

この記事では以下の内容を学びます:
- データ検証とは何か、いつ使用すべきか、含まれるチェック項目、実装に利用すべきライブラリについて。
- – 実際のPython例を用いたデータ検証の実行方法
- データ検証とは何か、その仕組み、検証チェックの例、および最適なアプローチ。
- 専用AIエージェントを用いたデータ検証の実装方法。
- データ検証とデータバリデーションを比較した要約表。
さあ、始めましょう!
データ検証:知っておくべきすべてのこと
データ検証とデータ検証の旅を始めるにあたり、最初のアプローチであるデータ検証を探求しましょう。
データ検証とは何か、なぜ重要なのか?
データ検証とは、データの正確性、品質、完全性を確認するプロセスです。通常、データが保存、使用、または処理される前に実施されます。その究極の目的は、一貫した品質と信頼性を保証することです。
特にこの手法は、データが定義されたルールや基準に従っていることを検証します。これにより、誤った情報や不完全な情報がシステム、アプリケーション、ワークフローに流入したり、データパイプラインを通過し続けるのを防ぎます。
データ検証は、高いデータ品質を維持するための基礎です。また、GDPR準拠やCCPAなどのコンプライアンス要件を満たし、セキュリティのベストプラクティスに従う上でも重要な役割を果たします。
データ検証を適用することで、データのエラーや問題を早期に発見できます。これにより、データライフサイクルにおける問題を深刻化する前に特定し、コストのかかるミスや深刻な問題の発生を防ぐことができます。
データ検証チェックの例
適用可能なデータ検証チェックは無数に存在し、具体的なニーズ、データフィールドの種類、特定のシナリオによって異なります。最も重要なチェックには以下が含まれます:
- データ型チェック:フィールドに入力されたデータが正しい型であることを確認します(例:
年齢フィールドが数字のみを受け入れることを保証)。 - フォーマットチェック:データが特定のパターン(例:電話番号フォーマット
「(XXX) XXX-XXXX」、日付フォーマット「YYYY-MM-DD」、メールアドレスフォーマット「[email protected]」)に準拠していることを検証します。 - 範囲チェック:数値が事前定義された最小値と最大値の範囲内にあることを保証します(例:
スコアフィールドは0から100の間でなければなりません)。 - 存在チェック:必須フィールドが空白またはNULLになっていないことを確認し、重要な情報が欠落していないことを保証します。
- コードチェック:入力値が事前定義された許容値リスト(例:ISO 3166リストの国コード)から選択されていることを検証します。
- 整合性チェック:同一エントリー内の複数フィールド間、または異なるエントリー間でデータが論理的かつ一貫していることを検証します(例:注文日は配送日より前である必要があります)。
- 一意性チェック:従業員IDやメールアドレスなど一意の値を必要とするフィールドでの重複入力を防止します。
実施タイミング
経験則として、データ検証はデータライフサイクル全体を通じて継続的に実施すべきです。同時に、検証が早い段階で行われるほど、エラーの拡散を効果的に防止できます。これはデータ品質における「シフトレフト」アプローチとして知られています。
