

Apollo.ioはB2Bプロスペクティングプラットフォームとして市場で最も広く利用されているサービスの一つです。2億7,500万件以上の連絡先、組み込みのメールシーケンス機能、そして100万人以上のユーザーが利用する無料プランを提供しています。少人数のSDRチームがメールのみのアウトバウンド活動を行う場合、検索・アウトリーチ・トラッキングを一つのインターフェースに統合できます。
Bright Dataは異なるアプローチを採用しています。静的な連絡先データベースを維持する代わりに、LinkedIn、Crunchbase、ZoomInfo、6sense、PitchBookなど10以上のプレミアムソースからオンデマンドでB2Bデータを収集するAPI アクセスを提供します。すべてのレコードはリクエスト時にスクレイピングされます。
両プラットフォームをデータ品質、鮮度、API機能、カバレッジ、価格の観点から比較しました。以下にその結果をまとめます。
Quick Comparison
| 機能 | Bright Data | Apollo.io |
|---|---|---|
| データアーキテクチャ | リアルタイムスクレイピング+事前集約されたマルチソースデータセット | 定期更新を行う独自の静的データベース |
| データソース | 10以上(LinkedIn、Crunchbase、ZoomInfo、6sense、PitchBookなど) | コントリビューターネットワーク+公開クローリング+サードパーティベンダー |
| 総レコード数 | Company Data APIデータセット全体で5億社以上のプロフィール、LinkedInスクレイピングはオンデマンド対応 | 2億7,500万件以上の連絡先、3,500万社以上の企業 |
| データの鮮度 | リアルタイム(リクエスト時に収集) | 定期的な更新サイクル(レコードの優先度によって異なる) |
| APIアクセス | 全アカウントで完全なREST APIを提供 | 有料プラン(Basic以上)でAPIデータエンリッチメントが利用可能。テストでは無料プランの検索・エンリッチメントエンドポイントで403エラーが発生 |
| データ配信 | API、S3、Snowflake、Azure、Webhook経由でJSON、CSV、Parquet形式に対応 | CSV/JSONエクスポート、対応エンドポイントでのAPIレスポンス |
| 価格モデル | レコード単位の従量課金制(PAYG:1,000件あたり$1.5)またはScaleプラン(月額$499で38万4,000件含む) | ユーザーシート単位+クレジットシステム(0〜$119/ユーザー/月) |
| アウトリーチツール | なし(データインフラのみ) | メールシーケンス、ダイヤラー、ミーティングスケジューラー、CRM |
| 最適な用途 | データチーム、AIパイプライン、大規模なエンリッチメント、マルチソースインテリジェンス | 自己完結型のアウトバウンドキャンペーンを運営する中小企業のSDRチーム |
The Freshness Problem with Static B2B Databases
B2Bの連絡先データは年間約22〜30%の割合で陳腐化します。転職、企業のリブランディング、電話番号の変更などが原因です。米国労働統計局によると、2024年と2025年の離職率はいずれも3.3%で、転職だけで毎年連絡先データベースのかなりの部分が時代遅れになることを意味します。
