

Tableauはデータ可視化の主要なツールですが、大きな制限があります。単独ではウェブサイトからライブデータを確実に取得できないのです。以前はこの問題を解決していた旧Web Data Connector(WDC v2)は、2023年に非推奨となりました。その最後の互換バージョン(Tableau 2022.4)もすでにサポート終了を迎えており、アナリストたちはサポート対象となるソリューションを失ってしまいました。
本ガイドでは、ウェブスクレイピングを行い、ライブデータをTableauに接続するための6つの手法を比較します。また、Bright DataのウェブスクレイパーAPIを使用してAPIからTableauへのパイプラインを構築するためのステップバイステップのチュートリアルも含まれています。
要約
Tableauはネイティブでウェブスクレイピングできず、そのWeb Data Connector(WDC v2)は2023年に非推奨となりました。外部のデータパイプラインが必要です。
- WDC v2は非推奨となり、WDC v3は抽出専用であり、構築が複雑です
- Google スプレッドシート、Excel、TabPyには、いずれも大規模な運用において重大な制限があります
- 自作のPythonスクリプトは初期段階では機能しますが、継続的なメンテナンスが必要です
- マネージドスクレイピングAPIなら、プロキシ、CAPTCHA、データパースを自動的に処理します
このガイドのステップバイステップチュートリアルに従って、Amazon → Bright Data → Tableau のパイプラインを構築してください。
Tableauに外部データパイプラインが必要な理由
現代のデータスタックには、競合他社の価格、ソーシャルメディアの指標、求人情報、不動産物件情報、金融フィードといったリアルタイムのウェブデータが必要です。Tableauは、こうしたデータを収集するために設計されたものではありません。
主な課題は以下の通りです:
- ウェブサイトは絶えず変化します。レイアウトの変更、ボット対策の進化、JavaScriptレンダリング要件の増加などが挙げられます
- スケーラビリティが不可欠です。毎日10,000件の競合他社のSKUを監視するには、単一ページのスクリプトでは不要なリトライロジック、レート制限、および障害処理が必要です
- コンプライアンスは必須です– GDPR、CCPA、およびプラットフォームの利用規約により、慎重なデータ収集手法が求められます
- インフラコストが高い– プロキシのローテーション、CAPTCHAの解決、リトライロジック、IP管理は、継続的なエンジニアリング上の課題である
以下の手法がそのギャップを埋めます。
ウェブスクレイピングとTableauへのライブデータ連携のための6つの手法
各手法は、スケーラビリティ、保守性、信頼性のバランスをそれぞれ異なって取っています。実用性の低いものから本番環境向けの準備が整っているものへと順にリストアップしています。
方法 1: Tableau Web Data Connector v2 (非推奨)
概要:WDC v2を使用すると、Web API からデータを直接 Tableau に取り込む JavaScript ベースのコネクタを構築できました。
使用できなくなった理由:Tableau 2023.1で非推奨となりました。WDC v2コネクタは現在のすべてのTableauバージョンでサポートされておらず、将来のリリースで完全に削除される可能性があります。WDC v3への移行が必要ですが、v3は根本的に異なるアーキテクチャを採用しています。
重大な制限事項:サポートが終了しました。現在もWDC v2コネクタを使用している場合は、今後のTableauのアップデートで動作しなくなる可能性があるため、今すぐ移行してください。
方法 2: 中間層としての Google スプレッドシート
仕組み:データを Google スプレッドシートに取得(Apps Script、IMPORTXML、IMPORTDATA、またはサードパーティ製ツールを使用)、その後 Tableau をライブデータソースとして Google スプレッドシートに接続します。
利用の利点:無料であり、コーディングは不要です。また、TableauはGoogle Driveコネクタを介してGoogle Sheetsに接続できます。
重要な制限事項:
- Google スプレッドシートには1,000 万セルの制限があり、大規模なデータセットではすぐにこの制限に達してしまいます
- ウェブサイトの構造変更により、
IMPORTXMLおよびIMPORTDATA関数が頻繁に動作しなくなる - 更新タイミングが不安定です。Googleは予測不能なタイミングで数式の実行を制限します
- JavaScriptレンダリングに対応していないため、最新のシングルページアプリケーション(SPA)では空のデータが返されます(これらにはスクレイピングブラウザが必要です)
- Google スプレッドシート API のレート制限により、スケジュールされた更新時に同期エラーが発生する
結論:小規模なプロトタイプには有効ですが、それ以上の規模になると機能しなくなります。変更頻度の低いデータを1万行未満で追跡する個人用ダッシュボードには適しています。
方法 3:Excel + OneDrive / SharePoint
仕組み:ExcelのPower Queryまたは「Webからデータを取得」機能を使用してURLからデータを取得し、OneDriveに保存します。その後、Tableauをクラウド上のExcelファイルに接続します。
重大な制限事項:
- 手動での更新が必要– Power Queryはバックグラウンドでの自動更新を確実に実行しない
- JavaScriptのレンダリングに対応していないため、React、Angular、またはSPAベースのサイトは処理できません
- パース機能に制限がある。複雑なHTML構造の場合、インポートが失敗することが多い
- OneDriveの同期競合により、データの整合性に問題が生じる
- プロキシのローテーション機能がないため、大規模なスクレイピングを行うとIPアドレスがブロックされる
結論:静的なウェブページからの単一レポートには適している。データパイプラインとしては不向き。
方法 4: TabPy (Python + Tableau 拡張機能)
仕組み: TabPyはTableauの公式Pythonサーバーです。 SCRIPT_REALや SCRIPT_STRなどの関数を使用して、Tableauの計算フィールド内でPythonスクリプトを実行します。理論上、ウェブスクレイピングロジックはTabPyを通じてTableau内部で直接実行されます。
利用理由:Pythonには豊富なスクレイピングライブラリがあり、TabPyはTableauによって公式にサポートされている。
重要な制限事項:
- TabPyサーバーの稼働が必要– 維持管理のための追加インフラが必要
- Tableauの計算フィールド内でのスクレイピングはアンチパターンです。処理が遅く、信頼性が低く、ダッシュボードのレンダリングを妨げます
- プロキシのローテーション機能がないため、トラフィック量の多いターゲットでは TabPy サーバーの IP アドレスが即座にブロックされる
- CAPTCHAの解決、リトライロジック、JavaScriptのレンダリングに対応していません
- 計算フィールドには実行時間制限があるため、複雑なスクレイピングジョブはタイムアウトする
- エラーが不明確なTableauのエラーメッセージとして表示されるため、デバッグが極めて困難
結論:TabPyはTableau内で機械学習モデルや統計計算を実行するには最適です。しかし、ウェブスクレイピングには適していません。
方法 5:自作の Python スクリプト(requests、Scrapy、Selenium)
仕組み: requests、BeautifulSoup、Scrapy、Seleniumなどのライブラリを使用して、カスタムPythonスクリプトを作成します。それらをスケジュール(cronやAirflowなど)で実行し、CSV/JSONファイルを出力して、Tableauをそれらのファイルに接続します。
利用理由:最大限の柔軟性。すべてを自分で制御できます。
主な制限事項:
- メンテナンス負荷が高い– ウェブサイトのレイアウト変更、ボット対策の追加、HTML構造の変更などが発生します。スクレイパーは予告なく動作しなくなり、ダッシュボードには古いデータが表示されます。
- 大規模なIPブロック–プロキシネットワークがない場合、対象サイトは数時間以内にサーバーをブロックします
- CAPTCHAの解決機能なし– Cloudflare、reCAPTCHA、hCaptchaはスクレイパーをブロックし、組み込みの回避策はありません(Web Unlockerのようなサービスはこれらを自動的に処理します)
- インフラコスト– サーバー、プロキシのサブスクリプション、監視、アラート機能が必要
- コンプライアンスリスク– 適切なインフラがなければ、GDPR、CCPA、またはプラットフォームの利用規約に違反する可能性があります
- スケーラビリティの欠如– 100件のURLをスクレイピングすることと、10万件をスクレイピングすることは異なります。前者に有効なアーキテクチャは、後者では完全に機能しなくなります。
結論:DIYは初期段階では有効ですが、長期的には信頼性がありません。多くのチームはここから始め、最初は成功するケースも少なくありません。しかし、時間の経過とともにメンテナンスの負担は増大します。
最初の1ヶ月は順調に機能しますが、数ヶ月も経つと、ダッシュボードの構築よりも、破損したセレクタの修正やIPアドレスの利用停止への対応に多くの時間を費やすことになります。1~2つのサイトを少量のデータでスクレイピングするだけなら、自作スクリプトで十分かもしれません。
方法6:Bright Data スクレイパー API(推奨)
仕組み:Bright DataのWebスクレイパーAPIは、プロキシローテーション、CAPTCHAの解決、JavaScriptレンダリング、ボット検知回避、構造化データ出力など、データ収集レイヤー全体を処理します。API経由で収集ジョブをトリガーし、クリーンなJSON/CSVデータを受け取り、Tableauに読み込みます。
メリット:
| 機能 | Bright Data | 自作スクリプト |
|---|---|---|
| プロキシネットワーク | 195カ国にまたがる1億5,000万以上のIPアドレス | 自分で購入(高価) |
| 既成のスクレイパー | 主要プラットフォーム向け120種類以上 | 一から構築 |
| CAPTCHAの解決 | 自動 | 含まれていません |
| JavaScriptレンダリング | 標準搭載 | Selenium/Playwrightが必要 |
| ボット対策バイパス | 自動 | 常時手動での更新が必要 |
| 稼働率 | 99.99% | インフラ環境に依存 |
| コンプライアンス | GDPR、CCPA、ISO 27001 | お客様の責任 |
| メンテナンス | 最小限 – Bright Dataがスクレイパーの更新を管理します | 常時 |
| スケーラビリティ | 1日あたり数百万ページ | お客様のサーバーによって制限されます |