したがって、データ検証が最も効果的かつ効率的なタイミングは入力時点です。ここでエラーを捕捉すれば、不良データがシステムに流入するのを防ぎ、後工程のクレンジングにかかる時間とリソースを節約できます。これはユーザー入力データ(フォームやファイルアップロード経由)、ウェブスクレイピングで取得したデータ、完全に信頼できない公開リポジトリからのデータにも適用されます。
バックエンドシステムのAPI経由など、ユーザーが提出するデータの場合、リアルタイム検証により即時フィードバックが可能となります(例:形式が不正なメールアドレスや不完全な電話番号を、APIレスポンス内で直接400 Bad Requestエラーとしてフラグ付け)。
ただし、データを即時検証できるとは限りません。例えばETL/ELTパイプラインでは、検証は通常以下の段階で適用されます:
- 抽出後:ソースシステムから取得したデータが転送中に破損または紛失していないことを確認します。
- 変換後:各変換ステップ(集計など)の出力が期待されるルールや基準を満たしていることを検証するため。
データが保存された後も、定期的に再検証すべきです。データは更新・強化・再利用されるため静的ではないからです。したがって継続的な検証が必要です。
データの検証方法
データ検証プロセスには以下のステップが含まれます:
- 要件定義:ビジネスニーズ、規制基準、期待値に基づき明確な検証ルールを確立する(例:データのスキーマとルールを定義)。
- データの収集:ウェブスクレイピング、API、データベースなど、様々なソースからデータを収集します。
- 検証の適用:定義したルールを実装し、データの正確性、一貫性、完全性をチェックします。
- エラー処理:組織のポリシーに従い、無効なレコードをログ記録、隔離、または修正する。ユーザーが誤ったデータを入力した際には明確なフィードバックを提供する。
- データロード:検証済みでクリーンなデータをデータウェアハウスなどの対象システムにロードする。
注:次の章では、ガイド付きPython例を通じてこれらのステップの適用方法を確認します。
データ検証用ライブラリ
以下は、データ検証に最適なオープンソースライブラリの一部をまとめた表です:
| ライブラリ | プログラミング言語 | GitHubスター数 | 説明 |
|---|---|---|---|
| Pydantic | Python | 25.3k+ | Pythonの型ヒントを用いたデータ検証 |
| Marshmallow | Python | 7.2k+ | 複雑なオブジェクトを単純なPythonデータ型に変換する軽量ライブラリ |
| Cerberus | Python | 3.2k+ | Python 用の軽量で拡張可能なデータ検証ライブラリ |
| jsonschema | Python | 4.8k | Python 向け JSON Schema 仕様の実装 |
| Validator.js | JavaScript | 23.6k+ | 文字列の検証およびサニタイズを行うライブラリ。 |
| Joi | JavaScript | 21.2k+ | JS 向けの最も強力なデータ検証ライブラリ |
| Yup | JavaScript | 23.6k+ | 超シンプルなオブジェクトスキーマ検証 |
| Ajv | JavaScript | 14.4k | 最速の JSON スキーマ検証ツール。JSON Schema draft-04/06/07/2019-09/2020-12 および JSON Type Definition (RFC8927) をサポート |
