

Crawl4AIとFirecrawlは、データ収集業界における2大AIバズ製品である。このガイドでは、両製品の基本的な使い方と統計について説明する。
読み終わる頃には、以下の質問に答えられるようになっていることだろう。
- Crawl4AIとは?
- ファイヤークロールとは?
- それぞれの輝きはどこにあるのか?
- どこが足りないのか?
- なぜブライト・データが両者に代わる素晴らしい選択肢なのか?
これらの新しいツールの比較を理解することは、ブライト・データの包括的でスケーラブルなソリューションを強調するのに役立ちます。一般的なスクレイピング機能から本格的なデータ収集スイートまで、ブライト・データは実績のあるテクノロジーを提供します。
概要と目的
具体的な説明に入る前に、それぞれの製品がどのようなもので、どのような人に向けて販売されているのかを詳しく見てみよう。それぞれ異なる目的で作られているので、これはリンゴとリンゴの比較ではない。どちらかというと、「工具箱対スイスアーミーナイフ」の比較だ。
クロール4AI

Crawl4AIはオープンソースのPythonライブラリで、AIを利用したウェブスクレイピングをより簡単に、よりアクセスしやすくする。抽出パイプラインの拡張に焦点を当てた開発者向けだ。完全にオープンソースだ。コードはGitHubページで自由に利用できる。Crawl4AIは、Bright Dataの伝統的なスクレイピングツールとの整合性が高い。
ファイヤークロール
Firecrawlは、AIを活用したウェブスクレイピングにおけるエンタープライズリーダーの一つである。言語にとらわれないフレームワークと豊富な統合オプションを提供している。Firecrawlは、伝統的にデータ収集や必ずしも開発に携わらない人々から多くの関心を集めている。Firecrawlによって、スクレイピングは、必ずしもコーディングスキルを持たない人々にもアクセス可能になる。
ユニークな特徴
クロール4AI
Crawl4AIが際立っているのは、完全にオープンソースであり、寛容なライセンスを採用しているからだ。Crawl4AIが開発者にとって非常に魅力的な選択肢となる特徴を見てみよう。このツールは、設定可能なオプションとコードの透明性による信頼を提供します。
- オープンソース:誰でもコードを見ることができる。バグはしばしば発見され、コミュニティによって素早く修正される。透明性の高いコードベースは、コードの読み方を知っていれば、驚きがないことを意味する。
- LLMとLLMフリーの抽出:Crawl4AIでは、抽出に小さなローカルモデルを使用するか、Deepseekのような外部モデルに接続するかを選択できます。
- 寛容なライセンスCrawl4AIのライセンスは非常に柔軟で寛容である。このため、趣味の開発者と企業の開発者の両方から関心を集めている。
- Pythonライブラリ:Crawl4AIはサブスクリプションサービスではない。Pythonのライブラリだ。Crawl4AIはPythonのライブラリであり、Crawl4AIをバックエンドとして使用し、独自のスクレイパーを構築することができる。
ファイヤークロール
Firecrawlは、ウェブスクレイピングのための最も人気のあるエンタープライズツールの一つである。Firecrawlは言語にとらわれないフレームワークを提供しており、Python、JavaScript、またはGUIウェブサイトを使用して抽出を行うことができる。ホビーユーザーからエンタープライズユーザーまで、様々なプランを提供している。
- エンタープライズFirecrawlは企業向け製品である。オープンソースのオプションも提供している。しかし、彼らの主な製品ラインは、スケーラブルなデータ収集を今日望んでいる人々に向けられている。
- 言語にとらわれない:Firecrawlは、ウェブアプリを通してGUIサポートを提供している。また、Pythonと JavaScriptのSDKサポートも提供している。Goと RustのSDKもコミュニティによって提供されている。Firecrawlを使えば、Pythonに限定されることはない。プログラミング環境さえも限定されない。
- 自然言語処理(NLP):Firecrawlは、自然言語による開発とデータ収集に向いている。あなたはモデルに何をすべきかを指示する。するとモデルは収集タスクを実行する。
使いやすさ
クロール4AI
Crawl4AIを使い始めるのは比較的簡単だ。pip経由でインストールし、Python環境から呼び出すことができる。以下のスニペットは、インストールとインストールの確認方法を示しています。
以下のコマンドでCrawl4AIをインストールする。
pip install crawl4aiセットアップを実行して、ブラウザとツールをインストールします。