| 価格 | 1,000件あたり1.50ドルから | 変動制(サーバー+プロキシ+保守) |
結論:お客様はTableauダッシュボードに集中し、データ収集のインフラはBright Dataが担当します。
トレードオフ:Bright Dataは有料のサードパーティ製サービスです。そのインフラと料金体系に依存することになります。1~2つのサイトを低頻度でスクレイピングする場合、自作スクリプト(方法5)の方がコストが安く、完全に制御できます。
どのTableauデータ接続方法を選ぶべきか?
この表では、本番環境のパイプラインにおいて最も重要な機能について、6つの方法をすべて比較しています。
| 方法 | JSレンダリング | プロキシローテーション | CAPTCHAの解決 | 自動リフレッシュ | スケーリング | メンテナンス | ステータス |
|---|---|---|---|---|---|---|---|
| WDC v2 | いいえ | いいえ | いいえ | はい | 低 | 該当なし | 非推奨 |
| Google スプレッドシート | いいえ | なし | なし | 信頼性が低い | 非常に低い | 低い | セル数制限 |
| Excel + OneDrive | なし | なし | いいえ | 手動 | 非常に低い | 中 | 手動プロセス |
| タブPy | 手動/DIY | いいえ | いいえ | はい | 低 | 高 | IPアドレスのブロック |
| DIY Python | Selenium経由 | 自作 | いいえ | cron経由 | 中 | 非常に高い | 大規模な環境では動作しない |
| Bright Data API | はい | はい (1億5000万以上のIP) | はい | はい | 高 | 最小限 | 本番環境対応 |
チュートリアル:ウェブスクレイピングAPIをTableauに接続する
このチュートリアルでは、Amazon スクレイパー API を使用して、実際のパイプラインを構築します:Amazon の商品価格 → Bright Data API → CSV → Tableau ダッシュボード。ここでは、チームが Web データを Tableau に接続する最も一般的な理由である「競合他社の価格監視」というユースケースについて解説します。
アーキテクチャ
パイプラインのフローは以下の通りです:
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ スクリプト │────▶│ Bright Data スクレイパー │────▶ │ CSV/JSON │────▶│ Tableau │
│ (Python/cron) │ │ API │ │ 出力 │ │ ダッシュボード │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
キーワード/URLによるトリガー プロキシの処理、 価格の可視化、
キーワード/URL CAPTCHAの処理、レンダリング 評価、トレンド前提条件
開始する前に、以下のものがインストールされているか、利用可能である必要があります:
- Python 3.8 以上
- Bright Dataアカウント(無料トライアルあり、クレジットカード不要)
- Bright Dataダッシュボードから取得したAPIトークン(手順0を参照)
- Tableau Desktop(14日間の無料トライアル)、Tableau Cloud、またはTableau Public(無料、ダッシュボードは公開されます)
これらの準備が整ったら、まずBright DataのAPIトークンを生成してください。
ステップ 0: Bright Data API トークンの取得
以下の手順に従って API トークンを生成してください:
- brightdata.com/cpにアクセスして、サインアップまたはログインします
- [アカウント設定] → [ユーザーとAPIキー]に移動します
- 「APIキーの追加」を選択します(APIキーセクションの右上)
- 権限と有効期限を設定し、「保存」を選択します
- トークンをコピーします
API トークンを保存したら、Python の依存関係をインストールします。
ステップ1: 依存関係をインストールする
必要なPythonパッケージをインストールします:
pip install requests pandasrequestsとpandasのインストールが完了したら、パイプラインスクリプトを作成します。
ステップ 2: パイプラインスクリプト
bright_data_to_tableau.py というファイルを作成します:
"""
Bright Data → Tableau パイプライン
Bright DataのウェブスクレイパーAPIを介してAmazonの商品データをスクレイピングし、
Tableauで利用可能なCSVファイルを出力します。
使用方法:
1. YOUR_API_TOKENを自身のBright Data APIトークンに置き換えてください
2. 実行: python bright_data_to_tableau.py
3. 出力されたCSVファイルをTableau Desktopで開きます
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── 設定 ───────────────────────────────────────────────────────────
API_TOKEN = "YOUR_API_TOKEN" # ご自身のBright Data APIトークンに置き換えてください
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Amazon Products Search (キーワード検索)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # ステータス確認の間隔(秒)
POLL_TIMEOUT = 300 # 最大待機時間(秒)
# ─── API エンドポイント ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/データセット/v3/トリガー"
f"?データセット_ID={データセット_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/データセット/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Bright Data上でデータ収集ジョブをトリガーします。"""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] キーワード '{keyword}' の収集をトリガー中...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" スナップショット ID: {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""データが準備できるまでスナップショットエンドポイントをポーリングします。"""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] 結果を待機中...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" 準備完了!{len(data)}件のレコードを受信しました。")
return data
elif response.status_code == 202:
print(f" 処理中... ({elapsed}秒 / {POLL_TIMEOUT}秒)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" エラー {response.status_code}: {response.text}")
sys.exit(1)
print(f" タイムアウト: {POLL_TIMEOUT}秒経過してもスナップショットが準備されませんでした。"
print(f" POLL_TIMEOUTの値を大きくするか、Bright Dataダッシュボードを確認してください。"
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""生のAPIデータを、Tableau用に最適化されたクリーンなCSVに変換します。"""
df = pd.DataFrame(data)
# APIのフィールド名 → Tableauに適した名前にマッピング
column_mapping = {
"title": "Product Name",
"seller_name": "Seller",
"brand": "ブランド",
"initial_price": "元価格",
"final_price": "現在価格",
"currency": "通貨",
"rating": "評価",
"reviews_count": "レビュー数",
"availability": "在庫状況",
"url": "商品URL",
"asin": "ASIN",
"categories": "カテゴリ",
"delivery": "配送情報",
}
# データに含まれる列のみを残す
available = {k: v for k, v in column_mapping.items() if k in df.columns}
df = df.rename(columns=available)
df = df[list(available.values())]
# Tableauでのフィルタリングおよび追跡用のメタデータを追加
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] {len(df)} 行を {output_path} に保存しました")
return df
def print_summary(df: pd.DataFrame):
"""スクレイピングしたデータの概要を出力します。"""
print(f"n{'─'*50}")
print(f" 概要")
print(f"{'─'*50}")
print(f" 商品総数 : {len(df)}")
if "Current Price" in df.columns:
prices = pd.to_numeric(df["Current Price"], errors="coerce")
print(f" 価格範囲 : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" 平均価格 : ${prices.mean():.2f}")
if "Brand" in df.columns:
print(f" ブランド数 : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" 平均評価 : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}n")
def run_pipeline(keyword: str):
"""パイプライン全体を実行:Trigger → Poll → CSV → Summary."""
