

このガイドでは、次のように説明する:
- Picaとは何か、そしてなぜPicaが外部ツールと統合するAIエージェントの構築に最適なのか。
- AIエージェントがデータ検索のためにサードパーティ・ソリューションとの統合を必要とする理由。
- Pica エージェントに組み込まれた Bright Data コネクタを使用して、より正確なレスポンスのためにウェブデータを取得する方法。
さあ、飛び込もう!
ピカとは何か?
Picaは、AIエージェントやSaaSインテグレーションを迅速に構築するために設計されたオープンソースのプラットフォームです。鍵の管理や複雑な設定を必要とせず、125以上のサードパーティAPIへのシンプルなアクセスを提供します。
Picaの目標は、AIモデルが外部のツールやサービスと簡単に接続できるようにすることです。Picaを使えば、わずか数クリックで統合をセットアップし、コードで簡単に使用することができる。これにより、AIワークフローはリアルタイムのデータ検索や複雑な自動化などに対応できるようになる。
このプロジェクトはGitHubで急速に人気を集め、わずか数ヶ月で1,300以上のスターを集めた。これは、コミュニティの強い成長と採用を示している。
AIエージェントにウェブデータ統合が必要な理由
すべてのAIエージェントフレームワークは、そのベースとなるLLMから核となる制限を受け継いでいる。LLMは静的なデータセットで事前に訓練されているため、リアルタイムの認識に欠け、ライブのウェブコンテンツに確実にアクセスすることができない。
その結果、回答が古くなったり、幻覚を見たりすることさえある。このような制限を克服するために、エージェント(と彼らが依存するLLM)は、信頼できる最新のウェブデータにアクセスする必要がある。なぜウェブデータなのか?なぜなら、ウェブは依然として最も包括的で最新の情報源だからです。
だからこそ、効果的なAIエージェントは、サードパーティのAIウェブデータプロバイダーと素早く簡単に統合できなければならないのです。そして、ピカが活躍するのはまさにここなのです!
Picaプラットフォームでは、Bright Dataを含む 125以上の統合が可能です:
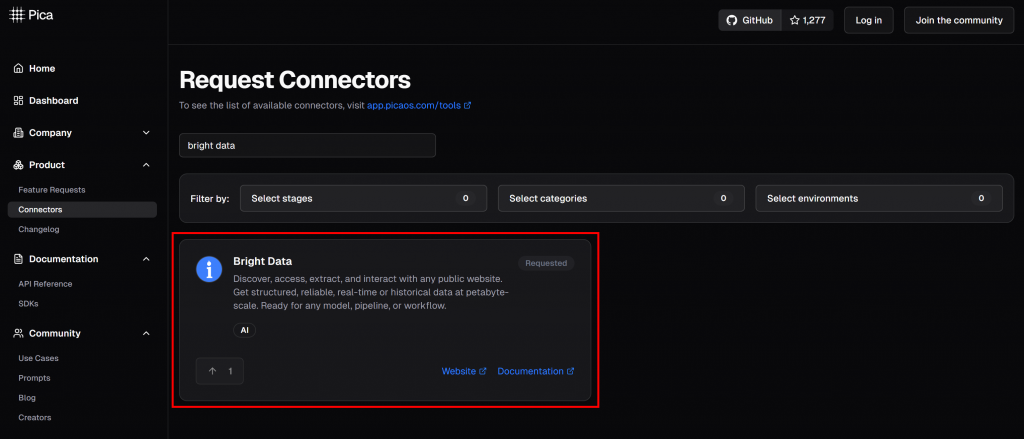
ブライトデータとの統合により、AIエージェントとワークフローがシームレスに接続できるようになります:
- Web Unlocker API:ボットプロテクションを回避する高度なスクレイピングAPIで、あらゆるウェブページのコンテンツをMarkdownフォーマットで配信します。
- ウェブスクレーパーAPI:Amazon、LinkedIn、Instagram、その他40のような人気サイトから新鮮で構造化されたデータを倫理的に抽出するための専門ソリューション。
これらのツールは、AIエージェント、ワークフロー、またはパイプラインに、関連するページからその場で抽出された信頼性の高いウェブデータを使用して、応答をバックアップする機能を提供します。次の章では、この統合を実際に見てみましょう!
ピカとブライト・データでウェブからデータを取得できるAIエージェントを構築する方法
このガイドセクションでは、Picaを使用して、Bright Dataインテグレーションに接続するPython AIエージェントを構築する方法を学びます。こうすることで、エージェントはAmazonのようなサイトから構造化されたウェブデータを取得できるようになります。
以下の手順に従って、ピカを使用してブライトデータを活用したAIエージェントを作成してください!
