
このブログ記事では、以下の内容をご紹介します:
- ソーシャルリスニングとは何か、そしてなぜそれが価値あるものなのか。
- ソーシャルリスニングを行う上で、エージェント型AIが最適なアプローチである理由。
- ソーシャルメディア・リスニング、特にエージェントを介したAI活用における主な課題。
- 専用のエージェント対応ソーシャルメディアスクレイピングツールを用いて、それらを克服する方法。
- Bright Dataのソーシャルメディアスクレイピングツールを活用し、LangChain上でエージェント型ソーシャルリスニングワークフローを構築するためのステップバイステップガイド。
- この例を本番環境対応のエージェンティックワークフローにするために必要なもの。
- ソーシャルリスニングにおける実世界のエージェント型ワークフローの事例。
さっそく見ていきましょう!
ソーシャルリスニング:その定義、仕組み、および事例
ソーシャルリスニングとは、デジタル上の会話を監視・分析し、ブランド、製品、発表、業界、または特定のトピックについて人々が何を言っているかを把握するプロセスです。
これは、単に言及を追跡するだけにとどまりません。ソーシャルリスニングは、トレンドの発見、感情の測定、そして外部の一般大衆が実際にどう感じているかを理解するのに役立ちます。その最終的な目標は、マーケティング、製品に関する意思決定、およびカスタマーサポートに役立つインサイトを生成することです。
大まかに言えば、ソーシャルリスニングは一般的に以下の2つのステップで進められます:
- モニタリング:ソーシャルメディアプラットフォーム上で、対象トピック(競合他社、自社ブランド、関連キーワードなど)に関連する言及、コメント、会話を追跡します。
- 分析:そのデータを解釈し、何が起きているかを把握し、パターンを特定し、成果を向上させたり、より深い知見を得たりするためのアクションを起こします。
例えば、企業はRedditのニッチなコミュニティにおけるフィルターのかかっていない議論を調査し、課題や機能要望を発見することができます。同様に、ブランドはInstagramのコメントやハッシュタグを分析して、エンゲージメントやブランド認知度を測定することも可能です。
ソーシャルリスニングにAIエージェント型ワークフローが最適な理由
従来のソーシャルリスニングのワークフローは通常、静的なものであり、固定されたパイプラインを通じて入力から出力へとデータを流す一連のコンポーネントで構成されています。
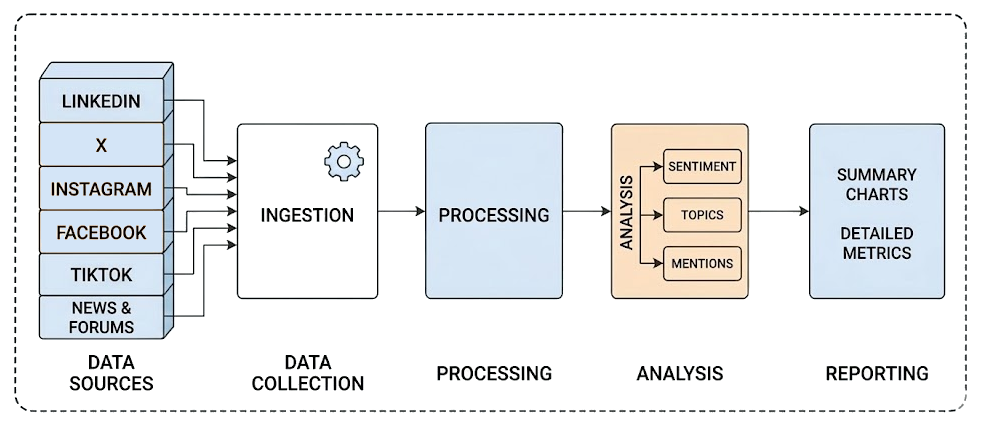
このアプローチは多くのデータ分析プロセスでは有効ですが、ソーシャルメディアデータには不向きです。その理由は、文脈を解釈し、新たな会話に継続的に適応することが極めて困難だからです。ここで、AI、特にエージェント型ワークフローが強力な解決策となります!
エージェント型ソーシャルリスニングワークフローは、受動的なデータストリームを能動的なインテリジェンスエンジンへと変革します。結局のところ、静的なパイプラインとは異なり、AIエージェントは自律的な行動をとることができるからです。
例えば、エージェントがReddit上で感情の異常な急上昇を検知した場合、XやThreads上の関連スレッドを積極的に調査して根本原因を特定できます。また、Reddit自体(あるいは場合によってはGoogle)でより詳細な調査を行い、何が起きているのかを理解することも可能です。
特に、エージェント型ソーシャルリスニングワークフローの主な利点は以下の通りです:
- 詳細なセンチメント分析:「ポジティブ/ニュートラル/ネガティブ」という単純なラベル付けにとどまらず、AIは皮肉や文化的背景を理解します。これにより、特にセンチメントやエンゲージメントの観点から、入力データを高精度に把握することが可能になります。
- 自律的な調査:エージェントは、絶え間ない手動介入を必要とすることなく、新たなトレンドを積極的に探したり、進行中の会話についてさらに深く掘り下げたりすることができます。
- クロスプラットフォーム統合:エージェント型ワークフローは複数のネットワークを同時に監視し、インサイトを単一のアクション可能なビューに集約できます。
固定的なパイプラインからエージェント型推論へと移行することで、真の意味でのソーシャルメディアのリスニングが可能になります。この転換により、パイプライン内の要素を変更することなく、会話そのものと同じ速さで進化する動的なシステムが実現します。
AIを活用したソーシャルメディア・リスニングの課題
AIがソーシャルリスニングを大幅に容易にしたことは疑いようがありません。特に「なぜ」を理解する点において顕著です。高度なAI/MLモデルは、センチメントを分析し、潜在的なトレンドを予測し、さらにはニュアンスを解釈することさえ可能です。しかし、依然として大きな課題が残っています。それは、ソーシャルメディアデータを確実かつ大規模に収集する方法です。
主な考え方は、エージェント型ワークフローをソーシャルプラットフォームのAPI(利用可能な場合)に直接接続することです。しかし、公式APIは高額であったり、レート制限の対象となったり、取得したデータの処理方法に制約が課されたりすることがあります。さらに、APIのレスポンスは時間の経過とともに変化したり、不完全であったりする場合もあります。これらの理由から、APIは現実的な選択肢とならないことが多く、多くのチームは代わりにウェブスクレイピングに頼っています。
それでも、ソーシャルメディアのスクレイピングは、いくつかの理由から本質的に困難です:
- プラットフォームの複雑さと変化:ソーシャルメディアサイトは絶えず進化しており、複雑で極めて動的なインタラクションやナビゲーションのパターンを有しています。そのため、データのパースは困難な作業となります。
