
このブログ記事では、次のことを学びます:
- smolagentsとは何か、なぜ人気があるのか。
- エージェントはどのようにツールの実行に依存しているのか、またBright DataのWeb MCP経由でツールを取得する方法。
- AIコードエージェントを構築するために、Web MCPツールをsmolagentsに統合する方法。
さあ、飛び込もう!
smolagentsとは?
smolagentsは、最小限のコードで強力なAIエージェントを構築できる軽量のPythonライブラリです。プロンプトを実行するために必要なアクションを、実行可能なPythonコードスニペットとして記述します(テキスト応答を返すだけではありません)。
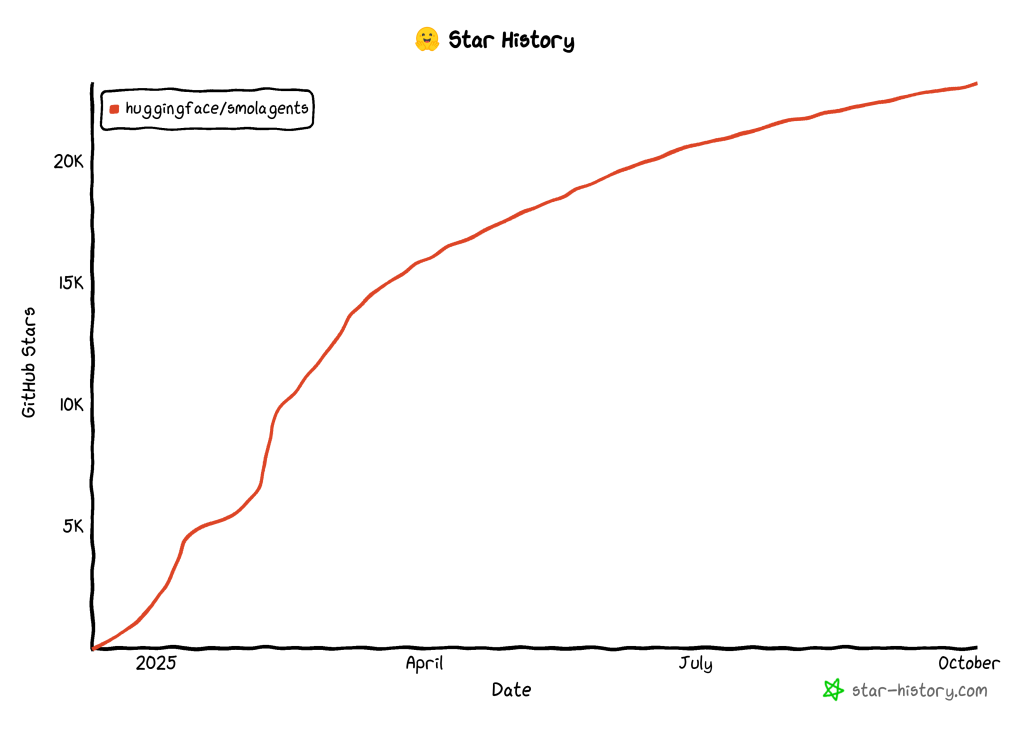
このアプローチは、効率を改善し、LLMの呼び出しを減らし、サンドボックス化された実行を通して、エージェントがツールや環境と安全に直接対話することを可能にする。コミュニティはAIエージェントを構築するためのこの新しいアプローチを受け入れており、それはライブラリがわずか数ヶ月の間にGitHubで2万3千のスターを獲得したことで証明されている:
smolagentsは以下の点に留意してほしい:
- モデルにとらわれず、OpenAI、Anthropic、局所変換器、Hugging Face Hub上のあらゆるLLMをサポートする。
- モダリティにとらわれず、テキスト、ビジョン、オーディオ、ビデオをサポートします。
- ツールにとらわれず、MCPサーバー、LangChain、Hub Spacesのツールをサポートします。
Hugging Faceブログのアナウンス記事で、このライブラリの背後にある哲学の詳細をご覧ください。
smolagentsがツール利用を推進する理由
LLMは訓練されたデータによって制限されます。LLMは、その知識に基づいて応答、コンテンツ、コード、マルチメディアを生成することができる。それは確かに強力だが、現在のAIの最大の限界のひとつでもある。
smolagentsは、ツールを中心に構築されたエージェントを提供することで、それに対処している。これは、ライブラリーのすべてのエージェントクラスが、ツールのリストを必須引数として受け付けるほど、極めて重要なことです。ツール呼び出しのおかげで、あなたのAIモデルは環境と対話し、コンテンツ生成以外のタスクを実行することができます。
特に、smolagentsはMCPサーバー、LangChain、あるいはHub Spaceからツールに接続できることを覚えておいてください。また、標準的なJSON/テキストベースのツール呼び出しもサポートしている。
さて、今日の典型的なAIに欠けているものは何だろうか?正確で最新のデータと、人間のようにウェブページと対話する能力だ。これこそが、ブライト・データのウェブMCPツールが提供するものだ!
