















「ソーシャルリスニングの成功は、データ収集に適切なツールを使用することにあります。正確で信頼性の高いデータがなければ、洞察は欠陥を抱え、意思決定は的外れになります。質の高いデータから始めれば、後は自然とついてきます。」 – Vadim Savin, 創業者 @notJust.dev
こんにちは!私はVadimです。AIを活用したソーシャルリスニングアプリケーションの 構築方法を共有できることを嬉しく思います。 このプロジェクトは、Bright Dataツールと最先端のAI技術を用いて 、ブランド監視、市場情報の収集、競合他社に対する優位性の維持を支援することを目的としています。
本題に入る前に、簡単な背景を説明させてください。数ヶ月前、私はインターネット上で自社ブランドを監視するツールを探していました。Googleやソーシャルメディアといった特定プラットフォーム向けの専門ツールは数多く存在しますが、ウェブ全体における自社ブランドの健全性を包括的に把握できるツール は見つかりませんでした。 自社製品が言及された時、苦情が寄せられた時、競合が新たな動きを見せた時を把握したかったのです。理想のツールが見つからなかったため、自ら開発することに決めました。
本日は、データ収集からAIを活用したインサイト生成、自動化に至るまでの全プロセスを解説します。開発者、経営者、あるいはソーシャルリスニングに興味がある方なら、このガイドで自身のプロジェクトにこれらの機能を実装するための実践的な手順が得られます。さあ始めましょう!
ソーシャルリスニングが重要な理由
まず簡単な質問から始めましょう:自社ブランドについてオンラインで何が言われているか、どれくらいの頻度で確認していますか? 「あまり頻繁ではない」という答えなら 、顧客や競合他社からの貴重なインサイトを見逃している可能性があります。
ソーシャルリスニングとは、オンライン上の会話を監視し、顧客の感情 や新たなトレンド、 さらにはエスカレートする前の潜在的なPR危機 を理解することです。競合他社の活動や戦略を分析し、彼らに先んじる強力な手段でもあります。しかし課題は、情報がソーシャル メディア、フォーラム、ブログ、検索エンジンなどに分散しているという分散型の性質にあります 。