crawl4ai-setup doctorコマンドを使用してインストールを確認し、問題を特定してください。
crawl4ai-doctor以下のコードはとてもシンプルだ。Crawl4AIのドキュメントからそのまま引用しています。これを任意のPythonファイルに貼り付け、python name-of-file.pyで実行する。実際には、Crawl4AIはシェルコマンドとして実行する方が良い。VSCodeや他のIDEから直接実行すると、asyncioの問題を引き起こす傾向がある。
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())ファイヤークロール
Firecrawlを始めるときは、彼らのプレイグラウンドに移動し、ターゲットURLを入力するだけです。このインターフェースは、開発者でない人にもとても親切だ。
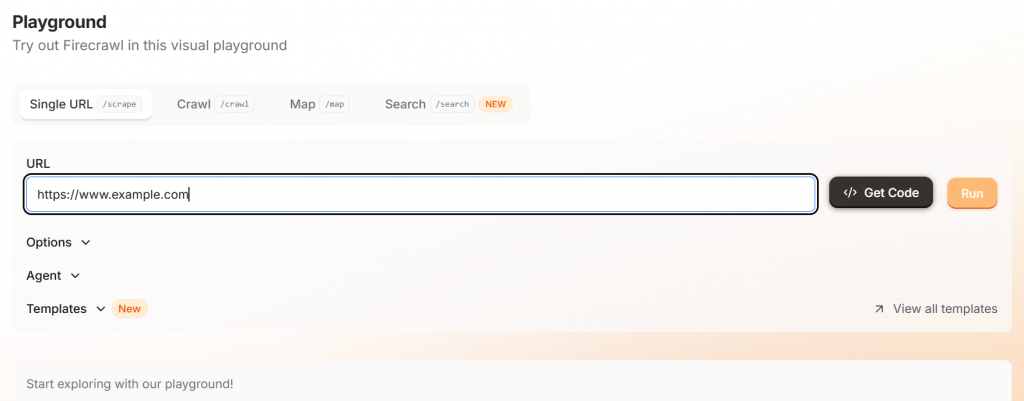
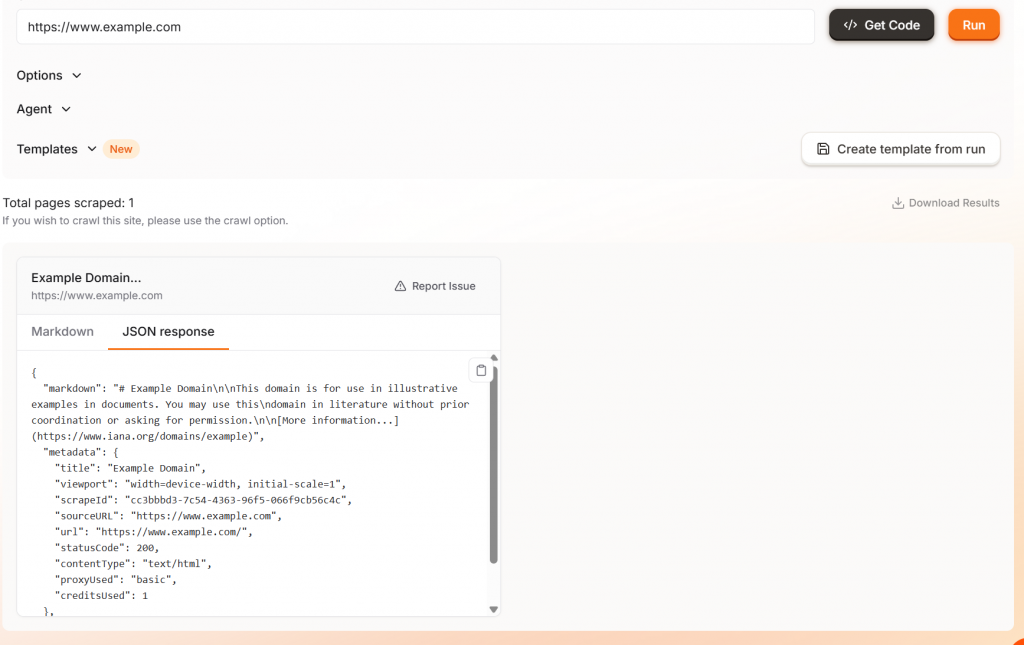
実行」ボタンをクリックすると、マークダウンかJSONのどちらかを選択した出力例が表示される。
パフォーマンスとスケーラビリティ
クロール4AI
下のスニペットは、先ほど見たサンプル・コードからのものである。全体として、例のドメインをスクレイピングするのに、2秒弱しかかかっていない。LLMなしで、Crawl4AIは非常に速い。パフォーマンスの面では、RequestsやBeautifulSoupを使った手動スクレイピングに匹敵する。

しかし、マークダウンスクレイピングと生のHTMLは、ほぼクリーンである。Crawl4AIは、LLMなしでJSONを抽出するためのサポートをリストアップしているが、サポートは限定的でバグが多い。完全なデータ構造を抽出するには、コードにLLMサポートを追加する必要がある。これはCrawl4AIの隠れたコストであり、本当のパースジョブを完了するためには、外部のLLMをホストするか、お金を払う必要がある。
以下のコードでは、BooksからScrapeにページを解析するためにOpenAIのモデルを使用しています。自分で実行する場合は、APIキーを自分のものに置き換えてください。
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
#tell the llm what to scrape and set config
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="Extract all product objects with 'name' and 'price' from the content.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
#build the crawler config
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
#create a browser config if needed
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
#crawl a single page
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
#assume the extracted content is json
data = json.loads(result.extracted_content)
print("Extracted items:", data)
#show usage stats
llm_strategy.show_usage()
else:
print("Error:", result.error_message)
if __name__ == "__main__":
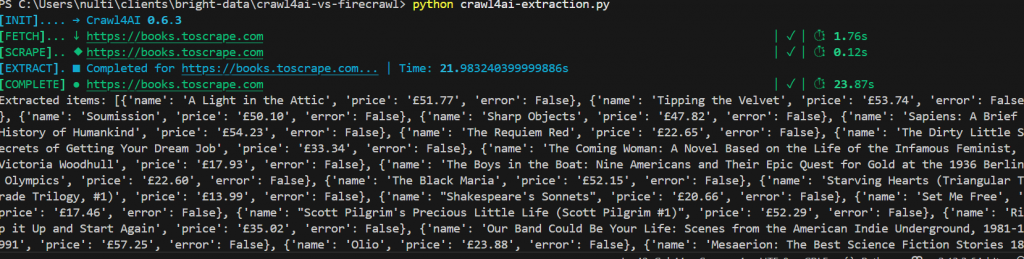
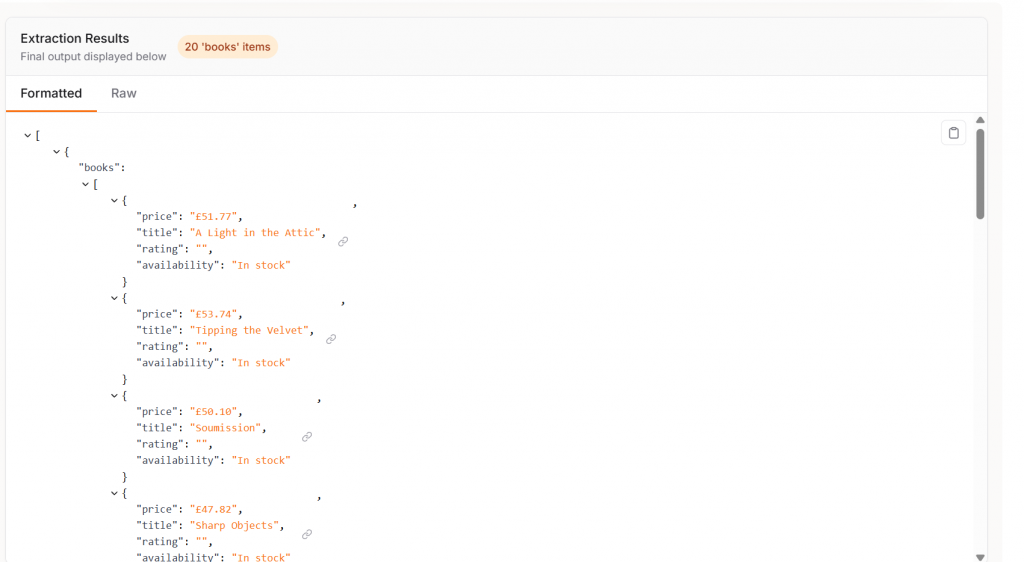
asyncio.run(main())これが出力結果だ。合計で25秒弱かかりました。また、各書籍が価格とともに、きれいに構造化されたJSONオブジェクトとしてリストされているのを見ることができる。
ファイヤークロール
FirecrawlはURLを入力するだけでページをスクレイピングしてくれる。Firecrawlのデフォルトバージョンを使用すると、JSONオブジェクトにダンプされた生のマークダウンとしてページを出力します。
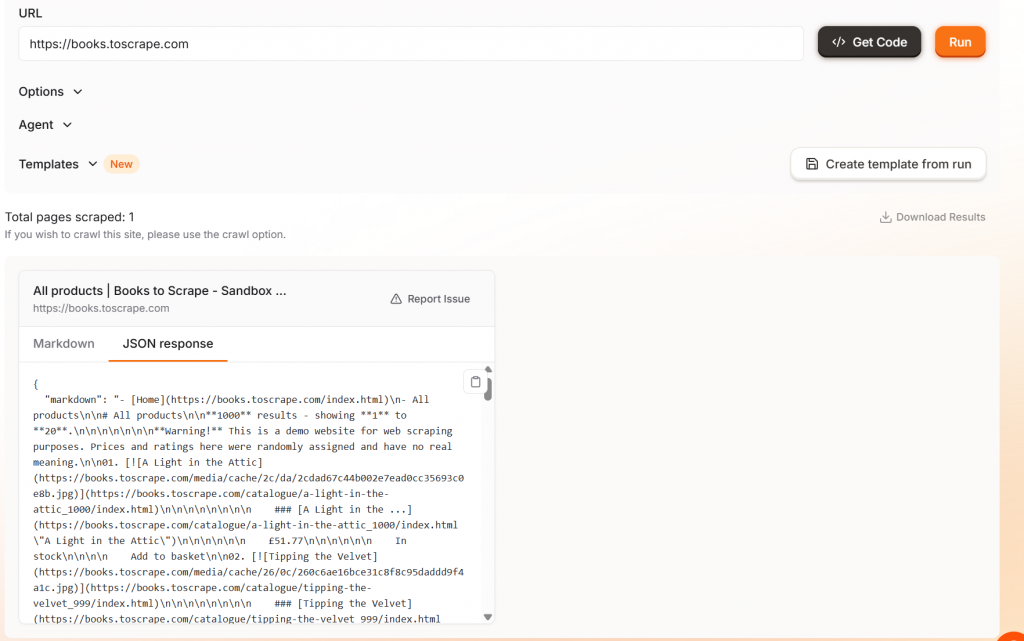
