

このチュートリアルでは、次のことを学びます:
- Crawl4AIとは何か、ウェブスクレイピングのために何を提供するか
- DeepSeekのようなLLMでCrawl4AIを使用する理想的なシナリオ
- DeepSeekを搭載したCrawl4AIスクレイパーの作り方をガイドします。
さあ、飛び込もう!
Craw4AIとは?
Crawl4AIは、大規模言語モデル(LLM)、AIエージェント、データパイプラインとシームレスに統合できるように設計された、オープンソースのAI対応ウェブクローラーとスクレーパーです。高速でリアルタイムのデータ抽出を実現すると同時に、柔軟で導入が容易です。
AIウェブスクレイピングのための機能は以下の通り:
- LLMのために作られました:検索機能付き生成(RAG)と微調整のために最適化された構造化Markdownを生成します。
- 柔軟なブラウザコントロール:セッション管理、プロキシ、カスタムフックをサポート。
- ヒューリスティック・インテリジェンス:スマートなアルゴリズムでデータ解析を最適化。
- 完全オープンソース:APIキーは不要で、Dockerやクラウドプラットフォームでデプロイ可能。
詳しくは公式ドキュメントをご覧ください。
ウェブスクレイピングにCrawl4AIとDeepSeekを使う場合
DeepSeekは、その効率性と有効性からAIコミュニティで話題となった、強力でオープンソースの無料のLLMモデルを提供しています。さらに、これらのモデルはCrawl4AIとスムーズに統合できます。
Crawl4AIのDeepSeekを活用することで、最も複雑で一貫性のないウェブページからも構造化データを抽出することができます。しかも、定義済みの解析ロジックは必要ありません。
以下は、DeepSeek + Crawl4AIの組み合わせが特に役立つ主なシナリオです:
- 頻繁なサイト構造の変更:従来のスクレイパーは、ウェブサイトがHTML構造を更新すると壊れてしまうが、AIは動的に適応する。
- 一貫性のないページレイアウト:Amazonのようなプラットフォームでは、商品ページのデザインが様々です。LLMはレイアウトの違いに関係なく、インテリジェントにデータを抽出することができます。
- 非構造化コンテンツの解析:フリーテキストのレビュー、ブログの投稿、フォーラムのディスカッションから洞察を抽出するのは、LLMを利用した処理で簡単になります。
Craw4AIとDeepSeekによるWebスクレイピング:ステップバイステップガイド
このガイド付きチュートリアルでは、Crawl4AIを使ってAIを搭載したウェブスクレーパーを構築する方法を学びます。LLMエンジンとして、DeepSeekを使用します。
具体的には、ブライト・データのG2ページからデータを抽出するAIスクレーパーの作成方法をご覧いただきます:
以下の手順に従って、Crawl4AIとDeepSeekを使用してWebスクレイピングを実行する方法を学んでください!
前提条件
このチュートリアルに従うには、以下の前提条件を満たしていることを確認してください:
- Python 3+をマシンにインストール
- GroqCloudアカウント
- ブライトデータのアカウント
GroqCloudまたはBright Dataのアカウントをまだお持ちでない方もご安心ください。次のステップでセットアップをご案内します。
ステップ1:プロジェクトのセットアップ
以下のコマンドを実行して、Crawl4AI DeepSeekスクレイピング・プロジェクト用のフォルダを作成します:
mkdir crawl4ai-deepseek-scraperプロジェクトフォルダーに移動し、仮想環境を作成します:
cd crawl4ai-deepseek-scraper
python -m venv venv次に、crawl4ai-deepseek-scraperフォルダをお気に入りのPython IDEにロードする。Python拡張機能付きのVisual Studio Codeか PyCharm Community Editionが2つの素晴らしい選択肢だ。
プロジェクトフォルダー内に
scraper.py:AIによるスクレイピングロジックを含むファイル。models/:PydanticベースのCrawl4AI LLMデータモデルを格納するディレクトリ。.env:環境変数を安全に保存するためのファイル。
これらのファイルとフォルダを作成した後、プロジェクトの構造は次のようになるはずだ:

次に、IDEのターミナルで仮想環境を有効にする。
LinuxまたはmacOSでは、このコマンドを起動する:
./env/bin/activate同様に、Windowsでは、実行する:
env/Scripts/activate素晴らしい!これでDeepSeekを使ったCrawl4AIウェブスクレイピングのPython環境が整いました。
ステップ2:Craw4AIをインストールする
仮想環境をアクティブにした状態で、crawl4ai pipパッケージ経由でCrawl4AIをインストールする:
pip install crawl4aiこのライブラリにはいくつかの依存関係があるため、インストールに時間がかかる場合がある。
インストールしたら、ターミナルで以下のコマンドを実行する:
crawl4ai-setupそのプロセスだ:
- 必要なPlaywrightブラウザ(Chromium、Firefoxなど)をインストールまたは更新します。
- OSレベルのチェックを行う(例:Linuxで必要なシステムライブラリがインストールされていることを確認する)。
- お客様の環境がウェブクローリングのために適切に設定されていることを確認します。
コマンドを実行すると、次のような出力が表示されるはずだ:
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:Usersantoz.crawl4aicrawl4ai.db.backup_20260219_092341
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!驚いた!Crawl4AIがインストールされ、使用できるようになりました。
ステップ4:scraper.pyの初期化
Crawl4AIは非同期コードを必要とするので、基本的なasyncioスクリプトを作成することから始める:
import asyncio
async def main():