Web MCPは、60以上のAIのためのツールを提供するオープンソースのサーバーで、すべてBright Dataのウェブインタラクションとデータ収集のためのインフラによって支えられています。無料版でも、2つの革新的なツールにアクセスできます:
| ツール | ツール |
|---|---|
検索エンジン |
Google、Bing、Yandexの検索結果をJSONまたはMarkdownで取得します。 |
scrape_as_markdown |
ボット検知やCAPTCHAをバイパスして、あらゆるウェブページをクリーンなMarkdownフォーマットにスクレイピングする。 |
これら以外にも、Web MCPはクラウドブラウザでインタラクションするためのツールや、YouTube、Amazon、LinkedIn、TikTok、Yahoo Financeなどのプラットフォームで構造化されたデータを収集するための数十の特別なツールを公開している。公式GitHubページで詳細をご覧ください。
smolagentsを使ったWeb MCPの実例をご覧ください!
Web MCPツールでsmolagents AIコードエージェントを拡張する方法
このチュートリアルでは、Bright Data Web MCPと統合するsmolagents AIエージェントを構築する方法を学びます。具体的には、エージェントは、MCP サーバーによって公開されるツールを使用して、オンザフライでウェブデータを取得し、それに対してセンチメント分析を実行します。
注:これは単なる例であり、入力プロンプトを変更することで、簡単に他のユースケースに適応させることができます。
以下の指示に従ってください!
前提条件
このチュートリアルに従うには、以下を確認してください:
- Python 3.10+がローカルにインストールされていること。
- Web MCPを実行するためにマシンにインストールされたNode.js(最新のLTSバージョンを推奨します)。
- Gemini APIキー(または他のサポートされているモデルのAPIキー)。
APIキー付きのBright Dataアカウントも必要です。APIキーについては後ほどご案内いたしますので、ご安心ください。MCPの仕組みや Web MCPが提供するツールについての基本的な理解も役立ちます。
ステップ1:プロジェクトのセットアップ
ターミナルを開き、smolagentsプロジェクト用の新しいフォルダを作成します:
mkdir smolagents-mcp-agentsmolagents-mcp-agent/には、Web MCP ツールを使って拡張した AI エージェントの Python コードが入ります。
次に、プロジェクト・ディレクトリに入り、その中で仮想環境を初期化します:
cd smolagents-mcp-agent
python -m venv .venvagent.pyという新しいファイルを追加します。プロジェクトのファイル構造は次のようになります:
smolagents-mcp-agent/ です。
├─ .venv/
└─ agent.pyagent.pyはメインのPythonファイルであり、AIエージェントの定義を含んでいます。
お気に入りのPython IDEでプロジェクトフォルダをロードします。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
先ほど作成した仮想環境を起動します。LinuxまたはmacOSでは、起動します:
source .venv/bin/activate同様に、Windowsでは、以下を実行します:
.venv/Scripts/activate仮想環境をアクティブにした状態で、必要なPyPIライブラリをインストールします:
pip install "smolagents[mcp,openai]" python-dotenv依存関係は
- 「
smolagents[mcp,openai]"です:smolagents[mcp,openai]”: MCP統合とOpenAIライクなAPIを提供するプロバイダへの接続のためのセクションで拡張されたsmolagentパッケージ。 python-dotenv: ローカルの.envファイルから環境変数を読み込みます。
完了です!これでsmolagentsでAIエージェントを開発するためのPython環境が整いました。
ステップ #2: 環境変数の読み込み設定
エージェントは、GeminiやBright Dataのようなサードパーティのサービスに接続します。これらの接続を認証するために、APIキーを設定する必要があります。agent.pyファイルにハードコーディングすることは、セキュリティ上の問題を引き起こす可能性があるため、コード臭くなります。そこで、環境変数から秘密を読み取るようにスクリプトを設定します。
これがpython-dotenvパッケージをインストールした理由です。agent.pyファイルで、ライブラリをインポートし、環境変数を読み込むためにload_dotenv() を呼び出します:
from dotenv import load_dotenv
load_dotenv()これでスクリプトはローカルの.envファイルから環境変数にアクセスできるようになりました。
プロジェクトのディレクトリに.envファイルを追加します:
smolagents-mcp-agent/に.envファイルを追加します。
├─ .venv/
├── .env # <------ └── agent.py
└── agent.pyこれで、コード中で環境変数にアクセスできるようになります:
import os
os.getenv("ENV_NAME")素晴らしい!これで、スクリプトは環境変数からサードパーティの統合シークレットを安全にロードできるようになりました。
ステップ 3: Bright Data Web MCP をローカルでテストする
Bright Data Web MCP への接続を設定する前に、マシンがサーバーを実行できることを確認してください。これは、ローカルで Web MCP を起動するように smolagents に指示するために必要です。エージェントは、STDIO経由で接続します。
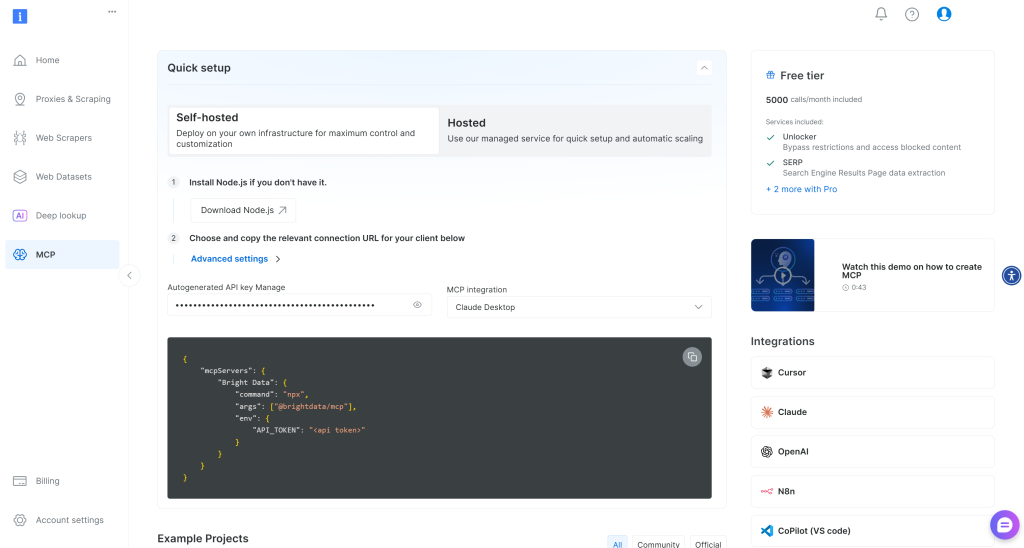
Bright Dataアカウントをお持ちでない場合は、新規アカウントを作成してください。お持ちの場合は、ログインしてください。簡単なセットアップには、アカウントの “MCP“セクションの指示に従ってください:
そうでない場合は、以下の手順に従ってください。
まず、Bright Data APIキーを生成します。すぐに必要になりますので、安全な場所に保管してください。ここでは、API キーが管理者権限を持っていると仮定します。
brightdata/mcpパッケージを使用して、Web MCP をお使いのマシンにグローバルにインストールします:
npm install -g @brightdata/mcp次に、ローカルのMCPサーバーを起動して動作することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellでも同様です:
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API> のプレースホルダを Bright Data API トークンに置き換えてください。これらのコマンドは必要なAPI_TOKEN環境変数を設定し、npmパッケージを実行してWeb MCPをローカルに起動します。
成功すると、このようなログが表示されます:

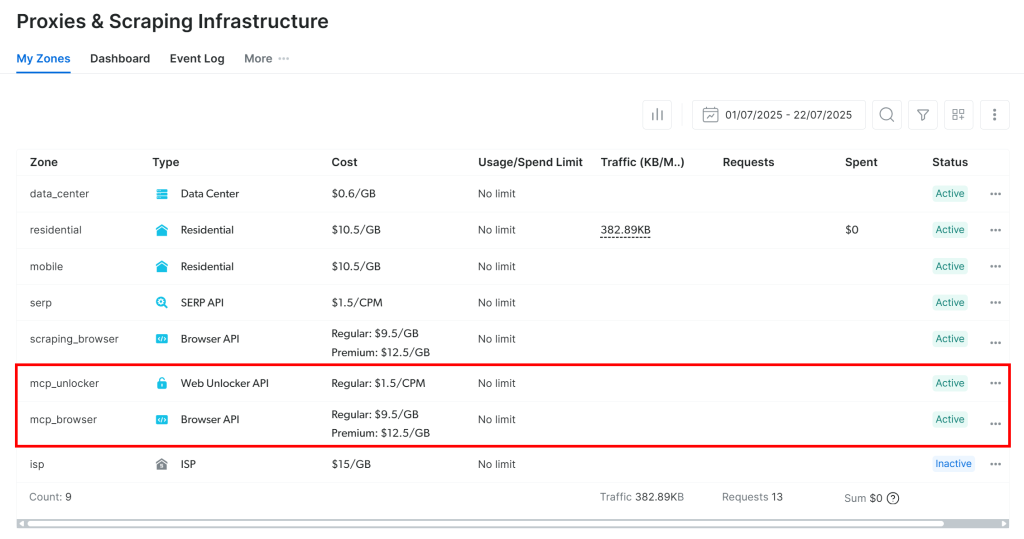
初回起動時に、Web MCPは自動的にBright Dataアカウントに2つのデフォルトゾーンを作成します:
mcp_unlocker:mcp_unlocker:Web Unlocker用のゾーンです。mcp_browser:mcp_unlocker:Browser APIゾーン。
60以上のツールを動かすために、Web MCPはこれら2つのBright Data製品に依存しています。
ゾーンが作成されたことを確認したい場合は、Bright Dataのダッシュボードにログインしてください。プロキシ&スクレイピングインフラストラクチャ“ページにアクセスし、テーブル内の2つのゾーンを確認してください:
注意: API トークンにAdmin権限がない場合、2つのゾーンは作成されません。この場合、GitHubで説明されているように、手動で設定し、環境変数で名前を設定する必要があります。
デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツール(とそのバッチ版)のみを公開します。これらのツールはWeb MCPのフリー・ティアに含まれているため、無料で使用することができます。
ブラウザ自動化ツールや構造化データ・フィード・ツールなどの高度なツールのロックを解除するには、Proモードを有効にする必要があります。これを行うには、Web MCPを起動する前に環境変数PRO_MODE="true "を設定します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、Windowsの場合
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpプロ・モードは60以上のツールをアンロックしますが、無料版には含まれておらず、追加料金が発生します。
素晴らしい!これでWeb MCPサーバーがシステム上で動作していることが確認できました。これからスクリプトを起動し、MCPに接続するように設定するので、MCPプロセスを終了してください。
ステップ#4: Web MCPへの接続
PythonスクリプトにSTDIO経由でWeb MCPサーバーに接続するように指示します。
まず、先ほど取得したBright Data APIキーを.envファイルに追加します:
bright_data_api_key="<your_bright_data_api_key>"<YOUR_BRIGHT_DATA_API_KEY> のプレースホルダを実際のキーに置き換えます。
agent.pyで、APIキーをロードします:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY") でAPIキーをロードします。次に、STDIO接続を設定するためにStdioServerParametersオブジェクトを定義します:
from mcp import StdioServerParameters
server_parameters = StdioServerParameters(
command="npx"、
args=["-y", "@brightdata/mcp"]、
env={
"API_TOKEN":bright_data_api_key、
"PRO_MODE":"true", # オプション
},
)このセットアップは、APIトークンに環境変数を使用する、先ほどのnpxコマンドを反映している。API_TOKENは必須ですが、PRO_MODEはオプションです。
MCPClientインスタンスを使用して、これらの接続設定を適用し、サーバーによって公開されたツールのリストを取得します:
from smolagents import MCPClient
from smolagents import MCPClient with MCPClient(server_parameters, structured_output=True) as tools:あなたのagent.pyスクリプトは、Web MCPプロセスを起動し、STDIO経由で接続します。結果は、smolagents AIエージェントに渡すことができるツールの配列です。
利用可能なツールを表示して接続を確認します:
for bright_data_tools in bright_data_tools:
print(f "TOOL: {bright_data_tool.name} - {bright_data_tool.description}n")Proモードを無効にしてスクリプトを実行すると、限られたツールしか表示されない:
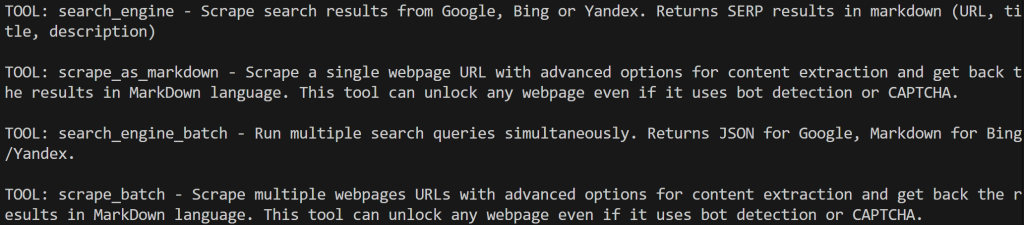
Proモードを有効にすると、60以上のツールがすべて表示される:
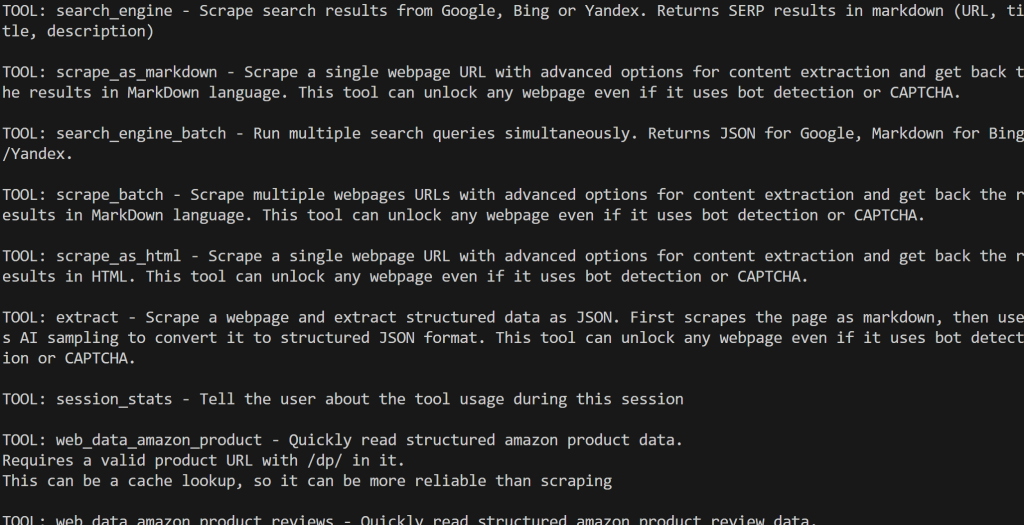
素晴らしい!これで、Web MCP統合が正しく機能していることが確認できます。
ステップ#5: LLM統合の定義
スクリプトはツールにアクセスできるようになりましたが、エージェントには頭脳も必要です。つまり、LLMサービスへの接続を設定する時です。
.envファイルにGemini APIキーを追加することから始めます:
gemini_api_key="<your_gemini_api_key>"次に、それをagent.pyファイルにロードします:
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")次に、Gemini API に接続するためのOpenAIServerModelインスタンスを定義します:
from smolagents import OpenAIServerModel
model = OpenAIServerModel(
model_id="gemini-2.5-flash"、
# Google Gemini OpenAI互換APIベースURL
api_base="https://generativelanguage.googleapis.com/v1beta/openai/"、
api_key=GEMINI_API_KEY、
)OpenAI用のモデルクラスを使用している場合でも、これは動作します。これは、設定した特定のapi_baseのおかげで、Gemini統合のためのOpenAI互換エンドポイントにアクセスすることができます。素晴らしい!
