

このガイドで、あなたは学ぶだろう:
- DifyがAIエージェントを構築するための強力なプラットフォームである理由。
- AIエージェントにウェブ検索機能が不可欠な理由。
- Difyでウェブを検索できるAIエージェントを作る方法。
さあ、飛び込もう!
Difyでエージェント型ワークフローオートメーション開発を解き明かす
Difyは、LLMアプリケーションの作成を簡素化するために設計された、革新的なローコード/ノーコードプラットフォームです。クラウド版でもオープンソース版でも使用でき、エージェント型ワークフローをサポートしています。
直感的なビジュアルエディターを提供し、複雑なAIロジックをドラッグ&ドロップで簡単に構築・管理することができます。Difyは、プロプライエタリなものからオープンソースまで、幅広いLLMに対応しており、プロジェクトに最適なモデルを柔軟に選択することができます。
BaaS(Backend-as-a-Service)として機能し、AIのインフラをあなたの代わりに処理する。さらに、その機能をさらに向上させるための拡張機能やプラグインもサポートされている。サードパーティとの統合により、AIアプリケーションの機能拡張への道が開けます。
AIエージェントがウェブ検索を可能にすべき理由
AIエージェントがウェブを検索する能力は、インテリジェントで最新の応答を実現するための基本的な必要条件である。ChatGPTやGeminiのような初期のLLMは、しばしば最新の情報やニッチな情報を提供することに苦労した。それは、学習データの静的な性質によって制限されていたからだ。
その精度が飛躍的に向上したのは、まさにウェブ検索ができるようになってからである。

この機能により、LLMは幻覚を減らすために知識ベースを拡大することを最終目標として、必要に応じて情報を引き出すことができる。
同時に、LLMのために組み込まれたウェブ検索機能は、通常、有料モデル専用である。さらに、単に「ウェブを検索する」だけでは十分ではありません。インターネット・データの膨大な量と未検証の性質が、不正確な結果や無関係な結果につながる可能性があるからだ。
真の力は、Google、Bing、DuckDuckGoなどの信頼できる検索エンジンから直接、信頼され検証されたSERP(検索エンジンの結果ページ)データにアクセスできることにあります。そのデータは、厳格な品質チェックを含む洗練されたランキングアルゴリズムによって形成されています。
その結果、SERPデータは、AIエージェントが情報を合成し、十分な情報に基づいた応答を生成するための、はるかに信頼できる基盤を保証する。AIにおける一般的なユースケースが、SERPデータを活用したRAGベースのチャットボットの構築である理由はここにある。
Dify AIエージェントのワークフローにSERPデータを提供するには、Bright Data Difyプラグインを使用します。このプラグインが提供するツールの中に、”Search Engine“というものがある。これは、Bright Data SERP APIに接続することで、Google、Bing、Yandex、その他の主要な検索エンジンの検索結果をリアルタイムで配信します。
この統合のおかげで、ノーコードのAIエージェントは、信頼できる検索エンジンの信頼性の恩恵を受けながら、広大なウェブを利用することができます。
Difyでウェブ検索できるAIエージェントを作る:ステップ・バイ・ステップのチュートリアル
このガイドセクションでは、AIエージェントのワークフローを構築します:
- キーフレーズを入力として受け付ける。
- Bright Dataプラグインの “Search Engine “ツールを使って、そのキーワードでGoogleを検索します。
- 検索結果をLLMで処理する。
このプロセス全体は完全にビジュアル化されており、コーディングは必要ありません。簡単なドラッグ&ドロップのインターフェースで各ノードを接続し、AIエージェントに命を吹き込みます。
それでは、Bright Dataを活用したWeb検索AIワークフローをDifyでノーコードで構築してみましょう!