Apolloは3つのチャネルでデータベースを維持しています。メールやカレンダーデータを同期する200万人以上のコントリビューターネットワーク、公開ウェブクローリング、そしてサードパーティデータベンダーです。このシステムは更新サイクルで月間約2億7,000万件のレコードを処理しています。「処理済み」は「レコードごとに検証済み」を意味するわけではなく、アクセス頻度の高い連絡先はより頻繁に更新される一方、アクセスの少ないレコードは数ヶ月間更新されないことがあります。
この問題は公開レビューに一貫して表れています。
- G2およびCapterraのレビュアーは、データ精度が全体的に65〜70%前後と報告しており、Apolloの公表値を下回っています
- Apolloからエクスポートされたリストのメールバウンス率は、地域や業界によって15〜35%に達することが独立したテストで定期的に確認されています
- 6〜12ヶ月前に転職した連絡先の役職や会社情報が古いままになっていることが多い
- 米国拠点のテック・SaaS系連絡先は最も精度が高く80〜88%ですが、海外データは60〜73%まで低下します
- 電話番号は1件につき8クレジットを消費し、メールよりも精度が低く、レビュープラットフォーム全体で最も多く指摘される問題です
r/coldemailで共有されたある詳細なテストでは、「検証済み」とラベル付けされた連絡先であっても、Apolloからエクスポートした500〜1,000件のリードで32〜38%のバウンス率が示されました。
Apolloの「People Search」は65以上のフィルター属性を持つ2億7,500万件以上の連絡先を検索できるデータベースです。
Bright Dataはこの更新問題を根本から解消します。LinkedIn Profiles Scraper APIを呼び出すと、リクエスト時点でLinkedInのライブページからデータが収集されます。キャッシュレイヤーも更新サイクルも存在しません。見込み客が今朝LinkedInのプロフィールを更新した場合、APIは今日の午後にはその更新版を返します。
これを直接テストしました。Profiles APIを通じてSatya NadellaのLinkedInプロフィールをスクレイピングしたところ、7.2秒でレスポンスが返され、収集タイムスタンプは2026-05-27T10:22:15.544Zでした。これはデータがキャッシュからではなく、ライブで取得されたことを確認するものです。
Bright Data’s B2B Data Stack: Hands-On Walkthrough
The Dataset Filter API: Large-Scale Company Search
Filter APIはApolloの企業検索に最も近い機能です。構造化フィルターを定義して、事前集約された企業データセットを照会します。Bright DataのCompany Data APIは、集約されたすべてのソース(LinkedIn、Crunchbase、ZoomInfo、6sense、PitchBookなど)全体で5億社以上の企業レコードを提供しています。結果は数分以内に返され、最終出力のレコード分のみ料金が発生します。
従業員数51〜200人の米国内ソフトウェア企業を検索するために使用したAPIコールは以下のとおりです。
import requests
import time
# Step 1: Trigger a filtered snapshot
# Field names vary by dataset; use API Request Builder for your selected dataset.
response = requests.post(