ステップ #6: Web MCPツールでAIエージェントを作成する
これで、smolagentsコードのAIエージェントを作成するためのすべての構成要素が揃いました。Web MCPツールとLLMエンジンを使って、AIエージェントを定義します:
from smolagents import CodeAgent
agent = CodeAgent(
model=model、
tools=tools、
stream_outputs=True、
)CodeAgentは、主なsmolagents AIエージェントタイプです。これは、アクションを実行し、タスクを解決するためのPythonコード・スニペットを生成します。このアプローチの長所と短所は以下の通りです:
長所
- 表現力が高い:複雑なロジックや制御フローを扱い、複数のツールを組み合わせることができる。さらに、ループ、変換、推論などもサポートする。
- 柔軟性がある:新しいアクションやツールを動的に生成できるため、すべてのアクションを事前に定義する必要がない。
- 創発的推論:マルチステップの問題や動的な意思決定に適している。
短所
- エラーのリスク:Pythonの構文エラーや例外が発生する可能性がある。
- 予測可能性が低い:出力が予期しない、あるいは安全でない可能性がある。
- 安全な環境が必要:安全な実行コンテキストで実行する必要があります。
あとはエージェントを実行し、タスクを実行させるだけです!
ステップ #7: エージェント内でタスクを実行する
エージェントのウェブデータ検索機能をテストするには、適切なプロンプトを書く必要があります。例えば、YouTube 動画のコメントのセンチメントを分析したいとします。
Web MCP ツールがコメントを取得し、CodeAgentによって生成された Python スクリプトがセンチメント分析を実行します。最後に、コードが実行されます。生成された Python コードを持つことは、プロセスを理解し、将来の拡張を容易にするためにも役立ちます。
エージェントで以下のようなプロンプトを実行することで、これを実現できます:
prompt = """
以下のYouTube動画からトップ10のコメントを取得します:
実際のコメントからの抜粋とともに、センチメント分析を含む簡潔なレポートを提供します。
"""
# エージェントでプロンプトを実行する
agent.run(prompt)入力ビデオは、コミュニティからあまり評判の良くないビデオゲームであるBlack Ops 7のトレイラー発表である。
ほとんどのコメントはかなり偏っているので、センチメント分析は主に否定的な反応を強調する結果を出すと予想される。
ステップ#8: 全てをまとめる
現在、agent.pyファイルには以下の内容が含まれているはずです:
# pip install "smolagents[mcp,openai]" python-dotenv
from dotenv import load_dotenv
import os
from smolagents import OpenAIServerModel, MCPClient, CodeAgent, ToolCallingAgent
from mcp import StdioServerParameters
# .envファイルから環境変数をロードする
load_dotenv()
# APIキーをenvファイルから読み込む
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
server_parameters = StdioServerParameters(
command="npx"、
args=["-y", "@brightdata/mcp"]、
env={
"API_TOKEN":bright_data_api_key、
"PRO_MODE":"true", # オプション
},
)
# Gemini への接続を初期化する
model = OpenAIServerModel(
model_id="gemini-2.5-flash"、
# Google Gemini OpenAI互換APIベースURL
api_base="https://generativelanguage.googleapis.com/v1beta/openai/"、
api_key=GEMINI_API_KEY、
)
# MCPクライアントの初期化とツールの取得
with MCPClient(server_parameters, structured_output=True) as tools:
# MCPツールで拡張されたAIエージェントを定義します。
agent = CodeAgent(
model=model、
tools=tools、
stream_outputs=True、
)
prompt = """
以下のYouTube動画からトップ10のコメントを取得する:
実際のコメントからの抜粋とともに、センチメント分析を含む簡潔なレポートを提供する。
"""
# エージェントでプロンプトを実行する
agent.run(prompt)約束通り、smolagentsは期待に応え、50行以下のコードでMCP統合の完全なAIエージェントを構築することができます。
実行してテストしてみましょう:
python agent.pyWeb MCPのProモードを有効にして実行するとします。結果は次のような複数ステップの出力になります:
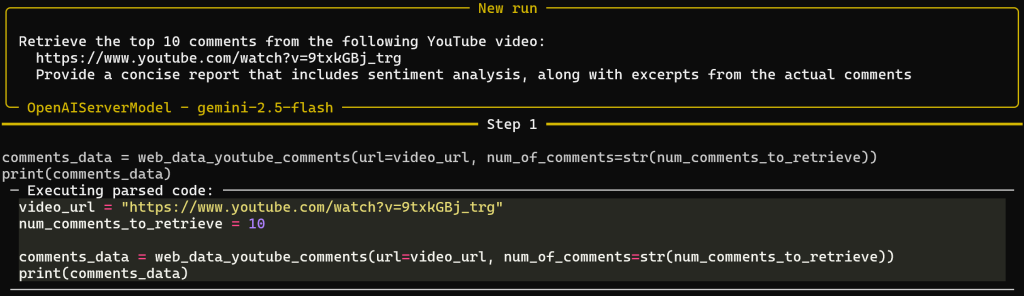
プロンプトに基づき、エージェントはweb_data_youtube_commentsWeb MCP ツールを正常に選択したことに注意してください。これは、ゴールに到達するために正しい引数で呼び出されました。このツールは次のように説明されています:「構造化されたyoutubeのコメントデータを素早く読み込む。有効なyoutube動画のURLが必要。これはキャッシュ検索が可能なので、スクレイピングよりも信頼できる。”ということで、良い判断ができた!
