
検索強化生成(RAG)アプリケーションを構築する場合、チュートリアルの静的なPDFではなく、トピックに関する最新のデータが必要です。しかし、実際の記事をスクレイピングするには、ボット対策の壁やリクエストのブロックといった課題があります。データを入手できたとしても、チャンク化、埋め込み、インデックス作成、そして検索機能の連携を行う必要があります。
このチュートリアルでは、そのすべてを実現します。Bright Dataが任意のトピックに関する記事を見つけスクレイピングし、Weaviateがそれらを保存・検索し、たった1つのPythonスクリプトで出典付きの回答を得ることができます。
要約
どんなトピックでも、検索可能なQ&Aナレッジベースに変えられます。しかも、古いトレーニングデータではなく、リアルタイムのウェブデータを活用します。
- Bright Data SERP APIがトピックに関連する実際の記事のURLを特定し、Web Unlockerがそれらをスクレイピングします(ボット対策が施されたサイトでも対応)。
- WeaviateはCohereを介してチャンクを自動ベクトル化し、ハイブリッド検索でインデックスを作成し、単一のAPI呼び出しで出典付きの回答を生成します
python3のpipeline.pyを実行し、トピックを入力するだけで、数分以内に引用元が明記されたRAG回答を取得できます。- GitHubに完全なソースコードを公開しています。クローンして実行してください
APIキーを取得し、ご自身のトピックで試してみてください。
最終的な出力は以下のようになります:

3~5分でパイプラインを実行
すでにAPIキーをお持ちの場合は、今すぐパイプラインを実行してください:
# 1. リポジトリをクローンする(Python 3.10以上が必要)
git clone https://github.com/triposat/weaviate-bright-data-rag.git
cd weaviate-bright-data-rag
# 2. 依存関係をインストールする
pip3 install -r requirements.txt
# 3. .env ファイルを作成します
cp .env.example .env
# .env を編集し、API キーを入力します(以下の「API キーの取得」を参照)
# 4. 実行します
python3 pipeline.pyパイプラインはトピックを要求し、Bright Dataのゾーンを自動検出します。実際の記事を見つけ、スクレイピングします。記事をチャンクに分割してWeaviateに保存し(Cohere経由で自動ベクトル化)、デモクエリを実行した後、インタラクティブモードに移行して、ユーザー自身の質問に対応します。
APIキーの取得(無料でお試しいただけます)
3つのAPIキーが必要です(各サービスから1つずつ)。CohereとWeaviateはクレジットカード不要です。Bright Dataは登録時に無料トライアルクレジットを提供します。
1. Bright Data APIキー
APIキーと2つのゾーンを作成します:
- brightdata.comでサインアップ
- 「アカウント設定」→「ユーザーとAPIキー」に移動
- 新しいAPIキーを作成→ コピー →
.envファイル内のBRIGHT_DATA_API_TOKEN値として貼り付け
また、パイプラインには「SERP API」と「Web Unlocker」の2つのゾーンが必要です。「Proxies & Scraping」→「My Zones」で既に存在するか確認してください。表示されない場合は、以下のように作成してください:
- 「Proxies & Scraping」→「My Zones」を選択
- [追加] を選択 → ゾーンタイプとして[SERP API] を選択 → 任意の名前を付ける(例:
serp) → 保存 - 再度「追加」を選択 → ゾーンタイプとして「Unlocker API」を選択 → 任意の名前を付ける(例:
unlocker) → 保存
ゾーン名やパスワードをコピーする必要はありません。パイプラインはAPIキーを使用して自動的にそれらを検出します。
2. Cohere APIキー(無料)
このパイプラインでは、Cohereが埋め込みと生成の両方を処理します:
- dashboard.cohere.comにアクセスします
- Google、GitHub、またはメールアドレスでサインアップ(クレジットカードは不要)
- ダッシュボードにトライアル用APIキーが表示されます。それをコピーしてください
- トライアルプランにはレート制限がありますが、利用枠は十分です(自動実行では20回未満の呼び出しを使用し、対話型の質問1つごとに2回分が追加されます)
3. Weaviate Cloudの認証情報(無料)
ベクトルの保存とクエリ実行を行う無料のサンドボックスクラスターを作成します:
- console.weaviate.cloudにアクセスしてください
- GoogleまたはGitHubでサインアップしてください
- 「クラスターの作成」を選択 → 「サンドボックス(無料)」を選択 → リージョンを選択 → 作成
- 約30秒待ち、その後クラスターを選択 →[詳細]タブ
- RESTエンドポイント(クラスターのURL)とAPIキーをコピーします
注:Sandboxクラスターは14日後に期限切れになります。クラスターの有効期限が切れた場合は、新しいクラスターを作成し、.envファイル内のURLとキーを更新してください。pipeline.pyを再実行して、データを再インポートしてください。
3つのキーをすべて入手したら、「3~5分でパイプラインを実行する」セクションに戻り、クローン/インストールの手順に従ってください。
RAGパイプラインのエンドツーエンドの仕組み
パイプラインは、データ収集、処理、ベクトル保存、生成の4つのステップで構成されています:
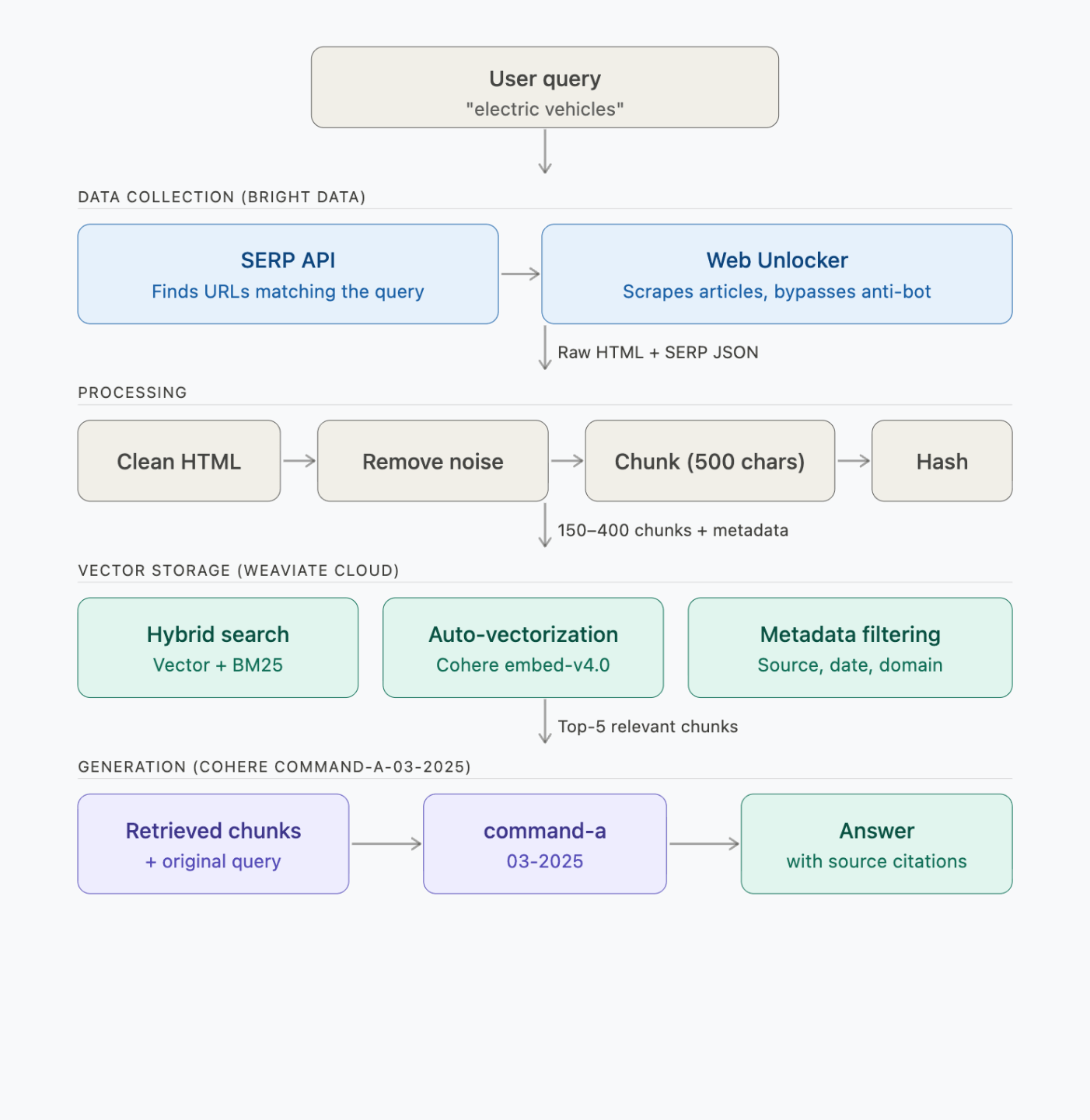
各ステップでは、以下のAPI呼び出しが行われます:
| ステップ | 実行内容 | 所要時間 | API呼び出し |
|---|---|---|---|
| 1. 検索 + スクレイピング | Bright Data SERP + Web Unlocker | 約2~3分 | 2件のSERP + 6件のスクレイピングリクエスト |
| 2. 処理 + チャンク化 | ローカル(BeautifulSoup + チャンカー) | 1秒未満 | 0 |
| 3. 埋め込み + 保存 | Weaviate → Cohere embed-v4.0 | 約30~60秒 | 約150~400個の埋め込み(バッチ処理) |
| 4. クエリ(3つのデモ) | Weaviate → Cohere command-a-03-2025 | クエリあたり約5秒 | クエリごとに検索1回 + 生成1回 |
パイプラインにおけるBright Dataの役割
Bright DataはWebデータプラットフォームです。このパイプラインでは、以下の2つの役割を担っています:
| 製品 | このパイプラインでの動作 |
|---|---|