"https://api.brightdata.com/datasets/filter",
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json={
"dataset_id": "gd_l1vikfnt1wgvvqz95w",
"filter": {
"operator": "and",
"filters": [
{"name": "industries", "operator": "includes",
"value": "Software Development"},
{"name": "country_code", "operator": "=", "value": "US"},
{"name": "company_size", "operator": "=",
"value": "51-200 employees"}
]
},
"records_limit": 100
}
)
snapshot_id = response.json().get("snapshot_id")
# Step 2: Poll until ready, then download
download_url = (
f"https://api.brightdata.com/datasets/snapshots"
f"/{snapshot_id}/download?format=json"
)
# Poll download_url until HTTP 200, then parse the JSON response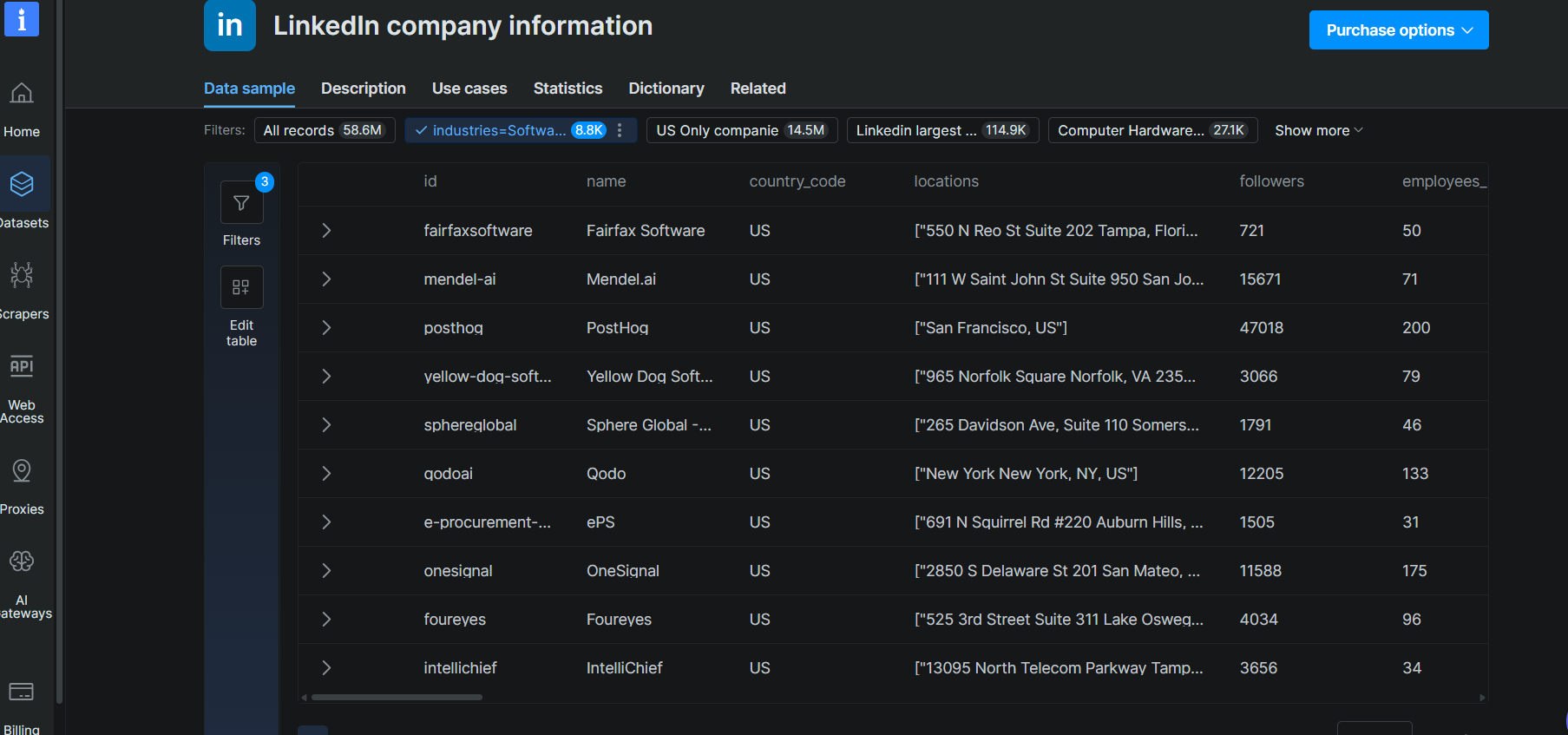
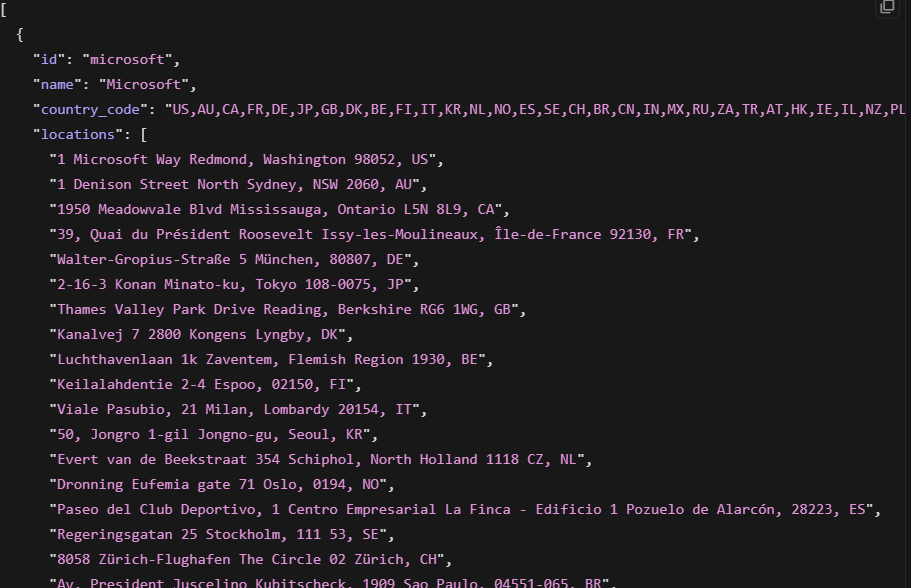
レスポンスは46.5秒で100件のマッチング企業を返しました。各レコードには企業名、ドメイン、業界分類、従業員数、本社所在地、設立年、LinkedIn URL、Crunchbase URLが含まれていました。基礎となるソースから利用可能な場合は、資金調達フィールドも含まれます。
サンプルレコード(Leanpath):
{
"about": "Leanpath, a Certified B-Corp, is on a mission to make food waste prevention and measurement everyday practice in the world's kitchens...",
"company_id": "400488",
"company_size": "51-200 employees",
"country_code": "US",
"crunchbase_url": "https://www.crunchbase.com/organization/leanpath-inc",
"employees_in_linkedin": 78,
"followers": 6199,
"founded": 2004,
"funding": {
"last_round_date": "2025-03-04T00:00:00.000Z",
"last_round_raised": "US$ 750.0K",
"last_round_type": "Debt financing",
"rounds": 3
}
}ここでマルチソースアーキテクチャの強みが発揮されます。企業のLinkedInデータには従業員数と業界が表示されます。Crunchbaseは資金調達ラウンド、投資家、バリュエーションデータを追加します。ZoomInfoはテクノグラフィクスと売上推定値を提供します。Filter APIはこれらをプロバイダー間でクロス検証した単一のレコードに統合します。Apolloの企業検索は一つの独自データベースを照会するのみです。