前提条件
このチュートリアルに沿ってDifyでウェブ検索AIエージェントを構築するには、以下のものが必要です:
- Difyのアカウント(無料プランで十分です)。
- Bright Data APIキー。
まだお持ちでない方は、上記のリンクからセットアップ手順に従ってください。
注:本番環境で使用するには、LLMプロバイダー(OpenAI、Anthropic、Geminiなど)のAPIキーも必要です。
ステップ#1: DifyでLLMインテグレーションを設定する
DifyでLLMを使用するには、まずLLMとの統合を設定する必要があります。まず、プロフィール画像をクリックし、”設定 “を選択します:

次に、”Model Provider “ページに移動します。ここでは、例えば、OpenAI プロバイダ・プラグインをインストールすることができます:
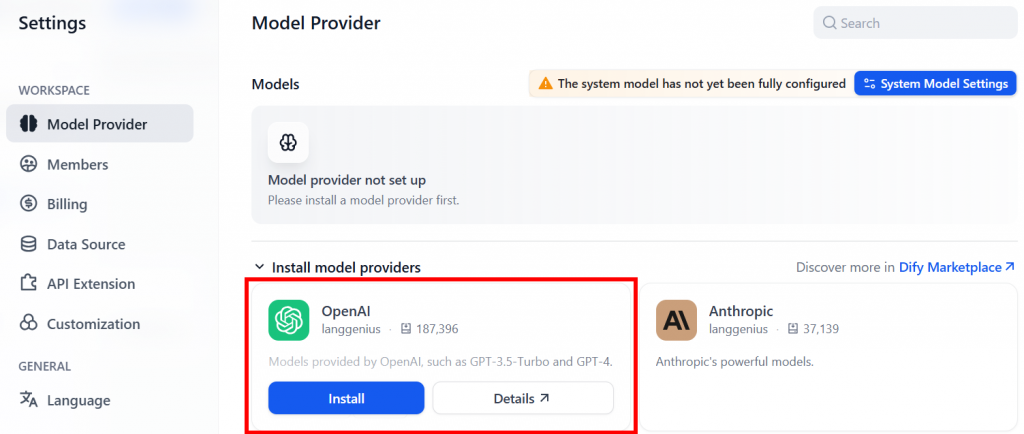
デフォルトでは、無料のメッセージクレジットは200です。この制限を解除するには、プラグインをインストールした後、OpenAIのAPIキーを追加してOpenAIの設定を行います:
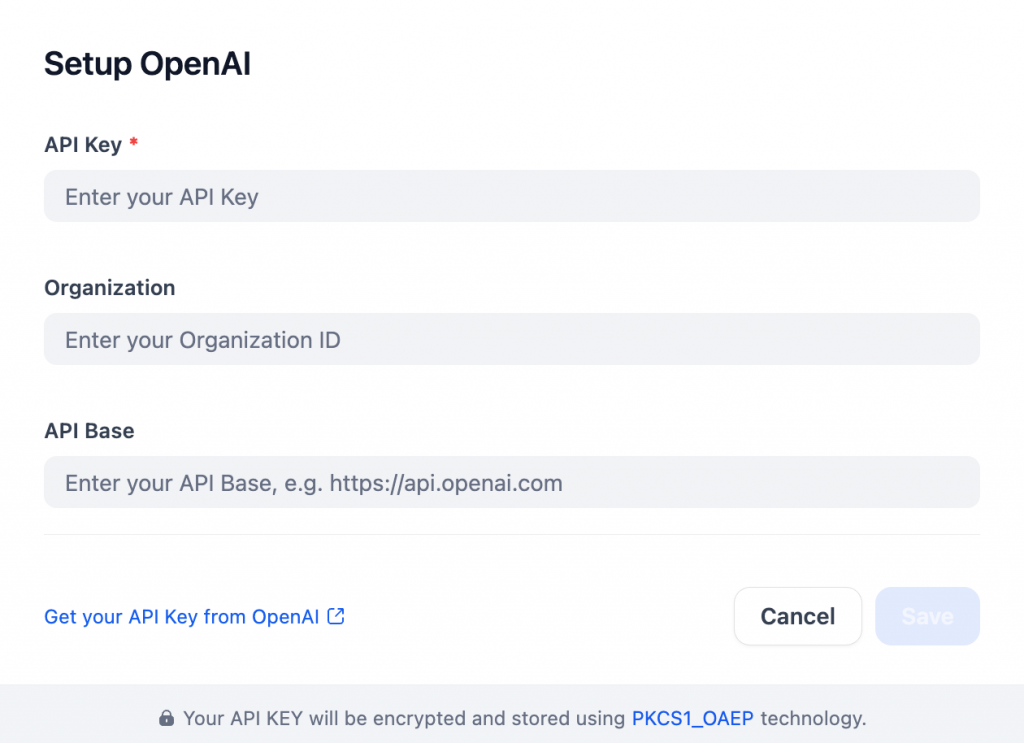
あるいは、無料で恒久的なLLM統合を行うには、Gemini LLMプロバイダーの利用を検討しよう。Flash 2.0のように、API経由でも無料で利用できるGeminiモデルもある。
素晴らしい!これで、ウェブ検索機能を備えたDify AIワークフローの構築を開始する準備が整いました。
ステップ2: Bright Dataプラグインのインストール
GitHubリポジトリのBright Dataプラグインのリリースページにアクセスし、brightdata_plugin.difypkgというファイルをダウンロードしてください。
Difyにインストールするには、”PLUGINS “をクリックしてプラグインマーケットプレイスを開き、”Install from Local Package File “を選択します:
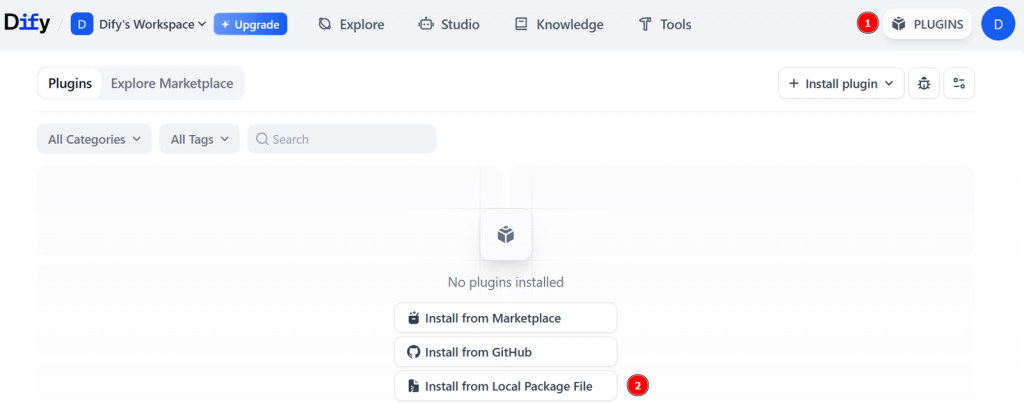