| FluentValidation | C# (.NET) | 9.5k+ | 強力な型付き検証ルールを構築するための人気の.NET検証ライブラリ |
| validator | Go | 19.1k+ | Go 構造体およびフィールドの検証(クロスフィールド、クロス構造体、マップ、スライス、配列のダイビングを含む) |
Pythonでデータ検証を適用する方法:ステップバイステップの例
このガイド付きチュートリアルでは、Pydanticを使用してJSON入力データにデータ検証を適用する方法を学びます。このチュートリアルでは、データ検証プロセスを構築する主な側面をカバーします。
シナリオの説明
あるeコマースサイトからデータを取得していると仮定します。特に、以下の商品ウェブページに注目してください:
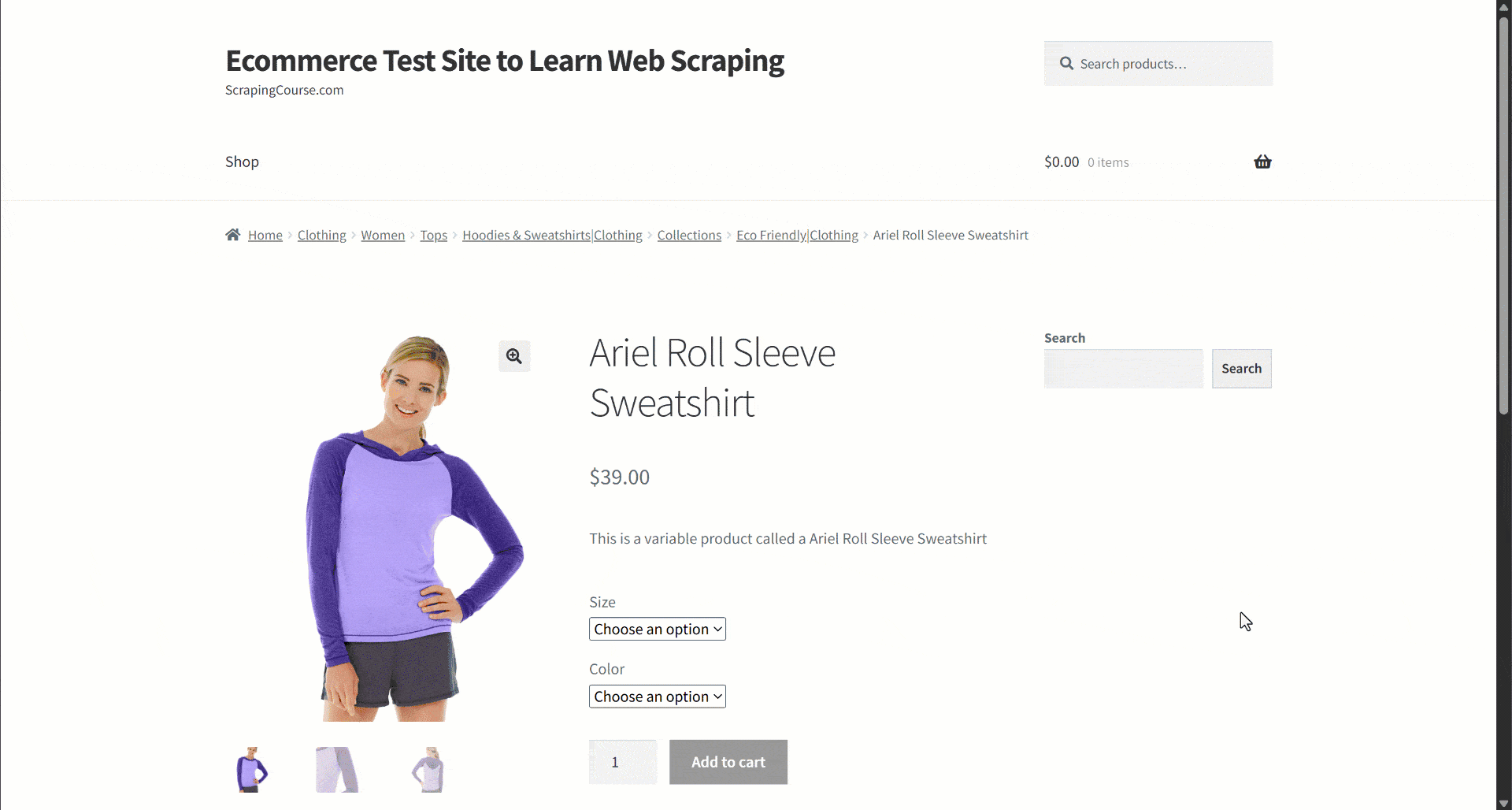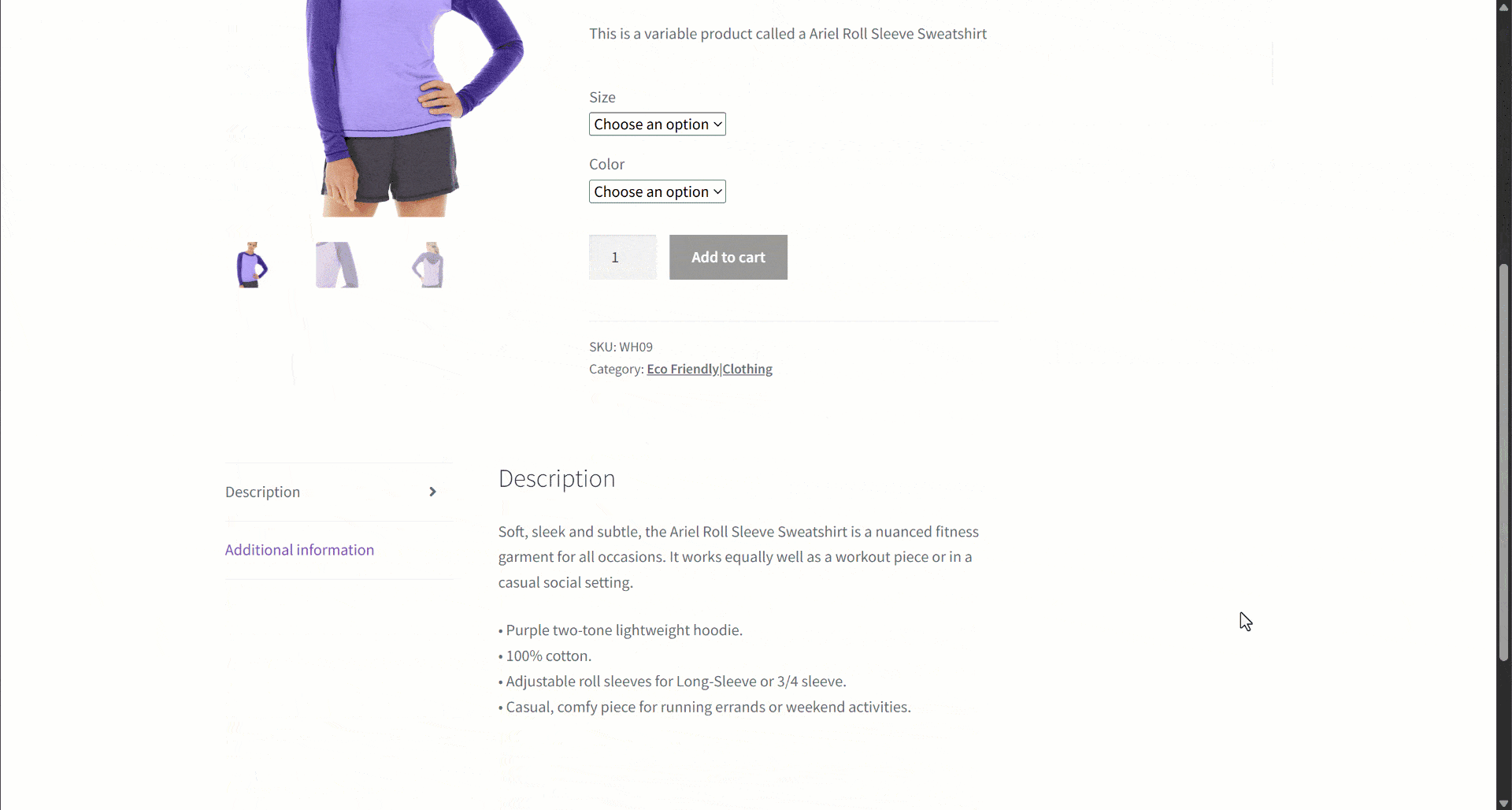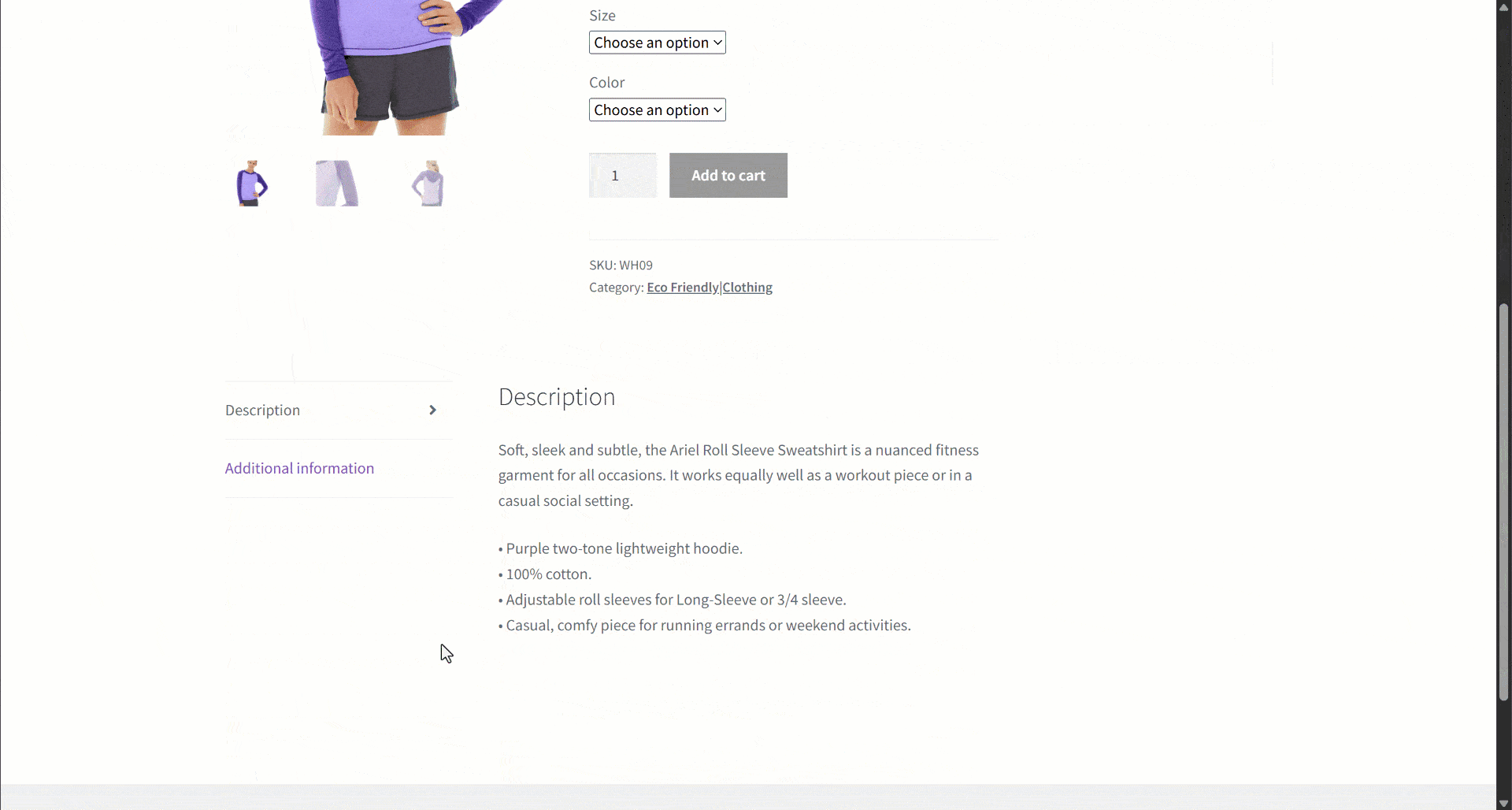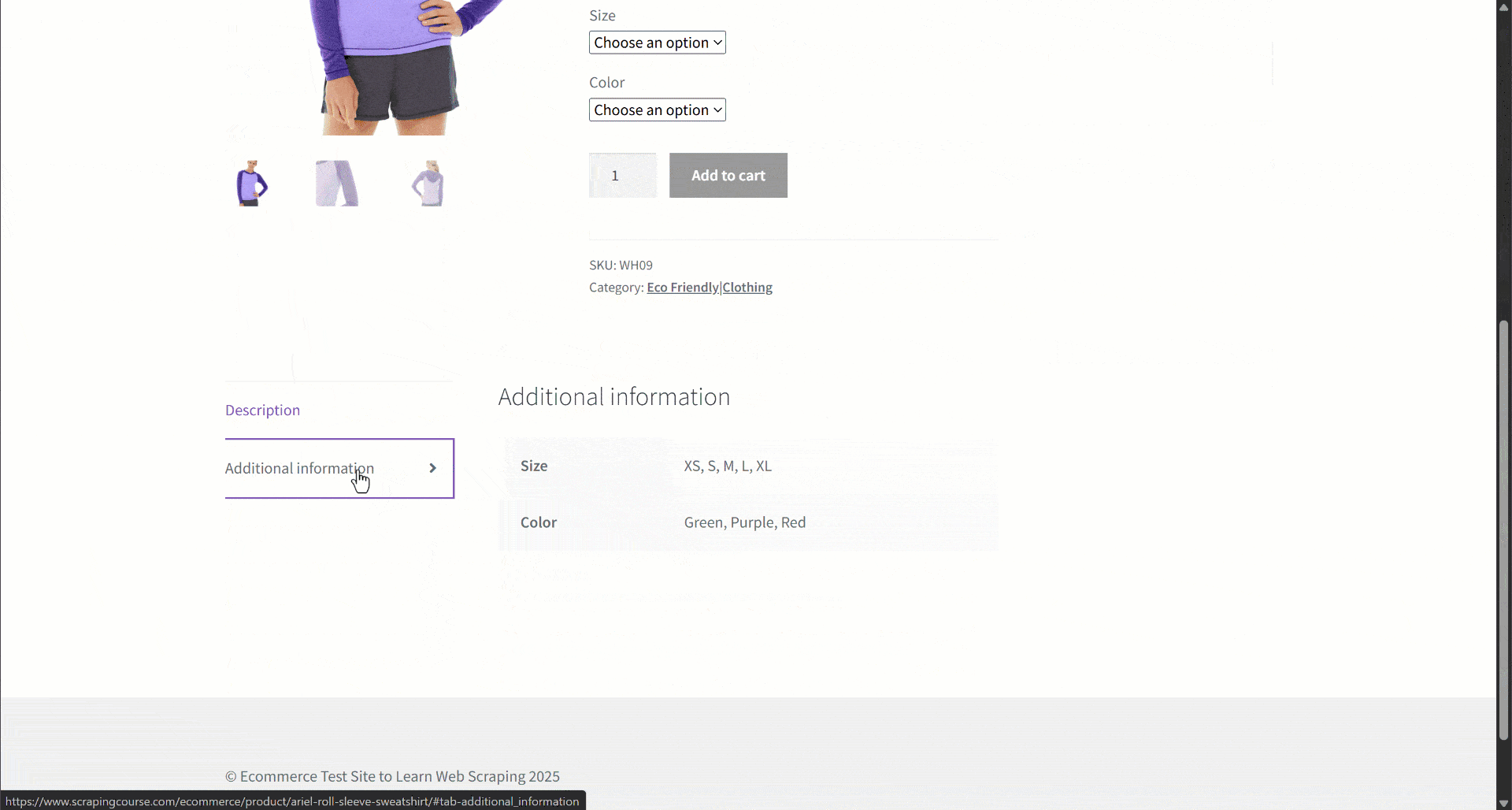
データ抽出中、ページコンテンツをLLMに提供してパースを簡略化します。ただしLLMは不正確な場合があり、作り話や信頼性の低い、あるいは不完全なデータを生成する可能性があります。そのためデータ検証の適用が極めて重要です。
簡略化のため、開発環境が設定済みのPythonプロジェクトが既に存在すると仮定します。
ステップ #1: 対象スキーマとルールを定義する
まず対象ページを調査し、商品ページに以下のフィールドが含まれていることを確認します:
- 製品URL: 製品ページのURL。
- 製品名: 製品名を含む文字列。
- Images: 画像URLのリスト。
- 価格: 浮動小数点数の価格。
- 通貨: 通貨を表す単一文字。
- SKU: 商品IDを含む文字列。
- カテゴリ: 1つ以上のカテゴリを含む配列。
- 説明: 商品の説明を記載するテキストフィールド。
- 詳細説明:すべての詳細を含む完全な製品説明を格納するテキストフィールド。
- 追加情報: 以下のオブジェクト:
- Size options: 利用可能なサイズを格納する文字列の配列。
- カラーオプション: 利用可能なカラーを格納する文字列の配列。
次に、以下のようにPydanticモデルでこれを表現します:
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options: Optional[List[str]] = None # ヌル可能
color_options: Optional[List[str]] = None # ヌル可能
class Product(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
product_url: HttpUrl # 必須、有効なURLであること
product_name: str # 必須
images: Optional[List[HttpUrl]] = None # 有効なURLのリスト、nullable
price: Optional[PositiveFloat] = None # nullable、0以上必須
currency: Optional[Annotated[str, StringConstraints(min_length=1, max_length=1)]] = None # nullable、1文字
