

このガイドで、あなたは学ぶだろう:
- OpenAI Agents SDKとは
- ウェブアンロックサービスとの統合が、その効果を最大化する鍵である理由
- OpenAI Agents SDKとWeb Unlocker APIを使用したPythonエージェントの構築方法を、ステップバイステップの詳細なチュートリアルで紹介します。
さあ、飛び込もう!
OpenAI Agents SDKとは?
OpenAI Agents SDKは、OpenAIによるオープンソースのPythonライブラリです。このライブラリは、エージェントベースのAIアプリケーションを、シンプルかつ軽量に、そして生産可能な方法で構築するために設計されています。このライブラリは、Swarmと呼ばれるOpenAIの初期の実験的プロジェクトを改良したものです。
OpenAIエージェントSDKは、最小限の抽象化でいくつかのコアプリミティブを提供することに重点を置いています:
- エージェントタスクを実行するための具体的な指示やツールと対になったLLM
- ハンドオフ:必要な時にエージェントが他のエージェントに仕事を任せること。
- ガードレール:エージェントの入力が期待される形式や条件を満たしているかどうかを検証する。
これらのビルディングブロックは、Pythonの柔軟性と相まって、エージェントやツール間の複雑な相互作用を簡単に定義することができる。
SDKにはトレース機能も組み込まれており、エージェントのワークフローを可視化、デバッグ、評価することができます。さらに、特定のユースケースに合わせてモデルを微調整することもできます。
AIエージェントを構築するこのアプローチの最大の限界
ほとんどのAIエージェントは、コンテンツの取得やページ上の要素とのインタラクションなど、ウェブページ上の操作を自動化することを目的としている。つまり、プログラムによってウェブを閲覧する必要がある。
AIモデル自体による潜在的な誤解はさておき、これらのエージェントが直面する最大の課題は、ウェブサイトの保護対策に対処することである。というのも、多くのサイトがボット対策やスクレイピング対策技術を導入しているため、AIエージェントをブロックしたり、誤解させたりする可能性があるからだ。これは、アンチAI CAPTCHAや高度なボット検知システムがますます一般的になっている今日、特に当てはまります。
では、AIウェブエージェントはこれで終わりなのだろうか?そうではありません!
これらの障壁を克服するには、Bright Data の Web Unlocker API のようなソリューションと統合することで、エージェントの Web ナビゲート能力を強化する必要があります。このツールは、インターネットに接続するあらゆるHTTPクライアントやソリューション(AIエージェントを含む)と連動し、Webロック解除ゲートウェイとして機能します。あらゆるウェブページから、ブロックされていないクリーンなHTMLを提供します。CAPTCHA、IP禁止、ブロックされたコンテンツはもう必要ありません。
なぜOpenAI Agents SDKとWeb Unlocker APIを組み合わせることが、パワフルでウェブに精通したAIエージェントを構築するための究極の戦略なのかをご覧ください!
Agents SDKとWeb Unlocker APIを統合する方法
このガイドセクションでは、OpenAI Agents SDKとBright DataのWeb Unlocker APIを統合して、以下のことが可能なAIエージェントを構築する方法を学びます:
- ウェブページのテキストを要約する
- eコマース・ウェブサイトから構造化された商品データを取得する
- ニュース記事から重要な情報を収集する
それを達成するために、エージェントはOpenAI Agents SDKに、任意のウェブページのコンテンツを取得するためのエンジンとしてWeb Unlocker APIを使用するように指示します。コンテンツが取得されると、エージェントはAIロジックを適用して、上記の各タスクに必要なデータを抽出し、フォーマットします。
免責事項:上記 3 つのユースケースは、単なる例です。ここで示したアプローチは、エージェントの動作をカスタマイズすることにより、他の多くのシナリオに拡張することができます。
以下の手順に従って、OpenAI Agents SDKとBright DataのWeb Unlocker APIを使用してPythonでAIスクレイピングエージェントを構築してください!
前提条件
このチュートリアルに入る前に、以下を確認してください:
- Python 3以上をローカルにインストール
- 有効なブライト・データ・アカウント
- アクティブなOpenAIアカウント
- HTTPリクエストの仕組みについての基本的な理解
- Pydanticモデルがどのように機能するかについての知識
- AIエージェントの機能に関する一般的な考え方
まだすべてがセットアップされていなくても心配しないでください。次のセクションで設定方法を説明します。
ステップ1:プロジェクトのセットアップ
始める前に、システムにPython 3がインストールされていることを確認してください。インストールされていない場合は、Pythonをダウンロードし、オペレーティングシステムのインストール手順に従ってください。
ターミナルを開き、スクレイピング・エージェント・プロジェクト用の新しいフォルダを作成する:
mkdir openai-sdk-agentopenai-sdk-agentフォルダには、PythonベースのAgent SDK搭載エージェントのすべてのコードが含まれます。
プロジェクトフォルダーに移動し、仮想環境をセットアップする:
cd openai-sdk-agent
python -m venv venvお気に入りのPython IDEでプロジェクトフォルダを読み込みます。Pythonエクステンションを持つVisual Studio Codeや PyCharm Community Editionは素晴らしい選択です。
openai-sdk-agentフォルダ内に、agent.pyという新しいPythonファイルを作成します。フォルダ構造は以下のようになります:

現在、scraper.pyは空白のPythonスクリプトですが、すぐに目的のAIエージェントロジックを含むようになります。
IDEのターミナルで、仮想環境を有効にします。LinuxまたはmacOSでは、このコマンドを実行する:
./env/bin/activate同様に、Windowsでは、実行する:
env/Scripts/activateこれで準備完了です!これで、OpenAI Agents SDKとWebアンロッカーを使って強力なAIエージェントを構築するためのPython環境が整いました。
ステップ #2: プロジェクトの依存関係をインストールして始める
このプロジェクトでは以下のPythonライブラリを使用する:
openai-agents:PythonでAIエージェントを構築するためのOpenAIエージェントSDKです。リクエストに対応します:Bright DataのWeb Unlocker APIに接続し、AIエージェントが操作するWebページのHTMLコンテンツを取得します。詳しくはPython Requestsライブラリを使いこなすためのガイドをご覧ください。pydantic:構造化された出力モデルを定義し、エージェントが明確で妥当なフォーマットでデータを返すことを可能にする。Markdownify:生のHTMLコンテンツをきれいなMarkdownに変換する。(なぜこれが便利なのかはすぐに説明します)。python-dotenv:.envファイルから環境変数をロードする。ここにOpenAIとBright Dataの秘密を保存する。
活性化された仮想環境で、それらをすべてインストールする:
pip install requests pydantic openai-agents openai-agents markdownify python-dotenvさて、以下のimportとasyncの定型コードでscraper.pyを初期化します:
import asyncio
from agents import Agent, RunResult, Runner, function_tool
import requests
from pydantic import BaseModel
from markdownify import markdownify as md
from dotenv import load_dotenv
# AI agent logic...
async def run():
# Call the async AI agent logic...
if __name__ == "__main__":
asyncio.run(run())素晴らしい!環境変数をロードする時間だ。
ステップ3:環境変数のセットアップ 読み込み
プロジェクトフォルダに.envファイルを追加する:

このファイルには、APIキーやシークレットトークンなどの環境変数が格納される。.envファイルから環境変数をロードするには、dotenvパッケージのload_dotenv()を使用します:
load_dotenv()以下のように、os.getenv()を使って特定の環境変数を読み込むことができる:
os.getenv("ENV_NAME")Python標準ライブラリからosをインポートするのを忘れないこと:
import os素晴らしい!環境変数を読み込む準備ができた。
ステップ #4: OpenAI Agents SDKのセットアップ
OpenAI Agents SDKを利用するには、有効なOpenAI APIキーが必要です。まだ生成していない場合は、OpenAIの公式ガイドに従ってAPIキーを作成してください。
このキーを入手したら、.envファイルに次のように追加する:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"必ず プレースホルダーを実際のキーに置き換えてください。
openai-agentsSDKはOPENAI_API_KEYenvからAPIキーを自動的に読み込むように設計されているため、追加の設定は必要ありません。
ステップ #5: ウェブアンロッカーAPIのセットアップ
まだの場合は、Bright Dataアカウントを作成してください。ログインしてください。
次に、Bright Data の公式 Web Unlocker ドキュメントを読み、API トークンを取得してください。または、以下の手順に従ってください。
Bright Dataの “User Dashboard “ページで、”Get proxy products “オプションを押してください:

製品テーブルで「unblocker」と書かれた行を探し、クリックする:

⚠️注意: Web Unblocker APIゾーンをまだ作成していない場合は、最初に新規作成する必要があります。Web Unblockerのセットアップドキュメントを参照してください。
unlocker “ページで、クリップボードアイコンを使ってAPIトークンをコピーします:

また、右上のトグルが「オン」になっていることを確認してください。これは、Web Unlocker製品がアクティブであることを示します。
Configuration “タブで、最適な効果を得るためにこれらのオプションが有効になっていることを確認してください:

.envファイルに以下の環境変数を追加する:
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN>"プレースホルダを実際のAPIトークンに置き換えてください。
完璧です!OpenAI SDKとBright DataのWeb Unlocker APIの両方をプロジェクトで使えるようになりました。
ステップ6:ウェブページコンテンツ抽出機能の作成
get_page_content()関数を作成する:
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN環境変数を読み込む- 指定された URL を使用して Bright Data の Web Unlocker API にリクエストを送信します。
- APIから返された生のHTMLを取得します。
- HTMLをMarkdownに変換して返します。
これが、上記のロジックを実装する方法である:
@function_tool
def get_page_content(url: str) -> str:
"""
Retrieves the HTML content of a given web page using Bright Data's Web Unlocker API,
bypassing anti-bot protections. The response is converted from raw HTML to Markdown
for easier and cheaper processing.
Args:
url (str): The URL of the web page to scrape.
Returns:
str: The Markdown-formatted content of the requested page.
"""
# Read the Bright Data's Web Unlocker API token from the envs
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN")
# Configure the Web Unlocker API call
api_url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN}"
}
data = {
"zone": "unblocker",
"url": url,
"format": "raw"
}
# Make the call to Web Uncloker to retrieve the unblocked HTML of the target page
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# Extract the raw HTML response
html = response.text
# Convert the HTML to markdown and return it
markdown_text = md(html)
return markdown_text注1: 関数は@function_tool でアノテーションされなければなりません。この特別なデコレータは、OpenAI Agents SDKに、この関数がエージェントによって特定のアクションを実行するためのツールとして使用できることを伝えます。この場合、関数はエージェントが操作するウェブページのコンテンツを取得するために利用できる “エンジン “として動作します。
注2:get_page_content()関数は、入力タイプを明示的に宣言しなければならない。
省略すると、次のようなエラーが発生します:レスポンスの取得に失敗しました:エラーコード:400 - {'error':エラーコード: 400 - {'error': {'message':"関数 'get_page_content' のスキーマが無効です:context=('properties', 'url')において、スキーマは'type'キーを持たなければなりません。
なぜ生のHTMLをMarkdownに変換するのか?答えは簡単で、パフォーマンス効率とコスト効率です!
HTMLは非常に冗長で、スクリプト、スタイル、メタデータなどの不要な要素を含むことが多い。AIエージェントが通常必要としないコンテンツです。エージェントがテキスト、リンク、画像のような必要不可欠なものだけを必要とするのであれば、Markdownはよりクリーンでコンパクトな表現を提供します。
詳細には、HTMLからMarkdownへの変換は、入力サイズを最大99%削減し、両方を節約することができます:
- OpenAIのモデルを使用する際のコストを下げるトークン
- より小さな入力に対してモデルがより速く動作するため、処理時間が短縮される。
より詳しい洞察は、記事 “なぜ新しいAIエージェントはHTMLよりMarkdownを選ぶのか?“をお読みください。
ステップ#7:データモデルの定義
OpenAI SDKのエージェントが正しく動作するためには、Pydanticモデルで出力データの構造を定義する必要があります。ここで、我々が構築しているエージェントは、3つの可能な出力のうちの1つを返すことができることを覚えておいてください:
- ページの要約
- 製品情報
- ニュース記事情報
そこで、対応する3つのパイダンティック・モデルを定義してみよう:
class Summary(BaseModel):
summary: str
class Product(BaseModel):
name: str
price: Optional[float] = None
currency: Optional[str] = None
ratings: Optional[int] = None
rating_score: Optional[float] = None
class News(BaseModel):
title: str
subtitle: Optional[str] = None
authors: Optional[List[str]] = None
text: str
publication_date: Optional[str] = None注意:オプションを使用することで、エージェントはより堅牢で汎用的になります。すべてのページがスキーマで定義されたすべてのデータを含むわけではないので、この柔軟性はフィールドが欠落したときのエラーを防ぐのに役立ちます。
タイピングから Optionalと Listをインポートすることをお忘れなく:
from typing import Optional, List素晴らしい!これでエージェントのロジックを構築する準備が整いました。
ステップ#8: エージェントロジックの初期化
openai-agentsSDKの Agentクラスを使用して、3つの特化したエージェントを定義します:
summarization_agent = Agent(
name="Text Summarization Agent",
instructions="You are a content summarization agent that summarizes the input text.",
tools=[get_page_content],
output_type=Summary,
)
product_info_agent = Agent(
name="Product Information Agent",
instructions="You are a product parsing agent that extracts product details from text.",
tools=[get_page_content],
output_type=Product,
)
news_info_agent = Agent(
name="News Information Agent",
instructions="You are a news parsing agent that extracts relevant news details from text.",
tools=[get_page_content],
output_type=News,
)各エージェント:
- 何をすべきかを説明する明確な命令文字列を含みます。これは、OpenAIエージェントSDKがエージェントの動作をガイドするために使用するものです。
get_page_content()を、入力データ(つまりウェブページの内容)を取得するツールとして使用する。- 先に定義したPydanticモデル
(Summary、Product、News)のいずれかで出力を返します。
ユーザーリクエストを適切な専門エージェントに自動的にルーティングするには、上位エージェントを定義します:
routing_agent = Agent(
name="Routing Agent",
instructions=(
"You are a high-level decision-making agent. Based on the user's request, "
"hand off the task to the appropriate agent."
),
handoffs=[summarization_agent, product_info_agent, news_info_agent],
) これは、AIエージェントのロジックを動かすために、run()関数で質問するエージェントです。