Firecrawlには、コードを実行する際にクールな機能がある。スクレイパーを実行すると、ブラウザがページをレンダリングする様子を見ることができます。
データの品質と正確性
クロール4AI
GPT-4oに接続すると、Crawl4AIは100%の精度で機能した。アイテム数をチェックするために、コードに以下の行を追加した。
print("Total products scraped:", len(data))下の出力にあるように、Crawl4AIとGPT-4oはページ上の20の項目をすべて発見した。

LLMと組み合わせることで、Crawl4AIは驚くほど精度の高い強力なツールとなる。
ファイヤークロール
Firecrawlは、スクレイピングに関して2つの異なる製品を提供している。シンプルでダーティなスクレイピングオプションには、普通のFirecrawlを使うことができる。Firecrawl Extractは、構造化されたJSONオブジェクトを抽出することができる。
レギュラー・ファイヤークロール
これは通常のFirecrawlを使ったBooks To Scrapeの出力である。見ての通り、ひどい-本当にひどい。Firecrawlはページをマークダウンに変換した。そして、生のマークダウンをJSONの一見ランダムなフィールドにスライスした。このデータは、手動でコードを使ってさらにクリーニングするか、LLMに渡す必要がある。
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [Travel](catalogue/category/books/travel_2/index.html)n - [Mystery](catalogue/category/books/mystery_3/index.html)n - [Historical Fiction](catalogue/category/books/historical-fiction_4/index.html)n - [Sequential Art](catalogue/category/books/sequential-art_5/index.html)n - [Classics](catalogue/category/books/classics_6/index.html)n - [Philosophy](catalogue/category/books/philosophy_7/index.html)n - [Romance](catalogue/category/books/romance_8/index.html)n - [Womens Fiction](catalogue/category/books/womens-fiction_9/index.html)n - [Fiction](catalogue/category/books/fiction_10/index.html)n - [Childrens](catalogue/category/books/childrens_11/index.html)n - [Religion](catalogue/category/books/religion_12/index.html)n - [Nonfiction](catalogue/category/books/nonfiction_13/index.html)n - [Music](catalogue/category/books/music_14/index.html)n - [Default](catalogue/category/books/default_15/index.html)n - [Science Fiction](catalogue/category/books/science-fiction_16/index.html)n - [Sports and Games](catalogue/category/books/sports-and-games_17/index.html)n - [Add a comment](catalogue/category/books/add-a-comment_18/index.html)n - [Fantasy](catalogue/category/books/fantasy_19/index.html)n - [New Adult](catalogue/category/books/new-adult_20/index.html)n - [Young Adult](catalogue/category/books/young-adult_21/index.html)n - [Science](catalogue/category/books/science_22/index.html)n - [Poetry](catalogue/category/books/poetry_23/index.html)n - [Paranormal](catalogue/category/books/paranormal_24/index.html)n - [Art](catalogue/category/books/art_25/index.html)n - [Psychology](catalogue/category/books/psychology_26/index.html)n - [Autobiography](catalogue/category/books/autobiography_27/index.html)n - [Parenting](catalogue/category/books/parenting_28/index.html)n - [Adult Fiction](catalogue/category/books/adult-fiction_29/index.html)n - [Humor](catalogue/category/books/humor_30/index.html)n - [Horror](catalogue/category/books/horror_31/index.html)n - [History](catalogue/category/books/history_32/index.html)n - [Food and Drink](catalogue/category/books/food-and-drink_33/index.html)n - [Christian Fiction](catalogue/category/books/christian-fiction_34/index.html)n - [Business](catalogue/category/books/business_35/index.html)n - [Biography](catalogue/category/books/biography_36/index.html)n - [Thriller](catalogue/category/books/thriller_37/index.html)n - [Contemporary](catalogue/category/books/contemporary_38/index.html)n - [Spirituality](catalogue/category/books/spirituality_39/index.html)n - [Academic](catalogue/category/books/academic_40/index.html)n - [Self Help](catalogue/category/books/self-help_41/index.html)n - [Historical](catalogue/category/books/historical_42/index.html)n - [Christian](catalogue/category/books/christian_43/index.html)n - [Suspense](catalogue/category/books/suspense_44/index.html)n - [Short Stories](catalogue/category/books/short-stories_45/index.html)n - [Novels](catalogue/category/books/novels_46/index.html)n - [Health](catalogue/category/books/health_47/index.html)n - [Politics](catalogue/category/books/politics_48/index.html)n - [Cultural](catalogue/category/books/cultural_49/index.html)n - [Erotica](catalogue/category/books/erotica_50/index.html)n - [Crime](catalogue/category/books/crime_51/index.html)nn# All productsnn**1000** results - showing **1** to **20**.nnnnnnn**Warning!** This is a demo website for web scraping purposes. Prices and ratings here were randomly assigned and have no real meaning.