sku: str # 必須
category: Optional[List[str]] = None # ヌル可能
description: Optional[str] = None # ヌル可能
long_description: Optional[str] = None # ヌル可能
additional_information: Optional[AdditionalInformation] = None # ヌル可能
@model_validator(mode="after")
# 価格が常に通貨に関連付けられていることを確認するカスタム検証ルール
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("価格が設定されている場合、通貨を指定する必要があります")
return valuesProductモデルは、フィールドとその型(例:str、HttpUrlなど)を定義するだけでなく、検証制約(例:通貨は1文字でなければならない)も含まれています。さらに、価格が常に通貨に関連付けられていることを保証する厳格な検証ルールを含み、モデルに直接一致しない余分なフィールドは禁止されています。
ステップ #2: データの収集
以下のチュートリアルで示されているように、AIウェブスクレイピングを介してデータを取得すると仮定します:
- ChatGPTを使ったウェブスクレイピング:ステップバイステップチュートリアル
- Geminiを使ったウェブスクレイピング:完全チュートリアル
- Perplexityを使用したウェブスクレイピング:ステップバイステップガイド
- Claudeを使ったウェブスクレイピング:PythonでのAI駆動型パース
スクレイピングされたデータを含むproduct.jsonファイルが生成されます。ここでは、LLMが以下のように出力したと仮定します:
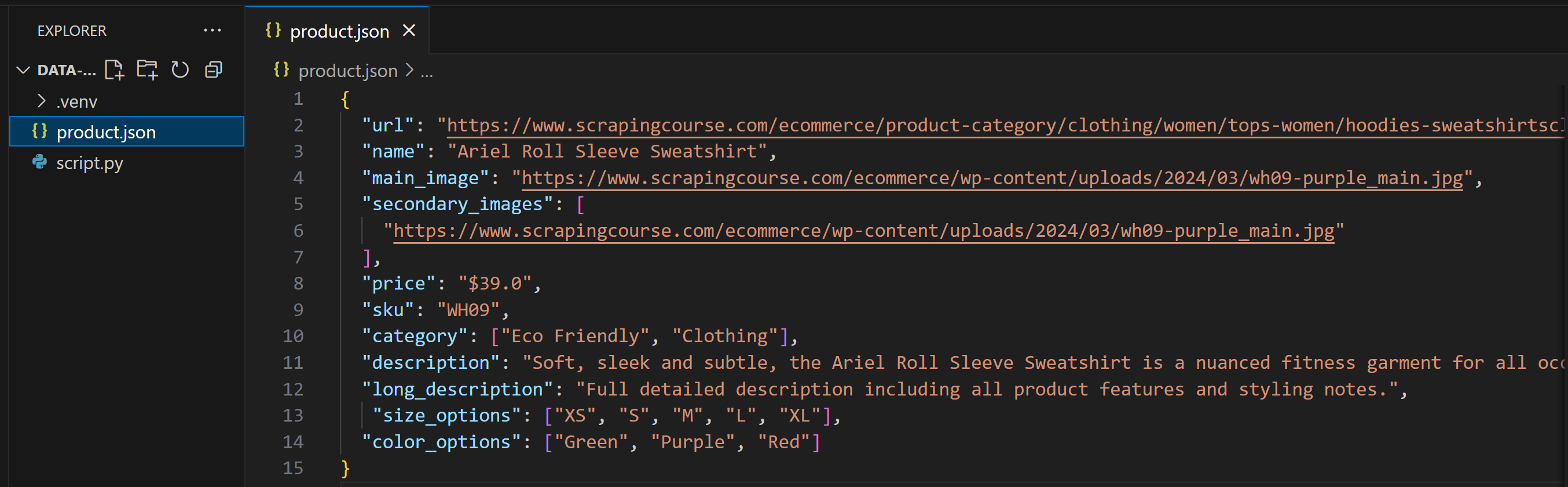
ご覧の通り、この出力はPydanticモデルと完全に一致していません。プロンプトで出力構造を明示的に指定していない場合や、AIの設定温度が高すぎる場合にこの現象はよく起こります。
ステップ #3: 検証ルールを適用する
product.jsonファイルからデータをロードします:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)次に、Pydanticで以下のように検証します:
try:
# Pydanticモデルでデータを検証
product = Product(**product_data)
print("検証成功!")
except ValidationError as e:
print("検証失敗:")
print(e)スクリプトを実行すると、以下のようなエラー出力が得られます:
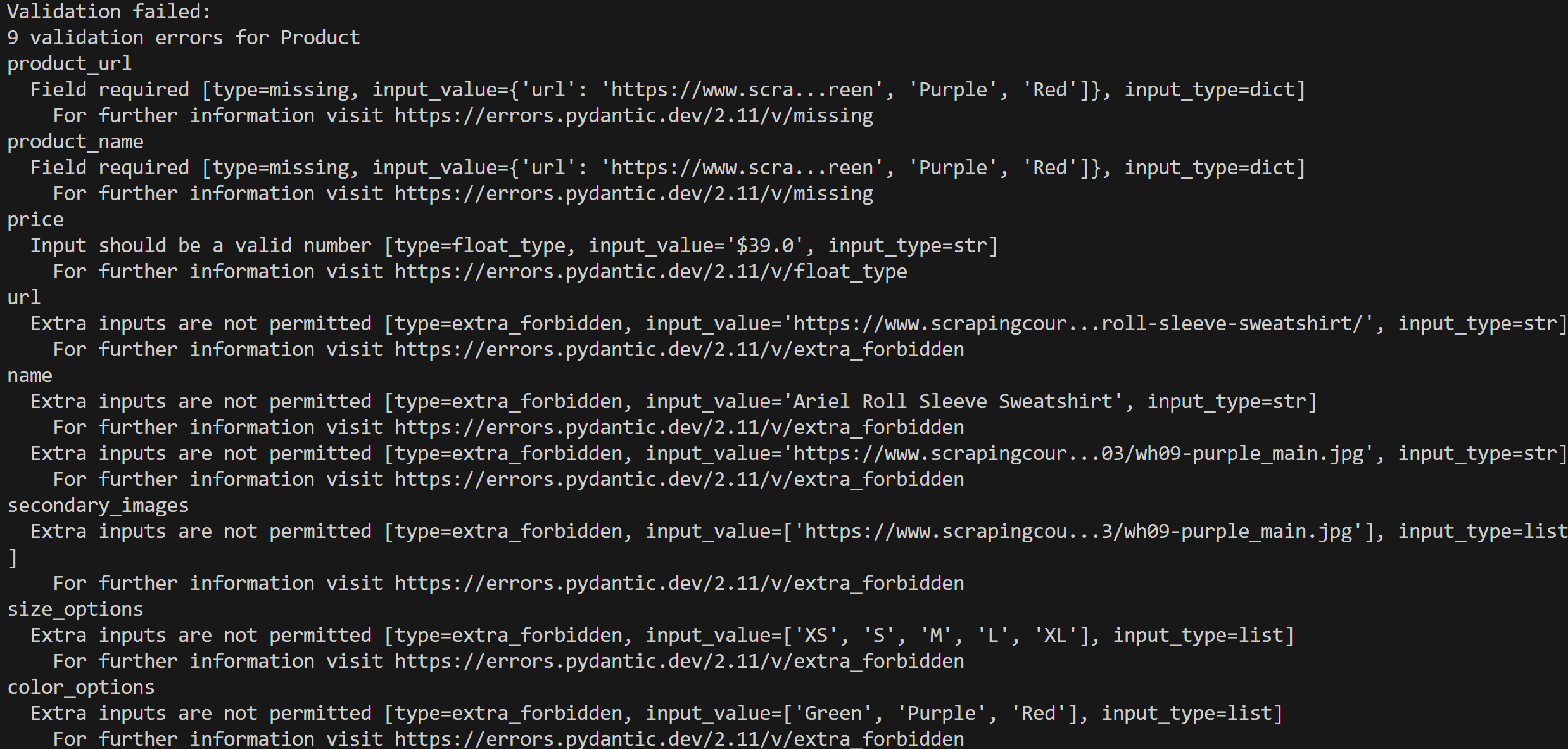
この場合、入力データがProductモデルに適合しないため、9件の検証エラーが検出されました。
ステップ #4: エラーの修正
検証ステップを通過するようデータを自動的に修正する普遍的なプロセスは存在しません。データパイプラインやワークフローはそれぞれ異なり、その異なる側面に介入する必要があるかもしれません。
このケースでは、OpenAIなどの大半のLLMがサポートする機能である、LLMプロンプトで期待される出力形式を明確に指定するだけで解決できます。