| SERP API | トピックを入力すると、SERP APIがGoogleを検索し、実際の記事のURLを返します。固定されたURLは必要ありません |
| Web Unlocker | トピックごとに6つの記事をスクレイピングします。ボット対策が施されたサイトも含みます。各記事は20万~180万文字です |
このパイプラインはSERP APIとWeb Unlockerを使用しています。その他のデータ収集手法については、Bright Dataの製品一覧をご覧ください。
RAGにBright Dataを利用する理由
RAG用のスクレイピングを行う際に重要なポイントは以下の通りです:
- 信頼性の高いスクレイピング。Web Unlockerはリトライ、IPローテーション、ブラウザフィンガープリントを自動的に処理するため、実行中にボット対策ページでパイプラインが停止することはありません。
- LLM対応の出力。Crawl APIは生のHTMLではなくクリーンなMarkdownを返すため、埋め込みパイプラインの前処理が不要になります(このチュートリアルではWeb UnlockerとBeautifulSoupを使用していますが、生のHTMLが必要ない場合はCrawl APIの方が高速です)。
- スケーラビリティ。このチュートリアルでは6件の記事をスクレイピングしていますが、本番環境では6,000件必要になるかもしれません。BrightDataのAIインフラストラクチャは、お客様の側でコードを変更することなく、その規模での同時スクレイピングをサポートします。
- コンプライアンス。Bright DataはGDPR準拠およびCCPAに準拠しており、ネットワークへのフルアクセスを許可する前に本人確認を必須としています。
パイプラインにおけるWeaviateの役割
Weaviateはオープンソースのベクトルデータベースです。単一のAPI呼び出しで検索と生成を実行するため、LLMを別途呼び出す必要はありません。
ここでは、Weaviateがスクレイピングしたチャンクを保存し、Cohereを通じてベクトル化します。クエリを実行すると、ハイブリッド検索が実行され、生成型検索APIを通じて回答が生成されます。
| 機能 | このパイプラインでの動作 |
|---|---|
| ハイブリッド検索 | 調整可能なアルファパラメータを介して、セマンティックベクトル(70%)とBM25キーワードマッチング(30%)を組み合わせます |
| 統合型ジェネレーティブ検索 | generate.hybrid()の単一の呼び出しで、上位5つのチャンクを取得し、引用された回答を生成します |
| 自動ベクトル化 | Weaviateはインポート時に自動的にCohereの埋め込みAPIを呼び出します。埋め込み用のコードを記述する必要はありません |
| メタデータフィルタリング | 各チャンクと共に、ソースURL、ドメイン、スクレイピング日時、コンテンツタイプを保存 |
大規模環境でのWeaviate
Weaviateには、このパイプラインでは使用されていませんが、大規模運用において重要な機能も備わっています:
- BSD 3条項ライセンス– 必要に応じてセルフホスティングやフォークが可能です
- 複数のデプロイオプション– Weaviate Cloud(無料サンドボックス)、Dedicated Cloud、セルフホスト型Kubernetes
- マルチテナント– SaaSアプリケーション向けにノードあたり50,000以上のテナントに対応
- 回転量子化– 98~99%のリコール率でベクトルを4倍圧縮
RAGパイプラインを段階的に構築する
以下の各ステップでは、pipeline.py のコアロジックを示します。完全なソースコードはGitHub にあります。
プロジェクトの設定とインポート
まず、依存関係をインポートし、.envファイルから認証情報を読み込みます:
import os
import sys
import time
import hashlib
import requests
import urllib3
from urllib.parse import quote
from datetime import datetime, timezone
from dotenv import load_dotenv
from bs4 import BeautifulSoup
import weaviate
from weaviate.classes.init import Auth
from weaviate.classes.config import Configure, Property, DataType
urllib3.disable_warnings()
load_dotenv()
# .env から認証情報を読み込む
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
WEAVIATE_URL = os.getenv("WEAVIATE_URL")
WEAVIATE_API_KEY = os.getenv("WEAVIATE_API_KEY")
BD_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
COLLECTION_NAME = "WebResearch"
def clean_url(url):
"""URL内のnbspアーティファクトを修正します(一部のサイトにおける エンコーディングの問題によるもの)。"""
cleaned = url.replace("nbsp", "-")
while "--" in cleaned:
cleaned = cleaned.replace("--", "-")
return cleaned
def clean_generated_text(text):
"""LLMが生成したテキストを、ターミナル表示用にクリーンアップします。"""
text = text.replace("**", "")
text = text.replace("nbsp", "-")
while "--" in text:
text = text.replace("--", "-")
return text処理を開始する前に、パイプラインは.envファイルにすべての必要な認証情報が設定されているかを確認します:
def validate_env():
"""必要な環境変数がすべて設定されているか確認します。"""
missing = []
if not BD_API_TOKEN:
missing.append("BRIGHT_DATA_API_TOKEN")
if not COHERE_API_KEY:
missing.append("COHERE_API_KEY")
if not WEAVIATE_URL:
missing.append("WEAVIATE_URL")
if not WEAVIATE_API_KEY:
missing.append("WEAVIATE_API_KEY")
if missing:
print("ERROR: .env ファイルに環境変数が不足しています:")
for var in missing:
print(f" - {var}")