print(f"n{'='*50}")
print(f" Bright Data → Tableau Pipeline")
print(f" キーワード: '{keyword}'")
print(f"{'='*50}n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# デフォルトのキーワード — これを変更するか、CLI引数として渡してください
keyword = sys.argv[1] if len(sys.argv) > 1 else "wireless headphones"
run_pipeline(keyword)ステップ 3: スクリプトを実行する
パイプラインスクリプトを実行します:
python bright_data_to_tableau.py期待される出力:
==================================================
Bright Data → Tableau パイプライン
キーワード: 'wireless headphones'
==================================================
[1/3] キーワード 'wireless headphones' の収集をトリガー中...
スナップショット ID: sd_mmlan9p51yycmmkd7d
[2/3] 結果を待機中...
処理中... (0秒 / 300秒)
完了!43件のレコードを受信しました。
[3/3] 43行を保存 → amazon_products_tableau.csv
──────────────────────────────────────────────────
概要
──────────────────────────────────────────────────
商品総数 : 43
価格帯 : $0.00 – $169.95
平均価格 : $45.98
ブランド数:4
平均評価:4.4 / 5.0
──────────────────────────────────────────────────CSVファイルの準備が整いました。Tableauで開いて、ダッシュボードの作成を開始してください。
ステップ 4: Tableau に接続する
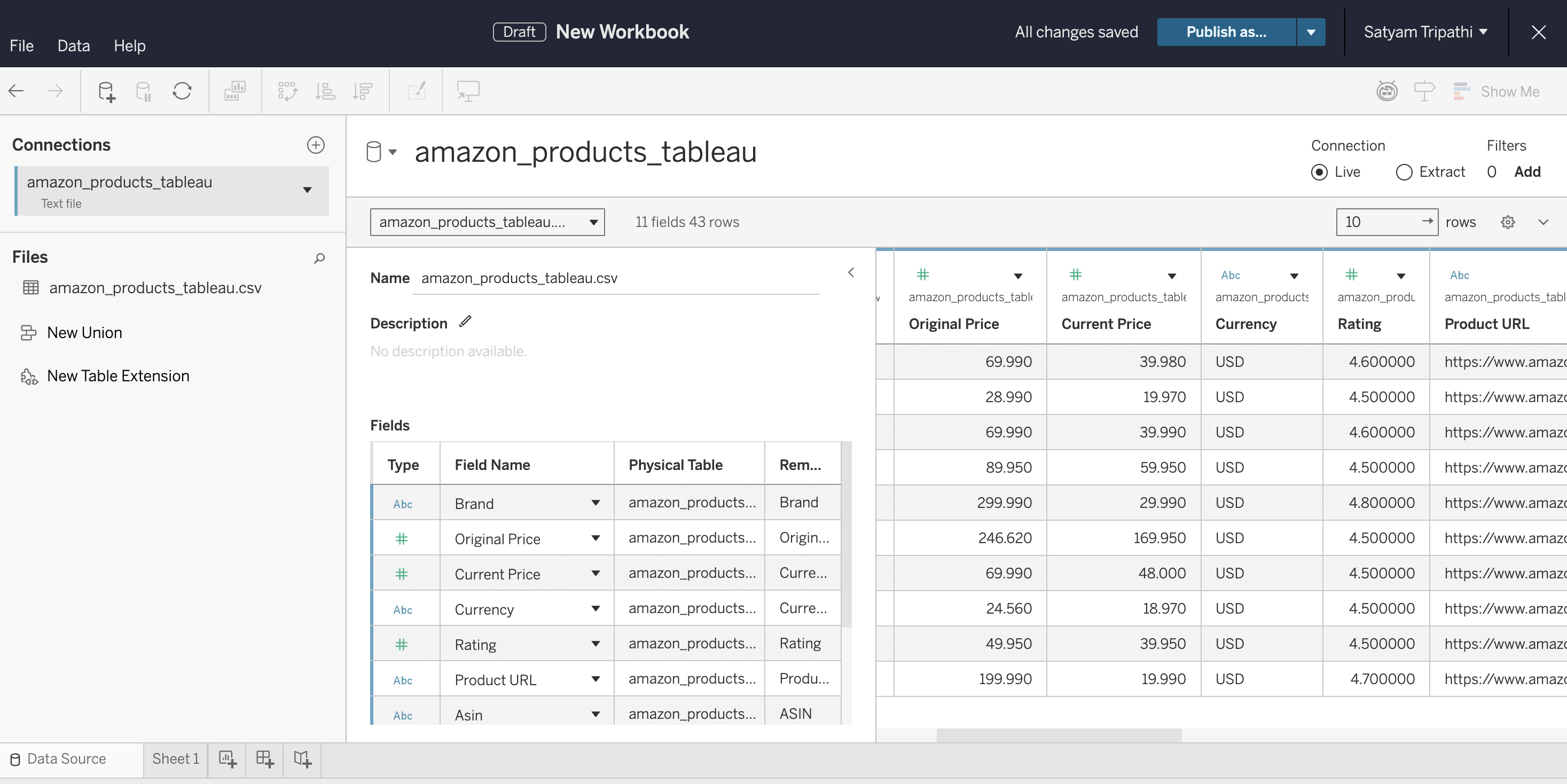
CSVをTableauに読み込み、データ型を確認します:
- Tableau Desktop、Tableau Cloud、またはTableau Publicを開きます
- CSVに接続します。Desktopの場合は、「接続」→「テキストファイル」を選択します。Cloudの場合は、「新規」→「ワークブック」→「ファイル」タブを選択し、ファイルをアップロードします
- 「
Current Price」と「Rating」が文字列(String)ではなく数値(Number)として認識されていることを確認してください - 「シート 1」を選択して作成を開始します
推奨されるダッシュボードのビュー:
- 価格分布– 市場での位置付けを把握するための「
現在の価格」のヒストグラム - 価格下落分析– 割引率を把握するための、
元価格と現在の価格を並べて表示した棒グラフ - 評価と価格– 高価値な製品を見つけるための散布図
- ブランド比較–
ブランドごとに商品をグループ化した棒グラフで、価格と評価を比較
ステップ5: 更新の自動化
ダッシュボードを常に最新の状態に保つため、cron(Linux/Mac)またはタスク スケジューラ(Windows)でスクリプトをスケジュールします:
# 6時間ごとに実行 — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.py新しいデータを表示するためにTableauを更新する:
- Tableau Desktop。cronジョブによってCSVが更新された後、F5(Windows)またはCommand+R(Mac)を押して再読み込みします。あるいは、[データ]メニューでデータソースを選択し、[更新]を選択します。Tableau Desktopはファイルベースのソースを自動的に更新しないため、手動で更新するか、ワークブックを再度開く必要があります。
