

このブログ記事では、以下の内容について理解できます:
- データセットとは何か、その利点、仕組み、使用するべき場面、そして高品質で信頼性の高いデータセットの入手先について。
- ウェブスクレイピングAPIとは何か、その利点、仕組み、活用するべき場面、そしてスケーラブルなものの入手先について。
- ガイド付きの例を通じて、類似シナリオで両方を使用する方法について。
- データセットとウェブスクレイピングAPIの比較、およびニーズに応じてどちらが優れているかについて。
- 両方を併用することが合理的かどうかについて。
それでは始めましょう!
データセットの世界を掘り下げる
データセットとウェブスクレイピングAPIの比較ガイドを、データセットの紹介から始めます。
データセットとは何か?
データセットとは、分析、処理、再利用のために整理された構造化された情報の集合体です。通常、CSV、JSON、SQLなどの形式で保存され、テキスト、数値、画像、動画、その他の種類のデータを含むことができます。
ほとんどのデータセットは、B2B、小売など、特定のトピック、業界、市場、または関心分野に焦点を当てています。この絞り込まれた焦点により、企業や研究者はインサイトを抽出し、トレンドを特定し、仮定ではなく実際のデータに基づいた意思決定を支援できます。
データセットは一般的に、特定の時点で収集されたデータの静的なスナップショットとみなされます。ただし、優れたデータセットプロバイダーの多くは、基礎となるデータソースから更新された情報を取得することで、定期的に更新されたレコードを受け取るサービスを提供しています。
具体的に、データセットが提供する3つの主な利点は次のとおりです:
- すぐに使える:事前に収集・構造化されたデータで、分析、AI、またはビジネスアプリケーションにすぐに使用可能。技術的な知識は不要です。
- コスト効率:社内でのデータ収集とエンジニアリングリソースの必要性を削減します。
- スケーラビリティ:業界全体で数百万〜数十億件のレコードをカバーする大規模なデータセットへのアクセスを提供します。
データセットの仕組み
現代のデータセットの多くはウェブを起源としており、ウェブは地球上で最大かつ最新の公開情報源です。ウェブサイト、マーケットプレイス、ソーシャルメディアプラットフォーム全体で新しいデータが継続的に生成されています。
データセット作成プロセスには、以下のステップが含まれます:
- データ収集:情報は1つまたは複数のソースから収集されます。最も一般的なのは、ウェブスクレイピング、API、または公開フィードを介したウェブサイトです。ユースケースに応じて、商品リスト、価格、レビュー、求人投稿、ソーシャルメディアコンテンツ、または企業データが含まれる場合があります。
- データクリーニングと検証:生データは多くの場合、乱雑で不完全、または重複しています。このステップでは、エラーを除去し、フォーマットを標準化し、欠損値を処理します。データは精度と一貫性を確保するために検証されます。
- データ構造化:クリーニングされたデータは、CSV、JSON、Parquetなどの一貫したフォーマットに整理されます。これにより、クエリのためのデータベースやデータウェアハウスへの保存が容易になり、データ分析やAIワークフローでの使用が可能になります。
これらのステップは技術的には社内で実施できますが、通常はデータセットプロバイダーに委託されます。大規模なデータの収集と処理には専門的なツールと専門知識が必要なためです。一部のデータセットには数十億件のレコードが含まれることも忘れないでください。
処理後、データセットプロバイダーはさまざまな配信方法でデータを配布します。小規模なデータセットの直接ダウンロード、S3インテグレーション、APIベースのアクセスなどが含まれます。
注記:すべてのデータセットがウェブから生まれるわけではありません。一部は、調査、研究、センサー、社内システム、または複数のソースの組み合わせによって作成されます。例えば、公開オープンデータと独自情報または非公開情報を組み合わせる場合があります。
ユースケース
以下は、企業、中小企業、個人、および公共部門におけるデータセットの最も関連性の高いシナリオです:
- AIモデルのトレーニング:データセットは機械学習とAIトレーニングプロセスの中核にあります。モデルに大量の高品質データを供給することで、言語理解、画像認識、推薦、予測などのパターンと能力を学習します。
- 市場トレンド分析:過去の市場データを分析して業界トレンドを研究し、顧客行動を理解します。仮定ではなく実際の外部データに基づいて製品アイデアを検証し、戦略的意思決定を支援します。
- ソーシャルメディア分析:ユーザー行動、エンゲージメント、センチメントに関するインサイトを抽出します。Reddit、Facebookなどのプラットフォームでブランドを監視し、オーディエンスを分析し、インフルエンサーを特定し、コンテンツパフォーマンスを評価します。
- ビジネスインテリジェンスと意思決定:価格、競合他社、市場シグナルを調査して機会を発見し、リソース配分を最適化し、戦略的意思決定を改善します。
- 採用と人材インテリジェンス:労働市場データを分析して候補者を見つけ、採用トレンドを把握し、スキル需要を評価し、競合他社の労働力構造をマッピングして採用戦略を改善します。
- 製品開発とユーザーエクスペリエンスの最適化:ユーザーレビュー、フィードバック、行動データを分析して製品を改善します。機能を改良し、エクスペリエンスをパーソナライズし、ユーザージャーニーを最適化して満足度とリテンションを向上させます。
更新済み・構造化・AI対応データセットの入手先
主要なデータセットマーケットプレイスの中で、Bright Dataは大規模なウェブ
データインフラと即使用可能なビジネスグレードのデータセットを組み合わせ、第1位にランクされています。
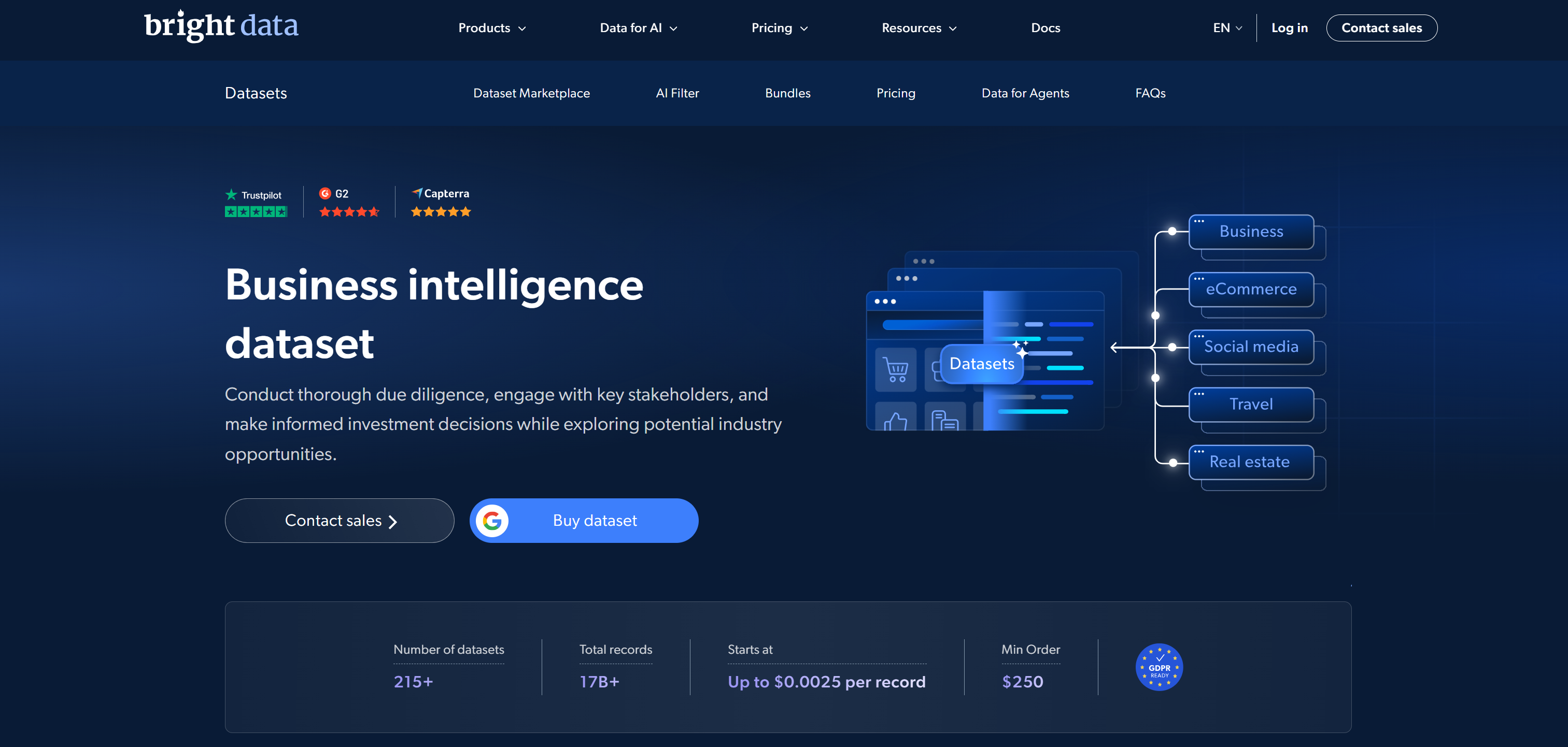
そのデータセットマーケットプレイスは、350以上のウェブドメインから事前収集されたデータセットを提供しており、合計170億件以上のレコードを含みます。Eコマース、ソーシャルメディア、不動産、金融、プロフェッショナルネットワーク、その他多くの業界をカバーしています。データセットはクリーニング、構造化、標準化され、AIとMLに最適化されています。JSON、CSV、Parquet、NDJSONなどの形式で配信されます。
Bright Dataのデータセットは、データフィールドに適用される基準を含む複数の次元でフィルタリングすることで、高度に絞り込まれた目標に合わせてカスタマイズすることもできます。AI搭載の追加フィルタリング層により、ユーザーは自然言語クエリを使用して大規模なデータセットを絞り込むことができ、データ選択がより使いやすくなります。
データはAPIアクセス、Amazon S3、Snowflake、Webhook、クラウドストレージインテグレーション、直接ダウンロードなど複数のチャネルで配信されます。この柔軟性により、軽量なユースケースからエンタープライズ規模のパイプラインまで対応できます。
Bright DataのデータセットはGDPRおよびCCPAコンプライアンス基準に準拠しています。また、公開データの信頼性と倫理的なソーシングを保証する検証、セキュリティ、品質管理プロセスによっても支援されています。
価格は、ボリュームと更新頻度(月次、四半期、または半年ごと)に応じて、データセットあたり250ドル(10万件のレコード)から始まります。
ウェブスクレイピングAPIの概要
データセットとは何か、いつ使用するかを理解したところで、ウェブスクレイピングAPIの同様の側面を探る準備が整いました。
ウェブスクレイピングAPIとは何か?