# ... 例となる .env フォーマットを出力 ...
print("n各キーの取得方法についてはブログ記事をご覧ください(すべて無料で始められます)。")
sys.exit(1)ゾーン名やパスワードを設定する必要はありません。パイプラインがAPIキーから自動的に検出します:
def discover_bright_data_credentials():
"""
APIキーからBright Dataのプロキシ認証情報を自動検出します。
どのBright Dataアカウントでも動作します。ハードコーディングされた値は不要です。
"""
headers = {"Authorization": f"Bearer {BD_API_TOKEN}"}
# 1. アクティブなゾーンを取得
zones = requests.get(
"https://api.brightdata.com/zone/get_active_zones", headers=headers
).json()
# 各タイプの最初のゾーンを選択(複数ある場合は、名前を明示的に設定してください)
zone_names = {}
for z in zones:
if z["type"] not in zone_names:
zone_names[z["type"]] = z["name"]
# "unblocker" は Web Unlocker 製品の API 名です
unlocker_zone = zone_names.get("unblocker")
serp_zone = zone_names.get("serp")
# 2. ゾーンのパスワードを取得
unlocker_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={unlocker_zone}",
headers=headers,
).json()["passwords"][0]
serp_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={serp_zone}",
headers=headers,
).json()["passwords"][0]
# 3. 顧客IDの取得(costエンドポイントは {customer_id: cost_data} を返す)
cost = requests.get(
f"https://api.brightdata.com/ゾーン/コスト?ゾーン={unlocker_ゾーン}",
headers=headers,
).json()
customer_id = list(cost.keys())[0]
return customer_id, unlocker_ゾーン, unlocker_pwd, serp_ゾーン, serp_pwdリポジトリをクローンし、APIキーを追加すれば、あとはパイプラインが自動的に処理します。
ステップ1:Bright Dataを使用して記事の検索とスクレイピングを行う
このパイプラインはSERP APIを使用してトピックに関連する記事のURLを検索し、Web Unlockerを通じて各記事をスクレイピングします:
def get_bd_proxy(customer_id, zone, password):
"""Bright DataのプロキシURLを生成します。"""
proxy = f"http://brd-customer-{customer_id}-zone-{zone}:{password}@brd.superproxy.io:33335"
return {"http": プロキシ, "https": プロキシ}
def search_serp(query, customer_id, zone, password, num=10):
"""Bright Data SERP API 経由で Google を検索し、オーガニック検索結果を返す。"""
proxies = get_bd_proxy(customer_id, zone, password)
# brd_json=1 を指定すると、Bright Data に生の HTML ではなく構造化された JSON を返すよう指示します
search_url = f"https://www.google.com/search?q={quote(query)}&brd_json=1&num={num}"
try:
# verify=False を指定すると、BD プロキシの SSL 検証をバイパスします。
# 本番環境では、代わりにBright DataのCA証明書をインストールしてください:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(search_url, proxies=proxies, timeout=30, verify=False)
if response.status_code == 200:
data = response.json()
return [
{
"title": item.get("title", ""),
"url": item.get("link", ""),
"description": item.get("description", ""),
}
for item in data.get("organic", [])
]
except Exception as e:
print(f"SERP error: {str(e)[:60]}", end=" ", flush=True)
return []search_serp() は、クエリを Bright Data の SERP プロキシ経由で送信し、構造化された JSON(タイトル、URL、説明文)を返します。brd_json=1パラメータを指定すると、Bright Data が Google の HTML をクリーンな JSON に変換して返します。
次に、find_articles_for_topic()はトピックごとに 2 つの SERP クエリを実行して結果をフィルタリングし、scrape_url()は Web Unlocker を通じて各記事を取得します:
def find_articles_for_topic(topic, customer_id, serp_zone, serp_pwd):
"""Bright Data SERP APIを使用して、トピックに関する実際の記事URLを検索します。"""
search_queries = [
f"{topic} 最新ニュースとトレンド",
f"{topic} 詳細分析ガイド",
]
# 記事以外のコンテンツ(動画、フィード、ソーシャルメディア)を返すドメインをスキップ
skip_domains = {
"youtube.com", "twitter.com", "x.com", "facebook.com", "instagram.com",
"reddit.com", "linkedin.com", "wikipedia.org", "amazon.com", "tiktok.com",
}
skip_extensions = (".pdf", ".doc", ".ppt", ".xls", ".zip", ".mp4", ".mp3")