# Scraping logic...
if __name__ == "__main__":
asyncio.run(main())このプロジェクトには、DeepSeek のようなサードパーティ・サービスとの統合が含まれることを忘れないでください。これを実装するには、API キーとその他のシークレットに依存する必要があります。それらを.envファイルに格納します。
環境変数をロードするためにpython-dotenvをインストールします:
pip install python-dotenvmain()を定義する前に、load_dotenv()で.envファイルから環境変数をロードする:
load_dotenv()python-dotenvライブラリからload_dotenv をインポートします:
from dotenv import load_dotenv完璧です!scraper.pyはAIを使ったスクレイピングロジックをホストする準備ができています。
ステップ #5: 最初のAIスクレイパーを作る
scraper.pyの main()関数の中に、基本的なCrawl4AIクローラーを使って以下のロジックを追加します:
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")上記のスニペットで、重要なポイントは以下の通りである:
BrowserConfig:ヘッドレスモードやウェブスクレイピング用のカスタムユーザーエージェントなどの設定を含め、ブラウザの起動方法や動作を制御します。CrawlerRunConfig:キャッシュ戦略、データ選択ルール、タイムアウトなどのクローリング動作を定義します。headless=True:リソースを節約するために、GUIを使わないヘッドレスモードでブラウザを実行するように設定します。CacheMode.BYPASS:このコンフィギュレーションは、クローラーがキャッシュデータに頼るのではなく、ウェブサイトから直接新鮮なコンテンツをフェッチすることを保証します。crawler.arun():このメソッドは、指定されたURLからデータを抽出するために非同期クローラーを起動します。result.markdown:抽出されたコンテンツはMarkdown形式に変換され、解析や分析が容易になります。
以下のインポートを忘れずに追加すること:
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode今現在、scraper.pyは以下を含んでいるはずです:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# Load secrets from .env file
load_dotenv()
async def main():
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")
if __name__ == "__main__":
asyncio.run(main())スクリプトを実行すると、以下のような出力が表示されるはずだ:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 0.83s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 1ms
