

このガイドで、あなたは学ぶだろう:
- GPT Visionが、従来の構文解析技術を超えるデータ抽出タスクに最適な理由。
- PythonでGPT Visionを使用してビジュアルなWebスクレイピングを実行する方法。
- この方法の主な限界と、それを回避する方法。
さあ、飛び込もう!
なぜデータスクレイピングにGPT Visionを使うのか?
GPT Visionは、テキストと画像の両方を理解するマルチモーダルAIモデルです。これらの機能は最新のOpenAIモデルで利用可能です。GPT Visionに画像を渡すことで、視覚的なデータ抽出を行うことができ、従来のデータ解析が破綻するようなシナリオに最適です。
通常のデータ解析では、ドキュメントからデータを取得するためのカスタムルールを記述する(例えば、HTMLページからデータを取得するためのCSSセレクタやXPath式など)。問題は、情報が画像やバナー、複雑なUI要素に視覚的に埋め込まれ、標準的な解析技術ではアクセスできないことです。
GPT Visionは、これらの届きにくいソースからデータを抽出するのに役立ちます。最も一般的なユースケースは以下の2つです:
- 視覚的なウェブスクレイピング:ページの変更やページ上のビジュアル要素を気にすることなく、ページのスクリーンショットから直接ウェブコンテンツを抽出します。
- 画像ベースのドキュメント抽出:履歴書、請求書、メニュー、領収書などのスクリーンショットやローカルファイルのスキャンから構造化データを取得します。
視覚的でないアプローチについては、ChatGPTを使ったウェブスクレイピングのガイドを参照してください。
PythonでGPT Visionを使ってスクリーンショットからデータを抽出する方法
このステップ・バイ・ステップのセクションでは、GPT Visionウェブスクレイピングスクリプトの構築方法を学びます。詳細には、スクレーパーはこれらのタスクを自動化します:
- Playwrightを使って、対象のウェブページに接続する。
- データを抽出したい特定のセクションのスクリーンショットを撮る。
- スクリーンショットをGPT Visionに渡し、構造化データの抽出を促す。
- 抽出したデータをJSONファイルにエクスポートします。
ターゲットは “Books to Scrape “の特定の商品ページである:
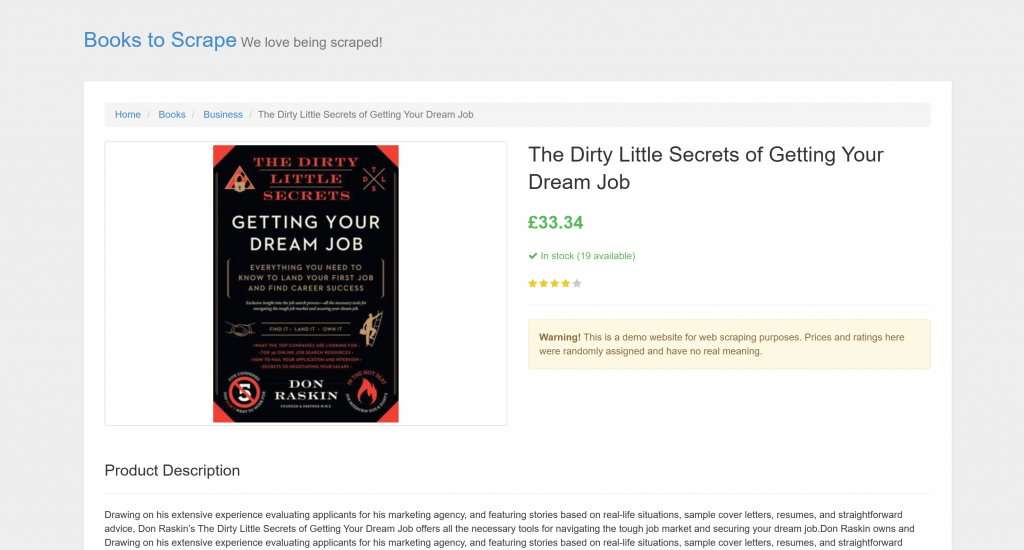
このページは、自動スクレイピング・ボットを明確に歓迎しているので、テストには最適だ。さらに、星評価ウィジェットのような視覚的要素も含まれており、従来の解析方法では対処が難しい。
注:サンプルスニペットは、OpenAI Python SDKが広く採用されているため、簡単のためにPythonで記述します。しかし、JavaScript OpenAI SDKや他のサポートされている言語でも同じ結果を得ることができます。
GPT Visionを使用してウェブデータをスクレイピングする方法については、以下の手順に従ってください!