all_urls = []
seen_domains = set()
serp_docs = []
for query in search_queries:
results = search_serp(query, customer_id, serp_zone, serp_pwd, num=10)
if results:
# SERPのタイトルと説明文をドキュメントとして保存し、フルスクレイピングが失敗した場合でもLLMが
# 記事の要約を参照できるようにする
serp_text = f"Google検索結果: {query}nn"
for r in results:
serp_text += f"タイトル: {r['title']}nURL: {r['url']}n"
serp_text += f"概要: {r['description']}nn"
serp_docs.append({
"url": f"https://google.com/search?q={quote(query)}",
"html": serp_text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
"is_serp": True,
})
# 記事のURLを抽出(多様性を確保するため、ドメインごとに1つずつ)
for r in results:
url = r.get("url", "")
if not url:
continue
domain = url.split("/")[2] if "://" in url else ""
base_domain = ".".join(domain.split(".")[-2:])
if base_domain in skip_domains:
continue
if any(url.lower().endswith(ext) for ext in skip_extensions):
continue
if base_domain in seen_domains:
continue # 多様性を確保するため、ドメインごとに1記事のみ
seen_domains.add(base_domain)
all_urls.append(url)
return all_urls[:6], serp_docs # 上位6つのURL
def scrape_url(url, customer_id, zone, password, retries=2):
"""Bright Data Web Unlockerを使用して、自動リトライ機能付きでURLをスクレイピングします。"""
proxies = get_bd_proxy(customer_id, zone, password)
# カスタムヘッダーは不要:Web UnlockerがUser-Agent、
# クッキー、フィンガープリントを自動的に管理します。
for attempt in range(retries + 1):
try:
# verify=False を指定すると、BDプロキシのSSL検証がバイパスされます。
# 本番環境では、代わりにBright DataのCA証明書をインストールしてください:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(
url, proxies=proxies, timeout=60, verify=False
)
if response.status_code == 200:
return {
"url": url,
"html": response.text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}
else:
print(f"HTTP {response.status_code}", end=" → ", flush=True)
except Exception as e:
print(f"Error: {str(e)[:60]}", end=" → ", flush=True)
if attempt < retries:
time.sleep(2)
return Nonecollect_data()は両方のステップを組み合わせたものです。SERPがURLを見つけ、Web Unlockerがそれらをスクレイピングします:
def collect_data(topic, customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd):
"""SERPを介してトピックに関する記事を見つけ、Web Unlockerでスクレイピングします。"""
documents = []
# 1. SERP APIを使用して記事のURLを検索
urls_to_scrape, serp_docs = find_articles_for_topic(
topic, customer_id, serp_zone, serp_pwd
)
if not urls_to_scrape:
return []
# 2. Web Unlockerを使用して見つかった記事をスクレイピングする
for i, url in enumerate(urls_to_scrape):
domain = url.split("/")[2] if "://" in url else url
print(f" ({i+1}/{len(urls_to_scrape)}) {domain}... ", end="", flush=True)
result = scrape_url(url, customer_id, unlocker_zone, unlocker_pwd)
if result:
documents.append(result)
print(f"OK ({len(result['html']):,} 文字)")
else:
print("失敗 (スキップします)")
# 3. SERPの結果を追加のドキュメントとして追加
documents.extend(serp_docs)
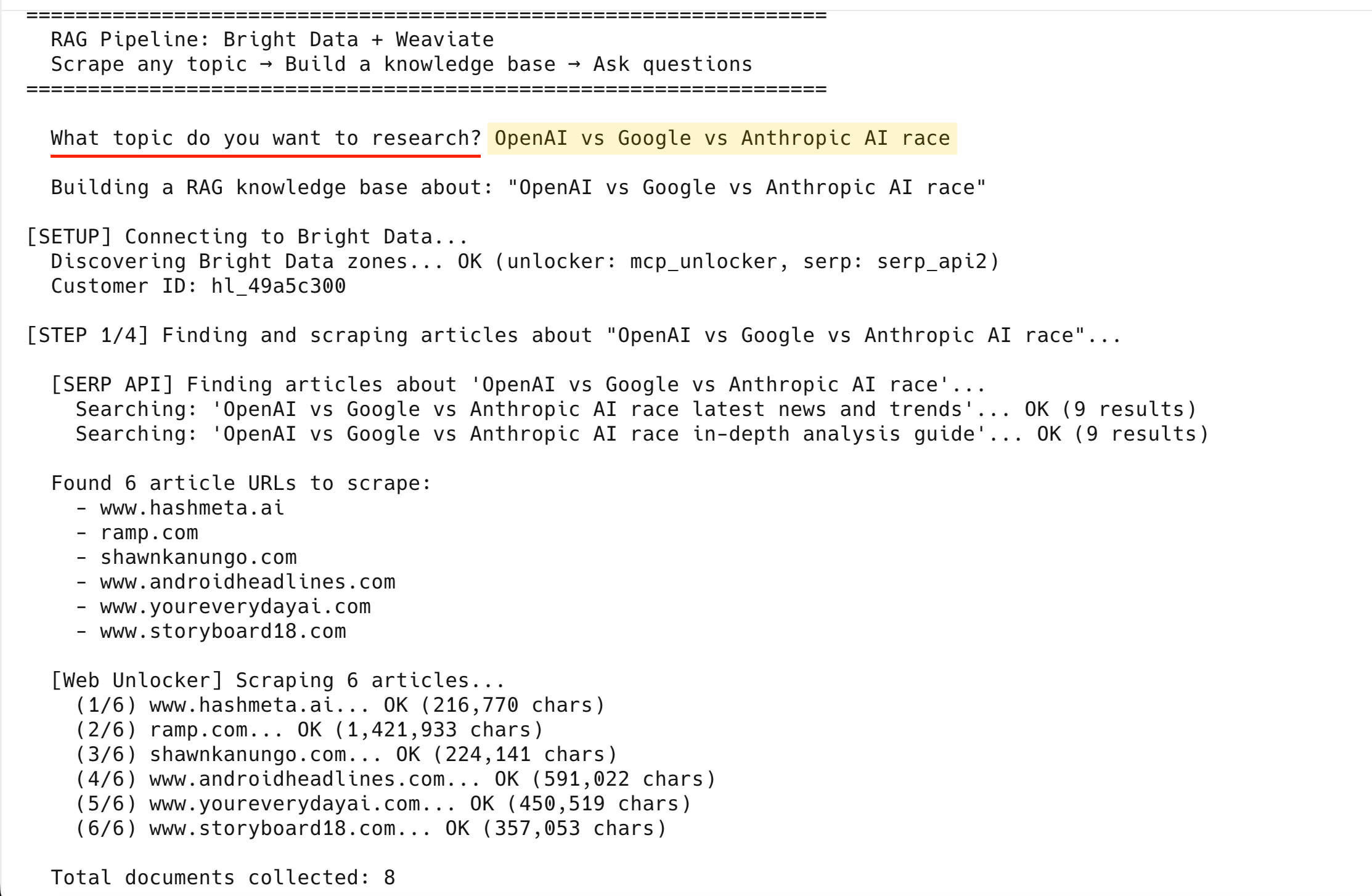
return documents「OpenAI vs Google vs Anthropic AI race」で実行すると、次のような出力が得られます:
[SERP API] 'OpenAI vs Google vs Anthropic AI race' に関する記事を検索中...
検索中: 'OpenAI vs Google vs Anthropic AI race 最新ニュースとトレンド'... OK (9件の結果)
検索中: 'OpenAI vs Google vs Anthropic AI race 詳細分析ガイド'... OK (9件の結果)
スクレイピング対象の記事URLを6件検出しました:
- www.hashmeta.ai
- ramp.com
- shawnkanungo.com
- www.androidheadlines.com
- www.youreverydayai.com
- www.storyboard18.com
[Web Unlocker] 6件の記事をウェブスクレイピング中...
