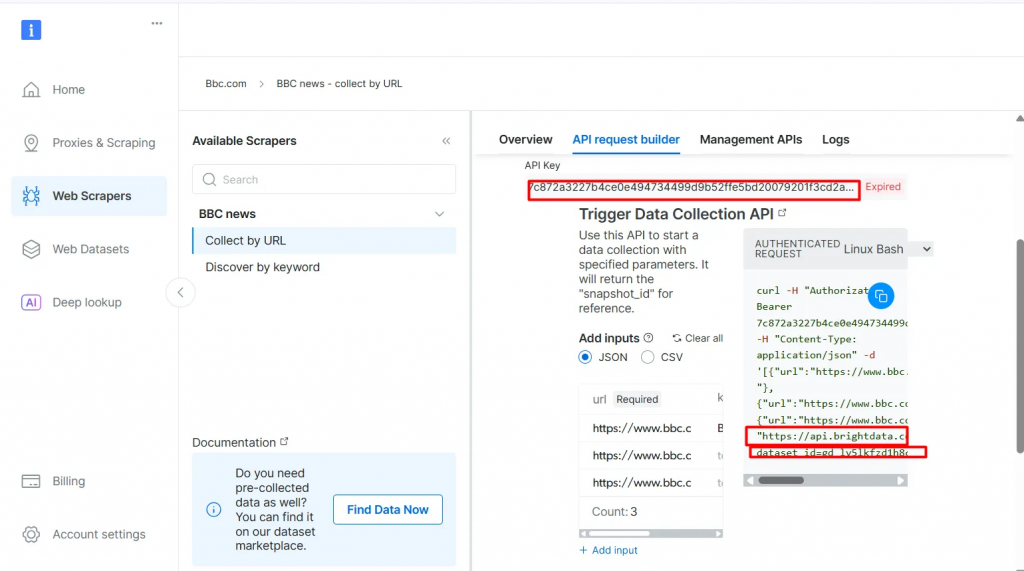
API-keyとdataset_idは、ワークフローでエージェント機能を有効にするために必要です。これらは、検索クエリが事前にインデックス付けされたコンテンツに直接マッチしない場合でも、ライブデータをベクターデータベースに埋め込み、リアルタイムのクエリをサポートすることを可能にします。
前提条件
始める前に、以下を確認してください:
- ブライトデータのアカウント
- OpenAIのAPIキーOpenAIにサインアップしてAPIキーを取得します:
- Pinecone APIキーPineconeのドキュメントを参照し、APIキーの取得セクションの指示に従ってください。
- Pythonの基本的な理解 Pythonは公式サイトからインストールできます。
- RAGとエージェントの概念の基本的理解
エージェントRAGの構造
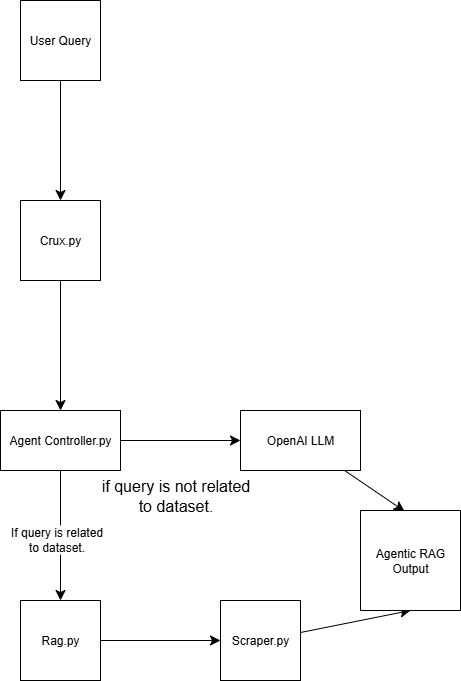
このAgentic RAGシステムは、4つのスクリプトを使って構築されている:
scraper.pyBright Data経由でウェブデータを取得する
rag.py ベクトルデータベース(Pinecone)にデータを埋め込む 注:ベクトル(数値埋め込み)データベースが使われるのは、一般的に機械学習モデルによって生成される非構造化データを格納するためです。このフォーマットは検索タスクにおける類似検索に最適です。
agent_controller.py制御ロジックを含みます。クエリの性質に応じて、ベクトルデータベースから前処理されたデータを使うか、GPTからの一般的な知識に依存するかを決定します。
crux.pyAgentic RAGシステムのコアとして動作します。APIキーを保存し、ワークフローを初期化します。
あなたのエージェントのボロ布の構造は、デモの最後にはこのようになる:
ブライト・データによるエージェントRAGの構築
ステップ1:プロジェクトのセットアップ
1.1 新規プロジェクト・ディレクトリの作成
プロジェクト用のフォルダを作成し、その中に移動する:
mkdir agentic-rag
cd agentic-rag
1.2 Visual Studio Codeでプロジェクトを開く
Visual Studio Codeを起動し、新しく作成したディレクトリを開きます:
.../Desktop/agentic-rag> code .