前提条件
このチュートリアルに従うには
- Python 3.9以上がインストールされていること(最新版を推奨)。
- ピカのアカウント
- Bright Data APIキー。
- OpenAI API キー。
Bright Data APIキーやPicaアカウントをまだお持ちでない方もご安心ください。次のステップで設定方法を説明します。
ステップ #1: Pythonプロジェクトの初期化
ターミナルを開き、Pica AIエージェントプロジェクト用の新しいディレクトリを作成します:
mkdir pica-bright-data-agentpica-bright-data-agentフォルダには、Pica エージェントの Python コードが格納されます。これは、Web データ検索に Bright Data インテグレーションを使用します。
次に、プロジェクト・ディレクトリに移動し、その中に仮想環境を作成する:
cd pica-bright-data-agent
python -m venv venvお気に入りのPython IDEでプロジェクトを開いてください。Pythonエクステンション付きのVisual Studio Codeか、PyCharm Community Editionをお勧めします。
プロジェクトフォルダ内に、agent.py という名前の新しいファイルを作成します。ディレクトリ構造は以下のようになります:
pica-bright-data-agent/
├── venv/
└── agent.pyターミナルで仮想環境をアクティブにする。LinuxまたはmacOSの場合、実行する:
source venv/bin/activateウィンドウズでは、このコマンドを実行する:
venv/Scripts/activate次のステップでは、必要なPythonパッケージをインストールします。仮想環境をアクティブにした状態で、今すぐすべてをインストールしたい場合は、単に実行してください:
pip install langchain langchain-openai pica-langchain python-dotenvこれで準備完了です!これでPythonの開発環境が整い、Bright Dataを統合したAIエージェントをPicaで構築できるようになりました。
ステップ2:環境変数の設定 読書
