

このチュートリアルでは、次のことを学びます:
- GEOとSEOを改善するために、クエリファンアウトとGoogle AI Overview比較に基づくアプローチをどのように利用できるか。
- 6つのAIエージェントを使って、このワークフローを高いレベルで構築する方法。
- GeminiおよびBright Dataと統合されたCrewAIを使用して、このAIコンテンツ最適化ワークフローを実装する方法。
- ワークフローをさらに充実させるためのアイデアやアドバイスもある。
さあ、飛び込もう!
TL;DR
すぐに使えるプロジェクト・ファイルまでスキップしたい?GitHubのプロジェクトをチェックしてください。
より良いGEOとSEOのためのクエリーファンアウトとAI概要比較の説明
SEO(検索エンジン最適化)とは、オーガニック検索結果におけるウェブサイトの可視性を向上させる技術であることは、誰もが知っている。しかし、世界は今、GEO(ジェネレーティブ・エンジン最適化)へと移行しつつある。
GEOをご存じない方は、Google AI OverviewsやChatGPTなど、AIを搭載した検索エンジン内でコンテンツをより見やすくすることに焦点を当てたデジタルマーケティング戦略である。
LLMは本質的にブラックボックスであるため、GEOのためにウェブページを「最適化」する簡単な方法はない(キーワードボリューム検索ツールが利用可能になる前のSEOのようなものだ)。
あなたができることは、経験的なアプローチに従うことである。現実のAIが生成したサマリーや、ターゲットキーワードに対するクエリのファンアウトを見ることである。特定の検索キーワードがあったとして、AIの検索結果に特定のトピックが表示され続けるのであれば、そのトピックを中心にページのコンテンツを最適化する必要がある。
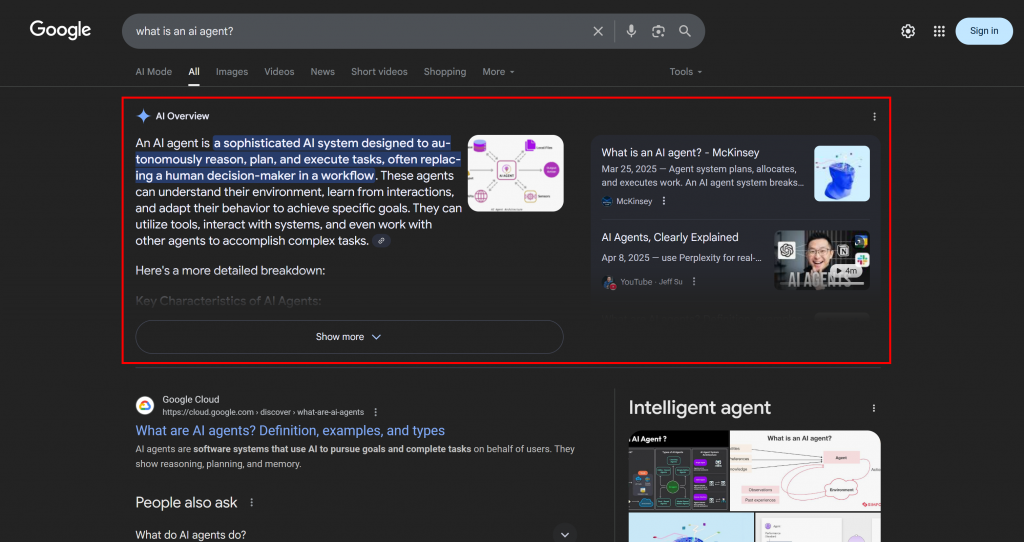
GoogleのAI検索において、クエリファンアウトとは、単一のユーザークエリを、関連するサブクエリのネットワークに変える技術である。Google AIモードは、元のクエリを最適な答えにマッチさせるだけでなく、関連する複数の質問を一度に生成して検索することで、さらに進化させる。
下の例でわかるように、Google AIモードは通常、トピックをより深く探求するのに役立つ短い要約を含む約10の関連リンクを返す:
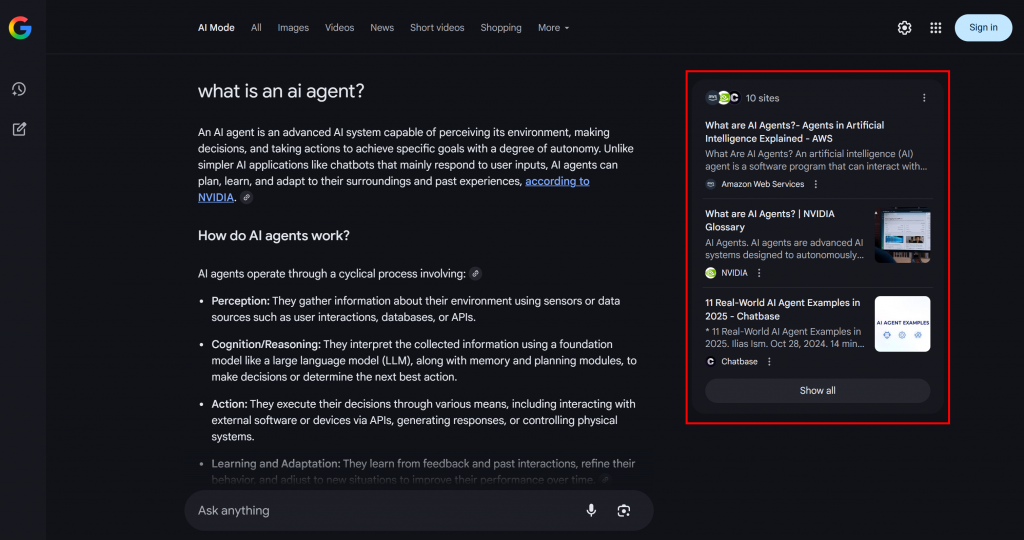
これがグーグルクエリのファンアウトであり、もっと簡単に定義すると、1つのAI検索から生成された関連するサブクエリの集合体である。