前提条件
始める前に、あなたが持っていることを確認してください:
- Python 3.8以上がインストールされていること。
- GPT Vision APIにアクセスするためのOpenAI APIキー。
OpenAI APIキーを取得するには、公式ガイドに従ってください。
以下の背景知識も、この記事を最大限に活用するのに役立つだろう:
注:このアプローチには、Playwrightのようなブラウザ自動化ツールが必要である。なぜなら、ブラウザ内でターゲット・ページをレンダリングする必要があるからだ。そして、ページが読み込まれたら、興味のある特定のセクションのスクリーンショットを撮ることができる。これは、Playwright Screenshots APIを使って行うことができる。
ステップ #1: Pythonプロジェクトの作成
ターミナルで以下のコマンドを実行し、スクレイピング・プロジェクト用の新しいフォルダを作成する:
mkdir gpt-vision-scrapergpt-vision-scraper/は、GPT Visionを使ってウェブスクレーパーを構築するためのメインプロジェクトフォルダになります。
フォルダに移動し、その中にPython仮想環境を作成する:
cd gpt-vision-scraper
python -m venv venvお好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio Codeや PyCharm Community Editionでも構いません。
プロジェクトフォルダ内にscraper.pyファイルを作成します:
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------現時点では、scraper.pyはただの空のファイルです。まもなく、GPT Visionを使ったビジュアルなLLMウェブスクレイピングのロジックが含まれるようになります。
次に、ターミナルで仮想環境を有効にする。LinuxまたはmacOSでは、起動する:
source venv/bin/activate同様に、Windowsでは、以下を実行する:
venv/Scripts/activateナイスこれでGPT Visionを使ったビジュアルスクレイピングの準備が整いました。
注:以下のステップでは、必要な依存関係をインストールする方法を説明します。一度にインストールしたい場合は、このコマンドを実行してください:
pip install playwright openaiそれからだ:
python -m playwright install素晴らしい!Pythonの環境が整いました。
ステップ2:ターゲット・サイトへの接続
まず、制御されたブラウザを使用してターゲットサイトにアクセスするようにPlaywrightに指示する必要があります。起動した仮想環境に、Playwrightをインストールしてください:
pip install playwright その後、必要なブラウザのバイナリをダウンロードしてインストールを完了する:
python -m playwright install次に、スクリプトでPlaywrightをインポートし、goto()関数を使ってターゲットページに移動する:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()このAPIをご存知でない方は、Playwrightを使ったウェブスクレイピングの記事をお読みください。
