

この記事では、以下のことを学びます:
- 合成データが本当にAIおよびMLトレーニングの未来であるかどうか。
- リアルワールドのウェブデータとは何か、その主要な種類、および大規模に収集する方法。
- 合成データとは何か、どのように分類できるか、およびどのように正常に生成されるか。
- コスト、プライバシー、堅牢性、および分布品質の観点からの合成データとリアルデータの影響。
- データの選択がAIトレーニングパイプラインとモデルパフォーマンスに与える影響。
- 両方のデータタイプを組み合わせたハイブリッドアプローチがしばしば最も効果的な戦略である理由。
- 各アプローチのメリットとデメリット。
それでは、始めましょう。
合成データはAI/MLの未来か、それともウェブデータはまだ重要か?
AIスケーリング法則は、モデルがより多くのパラメータ、より多くの計算リソース、そして重要なことに、より多くのデータでトレーニングされると、パフォーマンスが向上する傾向があることを示しています。言い換えれば、大規模なモデルはパフォーマンスの向上を維持するために指数関数的に大規模なデータセットを必要とします。
歴史的に、リアルウェブデータは現代のAIトレーニングの基盤として機能してきましたが、高品質なウェブデータは有限です。著名なところでは、イーロン・マスクがAI企業がトレーニングデータを使い果たしたと述べ、モデルトレーニングに利用可能な人間の知識の総和を「使い果たした」と発言しました。
さらに、ウェブデータはますます重複が増え、収集、クリーニング、法的審査に費用がかかります。これはまた、AIに最適化され、定期的に更新され、プライバシーに準拠したデータセットを提供するウェブデータセットプロバイダーの選択の重要性を浮き彫りにしています。
これらの圧力は、代替データソース、特に合成データへの関心を加速させています。Gartnerによると、2030年までに合成データはAIモデルトレーニングにおいてリアルワールドデータを凌駕すると予想されています。同社はこの変化を、より厳格なプライバシー要件、リアルワールドデータの希少性、および法的・コンプライアンスリスクを軽減する低コストの代替手段を求める組織に起因するとしています。
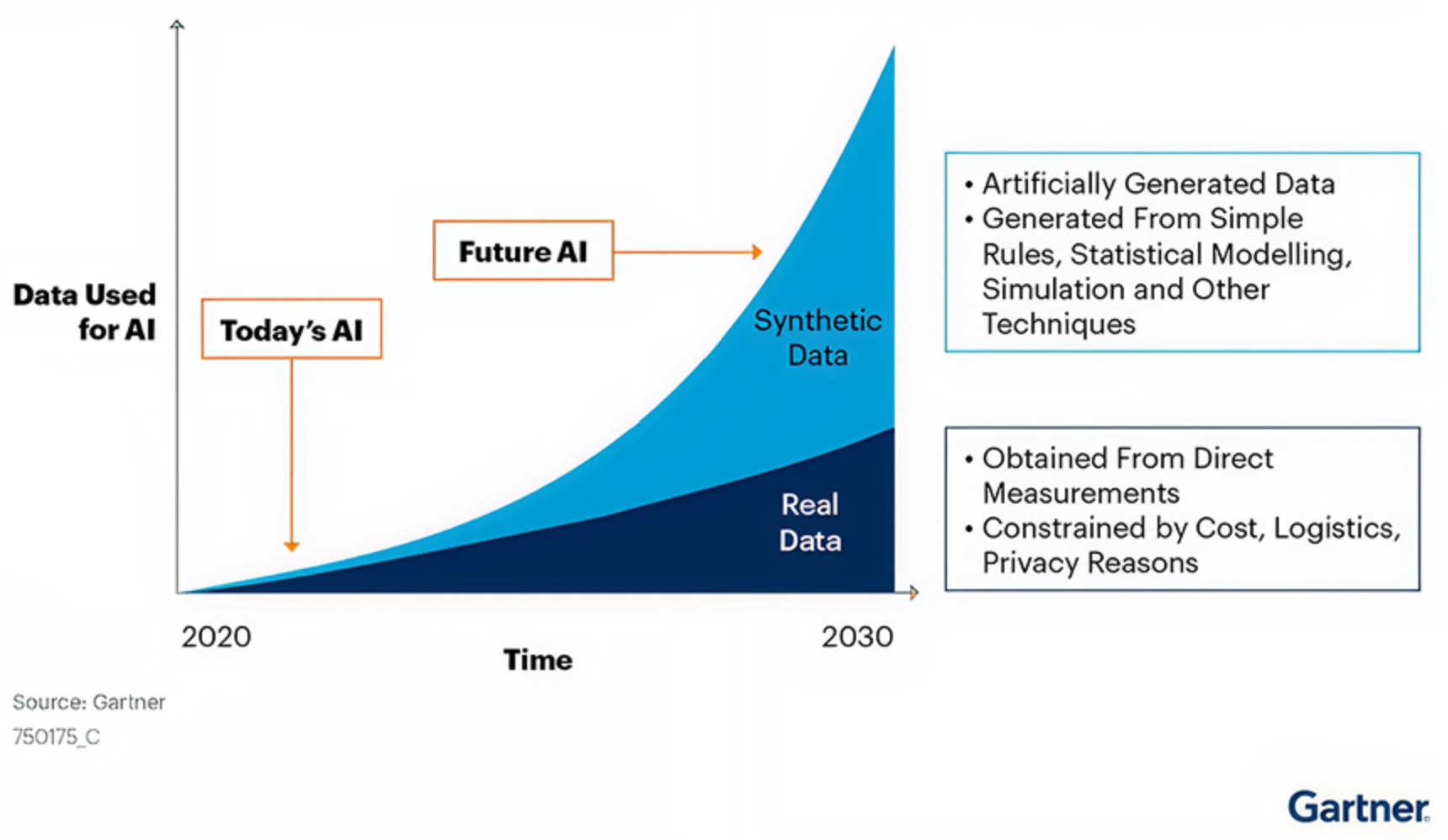
同時に、この予測は必然性ではなく推定として見るべきです。インターネットは依然として膨大な量のコンテンツを生成し続けており、毎日約4020億テラバイトのウェブデータが作成されています!