ウェブスクレイピングAPIは、独自のスクレイピングインフラを管理することなく、ウェブサイトからデータを抽出できるサービスです。対象ウェブページの取得、アンチスクレイピングおよびアンチボット保護のバイパス、結果の構造化フォーマットへのパースなどのタスクを処理します。
ウェブスクレイピングAPIは、Eコマースプラットフォーム、検索エンジン、ソーシャルメディアサイトなど、特定のウェブサイトやデータソースを対象とする傾向があります。より汎用的なものや、AIを通じて拡張してあらゆるウェブサイトから構造化データを返せるものもあります。これにより、企業や開発者は関連するオンラインソースからライブまたはオンデマンドのデータを取得できます。
特に、ウェブスクレイピングAPIの3つの主要な利点は次のとおりです:
- リアルタイムデータアクセス:必要なときにウェブサイトから最新情報を直接取得します。
- インフラ管理不要:スクレイパー、プロキシ、アンチボットシステムの構築・維持が不要です。
- スケーラビリティ:数百〜数千ページからのデータを確実かつ効率的に収集できます。
ウェブスクレイピングAPIの仕組み
ウェブスクレイピングAPIの内部的な動作は次のとおりです:
- リクエスト処理:ユーザーが対象ウェブページのURLを指定してAPIにリクエストを送信します。基礎となるスクレイピング動作をカスタマイズするための引数(JavaScriptレンダリング、IP位置情報など)を含めることができます。
- ページ取得とアクセス管理:APIはJavaScriptレンダリング、プロキシ、レート制限、CAPTCHA、その他のアンチボット保護などの技術的課題を処理しながら対象ウェブページを取得します。
- データ抽出とパース:生のHTMLまたはレスポンスコンテンツが処理され、構造化フォーマット(JSON、CSVなど)に変換されます。事前定義されたテンプレートを使用するAPIもあれば、AIを活用して任意のウェブページから構造化フィールドを動的に抽出するAPIもあります。
- データ配信:最終的な構造化データはAPIレスポンスを通じてユーザーに返されます。オプションで、さらなる処理のためにS3、Webhook、データベースなどのストレージシステムにプッシュすることもできます。
ユースケース
ウェブスクレイピングAPIが違いをもたらす最も重要なシナリオを以下に示します:
- 市場調査と競合追跡:競合他社のウェブサイト、価格変動、商品の在庫状況を監視します。トレンドが生まれる瞬間に把握し、常に変化する市場シグナルに基づいてビジネス戦略を適応させます。
- 財務意思決定:株価、暗号通貨の動き、企業アップデートなどのライブ市場データを抽出します。ストリーミングアップデートに依存した取引戦略、投資分析、リスク管理を支援します。
- Eコマース監視と価格最適化:複数のプラットフォームにわたって商品リスト、在庫レベル、価格変動を追跡します。頻繁に更新されるウェブデータを使用して動的価格設定、お得な情報の発見、カタログ最適化を実現します。