あなたのエージェントは、Pica、Bright Data、OpenAIのようなサードパーティのサービスに接続します。これらの統合を安全に保つために、APIキーを直接Pythonコードにハードコードすることは避けてください。代わりに、環境変数として保存します。
環境変数のロードを簡単にするには、python-dotenvライブラリを利用します。アクティベートした仮想環境に、次のようにインストールします:
pip install python-dotenv次に、ライブラリをインポートし、agent.pyファイルの先頭でload_dotenv()を呼び出して環境変数をロードします:
import os
from dotenv import load_dotenv
load_dotenv()この関数を使うと、スクリプトはローカルの.envファイルから変数を読み込むことができます。この.envファイルをプロジェクトディレクトリのルートに作成します。フォルダ構造は次のようになります:
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.py素晴らしい!これで、環境変数を使用してAPIキーやその他の秘密を安全に扱うための準備が整いました。
ステップ 3: ピカの設定
まだの場合は、無料の Pica アカウントを作成してください。デフォルトでは、PicaがAPIキーを生成します。そのAPIキーをLangChainやその他のサポートされているインテグレーションで使用することができます。
クイックスタート “ページにアクセスし、”LangChain “タブを選択します:
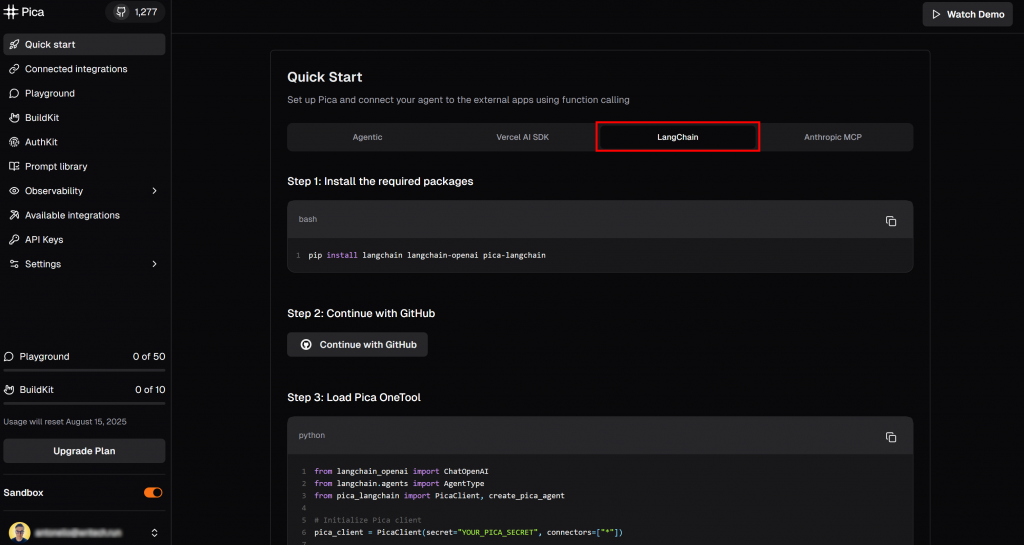
ここでは、LangChainでPicaを使い始めるための説明があります。具体的には、そこに示されているインストール・コマンドに従ってください。アクティベートされた仮想環境で
pip install langchain langchain-openai pica-langchain次に、”API Key “セクションに達するまで下にスクロールする:

copy to clipboard” ボタンをクリックして、Pica API キーをコピーします。そして、次のように環境変数を定義して、.envファイルに貼り付けます:
PICA_API_KEY="<YOUR_PICA_KEY>"プレースホルダを プレースホルダーを、コピーした実際のAPIキーに置き換える。