- Tableau Server。Tableau Desktopから、[サーバー] → [ワークブックの公開] を選択して公開します。公開ダイアログで、抽出の更新スケジュールを設定します(例:cronジョブに合わせて6時間ごと)。Tableau Serverはそのスケジュールに従って抽出を自動的に更新します。
- Tableau Cloud。ブラウザからアップロードされたCSVファイルは自動更新できません。更新を自動化するには、cronジョブを実行しているマシンにTableau Bridgeをインストールしてください。BridgeはローカルのCSVをTableau Cloudに接続し、スケジュールされた抽出データの更新をサポートします。Bridgeを使用しない場合は、パイプラインの実行ごとに手動でCSVを再アップロードする必要があります。
- Tableau Public。ファイルベースのソースに対するスケジュールされた更新はサポートされていません。CSVベースのパイプラインの場合、データが更新されるたびにワークブックを再公開する必要があります。
ステップ 6: スクレイパーを使用する(データセット ID の取得)
このチュートリアルでは、Amazon Products Search データセット (gd_lwdb4vjm1ehb499uxs) を使用しています。別のウェブサイトをスクレイピングする場合は、データセット ID を変更してください。ID の確認方法は以下の通りです:
- Bright Dataのコントロールパネルにログインします
- サイドバーの [Web スクレイパー] を選択して、Web スクレイパー Library を開きます
- 対象のドメイン(amazon.com、zillow.com、linkedin.comなど)を検索して選択します
- 収集方法を選択します(「URLで収集」または「キーワードで検索」)
- ブラウザのURLバー(例:
brightdata.com/cp/スクレイパー/gd_lfqkr8wm13ixtbd8f5)または「コード例」パネルからデータセットIDをコピーします
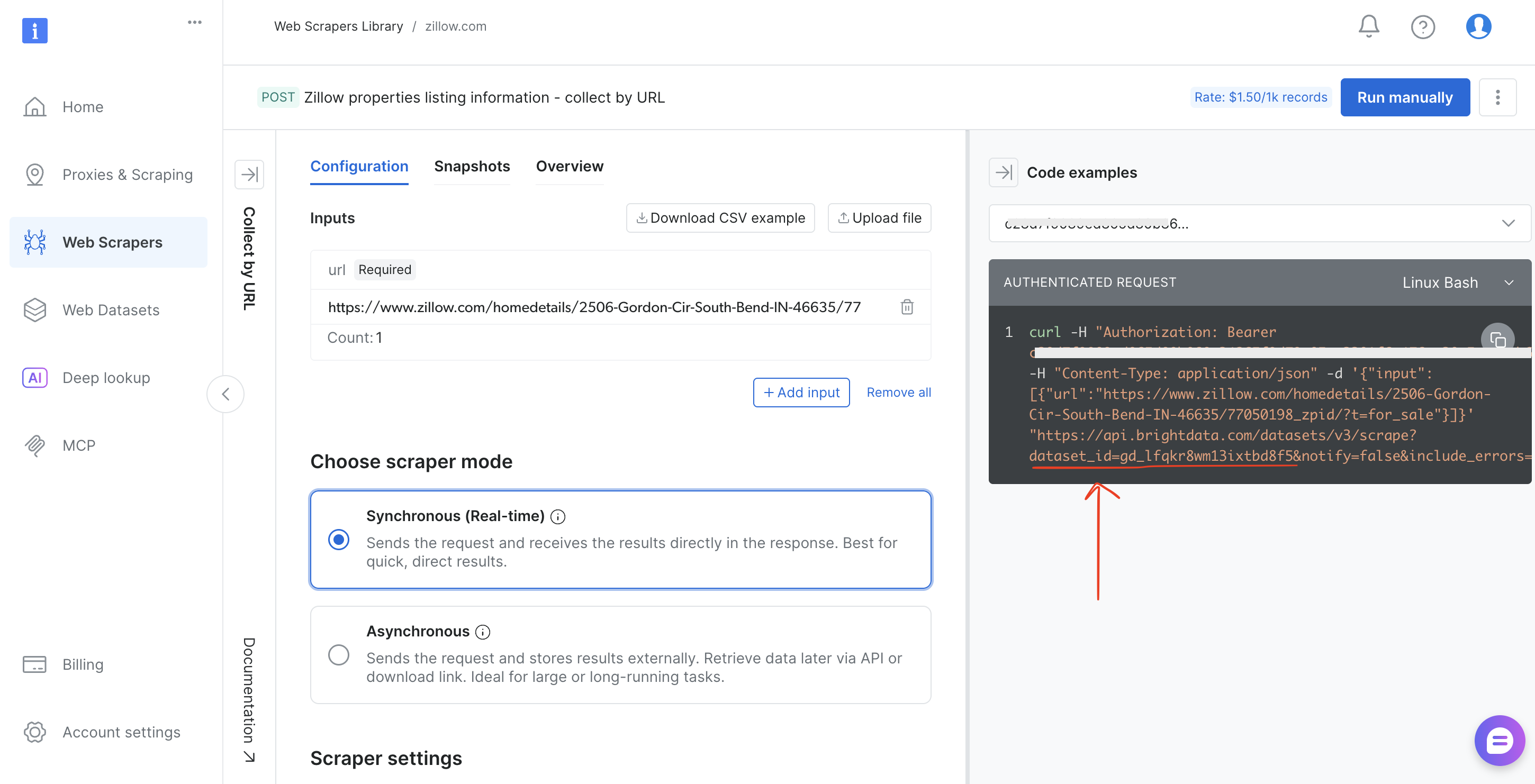
スクリプト内のDATASET_ID を置き換え、ペイロードを調整すれば、Bright Data の 120 以上のスクレイパーのいずれに対しても同じパイプラインが機能します。
実際の結果:スクレイピングされたデータの様子
以下のスクリーンショットは、パイプラインからの生のCSV出力です。これは、キーワード「wireless headphones」に対してBright DataのAPIが返した結果そのものです:
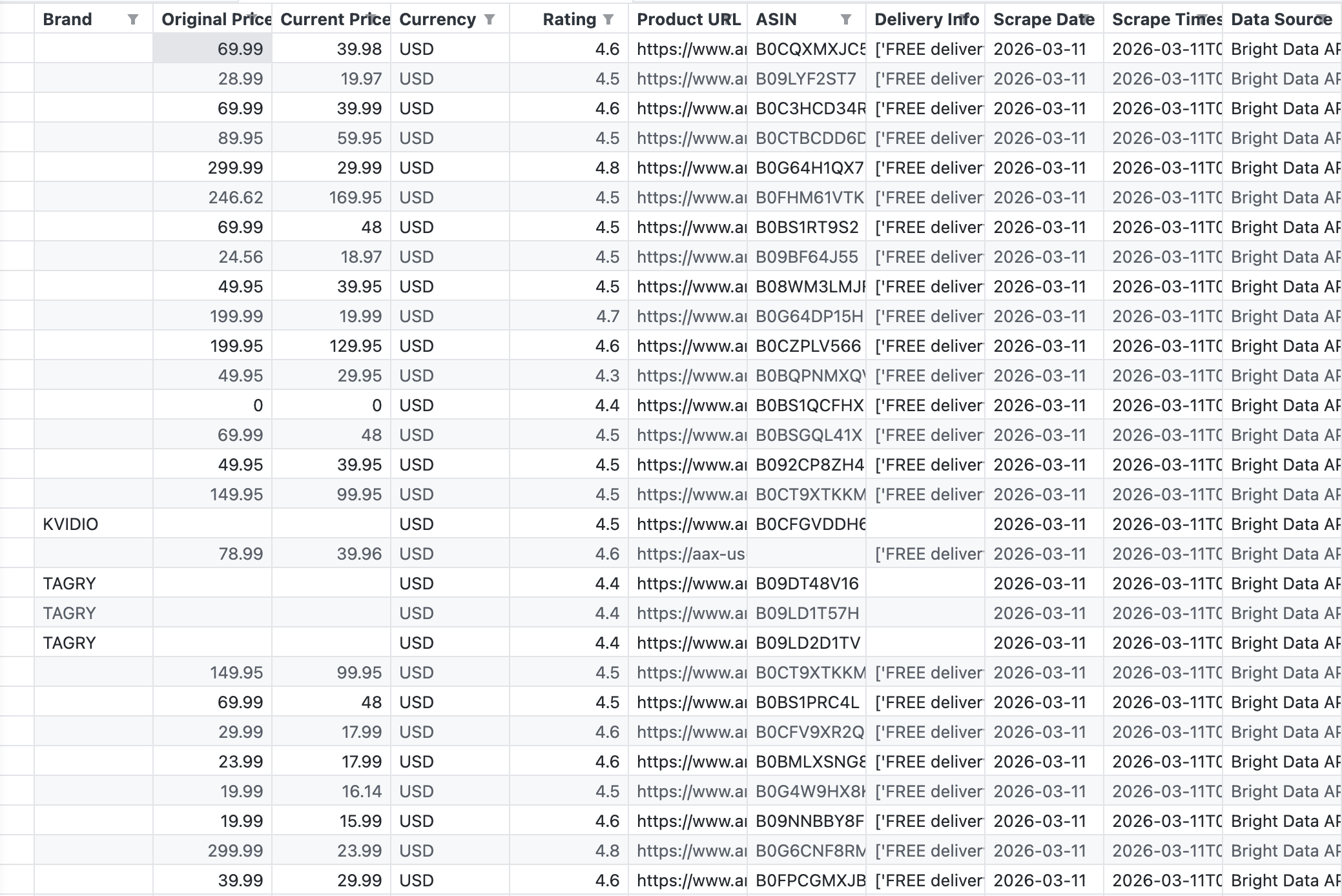
APIからは、ブランド、定価、現在価格、評価、ASIN、商品URL、配送情報を含む43件のレコードが返されました。
APIは1回の呼び出しで43件の商品を返しました。データは構造化されており、Tableauで即座に活用可能です。HTMLのパースも、破損したセレクターも、CAPTCHAの課題もありません。Amazonスクレイピングオプションの詳細については、「Amazon商品データのスクレイピング方法」をご覧ください。
データの可視化:CSVからインサイトへ
以下の4つのビジュアライゼーションは、パイプラインが生成した結果を示しています。各ビューは、スクリプトが生成したCSVファイルをそのまま使用して作成されています:
商品ごとの価格分布
このチャートは、31の商品(Amazon URLから名前を解析可能なもの)を現在の価格順(安価なものから高価なものへ)にランク付けしたものです:
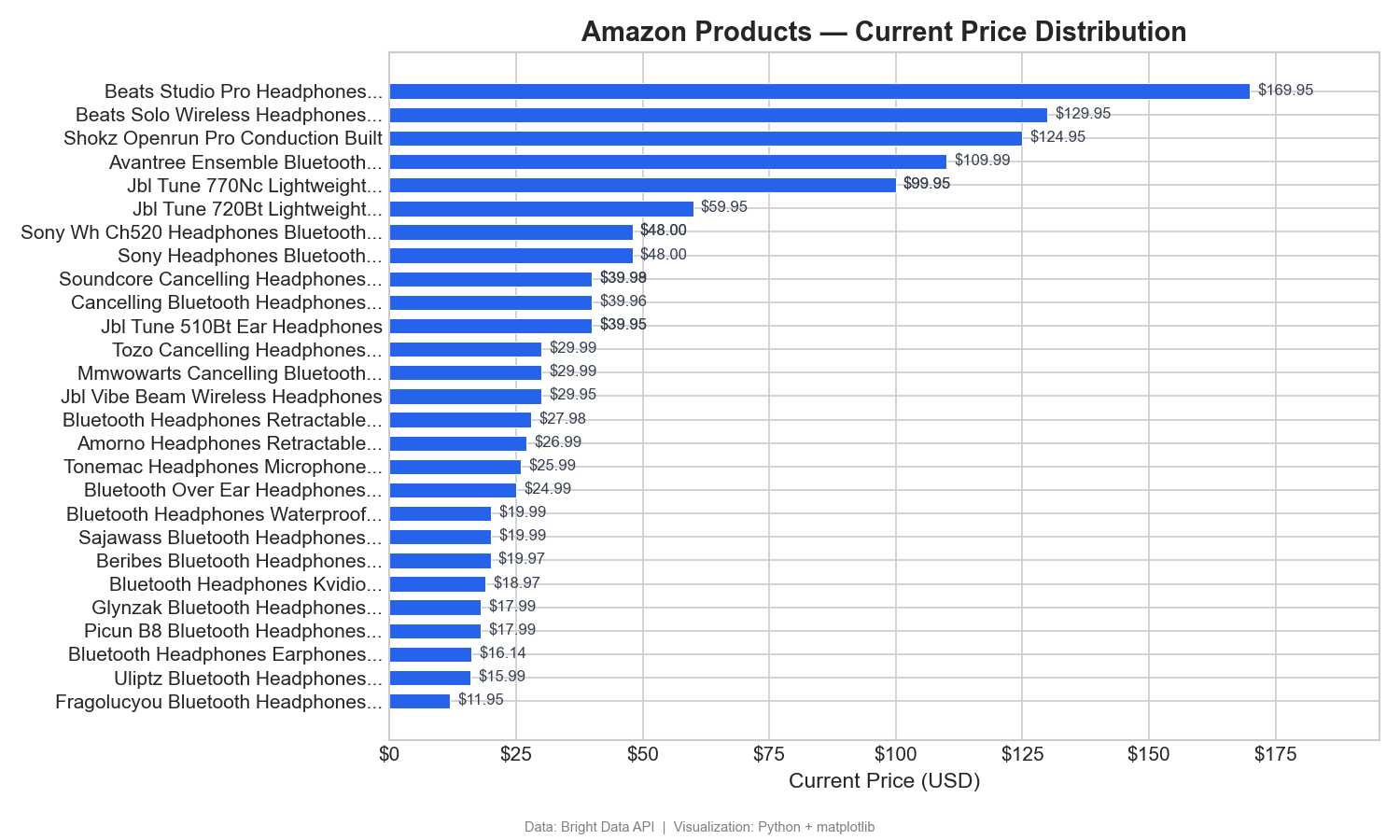
この横棒グラフは価格帯を明確に示しています。Beatsがプレミアム帯(125~170ドル)を独占している一方、ほとんどのワイヤレスヘッドホンは12~60ドルの範囲に集中しています。Tableauでは、これを「現在の価格」を列に、「製品名」を行に配置したソート済み棒グラフとして作成します。
価格下落:定価対現在価格
このグループ化棒グラフは、割引対象の上位10商品の定価と現在の価格を比較しています:
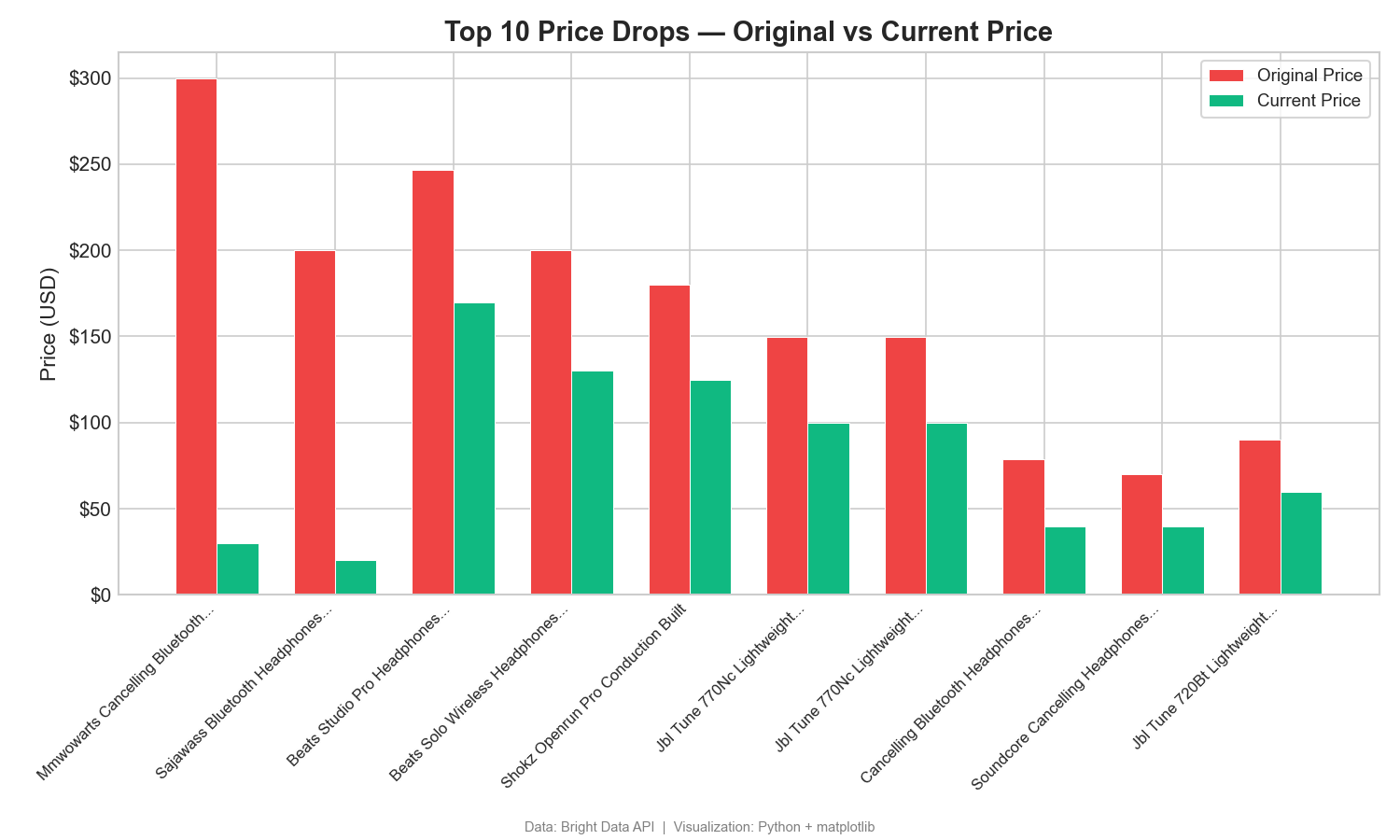
定価と現在の価格の差額は、大幅な値引きを示しています。ある製品では、定価から270ドルの値下がり(299.99ドル → 29.99ドル)が見られます。このような差額は、販促戦略や価格戦略を明らかにします。Tableauでは、色に「メジャール名」を設定した並列棒グラフを使用します。
評価と価格:価値の発見
この散布図は、顧客の評価と価格をプロットし、高価値な製品を特定します:
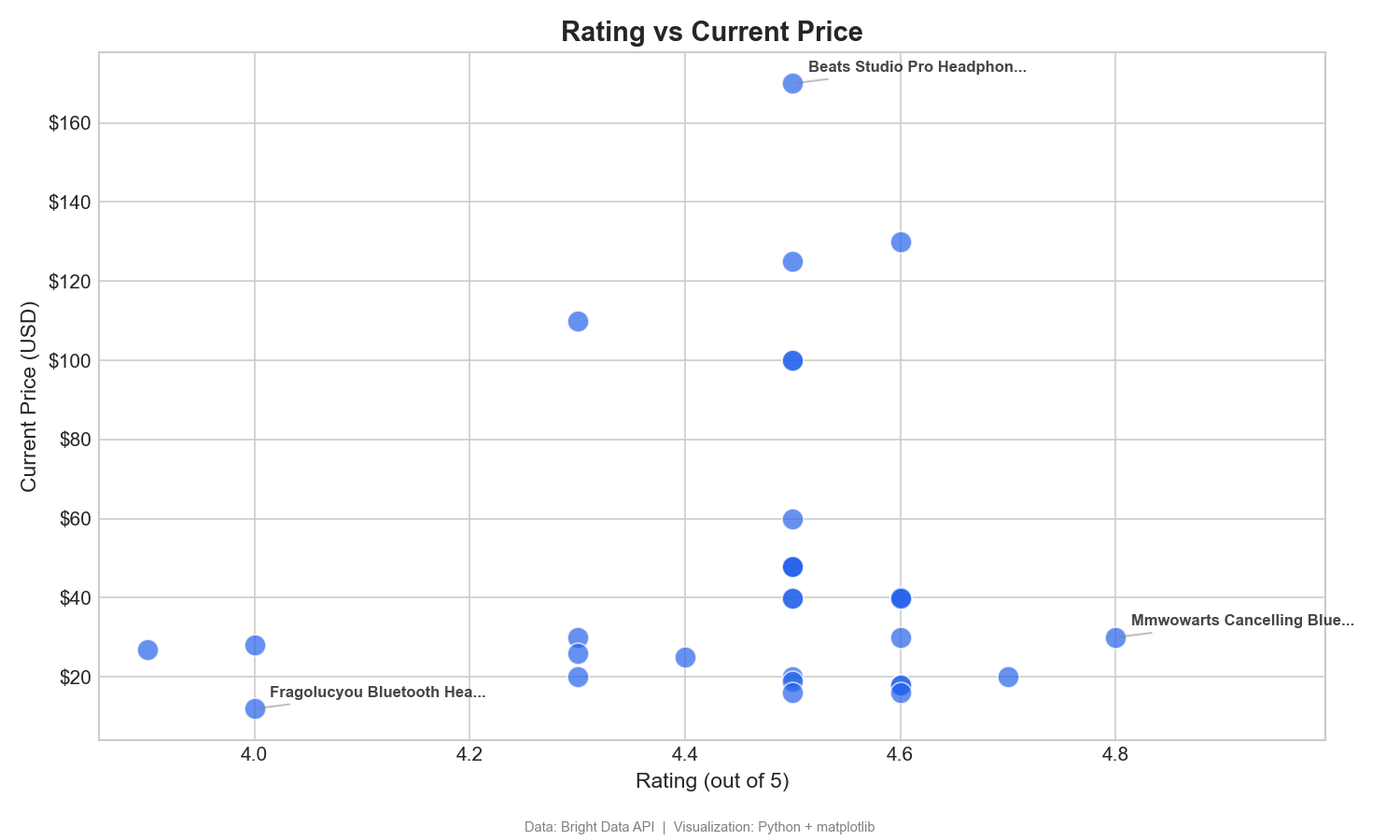
この散布図は、高評価かつ低価格(右下象限)の、価値の高い商品を特定するのに役立ちます。29.99ドルで評価4.8のMMWOWARTSヘッドホンは、その明確な例です。Tableauでは、「評価」を「列」に、「現在の価格」を「行」に、「商品名」を「詳細」にドラッグします。
価格帯による市場セグメンテーション
このドーナツチャートは、価格帯ごとに製品を分類しています:
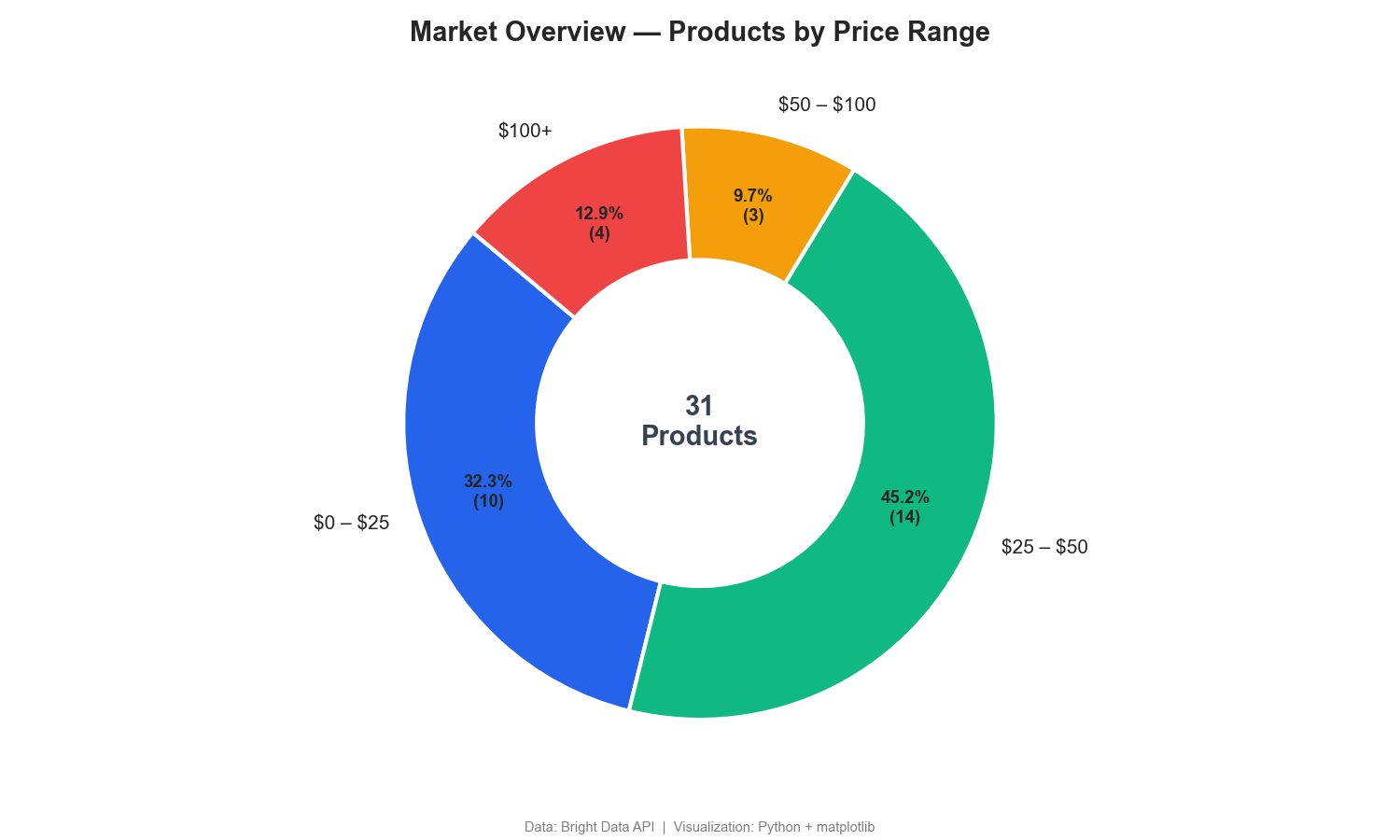
このドーナツチャートによると、ワイヤレスヘッドフォンの77%が50ドル未満で販売されており、100ドル以上のプレミアムセグメントはわずか13%です。競合他社の価格監視ダッシュボードには、同様のセグメンテーションが含まれていることがよくあります。
おまけ:Zillowを使った不動産パイプライン
このパイプラインのパターンは、Bright Dataの120種類以上のスクレイパーのいずれでも機能します。以下の例では、ZillowスクレイパーAPI(GitHubリポジトリ)を使用しています。「bright_data_to_tableau.py」内の2つの変数を更新するだけで、パイプラインの残りの部分は変更なしで実行されます:
# AmazonのデータセットIDをZillowのデータセットIDに置き換える
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Zillow物件次に、trigger_collection()内のペイロードを更新し、キーワードの代わりに場所のURLを使用するようにします:
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]スクリプトは同じ方法で実行してください。ポーリングおよびCSVエクスポートのロジックは変更なしで動作します。
Zillowのフィールドには、物件住所、価格、寝室数、浴室数、延床面積、敷地面積、築年数、物件タイプ、掲載ステータス、Zestimateが含まれます。
Tableauダッシュボードのアイデア:
- 郵便番号ごとの平方フィートあたりの価格ヒートマップ
- 掲載価格とZestimateの差額分析
- 都市または郵便番号別の住宅タイプ分布
- 改修の機会を把握するための築年数対価格の散布図
最大のメリット:一度パターンを把握すれば、あらゆるデータソースに適用できます。Amazon、Zillow、LinkedInの求人情報――これらすべてが、Bright Dataの同一インフラストラクチャを利用してTableauダッシュボードにデータを送信しています。
TableauにおけるライブWebデータの主な活用例トップ6
チームがTableauにWebデータパイプラインを構築する最も一般的な理由は以下の通りです。
1. 競合他社の価格監視
Amazon、Walmart、Target、あるいはあらゆるeコマースプラットフォームにおける競合他社の価格を追跡します。市場全体の日々の価格変動、過去の傾向、価格ポジショニングを表示するTableauダッシュボードを構築します。競合他社の価格が自社の最低価格を下回った際にアラートを設定します。
Bright Dataの120種類以上の既製スクレイパーを活用し、複数のマーケットプレイスにまたがる数千のSKUを監視できます。カスタムスクレイパーは不要です。
Tableauのビュー:価格ウォーターフォールチャート、SKUごとの時系列トレンド、競合他社の価格ヒートマップ。
2. ソーシャルメディアでのブランド追跡