LinkedIn Profiles Scraper API: Live Contact Data in 7 Seconds
連絡先レベルのデータについては、Bright DataのLinkedIn Profiles Scraper APIをテストしました。このAPIはLinkedInプロフィールURLを受け取り、ライブページをスクレイピング(CAPTCHA、ログインウォール、JSレンダリングを処理)して、構造化されたJSONを返します。
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={
"dataset_id": "gd_l1viktl72bvl7bjuj0",
"format": "json"
},
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json=[{"url": "https://www.linkedin.com/in/fimber-elemuwa/"}]
)
profile = response.json()今回はFimber Elemuwaのプロフィールをテスト対象としてスクレイピングしました。レスポンスは7.2秒で返され、名前、現在の役職、現在の会社、所在地、完全な職歴、学歴、スキル、エンゲージメントデータが含まれていました。タイムスタンプフィールドは2026-05-27T10:22:15.544Zを示しており、データがライブで収集されたことを確認しています。
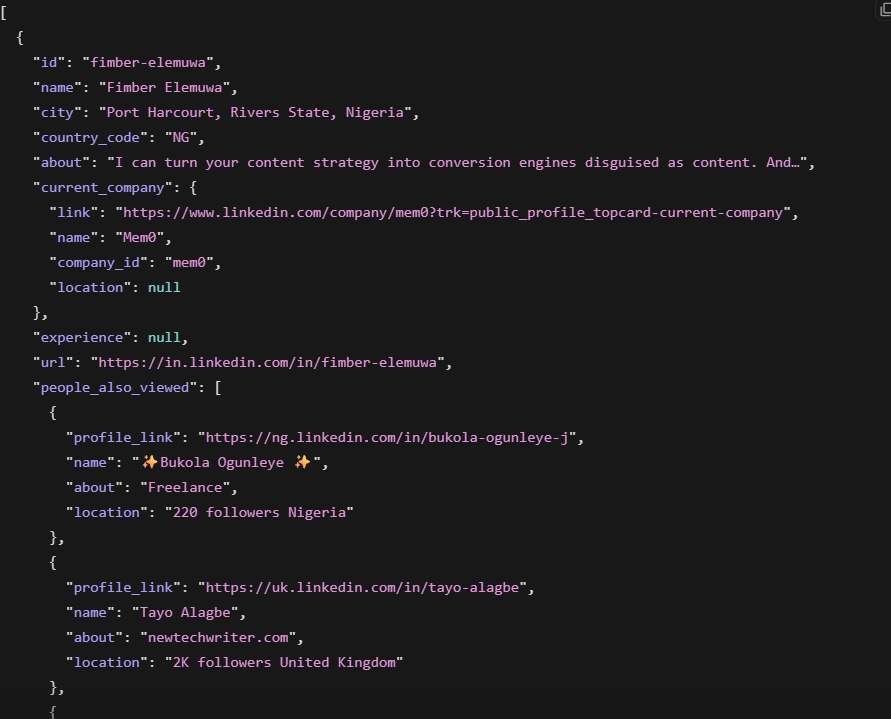
Apolloは独自のスケジュールで更新されたこのプロフィールのスナップショットを保存しています。Bright DataはリクエストのタイミングでLinkedInからデータを収集します。著名なCEOであれば両ソースの情報は一致するでしょう。しかし差が出るのは、Apolloの更新サイクルが低頻度で古いデータが生じやすい、中小企業の中間管理職レベルの連絡先です。
LinkedIn Companies Scraper API: Firmographic Data on Demand
MicrosoftのLinkedIn企業ページを取得することで、Companies Scraper APIもテストしました。
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={
"dataset_id": "gd_l1vikfnt1wgvvqz95w",
"format": "json"
},
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json=[{"url": "https://www.linkedin.com/company/microsoft/"}]
)
company = response.json()レスポンスは12.3秒で返され、企業名、従業員数(LinkedIn上で231,622人)、本社所在地、業界、Crunchbase URL、最近の企業投稿が含まれていました。今回のケースでは資金調達フィールドも存在しましたが、利用可能かどうかは企業によって異なります。