(1/6) www.hashmeta.ai... OK (216,770 文字)
(2/6) ramp.com... OK (1,421,933 文字)
(3/6) shawnkanungo.com... OK (224,141 文字)
(4/6) www.androidheadlines.com... OK (591,022 文字)
(5/6) www.youreverydayai.com... OK (450,519 文字)
(6/6) www.storyboard18.com... OK (357,053 文字)
収集されたドキュメントの総数: 86件すべて正常にスクレイピングされました。2つのSERP結果ページを含め、合計8件のドキュメントとなりました。
Web UnlockerがURLに対して3回試行しても失敗した場合、パイプラインはそのURLをスキップし、残りの記事の処理を続行します。
この時点で、8つの生データ(記事6件+SERP結果ページ2件)が揃っています。次に、埋め込み用にデータをクリーニングし、チャンク分けします。
ステップ2:データのクリーニングとチャンク化
生のHTMLの約90%はノイズです。処理ステップではこれを除去してクリーンなテキストにし、可能な限り文の区切りで分割して500文字(約125トークン)のチャンクに分割します。
チャンクサイズはRAGの核心的なトレードオフを左右します。小さいチャンク(200~500文字)は事実ごとの検索精度を高めますが、大きいチャンク(1000~2000文字)はLLMに周囲の文脈をより多く提供できる反面、検索結果のノイズが増えるという代償を伴います。500文字のデフォルト設定は、事実に基づく質問(「エンタープライズ分野において、AnthropicのOpenAIに対する勝率はどれくらいか?」)に適しています。 要約や比較など、より広い文脈を必要とするクエリでは、chunk_sizeを1500~2000に増やしてください。
50文字のオーバーラップ設定により、境界部分での情報損失を防ぎます。これを設定しないと、2つのチャンクにまたがる文が分割され、どちらのチャンクにも完全な文脈が含まれなくなってしまいます。
def clean_html(html, is_serp=False):
"""ナビゲーション、広告、定型文を削除し、HTMLをクリーンなテキストに変換します。"""
if is_serp:
return html # SERPの結果はすでにクリーンなテキストです
soup = BeautifulSoup(html, "html.parser")
# 不要な要素を削除
for tag in soup(["nav", "footer", "header", "script", "style",
"aside", "iframe", "noscript", "svg", "form", "button"]):
tag.decompose()
# 一般的な広告/クッキー/ポップアップコンテナを削除
for selector in [".ad", ".ads", ".cookie", ".popup", ".modal", ".sidebar",
"#cookie-banner", "#ad-container", "[role='banner']",
"[role='navigation']", "[role='complementary']"]:
for el in soup.select(selector):
el.decompose()
text = soup.get_text(separator="n", strip=True)
lines = [line.strip() for line in text.splitlines() if line.strip()]
return "n".join(lines)
def chunk_text(text, chunk_size=500, chunk_overlap=50):
"""テキストを文の境界で分割し、重複するチャンクに分割します。
overlap パラメータにより、チャンク境界にある文がチャンク間で失われないようにします。"""
if len(text) <= chunk_size:
return [text]
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# 文の区切りで分割を試みる
if end < len(text):
for sep in [". ", ".n", "nn", "n", " "]:
last_sep = text[max(start, end - 100):end].rfind(sep)
if last_sep != -1:
end = max(start, end - 100) + last_sep + len(sep)
break
chunk = text[start:end].strip()
if chunk and len(chunk) > 50:
chunks.append(chunk)
start = end - chunk_overlap
return chunks
def process_documents(documents):
"""すべてのドキュメントをクリーンアップし、チャンクに分割し、メタデータを追加する。"""
all_chunks = []
for doc in documents:
is_serp = doc.get("is_serp", False)
clean_text = clean_html(doc["html"], is_serp=is_serp)
if len(clean_text) < 100:
continue
chunks = chunk_text(clean_text)
domain = doc["url"].split("/")[2] if "://" in doc["url"] else "unknown"
for i, chunk in enumerate(chunks):
all_chunks.append({
"text": chunk,
"source_url": doc["url"],
"source_domain": domain,
"scraped_at": doc["scraped_at"],
"chunk_index": i,
"total_chunks": len(chunks),
"content_hash": hashlib.md5(chunk.encode()).hexdigest(),
"content_type": "serp_result" if is_serp else "article",
})
return all_chunks処理後、8つのドキュメントが(記事の長さにもよりますが)約150~400個のクリーンなテキストチャンクとなり、それぞれにメタデータ(ソースURL、ドメイン、タイムスタンプ、コンテンツハッシュ)が付与されます。
ステップ3:Weaviateへの埋め込みと保存
Weaviate Cloudに接続し、Cohereベクトル化機能を備えたコレクションを作成して、すべてのチャンクを一括インポートします。
def connect_weaviate():
"""タイムアウト時間を延長して Weaviate Cloud に接続します。"""
client = weaviate.connect_to_weaviate_cloud(
cluster_url=WEAVIATE_URL,
auth_credentials=Auth.api_key(WEAVIATE_API_KEY),
headers={"X-Cohere-Api-Key": COHERE_API_KEY},
additional_config=weaviate.classes.init.AdditionalConfig(
timeout=weaviate.classes.init.Timeout(init=30, query=60, insert=120),
),
skip_init_checks=True, # アイドル状態のサンドボックスでのgRPCタイムアウトを防止
)
if not client.is_ready():
print(" ERROR: Weaviateクラスタの準備ができていません。")
print(" .env内のWEAVIATE_URLとWEAVIATE_API_KEYを確認してください")
print(" console.weaviate.cloudでサンドボックスクラスタが実行されていることを確認してください")
sys.exit(1)
return client
def setup_collection(client):
"""ハイブリッド検索と生成型設定を備えたコレクションを作成します。"""
# この名前の既存のコレクションを削除します。新しいトピックで再実行すると、
# 以前のナレッジベースに追加されるのではなく、上書きされます。
if client.collections.exists(COLLECTION_NAME):
client.collections.delete(COLLECTION_NAME)
print(f" 既存の '{COLLECTION_NAME}' コレクションを削除しました")
client.collections.create(
name=COLLECTION_NAME,
description="RAG用にBright Data経由でスクレイピングされたWeb記事",
# Cohere embed-v4.0: インポート時にテキストを自動ベクトル化
vector_config=Configure.Vectors.text2vec_cohere(
model="embed-v4.0",
),
# Cohere command-a-03-2025: クエリ時にRAGの回答を生成
generative_config=Configure.Generative.cohere(
model="command-a-03-2025",
),
properties=[
Property(name="text", data_type=DataType.TEXT,
description="チャンクのテキストコンテンツ"),