素晴らしい!これでPlaywrightスクリプトがターゲットページに接続できました。スクリーンショットを撮りましょう。
ステップ3:ページのスクリーンショットを撮る
スクリーンショットを撮るロジックを書く前に、OpenAIはトークンの使用量に応じて課金されることを覚えておいてください。つまり、入力するスクリーンショットが大きければ大きいほど、料金は高くなります。
コストを抑えるには、スクリーンショットを興味のあるデータを含むHTML要素だけに限定するのが一番です。Playwrightはノードベースのスクリーンショットをサポートしているので、それは可能です。また、スクリーンショットを絞り込むことで、GPT Visionは関連するコンテンツに集中することができ、幻覚のリスクを減らすことができます。
まず、ブラウザでターゲット・ページを開き、その構造に慣れることから始める。次に、コンテンツを右クリックして「Inspect」を選択し、ブラウザのDevToolsを開きます:
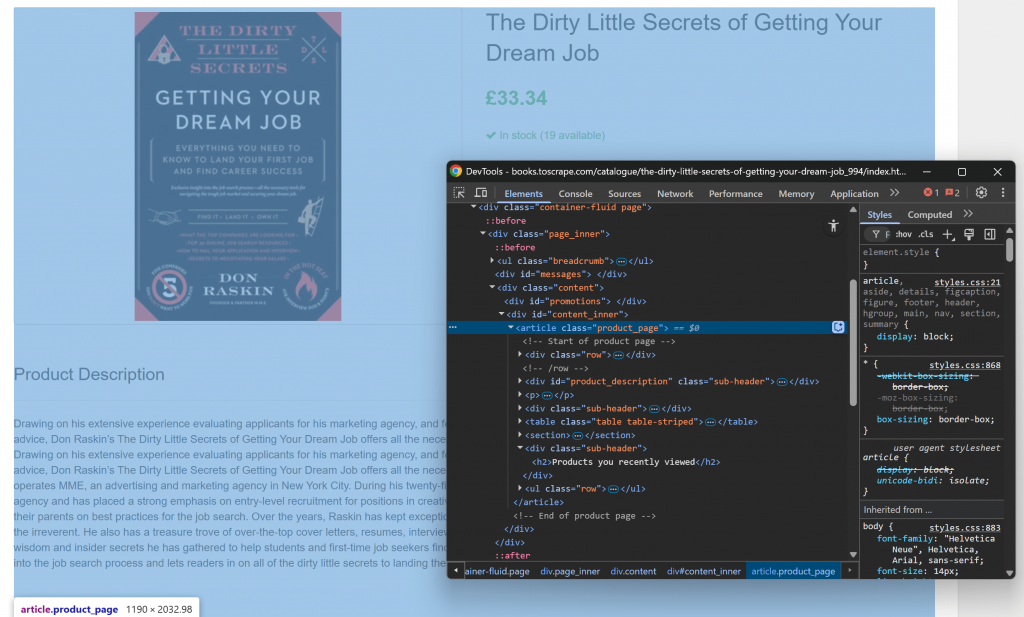
関連するコンテンツのほとんどが.product_pageHTML要素内に含まれていることにお気づきでしょう。
この要素は動的にロードされるか、JavaScriptで公開される可能性があるので、キャプチャする前にそれを待つ必要がある:
product_page_element = page.locator(".product_page")
product_page_element.wait_for()デフォルトでは、wait_for()は要素がDOMに表示されるまで最大30秒待つ。このマイクロ・ステップは基本的なもので、空の部分や見えない部分をスクリーン・ショットしたくないからです。
ここで、選択したロケータのscreenshot()メソッドを利用して、その要素だけのスクリーンショットを撮る:
product_page_element.screenshot(path=SCREENSHOT_PATH)ここで、SCREENSHOT_PATHは、次のような出力ファイル名を保持する変数である:
SCREENSHOT_PATH = "product_page.png"その情報を変数に保存しておくのはいい考えだ。
スクリプトを起動すると、product_page.pngというファイルが生成される:
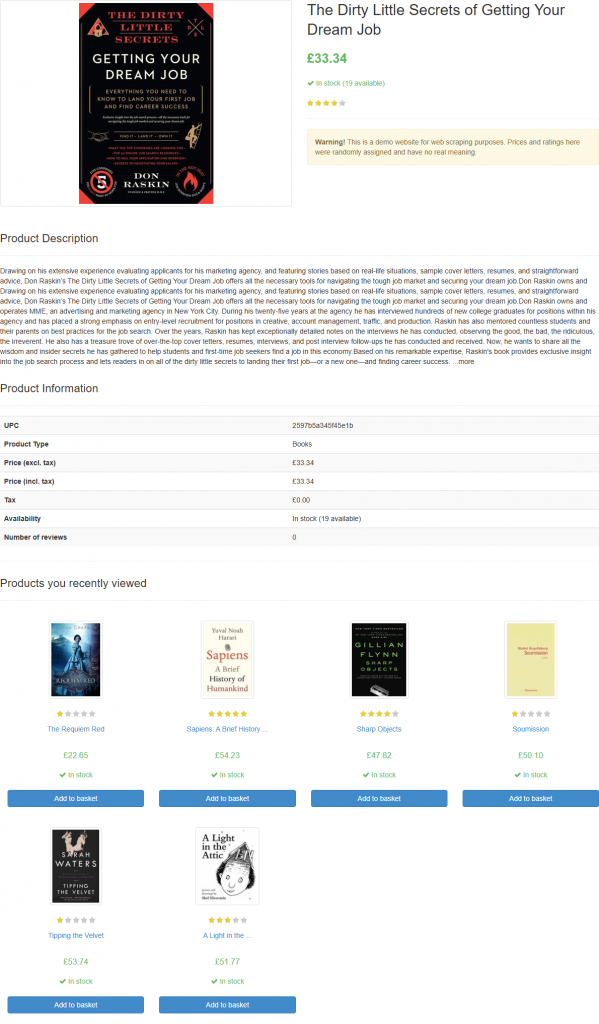
注:スクリーンショットをファイルに保存することは、後で別のテクニックやモデルを用いて再分析したくなるかもしれないので、ベストプラクティスである。
素晴らしい!スクリーンショットを撮るのは終わった。
ステップ4: PythonでOpenAIの設定をする
GPT Visionをウェブスクレイピングに使用するには、OpenAI Python SDKを使用します。起動した仮想環境で、openaiパッケージをインストールします:
pip install openai次に、scraper.py で OpenAI クライアントをインポートします:
from openai import OpenAI続けて、OpenAI クライアントインスタンスを初期化します:
client = OpenAI()これにより、Vision APIを含むOpenAI APIにより簡単に接続できるようになります。デフォルトでは、OpenAI()コンストラクタは、OPENAI_API_KEY環境変数でAPIキーを探します。このenvを設定することは、認証を安全に設定するために推奨される方法です。