クエリのファンアウトやAIの概要で特定のトピックが繰り返し表示されるのであれば、そのトピックを中心にコンテンツページを構成することは理にかなっている。副次的な効果として、このアプローチは従来のSEOも向上させることができる。Googleなどのエンジンは、AIを活用した検索結果ですでに良い結果を出しているページをSERPでブーストする可能性が高いからだ。
さて、基本を理解したところで、GEOへのこのアプローチの技術的な詳細について掘り下げてみよう!
マルチエージェントGEO最適化システムの構築方法
ご想像の通り、GEOコンテンツ最適化のワークフローをサポートするAIエージェントの実装は簡単ではありません。一つの効果的なアプローチは、6つの特化したエージェントに基づいたマルチエージェントシステムに頼ることです:
- タイトルスクレーパー:ウェブページのURLから大見出しやタイトルを抽出します。
- Googleクエリファンアウトリサーチャー:抽出されたタイトルを利用して、ジェミニで利用可能なGoogle検索ツールを呼び出し、クエリファンアウトを生成します。
- Google メインクエリ抽出:クエリファンアウトを解析し、Googleのような主要な検索クエリを特定して抽出する。
- Google AI Overview Retriever:メインクエリを使用してGoogle SERP検索を実行し、そこからAI概要セクションを取得します。
- クエリファンアウトサマライザ:クエリファンアウトコンテンツ(通常、かなり長い)を最適化されたMarkdown要約に凝縮し、重要なトピックを強調します。
- AIコンテンツオプティマイザー:クエリーファンアウトサマリーをGoogle AI Overviewと比較し、パターンや繰り返し発生するトピックを特定します。GEOコンテンツ最適化のための実用的な洞察を含む出力Markdownドキュメントを生成します。
さて、上述のエージェントのいくつかは、かなり汎用的で、ほとんどのLLMで実装可能である(例えば、Google Main Query Extractor、Query Fan-Out Summarizer、AI Content Optimizer)。しかし、他のエージェントは、より専門的な機能と特定のモデルやツールへのアクセスを必要とします。
例えば、Google Main Query Extractorは、Geminiモデルでのみ利用可能なgoogle_searchツールにアクセスする必要がある。同様に、Title Scraperエージェントは、タイトルを抽出するためにウェブページのコンテンツにアクセスする必要があります。このタスクは、多くのウェブサイトでAI対策が施されているため、難しいかもしれません。問題を回避するために、Title Scraperを Web Unlockerと統合することができます。このBright DataスクレイピングAPIは、生のHTMLまたはAIに最適化されたMarkdownフォーマットでコンテンツを取得し、すべてのブロックをバイパスします。