- ボット対策:CAPTCHA、人間による認証チェック、レート制限などに対処するには、IPローテーションやフィンガープリント管理など、高度な戦略が必要となります。
- データの断片化:データは複数のプラットフォーム(X、Instagram、Threads、TikTok、Reddit、LinkedIn、YouTube、Facebookなど)に分散しており、統一されたソーシャルメディアデータセットを作成するのが困難です。
信頼できるソーシャルメディアスクレイピングツールを利用できる場合でも、さらに2つの障壁が残ります:
- ツールの互換性:スクレイピングツールは、使用予定のAIライブラリやエージェント型ワークフローと互換性がある必要があります。
- データの有用性:スクレイピングされたデータは、構造化され、クリーニングされ、AIが容易に理解できる形式で提供されなければなりません。遅延、フォーマットの不統一、またはデータフィールドの欠落は、エージェント型ワークフローの有効性を低下させ、幻覚(ハルシネーション)のリスクを高める可能性があります。エージェント型AIに最適なデータ形式についてご覧ください。
このように、AIがソーシャルリスニングを変革している一方で、真のボトルネックはデータ取得にあります。
実証済みでスケーラブルなエージェント型ソーシャルリスニングを実現するAI対応ツール
AIエージェントが信頼できるソーシャルメディアデータにアクセスできるようにすることが、エージェント型ソーシャルリスニングワークフローにおける主な障壁であることはご存知でしょう。したがって、解決策は明らかです。エージェントには、ソーシャルメディアスクレイピングのための信頼性が高く、エンタープライズ対応のツールへのアクセスが必要です。
AIエージェントによって自律的に呼び出されると、これらのツールは選択されたソーシャルメディアプラットフォームからAIに最適化されたデータを取得します。返されたデータは、AIが分析、推論、そしてインサイトを導き出すための基盤となります。課題は優れたツールを見つけることです。それらがなければ、ウェブスクレイピングに伴う典型的な信頼性やスケーラビリティの問題に直面することになるからです。
したがって、エージェント対応のソーシャルメディアスクレイピングツールには、以下の要件が求められます:
- 高い堅牢性を備え、成功率が高く、ダウンタイムが最小限であること。
- 大量のデータを処理するために、同時リクエストに対応していること。
- JSONやMarkdownなど、LLMへの取り込みに最適な形式でコンテンツを返すこと。
- LangChain、LlamaIndex、CrawlAI、Agno、Dify、または類似のフレームワークなど、選択したAIエージェントライブラリとシームレスに統合できること。
- レート制限、IPローテーション、CAPTCHA、その他の保護措置を含む、ボット対策に対応していること。
- 複数のソーシャルメディアプラットフォームに対応していること。
これこそが、Bright Dataの「Social Mediaスクレイパー」サービスが提供する機能です。詳細を見ていきましょう!
Bright DataのAI対応ソーシャルメディアスクレイピングツール
Bright Dataは、業界をリードするウェブデータ収集プラットフォームであり、主要なソーシャルメディアデータプロバイダーの中でも第1位にランクされています。同社のAI対応スクレイピングソリューションの中でも、「Social Media Scraper」はエージェント型ワークフローにおいて際立っています:
- 99.99%の信頼性と99.95%の成功率を実現し、ダウンタイムを最小限に抑えながらAIエージェントへの継続的なデータフローを保証します。
- 195カ国にまたがる1億5,000万のIPアドレスから成るプロキシネットワークにより、高い同時接続性をサポートし、大規模な運用に対応しています。
- 最大5,000のソーシャルメディアページを同時に一括スクレイピングでき、エージェントが大量のデータを処理できるようにします。
- JSONやMarkdownなど、構造化されたLLM対応フォーマットでデータを返却し、高速な取り込み、推論、および下流のAI処理に最適化されています。
- 70以上のAIフレームワークやソリューションとの公式連携に加え、カスタム実装のためのネイティブAPIを提供します。
- ボット対策やスクレイピング対策の課題を自動的に処理します。
- Facebook、Instagram、LinkedIn、TikTok、X、Pinterest、Quora、YouTube、Threads、Reddit、Vimeo などの主要プラットフォームに対応しています。
- 成功報酬型モデルによりコスト効率が確保され、大規模なAI駆動型データ収集を予測可能かつ経済的に行えます。
注:このソリューションは、Bright DataのWeb MCPサーバーを介してネイティブにも利用可能であり、エージェントワークフローへの統合を簡素化します。
Bright Dataを活用したソーシャルリスニングエージェントの構築方法
このガイドセクションでは、シンプルなソーシャルリスニングエージェントの始め方をご紹介します。ここではLangChainで構築しGeminiに接続しますが、他のAIエージェントフレームワークやLLMプロバイダーでも同様に機能します。
注:Bright Dataのソリューションを使用してソーシャルリスニング向けのAI搭載アプリケーションを構築する方法に関する実践的な手順については、「AI搭載ソーシャルリスニングアプリの構築」ウェビナーをご参照ください。
以下の手順に従ってください!