開発またはテスト目的の場合は、コードに直接キーを追加することもできる:
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)プレースホルダを プレースホルダを実際の OpenAI API キーに置き換えてください。
素晴らしい!これでOpenAIのセットアップが完了し、GPT Visionをウェブスクレイピングに使う準備ができました。
ステップ #5: GPT Visionスクレイピングリクエストの送信
GPT Visionは、公開画像URLを含むいくつかのフォーマットで入力画像を受け付けます。ローカルファイルを扱うので、画像をBase64エンコード文字列に変換してOpenAIサーバに送信する必要があります。
スクリーンショット・ファイルをBase64に変換するには、以下のコードを書きます:
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") これはPython標準ライブラリからのインポートを必要とする:
import base64次に、ビジュアル・ウェブ・スクレイピングのために、エンコードされた画像をGPT Visionに渡します:
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)注:上の例ではgpt-4.1モデルを設定していますが、ビジュアル機能をサポートするOpenAIのモデルであれば、どのモデルでも使用できます。
GPT VisionがResponses APIに直接統合されていることに注目してください。つまり、特別な設定は必要ありません。type "を使用してBase64画像を含めるだけです:type": "input_image "を使用してBase64画像を含めるだけで、準備は完了です。
上記で使用したスクレイピング・プロンプトは以下の通り:
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.ターゲットのページの正確な構造を知らないかもしれないので、プロンプトはかなり一般的なものにしておくべきです(しかし、まだゴールに焦点をあてています)。ここでは、興味のないセクションを無視するようにモデルに明示的に指示しました。また、きれいで構造化されたキー名を持つJSONオブジェクトを返すように依頼しました。
OpenAI Responses APIリクエストは、JSONモードで動作するように設定されていることに注意してください。これは、モデルが JSON 形式で出力を生成することを保証する方法です。この機能を動作させるには、プロンプトに JSON でデータを返すインストルメントを組み込む必要があります:
Return the data in JSON format using lowercase snake_case attribute names.そうでなければ、リクエストは失敗する:
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}リクエストが正常に完了すると、パースされた構造化データにアクセスできる:
json_product_data = response.output_textオプションで、結果の文字列をパースしてPython辞書に変換します:
import json