同じように、Google AI Overview Retrieverは、検索クエリを実行し、AI Overviewをリアルタイムでスクレイピングするために、Bright Data SERP APIのようなツールを必要とする。
言い換えれば、GeminiとBright DataのAIインフラのおかげで、このGEO/SEOユースケースを実装することができる。今必要なのは、この概要グラフにあるように、これらのエージェントをオーケストレーションするAIエージェント構築システムである:
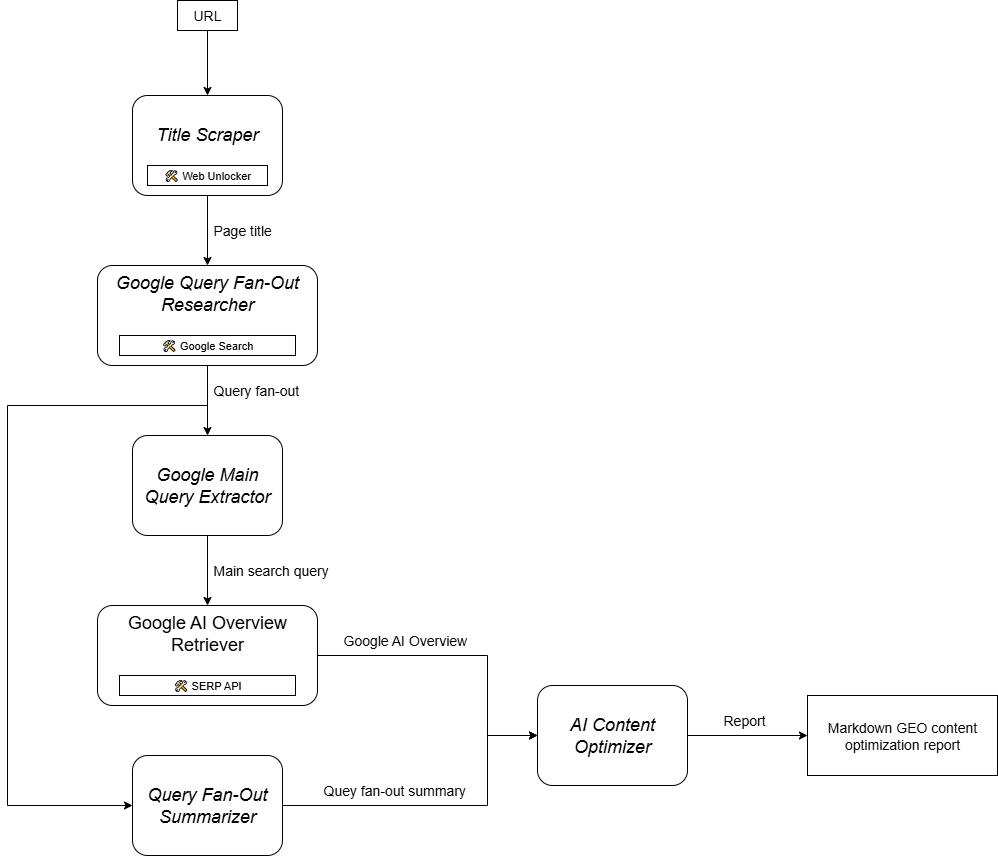
CrewAIはマルチエージェントシステムをオーケストレーションするために特別に設計されているため、このワークフローを構築し管理するのに理想的なフレームワークである。
ジェミニとブライトデータを用いたCrewAIにおけるマルチエージェントGEOコンテンツ最適化システムの実装
以下の手順に従って、AIを搭載した検索エンジン向けにウェブページを最適化するための反復可能なワークフローを提供するマルチエージェントシステムを構築する方法を学んでください。クエリのファンアウトとAIの概要を体系的に分析することで、優先順位の高いトピックを発見し、AI主導のランキング上位を達成するためにコンテンツを構成するのに役立ちます。
以下のコードはCrewAIを使用してPythonで書かれており、エージェントに必要なツールと機能を提供するためにBright DataとGeminiが統合されている。
前提条件
このチュートリアルについて行くには、以下を確認してください:
- Python 3.10以上をローカルにインストール。
- Gemini APIキー(クレジットは必要ありません)。
- ブライトデータのアカウント。
Bright Dataのアカウントをお持ちでない方もご安心ください。設定方法をご案内いたします。
また、CrewAIの仕組みをある程度理解しておくことも非常に重要です。始める前に、公式ドキュメントを確認することをお勧めします。
ステップ #1: CrewAIアプリケーションのセットアップ
CrewAIのインストールにはuvが必要です。以下のコマンドでグローバルにインストールできます:
pip install uvまたは、お使いのオペレーティングシステムの公式インストールガイドに従ってください。
次に、CrewAIをシステムにグローバルインストールします:
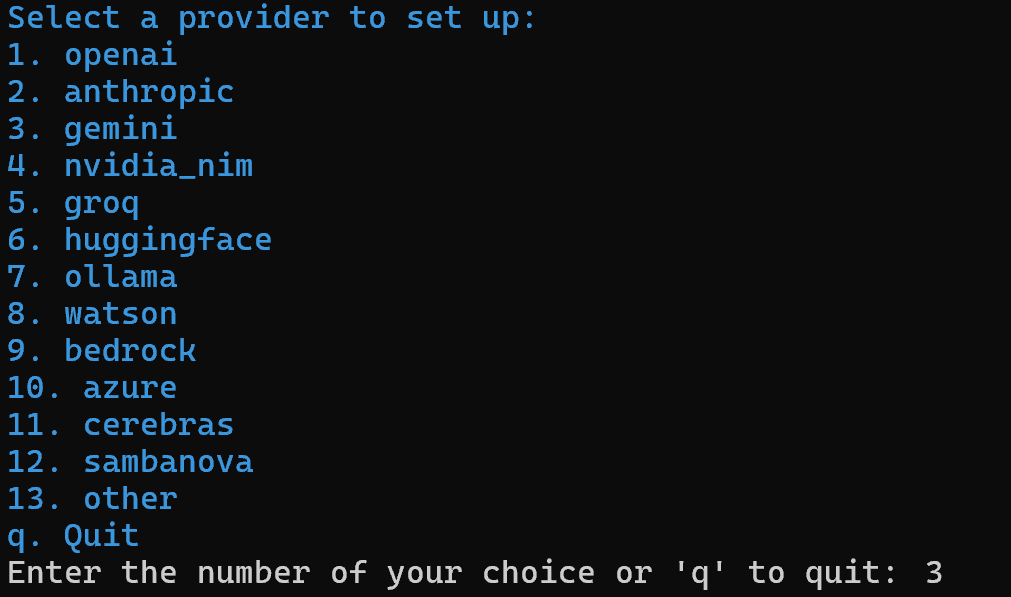
uv tool install crewai ここで、ai_content_optimization_agentという新しいCrewAIプロジェクトを作成します:
crewai create crew ai_content_optimization_agentAIプロバイダーを選択するよう求められます。現在のワークフローはGeminiで動作しているため、オプション3を選択します:
次に、ジェミニのモデルを選択する:
この記事の後半で交換するので、利用可能なモデルのどれを選んでもいい。ですから、それは重要ではありません。
続けて、Gemini APIキーを貼り付けます:

このステップの後、ai_content_optimization_agent/フォルダ構造内のプロジェクトは次のようになります:
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yamlお気に入りのPython IDEでプロジェクトをロードし、それに慣れる。現在のファイルを調べ、.envにはすでに選択したGeminiモデルとGemini APIキーが含まれていることに注意してください:
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>CrewAIのファイルに慣れていない場合や問題が発生した場合は、公式のインストールガイドを参照してください。
ターミナルでプロジェクトフォルダーに移動する:
cd ai_content_optimization_agentそして、その中でPython仮想環境を初期化する:
python -m venv .venv 注意:仮想環境は.venv という名前でなければなりません。そうでない場合、CrewAIワークフローを起動するためのcrewai runコマンドは失敗します。
LinuxとmacOSでは、次のようにして仮想環境をアクティブにする:
source .venv/bin/activateあるいは、Windowsの場合は、次のコマンドを実行する:
.venvScriptsactivate完了です!これで空白のCrewAIプロジェクトができました。
ステップ2:ジェミニの統合
前述したように、デフォルトでは、CrewAIは選択されたGeminiモデルを.envファイルに追加します。最新のモデルを設定するには、.envファイルのMODEL環境変数を次のように上書きします:
MODEL=gemini/gemini-2.5-flashこうすることで、CrewAIでオーケストレーションされたAIエージェントがgemini-2.5-flashに接続できるようになります。この記事を書いている時点では、これが最新のGemini Flashモデルだ。さらに、(このCrewAIの統合のように)API経由で問い合わせた場合、非常に寛大なレート制限があります。
crew.pyで、MODEL名を環境から読み込みます:
MODEL = os.getenv("MODEL")この変数は、後でエージェントにLLMを設定するために使われる。