より詳細なファーモグラフィックデータ(金額と投資家を含む完全な資金調達ラウンド履歴、売上推定値、テクノグラフィックプロフィール)については、Company Data APIのマルチソース集約レイヤーがLinkedInのみのスクレイピングよりも完全な情報を提供します。企業スクレイパーは迅速な単一ソースの検索に適しており、Filter APIは大規模なエンリッチ済みマルチソースレコードに適しています。
The Full Scraper API Suite
テストした2つのAPIに加え、Bright DataのLinkedInスクレイパースイートには以下も含まれています。
| API | 入力 | 主な出力 |
|---|---|---|
| Jobs API | LinkedIn求人URL | 役職名、企業、所在地、給与、説明、要件、投稿日 |
| Posts API | LinkedIn投稿URL | 著者、コンテンツ、エンゲージメント指標、日付、メディア |
これらは採用シグナルの検出(どの企業がどのチームを拡大しているか)や競合情報の収集(企業が何について投稿しているかの追跡)に役立ちます。URLを送信するだけで、ライブスクレイピングから構造化されたJSONを受け取れます。
Building Automated Lead Gen Pipelines
これらのAPIの真の力は、自動化されたワークフローに組み合わせたときに発揮されます。Bright DataはStreamlit上に構築されたオープンソースのAIリードジェネレーターを公開しており、以下の機能を備えています。
- 自然言語クエリを受け付ける(「ケニアのフィンテック企業のマーケティングマネージャーを探す」など)
- OpenAIを使用してクエリから構造化フィルターを抽出する
- Bright DataのAPIを呼び出してLinkedInからマッチするリードを収集する
- AIで各リードをスコアリングしてエンリッチする
- 各リードへのアウトリーチ提案を返す
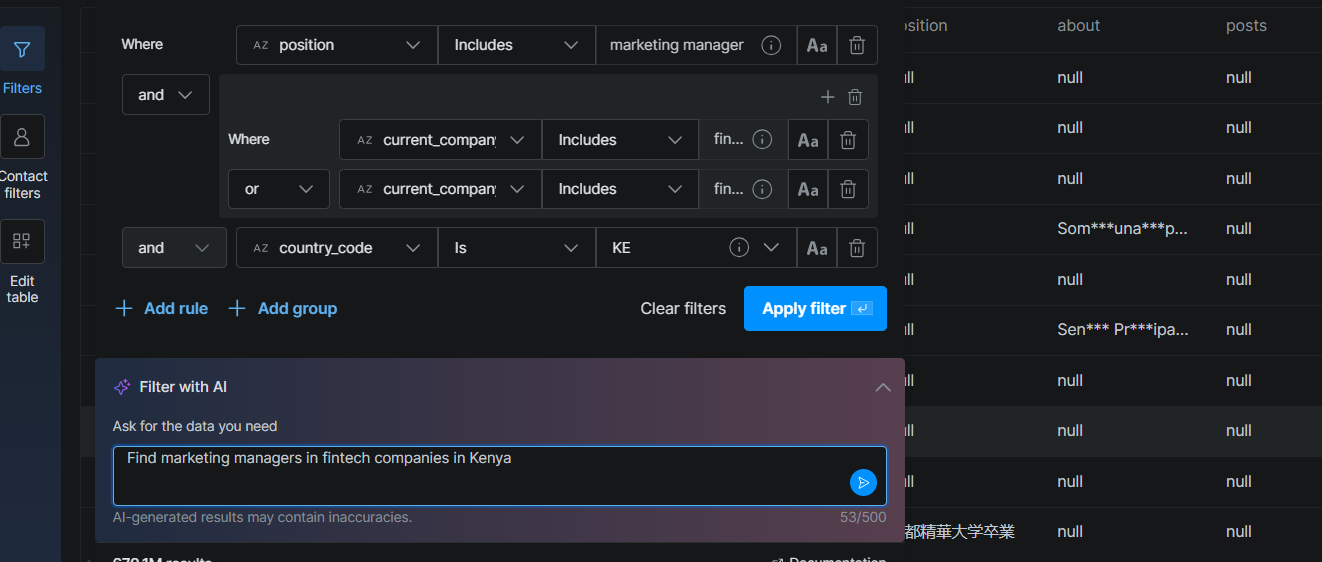
ApolloにもAI機能(メール作成、リードスコアリング提案)がありますが、それらはApolloのインターフェース内で動作するものであり、カスタムパイプライン向けの組み合わせ可能なビルディングブロックではありません。LangChain、LlamaIndex、CrewAIを使ったエージェントベースのワークフローを構築するチームには、Bright DataのAPIがデータ取得ツールとして直接統合できます。
Pricing: What You Actually Pay
Apollo
Apolloは統一されたクレジットシステムを採用しています。有料プランでは年間分のクレジットが前払いで付与され、無料プランでは月次で付与されます。料金ページには以下の内容が記載されています。
| プラン | 年間請求 | クレジット | 付与スケジュール |
|---|---|---|---|
| 無料 | $0 | 900件/年 | 月次(75件/月) |
| Basic | $49/シート/月 | 30,000件/年 | 前払い |
| Professional | $79/シート/月 | 48,000件/年 | 前払い |
| Organization | $119/シート/月(最低3シート) | 72,000件/年 | 前払い |
3つの有料プランすべてにCSV、CRM、APIデータエンリッチメントが含まれます。無料プランには含まれません。テストでは、無料プランアカウントで人物検索・エンリッチメントのAPIエンドポイント(mixed_people/api_search、people/match、people/bulk_match)がすべて403エラーを返しました。これは無料プランに「APIデータエンリッチメント」が含まれていないことと一致しています。