Instagram、Twitter/X、TikTok、LinkedInから、言及数、エンゲージメント指標、フォロワー数、コメントデータを取得します。プラットフォーム横断でのブランド可視性を追跡し、キャンペーンの経時的なパフォーマンスを測定するダッシュボードを構築します。スクレイピングブラウザは、標準的なHTTPリクエストではレンダリングできないJavaScriptを多用するソーシャルプラットフォームにも対応します。
Tableauビュー:エンゲージメント率の推移、期間ごとの言及数、プラットフォーム比較棒グラフ。
3. 求人市場分析
Indeed、Glassdoor、LinkedIn(GitHubリポジトリ)、およびニッチな求人サイトから求人情報を集約します。業界や地域ごとの採用動向、給与ベンチマーク、必須スキル、需要の変化を分析します。人事チームや採用担当者は、これらのダッシュボードを活用して報酬水準をベンチマークし、競合他社に先駆けて人材市場の変動を把握します。
Tableauビュー:求人情報の地理的バブルマップ、給与分布ヒストグラム、スキル需要のツリーマップ。
4. 不動産ダッシュボード
Zillow、Realtor.com、Redfin、Airbnbからの物件情報、価格変動、在庫水準、近隣のトレンドを監視します。不動産投資家やアナリストは、Tableauで地理的なヒートマップを作成し、過小評価されている市場を特定したり、都市ごとの賃貸利回りのトレンドを追跡したりしています。
Tableauのビュー:郵便番号別ヒートマップ、平方フィートあたりの価格の散布図、物件掲載数の時系列データ。
5. 金融データフィード
Yahoo Finance、Bloomberg、その他の金融プラットフォームから、株価、決算報告、アナリスト評価、インサイダー取引データ、金融ニュースを収集します。定量アナリストやポートフォリオマネージャーは、データの自動更新機能を備えた金融ダッシュボードを作成し、ポートフォリオのパフォーマンスや市場のシグナルを追跡します。
Tableauのビュー:ローソク足形式の価格チャート、決算サプライズの棒グラフ、セクターローテーションのダッシュボード。
6. サプライチェーンの監視
グローバルなマーケットプレイス全体における商品の在庫状況、配送予定日、販売者の在庫レベル、価格を追跡します。オペレーションチームは、突然の在庫切れや配送時間の急増といった供給の混乱を、サプライチェーンの他の部分に悪影響が及ぶ前に検知するTableauダッシュボードを構築します。
Tableauのビュー:在庫状況マトリックス、配送時間のトレンドライン、サプライヤーリスクスコアカード。
これらのユースケースはいずれも、Bright Data API → 構造化データ → Tableauダッシュボードという同じアーキテクチャに従います。変更されるのは、データセットIDと作成するTableauのビジュアライゼーションのみです。
Bright Data APIパイプラインの仕組み
チュートリアルスクリプトは、トリガー処理とポーリングを処理します。API呼び出しからTableauダッシュボードに至るまでの、パイプライン全体での処理の流れは以下の通りです。
データフローのステップバイステップ
- トリガー。PythonスクリプトがBright Dataの
/triggerエンドポイントにPOSTリクエストを送信します。キーワード(ディスカバリー用)またはURLのリスト(ターゲット収集用)のいずれかを指定します。APIは直ちにsnapshot_idを返します。 - 収集。Bright Dataのインフラストラクチャは、1億5,000万以上のレジデンシャルプロキシを経由してリクエストをルーティングします。CAPTCHAの検証を自動的に処理し、必要に応じてJavaScriptをレンダリングし、失敗したリクエストを再試行します。
- パース。Bright Dataは生のHTMLを構造化されたデータフィールドにパースします。Amazon商品の場合、これにはタイトル、価格、評価、レビュー、販売者情報、在庫状況などが含まれますが、返される具体的なフィールドはデータセットや検索タイプによって異なります。
- スナップショット。収集とパースが完了すると、Bright Dataはデータをスナップショットとして保存します。スクリプトは、