ヒント:この機能の実例は、GPT Visionを用いたビジュアルウェブスクレイピングガイドでご確認いただけます。
構造化出力機能が利用できない場合でも、JSON文字列としてダンプした期待されるPydanticモデルをプロンプトでLLMに一致させるよう要求できます:
prompt = f"""
指定されたページコンテンツからデータを抽出し、以下の構造で返す:
{Product.model_json_schema()}
CONTENT:
<ページコンテンツ>
"""いずれの場合も、LLMの出力は期待される形式に一致するはずです。
この変更後、product.jsonには以下が含まれます:
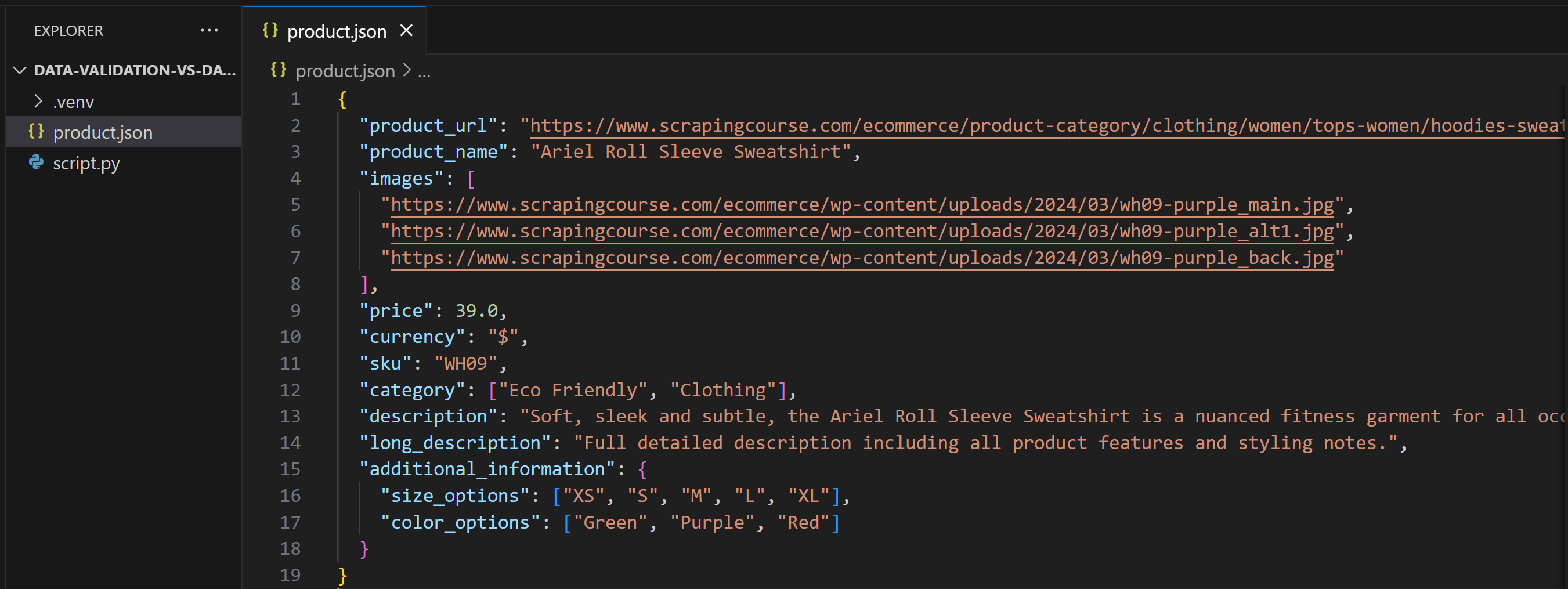
今回スクリプトを実行すると、以下が生成されます:

素晴らしい!データ検証が正常に完了しました。データ検証が完了したら、データの処理、データベースへの保存、その他の操作を続行できます。
データ検証:基本概念の解説
データ検証とデータバリデーションの比較ガイドを続けます。今回は2つ目の手法であるデータ検証に焦点を当てましょう。
データ検証とは何か?その重要性とは?
データ検証とは、データが正確であり現実世界の事実を反映していることを確認するプロセスです。これは、情報を信頼できる情報源と照合することで行われます。
データ検証とは異なり、データ検証はデータが事前定義されたルール(例:メールアドレスが正しい形式であること)を満たしているかのみを確認するものではなく、データが真実であり現実に合致していること(例:メールアドレスが実際に存在し、意図した人物に属していること)を確認します。
データの検証は、特に情報の意味性に関してデータ品質を確保する上で重要です。結局のところ、構造化され一見クリーンに見えるデータにも誤った情報が含まれている可能性があります。不正確なデータに依存すると、高額なミス、誤った意思決定、顧客体験の悪化、業務効率の低下を招く恐れがあります。
データ検証チェックの例
データ検証は複雑であり、適切な手法は入力データと運用領域に大きく依存します。それでも、一般的な検証方法には以下が含まれます:
- 自動検証:専用ソフトウェア、サードパーティサービス、またはエージェント型AIシステムを活用し、信頼できる情報源とデータを照合する。
- 校閲:文書、データ、またはデータフィールドを手動で確認し、正確な情報が含まれていることを保証します。これは、人間の知識を用いた手動による方法、またはAIによる自動化された方法で行われます。
- 二重入力:二つの別々のシステム(または自律型AIエージェント)が同じ主題について独立してデータを入力します。その後、記録を比較し、不一致があればレビューまたは修正のためにフラグを立てます。
- ソースデータ検証:データベースに保存されたデータを元のソース文書(例:患者の医療記録)と照合し、一致を確認する。
実施すべきタイミング
データ検証は、データソースを完全に信頼できない場合に実施すべきです。代表的な例は、AIによるデータ生成や補完時です。AIは一見妥当に見えるが不正確な情報を生成する可能性があります。
データ検証が重要な別のシナリオは、移行や統合時など、データが転送または保存された後です。こうした作業後は、結果として得られたデータの正確性が維持されていることを確認する必要があります。データ検証は、継続的なデータ品質維持の一環としても関連性があります。