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [A Light in the ...](catalogue/a-light-in-the-attic_1000/index.html "A Light in the Attic")nnnnnn £51.77nnnnnn In stocknnnn Add to basketnn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [Tipping the Velvet](catalogue/tipping-the-velvet_999/index.html "Tipping the Velvet")nnnnnn £53.74nnnnnn In stocknnnn Add to basketnn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn In stocknnnn Add to basketnn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn In stocknnnn Add to basketnn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [Sapiens: A Brief History ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "Sapiens: A Brief History of Humankind")nnnnnn £54.23nnnnnn In stocknnnn Add to basketnn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [The Requiem Red](catalogue/the-requiem-red_995/index.html "The Requiem Red")nnnnnn £22.65nnnnnn In stocknnnn Add to basketnn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [The Dirty Little Secrets ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "The Dirty Little Secrets of Getting Your Dream Job")nnnnnn £33.34nnnnnn In stocknnnn Add to basketnn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [The Coming Woman: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull")nnnnnn £17.93nnnnnn In stocknnnn Add to basketnn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [The Boys in the ...](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics")nnnnnn £22.60nnnnnn In stocknnnn Add to basketnn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [The Black Maria](catalogue/the-black-maria_991/index.html "The Black Maria")nnnnnn £52.15nnnnnn In stocknnnn Add to basketnn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [Starving Hearts (Triangular Trade ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "Starving Hearts (Triangular Trade Trilogy, \#1)")nnnnnn £13.99nnnnnn In stocknnnn Add to basketnn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [Shakespeare's Sonnets](catalogue/shakespeares-sonnets_989/index.html "Shakespeare's Sonnets")nnnnnn £20.66nnnnnn In stocknnnn Add to basketnn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn In stocknnnn Add to basketnn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [Scott Pilgrim's Precious Little ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "Scott Pilgrim's Precious Little Life (Scott Pilgrim \#1)")nnnnnn £52.29nnnnnn In stocknnnn Add to basketnn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn In stocknnnn Add to basketnn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [Our Band Could Be ...](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991")nnnnnn £57.25nnnnnn In stocknnnn Add to basketnn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [Olio](catalogue/olio_984/index.html "Olio")nnnnnn £23.88nnnnnn In stocknnnn Add to basketnn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [Mesaerion: The Best Science ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "Mesaerion: The Best Science Fiction Stories 1800-1849")nnnnnn £37.59nnnnnn In stocknnnn Add to basketnn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [Libertarianism for Beginners](catalogue/libertarianism-for-beginners_982/index.html "Libertarianism for Beginners")nnnnnn £51.33nnnnnn In stocknnnn Add to basketnn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [It's Only the Himalayas](catalogue/its-only-the-himalayas_981/index.html "It's Only the Himalayas")nnnnnn £45.17nnnnnn In stocknnnn Add to basketnnn-nPage 1 of 50nnn- [next](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "24th Jun 2016 09:29",
"viewport": "width=device-width",
"title": "n All products | Books to Scrape - Sandboxn",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}通常のFirecrawlはページを取得するが、それ以上のことはできない。スライスされたマークダウンのページが大きなJSONオブジェクトに叩き込まれます。ページを取得することはできますが、ウェブページを使用可能なデータに変換するために多くの作業を必要とします。
ファイヤークロール抽出物
Extractはその次の段階です。Extractでは、NLPによるスクレイピングを完全にサポートする。取得すべきデータをモデルに伝えると、ページからそれを抽出する。下の画像にあるように、タイトル、価格、在庫状況フィールドを含む推奨スキーマも取得できる。スキーマに満足したら、”Run “ボタンをクリックする。