product_data = json.loads(json_product_data)GPT Visionデータ解析ロジック完了!あとは、スクレイピングされたデータをローカルのJSONファイルにエクスポートするだけです。
ステップ6:スクレイピングしたデータをエクスポートする
GPT Vision API 呼び出しによって生成された出力 JSON 文字列を書き込みます:
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)これは、視覚的に抽出されたデータを格納するproduct.jsonファイルを作成します。
よくできました!GPT Visionを搭載したウェブスクレーパーの準備が整いました。
ステップ7:すべてをまとめる
以下はscraper.pyの最終的なコードです:
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)すごい!わずか65行のコードで、GPT Visionを使ったビジュアル・ウェブ・スクレイピングを実行したことになる。
GPTビジョンスクレーパーを実行する:
python scraper.pyスクリプトはしばらくしてから、product.jsonファイルをプロジェクトのフォルダに書き込みます。それを開いてください:
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}純粋に視覚的な要素から、レビュー評価を含むページ上のすべての製品情報をうまく抽出していることに注目してください:
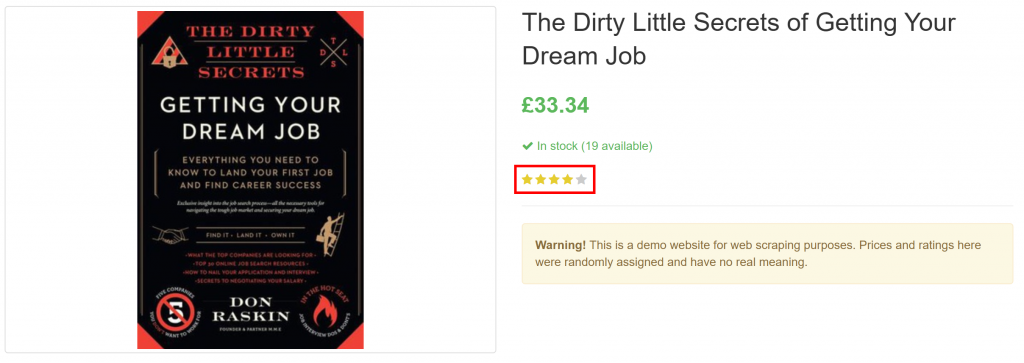
出来上がり!GPT Visionは、スクリーンショットをきれいに構造化されたJSONファイルに変換することができました。
次のステップ
GPT Visionスクレーパーを改善するために、以下の調整を検討してください:
- 再利用可能にする:スクリプトをリファクタリングして、ターゲットURL、待機する要素のCSSセレクタ、CLIからのLLMプロンプトを受け付けるようにする。こうすることで、コードを修正することなく異なるページをスクレイピングできるようになります。
- APIキーの保護:OpenAIのAPIキーをハードコーディングする代わりに、
.envファイルに保存し、python-dotenvパッケージを使ってロードします。あるいは、OPENAI_API_KEYという名前のグローバル環境変数として設定します。どちらの方法も、認証情報を保護し、コードベースを安全に保つのに役立ちます。
ビジュアル・ウェブ・スクレイピングの最大の制限を克服する
ウェブスクレイピングへのこのアプローチの主な課題は、スクリーンショットのステップにある。Books to Scrape」のようなサンドボックス・サイトでは完璧に機能したが、現実のウェブサイトでは異なる現実が待っている。
最近のウェブサイトの多くは、ページにアクセスする前にスクリプトをブロックするスクレイピング対策を導入しています。スクレイパーがページへのアクセスに成功しても、エラーや人間による確認が行われる場合があります。例えば、G2.comのようなサイトに対してvanilla Playwrightを使用すると、このようなことが起こります:

このような問題は、ブラウザのフィンガープリンティング、IPレピュテーション、レート制限、CAPTCHAチャレンジなどによって引き起こされる可能性があります。
このようなブロックを回避する最も強固な方法は、専用のWebロック解除APIに頼ることだ!