ツールがコメントデータを返した後、レポート生成のステップ2が始まる:
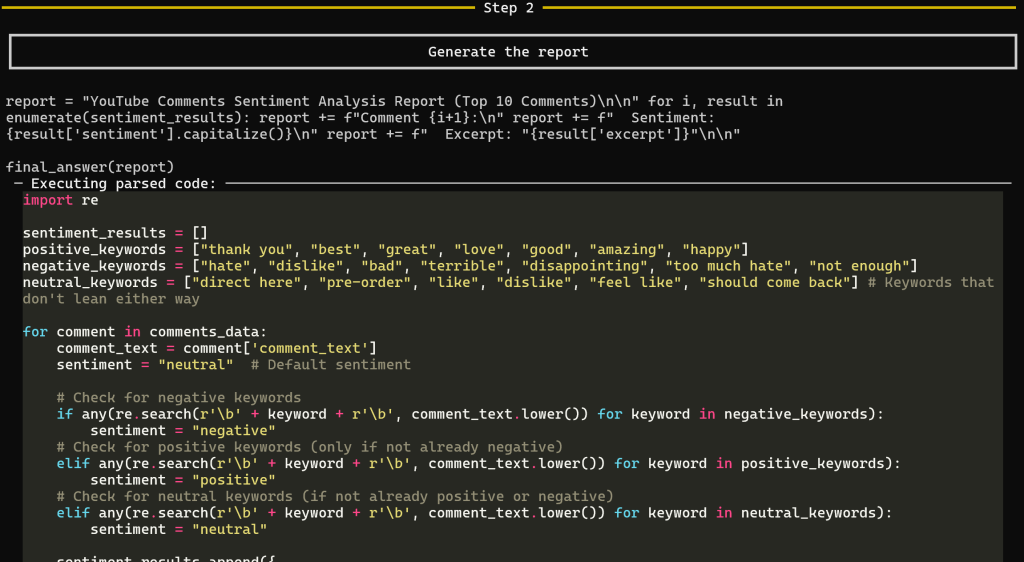
このステップでは、最終的なセンチメント分析レポートを生成します。特に、CodeAgent はレポートを生成するためのすべての Python コードを生成し、web_data_youtube_comments によって取得されたデータに対して実行します。
このアプローチでは、AI が出力を生成するために使用したプロセスを明確に理解することができ、LLM の通常の「ブラックボックス」効果の多くを取り除くことができます。
結果は次のようになる:
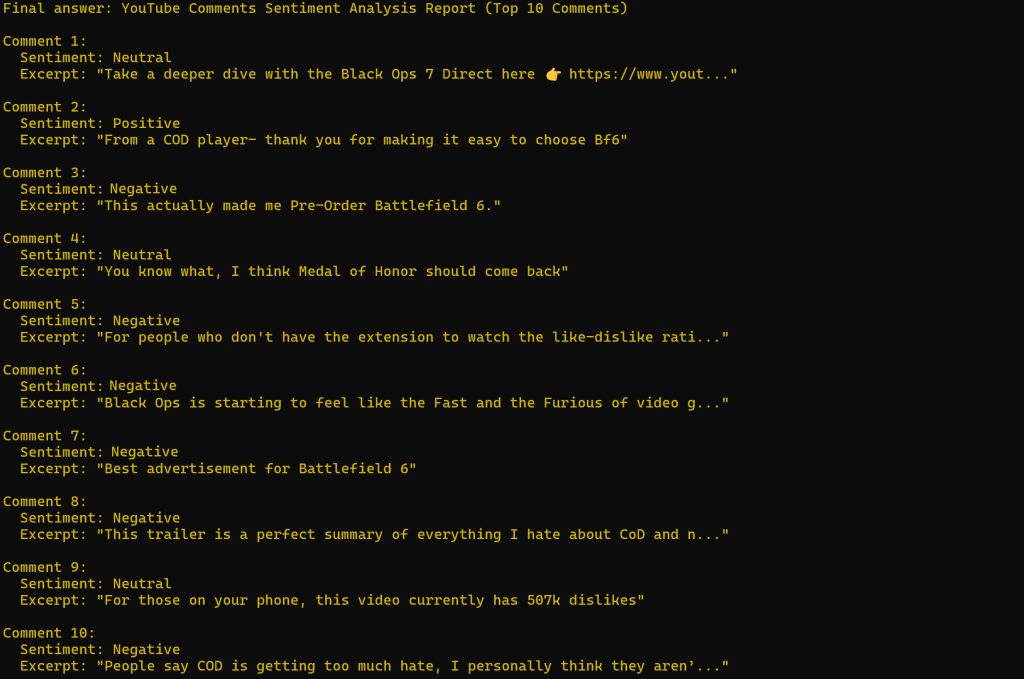
予想通り、センチメント分析は大部分が否定的である。
レポートで参照されているコメントは、YouTubeの動画ページで見ることができるものと完全に一致することに注意してください:
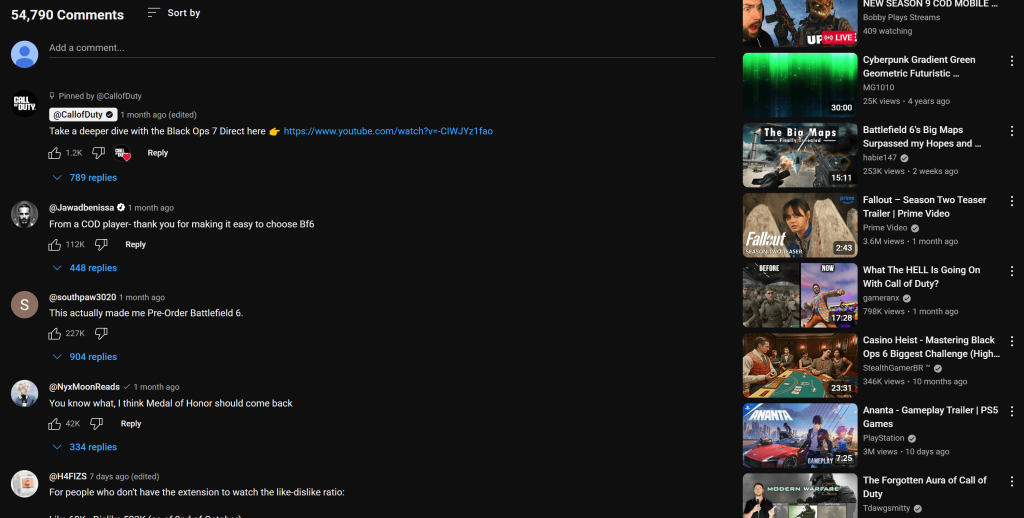
YouTubeのスクレイピングを試したことがある人なら、ボット対策やユーザーとのやり取りが必要なため、いかに難しいかわかるだろう。これは、バニラLLMでは対応できないことであり、ブライト・データのウェブMCPをsmolagents AIエージェントに統合することのパワーと有効性を示しています。
様々な入力プロンプトを自由に試してみてください。Bright Dataの幅広いWeb MCPツールを使えば、実世界の様々なユースケースに対応できます。
出来上がりです!Bright DataのWeb MCPとPythonのsmolagentsコードAIエージェントの組み合わせの威力がお分かりいただけたと思います。
まとめ
このブログポストでは、smolagentsを使ってコードベースのAIエージェントを構築する方法を学びました。Bright DataのWebMCPのツールを使ってそれを強化する方法を学びました。
この統合は、ウェブ検索、構造化データ抽出、ライブウェブデータフィードへのアクセス、自動化されたウェブインタラクションなどでエージェントを強化します。さらに洗練されたAIエージェントを作成するには、Bright Dataのエコシステムで利用可能な幅広いAI対応製品とサービスをご覧ください。
今すぐBright Dataのアカウントを作成し、ウェブデータツールの実験を開始してください!