ステータスが202(処理中)から200(準備完了)に変わるまで、/snapshotエンドポイントをポーリングします。 - 配信。スナップショットをJSONまたはCSV形式で取得します。あるいは、Amazon S3、Google Cloud Storage、Azure Blob、Snowflake、SFTP、またはWebhookへの配信を設定することも可能です。自動配信は、データをデータウェアハウスに保存する本番環境のパイプラインに役立ちます。
- 変換。スクリプト(またはpandasなどのツール)を使用して、列の名前を変更し、フィールドをフィルタリングし、Tableauが読み取れる形式にデータを整形します。ここで、スクレイプ日時やデータソースなどのメタデータ列を追加します。
- 可視化。Tableauは出力ファイルを読み込み(または、データをデータベースにロードしている場合はデータベースに接続し)、最新のデータを使用してダッシュボードをレンダリングします。
パイプラインの拡張
本番環境での利用には、以下の機能強化を検討してください:
- 複数のキーワード。スクリプト内でキーワードや製品カテゴリのリストをループ処理し、包括的なデータセットを構築します。
- データベースへの保存。CSVの代わりに、PostgreSQLやMySQLに書き込みます。Tableauはこれら両方にネイティブで接続でき、時間の経過とともに履歴データが蓄積されるため、トレンド分析に役立ちます。
- オーケストレーション。Apache Airflow、Prefect、またはcronジョブを使用して、ビジネスに必要な頻度(毎時、毎日、毎週)で実行をスケジュールします。
- Webhookによる配信。結果の準備が整った時点でBright DataからサーバーへPOST送信するよう設定することで、ポーリングを完全に省略できます。
本番環境チェックリスト
パイプラインを本番スケジュールにデプロイする前に、以下の運用上の課題に対処してください:
- エラー処理。API呼び出しをtry/exceptブロックで囲み、リトライロジックを実装してください。ファイルまたは監視サービスに障害をログ記録し、古いデータを早期に検出できるようにします。
- データの重複排除。一意のキー(ASIN + スクレイピング日時など)を追加し、Tableauに読み込む前に重複排除を行ってください。重複行があると集計結果が歪みます。
- スキーマの検証。CSVへの書き込み前に、APIレスポンスに期待されるフィールドが含まれていることを確認してください。ウェブサイトの変更により、予告なしにデータ構造が変更される可能性があります。
- 監視とアラート。実行の失敗、データセットの空状態、または予期せぬ行数の急減に対して、アラート(メール、Slack、またはPagerDuty)を設定します。
- データのバックアップ。各CSVスナップショットにタイムスタンプを付けてアーカイブします。不正なスクレイピングによって作業ファイルが破損した場合、以前のバージョンにロールバックできるようにします。
TableauパイプラインにBright Dataを選ぶ理由
本番環境の Tableau ワークフローにおいて、以下の要素が重要です:
- 柔軟なデータ配信。API、Webhook、Amazon S3、Google Cloud、Azure、またはSFTP経由で、結果をJSON、CSV、またはNDJSON形式で取得できます。データをTableauデータウェアハウスにロードします。
- カスタムまたは既製。Serverless Functionsを使用してカスタムスクレイパーを作成したり、Scraper StudioでAIを活用した自動生成スクレイパーを作成したり、コードを書かずに即座にアクセスできる既製データセットを利用したりできます。
- コスト効率の良さ。従量課金制で1,000レコードあたり1.50ドル、上位プランではボリュームディスカウントにより1,000レコードあたり0.75ドルまで割引されます。
ライブWebデータパイプラインを構築
利用可能なデータと必要なデータとのギャップは拡大し続けており、特にそのデータがAPIやコネクタのないオープンウェブ上に存在する場合、その傾向は顕著です。
WDC v2は非推奨となり、サポート対象外です。Google スプレッドシートはセル数に制限があります。Excelでは手作業が必要です。TabPyにはプロキシローテーション機能が欠けています。自作スクリプトは大規模になると動作しなくなります。