Bright Data の Web Unlocker は、1億5千万を超える IP のプロキシネットワークに支えられた強力なスクレイピングエンドポイントです。特に、指紋偽装、JavaScriptレンダリング、CAPTCHA解決機能、その他多くの機能を提供しています。スクリーンショットのキャプチャもサポートしており、手動で行うPlaywrightのスクリーンショットロジックを完全に省略することができる。
Bright DataのG2セラーページから平均星評価を抽出したいとします:
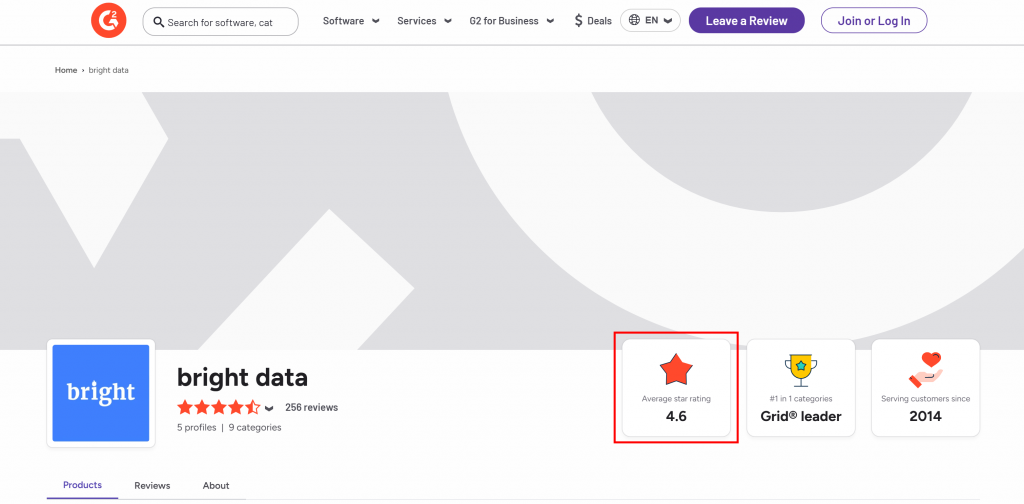
始めに、ドキュメントで説明されているようにWeb Unlockerをセットアップし、Bright Data APIキーを取得します。GPT VisionとWeb Unlockerを以下のように併用します:
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
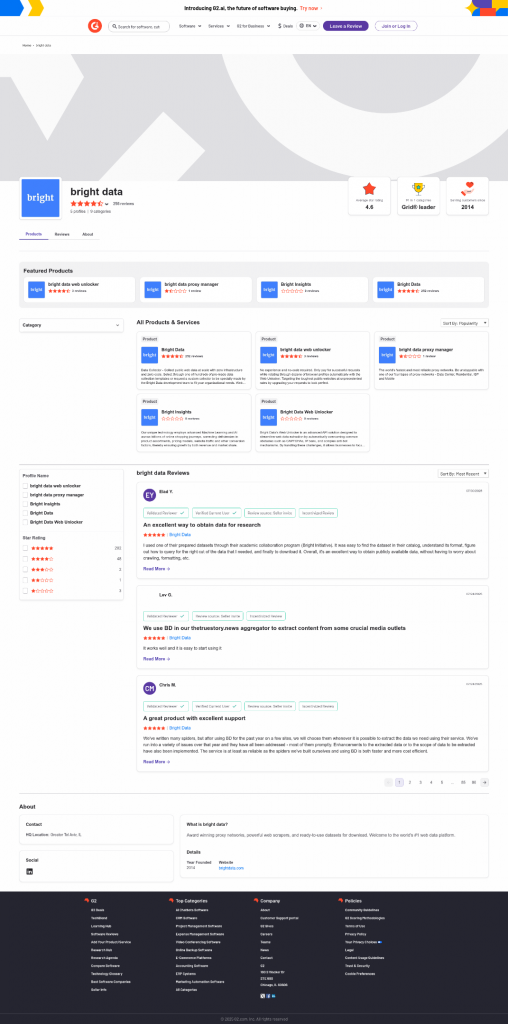
print(response.output_text)上記のスクリプトを実行すると、次のような出力が得られる:
The average star rating from the image is 4.6.Web Unlockerが返す生成されたscreenshot.pngファイルで視覚的に確認できるように、これは正しい情報です:
Web Unlockerを使えば、完全にロック解除されたページのHTMLを取得したり、AIに最適化されたMarkdown形式でコンテンツを取得することもできる。
もうブロックも頭痛の種もありません。これで、保護されたウェブサイト上でも動作する、GPT Visionを搭載したプロダクショングレードのウェブスクレーパーが手に入ります。
OpenAI SDKとWeb Unlockerが、より複雑なスクレイピングシナリオで連携する様子をご覧ください。
結論
このチュートリアルでは、GPT VisionとPlaywrightのスクリーンショット機能を組み合わせて、AIを搭載したウェブスクレーパーを構築する方法を学びました。最大の課題(スクリーンショット撮影中にブロックされる)は、Bright DataWeb Unlocker APIで解決しました。
説明したように、GPT VisionとWeb Unlocker APIが提供するスクリーンショット機能を組み合わせることで、あらゆるウェブサイトから視覚的にデータを抽出することができます。それもすべて、カスタム解析コードを書くことなく。これは、ブライト・データのAI製品やサービスがカバーする多くのシナリオの一つに過ぎません。
Bright Dataのアカウントを無料で作成し、データソリューションをお試しください!