- ニュースとイベント監視:複数のソースから速報ニュース、規制アップデート、業界アナウンスを収集します。状況認識を向上させ、市場や政策の変化への迅速な対応を支援します。
- リード生成とセールスインテリジェンス:ディレクトリ、企業ウェブサイト、プロフェッショナルプラットフォームから最新のビジネスおよび連絡先データを抽出します。新しい見込み客を特定し、常に更新される情報でセールスパイプラインを充実させます。
- ブランド監視とレピュテーション追跡:AIチャットボットや検索エンジンでの言及を観察します。フォーラム、ソーシャルメディア、ニュースサイト全体でのレビューやディスカッションからのセンチメントを追跡します。センチメントの変化を早期に検出し、レピュテーションリスクや機会に迅速に対応します。
- AIエージェントのグラウンディングとウェブアクセス:AIエージェントにウェブスクレイピングAPIへの直接アクセスを提供し、オンデマンドでコンテキストに即した最新の外部データを取得できるようにします。これによりグラウンドされた推論が可能になり、幻覚を減らし、エージェントがオンラインで利用可能な最新情報に基づいて行動できるようになります。
ウェブスクレイピングAPI:最良のプロバイダーはどこか?
Bright DataはウェブスクレイピングAPIの最良プロバイダーとして浮上しています。大規模なプロキシネットワークと、信頼性が高くコンプライアントでスケーラブルなデータ抽出のために構築された包括的なWeb Scraper APIエコシステムを組み合わせています。
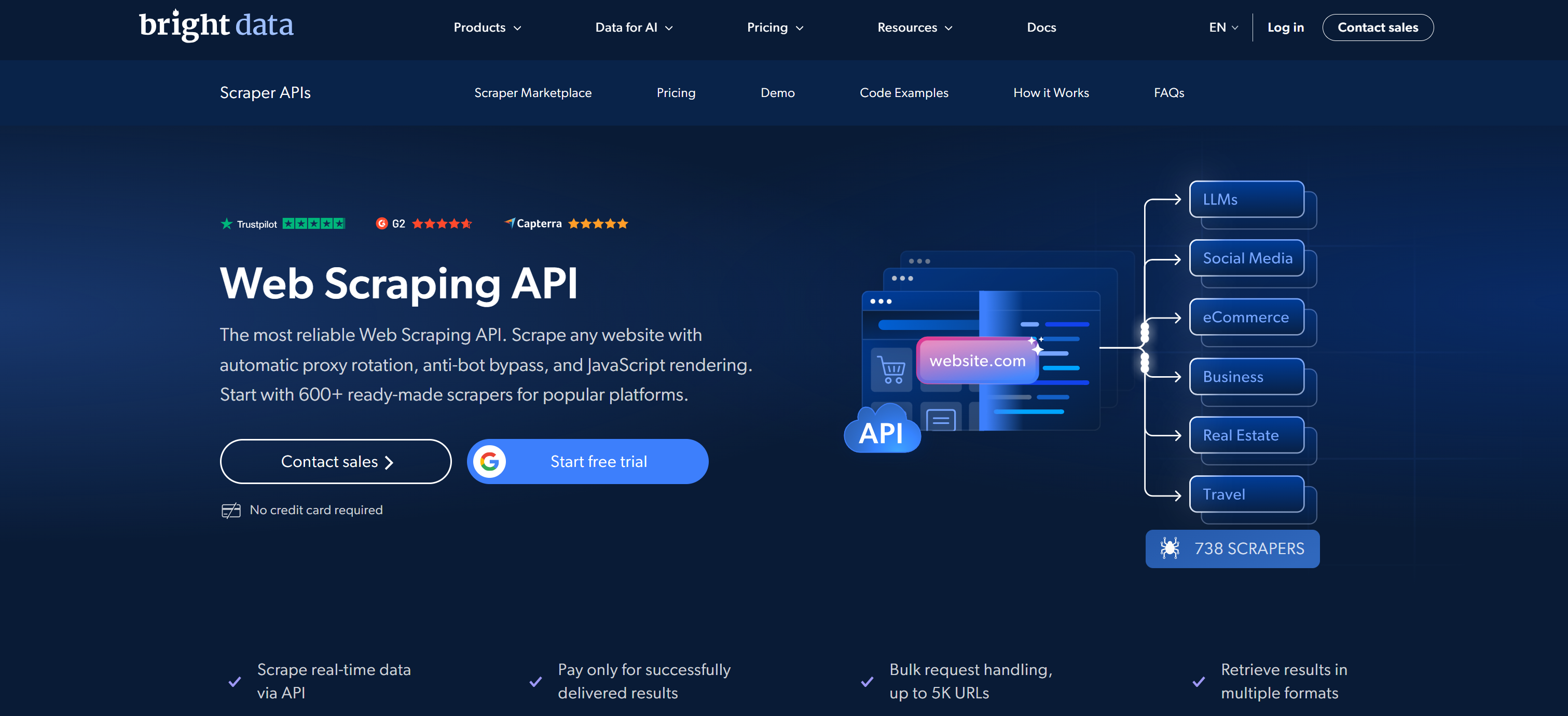
そのWeb Scraper APIライブラリは、主要なデータソースをカバーする600以上の既製スクレイパーをサポートしています。Amazon、LinkedIn、X/Twitter、Instagram、TikTok、YouTube、Walmart、Zillow、Indeed、Glassdoor、Booking、Airbnb、Yelp、Yahoo Finance、Facebookなどが含まれます。これらのスクレイピングAPIにより、JSON、NDJSON、またはCSVでドメイン固有の構造化データを直接抽出できます。
Bright Dataが際立っている点は、195か国にわたる4億以上のレジデンシャルIPのグローバルネットワークという基盤にあります。これにより、SLAに裏付けられた99.99%の稼働率と99.95%のリクエスト成功率を持つ大規模なエンタープライズ対応アーキテクチャが実現されます。
Bright DataのWeb Scraper APIは、プロキシローテーション、CAPTCHAの解決、JavaScriptレンダリング、レート制限、アンチボットバイパスなど、スクレイピングのライフサイクル全体を自動的に処理します。バルクリクエスト(ジョブあたり最大5,000URL)、スケジュールスクレイピング、柔軟な配信パイプラインもサポートしています。
価格は使用量ベースで、成功したリクエストに対してのみ支払います。従量課金制モデルは1,000レコードあたり1.5ドルから始まり、企業向けにいくつかのサブスクリプションベースのプランが利用可能です。