素晴らしい!これでピカアカウントは完全に設定され、コードで使用する準備が整いました。
ステップ4:ピカでブライト・データを統合する
始める前に、必ず公式ガイドに従って Bright Data API キーを設定してください。このキーは、Picaプラットフォームで利用可能なビルトイン統合を使用して、エージェントをBright Dataに接続するために必要です。
APIキーを取得したら、PicaにBright Dataインテグレーションを追加します。
Picaダッシュボードの “LangChain “タブで、”Recent Integrations “セクションまでスクロールダウンし、”Browse integrations “ボタンを押してください:
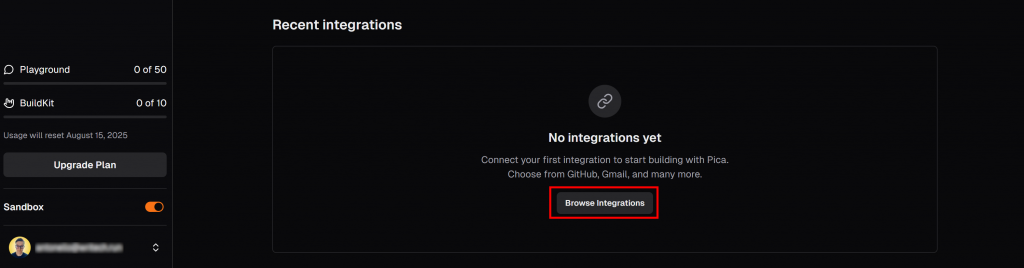
モーダルが開きます。検索バーに “brightdata “と入力し、”BrightData “インテグレーションを選択します:
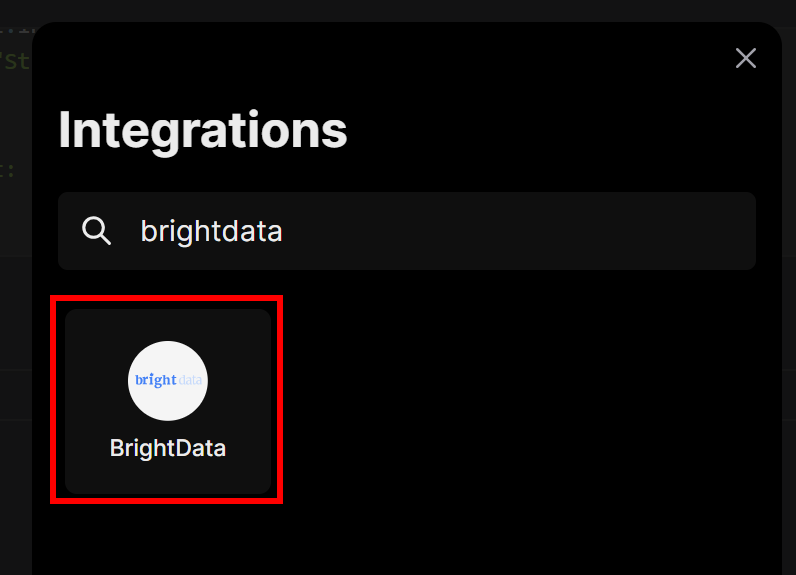
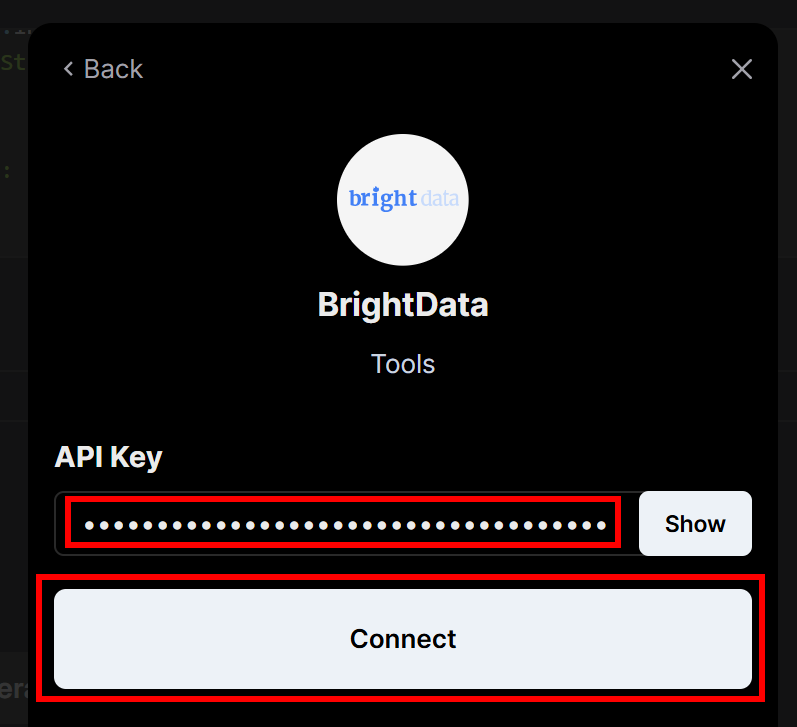
先ほど作成したBright Data APIキーの入力を求められます。それを貼り付けて、”Connect “ボタンをクリックしてください:
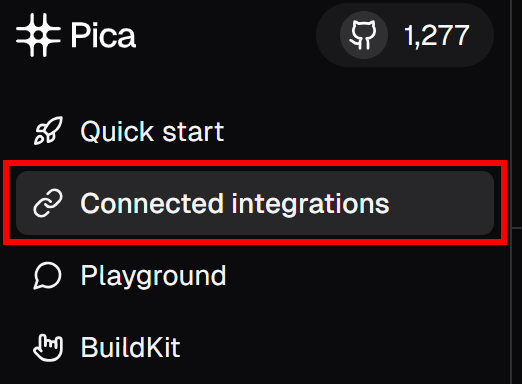
次に、左側のメニューで、”Connected Integrations “メニュー項目をクリックする:
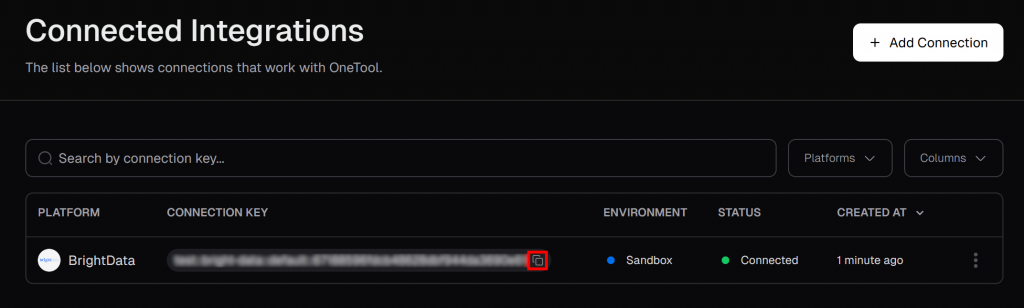
Connected Integrations” ページで、Bright Data が接続されたインテグレーションとして表示されているはずです。テーブルから、”Copy to clipboard “ボタンをクリックして、接続キーをコピーしてください:
次に、これを.envファイルに追加して貼り付ける:
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"必ず プレースホルダーをコピーした実際の接続キーに置き換えてください。
この値は、設定された Bright Data 接続を読み込むために、Pica エージェントをコードで初期化するために必要です。次のステップでその方法を説明します!