データ検証は一般的にデータ検証(バリデーション)の後に行われる点に留意してください。データの構造が期待される形式と一致しない場合、検証は意味をなしません。なぜならデータが全く使用不能である可能性があるからです。データが検証を通過した後に初めて、検証に進むことが意味を持ちます。
データの検証は、検証(バリデーション)よりも確実に複雑です。なぜなら、決定論的な結果を得ることができないからです(前述のシンプルなPythonスクリプトで示したように)。これは、情報が真実であるかどうかを絶対的な確信をもって判断することが非常に困難であるためです。
データ検証の主要な手法
ユーザー投稿コンテンツを扱う場合、最も効果的な検証方法は人間による確認です。例としては以下が挙げられます:
- メールアドレス検証:登録時にユーザーが入力したメールアドレスに対し、確認リンクまたはコードを含む自動送信メールを送信し、アドレスの有効性とアクセス可能性を確認します。
- 電話番号検証:SMSまたは電話でワンタイムパスワード(OTP)を送信し、番号が有効で稼働中であり、ユーザー本人のものであることを確認します。
同様に、本人確認や住所確認のために書類や請求書の提出を求めることも可能です。これらの書類はOCRシステムで処理され、ユーザーが入力したデータがアップロードされた書類の情報と一致するか検証されます。この手法は依然として不正のリスクがありますが、データの信頼性を高める上で非常に有用です。
真の課題は、最大かつ最も構造化されていない情報源であるウェブから公開データを取得する際に生じます。この場合、情報の正確性を判断することは困難です。一般的なアプローチは、信頼できる情報源(例:文書、公式声明)を優先し、入力された内容を基にその出所を追跡し、信頼できる情報源とオンラインで照合し、結果を比較することです。
これを手動で行うのは非常に時間がかかるため、現在ではウェブデータ検索やウェブスクレイピングのツールを備えたAIエージェントを用いて、こうしたタスクの多くが自動化されている。
データ検証の方法:Pythonの例
このセクションでは、データ検証のためのAIエージェントを構築する手順を段階的に示します。エージェントは以下の処理を行います:
- サンプルテキストを入力として受け取る。
- ウェブ検索・ウェブスクレイピング機能を備えたLLM(大規模言語モデル)に情報を渡す。
- ソーステキストの主要トピックを特定し、正確性を検証するため関連する信頼性の高いページをGoogleで検索するようAIに指示する。
- それらのページから情報をスクレイピングし、ソーステキストと比較する。
- データの正確性を示すレポートを返却し、不正確な場合は修正方法を提案する。
この種のワークフローは、Bright DataのAIインフラストラクチャが提供するような、ウェブデータ取得・検索・インタラクションなどをサポートするAI対応インフラなしでは実現できません。
より容易な統合のため、60以上のツールを提供するBright Data Web MCPを利用します。特に無料プランでは以下の2ツールが含まれます:
search_engine: Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得。scrape_as_markdown: ボット検知やCAPTCHAを回避し、任意のウェブページをクリーンなMarkdown形式でスクレイピングします。
この2つのツールでデータ検証エージェントを駆動し、目的を達成するのに十分です!
シナリオ説明