Property(name="source_url", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="source_domain", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="scraped_at", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="chunk_index", data_type=DataType.INT,
skip_vectorization=True),
Property(name="total_chunks", data_type=DataType.INT,
skip_vectorization=True),
Property(name="content_hash", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="content_type", data_type=DataType.TEXT,
skip_vectorization=True),
],
)
print(f" '{COLLECTION_NAME}' コレクションを作成しました")いくつか注意点があります:
- メタデータフィールドに
skip_vectorization=True を設定–テキストフィールドのみが埋め込まれ、API呼び出しを節約し、よりクリーンなベクトルを生成します content_hashはチャンクごとに保存されます。増分再スクレイピングロジックを追加する際、変更のないコンテンツの再埋め込みをスキップするためにこれを使用してください(現在のパイプラインは実行のたびにデータを再インポートします)
再実行時の動作:パイプラインは実行のたびにコレクションを削除して再作成します。「AIレース」の後に「量子コンピューティング」を実行すると、AIレースのデータが上書きされます。複数のトピックを維持するには、
COLLECTION_NAMEをトピックごとに一意の名前(例:WebResearch_ai_race、WebResearch_quantum)に変更してください。
AI対応ベクトルデータセットの準備に関する詳細は、Bright Dataガイドをご覧ください。
store_chunks()関数は、すべてのチャンクをコレクションに一括挿入します:
def store_chunks(client, chunks):
"""チャンクを Weaviate にバッチインポートします(Cohere 経由で自動ベクトル化されます)。"""
collection = client.collections.use(COLLECTION_NAME)
with collection.batch.fixed_size(batch_size=50) as batch:
for chunk in chunks:
batch.add_object(properties=chunk)
failed = len(collection.batch.failed_objects) if collection.batch.failed_objects else 0
if failed > 0:
print(f" 最初のエラー: {collection.batch.failed_objects[0].message[:120]}")
return failedbatch.fixed_size(50) は、1つずつ挿入する代わりに、スループット向上のためにインポートをバッチ処理します。テスト実行では、すべてのチャンクがエラー0件でインポートされました。Weaviateは、インポート時に各チャンクを埋め込むためにCohereを呼び出します。
ステップ4: ハイブリッド検索と生成によるクエリ
すべてのチャンクが埋め込まれ、インデックス化されたら、rag_query()関数を使用してクエリを実行します。この関数はgenerate.hybrid()を呼び出し、単一のリクエストで検索と生成を行います:
def rag_query(client, question, alpha=0.7, limit=5):
"""Weaviateのハイブリッド検索と生成AIを使用したRAGクエリを実行します。"""
collection = client.collections.use(COLLECTION_NAME)
response = collection.generate.hybrid(
query=question,
alpha=alpha, # 0.7 = 70% セマンティック、30% キーワード
limit=limit,
grouped_task=f"""以下の検索結果に基づいて、この質問に答えてください:
"{question}"
指示:
- 明確で包括的な回答を提供してください
- 主要な主張ごとに情報源のURLを明記してください
- 情報が古くなっている、または矛盾していると思われる場合は、その旨を記載してください
- 回答は簡潔かつ有益なものにしてください(2~4段落)""",
)
print(f"n Q: {question}")
print(f" {'─' * 60}")
if response.generated:
print(f" A: {clean_generated_text(response.generated)}")
else:
print(" A: (応答が生成されませんでした — Cohere API キーを確認してください)")
# 記事の出典と SERP サマリーのチャンクを分離する
article_sources = []
serp_sources = []
seen_urls = set()
for obj in response.objects:
url = obj.properties.get("source_url", "unknown")
if url in seen_urls:
continue
seen_urls.add(url)
content_type = obj.properties.get("content_type", "")
domain = obj.properties.get("source_domain", "")
if content_type == "serp_result":
serp_sources.append((domain, url))
else:
article_sources.append((domain, clean_url(url)))
print(f"n ソース ({len(response.objects)} チャンクを取得):")
for domain, url in article_sources:
print(f" - [{domain}] {url}")
if not article_sources and serp_sources:
print(" (SERPサマリーに基づく — 一致する記事チャンクなし)")
return response純粋なベクトル検索では、「GPT-5」や「Claude Code」のような正確な用語を見逃す可能性があります。純粋なキーワード検索では、意味的に関連するコンテンツを見逃してしまいます。alpha=0.7のブレンドにより、その両方をカバーできます。WeaviateのBlockMax WANDアルゴリズムは、大規模な処理においてもBM25キーワードコンポーネントの高速性を維持します。
limit=5に設定すると、クエリは上位5つのチャンクを取得します。これは、ノイズでLLMを過剰に負荷させることなく、詳細な回答を得るのに十分な文脈です。複数のサブトピックにまたがる広範な質問の場合は10に増やし、正確な事実確認の場合は3に減らしてください。grouped_taskパラメータを指定すると、取得したすべてのチャンクが1つのプロンプトとしてCohereに送信され、単一の回答が生成されます。対照的に、single_promptを指定するとチャンクごとに回答が生成されます。これは文書ごとの要約には有用ですが、複数の情報源にまたがる回答には適しません。
その他のオプションについては、Bright Dataのセマンティック検索APIに関するまとめ記事をご覧ください。
4つのステップを統合する
main()関数はパイプライン全体を実行します。トピックを選択するだけで、残りの処理はすべてこの関数が行います:
def main():
print("=" * 65)
print(" RAGパイプライン: Bright Data + Weaviate")
print(" 任意のトピックをスクレイピング → ナレッジベースを構築 → 質問を行う")
print("=" * 65)
# ── 環境の検証 ──
validate_env()
# ── ユーザーにトピックを尋ねる ──
print()
try:
topic = input(" どのトピックについて調査しますか? ").strip()
except (EOFError, KeyboardInterrupt):
print("n さようなら!")
return
if not topic:
print(" トピックが入力されていません。終了します。")
return
print(f'n 次のトピックに関するRAGナレッジベースを構築中: "{topic}"')
# ── Bright Dataの認証情報を自動的に検出 ──
print("n[SETUP] Bright Dataに接続中...")
cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd = (
discover_bright_data_credentials()
)
# ── ステップ 1: トピックに関する記事の検索とスクレイピング ──
print(f'n[STEP 1/4] "{topic}" に関する記事の検索とスクレイピング中...')
documents = collect_data(
topic, cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd
)
print(f"n 収集されたドキュメントの総数: {len(documents)}")
if not documents:
print(" エラー: ドキュメントが収集されませんでした。別のトピックを試してください。")
return
# ── ステップ 2: 処理とチャンク化 ──
print("n[STEP 2/4] ドキュメントの処理とチャンク化中...")