前提条件
このチュートリアルを進めるには、以下の環境が整っていることを確認してください:
- ローカル環境にPython 3.10がインストールされていること。
- APIキーが準備されたBright Dataアカウント。
- Gemini APIキー(またはLangChainがサポートする他のLLMプロバイダーのAPIキー)。
- LangChainエージェントの仕組みに関する基本的な理解。
Bright Data APIキーの設定については、公式ガイドをご参照ください。公式のLangChain–Bright Dataツールを使用してLangChainエージェントをBright Dataに接続する際に必要となるため、APIキーは安全に保管してください。
Bright DataとLangChainの統合に関する詳細については、以下のブログ記事をご参照ください:
ステップ 1: LangChain プロジェクトの設定
ソーシャルリスニングエージェント用の新しい Python プロジェクトを作成します:
mkdir agentic-social-listening
cd agentic-social-listeningプロジェクトフォルダ内で仮想環境を作成し、有効化します:
python -m venv .venv
source .venv/bin/activate # Windowsの場合は: .venvScriptsactivateソーシャルリスニングエージェントのロジックを記述するagent.pyファイルを追加します。プロジェクトの構造は次のようになります:
agentic-social-listening/
├── .venv/
└── agent.py起動した仮想環境で、必要なライブラリをインストールします:
pip install langchain langchain-google-genai langchain-brightdataこれらは以下の通りです:
langchain: AIエージェントの構築を簡素化します。langchain-google-genai:ChatGoogleGenerativeAI統合機能を通じて、エージェントを Gemini に接続します。langchain-brightdata:ドキュメントで説明されているように、公式の統合機能を通じて、LangChainエージェントをBright Dataのスクレイピングソリューションに接続します。
素晴らしい!お気に入りのPython IDEでプロジェクトフォルダを開き、エージェント型ソーシャルリスニングワークフローの開発準備を整えましょう。
ステップ #2: エージェントのワークフローを定義する
ある発表に関する2つの投稿(InstagramとTikTokの各1件)のセンチメントとメンションを監視するソーシャルリスニングエージェントを構築するとします。投稿は異なりますが、その根底にある発表内容は同一です。
これは興味深い例です。なぜなら、エージェントが単一のキャンペーンに対して複数のプラットフォームにわたるエンゲージメントを追跡し、共通する感情やプラットフォーム固有の感情を特定し、製品の言及やプロモーションの依頼を検出できることを示しているからです。
ここでは、ナイキの発表を例に挙げます。Instagramでは次のように表示されます: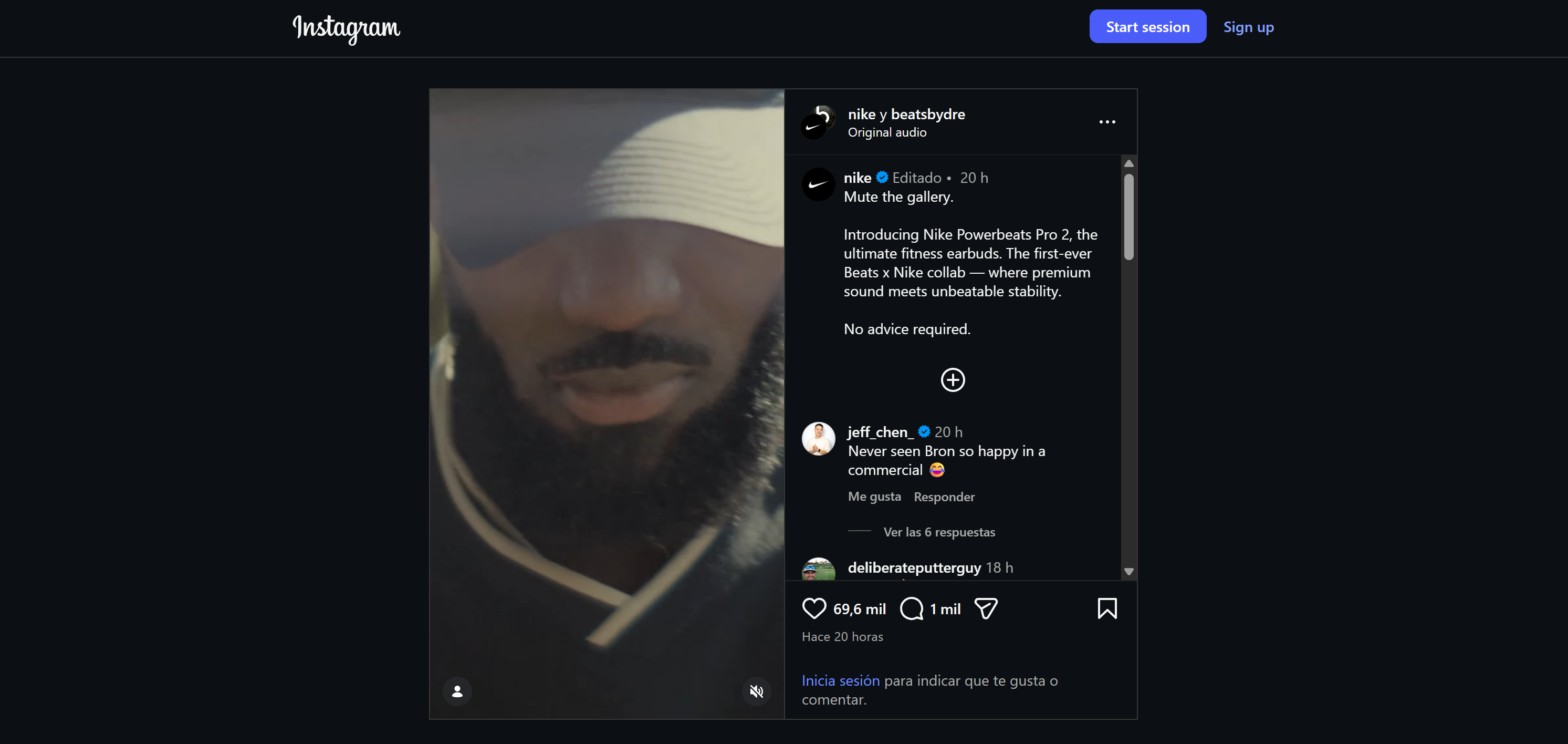
そして、TikTokでは次のように表示されます: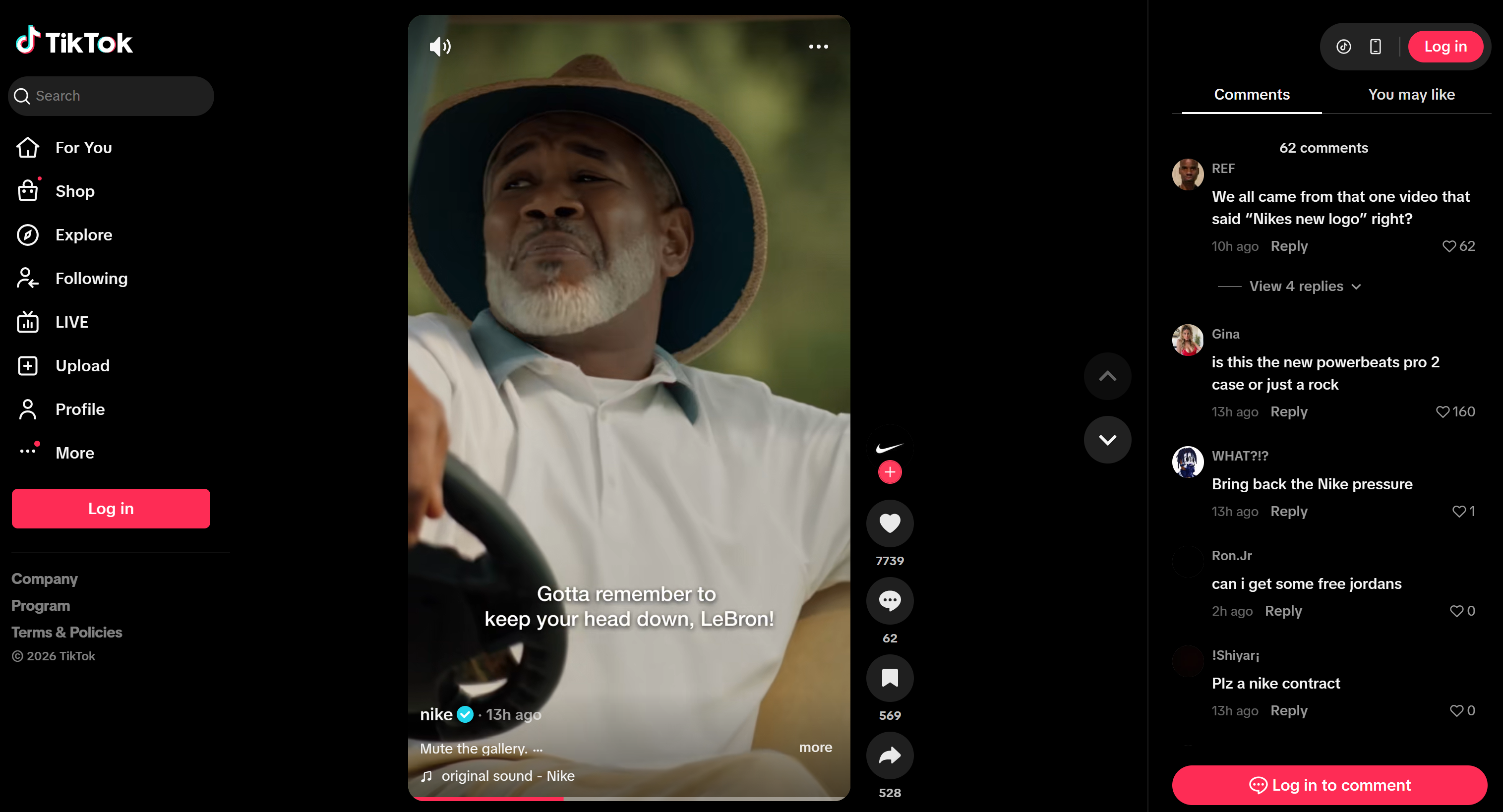
このアイデアは、AIエージェントにBrightDataのSocial MediaスクレイパーAPIを使用させ、両方の投稿からコメントを取得させるというものです。その後、Geminiを搭載したLLMブレインを通じてそのデータを分析・処理します。これで基本的なエージェント型ソーシャルリスニングのワークフローが完成します。
注:これはあくまで一例であり、対象となるソーシャル投稿が既に存在することを前提としています。本番環境では、Bright Dataのツールを使用してウェブ検索、ソーシャルメディアアカウント全体の追跡、および大規模なマルチプラットフォーム・ソーシャルリスニングを処理することができます。
準備完了! それではエージェントを開発しましょう。
ステップ #3: エージェントの実装