先ほどダウンロードしたローカルの.difypkgファイルを選択し、「インストール」ボタンをクリックしてください:

以上です!これでBright DataプラグインがDifyにインストールされました。
ステップ3:新しいDifyアプリケーションの考案
これで、すべての設定が完了し、AIエージェントの構築を開始する準備ができました。Difyワークスペースのホームページから、”Create from Blank “を選択し、新しいアプリケーションを作成します:

次に、アプリケーションの種類として「ワークフロー」を選択し、AIアプリケーションに名前を付けて「作成」をクリックします:

これにより、新しい空白のワークフローキャンバスが生成される:
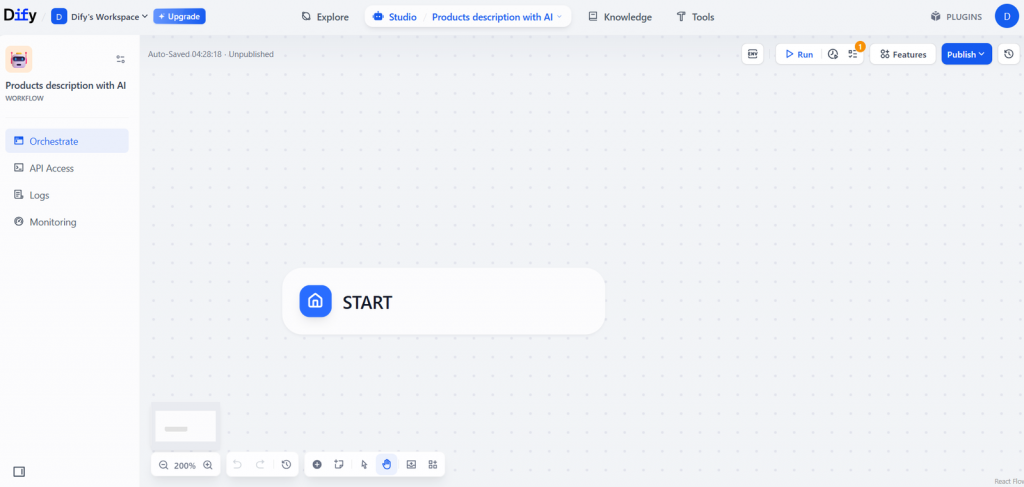
ノーコードAIエージェントを構築する前に、エージェントが何をすべきか、どのノードが必要かを概説します。このチュートリアルでは、以下のノードを使ったシンプルな4ステップのワークフローで目標を達成することができます:
- 入力変数(キーフレーズ)を定義する「Start」ノード。
- そのキーワードを使ってウェブを検索する「サーチエンジン」ノード。
- 検索結果を分析し、カスタムプロンプトを使用して有用な洞察を抽出する「LLM」ノード。
- AIが作成した最終レポートを表示する「End」ノード。
素晴らしい!あなたのウェブ検索AIワークフローをDifyに実装する時が来ました。
ステップ4: “Start “ノードの設定
まず “Start “ノードをクリックし、”INPUT FIELD “を選択する:
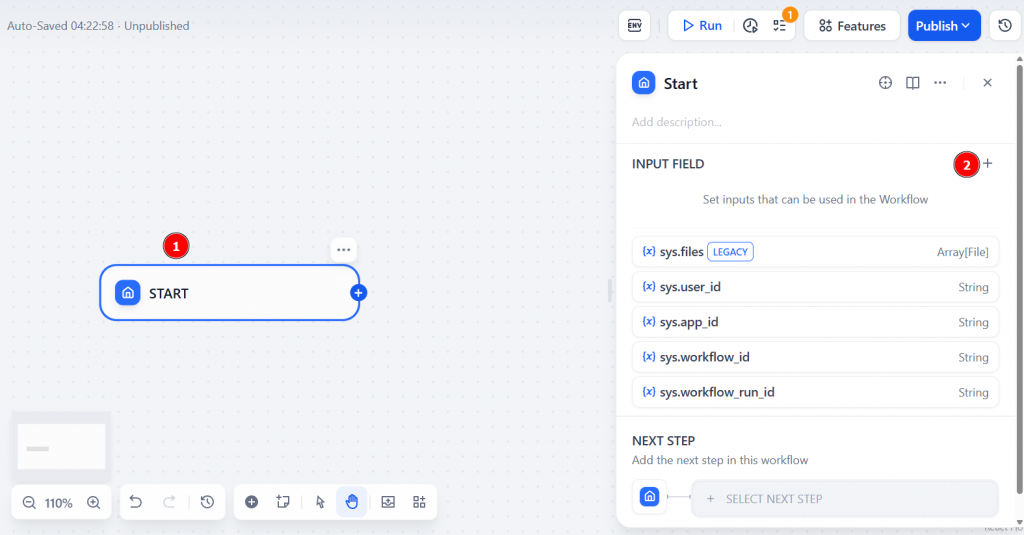
入力として短いテキスト・クエリを入力するので、「フィールド・タイプ」を「ショート・テキスト」に設定する。入力フィールドにsearch_topic と名前をつけます。これは、AIエージェントがウェブ検索を実行するために使用するキーワードを表します。
保存」をクリックして確認する:

良かった!これで “Start “ノードが正しく設定されました。
ステップ#5:「検索エンジン」ノードの統合