ステップ #5: Pica エージェントの初期化
agent.py で Pica エージェントを初期化します:
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()上記のスニペットは Pica クライアントを初期化し、環境から読み込んだPICA_API_KEYシークレットを使用して Pica アカウントに接続します。また、利用可能なコネクタの中から、先に設定した Bright Data インテグレーションを選択します。
つまり、このクライアントで作成したAIエージェントは、Bright Dataのリアルタイムのウェブデータ検索機能を活用することができます。
必要なクラスをインポートすることを忘れないでください:
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptions素晴らしい!LLM統合の準備が整いました。
ステップ6:OpenAIの統合
Pica エージェントは、入力プロンプトを理解し、Bright Data の機能を使用して必要なタスクを実行するために、LLM エンジンを必要とします。
このチュートリアルでは、OpenAIインテグレーションを使用します。そのため、agent.pyファイルに以下のようにエージェントのLLMを定義します:
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)これはモデルが決定論的であり、同じ入力に対して常に同じ出力を生成することを保証します。
ChatOpenAIクラスはこのインポートから来ていることを覚えておいてください:
from langchain_openai import ChatOpenAI特に、ChatOpenAIは OpenAI API キーがOPENAI_API_KEY という環境変数に定義されていることを期待します。そこで、.envファイルに次のように追加します:
OPENAI_API_KEY=<YOUT_OPENai_API_KEY>プレースホルダを プレースホルダを実際の OpenAI API キーに置き換えてください。
驚きです!これでピカAIエージェントを定義するためのすべての構成要素が揃いました。
ステップ#7:ピカエージェントの定義
ピカでは、AIエージェントは3つの主要部分から構成される:
- Pica クライアントのインスタンス
- LLMエンジン
- ピカ剤タイプ
この場合、OpenAIの関数を呼び出すことができるAIエージェントを作りたいとします(このAIエージェントは、Picaインテグレーションを通じてBright Dataのウェブ検索機能に接続します)。このように、Picaエージェントを作成します:
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
) 必要な輸入品を追加することを忘れないでください:
from pica_langchain import create_pica_agent
from langchain.agents import AgentTypeすばらしい!あとは、データ検索タスクでエージェントをテストするだけだ。
ステップ#8:AIエージェントを尋問する
Bright Data インテグレーションがお客様の Pica エージェントで動作することを確認するために、通常単独では実行できないタスクを与えてください。例えば、Nintendo Switch 2(https://www.amazon.com/dp/B0F3GWXLTS/)のような最近のAmazon商品ページから更新されたデータを取得するように依頼します。
そのためには、この入力でエージェントを起動する:
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})注意:このプロンプトは、意図的に明示的なものである。エージェントが何をすべきか、どのページをスクレイピングすべきか、どのインテグレーションを使用すべきかを正確に指示しています。これにより、LLM は Pica を通して設定された Bright Data ツールを活用し、期待通りの結果を得ることができます。
最後に、エージェントの出力を表示する:
print(f"nAgent Result:n{result}")そしてこの最後の一行で、あなたのピカAIエージェントは完成です。それでは、実際に動いているところをご覧ください!
ステップ9:すべてをまとめる
これで、agent.pyファイルには
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")ご覧のように、50行以下のコードで、強力なデータ検索機能を持つ Pica エージェントを構築しました。これは、Pica プラットフォームで直接利用可能な Bright Data インテグレーションのおかげです。