前述のソーシャルリスニングエージェントを構築するには、agent.pyに以下のコードを追加します:
# pip install langchain langchain-google-genai langchain-brightdata
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import create_agent
# 実際のAPIキーに置き換えてください
GOOGLE_API_KEY = "<YOUR_GOOGLE_API_KEY>"
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
# LLMエンジンを初期化
llm = ChatGoogleGenerativeAI(
model="gemini-3-flash-preview",
google_api_key=GOOGLE_API_KEY
)
# Bright Data ウェブスクレイピング API ツールを初期化
web_scraper_api_tool = BrightDataWebScraperAPI(
bright_data_api_key=BRIGHT_DATA_API_KEY
)
# Bright Data ウェブスクレイピング API にアクセスできる ReAct エージェントを作成
agent = create_agent(llm, [web_scraper_api_tool])
# シンプルなソーシャルリスニングクエリを定義
prompt = """
あなたはソーシャルリスニングの専門家です。
対象:
- Instagram Reel: "https://www.instagram.com/nike/reel/DV_PTxKDueO/"
- TikTok動画: "https://www.tiktok.com/@nike/video/7618336096694406414"
タスク:
1. Bright DataのソーシャルメディアスクレイパーAPIを使用して、対象投稿のすべてのコメントを収集してください。