Start “ノードから “+”アイコンをクリックします。ツール」→「Bright Data Web Scraper」→「検索エンジン」と進みます:
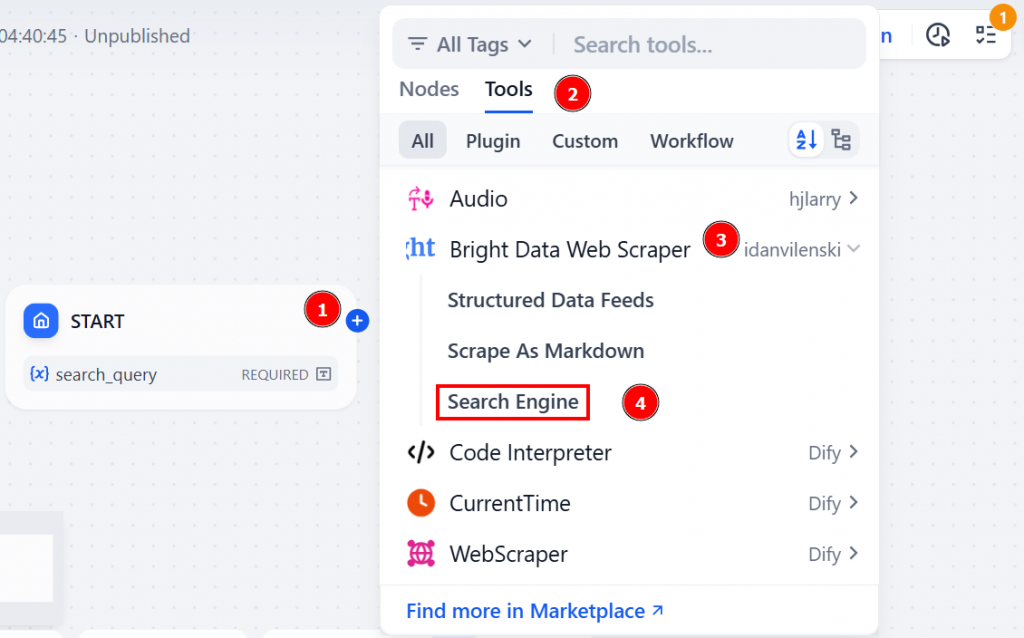
このBright Dataプラグインノードは、DifyワークフローとBright Data AIインフラストラクチャの橋渡しをします。特に、”Search Engine “ツールは、AIエージェントがウェブから直接リアルタイムの検索結果を取得することを可能にします。
Authorize」をクリックし、Bright Data APIトークンを入力してください:
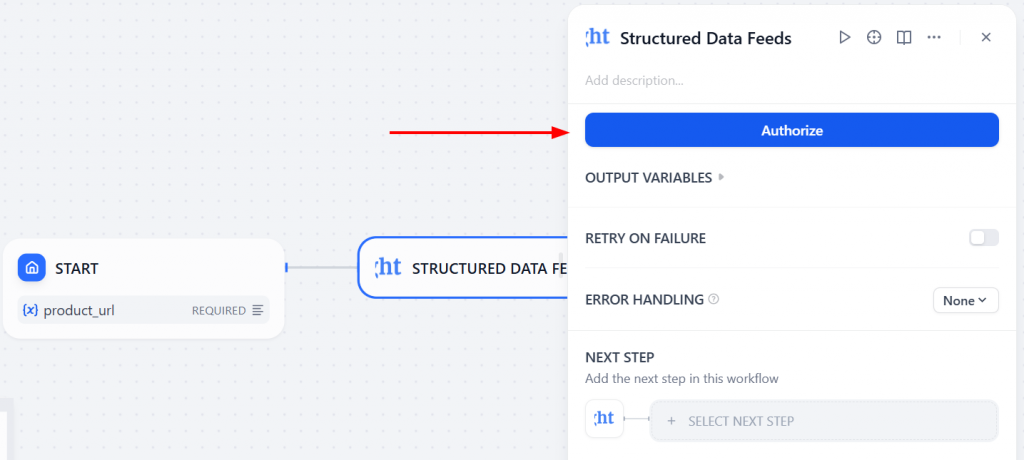
認証されると、Bright Dataプラグインがお客様のアカウントに接続されます。
ここで、先ほど設定した入力変数を渡す。Search Query “フィールドに”/”を入力して利用可能な変数を表示し、search_topicを選択する。Search Engine “ノードは、ユーザー入力に基づいてライブ・ウェブ検索を実行する:

最後に、”SEARCH ENGINE “ドロップダウンで、使用する検索エンジンを選択します(このチュートリアルでは、Googleを使用します):
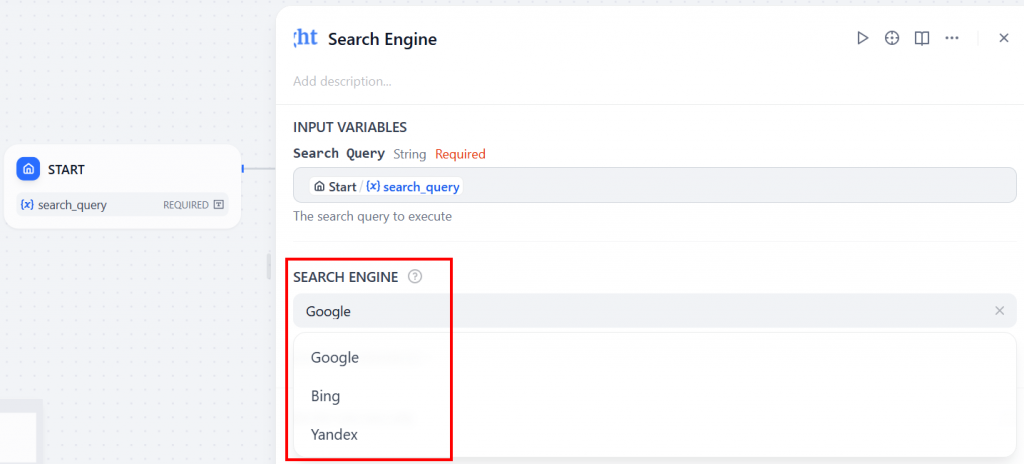
素晴らしい!Bright Dataの “Search Engine “ノードが設置された。
ステップ#6:「LLM」ノードの追加
サーチエンジン」ノードから「+」アイコンをクリックし、「LLM」ノードを選択する:

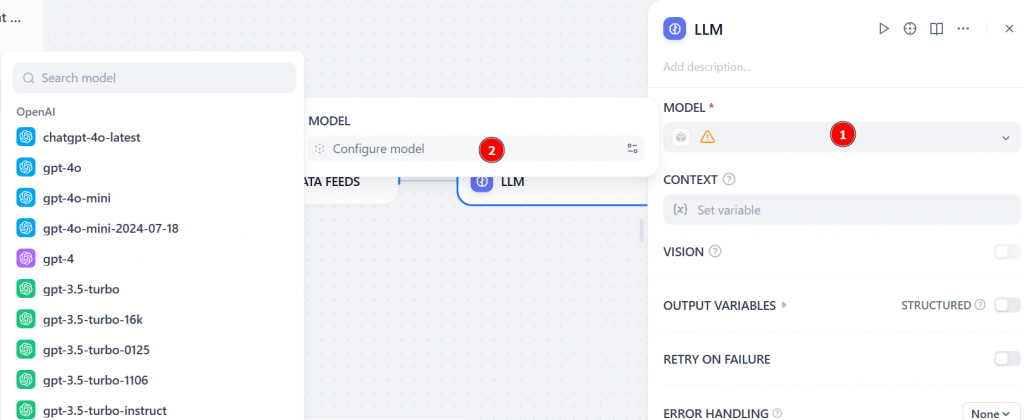
MODEL “セクションで “Configure model “をクリックし、リストからLLMを選択する(例えばgpt-4):
SYSTEM」セクションに、以下のようなプロンプトを入力する:
You are an expert SEO analyst. You have been given data containing the results from a Google search.