chunks = process_documents(documents)
print(f" {len(documents)} 件のドキュメントから {len(chunks)} 個のチャンクを作成しました")
if not chunks:
print(" ERROR: チャンクが作成されませんでした。ドキュメントが短すぎる可能性があります。")
return
# ── ステップ 3: Weaviate への保存 ──
print("n[STEP 3/4] Weaviateへの保存(埋め込み+インデックス作成)中...")
print(" Weaviate Cloudに接続中...", end=" ", flush=True)
client = connect_weaviate()
print("OK")
print(" コレクションの設定中...")
setup_collection(client)
print(f" {len(chunks)} 個のチャンクをインポート中 (Cohere 経由で自動ベクトル化)...")
failed = store_chunks(client, chunks)
print(f" インポート結果: {len(chunks) - failed} 件成功、{failed} 件失敗")
# 件数を確認
collection = client.collections.use(COLLECTION_NAME)
count = collection.aggregate.over_all(total_count=True).total_count
print(f" Weaviate内のオブジェクト総数: {count}")
# ── ステップ 4: デモクエリ + 対話モード ──
print(f'n[STEP 4/4] "{topic}" に関する RAG クエリ...')
print("=" * 65)
demo_queries = [
f"{topic}の最新動向とトレンドは?",
f"{topic}における最大の課題とリスクは?",
f"{topic}の将来の見通しは?",
]
for question in demo_queries:
rag_query(client, question)
print()
# ── サマリー ──
print("=" * 65)
print(" パイプライン完了!")
print(f' トピック: "{topic}"')
print(f" - Bright Data経由で{len(documents)}件のソースをスクレイピング")
print(f" - Weaviateに{count}個のチャンクを保存")
print(f" - {len(demo_queries)}個のデモRAGクエリを実行")
print("=" * 65)
# ── 対話モード ──
print(f'n "{topic}"に関するナレッジベースの準備が整いました!')
print(" 何でも聞いてください。終了するには 'quit' と入力してください。n")
while True:
try:
user_question = input(" 質問を入力してください: ").strip()
except (EOFError, KeyboardInterrupt):
print("n さようなら!")
break
if not user_question:
continue
if user_question.lower() in ("quit", "exit", "q"):
print(" さようなら!")
break
rag_query(client, user_question)
print()
client.close()
if __name__ == "__main__":
main()実行:
python3 pipeline.pyAIレースのテスト実行によるRAGの回答
このパイプラインは、「OpenAI vs Google vs Anthropic AI競争」をトピックとして実行されました。以下はテスト実行時のRAG回答のサンプルです。実際の結果は、実行時に公開されている記事によって異なります。
クエリ 1: 「OpenAI、Google、AnthropicのAI競争における最新の動向とトレンドは何ですか?」
OpenAI、Google、AnthropicによるAI競争は急速に進化を続けており、各社が独自の強みを活かしています。OpenAIは、先駆者としての優位性を活かし、収益と一般消費者への普及においてリードを維持しています。Anthropicは、Claude Codeのような専門ツールや、AIサービスを購入する企業間での直接対決における70%の勝率を武器に、企業向け普及において差を縮めています。Googleは、比類のない計算リソースと、自社のエコシステム全体にわたるシームレスな統合を提供しています。
出典:shawnkanungo[.]com、hashmeta[.]ai、ramp[.]com
クエリ2:「OpenAI対Google対AnthropicのAI競争における最大の課題とリスクは何ですか?」
OpenAIは、特に計算リソースをパートナーシップに依存していることから、独立性を維持しつつイノベーションのペースを持続させるという課題に直面している。Googleは官僚的な硬直性に苦しみ、対話型AIによって広告クリック数が減少することで、中核となる検索広告事業を食い荒らすリスクを抱えている。安全性を最優先とする立場にあるAnthropicは、能力主導型の市場において、解釈可能性への注力を市場シェアへと転換しなければならない。
出典:hashmeta[.]ai、shawnkanungo[.]com
クエリ3:「OpenAI、Google、Anthropic AIの競争の将来展望は?」
OpenAIは収益と消費者への普及においてリードしており、そのロードマップにはGPT-5や推論コスト削減への投資が含まれている。Anthropicの将来の成功は、説明可能性に関する規制要件が生まれるかどうかにかかっている。安全性と解釈可能性への早期投資が、大きな優位性をもたらす可能性がある。Googleは依然として強力な競争相手であり、特にGeminiのようなツールを特定のユースケースに合わせて最適化したり、AIを日常のワークフローに統合したりする点で強みを発揮している。
出典:hashmeta[.]ai、shawnkanungo[.]com
各回答は、そのパイプライン実行中にスクレイピングされた記事に基づいています。各引用はステップ1でスクレイピングされた情報源を指しており、URLを開くことで主張の真偽を確認できます。スクレイピングされた記事で扱われていない内容について質問した場合、モデルはその旨を伝えるか、詳細を省いた回答をします。
デモのクエリ終了後、パイプラインは対話モードに移行し、独自の質問を行うことができます:

本番環境への移行
本番環境でこれを利用する必要がある場合は、マルチテナント機能、コンプライアンス、およびコスト管理が必要になります。(全体像については、RAGが本番環境のAIエージェント技術スタックにどのように組み込まれるかをご覧ください。)
データ分離のためのマルチテナント機能
複数の顧客向けにRAGを構築する場合、Weaviateのマルチテナント機能により、各テナントに専用のシャードと分離されたベクトルインデックスが割り当てられます:
from weaviate.classes.config import Configure
from weaviate.classes.tenants import Tenant
# コレクションでマルチテナントを有効化
collection = client.collections.create(
name="WebContent",
multi_tenancy_config=Configure.multi_tenancy(enabled=True),
# ... ベクトライザー + 生成モデル設定
)
# 各顧客に独自の分離されたテナントを割り当てる
collection.tenants.create([
Tenant(name="customer_a"),
Tenant(name="customer_b"),
Tenant(name="customer_c"),
])
# テナントごとにデータをスクレイピングして保存
tenant_collection = collection.with_tenant("customer_a")
with tenant_collection.batch.dynamic() as batch:
for chunk in customer_a_chunks:
batch.add_object(properties=chunk)1ノードで5万以上のアクティブなテナントをサポートし、20ノードのクラスターでは100万件を処理します。
コスト最適化
データ量が増加するにつれてコストを削減する4つの手法:
- Weaviateローテーション量子化– 98~99%のリコール率でベクトルを4倍圧縮。
- コンテンツハッシュ–
content_hashフィールドにより、変更のないチャンクの再埋め込みをスキップする増分更新が可能になります(上記のステップ3を参照)。 - メタデータフィールドで `
skip_vectorization=True` を設定 – 重要な部分のみを埋め込みます。 - Bright Data Dataset Marketplace– 一般的なドメインについては、スクレイピングではなく、事前に収集されたデータセットを利用します。
これらは、単一ユーザーのプロトタイプ段階を過ぎると重要になります。
よくあるエラーとその対処法
問題が発生した場合は、まずこの表を確認してください:
| 問題 | 原因 | 解決策 |
|---|---|---|
Weaviate gRPC DEADLINE_EXCEEDED |
スクレイピング中にサンドボックスクラスターがアイドル状態になった | pipeline.pyを再実行してください。スクリプトが自動的に再接続します。それでも問題が解決しない場合は、Weaviate コンソールでクラスターを確認してください |
Cohere API のレート制限 (429) |
トライアルプランはレート制限が適用されています | 1分待ってから再試行するか、Cohereダッシュボードで利用状況を確認してください。自動実行では20回未満の呼び出しを使用します。対話型のクエリごとに2回分が追加されます |
Web Unlockerゾーンが見つかりません |
Bright DataアカウントにWeb Unlockerゾーンがありません | Bright Data → プロキシとウェブスクレイピング → マイゾーン → Web Unlockerゾーンを作成してください |
SERP APIゾーンが見つかりません |
Bright DataアカウントにSERPゾーンがありません | Bright Data → プロキシとスクレイピング → マイゾーン → SERP APIゾーンを作成してください |
すべての URL でHTTP 403エラーが発生しています |
Web Unlockerの再試行回数が上限に達しました | 別のトピックを試してください – 一部のニッチなサイトでは厳格なボット対策が実施されています。詳細なオプションについては、CAPTCHAの回避方法をご確認ください |
Weaviateクラスターの準備ができていません |
サンドボックスの有効期限が切れました(14日間の制限) | Weaviateコンソールで新しいサンドボックスを作成し、.envを更新してください |
| Cohereモデルが利用不可 | command-a-03-2025またはembed-v4.0は廃止されました |
docs.cohere.com/docs/modelsで利用可能なモデルを確認し、setup_collection()内のmodel=パラメータを更新してください |
ModuleNotFoundError: 'weaviate' という名前のモジュールはありません |
依存関係がインストールされていません | プロジェクトディレクトリから `pip3 install -r requirements.txt` を実行してください |
エラーがリストにない場合は、完全な出力を確認してください。パイプラインは各ステップの詳細をログに記録しています。
ユースケース
このアーキテクチャはあらゆるトピックに適用可能です。いくつかの例を挙げます:
- 競合情報– トピック:「競合他社Xの価格戦略」。パイプラインは競合他社のウェブサイト、価格ページ、アナリストレポートをスクレイピングします。その後、「競合他社Xのエンタープライズ向け価格は当社と比べてどうなのか?」と質問します。
- 市場調査– トピック:「東南アジアのフィンテック動向」。地域のニュースや業界誌をスクレイピングし、「東南アジアで台頭している主要なフィンテックトレンドは何か?」といった質問を可能にします
- eコマース– トピック:「サステナブルファッション市場」。市場レポートや市場調査をスクレイピングします。「どのサステナブルファッションブランドが市場シェアを伸ばしているか?」
- 技術調査– トピック:「Kubernetesのセキュリティベストプラクティス」。技術ブログやセキュリティアドバイザリを収集するため、特定のCVEや設定ミスについて質問できます。
次に構築すべきもの
これは、以下の既知の制約がある動作するプロトタイプです:
- 実行ごとにコレクション全体が上書きされる(増分更新なし) – 差分比較を行うには
content_hashを使用してください - テキストのみを処理します。スクレイピングしたページ内の表、画像、PDFは除外されます
- Google検索でコンテンツを検索します。特定のURLがある場合は、
scrape_url()に直接渡してください - シングルユーザーCLIとして動作します
ここから、以下のことが可能です:
- スケジュール設定– cronジョブでパイプラインを実行し、ナレッジベースを最新の状態に保つ
- マルチテナント– 各顧客に独自の分離されたシャードを割り当てます(上記の「本番環境への移行」セクションを参照)
- 異なるデータソース– 構造化されたAmazonやLinkedInのデータにはBright DataWebスクレイパーAPIを、サイト全体のMarkdownデータにはCrawl APIを使用
- フロントエンド–
rag_query()をFlaskまたはFastAPIのエンドポイントでラップし、チャットUIを接続 - エージェント型RAG– いつ、何をスクレイピングするかを自律的に判断するエージェント型RAGシステムを構築する
- LangChain– 組み込みのチェーンオーケストレーションとメモリ機能を活用するため、Bright Data を使用してパイプラインをLangChainに移植
よくある質問
このパイプラインではどのようなトピックに対応していますか?
オープンウェブ上に記事が存在するトピックであれば何でも対応可能です。このパイプラインはBright DataのSERP APIを使用してGoogleでトピックを検索し、上位の結果をスクレイピングします。インデックス登録されたページが少ないニッチなトピックでは返される記事数が少なくなりますが、パイプラインは機能します。見つかった情報をそのまま使用します。
実行にかかる費用はいくらですか?
3つのサービスすべてで、無料で始められる方法を提供しています。Cohereのトライアルプランは無料で、クレジットカードも不要です。Weaviate Cloudは無料のサンドボックスクラスターを提供しており、Bright DataはSERP APIとWeb Unlockerの無料トライアルを提供しています。
別の埋め込みモデルやLLMを使用できますか?
はい。埋め込みと生成の両方について、setup_collection()内のモデルパラメータを変更してください。Weaviateは、Cohere、OpenAI、Google、Hugging Faceのベクトライザーを標準でサポートしています。切り替えるには、text2vec_cohere をtext2vec_openaiに置き換え、connect_weaviate()内のAPIキーヘッダーを更新し、パイプラインを再実行してください。
ナレッジベースを最新の状態に保つにはどうすればよいですか?
同じトピックでpipeline.py を再度実行してください。パイプラインは古いコレクションを削除し、新たにスクレイピングされたデータで新しいコレクションを作成します。本番環境では、content_hashチェックを追加して、変更されていないチャンクの再埋め込みをスキップするようにしてください。任意の間隔でデータを自動的に更新するために、パイプラインを cron ジョブでスケジュールしてください。
すでにスクレイピングするURLがある場合はどうすればよいですか?
SERP検出ステップをスキップしてください。collect_data()内で、find_articles_for_topic()の呼び出しを独自のURLリストに置き換え、各URLをscrape_url()に渡してください。パイプラインの残りの部分(チャンキング、エンベディング、クエリ)は通常通り動作します。
6件以上の記事をスクレイピングするにはどうすればよいですか?
find_articles_for_topic()の末尾にある[:6]のスライスを、より大きな数値(例:[:12])に変更してください。また、search_queriesリストに検索クエリを追加することで、より幅広い検索結果を取得することも可能です。記事数が増えるとスクレイピング時間が長くなり、チャンク数も増えますが、パイプラインの残りの処理は自動的に対応します。