Python標準ライブラリからosをインポートすることを忘れないでください:
import osクールだ!ジェミニのセットアップは終わった。
ステップ#3: CrewAI Bright Data Toolsのインストールと設定
AIを使ってウェブページからタイトルを抽出するのは簡単ではない。ほとんどのLLMはウェブページのコンテンツに直接アクセスできない。また、そうするためのツールが組み込まれていても、ブラウザのフィンガープリンティングやCAPTCHAのような高度なスクレイピング対策のために失敗することが多い。Googleは自動スクレイピングを積極的に防止しているため、同じ課題がライブSERPスクレイピングにも当てはまる。
ここでブライト・データが基本となる。ありがたいことに、CrewAIのBright Dataツールによって公式にサポートされている。
まずは、Bright Dataアカウントにサインアップしてください(すでにお持ちの場合はログインしてください)。その後、プロフィールのダッシュボードにアクセスし、公式の指示に従ってWeb Unlockerゾーンを設定してください:

ゾーンが「アクティブ」に設定されていることを確認してください:
この場合、Web Unlockerゾーンの名前は「web_unlocker」ですが、好きな名前を付けることができます。この名前はすぐに必要になるので、覚えておいてください。
セットアップが完了したら、公式ガイドに従ってBright Data APIキーを生成してください。すぐに必要になりますので、安全に保管してください。
起動した仮想環境に、CrewAI Bright Dataツール要件をインストールします:
pip install crewai[tools] aiohttp requests統合を機能させるために、以下の2つのenvを通して、Bright Dataの認証情報を.envファイルに追加してください:
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"を置き換える。 と プレースホルダーをそれぞれ実際の Bright Data API キーと Web Unlocker ゾーン名に置き換えてください。
次に、crew.pyでBright Dataツールをインポートします:
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchTool以下のように初期化する:
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()これらのツールをエージェントに渡すだけで、ウェブのロック解除とSERP検索機能をエージェントに提供できるようになりました。素晴らしい!