あなたのウェブサイトには/*が付加されています – これはExtractにサイト全体を自動的にクロールするように指示します。クレジットを節約するには、/*を削除してください。
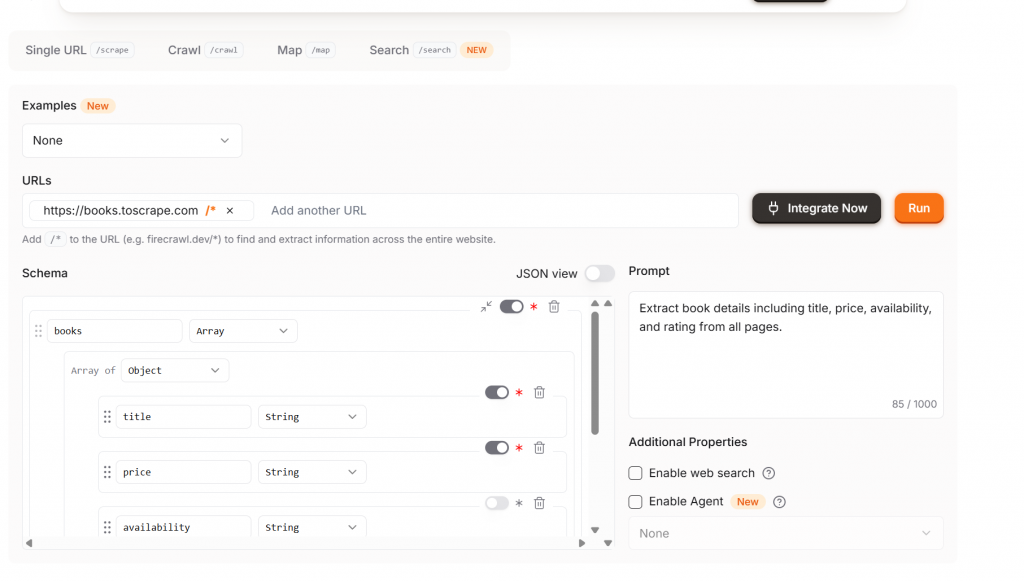
単一ページをクロールしたい場合は、デフォルトの設定からExtractを変更してください。下の画像は、単一ページをスクレイピングする設定です。演算子/*は見落としがちなので、必要なときだけ使うようにしましょう。
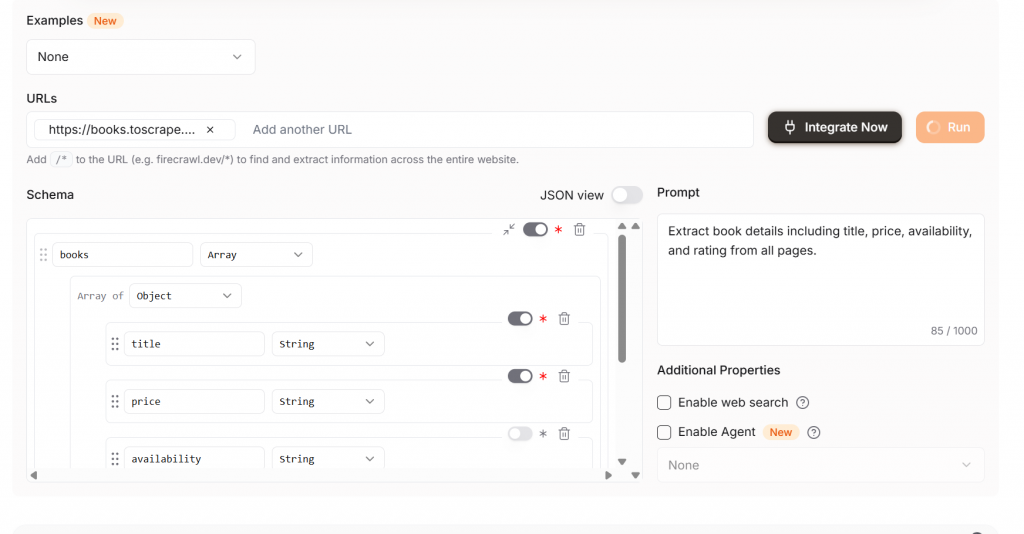
Firecrawl Extract を使用すると、出力はクリーンですぐに使用できます。ご覧の通り、以下の特徴を持つ構造化された JSON オブジェクトが得られます。
タイトル価格格付け可用性
セキュリティとコンプライアンス
クロール4AI
Crawl4AIは、ソフトウェアに組み込まれたコンプライアンスの保証は付属していません。しかし、robots.txtファイルのようなコンプライアンスをサポートする設定をいくつか提供しています。
Crawl4AIを使用する場合、GDPRやCCPAのような法律への準拠は自己責任となります。Crawl4AIは、法律やセキュリティのコンプライアンスに関する支援をほとんど提供していません。つまり、大規模なプロジェクトを実行する場合、適切な慣行に従っていることを確認するために、追加のサポートを雇う必要があるでしょう。
ファイヤークロール
ドキュメントによると、Firecrawlはあなたの情報をGoogleに渡して処理する。Firecrawlは、GDPRとCCPAに従うが、これらのポリシーは利用者自身が遵守する必要があることを規約で明示している。これらの行為に対する違反はすべてあなたの責任であり、ツールの誤用については責任を負わないという。
Firecrawlは、Crawl4AIよりも多くの責任保護を提供しています。しかし、それでもまだ多くはない。彼らの製品にはガードレールがついていない。ルールに従うことが期待され、もし従わなければ、誤用の責任を負うことになる。詳しくはFirecrawlの利用規約をご覧ください。
価格とライセンス
クロール4AI
Crawl4AIは誰でも無料で利用できる。ここで言う “無料 “とは、かなり大雑把に使っている。おそらくお気づきだと思うが、実際の抽出作業にはLLMの統合が必要だ。LLMを自分でホストするか、OpenAI APIのようなサービスにプラグインすることができる。Crawl4AIを使用する場合、セルフホスティングの場合は、外部サービスやインフラストラクチャのコストを支払う必要がある。これらのコストはかさむ。Crawl4AIを使っても、運用コストをゼロにすることはできない。
Crawl4AIはApache Licenseの下で配布されています。Crawl4AIの派生物を修正、配布、そして商業的に販売することも許可されている。もしコンプライアンスに問題があるのであれば、Crawl4AIの寛容なライセンスは、開発者やデータチームにとって非常に魅力的な選択肢となる。
ファイヤークロール
レギュラー・ファイヤークロール
Vanilla Firecrawlには様々な料金プランがあります。無料プランを試すことができる。有料プランは3,000ページで$16/月から500,000ページで$333/月まで。

ファイヤークロール抽出物
Extractを使用する場合、年間18,000,000トークンで月額89ドルから、年間192,000,000APIトークンで月額719ドルまでの有料プランがある。

Firecrawlライセンス
Firecrawlは、さまざまな製品に異なるライセンスを使用しています。すべてのライセンスはこちらでご覧いただけます。Firecrawl はエンタープライズレベルの製品であり、彼らのコードを自分のものとしてリパッケージすることはできないことにご注意ください。オープンソースのコードでさえ、AGPL-3.0ライセンスの下で配布されています。他のGNUソフトウェア契約と同様に、企業での使用に関しては厳しい制限があります。
コミュニティとサポート
クロール4AI
オープンソースプロジェクトとして、Crawl4AIは持てるリソースでできる限りのサポートを提供する。ヘルプデスクやSLAはない。しかし、あなたは彼らのDiscordチャンネルを介して自由に開発者に連絡することができます。待ち時間は変動する可能性がある。専門チームが問題を追跡し、タイムリーにあなたのニーズを解決することは期待しないでください。
ファイヤークロール
Firecrawlのダッシュボードでは、ドキュメント、FAQページ、ステータスアップデートなどのサポートオプションを提供しています。優先順位はプランのランクによって異なりますが、”サポートに連絡 “ボタンからサポートチームに連絡することができます。また、Discord チャンネルにも自由に参加することができます。