2. エンゲージメントとセンチメントを要約したMarkdownレポートを生成してください。
3. 他のNike製品、プロモーション、または興味深いユーザーのリクエストについて言及しているコメントをハイライトし、追跡分析に活用する。
"""
# エージェントのステップごとの出力をストリーム処理
for step in agent.stream(
{
"messages": prompt
},
stream_mode="values",
):
step["messages"][-1].pretty_print()このコードの機能:
- GeminiおよびBright Data APIへのアクセス用認証情報を読み込みます(本番環境では、envsから読み取ります)。
- ソーシャルメディアデータを処理・分析するためのGemini搭載AIエンジンを作成します。
BrightDataWebScraperAPILangChainツール経由で、エージェントをBright DataのスクレイピングAPI(ソーシャルメディアスクレイパーAPIを含む)に接続します。create_agent()関数を使用して、Bright Dataのスクレイピングツールを動的に呼び出せるReActエージェントを定義します。- エージェントに対して、対象(InstagramおよびTikTokの投稿)とタスク(コメントの収集、感情分析、レポート生成、主要なメンションのフラグ付け)を指示します。
- エージェントを起動し、結果をターミナルにストリーミングします。
ミッション完了!これで、ソーシャルリスニングのためのシンプルなエージェント型ワークフローを実装しました。
ステップ #4: エージェントのテスト
次のコマンドでエージェントを実行します:
python agent.py(予想通り)エージェントがbright_data_web_scraperツールを実行しているのが確認できます: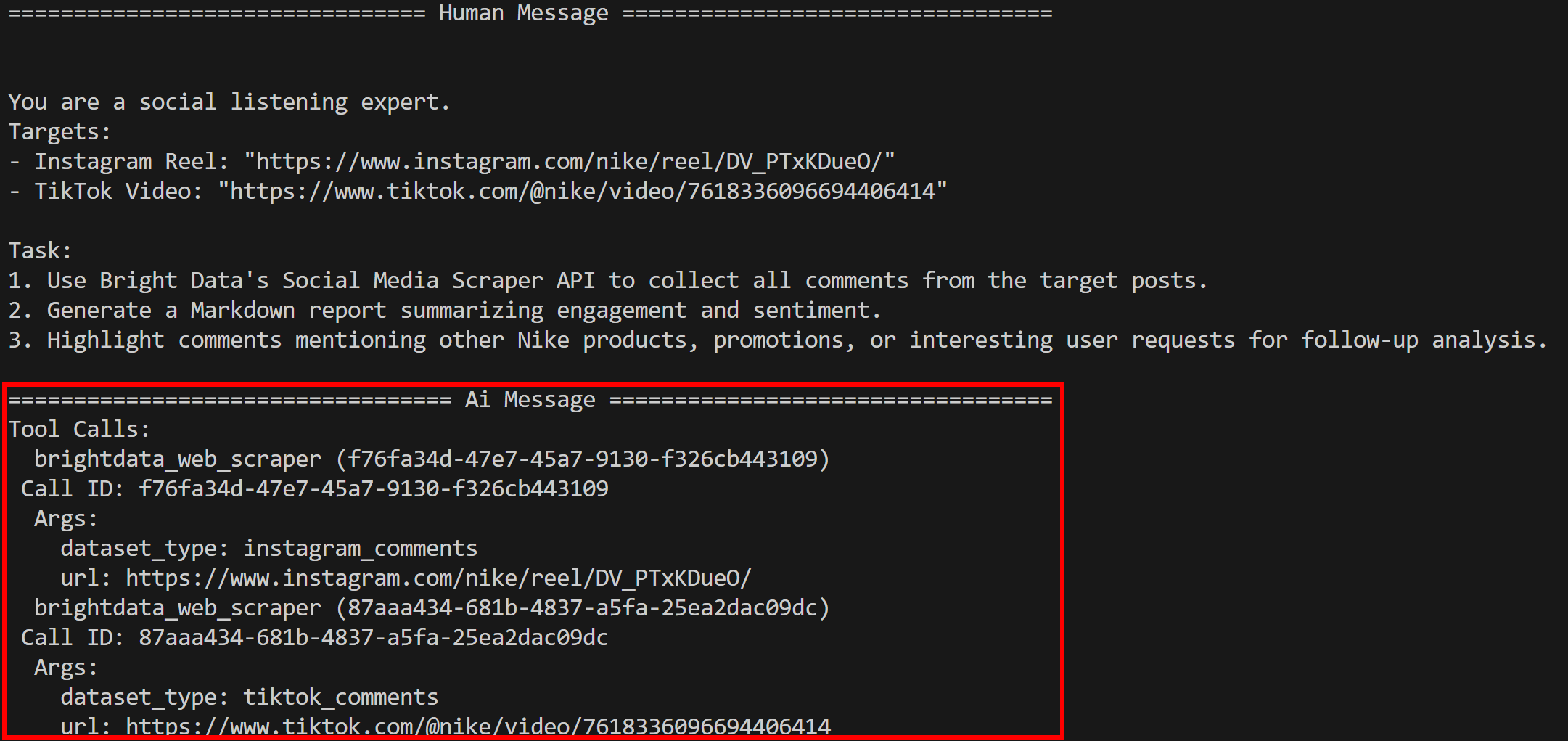
具体的には、基盤となるinstagram_commentsおよびtiktok_commentsツールを呼び出します。内部的には、これらは Bright Data のInstagram Comments スクレイパーおよび TikTok Comments スクレイパーに依存しています。