Based on this information, please report on the following:
- Common Talking Points: What are the most common themes and keywords you see repeated in the search result titles and descriptions?
- Dominant Content Types: Based on the titles, what kind of articles seem to be ranking? (e.g., "What is...", "Top 10...", "Beginner's Guide...", "Vs...").
Also, report the URLs.
Search Results Data:
{{Search_engine.text}}このプロンプトは、LLMに次のように指示する:
- サーチエンジン」ノードが返す検索結果を分析する。
- 繰り返されるテーマ、人気のあるコンテンツフォーマット、関連するURLを抽出し、SEOアナリストとして機能します。
注:変数{{Search_engine.text}}は、”Search Engine “ノードからのテキスト出力を直接LLMプロンプトに渡します。つまり、LLMは “Search Engine “ノードが返すリアルタイムのウェブ検索データにアクセスできる。
以下は「LLM」ノードのコンフィギュレーションである:
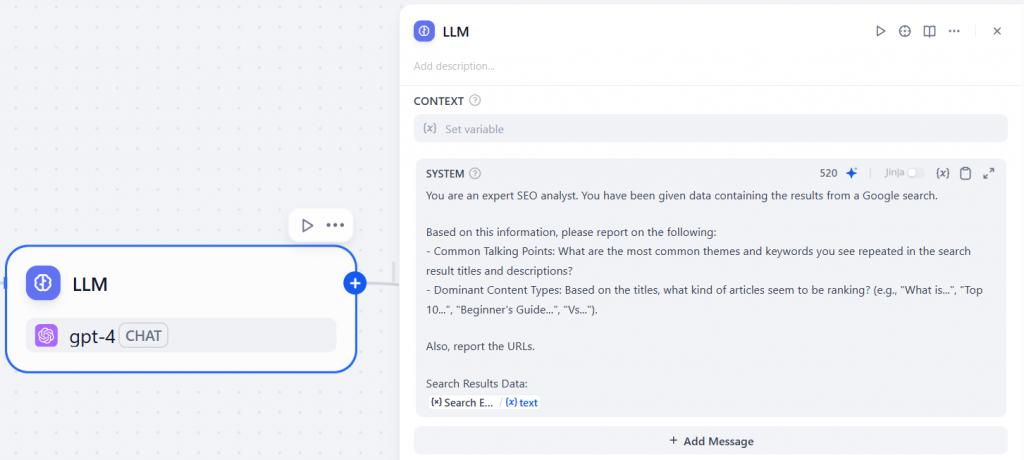
素晴らしい!あとはワークフローに最後のノードを追加するだけだ。
ステップ#7:「終了」ノードでAIワークフローを確定する
End “ノードを追加してワークフローを完成させる:

このノードは、LLMによって生成された最終出力を返す。その動作を設定するには、”OUTPUT VARIABLE “セクションをクリックし、LLMノードからテキスト変数を選択します:
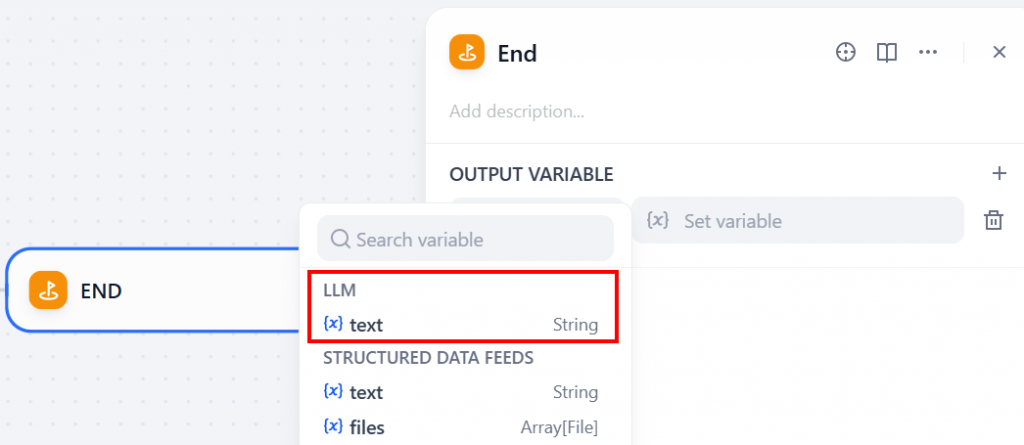
この設定により、LLMからの最終レスポンス(ライブ検索エンジンの結果に基づく)が、ワークフロー全体の出力として返されるようになります。
ステップ#8: AIウェブ検索ワークフローの実行
ブライトデータの “検索エンジン “ツールを利用した、Difyでの最後のウェブ検索AIワークフローです:
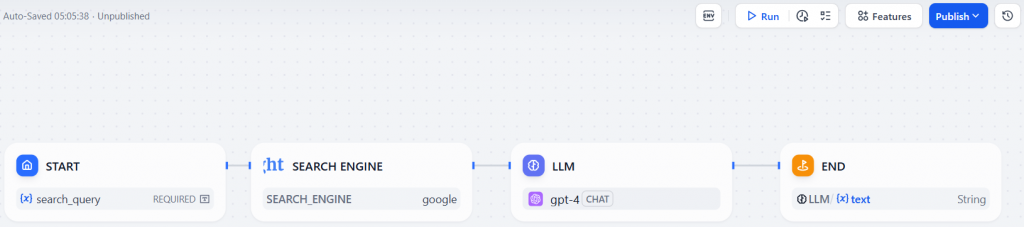
ワークフローを実行するには、”Run “ボタンをクリックする。search_topic の入力フィールドに、調査したいトピックを入力する(例:“new AI protocols“)。そして、”Start Run “を押してエージェントを起動する:
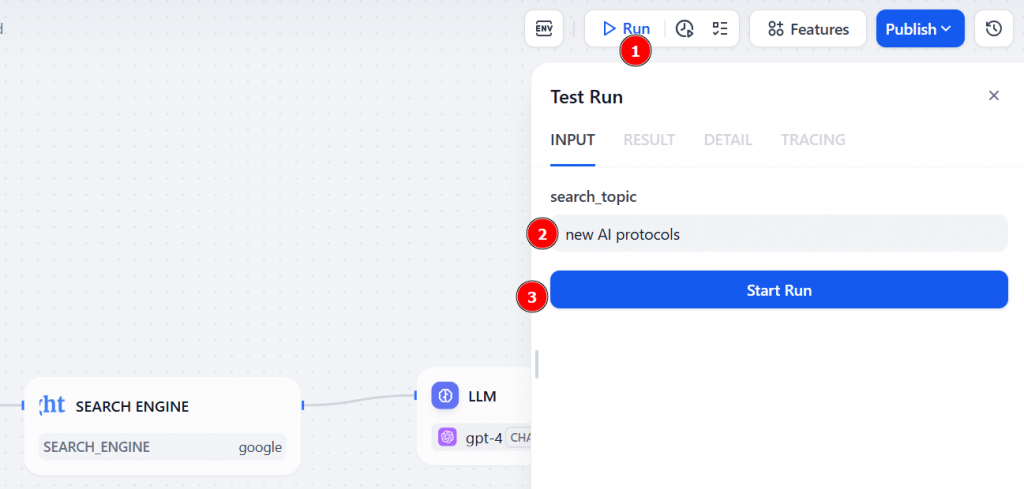
ワークフローが開始される。Bright DataノードがライブでGoogle検索を実行し、LLMノードがその結果を受け取り、指示に従ってサマリーを生成する。
最終的な出力は「結果」タブに表示される。以下のように表示される:

以下はその結果である:
Common Talking Points: The most frequently mentioned themes and keywords in the search results are "AI protocols", "Model Context Protocol (MCP)", "Agent2Agent (A2A) protocol", "Agent Communication Protocol (ACP)", "AI integration", "AI agent communications", "non-deterministic behavior", "secure, two-way connections", "data sources", and "AI-powered tools". These terms suggest a focus on new methodologies and standards in AI technology, particularly in terms of communication and integration.
