

完全に自動化されたニュースレターを発行できるとしたらどうだろう。n8n、Bright Data、OpenAIは、まさにこれを実現する力を与えてくれる。
今日は、このプロセスが本当に簡単であることをお見せしよう!
はじめに
まずはワークフローにアクセスすることから始めよう(無料で使い始めることができる)。彼の投稿の一番上にある “ワークフローを使う “というボタンをクリックする。プロンプトが表示されたら、必ずn8nのセルフホスト・インスタンスを実行してください。

セルフ・ホスティング n8n
sudo snap install dockerdockerを起動し、n8nを立ち上げる。
sudo docker volume create n8n_data
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nコミュニティ・ノードの設置
さて、いよいよコミュニティ・ノードをいくつかインストールしましょう。設定」から「コミュニティ・ノード」をクリックしてください。

npm “入力ボックスにBright Data nodeを入力します。
n8n-nodes-brightdata次に、Document Generatorも同じようにします。
n8n-nodes-document-generator
これらのノードをインストールしたら、ctrl+cでDockerインスタンスを終了させる。
その後、再起動する。
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nコミュニティ・ノードのインストールに関する完全なドキュメントはこちらをご覧ください。
APIキーの取得
ブライトデータ
もしまだなら、Web Unlockerにサインアップする必要がある。このツールは、CAPTCHAバイパスやプロキシ統合など、あらゆる種類のクールなスクレイピング機能を提供している。プレイグラウンドでは、APIキーを取得できる。

この鍵を持って、安全な場所に保存しておいてください。
オープンAI
OpenAI のダッシュボードから、API Keys タブで新しいキーを表示したり作成したりできます。

もう一度言うが、鍵は安全な場所に保管すること。
SMTP
SMTPにはElastic Emailを使っている。無料プランでは自分宛にしかメールを送れないが、このチュートリアルではこれで十分だ。
注:SMTP接続を作成する際にエラーに遭遇しました。SSLを無効にすると解決しました。

SMTPの場合、どのクライアント(Elastic Emailでもその他でも)を使う場合でも、ユーザー名、パスワード、接続の詳細を保存する必要があります。Elastic Emailの場合、ここでこれらの情報を見ることができます。

ワークフローの調整
Web Unlockerでサイトを取得する
ワークフローのBright Dataアイコンを右クリックし、”Open “をクリックします。鉛筆アイコンをクリックして設定を編集します。

Token」セクションにWeb Unlocker API Keyを追加します。

では、スキーマを調整して、すべてが正しく機能するようにしよう。設定の一番下で、フォーマットが “JSON “に設定されていることを確認する。下の画像では、urlがhttps://www.mediamarkt.de/、これをスクレイピングしたいurlに置き換えてください。ゾーン名をあなたのウェブアンロッカーのゾーン名に置き換えてください。

HTMLの抽出
では、HTML抽出が適切に設定されていることを確認しましょう。ソースデータ」が「JSON」に設定されていることを確認してください。抽出値は、以下の画像に表示されているものと一致する必要があります:キー:title, CSSセレクタ:title, 返り値:テキスト。異なるサイトで作業している場合は、ニーズに合わせてこれらのフィールドを調整できますが、ページに本文や タイトルがない場合は、いずれにせよスクレイピングする価値はないでしょう。

閉じる前に、スクロールダウンして、他のフィールドにもマッチさせてください:キー:body、CSSセレクタ:body、戻り値:テキスト。

ChatGPTにデータを渡す
ChatGPTはデータを解析してくれます。LLMの力を使えば、パーサーを書く必要すらありません。AIモデルによるスクレイピングについてはこちらをご覧ください。ChatGPTにウェブページを渡すと、きれいな商品リストを吐き出します。
さて、ChatGPT接続の設定です。カテゴリ別の案件リストを生成する」というノードの設定を開きます。Bright Data API キーを追加したのと同じように、OpenAI API キーを追加します。そして以下のフィールドが正しいことを確認してください:Resource:テキスト:Message a Model.別のモデルを使用したい場合は、自由に変更してください。

下までスクロールし、残りのフィールドが正しいことを確認する。

ChatGPTから結果を取り出す
次に、「結果から項目を抽出する」というタイトルのノードの設定を開きます。分割するフィールド」がmessage.content.resultsに設定されていることを確認する。

HTMLドキュメントの生成
さて、いよいよHTMLドキュメントの作成です。これが実際のメールを構成する生のHTMLです。ワークフローテストを実行すると、実際にHTMLテンプレートに入力値をドラッグ&ドロップすることができます。Template String “がExpressionに設定されていることを確認してください。