Bright DataのWebスクレイパーAPIは、これらのアプローチに欠けているインフラストラクチャ層を提供します。 このAPIには、120種類以上の既製スクレイパー、195カ国にまたがる1億5,000万以上のプロキシ、自動CAPTCHAの解決機能、およびTableauがネイティブでサポートする形式での構造化データ出力が含まれています。価格は1,000レコードあたり1.50ドルからで、99.99%の稼働率と、GDPR準拠、CCPA、ISO 27001への完全な準拠を保証します。
データ収集インフラの構築に時間を費やすのではなく、ダッシュボードの作成に集中しましょう。
よくある質問
Tableau WDCは非推奨になりましたか?
はい。TableauのWeb Data Connector v2は、2023.1リリースで正式に非推奨となりました。WDC v2をサポートする最後のバージョンであるTableau 2022.4は、サポート終了(EOL)を迎えています。WDC v2コネクタは現在のすべてのTableauバージョンでサポートされておらず、今後のアップデートで削除される可能性があります。
Tableau WDCの後継は何ですか?
TableauはWDC v3をリリースしましたが、これは抽出専用であり、Tableau Bridgeではサポートされていません。ライブWebデータについては、スクレイピングAPIパイプライン(Bright Data → CSV/JSON → Tableau)が実用的な代替手段となります。本ガイドのチュートリアルでは、そのパイプラインを構築します。
TableauはウェブスクレイピングAPIに直接接続できますか?
ネイティブにはできません。Tableauはデータベース、ファイル、および特定のクラウドサービスに接続します。スクレイピングAPIを使用するには、APIを呼び出してデータを受信するPythonまたはNode.js製の軽量スクリプトが必要です。その後、スクリプトはTableauが読み取れる形式(CSV、JSON、またはデータベースへの挿入)でデータを出力します。
Tableauダッシュボードのデータを最新の状態に保つにはどうすればよいですか?
cron(Linux/Mac)、タスク スケジューラ(Windows)、または Apache Airflow のようなワークフローオーケストレーターを使用して、データ収集スクリプトをスケジュールします。スクリプトは Bright Data の API から最新のデータを取得し、CSV ファイルを上書きします。Tableau は次の更新サイクルで更新されたデータを読み込みます。
TableauにWebデータを読み込むにはいくらかかりますか?
Bright DataのWebスクレイパーAPIは、従量課金制で1,000レコードあたり1.50ドルから利用可能で、ボリュームディスカウントにより1,000レコードあたり0.75ドルまで下がります。1日あたり5,000製品を追跡する一般的な競合他社モニタリングダッシュボードの場合、1日あたり約7.50ドル、または月額約225ドルとなります。
Bright DataはTableau向けにどのようなデータ形式を出力しますか?
Bright DataはAPI経由でJSON、CSV、またはNDJSON形式でデータを提供します。Tableauの場合、CSVが最も直接的な選択肢です。Tableauは変換を必要とせず、ネイティブで読み込むことができます。あるいは、本番環境のパイプライン向けに、Amazon S3、Google Cloud Storage、Azure Blob、Snowflake、SFTP、またはWebhookへの自動配信を設定することも可能です。
Bright DataをTableau Publicで使用できますか?
はい。Bright Dataは、Tableau Publicがネイティブで読み込める標準的なCSVファイルを出力します。ただし、制限はTableau Public側にあります。ファイルベースのソースに対する定期的な更新はサポートされていません。データが更新されるたびに、データ収集スクリプトを再実行し、ワークブックを再公開する必要があります。