Dominant Content Types: The search results seem to include a mix of explanatory articles, guides, and news updates. There are multiple "What is..." type articles, explaining terms like MCP, A2A, and ACP. "A developer's guide to AI protocols..." and "What Every AI Engineer Should Know About A2A, MCP &..." are examples of guide-type articles, while titles like "Introducing the Model Context Protocol Anthropic" and "AI Will Be Governed by Protocols No One Has Agreed on yet" suggest news updates or announcements.
URLs:
1. https://www.anthropic.com/news/model-context-protocol
2. https://www.infoworld.com/article/4007686/a-developers-guide-to-ai-protocols-mcp-a2a-and-acp.html
3. https://www.businessinsider.com/ai-protocol-rules-future-2025-6
4. https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html
5. https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/
6. https://hackernoon.com/mcp-a2a-agp-acp-making-sense-of-the-new-ai-protocols
7. https://www.youtube.com/watch?v=rmphqjsc4Po
8. https://www.youtube.com/watch?v=CQywdSdi5iA
9. https://www.youtube.com/watch?v=TQXG4r0U2PQ
10. https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/
11. https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
12. https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source指示通り、LLMモデルはあなたが促した通りの結果を報告した:
- モデルコンテキストプロトコル(MCP)」や「エージェントツーエージェント(A2A)プロトコル」など、共通のトーキングポイントを特定。
- 開発者ガイドや情報記事など、支配的なコンテンツタイプを強調。
- さらに読むための関連URLを記載。
出来上がり!あなたは、リアルタイムの情報をウェブで検索し、カスタムインサイトを提供できるAIエージェントの構築に成功した。
結論
この記事では、Difyを使ってWeb検索が可能なノーコードAIワークフローを構築する方法を学びました。この機能は、Bright Data Difyプラグインのおかげで実現しました。このプラグインは、主要な検索エンジンからリアルタイムのSERPデータを取得する「検索エンジン」ツールを提供します。
これは一例に過ぎないが、他にも多くの使用例が考えられる。特定のAIワークフローの目標に関係なく、効果的なエージェントは、ウェブデータを取得、検証、変換するためのツールを利用する必要があります。これこそが、ブライト・データのAIインフラストラクチャが提供するものです。
無料のBright Dataアカウントを作成し、今すぐAI対応データツールの実験を始めましょう!