ステップ #4: タイトルスクレーパーエージェントの構築
これで、最初のエージェントを構築するための準備がすべて整いました。ウェブページからタイトルを抽出するタイトルスクレーパーエージェントから始めましょう。
ページタイトルを得るには、主に2つの方法がある:
<h1>HTML要素からテキストコンテンツを取得する。<h1>がない場合は、AIにページの残りの内容からページタイトルを推測してもらう。
これにはWeb Unlockerツールの統合が必要であることを忘れないでください。crew.pyで、CrewAIエージェントとタスクを以下のように定義します:
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)このタスクはサードパーティツールを呼び出すので、max_retriesオプションでリトライロジック(最大3回まで)を有効にすることは理にかなっている。これにより、一時的なネットワーク問題やツールエラーによるワークフロー全体の失敗を防ぐことができる。同じロジックを、(ツール経由の)サードパーティ・サービスに依存する、あるいはLLM処理エラーのために失敗する可能性のある複雑なAI操作を含む他のすべてのタスクに適用すべきである。
次に、agents.yaml設定ファイルで、Title Scraperエージェントを次のように定義する:
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."次に、tasks.yamlにそのメインタスクを以下のように記述する:
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."url}構文のおかげで、このタスクがCrewAIの入力からURLを読み取ることに注意してください。次のステップで、入力引数に入力する方法を説明します。
素晴らしい!Title Scraperエージェントが完成しました。同様のロジックを適用して、残りのすべてのエージェントを定義します。
ステップ#5: Googleクエリファンアウトリサーチャーエージェントの実装
CrewAIは、Geminiモデルで利用可能なGoogle検索ツールにアクセスする組み込みの方法を提供していません。代わりに、公式のGemini CrewAI統合リポジトリに示されているように、カスタムのGemini LLM統合を定義する必要があります。
基本的には、CrewAILLMクラスを継承したクラスを作成します。これはGeminiに接続し、google_searchツールを有効にします。このクラスは、カスタムllms/サブフォルダ内のgemini_google_search_llm.pyというファイルに置くことができます(または、このクラスを直接crew.pyの先頭に置くこともできます)。
カスタムのGemini LLM統合クラスを次のように定義します:
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)これにより、設定されたGeminiモデルでGoogle検索ツールにアクセスできるようになります。
注:Google検索ツールは、APIの無料ティアにいくつかのクォータを含んでいるので、プレミアムプランを必要とせずにあなたのアプリで使用することができます。
次に、crew.pyで GeminiWithGoogleSearchクラスをインポートします:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearchこれを使用して、クエリ・ファンアウト・リサーチャー・エージェントを以下のように指定する:
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)エージェントクラスで使用されるLLMはカスタムGeminiWithGoogleSearchクラスのインスタンスであることに注意してください。クエリファンアウト生成タスクはデバッグとさらなる分析のための貴重な出力を生成するので、カスタム出力ファイルにエクスポートする必要があります。この場合、生成された出力はoutput/query_fanout.mdファイルに保存されます。