実際の使用例
クロール4AI
Crawl4AIには、現代の開発者のための実世界での様々な使用例があります。あなたが構築できるものは限られています。
- バックエンドのサポート独自のデータ製品を作成することを決めた場合、Crawl4AIを独自のLLMと統合し、製品を販売することができます。
- AIエージェント:CSV、JSON XMLなど、LLMが見たことのあるフォーマットであれば、どのようなフォーマットでも利用可能だ。
- 趣味のプロジェクトとスタートアップCrawl4AIのようなオープンソースツールは、実験、概念実証、パイプラインのプロトタイプのための迅速なアクセスを提供します。
ファイヤークロール
Firecrawlは、社内での開発をほとんど行わずに大量のスクレイピングを必要とするチームのために構築されている。アイデアから具体的な製品まで、労力をかけずに作り上げたいのであれば、Firecrawlはそのお手伝いをします。
- プロダクションレベルのクローリングFirecrawlは、大規模なクロールのために構築されている。Firecrawlのツールは、デフォルトでウェブサイト全体をクロールします。
- コンテンツのモニタリング:競合他社を定期的にクロールし、価格とコンテンツを監視する。
- クリーンでレディなデータ:Extractを使用すると、データをほとんどクリーンアップすることなく、そのままデータチームに渡すことができます。
長所と短所
| クロール4AI | ファイヤークロール | |
|---|---|---|
| 長所 | – 完全なオープンソースと透明性。 – 許可されたApacheライセンス – 構築、変更、再販。 – 柔軟:LLM搭載またはLLM非搭載のオプション。 – カスタムパイプライン用のプラグアンドプレイPythonライブラリ。 |
– 非開発者にとっては至ってシンプル:GUI、プレイグラウンド、NLPプロンプト。 – 複数の言語(Python、JS、Go、Rust)で動作。 – 単発のスクレイピングや定期的なスクレイピングに素早くデプロイできます。 – エンタープライズ価格とサポートが利用可能。 |
| 短所 | – 実際の構造化抽出には別のLLMが必要 – 隠れたコストがかかる。 – 限られた組み込みコンプライアンスサポート – GDPR/CCPAを管理する必要がある。 – 非同期のクセ – シェルの実行がベスト。 |
– Extractなしではベース出力がしばしば乱雑になる – 生のマークダウンはより多くの作業を必要とする。 – コンプライアンスに関する真のガードレールがない – ユーザは依然として責任を負う。 – クローズドソースのコア、AGPLの制限によりカスタムビルドが制限される。 – 規模やワイルドカードクローリングによって、利用コストが急速に増大する可能性がある。 |
ブライト・データを考慮すべき理由
Crawl4AIとFirecrawlにはトレードオフがある。Crawl4AIには、開発者のニーズと隠れたLLMコストが伴う。Firecrawlでは、利用階層とFirecrawlエコシステムにロックされる。
ブライト・データは、前述の両ツールと同じニッチを埋めるのに役立つ様々な製品を提供している。
トップ・ブライト・データ・ツール
- スクレイパーAPI:いつでも好きな時に、クリーンですぐに使えるデータで、あらかじめ構築されたスクレイパーを実行できます。
- Web Unlocker API:サイトブロックを回避し、CAPTCHAを解決し、マークダウンとしてスクレイピングし、さらにジオロケーションをコントロールします。
- ブラウザAPI:あなたのプログラミング環境から、統合されたプロキシとCAPTCHA解決でリモートブラウザを制御します。
- データセット年前にさかのぼる100以上のドメインの膨大な過去のデータセットライブラリにアクセスします。
MCPサーバーは、LLMに最適なパッケージで、Bright Dataの全製品にアクセスできます。LLMに接続し、プロンプトを書き込んで、システムにお任せください。
明るいデータ統合オプション
私たちは、今日のAIや開発業界で最高のツールのいくつかとの統合も提供しています。私たちは常に新しい統合を追加しています。最新のリストはドキュメントをご覧ください。
結論
ブライトデータでは、スクレイピングの問題を解決するだけでなく、AIスタックのエコシステム全体を提供します。ライブデータの取得からトレーニングのための過去のアーカイブの利用まで、インフラストラクチャではなく、インサイトに時間を費やせるようにします。
今すぐ無料トライアルを開始し、その違いをお確かめください。