実際のシナリオにおけるデータセットとウェブスクレイピングAPI
データセットまたはウェブスクレイピングAPIを使用してデータを取得する方法を理解するために、同じ高レベルのユースケースを考えてみましょう。クライアントの見込み客開拓と、AIを活用したライブ企業分析のそれぞれの目的で、CrunchbaseからCrunchbaseの企業データを抽出したいとします。
最初のユースケースにはCrunchbaseデータセットが必要で、2番目にはCrunchbaseウェブスクレイピングAPIが必要です。次の2つの章では、Bright Dataのソリューションを使用して両方の種類のデータにアクセスする方法を説明します。
注記:以下のガイドセクションの前提条件として、Bright Dataアカウントをすでに持っている必要があります。そうでない場合は、新しいアカウントを作成してください。
Bright Dataのデータセットを始める
このステップバイステップのセクションでは、Bright DataからCrunchbaseデータセットをすぐに取得する方法を説明します。
ステップ#1:Crunchbaseデータセットにアクセスする
Bright Dataアカウントにログインすることから始めます。コントロールパネルで、「データセット」メニューの「データセットマーケットプレイス」オプションを選択します。
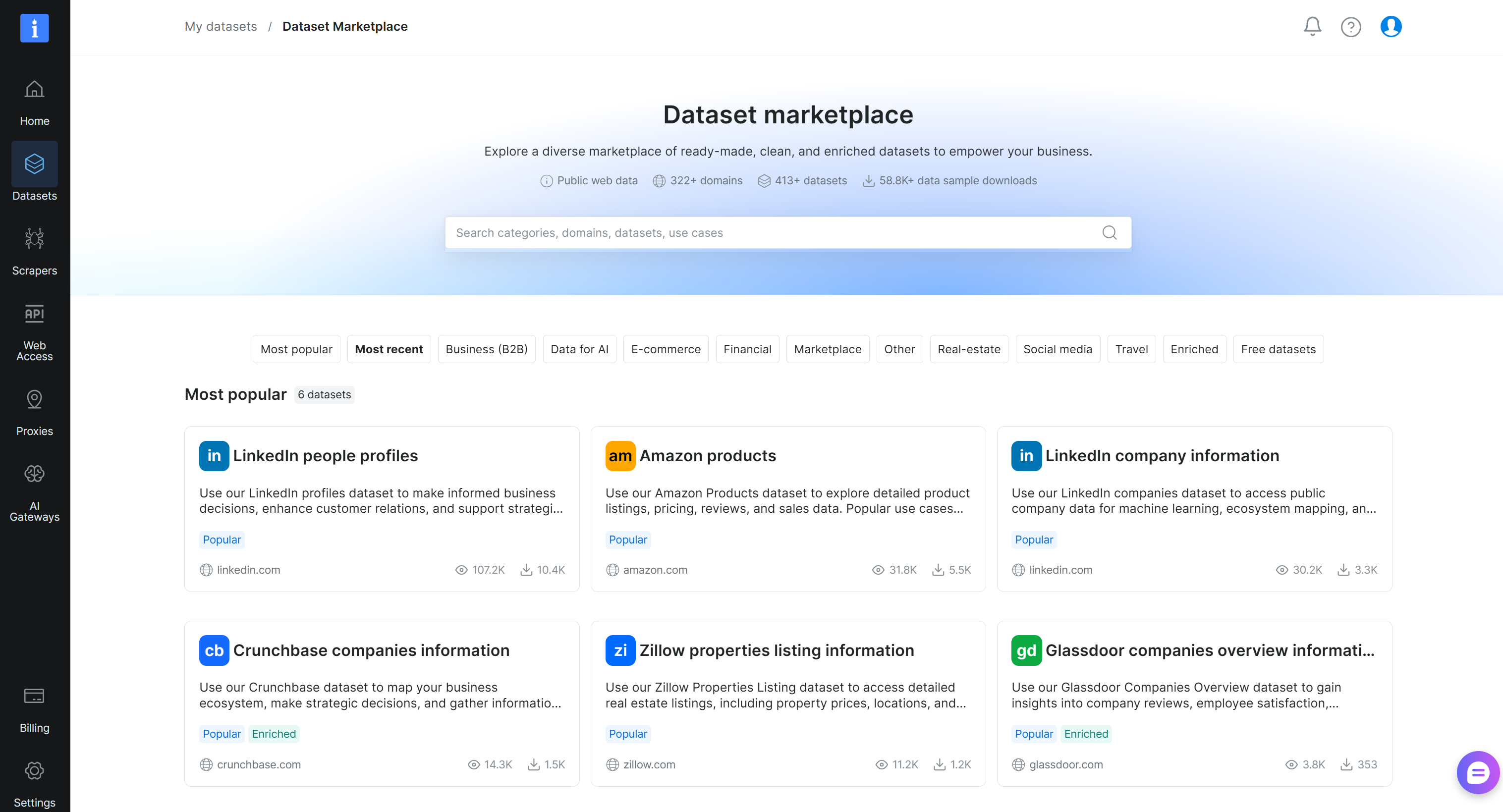
「マイデータセット」ページで「データセットマーケットプレイス」タブに移動すると、このページが表示されます:
「crunchbase」を検索し、「Crunchbase companies information」データセットを選択します:
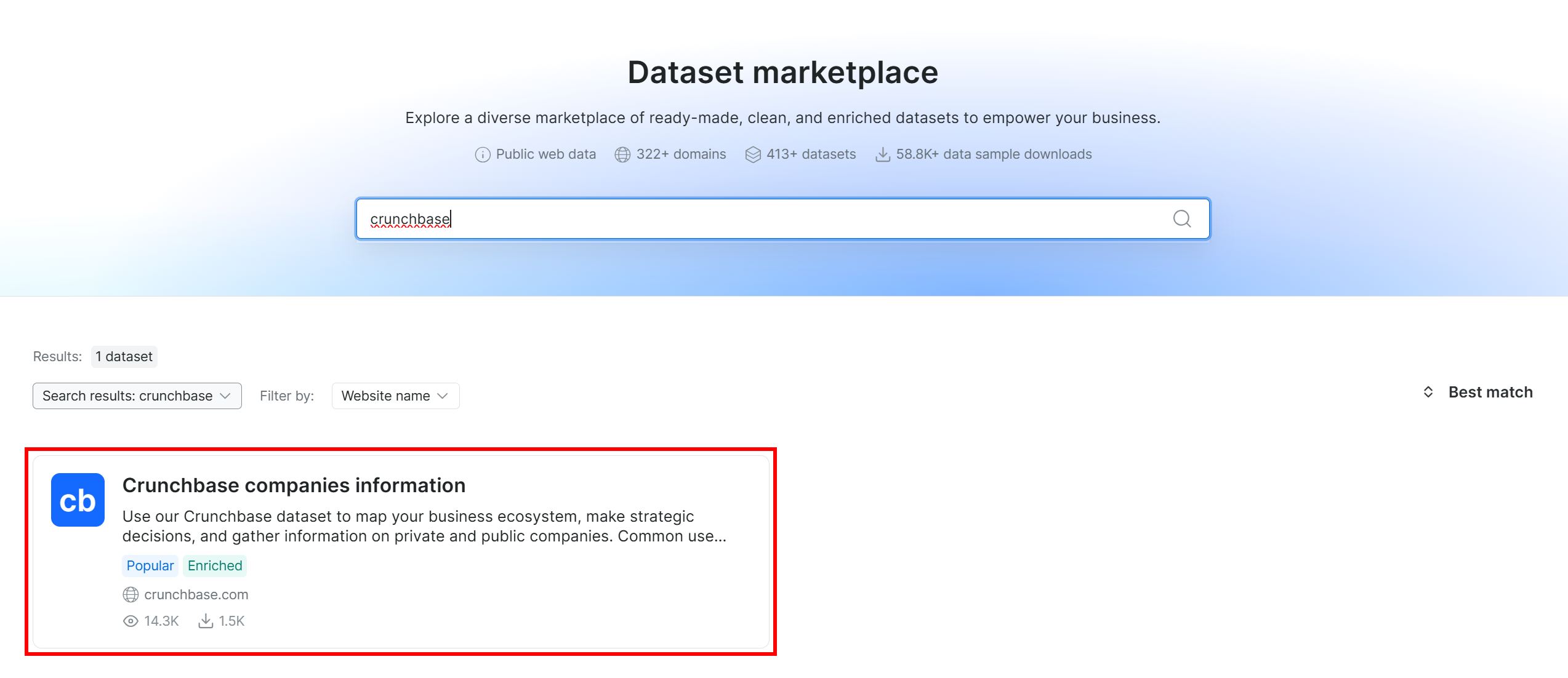
その後、「Crunchbase companies information」データセットページに移動します。
ステップ#2:データセットに慣れ親しむ
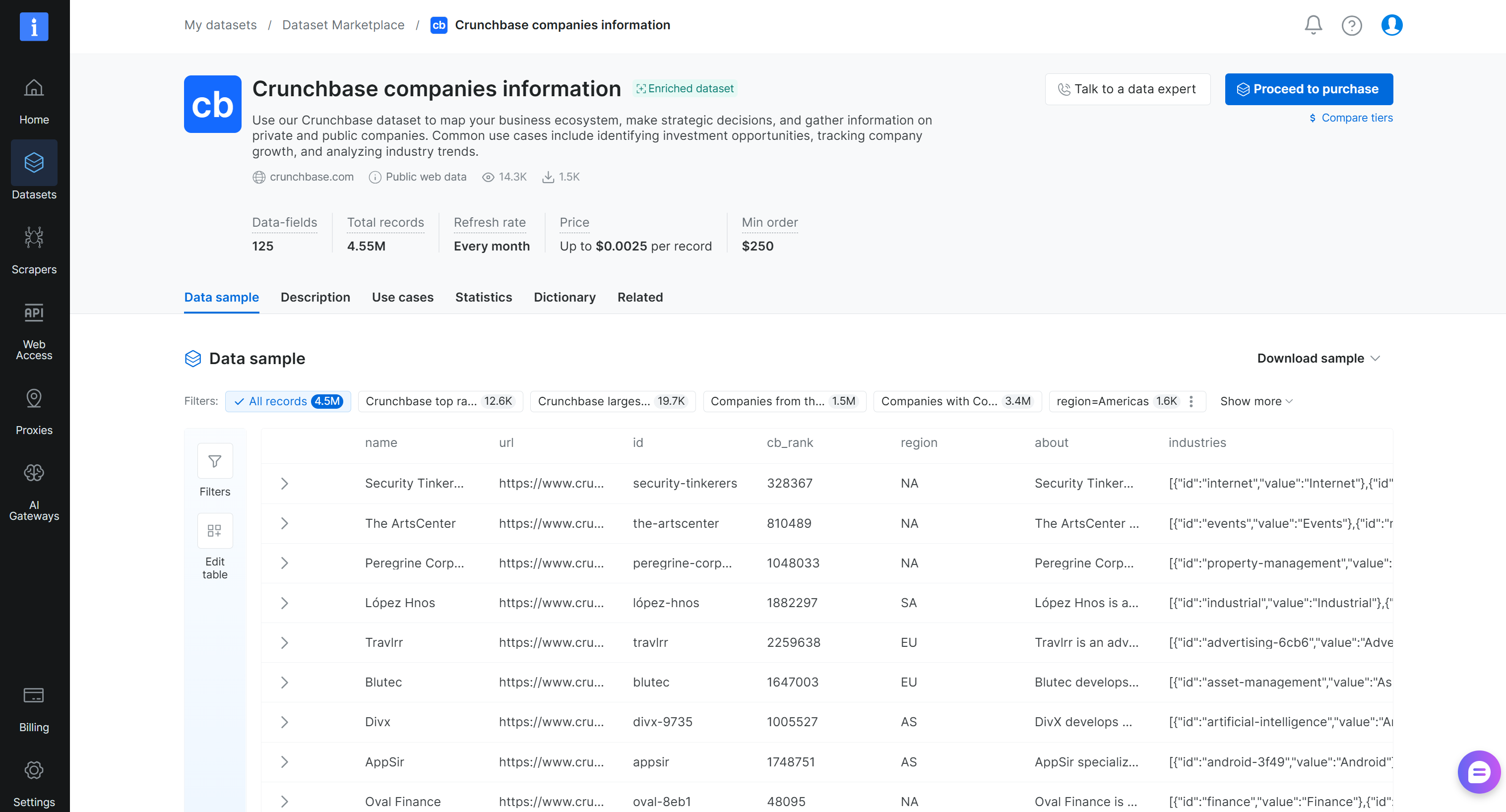
「Crunchbase companies information」データセットページでは、データセットを探索できます。具体的には、サンプルレコードにアクセスし、既製のサブセット(例えば、上位ランクのCrunchbase企業)を閲覧し、フィールドの充填率などの主要統計を確認できます。また、フィールド名、タイプ、説明を含む完全なデータ辞書を表示し、データセットを絞り込むためのフィルターを適用することもできます。
左側の「フィルター」ボタンをクリックすると、次のモーダルが開きます:
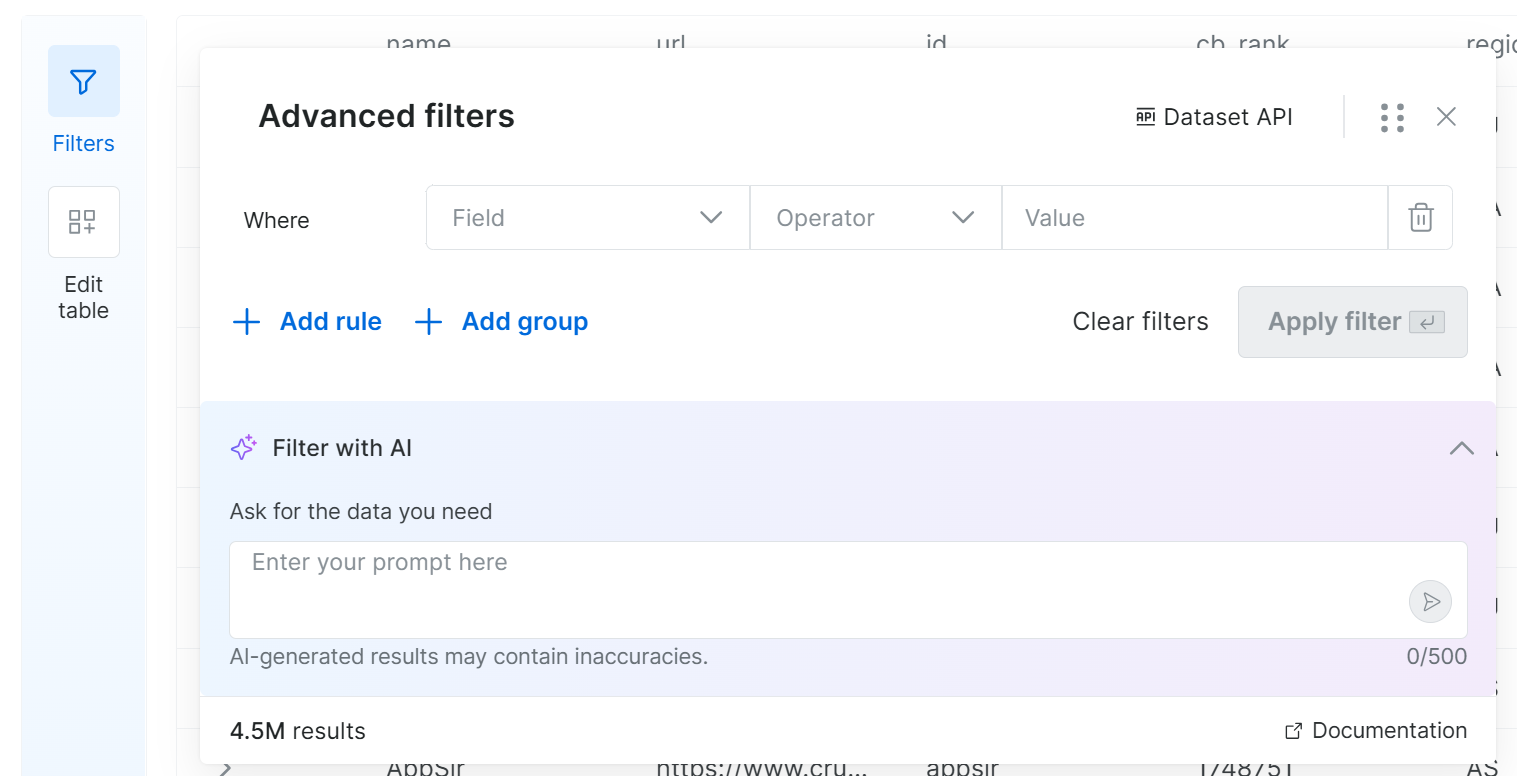
この機能を使用すると、選択したフィールドに1つ以上の条件を設定してフィルターを定義できます。または、自然言語でプロンプトを入力するだけで、システムが自動的にフィルターを生成します。素晴らしい!