ステップ#9:実行ループの実装
run()関数に、以下のループを追加し、AIエージェントロジックを起動します:
# Keep iterating until the use type "exit"
while True:
# Read the user's request
request = input("Your request -> ")
# Stops the execution if the user types "exit"
if request.lower() in ["exit"]:
print("Exiting the agent...")
break
# Read the page URL to operate on
url = input("Page URL -> ")
# Routing the user's request to the right agent
output = await Runner.run(routing_agent, input=f"{request} {url}")
# Conver the agent's output to a JSON string
json_output = json.dumps(output.final_output.model_dump(), indent=4)
print(f"Output -> n{json_output}nn")このループは、ユーザの入力を継続的にリッスンし、各リクエストを適切なエージェント(サマリー、商品、ニュース)にルーティングして処理します。ユーザーのクエリとターゲットURLを結合し、ロジックを実行し、jsonを使用してJSON形式で構造化された結果を表示します。でインポートします:
import json驚きました!OpenAI Agents SDKとBright DataのWeb Unlocker APIの統合が完了しました。
ステップ10:すべてをまとめる
あなたのscraper.pyファイルには次の内容が含まれているはずです:
import asyncio
from agents import Agent, RunResult, Runner, function_tool
import requests
from pydantic import BaseModel
from markdownify import markdownify as md
from dotenv import load_dotenv
import os
from typing import Optional, List
import json
# Load the environment variables from the .env file
load_dotenv()
# Define the Pydantic output models for your AI agent
class Summary(BaseModel):
summary: str
class Product(BaseModel):
name: str
price: Optional[float] = None
currency: Optional[str] = None
ratings: Optional[int] = None
rating_score: Optional[float] = None
class News(BaseModel):
title: str
subtitle: Optional[str] = None
authors: Optional[List[str]] = None
text: str
publication_date: Optional[str] = None
@function_tool
def get_page_content(url: str) -> str:
"""
Retrieves the HTML content of a given web page using Bright Data's Web Unlocker API,
bypassing anti-bot protections. The response is converted from raw HTML to Markdown
for easier and cheaper processing.
Args:
url (str): The URL of the web page to scrape.
Returns:
str: The Markdown-formatted content of the requested page.
"""
# Read the Bright Data's Web Unlocker API token from the envs
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN")
# Configure the Web Unlocker API call
api_url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN}"
}
data = {
"zone": "unblocker",
"url": url,
"format": "raw"
}
# Make the call to Web Uncloker to retrieve the unblocked HTML of the target page
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# Extract the raw HTML response
html = response.text
# Convert the HTML to markdown and return it
markdown_text = md(html)
return markdown_text
# Define the individual OpenAI agents
summarization_agent = Agent(
name="Text Summarization Agent",
instructions="You are a content summarization agent that summarizes the input text.",
tools=[get_page_content],
output_type=Summary,
)
product_info_agent = Agent(
name="Product Information Agent",
instructions="You are a product parsing agent that extracts product details from text.",
tools=[get_page_content],
output_type=Product,
)
news_info_agent = Agent(
name="News Information Agent",
instructions="You are a news parsing agent that extracts relevant news details from text.",
tools=[get_page_content],
output_type=News,
)
# Define a high-level routing agent that delegates tasks to the appropriate specialized agent
routing_agent = Agent(
name="Routing Agent",
instructions=(
"You are a high-level decision-making agent. Based on the user's request, "
"hand off the task to the appropriate agent."
),
handoffs=[summarization_agent, product_info_agent, news_info_agent],
)
async def run():
# Keep iterating until the use type "exit"
while True:
# Read the user's request
request = input("Your request -> ")
# Stops the execution if the user types "exit"
if request.lower() in ["exit"]:
print("Exiting the agent...")
break
# Read the page URL to operate on
url = input("Page URL -> ")
# Routing the user's request to the right agent
output = await Runner.run(routing_agent, input=f"{request} {url}")
# Conver the agent's output to a JSON string
json_output = json.dumps(output.final_output.model_dump(), indent=4)
print(f"Output -> n{json_output}nn")
if __name__ == "__main__":
asyncio.run(run())出来上がり!たった100行以上のPythonで、あなたはAIエージェントを構築したのです:
- あらゆるウェブページのコンテンツを要約する
- あらゆるeコマースサイトから商品情報を抽出
- オンライン記事からニュースの詳細を引き出す
それを実際に見る時が来た!
ステップ#11: AIエージェントのテスト
AIエージェントを起動するには、以下を実行する:
python agent.pyここで、ブライト・データのAIサービス・ハブからコンテンツを要約したいとします。このようにリクエストを入力するだけだ:

以下は、得られるJSON形式の結果である:

今回は、PS5のリストのように、アマゾンの商品ページから商品データを取得したいとします:
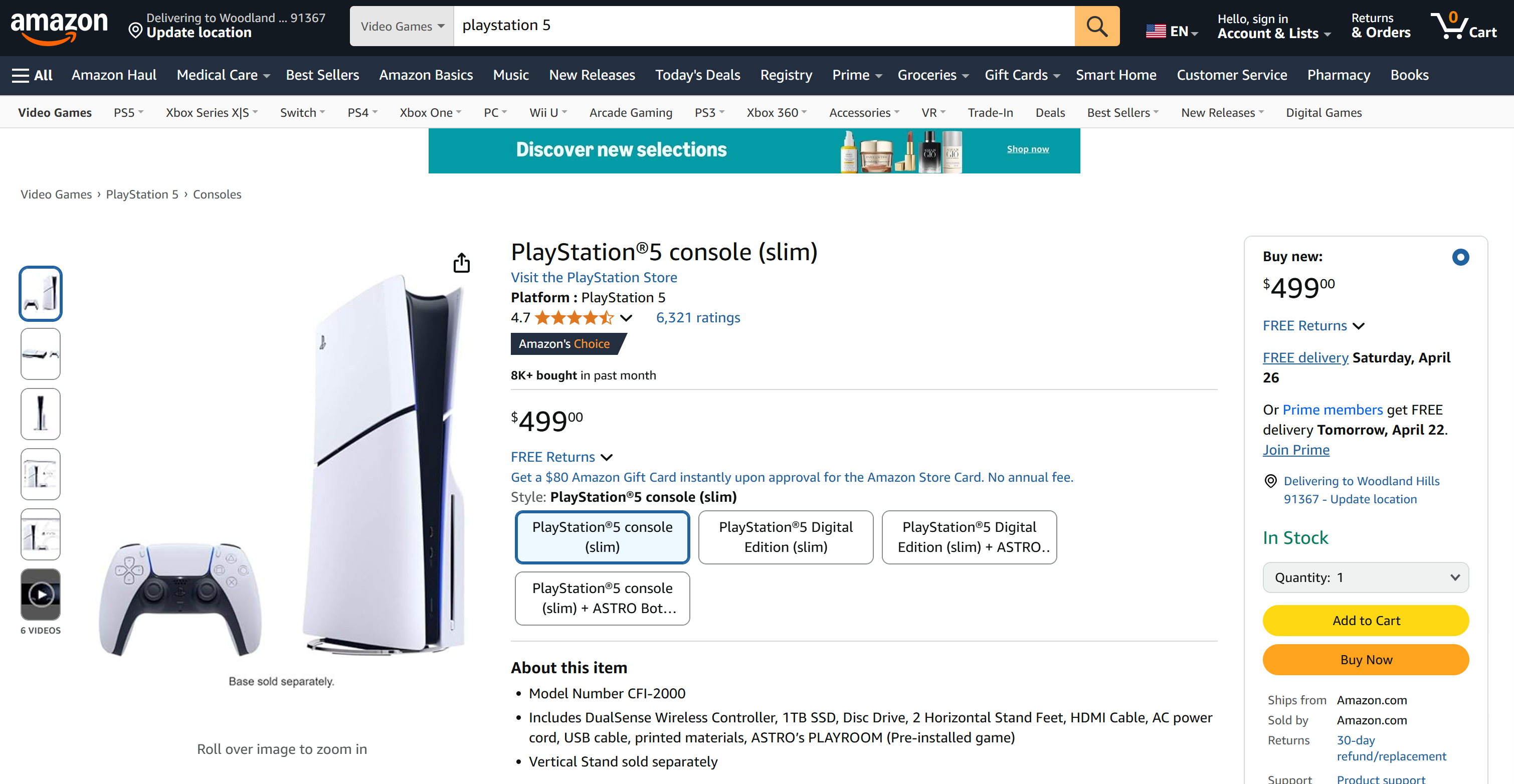
通常、AmazonのCAPTCHAやアンチボットシステムは、あなたのリクエストをブロックします。Web Unlocker APIのおかげで、あなたのAIエージェントはブロックされることなくページにアクセスし、解析することができます:

出力はこうなる:
{
"name": "PlayStationu00ae5 console (slim)",
"price": 499.0,
"currency": "USD",
"ratings": 6321,
"rating_score": 4.7
}これがアマゾンのページに掲載されている商品データだ!
最後に、ヤフーニュースの記事から構造化されたニュース情報を得たいと考えてみよう:

以下のインプットで目標を達成しよう:
Your request -> Give me news info
Page URL -> https://www.yahoo.com/news/pope-francis-dies-88-080859417.html結果はこうなる:
{
"title": "Pope Francis Dies at 88",
"subtitle": null,
"authors": [
"Nick Vivarelli",
"Wilson Chapman"
],
"text": "Pope Francis, the 266th Catholic Church leader who tried to position the church to be more inclusive, died on Easter Monday, Vatican officials confirmed. He was 88. (omitted for brevity...)",
"publication_date": "Mon, April 21, 2026 at 8:08 AM UTC"
}今回もAIエージェントは正確なデータを提供し、Web Unlockerのおかげでニュースサイトからのブロックはない!
結論
このブログポストでは、Pythonで非常に効果的なWebエージェントを構築するために、OpenAI Agents SDKとWebロック解除APIを組み合わせて使用する方法を学びました。
実証されたように、OpenAI SDKとBright DataのWeb Unlocker APIを組み合わせることで、本当にどんなウェブページでも確実に動作するAIエージェントを作成することができます。これは、Bright Dataの製品とサービスがどのように強力なAI統合をサポートできるかの一例に過ぎません。
AIエージェント開発のためのソリューションをご覧ください:
- 自律型AIエージェント:強力なAPIセットを使って、あらゆるウェブサイトをリアルタイムで検索、アクセス、対話。
- 業種別AIアプリ:信頼性の高いカスタムデータパイプラインを構築し、業種固有のソースからウェブデータを抽出します。
- 基礎モデル:ウェブスケールのデータセットにアクセスし、事前学習、評価、微調整を行うことができます。
- マルチモーダルAI:AIに最適化された世界最大の画像、動画、音声のリポジトリを利用できます。
- データプロバイダー:信頼できるプロバイダーと接続し、高品質でAIに対応したデータセットを大規模に調達。
- データパッケージ:構造化、エンリッチ化、アノテーションが施された、すぐに使えるデータセットを入手。
詳しくは、AI製品の全ラインナップをご覧ください。
ブライトデータのアカウントを作成し、AIエージェント開発のためのすべての製品とサービスをお試しください!