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 0.83s
Parsed Markdown data:解析されたMarkdownコンテンツは空なので、これは疑わしい。さらに調べるには、レスポンスのステータスを表示する:
print(f"Response status code: {result.status_code}")今回の出力は以下の通り:
Response status code: 403Crawl4AIのリクエストがG2のボット検知システムによってブロックされたため、Markdownで解析された結果は空である。それは、サーバーから返された403 Forbiddenステータスコードによって明らかである。
G2には厳格なボット対策が施されているからだ。特に、通常のブラウザからアクセスした場合でも、しばしばCAPTCHAが表示される:

この場合、有効なコンテンツが受信されなかったため、Crawl4AIはそれをMarkdownに変換することができなかった。次のステップでは、この制限を回避する方法を探ります。さらに読むには、PythonでCAPTCHAをバイパスする方法のガイドをご覧ください。
ステップ #6: Web Unlocker APIの設定
Crawl4AIは、ボット回避メカニズムが組み込まれた強力なツールです。しかし、G2のような厳重で一流のボット対策とスクレイピング対策を採用している高度に保護されたウェブサイトをバイパスすることはできません。
このようなサイトに対しては、保護レベルに関係なく、あらゆるウェブページのブロックを解除するように設計された専用ツールを使用するのが最善の解決策です。このタスクに最適なスクレイピング製品は、Bright DataのWeb Unlockerです:
- 実際のユーザー行動をシミュレートし、アンチボット検出を回避
- プロキシ管理とCAPTCHA解決を自動的に処理する
- インフラ管理を必要とせず、シームレスに拡張可能
次の手順に従って、Web Unlocker APIをCrawl4AI DeepSeekスクレイパーに統合してください。
または、公式ドキュメントを参照してください。
まず、Bright Dataアカウントにログインしてください。アカウントに入金するか、すべての製品で利用可能な無料トライアルをご利用ください。
次に、ダッシュボードの “Proxies & Scraping “に移動し、表の中の “unblocker “オプションを選択する:
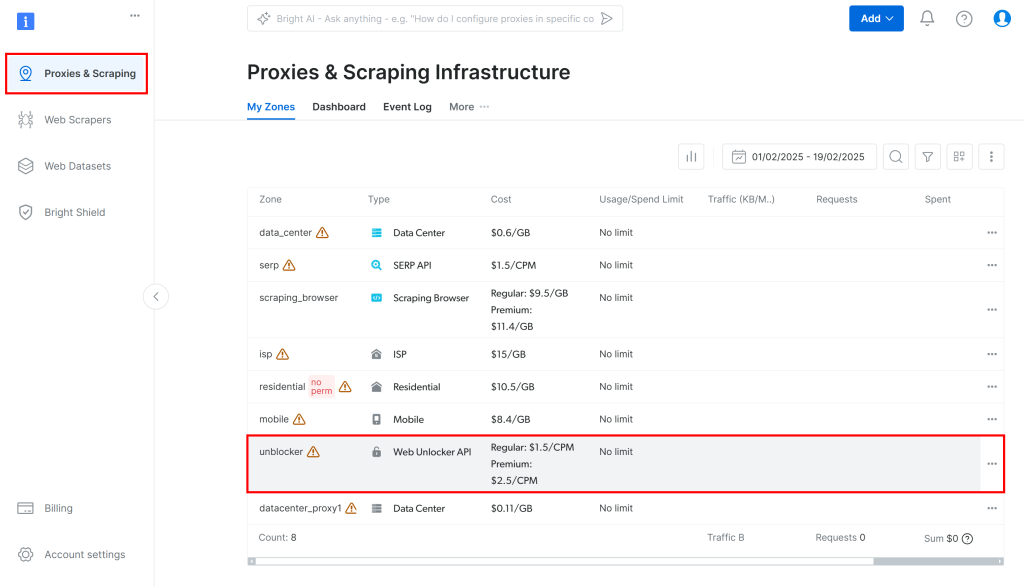
これにより、以下の Web Unlocker API 設定ページが表示されます:
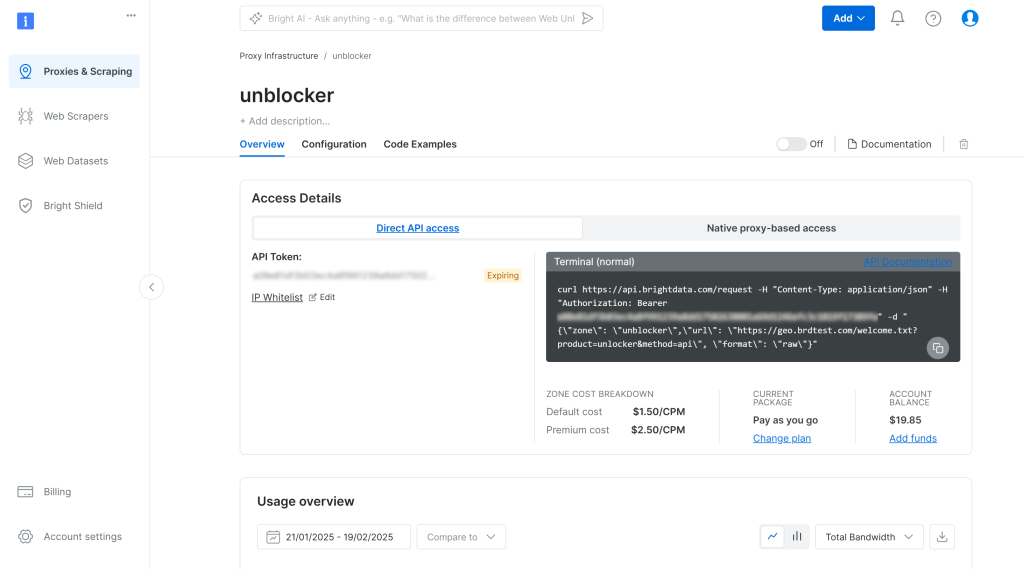
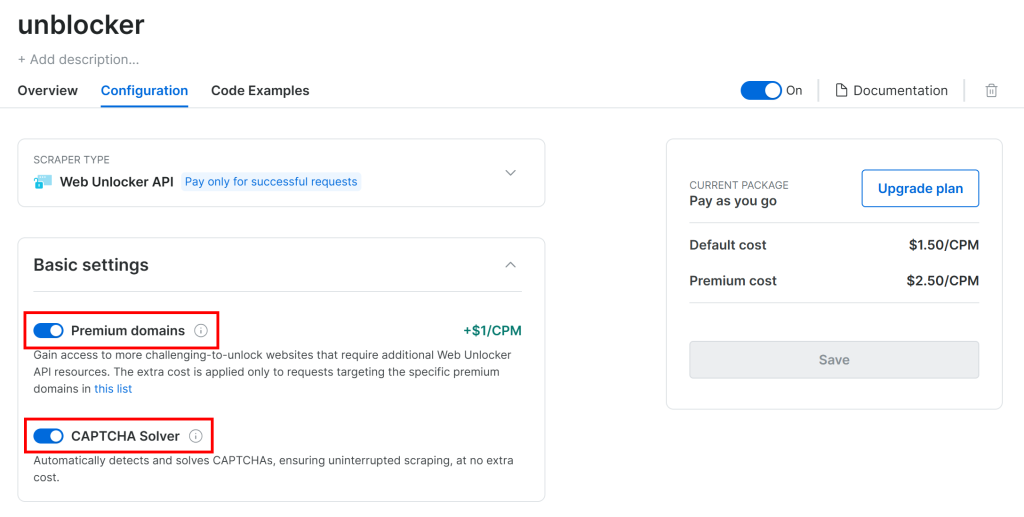
ここで、トグルをクリックしてWeb Unlocker APIを有効にします:

G2は、CAPTCHAを含む高度なボット対策によって保護されています。そのため、”Configuration “ページで以下の2つのトグルが有効になっていることを確認してください:
Crawl4AIは、制御されたブラウザでページをナビゲートすることで動作する。Crawl4AIは、Playwrightのgoto()関数に依存しており、HTTPGETリクエストをターゲットのウェブページに送信する。対照的に、Web Unlocker APIはPOSTリクエストで動作する。
プロキシとして設定することで、Crawl4AIでWeb Unlocker APIを使用することができますので、問題ありません。これにより、Crawl4AIのブラウザは、Bright Dataの製品を通してリクエストを送信し、ブロックされていないHTMLページを受信することができます。
Web Unlocker API のプロキシ認証情報にアクセスするには、「概要」ページの「ネイティブプロキシベースのアクセス」タブにアクセスします:
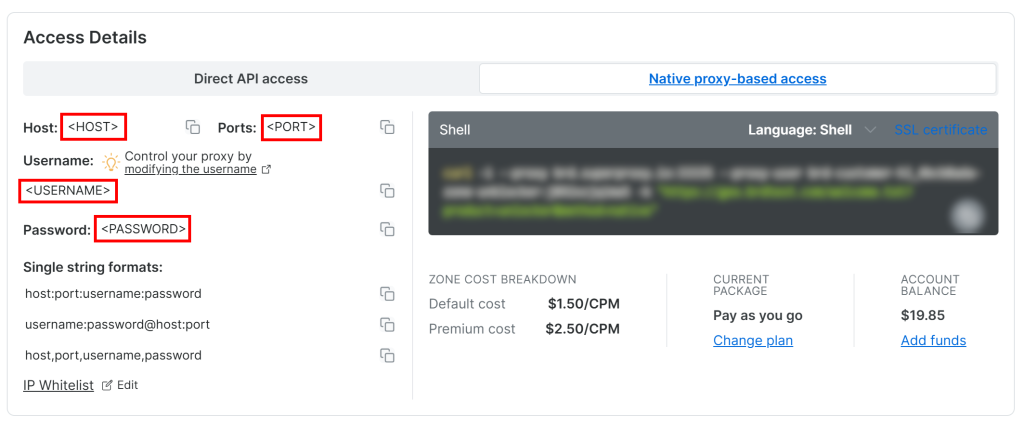
そのページから以下の認証情報をコピーする:
<ホスト<ポート<ユーザー名<パスワード
次に、これらの環境変数を.envファイルに入力する:
PROXY_SERVER=https://<HOST>:<PORT>
PROXY_USERNAME=<USERNAME>
PROXY_PASSWORD=<PASSWORD>素晴らしい!Web UnlockerがCrawl4AIと統合できるようになりました。
ステップ #7: Web Unlocker APIを統合する
BrowserConfigは、proxy_configオブジェクトを通して、プロキシの統合をサポートしています。Web Unlocker APIとCrawl4AIを統合するには、.envファイルから環境変数をこのオブジェクトに入力し、BrowserConfigのコンストラクタに渡します:
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)Python標準ライブラリからosをインポートすることを忘れずに:
import osWeb Unlocker APIは、プロキシ経由のIPローテーションと最終的なCAPTCHAの解決により、若干の時間オーバーヘッドが発生することに留意してください。それを考慮する必要があります:
- ページのロードタイムアウトを3分に増やす
- DOMが完全に読み込まれるまで待ってから解析するようクローラーに指示する。
次のようなCrawlerRunConfigの設定で実現できる:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded", # wait until the DOM of the page has been loaded
page_timeout=180000, # wait up to 3 mins for page load
)G2 のような複雑なサイトを扱う場合、Web Unlocker API でも完全ではないことに注意してください。まれに、スクレイピング API がブロック解除されたページの取得に失敗し、スクリプトが以下のエラーで終了することがあります:
Error: Failed on navigating ACS-GOTO:
Page.goto: net::ERR_HTTP_RESPONSE_CODE_FAILURE at https://www.g2.com/products/bright-data/reviews成功したリクエストに対してのみ課金されますのでご安心ください。そのため、スクリプトが動作するまでスクリプトを再 起動する心配はありません。本番用スクリプトでは、自動再試行ロジックの実装を検討してください。
リクエストが成功すると、次のような出力が表示される:
Response status code: 200
Parsed Markdown data:
* [Home](https://www.g2.com/products/bright-data/</>)
* [Write a Review](https://www.g2.com/products/bright-data/</wizard/new-review>)
* Browse
* [Top Categories](https://www.g2.com/products/bright-data/<#>)
Top Categories
* [AI Chatbots Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/ai-chatbots>)
* [CRM Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/crm>)
* [Project Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/project-management>)
* [Expense Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/expense-management>)
* [Video Conferencing Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/video-conferencing>)
* [Online Backup Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/online-backup>)
* [E-Commerce Platforms](https://www.g2.com/products/brig素晴らしい!今回、G2は200 OKステータスコードで応答した。これはリクエストがブロックされなかったことを意味し、Crawl4AIは意図した通りにHTMLをMarkdownに解析することができた。
ステップ#8: Groqのセットアップ
GroqCloudは、無料プランでもOpenAI互換のAPIを介してDeepSeek AIモデルをサポートする数少ないプロバイダーの一つである。そのため、Crawl4AIのLLM統合に使用されるプラットフォームとなる。
