

ビジネスデータは不完全であったり、一貫性がなかったり、コンテキストが欠けていたりすることが多く、戦略的な意思決定への有用性が制限されます。AIデータエンリッチメントは、信頼できる外部ソースを取り込むことによって生データを改善し、さまざまな業界にわたってより良い意思決定をサポートする実用的で高品質なデータセットを提供します。
本ガイドでは、AIデータエンリッチメントとは何か、従来の手法をどのように強化するのか、どのような分野で適用されているのか、効果的に実施する方法について説明する。
AIデータエンリッチメントとは?
AIデータエンリッチメントは、ファーストパーティーの記録を信頼できる外部属性で補強する。人工知能(AI)を用いてエンティティ解決(ER)、重複排除、スキーマ標準化を行い、手作業による検索を削減する。
例えば、営業チームは、企業リストにリーダーシップの詳細(CEO、創業者)、資金調達の最新情報、技術情報、確認済みの連絡先を追加する。財務チームは、顧客プロファイルを信用情報機関の属性や取引パターンと組み合わせます。これにより、営業部門はより正確なセグメンテーション、よりスマートなルーティング、より信頼性の高いスコアリングを、財務部門はより強力なリスク評価を行うことができる。
健全なデータガバナンス、バイアスのチェック、継続的なモニタリングが実施されていれば、カバレッジを拡大し、フィーチャーの質を向上させることで、エンリッチメントはダウンストリームモデルを強化し、典型的な「ガベージイン、ガベージアウト」の影響を軽減します。
AIが従来のデータエンリッチメントを強化する方法
従来のデータエンリッチメントは、手作業による調査、ルックアップテーブル、スプレッドシート式、または基本的なETLスクリプトに大きく依存しており、時間がかかり、エラーが発生しやすく、拡張が困難でした。自動化されたツールの中には部分的な拡張性を提供するものもあったが、多様なデータソースへの適応性に欠けていた。AIは、より速く、より正確で、スケーラブルなエンリッチメントを提供する高度なテクノロジーを活用することで、このプロセスを変革する:
- パターン認識とソース・ランキング機械学習(ML)モデルは、欠落フィールドをインポートするためのパターンを識別し(例えば、類似のレコードから役職を予測する)、網羅率、精度、鮮度によってデータソースをランク付けする。例えば、MLは古いデータベースよりも検証済みのLinkedInプロフィールを優先することができる。
- 非構造化テキスト処理。自然言語処理(NLP)と名前付きエンティティ認識(NER)は、ソーシャルメディアや企業ウェブサイトのような非構造化ソースから、エンティティ(名前や組織など)、トピック、センチメント、購買シグナルを抽出する。
- 文書理解。光学式文字認識(OCR)とレイアウト分析により、請求書、契約書、フォームなどの文書を構造化されたフィールドに変換します。AI主導のインテリジェント・ドキュメント・プロセッシング(IDP)は、表や複数カラム形式などの複雑なレイアウトを識別します。
- 同期と鮮度。AIは複数のAPIとデータセットを調整し、バックオフ・メカニズム、重複排除、検証を使用して、リアルタイムのデータ鮮度を確保します。
これらの技術は、より速く、より正確なエンリッチメントを提供し、フィールドをクリーンなスキーマに正規化し、壊れやすいルールセットなしでリアルタイムのデータ鮮度を維持する。
注– 最新のエンリッチメントは、LLMを利用した抽出と、古典的なマスターデータ管理/抽出-ロード-変換(MDM/ELT)を組み合わせています。チームは信頼できる外部データ(マーケットプレイス+ウェブスクレイピング)を入手し、それをLLMで構造化フィールドに変換し、エンティティを単一のゴールデンレコードに解決し、データ品質チェックを実施し、データウェアハウスとベクトルデータベース+検索拡張世代(RAG)を介して結果を提供します。
業界横断的な使用例
AIデータエンリッチメントは、ほぼすべての分野で価値を提供します。主な用途をご紹介します:
- マーケティングとセールス。人口統計学的、企業統計学的、および行動データ(職種、購買履歴、ソーシャルメディア活動など)を使って顧客プロファイルを充実させ、セグメンテーションを洗練させ、リードスコアリングを改善し、推奨をパーソナライズする。
- 金融サービス。取引履歴を外部シグナル(ニュース、公的提出書類、代替信用データなど)と統合し、リスク評価、詐欺検出、AMLモデルを強化すると同時に、責任ある信用供与を調整する。
- ヘルスケア。EHR データを非識別化された母集団やライフスタイルのデータセットと組み合わせて、再入院を予測し、ケアをパーソナライズする。
- 小売業とeコマース。POSやカタログデータと外部要因(天候、競合他社の価格設定など)を統合し、需要予測、在庫管理を最適化し、在庫切れを削減する。
実践的な実装 – AIエンリッチメント・システムの構築
ここでは、企業名のリスト(入力またはCSVでアップロード)を処理して包括的なビジネスインテリジェンスを提供する企業データエンリッチメントシステムの構築方法を説明します。
3つのコア・コンポーネントが必要です:
- ウェブ・インターフェース。ユーザーが会社名を入力したりCSVファイルをアップロードするための、Streamlitを使用したシンプルなフロントエンド。
- データ収集。Bright DataのWeb Scraper APIを使用して、ウェブからリアルタイムの公開データを収集します。
- AI処理 Google Geminiのような大規模言語モデル(LLM)が、生のページを解析し、構造化されたフィールド(CEO、本社、最近のニュース、資金調達ラウンドなど)を抽出します。
仕組み
フローは以下の通り:
- 入力の検証。Streamlitのテキスト入力またはCSVアップロードで企業名を受け付ける。
- データスクレイピング。Bright DataのWeb Scraper APIを使って、各企業の公開データを収集する。
- AI抽出。ページテキストを正規化し、スキーマに一致する厳密なJSONオブジェクトを返すようGeminiに要求します。
- データ処理。JSON出力をクリーンアップし、検証します。
- エクスポート。ソート、フィルタリング、ダウンロードなどのオプションを使用して、結果をインタラクティブなテーブルとしてStreamlitに表示する。
AI Company Enrichmentのレポにある完全なコードをチェックしてください。サンプル・インターフェースはこちらです:
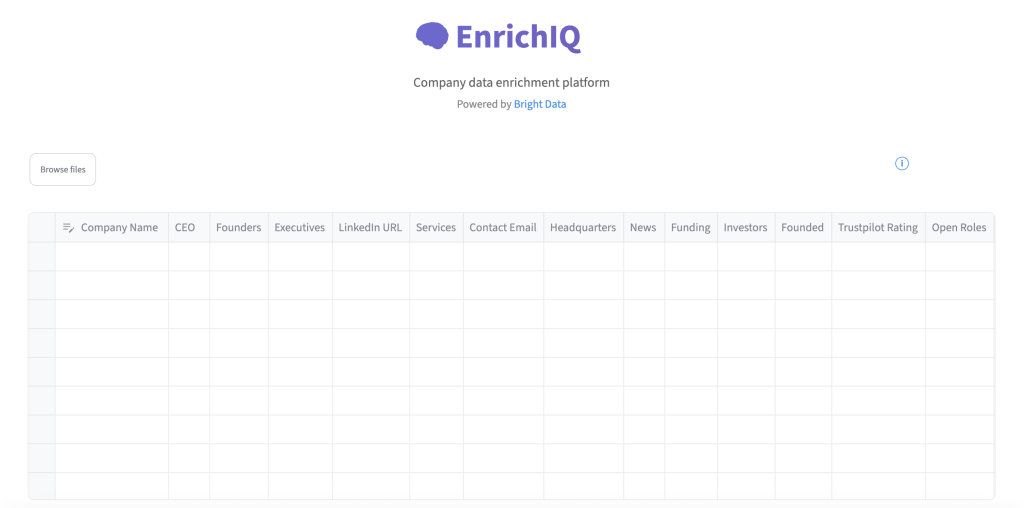
これで準備完了です!
課題とベストプラクティス
効果的なAIデータエンリッチメントには、主要な課題に対処するための慎重な計画が必要です:
- データ品質の問題。データ品質の問題。一貫性のない、不完全な、または偏ったデータは、AIモデルを弱体化させ、信頼性の低い予測につながる可能性がある。不十分なガバナンスはこれらのリスクを悪化させる。エンリッチメント前のデータクリーニングと検証は、正確性と公平性を確保するために非常に重要である。
- 統合の課題。多くのAIプロジェクトは、エンリッチされたデータと既存システムとの統合が困難なために失敗している。シームレスなワークフローには、堅牢なツールと計画が必要である。
- コンプライアンス要件。GDPRのような規制では、合法的根拠、目的の限定、保存期間の定義が要求され、CCPA/CPRAではデータの最小化と透明性が重視される。コンプライアンス違反は、罰金や風評被害のリスクとなる。
- インフラの信頼性。データパイプラインは、中断のないAIワークフローをサポートするために、高いアップタイムを維持し、利用制限を管理する必要がある。ダウンタイムやボトルネックは、モデルのトレーニングやデプロイメントを中断させる可能性があります。Bright Dataのプラットフォームは、99.99%のネットワークアップタイムを提供し、中断のないデータフローを実現します。
ベストプラクティス
- 信頼性とコンプライアンスに優れたインフラを選択する。実績のあるアップタイム(理想的には99.9%以上)とGDPRやCCPAのような規制に準拠したプラットフォームを選択する。データ量や特定のAIニーズなどのユースケースに基づいて複数のプロバイダーを評価し、倫理的なデータ調達方法を確認する。
- 検証と異常検知を実施する。自動化ツールを使用して、エンリッチメントの前に不整合、重複、異常値をチェックする。これにより、高品質な入力が保証され、AIモデルにおける下流のエラーが減少する。
- 詳細な文書化を維持する。データソース、目的、保持ポリシーを文書化し、トレーサビリティとコンプライアンスを確保する。これは、監査やAIシステムの信頼構築に不可欠である。
- 多様なデータソースを活用する。エンリッチメントを簡素化するために、評判の高いデータマーケットプレイスや 既製のデータセットを探索する。品質、コスト、AIの目標との関連性についてプロバイダーを比較し、既成のオプションがニーズを満たさない場合はカスタムデータ収集を検討する。
結論
AIデータエンリッチメントは、生データを競争力に変え、よりスマートな意思決定、顧客体験の向上、収益成長を促進する。データ品質、統合、コンプライアンス、インフラストラクチャなどの課題に取り組むことで、企業はAIの可能性を最大限に引き出します。Bright Dataは、信頼性の高いインフラストラクチャと高品質のデータセットでこの旅をサポートし、お客様が洞察に集中できるようにします。
次のステップ
AIデータエンリッチメントをマスターするには、Bright Dataの強力なツールとサポートをご活用ください:
- シームレスなデータアクセスのための高度なWeb Access APIでAIモデルを強化します。
- AIをウェブに接続し、毎月5,000件のMCPリクエストを無料で利用できる究極のMCPツールをご利用ください。
- 数十億レコードの収集済みデータセットを使用して、高品質なデータを提供します。
- n8nやCrewAIのようなAIプラットフォームと統合し、AIエージェントを接続、構築します。
- ブライトデータのブログページでAIデータソリューションの詳細をご覧ください。
専門家によるガイダンスについては、Bright Dataのサポートチームにお問い合わせください。