ステップ#3:データセットを購入する
特定のユースケース向けにデータをフィルタリングした後(またはそのままにして)、「購入に進む」ボタンを押します:

次に、データセットのスナップショットサイズを定義し、更新頻度を選択します:
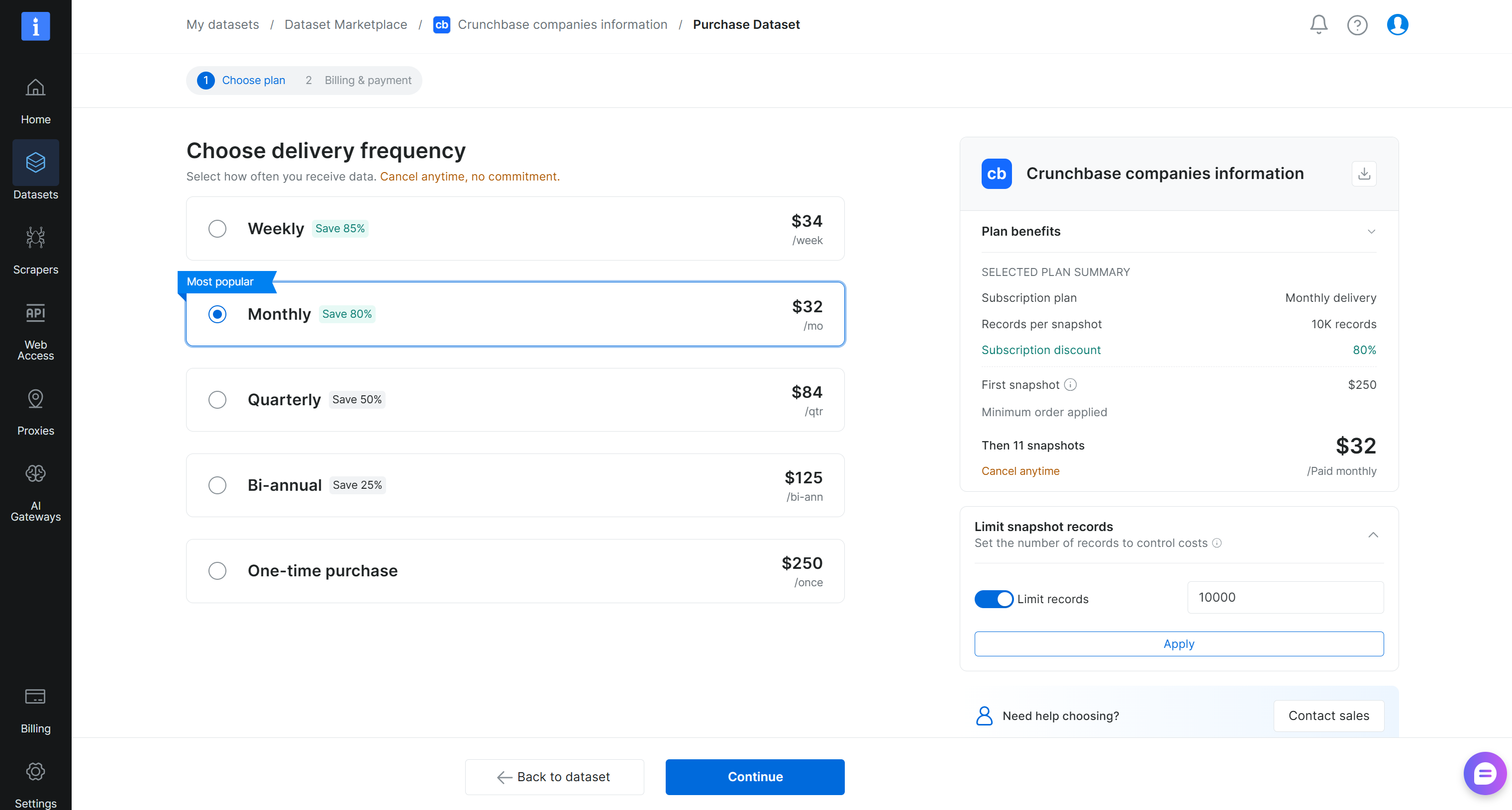
この例では、10,000件のレコードをすぐに配信し、その後11回の継続的な月次更新を含むように配信を設定しました。「続行」をクリックし、支払い情報を追加してチェックアウトプロセスを完了します。
ステップ#4:受け取ったデータセットを探索する
データセットの準備ができると、メール通知が届き、Bright Dataコントロールパネルからダウンロードできます。そこから、データセットをダウンロードする形式を定義し、希望する配信方法(ファイルダウンロード、S3など)を設定できます。
CSVでのフラットファイル配信の場合、次のようなファイルが届きます:
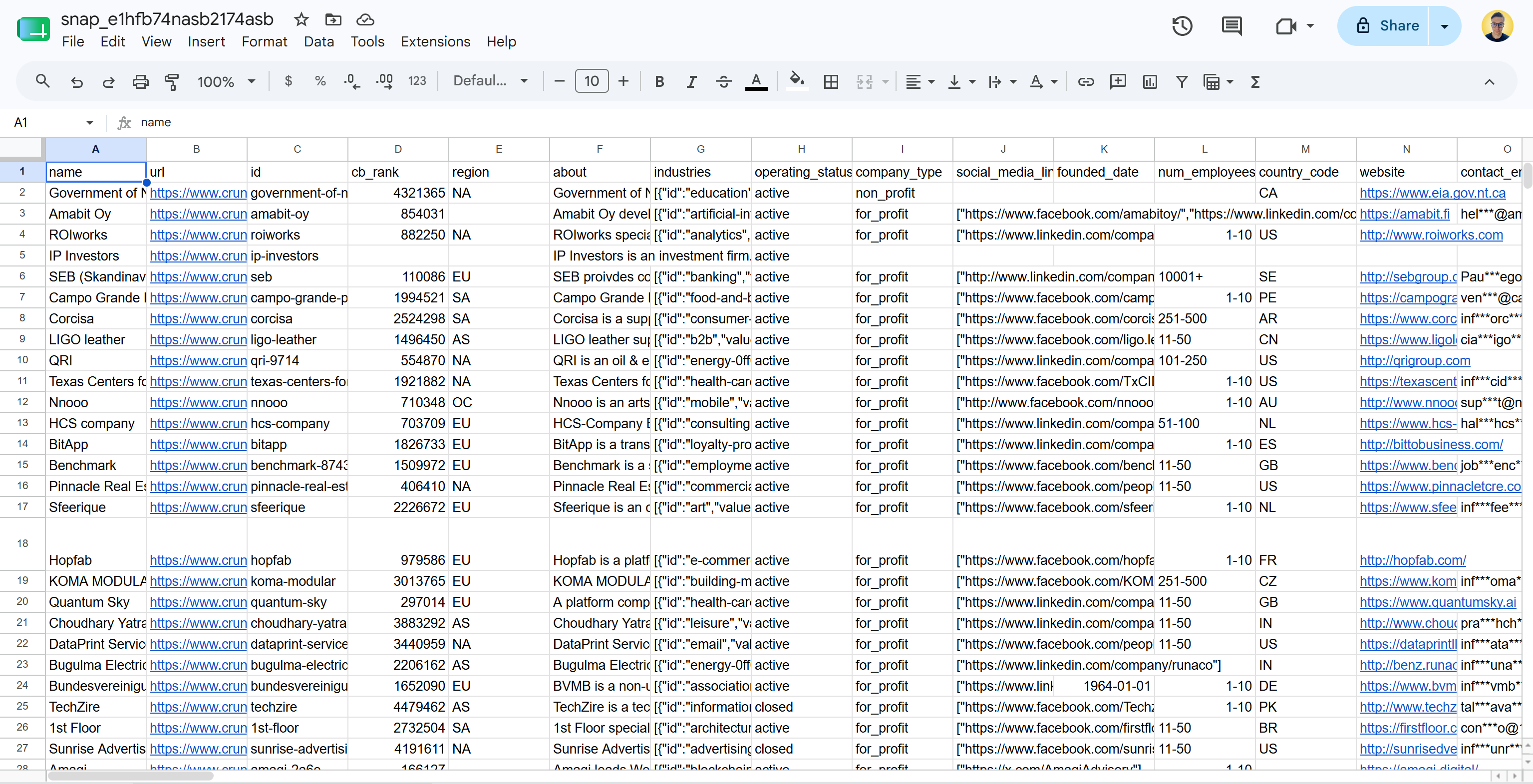
これには構造化フォーマットで即座に分析可能な実際のCrunchbaseデータが含まれています。ミッション完了!
次のステップ
データセットの準備ができたら、簡単なクエリのためにデータウェアハウスまたはデータベースに取り込みます。データ分析および処理パイプラインに統合することもできます。
例えば、次のことができます:
- AIモデルのファインチューニングに使用する。
- 分析、トレンド検出、または予測のためにAIシステムに供給する。
- レポートと監視のためにBIダッシュボードに統合する。
- 他のデータセットと組み合わせて内部データを充実させる。
これらは、特定のユースケース向けに生データを実用的なインサイトに変えるためのアイデアの一部に過ぎません。
Bright DataのウェブスクレイピングAPIを通じて新鮮な構造化データを収集する
ここでは、ウェブスクレイピングAPIの使い始め方を学びます。Bright DataのCrunchbase Scraper APIを使用して、Crunchbaseから構造化された最新データを取得する方法を説明します。
注記:このセクションの前提条件として、Bright Data APIキーがすでに設定されている必要があります。そうでない場合は、Bright Data APIキーを生成するための公式ガイドに従ってください。
ステップ#1:CrunchbaseウェブスクレイパーAPIにアクセスする
Bright Dataアカウントにログインすることから始めます。次に、メューから「スクレイパーライブラリ」ページを選択します:
「スクレイパーライブラリ」ページに移動し、利用可能なすべてのBright Data Web Scraper APIを探索できます:
「crunchbase.com」を検索し、「crunchbase.com」スクレイパーを選択します:
コントロールパネルの「crunchbase.com Scraper API」ページに移動します。
ステップ#2:Scraper APIのオプションを理解する
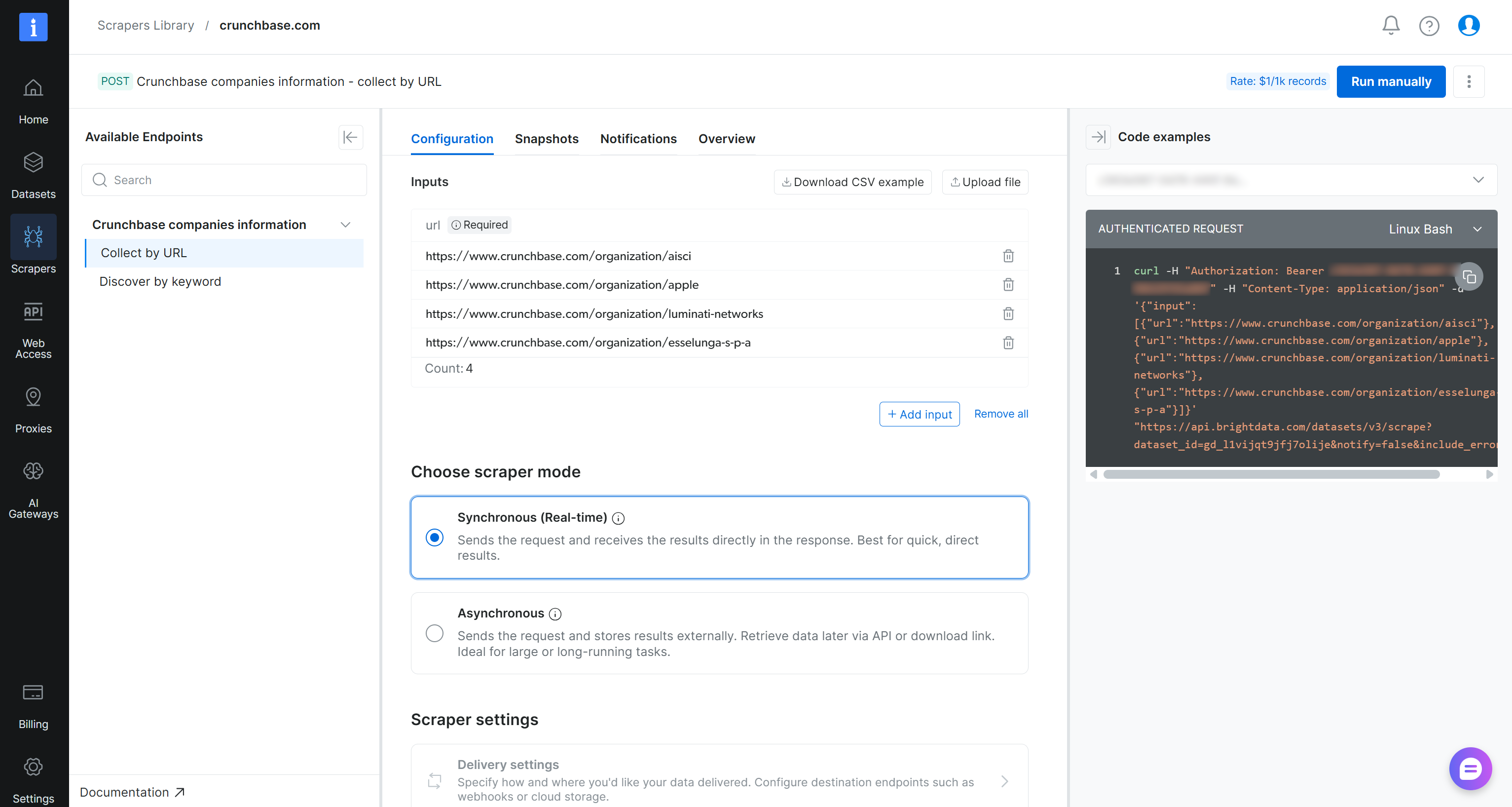
「crunchbase.com」Scraper APIページでは、左パネルで利用可能なすべてのスクレイピングエンドポイントにアクセスできます。各エンドポイントについて、対象URLを追加してAPIコールを設定できます。スクレイピングモード(同期または非同期)を選択し、データ配信オプションを設定することもできます。
重要:「手動で実行」ボタンをクリックしてAPIを直接実行します。準備ができたら、「スナップショット」タブから抽出されたデータにアクセスできます。このワークフローにより、非技術系ユーザーもAPIを利用しやすくなります。
素晴らしい!最新のCrunchbaseデータを取得するための特定のAPIコールを設定する時間です。
ステップ#3:APIコールを設定する
ページの右側では、ウェブスクレイピングAPIを呼び出すための事前定義されたコードスニペットにアクセスできます。これらはBright Data APIキーで自動的に設定されています。
例えば、PythonでAnthropicのCrunchbase企業データを取得したい場合は、対象URLを入力セクションに貼り付けます(例:https://www.crunchbase.com/organization/anthropic)。「同期(リアルタイム)モード」を選択し、利用可能なオプションから「Python (requests)」スニペットを選択します:
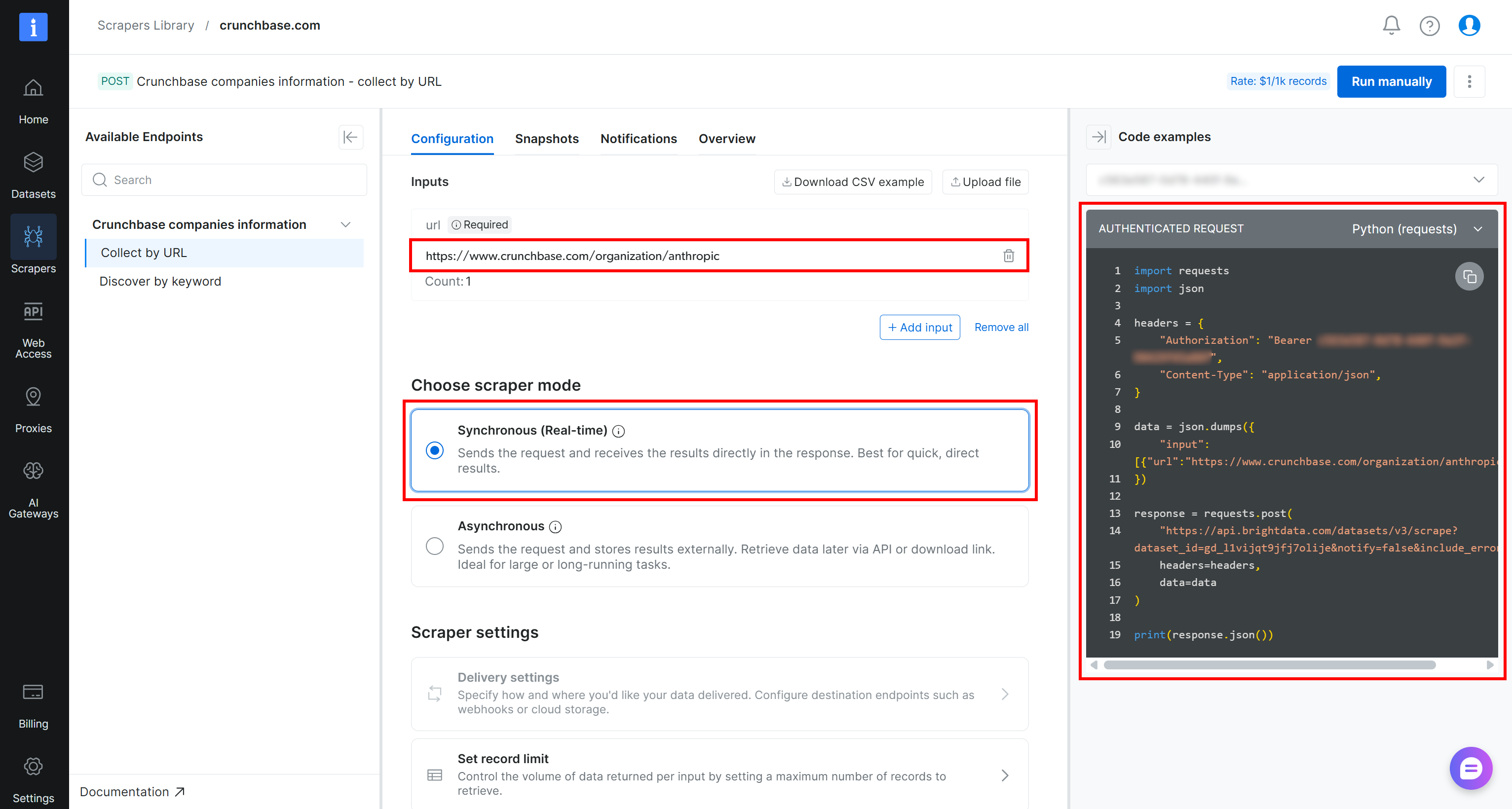
受け取るスクリプトは次のとおりです:
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://www.crunchbase.com/organization/anthropic"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_l1vijqt9jfj7olije¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())結果を取得するために実行してみましょう!