必要であれば、私のHTMLテンプレートを以下からコピー&ペーストしてください。以下のHTMLは必須ではありません。JSONデータを正しく挿入してください。
<h1>{{ $json.name }}</h1>
<p>{{ $json.description }}</p>
<a href={{ $('Generate List of Deals by Category').item.json.message.content.results[0].link }}>
{{ $('Generate List of Deals by Category').item.json.message.content.results[0].link }}
</a>
<h2>{{ $('Generate List of Deals by Category').item.json.message.content.results[1].name }}</h2>
<ul>
<li><p>{{ $('Generate List of Deals by Category').item.json.message.content.results[1].description }}</p></li>
<li>{{ $('Generate List of Deals by Category').item.json.message.content.results[1].price }}</li>
<li>
<a href={{ $('Generate List of Deals by Category').item.json.message.content.results[1].link }}>
{{ $('Generate List of Deals by Category').item.json.message.content.results[1].link }}
</a>
</li>
</ul>
<h2>{{ $('Generate List of Deals by Category').item.json.message.content.results[2].name }}</h2>
<ul>
<li><p>{{ $('Generate List of Deals by Category').item.json.message.content.results[2].description }}</p></li>
<li>{{ $('Generate List of Deals by Category').item.json.message.content.results[2].price }}</li>
<li>
<a href={{ $('Generate List of Deals by Category').item.json.message.content.results[2].link }}>
{{ $('Generate List of Deals by Category').item.json.message.content.results[2].link }}
</a>
</li>
</ul>
<h2>{{ $('Generate List of Deals by Category').item.json.message.content.results[3].name }}</h2>
<ul>
<li><p>{{ $('Generate List of Deals by Category').item.json.message.content.results[3].description }}</p></li>
<li>{{ $('Generate List of Deals by Category').item.json.message.content.results[3].price }}</li>
<li>
<a href={{ $('Generate List of Deals by Category').item.json.message.content.results[3].link }}>
{{ $('Generate List of Deals by Category').item.json.message.content.results[3].link }}
</a>
</li>
</ul>
<h2>{{ $('Generate List of Deals by Category').item.json.message.content.results[4].name }}</h2>
<ul>
<li><p>{{ $('Generate List of Deals by Category').item.json.message.content.results[4].description }}</p></li>
<li>{{ $('Generate List of Deals by Category').item.json.message.content.results[4].price }}</li>
<li>
<a href={{ $('Generate List of Deals by Category').item.json.message.content.results[4].link }}>
{{ $('Generate List of Deals by Category').item.json.message.content.results[4].link }}</a></li>
</ul>
<h2>{{ $('Generate List of Deals by Category').item.json.message.content.results[5].name }}</h2>
<ul>
<li><p>{{ $('Generate List of Deals by Category').item.json.message.content.results[5].description }}</p></li>
<li>{{ $('Generate List of Deals by Category').item.json.message.content.results[5].price }}</li>
<li>
<a href={{ $('Generate List of Deals by Category').item.json.message.content.results[5].link }}>
{{ $('Generate List of Deals by Category').item.json.message.content.results[5].link }}
</a>
</li>
</ul>電子メールによるユーザーへの通知
いよいよSMTPサーバーに接続します。まだAPIキーを追加していない場合は、「鉛筆」アイコンをクリックして接続の詳細を編集します。From Email “を送信元のメールに変更します。件名 “はお好きなものに変更してください。Email Format “は必ずHTMLのままにしてください。

SMTPアカウントに認証情報を追加します。ユーザー、パスワード、ホスト、ポートが必要です。

ユーザーに成功を知らせる
では、すべての完了をユーザーに伝えるページを作りましょう。完了メッセージ」と「完了タイトル」を好きなように変更してください。これらの他のフィールドはすべて同じままにしておいてください–単にプロセスが終了したことをユーザーに知らせるだけなのですから。