ツールの結果はJSON形式のデータとして返され、2つの投稿からスクレイピングされたすべてのコメントが含まれています: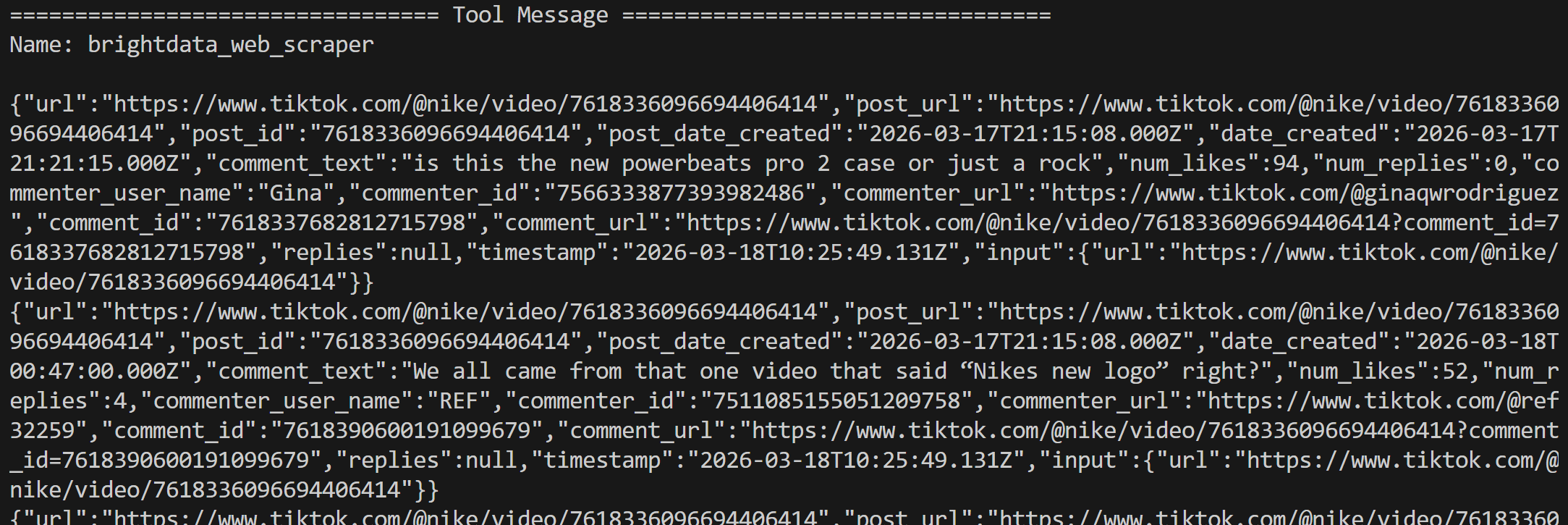
次に、エージェントは指示に従ってコメントをソーシャルリスニング用に処理し、Markdown形式のレポートを生成します: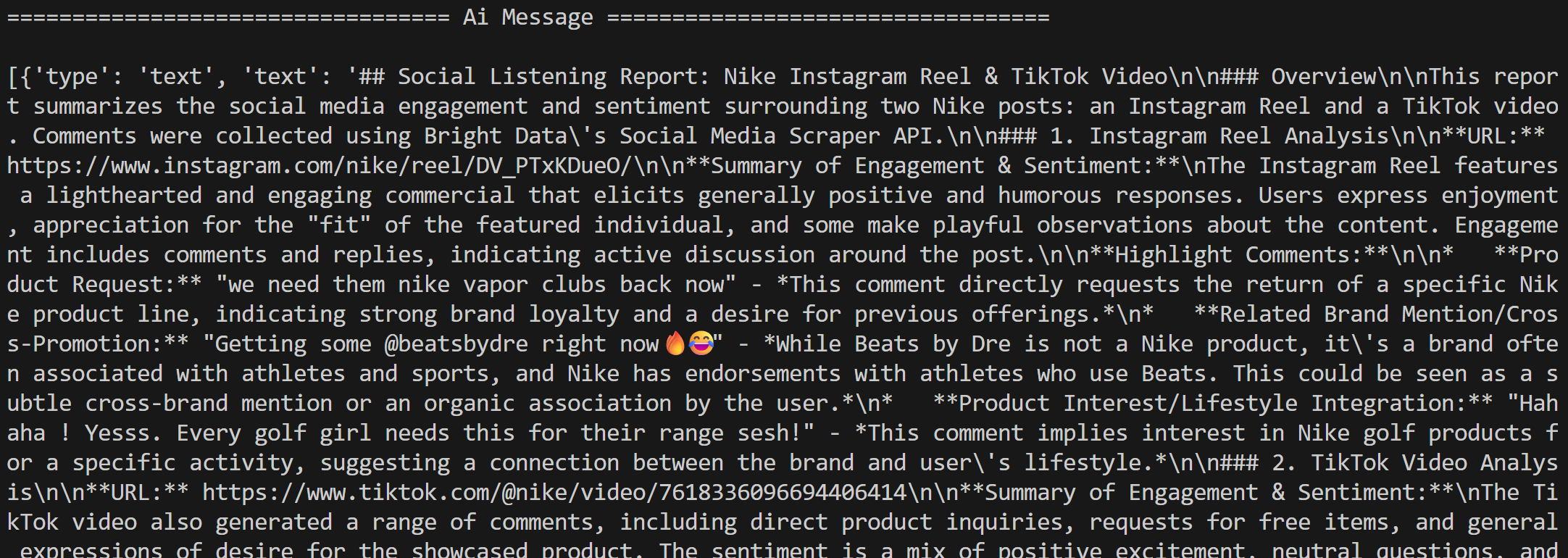
Markdownレンダラーで表示すると、レポートは次のようになります: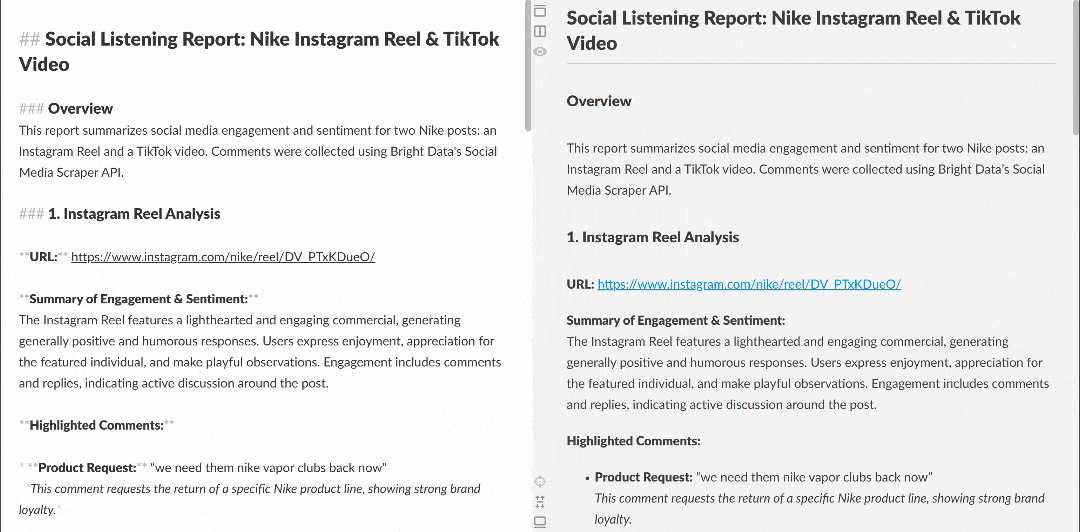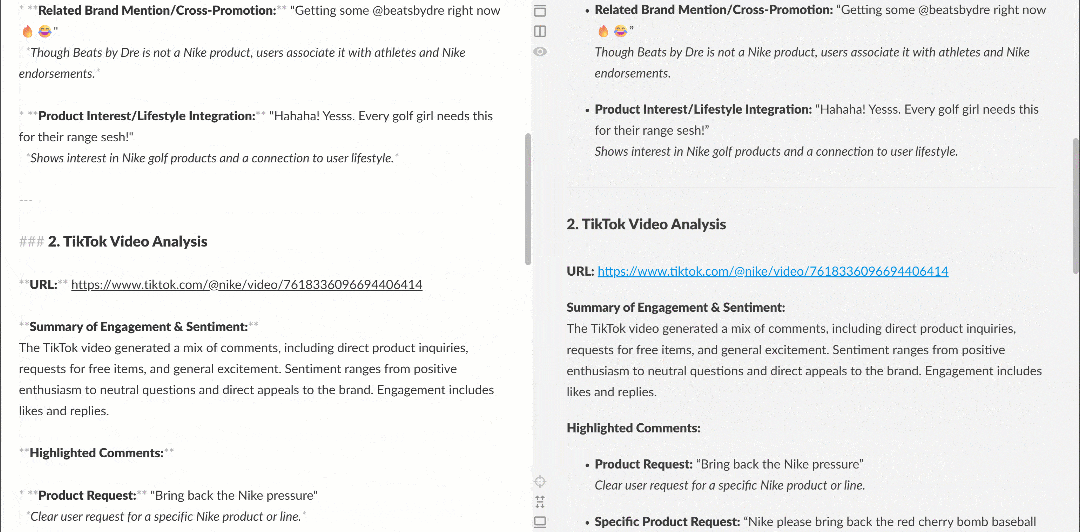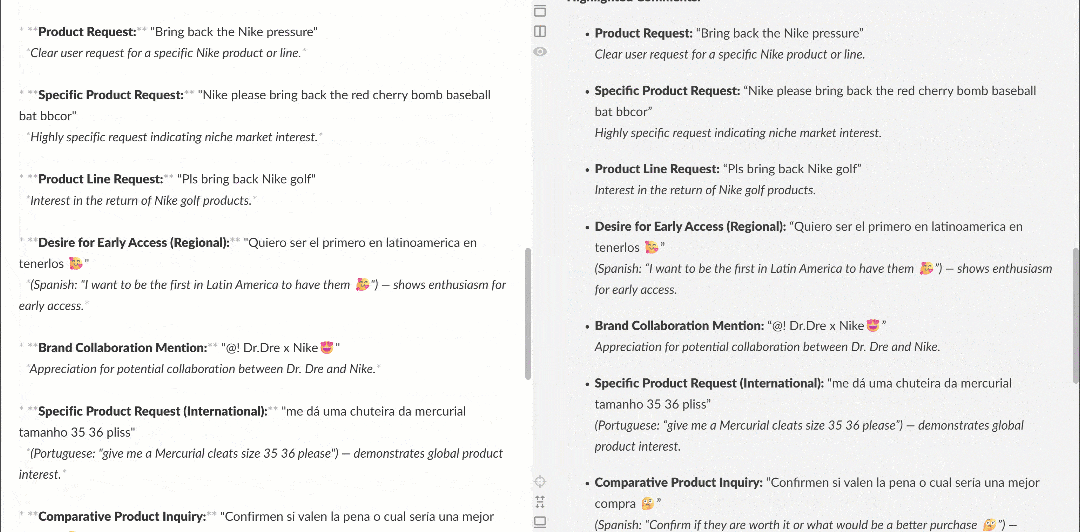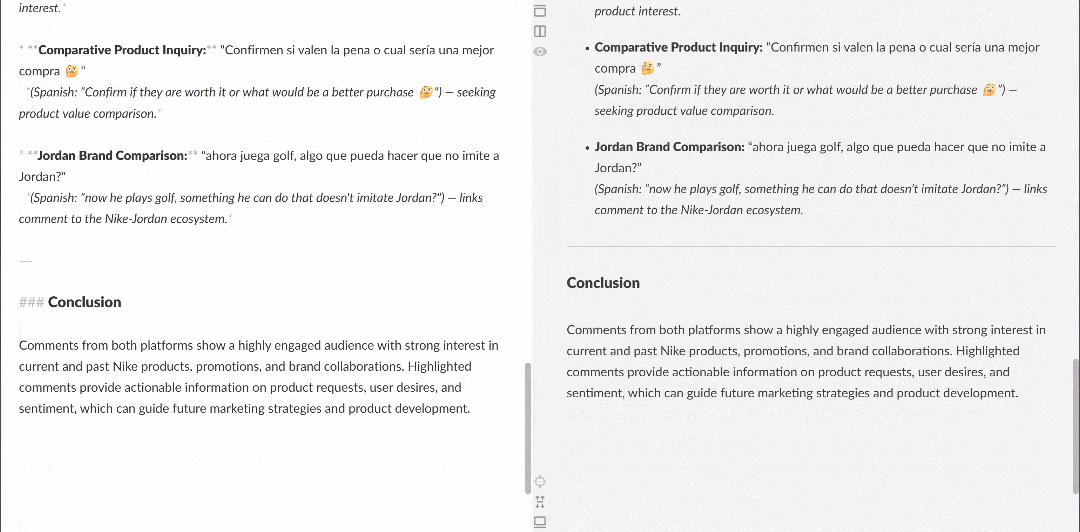
複数のユーザーが Nike に「Nike Golf を復活させてほしい」や「ゴルフ製品にもっと注力してほしい」と求めているなど、興味深いインサイトが含まれている点に注目してください。これらは、基本的なセンチメント分析ワークフローでは見逃されていたかもしれない詳細です。
また、エラーが発生した場合や、取得したデータが目標を達成するのに不十分であるとエージェントが判断した場合は、自動的に追加のコメントを取得するか、Bright Dataツールへの呼び出しを繰り返します。これにより、エージェントは完全に自律的に動作します。
これで完了です!LangChain上で、Bright Dataを活用したエージェント型ソーシャルメディア・リスニング・ワークフローを構築する方法を学びました。
ソーシャルリスニングのための本番環境対応エージェント型ワークフロー
前の章では、シンプルなソーシャルリスニングエージェントの構築方法を紹介しました。しかし、本番環境対応のエージェンティックワークフローは、はるかに複雑です。その設計方法と実装手順について見ていきましょう!