ステップ#4:結果を探索する
Bright Dataコントロールパネルからスニペットをscript.pyなどのファイルとしてローカルに保存します。
Pythonがローカルにインストールされていると仮定して、必要な依存関係をインストールします:
pip install requests次に、以下のコマンドでスクリプトを実行します:
python script.py結果は次のようになります:
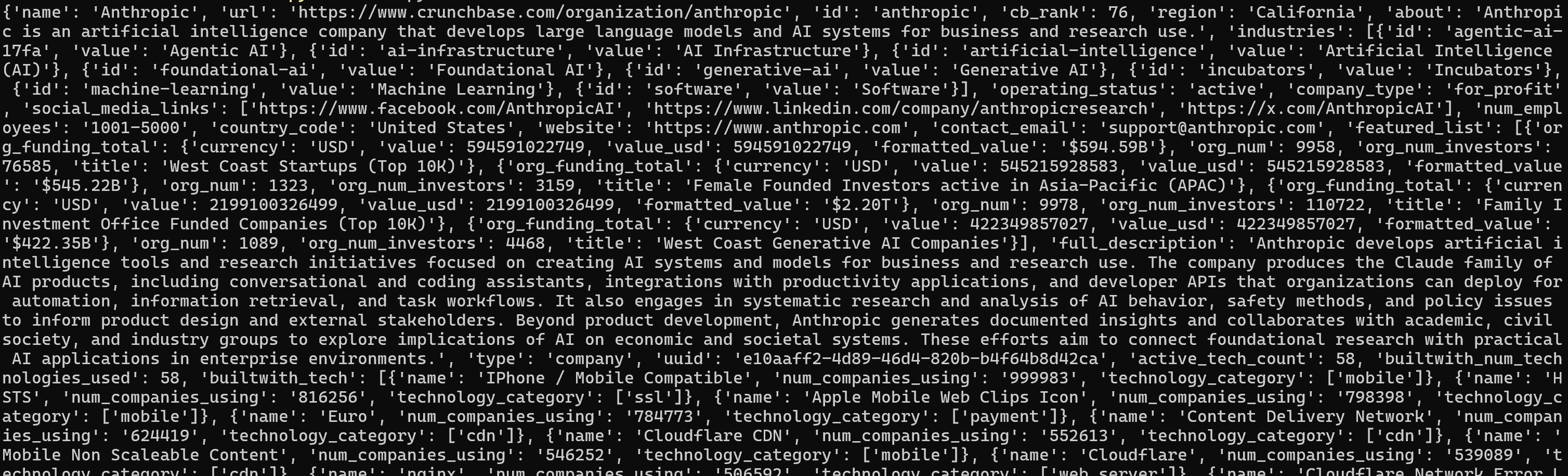
より見やすくするために、出力をJSONビューアーに貼り付けます:
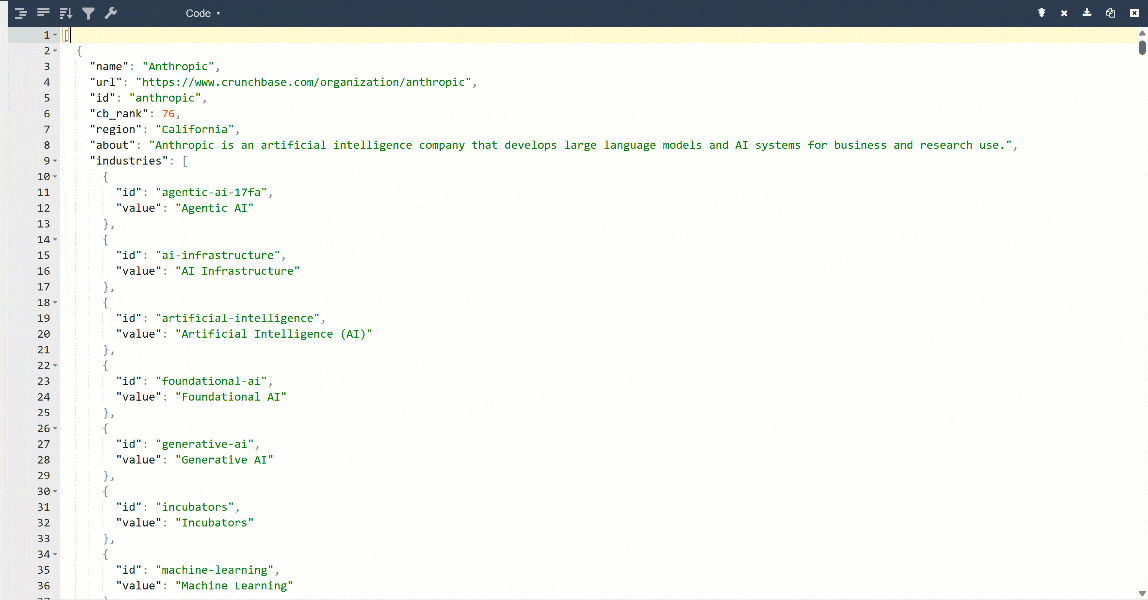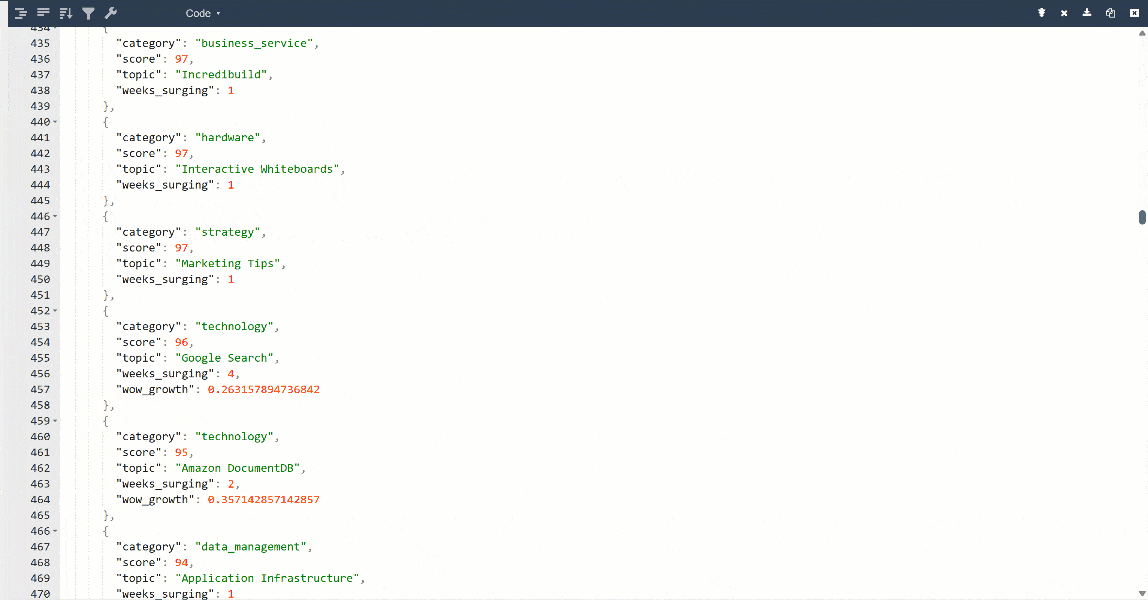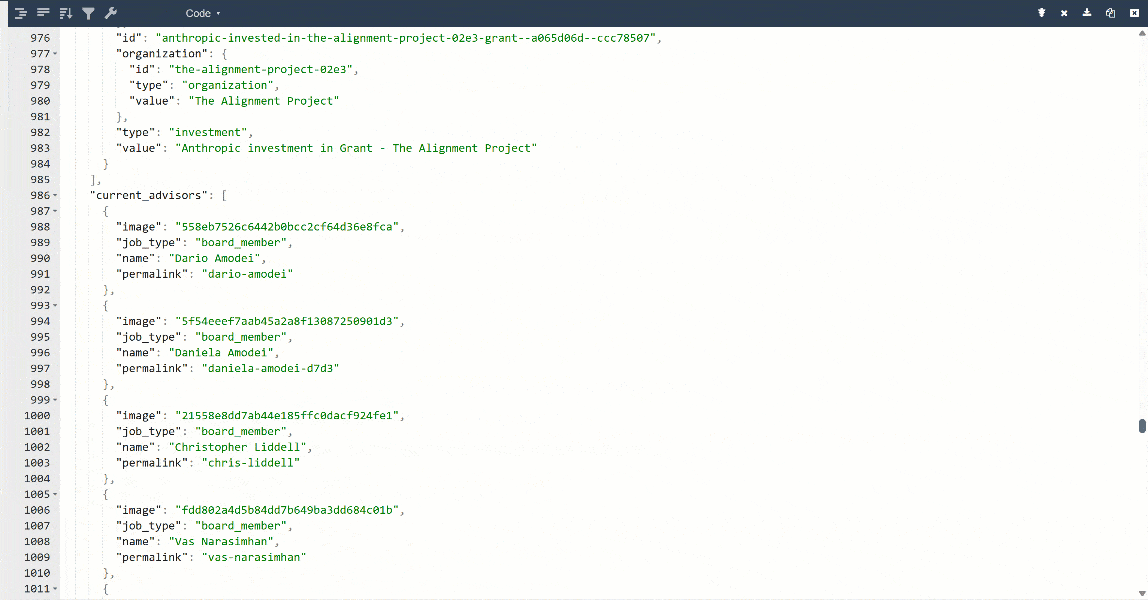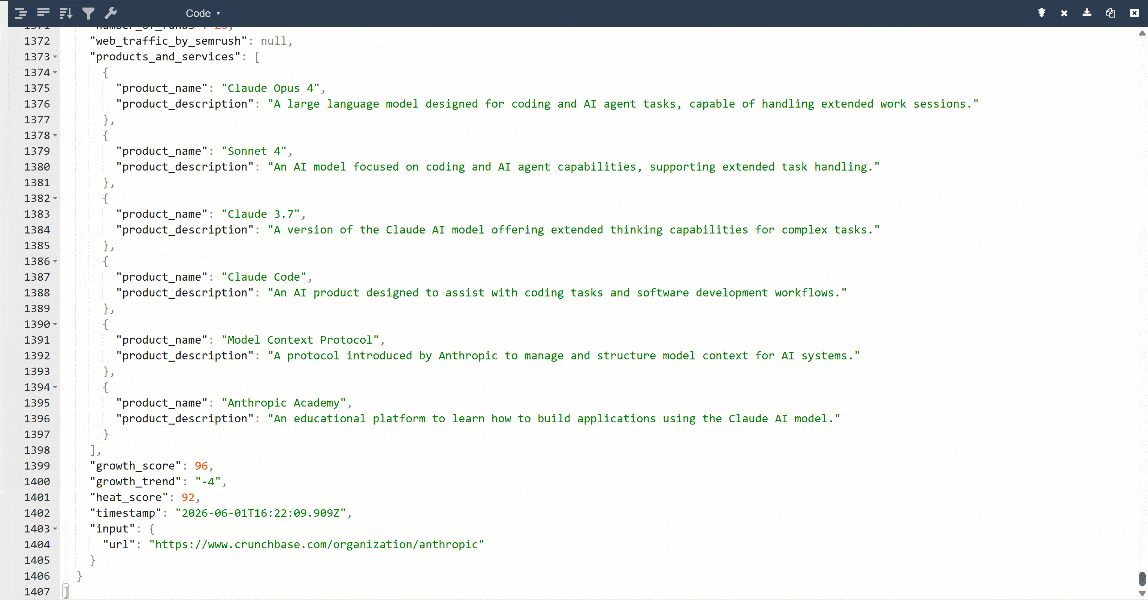
これは対象ページから抽出された同じデータですが、構造化フォーマットになっています:
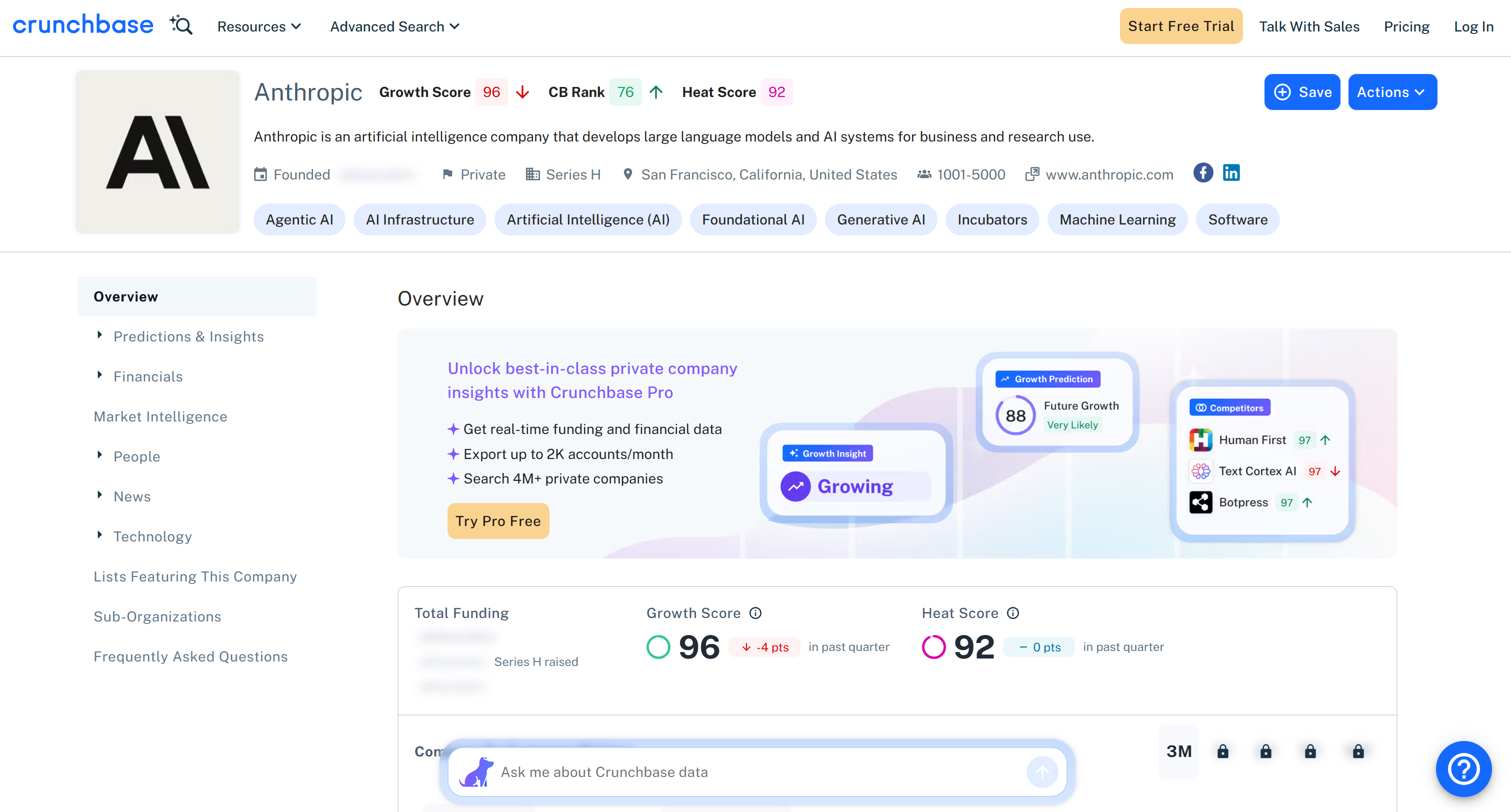
Bright Data Crunchbase Scraper APIから返されたすべての情報は、対象ページのコンテンツと一致することに注目してください。データはウェブスクレイピングによってその場で取得されるため、常に最新の状態です。
完成!Bright DataウェブスクレイピングAPIを使用してデータを正常に取得しました。
次のステップ
上の章では、PythonでBright DataウェブスクレイピングAPIを呼び出す簡単な例を示しました。ただし、ウェブスクレイピングAPIはそれ以上のことができます。これらを活用することで、構造化された最新データをアプリケーション、システム、またはAIワークフローに直接ストリーミングできます。
特にAIエージェントのユースケースでは、これらのAPIはライブグラウンディングレイヤーとして機能し、新鮮な外部コンテキストをシステムに継続的に供給します。例えば、次のことができます:
- 取得と推論のためにリアルワールドの最新ウェブデータでAIエージェントを強化する(例えば、Bright DataのWeb MCPを通じて)。
- Crunchbase、Eコマースプラットフォーム、ソーシャルメディアなどのソースからのライブ情報でLLMの出力をグラウンディングする。
- スクレイピングされたウェブデータがプロンプトまたはベクターデータベースに注入されるリアルタイムRAGパイプラインを構築する。
- 現在の価格、企業アップデート、市場シグナルなどに依存する金融またはビジネスエージェントを支援する。
一般的に、Bright DataウェブスクレイピングAPIは、新鮮なウェブインテリジェンスに依存する動的でデータ対応のシステムを構築するためのコアインフラレイヤーです。
データセットとウェブスクレイピングAPI:最終比較表
以下のデータセットとウェブスクレイピングAPIの比較表で、2つのデータ取得アプローチを一目で比較できます:
| データセット | ウェブスクレイピングAPI | |
|---|---|---|
| 説明 | 事前収集された構造化データのコレクション | オンデマンドで対象ウェブサイトからライブウェブデータを抽出して返すAPI |
| データフォーマット | CSV、JSON、Excel、Parquet、NDJSONなど | JSON、CSV |
| データの新鮮さ | 静的または定期的に更新されるスナップショット | リアルタイム |
| 更新モデル | 日次、月次、四半期ごとの更新サイクル | リアルタイム |
| スケーラビリティ | 数十億件のレコード | APIプロバイダーのレート制限とインフラに依存する高いスケーラビリティ |
| 必要なインフラ | なし(プロバイダーが管理) | なし(プロバイダーが管理) |