結果のEメール
すべての設定が終わったので、試してみよう。”ワークフローのテスト “をクリックしてください。このようなポップアップが表示されるはずです。カテゴリーを選択し、お得な情報を受け取るためのメールアドレスを入力します。
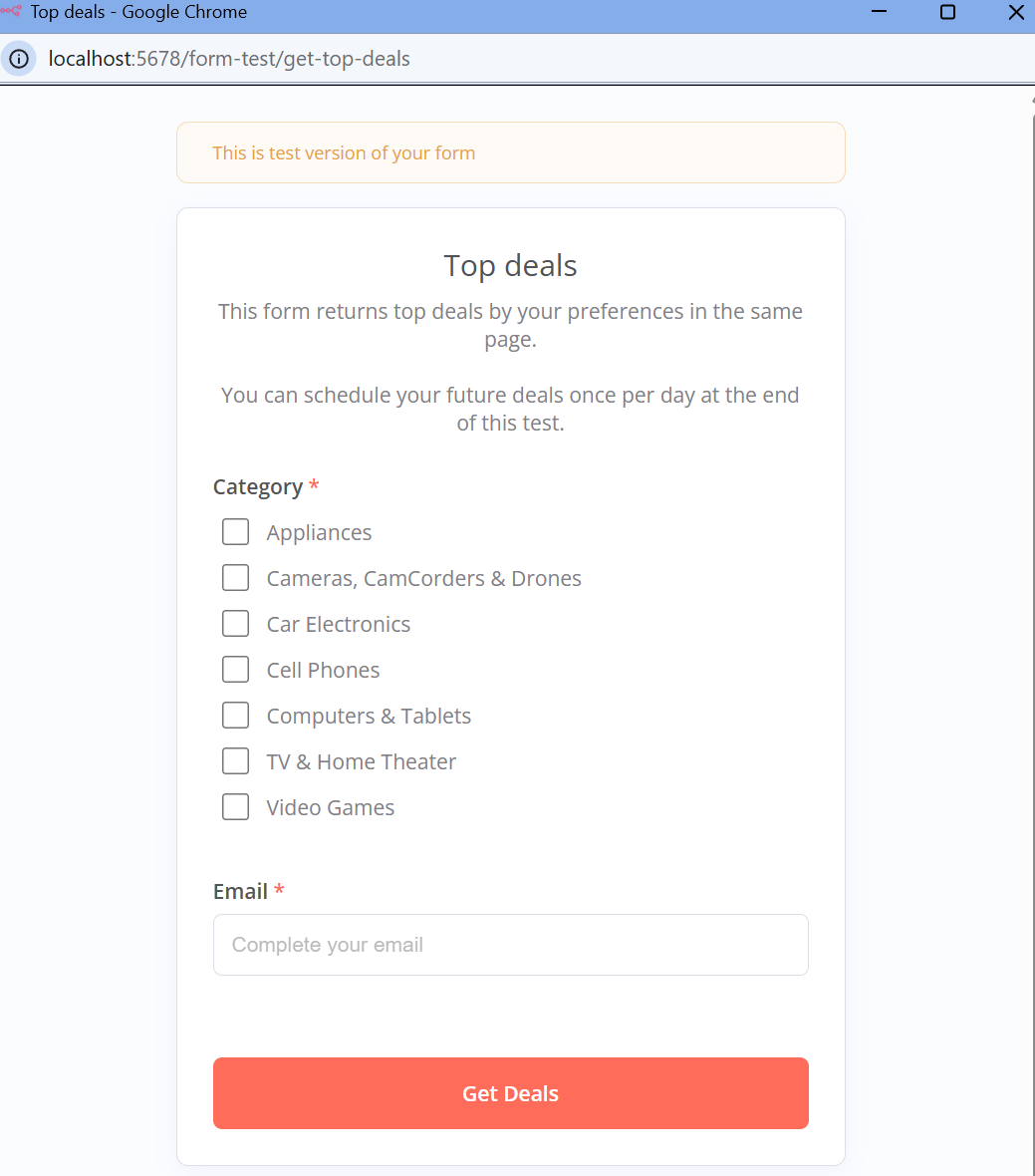
お得な情報を入手する」をクリックします。情報を送信すると、ポップアップがこのように表示されます。

最後に、受信トレイをチェックしてください。お得なメールがすぐに表示されない場合は、迷惑メールフォルダを見てみよう。最近のメールサービスのほとんどは、このような大量メールをスパムとしてマークします。メールを見つけたら、開いてお得な情報を見てみましょう!

結論
n8n、Bright Data、OpenAIにより、スマートでデータドリブンなニュースレターを完全に自動化するツールが揃いました。データ抽出にWeb Unlocker、コンテンツ生成にChatGPT、Eメール配信にSMTPを活用することで、最小限の労力でパーソナライズされたおすすめ案件を作成できます。
しかし、なぜここで止まるのでしょうか?ブライト・データは、自動化をさらに強化するためのデータ・ソリューション・スイートを提供しています:
- レジデンシャル・プロキシ
- スクレイピング・ブラウザ
- スクレイパーAPI
- データセット
メールマーケティングオートメーションを次のレベルへ。今すぐ無料トライアルに登録して、よりスマートで効率的なワークフローの構築を始めましょう!