クレジットはアクション単位で消費されます。メールの開示に1クレジット、携帯電話番号の開示にはより多く(アカウント設定によって8クレジットと報告されています)、APIを通じたエンリッチメントはリクエストするフィールドによって異なります。クレジットは年間契約期間を超えて繰り越すことはできません。活発なアウトバウンドチームは、エンリッチメントや電話番号の開示が増えると、ベースプランの費用を超えてクレジットの追加購入が定期的に必要になります。
プラン別の主な機能:BasicはCRM統合、高度なフィルター、ウォーターフォールエンリッチメント、米国ダイヤラーを追加。ProfessionalはシーケンスのA/Zテスト、自動化ワークフロー、通話録音(4,000分)、アナリティクスを追加。OrganizationはカスタマイズレポートSSO、高度なセキュリティ、独自のLLM APIキーの使用オプションを追加します。
Bright Data
| 製品 | 価格 |
|---|---|
| LinkedIn Scraper APIs(PAYG) | 1,000件あたり$1.5(成功分のみ課金) |
| LinkedIn Scraper APIs(Scale) | 月額$499(38万4,000件含む、追加分は1,000件あたり$1.3) |
| Company Data API(Filter) | 1,000件あたり$2.50〜 |
| Pre-built Datasets | 10万件あたり$250〜 |
| 無料トライアル | 1,000リクエスト(1回限り)、1週間有効、クレジットカード不要 |
シート単位の料金なし。クレジットシステムなし。プランによる機能制限なし。無料トライアルを含む全アカウントで完全なAPIアクセスが可能です。S3、Snowflake、Azure、Google Cloud、Webhookへのデータ配信も含まれています。
Cost Comparison for a Real Workflow
月間1万件のLinkedIn企業プロフィールを取得する場合:
Bright Data:PAYGプランで10,000件、1,000件あたり$1.5 = 月額$15。アカウントレベルのターゲティングにFilter APIを追加すると、1,000件あたり$2.50 = 1万件のフィルタリングで$25。合計:約$40/月。大量利用(月間10万件以上)の場合、38万4,000件を含む月額$499のScaleプランにより、実質レートが1,000件あたり$1.3に下がります。
Apollo:APIアクセスが可能な最安プランはBasicで月額$49/シート(年間$588)、年間30,000クレジットが前払いで付与されます。1クレジットでメール開示1件とすると、30,000クレジットでメールのみのエクスポートが30,000件分カバーされますが、8クレジットの電話番号はプールを大幅に早く消費します。Basicプランの3人チームでは、シート費用だけで年間$1,764かかり、年間を通じて合計90,000クレジットを共有することになります。
月間10万件のレコードになると差はさらに広がります。Bright DataのPAYGレートでは月額$150、またはScaleプランの月額$499で38万4,000件をカバーできます。
上記のApollo料金は2026年5月時点のApolloの料金ページから直接引用しています。アクション単位のクレジットコスト(メール開示、電話番号開示、エンリッチメント)は料金ページに記載されておらず、異なる場合があります。Bright Dataの料金は現在の公開レートを反映しています。