アーキテクチャ
エージェント型ソーシャルリスニングワークフローでは、単一のモノリシックなエージェントを使用するよりも、複数の特化型AIエージェントに依存する方が、より良い結果が得られる傾向があります。各エージェントは明確な役割に集中すべきであり、考えられるエージェント構成は以下の通りです:
- データ取得エージェント:Bright DataのSocial Mediaスクレイパーなどのツールを通じて、複数のソーシャルメディアプラットフォームから投稿、コメント、プロフィール、またはエンゲージメント指標を収集します。
- 分析エージェント:収集したデータを処理してトレンド、センチメント、その他の実用的なインサイトを抽出し、生のソーシャルコンテンツを意味のある知見へと変換します。
- レポート/出力エージェント:分析されたデータをダッシュボード、要約、またはファイル(JSON、CSV)形式に整え、人間や他のAIシステムが容易に利用できるようにします。
- 調整エージェント:ワークフローを監督し、スムーズな引き継ぎを確保するとともに、結果の品質を評価し、改善や追加のデータ収集が必要な場合にプロセスを自動的に反復させます。
ロードマップ
これら4つのエージェントを用いて、ソーシャルリスニングのためのエージェント型ワークフローを次のように実装します:
- AIエージェントスタックの選択:必要なエージェントの種類、ツールの統合、ワークフローのオーケストレーションの容易さを基に選定します。
- エージェントの追加:選択したAIエージェントフレームワーク内に、4つのプレースホルダーエージェントを作成します。
- ソーシャルメディアスクレイパーの統合:データ取得エージェントに、Bright DataのSocial Media Scraper、または特定の単一のソーシャルメディアスクレイパーへのアクセス権を付与します。
- データ取得タスクの設定:データ取得エージェントに対し、必要なソーシャルメディアデータを取得するよう指示します。
- 収集したデータの分析:分析エージェントに対し、テキスト、センチメント、トレンド、エンゲージメント指標の処理を指示します。
- 構造化されたレポートを生成する:レポート作成エージェントに対し、分析されたデータに基づいて所望の出力を生成するよう指示します。
- 調整と反復:調整エージェントを実装し、結果の監視や反復サイクルのトリガーなどを実行します。
- エージェントループの設計:4つのエージェント(データ取得 → 分析 → レポート作成 → 調整)を連携させます。
- ワークフローのスケジューリングを自動化する:継続的なソーシャルリスニングのために定期的な実行を設定する。
エージェント型ソーシャルリスニングワークフローの例
前述のAIエージェントのロードマップに基づき、いくつかのエージェント型ソーシャルメディア・リスニング・ワークフローを構築できます。以下にいくつかの例をご紹介します!
ブランドセンチメントのモニタリング
AIエージェントが、ソーシャルプラットフォーム全体で自社ブランドへの言及を継続的に追跡します。Bright Dataのソーシャルメディアスクレイパーを活用し、エージェントが投稿、コメント、リアクションを収集した後、センチメントを分析し、新たなトレンドを検知し、ネガティブな急増をフラグ付けすることで、先を見越した評判管理を可能にします。
競合分析
AIエージェントは、TikTok、X、Reddit、YouTubeのコメント欄において、ハッシュタグ、キーワード、および議論を監視します。AIはコンテンツ戦略、キャンペーンのパフォーマンス、オーディエンスのエンゲージメントパターンを検出し、自社の戦略をリアルタイムで調整するのに役立ちます。
トレンドの発見と予測
AIエージェントは、TikTok、X、Redditにおけるハッシュタグ、キーワード、およびディスカッションを監視します。Bright DataのスクレイパーAPIは、構造化されLLM対応のデータを提供し、エージェントが台頭するトレンドを検知し、人気を予測し、マーケティングや製品に関する意思決定を導くことを可能にします。
危機の検知と対応
エージェントは、複数のネットワークにおけるネガティブな感情の急激な高まりやバイラル投稿を監視します。Bright Dataのソーシャルメディアスクレイパーを活用することで、AIはチームに即座にアラートを送信したり、文脈に応じた返信案を作成したり、自動エスカレーションワークフローを起動したりすることが可能です。
キャンペーンのフィードバック分析
AIエージェントは、Facebook、Instagram、YouTube、その他のプラットフォームからユーザーの反応、コメント、投稿指標を収集します。Bright Dataのスクレイパーを活用することで、エージェントはキャンペーンの成果を追跡し、メッセージ戦略を最適化するために必要なデータを取得できます。
まとめ
この記事では、ソーシャルメディア・リスニングとは何か、その内容、そしてエージェント型ワークフローが実装に最適な理由について学びました。また、関連する課題と、AI対応のソーシャルメディアスクレイピングツールを活用してそれらを克服する方法についても明確に理解できたはずです。
Bright Dataは、専用かつエンタープライズレベルで、統合が容易なソーシャルメディアスクレイパーを通じてソーシャルリスニングをサポートしています。これにより、信頼性やパフォーマンスを損なうことなく、ソーシャルリスニング(およびその他のソーシャルメディアマーケティングのユースケース)向けにスケーラブルなエージェント型ワークフローを構築することが可能になります。
今すぐBright Dataのアカウントを無料で作成し、AI対応のWebデータ収集ソリューションをご確認ください!
よくある質問
ソーシャルリスニングとソーシャルモニタリングの違いは何ですか?
ソーシャルモニタリングは、通知、いいね、指標を収集することで「何が」起きたかを追跡します。一方、ソーシャルリスニングは、それらの会話の背後にある感情やトレンドを分析し、「なぜ」起きたのかを解明することで、長期的な戦略の指針とします。
センチメント分析とソーシャルリスニングの違いは何ですか?
センチメント分析は、テキストに含まれる感情や意見(ポジティブ、ネガティブ、ニュートラルなど)を評価するものです。一方、ソーシャルリスニングはより広範な概念であり、プラットフォームを横断して会話をモニタリングし、トレンド、ブランド認知、顧客フィードバックを追跡します。多くの場合、センチメント分析はそのツールの一つとして活用されます。
AIエージェントをソーシャルリスニングに活用できますか?
はい、AIエージェントはソーシャルリスニングに活用できます。実際、絶えず変化し続けるソーシャルメディアの環境において、AIエージェントは変化や予期せぬシナリオに適応する能力を備えているため、このタスクに最適です。
AIがソーシャルリスニングを行うには、どのようなツールが必要ですか?
ソーシャルリスニング用のAIエージェントには、ソーシャルメディアデータを収集するためのツールが必要です。BrightDataのSocial Media Scraperのようなスクレイパーと統合することで、エージェントは複数のプラットフォームを大規模に監視し、リアルタイムで実用的なインサイトを提供できます。
ソーシャルリスニングを適用するのに適したソーシャルメディアプラットフォームはどれですか?
エージェントによるソーシャルリスニングのためにスクレイピングを行うのに最も適したソーシャルメディアプラットフォームは、X、Reddit、Threads、Facebook、Instagram、LinkedIn、TikTok、Quora、Pinterest、YouTube、およびVimeoです。