summary.txtファイルに保存された入力データの正確性を検証したいとします。例えば、スーパーボウルLIXの短い要約が以下のように含まれている場合:

Web MCPと統合したLangChainを使用してデータ検証エージェントを構築します。作業には以下が必要です:
- ローカルにインストールされたPython
- 設定済みのLangChainプロジェクト。
- Web MCPへの接続認証用Bright Data APIキー。
- OpenAI APIキー
開始前に、Bright DataのWeb MCPとの連携のためのLangChain MCPアダプター使用チュートリアルをご確認ください。他のフレームワークやツールを使用したい場合は、以下のガイドを参照してください:
- CrewAIとBright DataのModel Context Protocol(MCP)を用いたウェブスクレイピングエージェントの構築
- LlamaIndexとBright DataのMCPを用いたCLIチャットボット構築
- Claude CodeとBright DataのWeb MCPの統合
- SERPデータを使用したGPT-4oによるRAGチャットボットの作成方法
データ検証用AIエージェントの構築
LangChainとBright DataのWeb MCPを使用したデータ検証エージェントの構築方法:
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # 自分のOpenAI APIキーに置き換えてください
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# 検証用入力データの読み込み
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# LLMエンジンの初期化
llm = ChatOpenAI(
model="gpt-5-nano",
)
# ローカルのBright Data Web MCPサーバーインスタンスへの接続設定
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Bright Data APIキーに置き換えてください
}
)
# MCPサーバーへの接続
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# MCPクライアントセッションの初期化
await session.initialize()
# MCPツールの取得
tools = await load_mcp_tools(session)
# ReActエージェントを作成
agent = create_react_agent(llm, tools)
# エージェントタスクの説明
input_prompt = f"""
以下の入力内容に基づき、次の手順を実行してください:
1. 主要トピックをGoogle風検索クエリとして特定し、それを使用してウェブ検索を行い情報を収集する。
2. 検索結果から、信頼性の高い情報源(例:信頼できるニュースサイト、学術誌、公式出版物)の上位2~3件を選択する。
3. 選択したページからコンテンツをスクレイピングする。
4. スクレイピングした情報と入力内容を比較し、正確性を判断する。
5. 正確でない場合、入力内容で見つかった全誤りをリスト化したレポートを作成し、修正情報と裏付けソースへのリンクを添付する。
入力内容:
{summary_data_to_verify}
"""