まだGroqアカウントをお持ちでない場合は、アカウントを作成してください。そうでなければ、ログインしてください。ユーザーダッシュボードの左メニューから “API Keys “に移動し、”Create API Key “ボタンをクリックします:
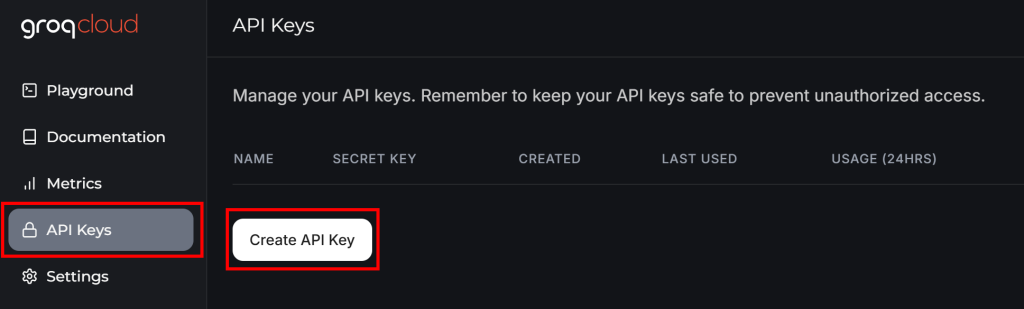
ポップアップが表示されます:
APIキーに名前を付け(例:”Crawl4AI Scraping”)、Cloudflareによるアンチボット検証を待つ。その後、”Submit “をクリックしてAPIキーを生成する:
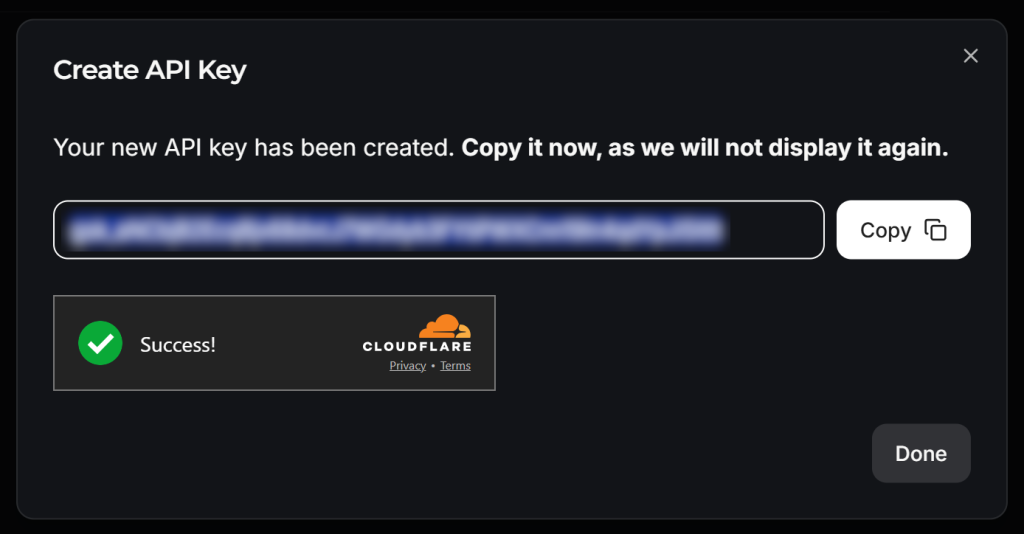
APIキーをコピーして、以下のように.envファイルに追加する:
LLM_API_TOKEN=<YOUR_GROK_API_KEY>を置き換えてください。 を Groq が提供する実際の API キーに置き換えてください。
美しい!これで、Crawl4AIでDeepSeekをLLMスクレイピングに使用する準備が整いました。
ステップ#9: スクレイピングしたデータのスキーマを定義する
Crawl4AIは、スキーマベースのアプローチに従ってLLMスクレイピングを実行する。この文脈では、スキーマはJSONデータ構造で定義される:
- ページ上の “コンテナ “要素を特定するベース・セレクタ(例:商品列、ブログ記事カード)。
- 各データ(テキスト、属性、HTMLブロックなど)をキャプチャするためのCSS/XPathセレクタを指定するフィールド。
- 繰り返し構造や階層構造のための入れ子型やリスト型。
スキーマを定義するには、まずターゲット・ページから抽出したいデータを特定する必要があります。そのためには、ブラウザのシークレット・モードでターゲット・ページを開きます:
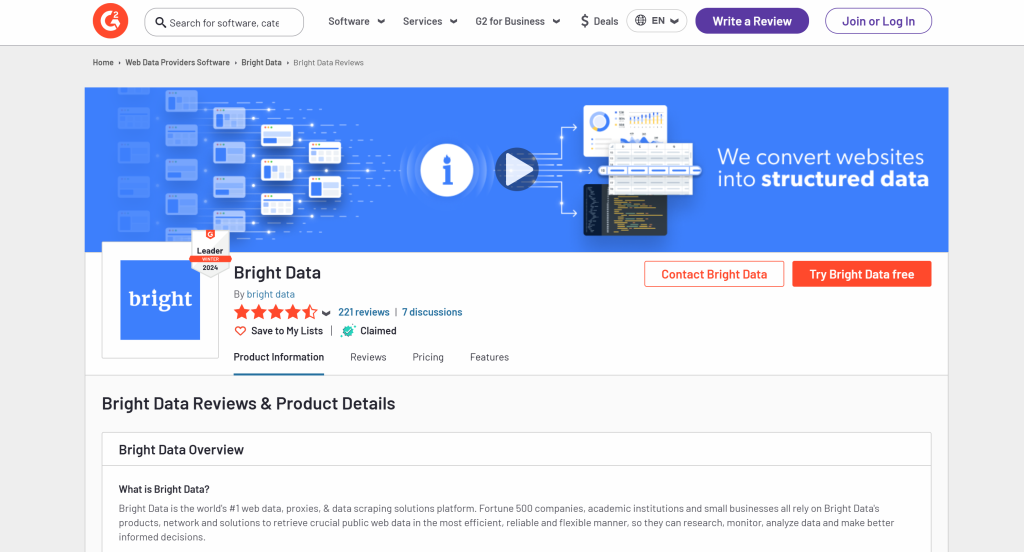
この場合、以下の分野に興味があると仮定する:
name: 商品名/会社名。image_url:商品/企業画像のURL。説明製品/会社の簡単な説明。レビュースコア製品/企業の平均レビュースコア。number_of_reviews:レビューの総数。請求済み:会社プロファイルが所有者によって請求されているかどうかを示すブール値。
次に、modelsフォルダにg2_product.pyファイルを作成し、G2ProductというPydanticベースのスキーマクラスを以下のように設定します:
# ./models/g2_product.py
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolはい!DeepSeek が実行するLLM スクレイピング処理では、上記のスキーマに従ってオブジェクトが返されます。
ステップ#10: DeepSeekの統合準備
DeepSeekとCrawl4AIの統合を完了する前に、GroqCloudアカウントの「設定 > 制限」ページを確認してください:
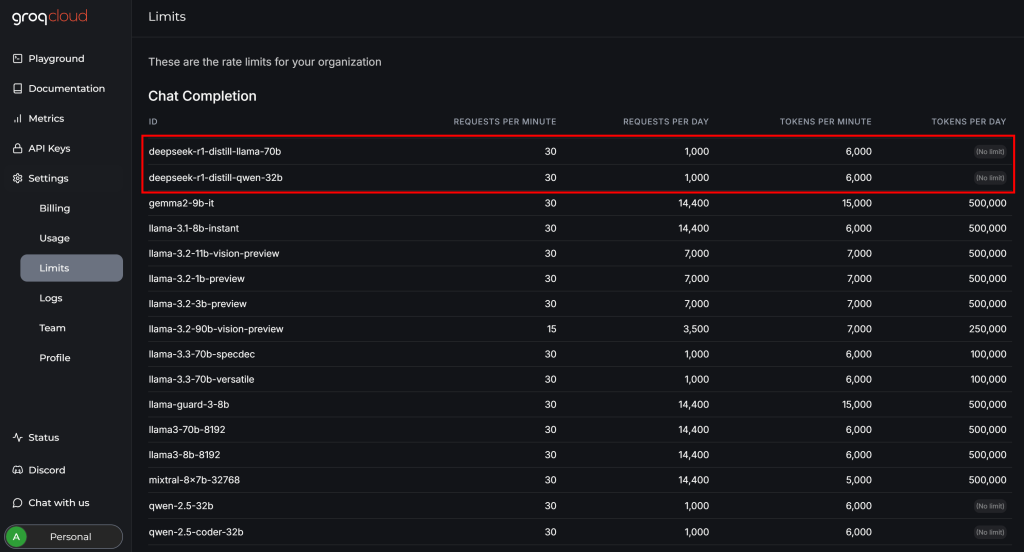
そこで、利用可能な2つのDeepSeekモデルには、無料プランで以下の制限があることがわかります:
- 毎分最大30リクエスト
- 1日あたり最大1,000リクエスト
- 毎分6,000メダル以下