そこでBright Data のようなツール や大規模言語モデル(LLM)が活躍します 。これらの技術を組み合わせることで、ウェブ全体からデータを収集・処理し、実用的なインサイトを抽出することが可能になります。すべてを一元的に管理できるのです。
ソーシャルリスニングアプリケーションのアーキテクチャ
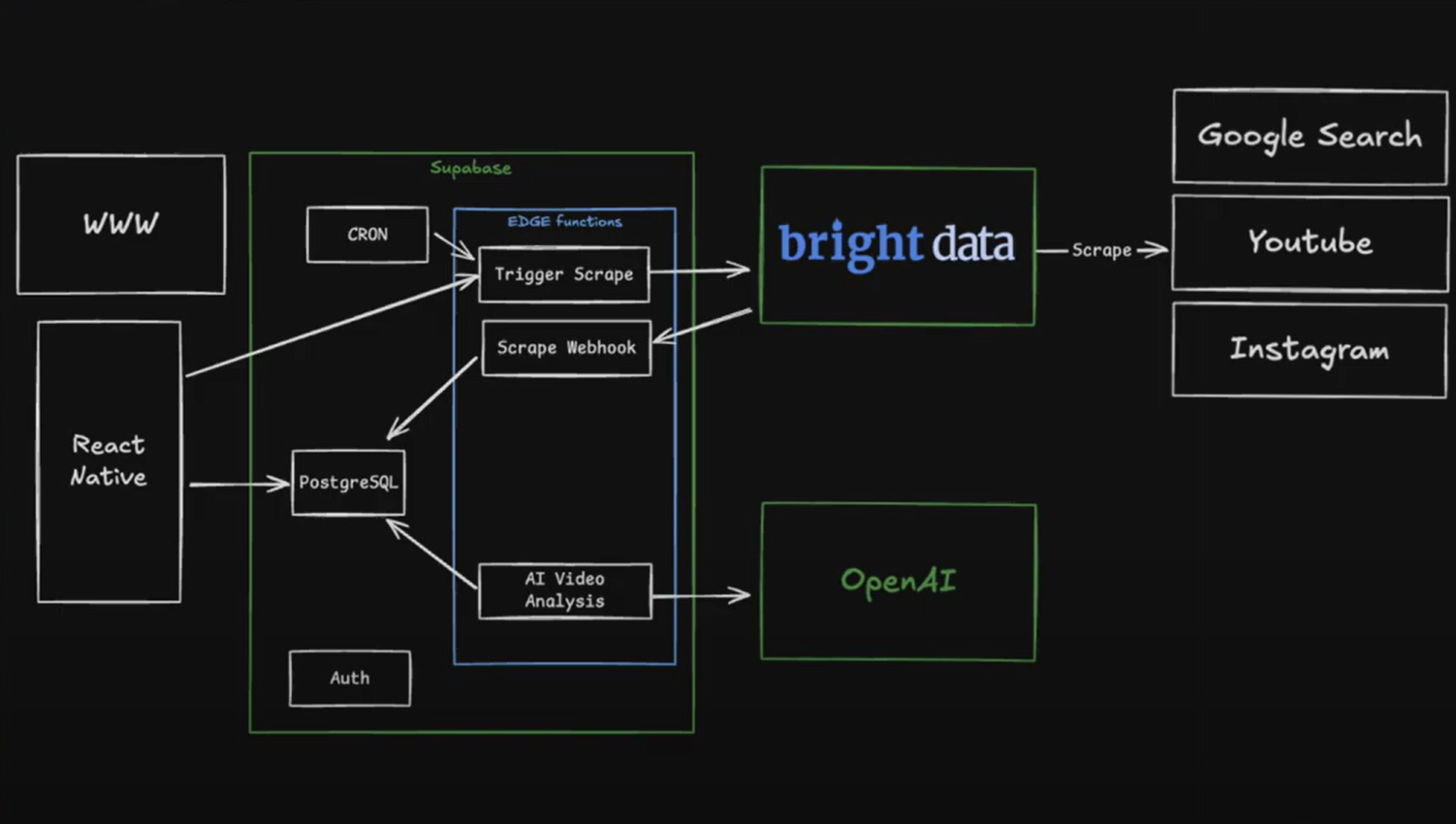
構築するシステムの概要は以下の通りです:
- データ収集 : Bright DataのAPIを活用し、検索エンジン、ソーシャルメディアプラットフォーム、その他のソースからデータをスクレイピングします。
- データストレージ: 構造化されたデータをデータベースに保存し、容易なアクセスと分析を実現。
- AIによるインサイト抽出: OpenAIの大型言語モデルを活用し、感情分析、トレンドトピック、顧客の課題点などの主要なインサイトを抽出。
- 自動化: データを自動で継続的に監視・更新するシステムを構築します。
これを段階的に分解してみましょう。
ステップ1:Bright Data APIによるデータ収集
検索エンジンの結果をスクレイピング
Googleなどの検索エンジンにおける自社ブランドのパフォーマンスを監視するため、BrightDataのSERP API を活用します。 このツールにより、検索結果のスクレイピングや、順位、リンク、説明文などのデータ抽出が容易になります。
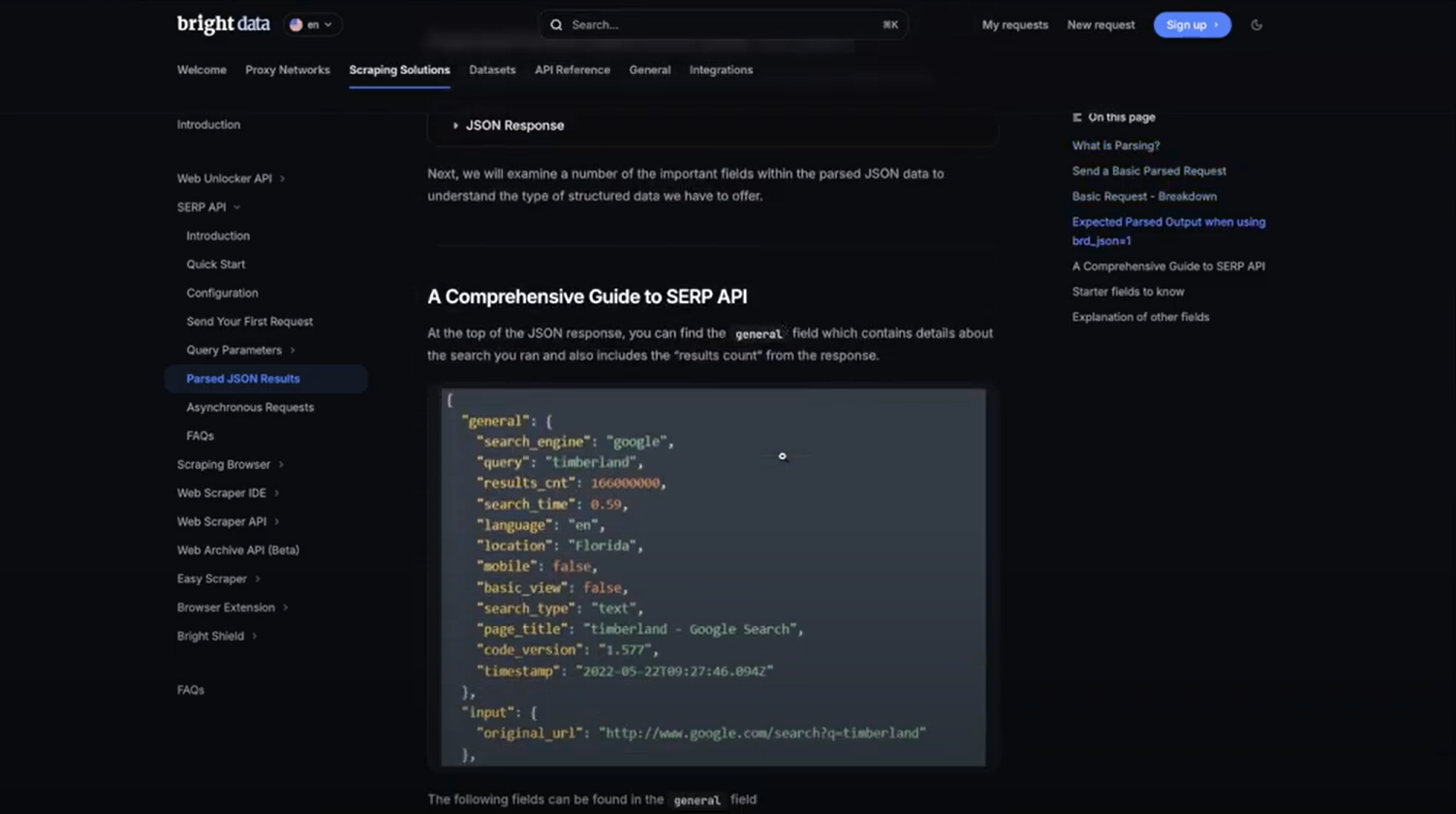
仕組みは以下の通りです:
- BrightDataで CAPTCHAの解決機能を有効にしたゾーン を設定し、スクレイピング対策に対処します。
- SERP APIを使用して特定のクエリ(例:自社ブランド名)に対するリクエストを送信します。
- JSONレスポンスをパースし、必要なデータ(オーガニックリンク、タイトル、説明文など)を抽出します。
収集したデータは、高速アクセスと将来の分析のために、PostgreSQL( Supabaseで ホスト) などのデータベースに保存します。
ソーシャルメディアデータのスクレイピング
ソーシャルメディアプラットフォームは、ブランド言及や顧客フィードバックの宝庫です。Bright DataのWeb Scraper APIは 、YouTube、Instagram、LinkedIn、Redditなどのプラットフォーム向けに事前構築されたスクレイパーを提供します 。