1.3 仮想環境のセットアップとアクティベーション
仮想環境をセットアップするには、以下を実行する:
python -m venv venv
あるいは、Visual Studio Codeで、Python環境ガイドのプロンプトに従って仮想環境を作成します。
環境をアクティブにする
- Windowsの場合:
.venv - macOSまたはLinuxの場合:
ソース venv/bin/activate
ステップ2: Bright Data Retrieverの導入
2.1scraper.pyファイルにrequestsライブラリをインストールする
pip install requests
2.2 以下のモジュールをインポートする
import requests
import json
import time
2.3 認証情報を設定する
先ほどコピーした Bright DataAPI キー、データセット URL、dataset_idを使用してください。
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 応答ロジックの設定
スクレイピングしたいページのURLをリクエストに入力する。この場合、スポーツ関連の記事に焦点を当てる。
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 コードの実行
スクリプトを実行すると、プロジェクト・フォルダーにnews-data.jsonというファイルが現れます。このファイルには、スクレイピングされた記事データが構造化されたJSON形式で含まれています。
以下は、JSONファイル内のコンテンツの例である:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
データが手に入ったので、次のステップはそれを埋め込むことだ。
ステップ3:埋め込みとベクターストアのセットアップ
3.1rag.pyファイルに必要なライブラリをインストールする
pip install openai pinecone pandas
3.2 必要なライブラリのインポート
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 OpenAIのキーを設定する
OpenAIを使って、text_for_embeddingフィールドからエンベッディングを生成する。
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Pinecone API キーとインデックスの設定
Pinecone環境をセットアップし、インデックス構成を定義します。
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Pineconeクライアントとインデックスの初期化
クライアントとインデックスがデータの保存と検索のために適切に初期化されていることを確認する。
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 データのクリーニング、ロード、前処理
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
注意: データが最新であることを確認するために
scraper.pyを再実行することができます。
3.7 OpenAIを使って埋め込みを生成する
OpenAIのエンベッディングモデルを使って、前処理されたテキストからエンベッディングを作成します。
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 埋め込みでPineconeを更新する
生成されたエンベッディングをPineconeにプッシュし、ベクターデータベースを最新の状態に保つ。
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
注:このステップを実行するのは、データベースにデータを入力するために一度だけです。その後、この部分をコメントアウトすることができます。
3.9 松ぼっくり検索機能の初期化
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
注:
スコアのしきい値は、結果が関連性があるとみなされるための最小類似度スコアを定義します。この値はニーズに応じて調整できます。スコアが高いほど、より正確な結果が得られます。
3.10 OpenAIを使って回答を生成する
OpenAIを使って、Pineconeで取得したコンテキストから回答を生成する。
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (オプション) 簡単なテストを実行し、クエリを実行して結果を印刷する。
基本的なテストを実行できる、CLI フレンドリーなコードを含めます。このテストは、実装が動作していることを確認し、データベースに保存されたデータのプレビューを表示するのに役立ちます。
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
ヒント:例えば、結果をスライスすることによって、表示されるテキストの量をコントロールすることができます:
[:250].
これでデータはベクターデータベースに保存されました。つまり、2つのクエリーオプションがあります:
- データベースから取得
- OpenAIによって生成された汎用応答を使用する
ステップ 4: エージェントコントローラの構築
4.1agent_controller.py内
rag.py から必要な機能をインポートします。
from rag import openai_generate_answer, pinecone_search
4.2 松ぼっくり検索の実装
Pinecone ベクターストアから関連データを取得するロジックを追加します。
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 フォールバックOpenAIレスポンスの実装
関連するコンテキストが取得されなかった場合に、OpenAIを使用して回答を生成するロジックを作成します。
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
ステップ5:すべてをまとめる
5.1crux.py
agent_controller.py から必要な関数をインポートします。
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 APIキーを提供する
OpenAIとPineconeのAPIキーが正しく設定されていることを確認してください。
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3main()関数にプロンプトを入力する
main()関数の中でプロンプト入力を定義する。
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 エージェントRAGを呼び出す
Agentic RAG ロジックを実行します。ベクタデータベースにクエリを実行する前に、まずその関連性をチェックすることで、クエリをどのように処理するかがわかります。

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
あなたのデータベースと一致しないクエリーでテストしてみてください:
def main():
query = "Why Sleep?"
エージェントは、Pineconeで良いマッチが見つからなかったと判断し、OpenAIを使った一般的なレスポンスの生成に戻る。

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
ヒント:エージェントの信頼度を理解するために、各プロンプトの関連性スコア(score_threshold)を印刷することができます。
以上です!これでAgentic RAGは完成です。
ステップ6(オプション):フィードバック・ループと最適化
フィードバック・ループを導入することで、トレーニングやインデクシングを長期的に改善し、システムを強化することができる。
6.1 フィードバック機能の追加
agent_controller.pyで、応答が表示された後にユーザーにフィードバックを求める関数を作成します。この関数はcrux.pyのメインランナーの最後で呼び出すことができます。
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 フィードバック・ロジックの実装
agent_controller.pyに、フィードバックが否定的な場合に検索処理を再実行する新しい関数を作成します。そして、crux.pyでこの関数を呼び出します:
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
結論と次のステップ
この記事では、ウェブスクレイピングのためのBright Data、ベクターデータベースのPinecone、テキスト生成のためのOpenAIを組み合わせた自律エージェント型RAGシステムを構築した。このシステムは、以下のような様々な追加機能をサポートするために拡張できる基盤を提供します:
- ベクトル・データベースとリレーショナルまたは非リレーショナル・データベースとの統合
- Streamlitを使ったユーザーインターフェースの作成
- トレーニングデータを常に最新の状態に保つためのウェブデータ検索の自動化
- 検索ロジックとエージェント推論の強化
実証されたように、Agentic RAGシステムの出力の質は、入力データの質に大きく依存します。Bright Dataは、効果的な検索と生成に不可欠な、信頼性が高く新鮮なウェブデータを可能にする上で重要な役割を果たした。
このワークフローをさらに強化し、将来のプロジェクトでBright Dataを使用して、一貫した高品質の入力データを維持することを検討してください。