また、エージェントのメインタスクのコンテキストが、ワークフロー内の前のエージェントからのメインタスクの出力であることに注目してください。このように、現在のエージェントは、タイトルスクレーパーエージェントによって生成された出力にアクセスすることができます。特に、Google検索ツールを介してファンアウト検索を実行する際に、それを入力として利用します。
次に、agents.yamlに以下を追加する:
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."そしてtasks.yamlの中にある:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."クエリーファンアウトがどのようなものか気になる方は、以下は実際のgoogle_searchツールの出力からの短いスニペットです:
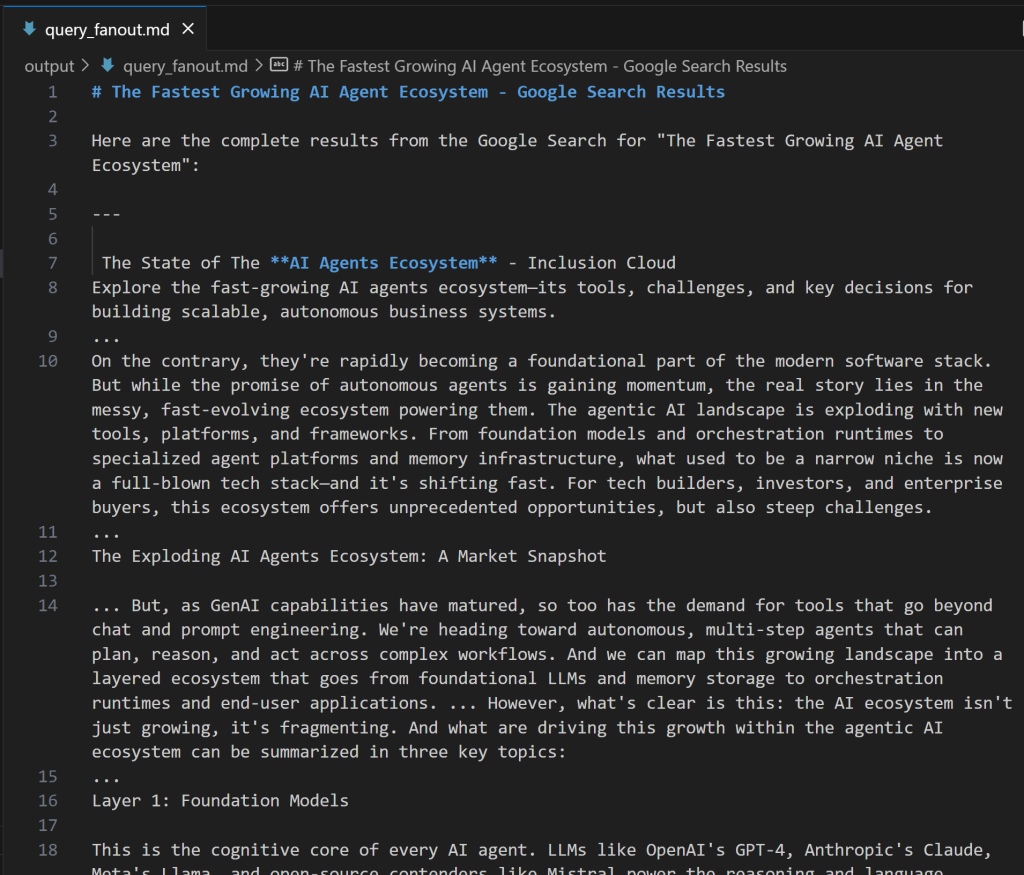
完璧!Google Query Fan-Out Researcherエージェントの準備が整いました。
ステップ6:残りのエージェントを定義する
前回同様、crew.pyに残りのエージェントを定義します:
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)それぞれ、上記のコードで指定されている:
- Google Main Query Extractorエージェントとその主なタスク。
- Google AI Overview Retrieverエージェントとその主なタスク。
- クエリファンアウトサマライザーエージェントとその主なタスク。
- AIコンテンツオプティマイザーエージェントとその主なタスク。
以下の行をagents.yamlに追加して、エージェント定義を完成させる:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."そして以下の行をtasks.yamlに追加する:
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.ai_overview_extraction_taskタスクが、SERP APIレスポンスに含まれるAI Overviewを取得するための技術仕様をどのように含んでいるかをご覧ください。詳しくは公式ドキュメントをご覧ください。
素晴らしい!これで、GEOコンテンツ最適化ワークフロー内のすべてのAIエージェントが作成されました。次に、それらをオーケストレーションするCrewを追加します。
ステップ#7:クルー内の全エージェントを集約する
crew.py内で、エージェントを順次実行するための新しいCrew関数を定義します:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)驚いた!crew.pyファイルのAiContentOptimizationAgentクラスが完成しました。ワークフローを開始するには、main.pyファイルのcrew()メソッドを実行するだけです。
ステップ#8:ランフローの定義
main.pyファイルをオーバーライドする:
- Pythonの
input()関数を使ってターミナルから入力URLを読み込む。 - 提供された URL を使用して、必要なエージェント入力を構築します。
AiContentOptimizationAgentインスタンスを初期化し、そのcrew()メソッドを呼び出します。- AIワークフローを実行する。
上記のロジックをmain.pyに以下のように実装します:
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")ステップ#9:エージェントのテスト
起動した仮想環境で、エージェントを起動する前に、必要な依存関係をインストールします:
crewai install次に、マルチエージェントGEO最適化システムを起動します:
crewai run入力URLを入力するプロンプトが表示されます:

この例では、CrewAIのサイトのページを入力として使用します:
https://www.crewai.com/ecosystem
このページでは、AIエージェントのエコシステムにおける主なアクターを紹介する。
このページでエージェントを実行すると、次のような出力が表示されます:
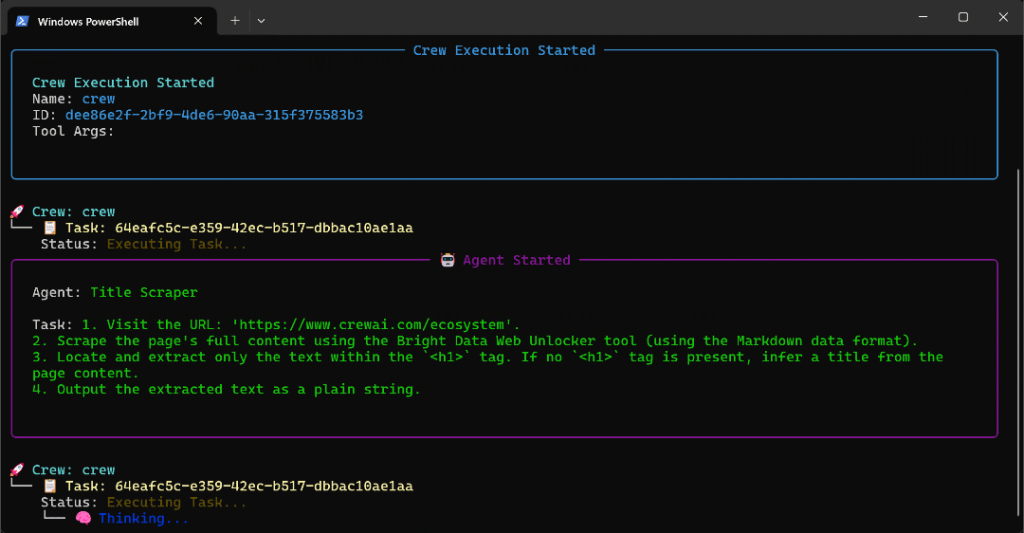
上のGIFはスピードアップされているが、これはステップ・バイ・ステップで起こることである:
- Title Scraperエージェントは、Bright Data Web Unlockerツールを介してページタイトルを収集します。その結果、
「最も急成長しているAIエージェントのエコシステム」(まさにページのスクリーンショットの通り)が出来上がりました。 - Google Query Fan-Out Researcherは
google_searchツールからクエリファンアウト出力を生成します。これはoutput/フォルダにquery_fanout.mdファイルを生成します。 - Google Main Query Extractorは、クエリファンアウトから主要なGoogleらしい検索クエリを特定する。結果は
"AI agent ecosystem growth "である。 - Google AI Overview RetrieverはBright Data SERP API経由で検索クエリのAI Overviewを取得します。出力は
ai_overview.mdに保存されます。 - クエリファンアウトサマライザーエージェントは、クエリファンアウトコンテンツを
query_fanout_summary.mdの詳細なMarkdown要約に凝縮します。 - AI Content Optimizerは、クエリファンアウトサマリーをGoogle AI Overviewと比較し、最終的な
report.mdファイルを生成します。
実行終了後、output/フォルダには以下の4つのファイルが格納されているはずだ:
Visual Studio Codeのプレビューモードでreport.mdを開き、スクロールする:

ご覧のように、GEO(およびSEO)のために指定された入力ページのコンテンツを最適化するのに役立つ詳細なMarkdownレポートが含まれています!
AIランキングのために改善したいウェブページのURLにこのエージェントを使用することで、GEOとSEOのポジショニングを強化することができます。
やった!ミッション完了。
次のステップ
上記で構築したAIコンテンツ最適化エージェントは、すでにかなり強力ですが、常に改善することができます。一つのアイデアは、ワークフローの最初にサイトマップを入力として受け取る別のエージェントを追加することです(オプションとして、例えばブログ記事のみを選択するために、正規表現を使ってURLをフィルタリングします)。このエージェントは、URLを既存のワークフローに渡すことができ、並行して、AIコンテンツ最適化のために複数のページを同時に分析できる可能性がある。
一般的に、agents.yamlと tasks.yamlの指示を試して、6つのエージェントの動作をあなたの特定のユースケースに合わせることができることを覚えておいてください。これらの調整に高度な技術的スキルは必要ありません!
結論
この記事では、Bright DataのAI統合機能を活用して、CrewAIでGEO/SEO最適化のための複雑なマルチエージェントワークフローを構築する方法を学びました。
ここで紹介するAIワークフローは、従来の検索エンジンとAIを活用した検索の両方に対して、ウェブページのコンテンツをプログラム的に改善する方法を探している人にとって理想的なものだ。
同様の高度なワークフローを作成するには、Bright Data AIインフラストラクチャでライブウェブデータを取得、検証、変換するためのあらゆるソリューションを探求してください。
今すぐBright Dataの無料アカウントを作成し、AIに対応したウェブツールの実験を始めましょう!