When to Use Which
Apolloを使用すべき場合は、検索・シーケンス・トラッキングを一つのプラットフォームにまとめたい小規模なSDRチーム(1〜5名)の場合です。ICPが米国拠点のテック/SaaS企業に集中しており(Apolloのデータが最も強い分野)、月間プロスペクティング量がプランのクレジット上限内に収まる場合に適しています。
Bright Dataを使用すべき場合は、大規模な新鮮なデータが必要な場合(月間1万件以上)、ICPが海外市場や静的データベースに既知のギャップがある小規模企業を含む場合、自動化されたエンリッチメントやAI駆動のリードジェネレーションパイプラインを構築している場合、または用途が営業アウトリーチを超えて競合情報、投資調査、市場マッピングまで及ぶ場合です。
両方を組み合わせることで最強のスタックが実現します。データ品質と実行効率の両方を求めるグロースチームに推奨されるアプローチです。
- Bright DataのCompany Data APIを使用して、10以上のソースからファーモグラフィクス、資金調達ステージ、テクノグラフィクス、成長シグナルでフィルタリングした適格なアカウントリストを構築する
- Bright DataのLinkedIn Profiles Scraper APIを使用して、ターゲットアカウントの意思決定者の最新の連絡先データを取得する
- 送信前に検証ツール(NeverBounce、ZeroBounce、またはProspeo)でメールアドレスを検証する
- Apollo(または任意のシーケンスツール)で検証済み連絡先を読み込み、アウトリーチキャンペーンを実施する
この構成では各プラットフォームの強みを最大限に活かしています。Bright Dataがデータレイヤーを担い、検証ツールがメール精度を確保し、Apolloが実行レイヤーを担当します。
!bright-data-apollo-combined-stack
Final Thoughts
Apolloは、手頃な価格で自己完結型のワークフローを求める中小企業の営業チームにとって有能なアウトバウンドプラットフォームです。無料プラン、組み込みのシーケンス機能、短いセットアップ時間により、ゼロから最初のキャンペーンまでの最速の道を提供します。
限界はデータの鮮度です。公開レビューでは全体的な精度が65〜70%、エクスポートされたリストのバウンス率が15〜35%と一貫して報告されています。数ヶ月前に転職した連絡先の役職情報が古いままになっていることも多くあります。小規模かつ米国中心のメールアウトリーチであれば許容範囲かもしれません。しかし大規模になると、古いデータの累積コストは無視できなくなります。クレジットの無駄遣い、送信者レピュテーションの低下、転職済みの見込み客からの機会損失などが生じます。
Bright DataのDataset Filter APIとLinkedIn Scraper APIsは、リクエスト時にソースからデータを取得し、集約された企業データ製品全体をカバーし、チームの成長を妨げないレコード単位の価格設定を採用しています。LinkedInのライブプロフィールを7.2秒、企業ページを12.3秒で取得し、LinkedIn企業データセットから100社を1分以内にフィルタリングしました。
アウトバウンドの成果がデータ品質によって制限されている場合、または基本的なメールプロスペクティングを超えたB2Bデータが必要な場合、Bright Dataはユースケースの要件に合わせてまさに必要なものを構築するためのインフラを提供します。