最初の2つの制限はこの例では問題ないが、最後の制限は難題である。典型的なウェブページには数百万文字が含まれることがあり、これは数十万のトークンに相当する。
つまり、トークンの制限により、G2ページ全体をGroq経由でDeepSeekモデルに直接フィードすることはできません。この問題に対処するため、Crawl4AIではページの特定のセクションのみを選択することができます。ページ全体ではなく、それらのセクションがMarkdownに変換され、LLMに渡されます。セクションの選択プロセスはCSSセレクタに依存している。
選択するセクションを決定するには、ブラウザで対象ページを開きます。目的のデータを含む要素を右クリックし、「検査」オプションを選択します:
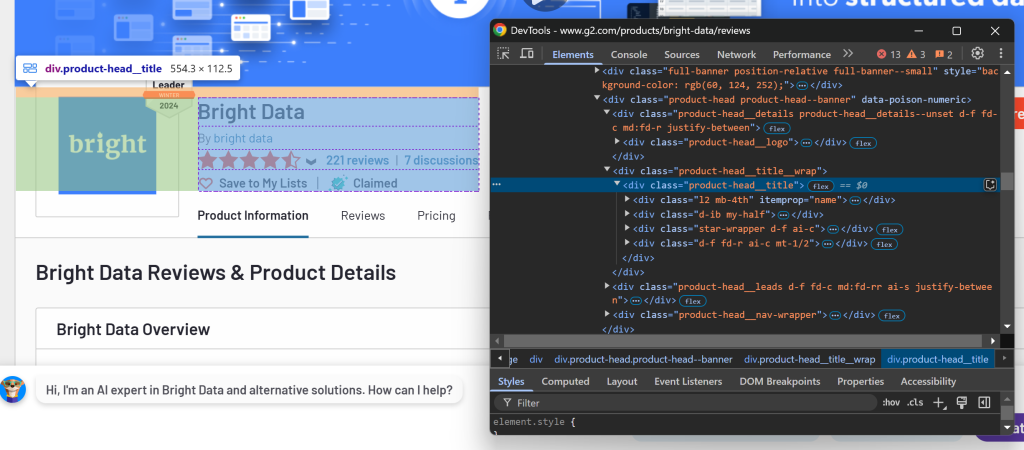
ここでは、.product-head__title要素に製品名/会社名、レビュースコア、レビュー数、クレームステータスが含まれていることがわかります。
次に、ロゴの部分を点検する:
この情報は、.product-head__logoCSSセレクタを使用して取得できます。
最後に、説明欄を点検する:
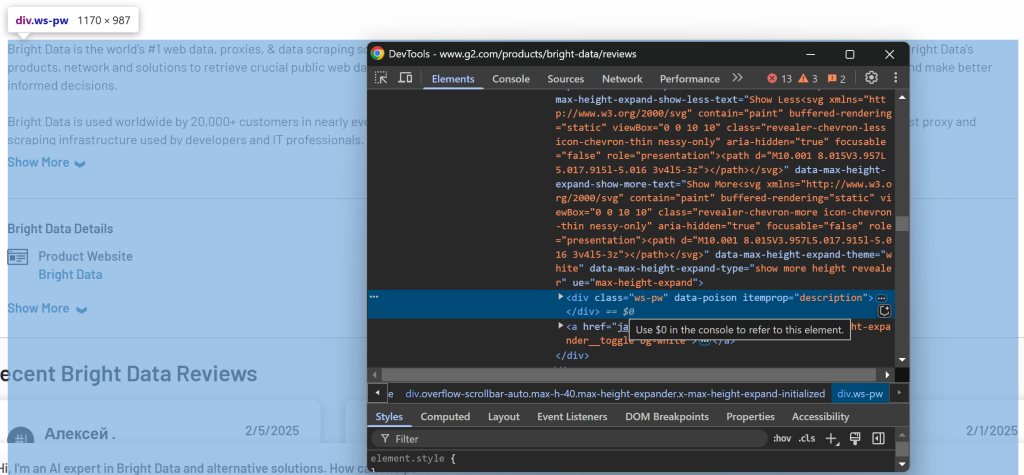
説明文は、[itemprop="description"]セレクタを使って利用できます。
これらのCSSセレクタをCrawlerRunConfigで以下のように設定する:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000,
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]", # the CSS selectors of the elements to extract data from
)もう一度scraper.pyを実行すると、次のようになります:
Response status code: 200
Parsed Markdown data:
[](https:/www.g2.com/products/bright-data/reviews)
[Editedit](https:/my.g2.com/bright-data/product_information)
[Bright Data](https:/www.g2.com/products/bright-data/reviews)
By [bright data](https:/www.g2.com/sellers/bright-data)
Show rating breakdown
4.7 out of 5 stars
[5 star78%](https:/www.g2.com/products/bright-data/reviews?filters%5Bnps_score%5D%5B%5D=5#reviews)
[4 star19%](https:/www.g2.cHTMLページ全体ではなく、関連するセクションのみを出力します。このアプローチではトークンの使用量が大幅に削減されるため、Groqのfree-tierの制限内に収めながら、目的のデータを効率的に抽出することができます!