例:YouTubeチャンネルデータのスクレイピング
- YouTube Profilesスクレイパー を使用して、登録者数、動画リンク、説明などの情報を抽出します。
- ジョブ完了時にスクレイピングデータを自動受信するWebhook を設定します。
- データをデータベースに保存し、さらに処理します。
最大の利点は?Bright Dataのスクレイパーは定期的にメンテナンス・更新されるため、ウェブサイトの変更でコードが壊れる心配がありません。
ステップ2:AIによるデータ分析
データを収集したら、次のステップはAIを使用して実用的なインサイトを 抽出することです。ここでOpenAIの大規模言語モデル(LLM)が活躍します。
ユースケース1:動画文字起こし分析
YouTube動画の場合、文字起こしを分析して以下が可能です:
- コンテンツの要約
- 主要な議論トピックを抽出する。
- ブランド言及とタイムスタンプを特定する。
OpenAIのAPIを使用し、希望の出力形式(例:JSON)を指定したプロンプトと共に文字起こしデータを送信します。AIは構造化された要約と主要トピックを返却し、これをデータベースに保存します。
ユースケース2:コメントの感情分析
顧客フィードバックは世論理解に不可欠です。YouTubeコメント(または他プラットフォームの投稿)を分析することで以下が可能になります:
- 感情( 肯定的、否定的、中立的)を判定する。
- 共通トピックや課題点を抽出する。
- トレンドや潜在的なPR危機の特定
プロセスは以下の通りです:
- コメントのバッチをOpenAIのAPIに送信し、感情分析とトピック抽出を求めるプロンプトを指定する。
- JSON形式の応答をパースし、結果をデータベースに保存する。
- ユーザーフレンドリーなダッシュボードでインサイトを可視化する。
ステップ3: ワークフローの自動化
システムを真に強力にするには、プロセス全体を自動化する必要があります。具体的には、cronジョブ を設定し定期的に以下を実行します :
- 追跡対象(特定のチャンネル、検索クエリ、ソーシャルメディアプロフィールなど)のデータスクレイピングをトリガーする。
- 新たに収集したデータに対してAI分析を実行する。
- データベースを更新し、重要な変更をユーザーに通知する。