でエージェントを動かす:
python agent.pyターミナルには、以下のようなログが表示されるはずだ:
# Omitted for brevity...
2026-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2026-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2026-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2026-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2026-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2026-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2026-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2026-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2026-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2026-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2026-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-dataもっと簡単に言えば、これがあなたのピカ代理人がやったことだ:
- Pica に接続し、設定した Bright Data インテグレーションを取得します。
- Bright Dataプラットフォームには54の利用可能なツールがあることを発見。
- Bright Dataから全データセットのリストを取得。
- あなたのプロンプトに基づいて、”Trigger Synchronous Web Scraping and Retrieve Results “ツールを選択し、指定されたAmazon商品ページから新鮮なデータをスクレイピングするために使用します。裏側では、これがBright Data Amazon Scraperへの呼び出しをトリガーし、Amazon商品のURLを渡します。スクレーパーは商品データを取得して返します。
- スクレイピングアクションが正常に実行され、データが返された。
出力は次のようになるはずだ:

この出力をMarkdownエディターに貼り付けると、次のような整形された製品レポートができあがる:
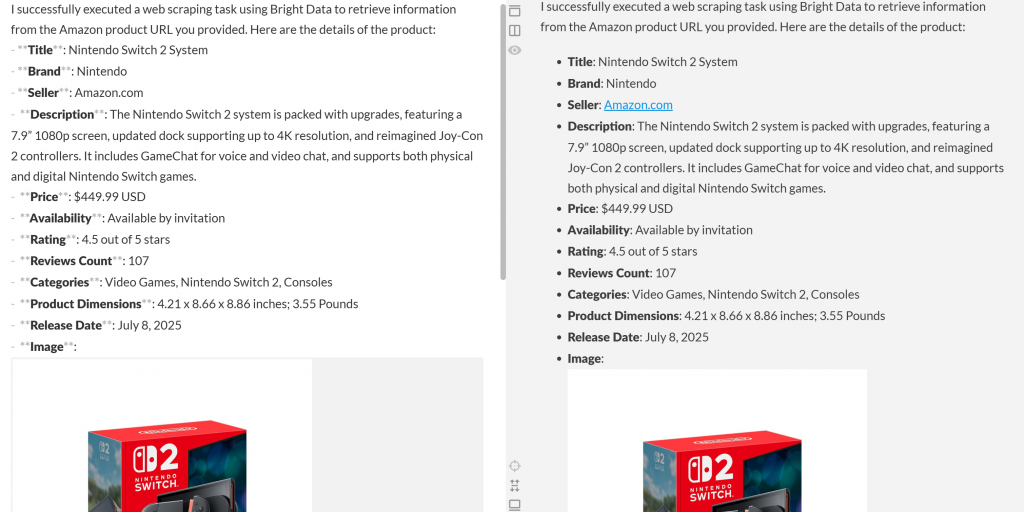
お分かりのように、エージェントはAmazonの商品ページから意味のある最新のデータを含むMarkdownレポートを作成することができました。ブラウザで対象の商品ページにアクセスすることで、正確性を確認することができます:
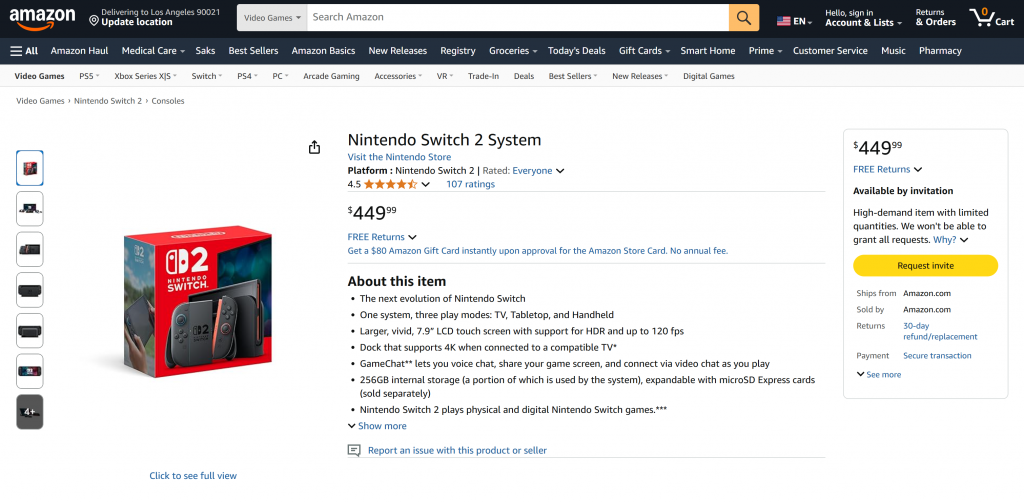
生成されたデータが、LLMによって幻覚化されたものではなく、アマゾンのページからの実際のデータであることに注目してほしい。これは、Bright Dataのツールでスクレイピングされた証拠である。そして、これはほんの始まりに過ぎない!
Pica の幅広い Bright Data アクションにより、エージェントは事実上あらゆるウェブサイトからデータを取得することができます。Amazonのようなスクレイピング対策(悪名高いAmazon CAPTCHAなど)で知られる複雑なターゲットも含まれます。
出来上がり!Pica AI エージェントに Bright Data を統合することで、シームレスなウェブスクレイピングが可能になります。
結論
この記事では、ピカを使用して、新鮮なウェブデータで応答をバックアップできるAIエージェントを構築する方法を紹介しました。これは、Picaに組み込まれたBright Dataとの統合により可能になりました。Pica Bright Dataコネクタは、AIにあらゆるウェブページからデータを取得する機能を提供します。
これは単純な例であることに注意してください。より高度なエージェントを構築したい場合は、ライブのウェブデータを取得、検証、変換するための堅牢なソリューションが必要です。それこそが、Bright Data AIインフラストラクチャにあるものです。
無料のBright Dataアカウントを作成し、AIに対応したWebデータ抽出ツールの検索を開始します!