ステップ#11:DeepSeek ベースの LLM 抽出ストラテジーの定義
Craw4AIは、LLMExtractionStrategyオブジェクトを通じて、LLMベースのデータ抽出をサポートしています。DeepSeekとの統合には、以下のように定義できます:
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)LLMモデルを指定するには、.envに以下の環境変数を追加する:
LLM_MODEL=groq/deepseek-r1-distill-llama-70bこれは、LLMベースのデータ抽出にGroqCloudのdeepseek-r1-distill-llama-70bモデルを使用するようにCraw4AIに指示する。
scraper.pyで、LLMExtractionStrategyと G2Productをインポートします:
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product次に、extraction_strategyオブジェクトをcrawler_configに渡す:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)スクリプトを実行すると、Craw4AIは次のようになる:
- Web Unlocker API プロキシ経由で対象の Web ページに接続します。
- ページのHTMLコンテンツを取得し、指定されたCSSセレクタを使って要素をフィルタリングする。
- 選択したHTML要素をMarkdown形式に変換します。
- データ抽出のために、フォーマットされた Markdown を DeepSeek に送信します。
- 指定されたプロンプト
(命令)に従って入力を処理し、抽出されたデータを返すように DeepSeek に指示します。
crawler.arun()を実行した後、以下のようにしてトークンの使用状況をチェックできる:
print(extraction_strategy.show_usage())そして、抽出されたデータにアクセスし、印刷することができます:
result_raw_data = result.extracted_content
print(result_raw_data)スクリプトを実行して結果を表示すると、次のような出力が表示されるはずだ:
=== Token Usage Summary ===
Type Count
------------------------------
Completion 525
Prompt 2,002
Total 2,527
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 525 2,002 2,527
None
[
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c07c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}
]出力の最初の部分(トークンの使用量)はshow_usage() からのもので、6,000 トークンの制限を十分に下回っていることが確認できます。次の結果データは、G2Productスキーマにマッチする JSON 文字列です。
本当に信じられない!
ステップ#12: 結果データの処理
前のステップの出力からわかるように、DeepSeek は通常、単一のオブジェクトではなく配列を返します。これを処理するには、返されたデータを JSON として解析し、配列から最初の要素を抽出します:
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]Python Standard Libraryからjsonをインポートすることを忘れないでください:
import jsonこの時点で、result_dataは G2Productのインスタンスになっているはずだ。最後のステップは、このデータをJSONファイルにエクスポートすることである。
ステップ #13: スクレイピングしたデータをJSONにエクスポートする
result_dataを g2.jsonファイルにエクスポートするにはjsonを使用する:
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)ミッション完了!
ステップ#14:すべてをまとめる
最終的なscraper.pyファイルには以下の内容が含まれるはずです:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
import os
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product
import json
# Load secrets from .env file
load_dotenv()
async def main():
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)
# LLM extraction strategy for data extraction using DeepSeek
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# Log the AI model usage info
print(extraction_strategy.show_usage())
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]
# Export the scraped data to JSON
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)
if __name__ == "__main__":
asyncio.run(main())そして、models/g2_product.pyに格納されます:
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolそして、.envにはある:
PROXY_SERVER=https://<WEB_UNLOCKER_API_HOST>:<WEB_UNLOCKER_API_PORT>
PROXY_USERNAME=<WEB_UNLOCKER_API_USERNAME>
PROXY_PASSWORD=<WEB_UNLOCKER_API_PASSWORD>
LLM_API_TOKEN=<GROQ_API_KEY>
LLM_MODEL=groq/deepseek-r1-distill-llama-70bでDeepSeek Crawl4AIスクレイパーを起動します:
python scraper.pyターミナルの出力は次のようになる:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 56.13s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 397ms
[LOG] Call LLM for https://www.g2.com/products/bright-data/reviews - block index: 0
[LOG] Extracted 1 blocks from URL: https://www.g2.com/products/bright-data/reviews block index: 0
[EXTRACT]. ■ Completed for https://www.g2.com/products/bright-data/reviews... | Time: 12.273853100006818s
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 68.81s
=== Token Usage Summary ===
Type Count
------------------------------
Completion 524
Prompt 2,002
Total 2,526
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 524 2,002 2,526
Noneまた、プロジェクトのフォルダにg2.jsonファイルが表示されます。それを開くと
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c7c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}おめでとうございます!ボットで保護されたG2ページから始め、Crawl4AI、DeepSeek、Web Unlocker APIを使用して、解析ロジックを1行も書くことなく、構造化データを抽出しました。
結論
このチュートリアルでは、Crawl4AIとは何か、そしてAIを搭載したスクレイパーを構築するためにDeepSeekと組み合わせて使用する方法を探りました。スクレイピングを行う際の大きな課題の1つはブロックされるリスクですが、Bright DataのWeb Unlocker APIを使用することでこれを克服することができました。
このチュートリアルで実証されているように、Crawl4AI、DeepSeek、Web Unlocker APIを組み合わせることで、特定の解析ロジックを必要とすることなく、あらゆるサイト(G2のように保護されているサイト)からデータを抽出することができます。これは、効果的なAI駆動型Webスクレイピングの実装を支援するBright Dataの製品やサービスがサポートする多くのシナリオの1つに過ぎません。
Crawl4AIと統合する他のウェブスクレイピングツールをご覧ください:
- プロキシサービス:400M+ monthly以上の家庭用IPを含む、場所制限を回避するための4つの異なるタイプのプロキシ
- ウェブスクレーパーAPI:100以上の人気ドメインから新鮮で構造化されたウェブデータを抽出するための専用エンドポイント。
- SERP API:SERPのすべての継続的なロック解除管理を処理し、1つのページを抽出するAPI
- スクレイピング・ブラウザ:Puppeteer、Selenium、Playwright互換のブラウザで、ロック解除アクティビティが組み込まれています。
今すぐBright Dataに登録し、プロキシサービスやスクレイピング製品を無料でお試しください!