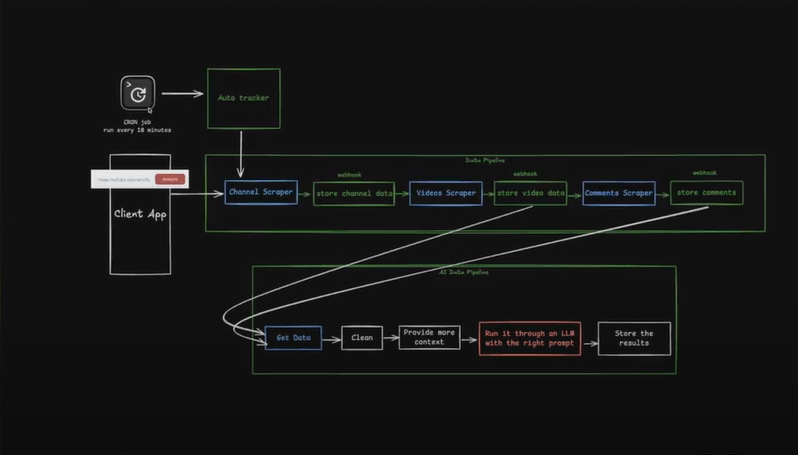
例えば、Google検索結果を24時間ごとにスクレイピングしたり、Reddit投稿を10分ごとに監視したりするスケジュールを設定できます。これにより、手動介入なしに常に最新のインサイトを得られます。
ステップ4: ユーザーインターフェースの構築
フロントエンドでは、ユーザーが以下の操作を行えるダッシュボードを作成できます:
- 特定のチャンネル、検索クエリ、プロフィールを追跡する。
- センチメント分析やトレンドトピックなどのリアルタイムインサイトを表示する。
- 重大な変化や潜在的なPR危機に関するアラートを受信する。
React Nativeや Expo などのツールを使用すれば、 Webとモバイルデバイス双方でシームレスに動作するクロスプラットフォームアプリケーションを構築できます。
次なるステップ:ソーシャルリスニングアプリケーションの強化
アプリケーションを次のレベルに引き上げるためのアイデアをいくつかご紹介します:
- アラートと通知: 特定の指標や閾値に対するメールやSlackアラートを設定します。
- 競合分析: 自社ブランドのパフォーマンスや感情を競合他社と比較します。
- 履歴データ: 経時的な変化を追跡し、トレンドと進捗を特定します。
- AIによる推奨事項: 洞察に基づき実行可能なアクションをAIで提案。
- RAGシステム: 検索強化生成(Retrieval-Augmented Generation)を導入し、データ向けチャットボットや検索エンジンを構築します。
まとめ
Bright DataのスクラッピングツールとOpenAIの大規模言語モデルを組み合わせることで、インターネット全体で自社ブランドを監視できるスケーラブルなAI搭載ソーシャルリスニングアプリケーションを構築しました。データ収集からインサイト抽出、ワークフローの自動化まで、このシステムは常に情報を把握し、データに基づいた意思決定を行う力を提供します。
本ガイドが参考になり、インスピレーションを得られたことを願っています。ご質問やご自身の活用事例を共有したい場合は、ソーシャルメディアで私までご連絡いただくか、YouTubeチャンネルでさらに多くのチュートリアルをご覧ください。
本プロジェクト実現に不可欠なツールを提供してくださったBright Data社に心より感謝申し上げます。