| カバレッジ | 広いがデータセットの範囲に限定される | 潜在的にあらゆるウェブサイトまたはドメイン |
| ユーザーの複雑さ | 非常に低い | 低〜中(API統合が必要) |
| AI活用 | 主にトレーニング用 | リアルタイムグラウンディングなど(Web MCPを通じてサポート) |
データセットを選ぶべき場合…
- 分析またはMLトレーニングにすぐに使用できるクリーンで構造化されたデータが必要な場合。
- ユースケースがリアルタイム更新を必要とせず、履歴または集計情報に依存する場合。
- データエンジニアリングやスクレイピングの複雑さを避けたい場合。
- 大規模なキュレーションデータへのコスト効率の良いアクセスが必要な場合。
- バッチ指向のワークフロー(ダウンロード → 保存 → クエリ)を好む場合。
ウェブスクレイピングAPIを選ぶべき場合…
- ウェブから新鮮なリアルタイムデータが必要な場合。
- システムがライブの変化やイベント(価格、ニュース、企業アップデートなど)に反応する必要がある場合。
- 外部グラウンディングを必要とするAIエージェントを構築している場合。
- 社内でスクレイピングインフラを維持せずにウェブデータが必要な場合。
- 進化するデータの継続的または繰り返しの抽出が必要な場合。
データセット + ウェブスクレイピングAPI:併用は可能か?
データセットとウェブスクレイピングAPIを一緒に使用することは可能なだけでなく、現代のデータおよびAIシステムにとって最も実用的な設定であることが多いです。
データセットは、クリーンで構造化された、すぐに使用できる履歴スナップショットを提供します。インフラを心配することなく一貫性、再現性、大規模な分析が必要な場合に最適です。
一方、ウェブスクレイピングAPIはウェブから直接、新鮮なオンデマンドデータを提供します。リアルタイムアプリケーションや急速に変化するソースに適しています。
実際には、2つのアプローチは非常に補完的です。一般的なパターンは、データセットから始めてドメインのベースライン状態を定義することです。次に、ウェブスクレイピングAPIを使用してその特定の部分を充実させるか更新します。この組み合わせは、安定した背景知識とライブコンテキストの両方が必要なシナリオで特に有用です。
Crunchbaseの実際の例については、「CrunchbaseデータセットをフィルタリングしてAIで処理し、新規クライアントを開拓する」という記事を参照してください。Crunchbaseデータセットをフィルタリングし、ウェブスクレイピングAPIを使用してライブ企業ウェブサイトを取得し、AIで潜在的クライアントをスコアリングすることで、AI搭載のクライアント開拓ワークフローを構築する方法を説明しています。
まとめ
このブログ記事では、データセットとウェブスクレイピングAPIがそれぞれ何をもたらすかを理解しました。データセットは静的で構造化された大量のデータが必要なシナリオに最適であり、ウェブスクレイピングAPIはウェブから直接取得した新鮮なデータが必要な場合に優れていることを学びました。
どちらの場合も、選択したアプローチに関わらず、信頼できるウェブデータプロバイダーが必要です。Bright Dataは以下でサポートします:
- データセットマーケットプレイス:JSON、CSV、Parquetなどの形式で350以上のドメインにわたる事前構築済みでフィルタリングされた公開ウェブデータ。170億件以上のデータレコードのコレクションへのアクセスを提供します。
- ウェブスクレイピングAPI:250以上のドメインでリアルタイムウェブデータ抽出を自動化する600以上のスクレイピングエンドポイントのコレクション。IPローテーション、CAPTCHA、アンチボットシステムを処理し、インフラのオーバーヘッドなしに構造化データを返します。
今すぐBright Dataアカウントを作成して、ウェブデータソリューションを無料でお試しください!