# エージェントの応答をストリーム処理
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())上記スクリプトで最も重要な部分であるプロンプト自体に焦点を当ててください。
エージェントの実行
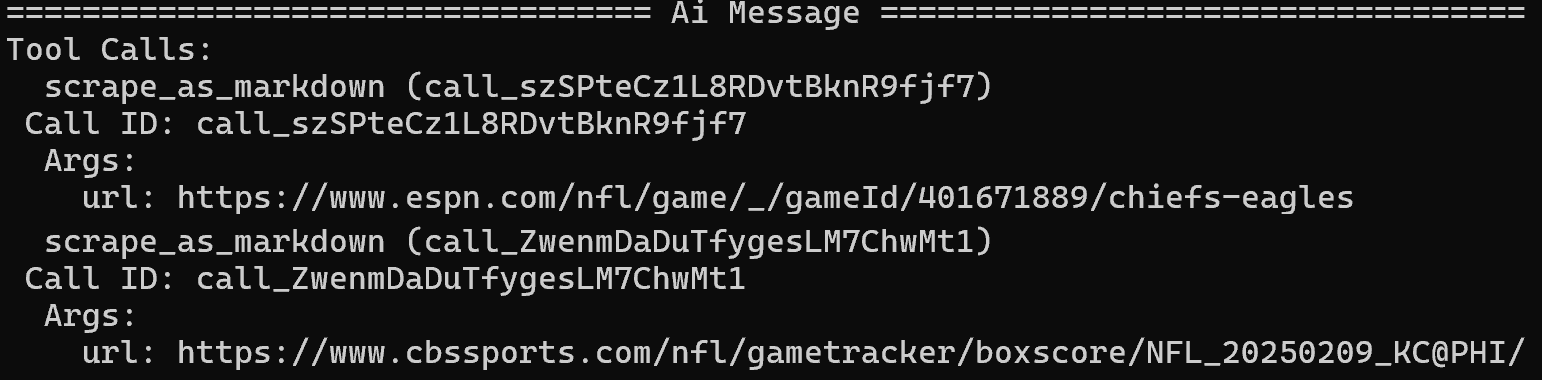
エージェントを起動すると、メイントピックが「Super Bowl LIX」と正しく識別されるのが確認できます。その後、WebMCPのsearch_engineツールを使用してGoogle検索を実行します:

検索結果ページから、ESPNとCBS Sportsの記事を主要情報源として特定し、scrape_as_markdownツールでスクレイピングします:
3つのニュースソースからコンテンツを抽出した後、以下のMarkdownレポートを生成します:
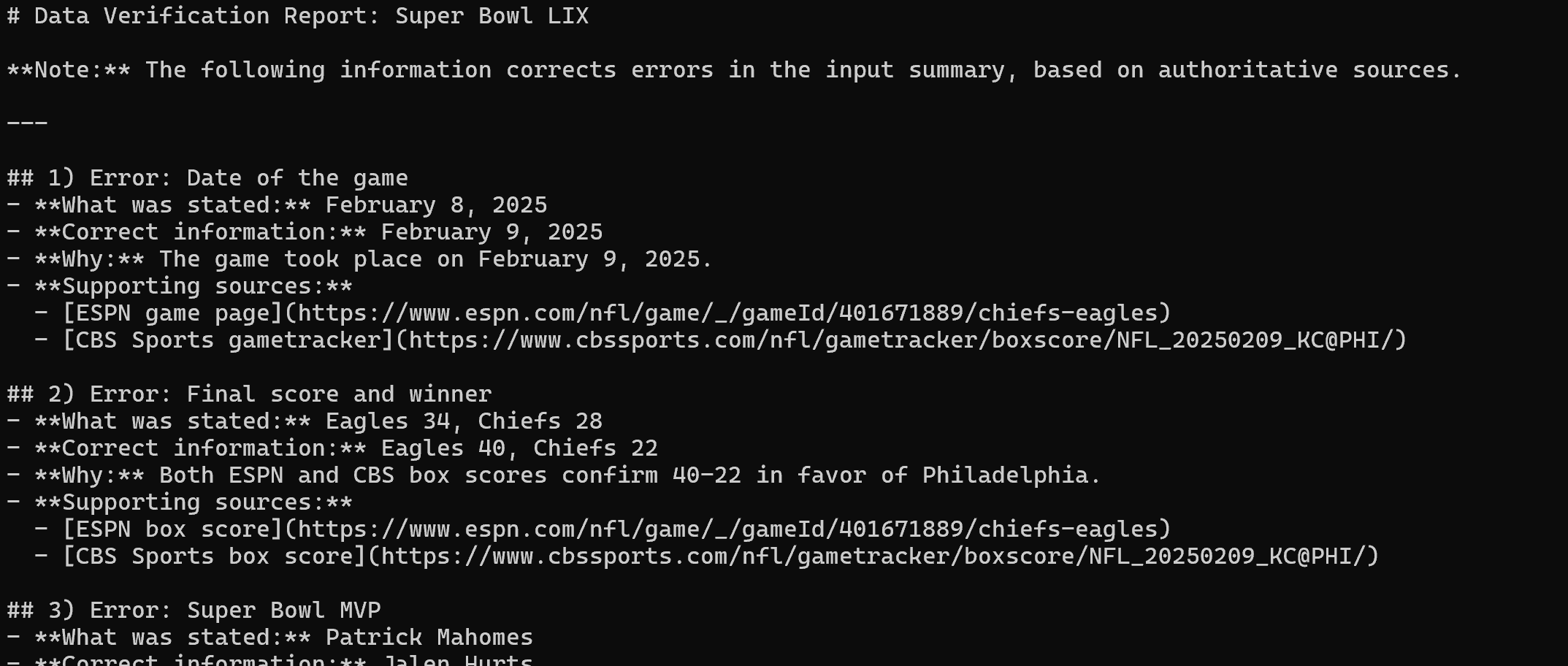
Visual Studio Codeでレンダリングすると、最終レポートが表示されます。
ご覧の通り、Web MCPのウェブ検索とウェブスクレイピング機能により、LangChainエージェントは元の誤ったテキスト内の全エラーを特定できました。ミッション完了!
データ検証とデータ確認:比較表
データ検証とデータ確認の2つの手法を、以下の要約表で比較します:
| 側面 | データ検証 | データ検証 |
|---|---|---|
| 定義 | 使用または保存前に、事前定義されたルールや基準に対してデータの正確性、品質、完全性を検証する。 | 権威ある情報源と照合することで、データが現実世界の事実を正確に反映していることを確認する。 |
| 目的 | データが期待される形式、種類、範囲、規則に準拠していることを保証し、不良データがシステムに流入するのを防止する。 | 意思決定のためにデータが真実性、正確性、信頼性を備えていることを保証する。 |
| タイミング | 入力時、抽出後、変換後、または定期的に実施される。 | 検証後、またはデータソースの信頼性が不確かな場合に実施。通常はデータ収集または転送後。 |
| 複雑さ | 比較的単純;定義されたルールに基づく決定論的チェック。 | より複雑;不確実性、外部ソース、手動レビューを伴う可能性あり;非決定論的結果が生じる可能性あり。 |
| 例 | 価格は0 以上でなければならない |
価格が公式ストア掲載価格と一致することを確認 |
最終コメント
このデータ検証とデータ検証の比較ブログ記事で学んだように、データ検証とデータ検証は異なるが補完的な2つのタスクに対応します。特に、どちらも高いデータ品質の達成に貢献します。もう1つの類似点は、いずれかを見落とすと、ほとんどのビジネスオペレーションを支えるデータ駆動型プロセス全体に重大な問題を引き起こす可能性があることです。
だからこそ、信頼できるデータプロバイダーを選ぶことが不可欠です。適切なデータ検証を保証する複数のソリューションを提供し、効果的なデータ検証システムを構築するためのツールを備えたプロバイダーを選ぶべきです。
Bright Dataはその優れた例です。すぐに使用可能な検証済みデータセットから、ウェブから正確な情報を収集するためのAI対応ウェブスクレイピングソリューションまで、幅広い製品を提供し、検証と確認の両方のワークフローをサポートします。
今すぐBright Dataの無料アカウントに登録し、当社のデータサービスをご活用ください!