参考までに、GPT-3はフィルタリング前に約45テラバイトの生テキストでトレーニングされました。この比較は、ウェブスケールの人間生成データがAIトレーニングにとって依然として広大で非常に関連性が高いことを示唆しています。
その結果、AIトレーニングの未来は合成データのみに依存することはないでしょう。代わりに、多くの機械学習の専門家はハイブリッドアプローチを期待しており、この記事の後半で検討するトピックです。
合成データとリアルウェブデータ:2つのデータパラダイムの比較
以下の章では、合成データとリアルウェブデータとは何か、それらが何を提供するか、そしてAIモデルトレーニングの複数の側面でどのように比較されるかを学びます。より自然に理解しやすいリアルウェブデータから始め、次に合成データに移ります。
即座の高レベルな比較のために、以下の合成データとリアルウェブデータの表をご覧ください:
| リアルウェブデータ | 合成データ | |
|---|---|---|
| 定義 | リアルウェブソースから収集されたデータ | モデルやルールを使用してリアルワールドの分布を模倣する人工的に生成されたデータ |
| 例 | ウェブページ、フォーラム、ニュース記事、製品ページ、PDFなど | LLM生成テキスト、GAN画像、シミュレートされたロボット環境、ルールベースのデータセットなど |
| 主な目的 | リアルワールドの複雑さと自然な行動を捉える | スケール、カバレッジ、制御性を高める |
| データタイプ | 非構造化(テキスト、画像)、半構造化(JSON、XML) | 構造化、半構造化、非構造化(テキスト、画像、音声、動画) |
| 取得方法 | 主にウェブスクレイピング | LLM生成、GAN、VAE、ルールベースシステム、シミュレーションエンジン |
| プライバシーリスク | 高い(PII、コンプライアンスが必要) | 低い(適切に生成された場合、実ユーザーデータなし) |
| データ品質 | ノイズが多く、一貫性がないが、本物 | クリーンで構造化されているが、アーティファクトや幻覚が含まれる可能性あり |
| 分布 | 自然なリアルワールド分布 | 制御されているが、合成バイアスやシフトが生じる可能性あり |
| 堅牢性 | リアルワールド入力への強い汎化 | 特定シナリオに強いが、汎化は弱い |
| ロングテールカバレッジ | 自然に存在するが希少 | 明示的に生成してオーバーサンプリング可能 |
| バイアスリスク | リアルワールドのバイアスを反映 | 新たなバイアスを増幅または導入する可能性あり |
| 典型的なパイプラインの役割 | 事前トレーニング、ファインチューニング、評価 | 事前トレーニング、拡張、エッジケース生成 |
| リスク | データ希少性、コンプライアンス制約、ノイズ | 合成からリアルへのギャップ、モデル崩壊、幻覚パターン |
さあ、現代のAIトレーニングを形成する2つのコアデータパラダイムに飛び込む時間です!
リアルウェブデータの世界を探索する
ここでは、AIモデルトレーニングのためのリアルウェブデータについて知っておくべきことをすべてカバーします。
ウェブデータとは?
ウェブデータとは、主にウェブスクレイピングを通じてウェブページやその他の公開ウェブソースから収集された情報です。テキスト、画像、コード、メタデータ、ドキュメント(PDFなど)などの非構造化コンテンツ、およびJSONやXMLなどの半構造化データが含まれます。
ウェブデータの種類
ウェブデータには多くの可能なカテゴリがあります。それでも、特にAIの文脈では、高レベルで2つの主要なタイプを区別することが有用です:
- 過去のウェブデータ:通常、ウェブスクレイピングパイプラインを通じて収集され、クリーニング、エンリッチメント、重複排除、およびCSV、JSON、Parquetなどの形式の構造化データセットに集約されます。これらのデータセットはモデルの事前トレーニングとファインチューニングに使用されます。
- ライブウェブデータ:スクレイピングまたはAPIを通じてウェブページからリアルタイムで取得されます。インターネット上で利用可能な最新の情報を反映します。これにより、AIレスポンスのグラウンディングや、鮮度と事実の正確さが重要なRAGシステムに特に有用です。
これら2つの形式のウェブデータは、現代のAIシステムで補完的な役割を果たします。
ウェブデータの取得方法
AI/MLトレーニング用のウェブデータを取得するには、スケーラブルなウェブスクレイピングパイプラインが必要です。それを社内で構築するには、かなりのエンジニアリング専門知識が必要です。
IPブロッキング、CAPTCHAの解決、レートリミッターなど、さまざまなアンチスクレイピングの課題への対処が必要です。さらに、クリーニング、重複排除、正規化のための強力なデータエンジニアリング能力が求められます。その結果、企業はBright Dataなどの専用ウェブデータプラットフォームに依存することを好みます。
Bright Dataは、ウェブデータ収集と配信のためのエンドツーエンドのエコシステムを提供します。際立っているのは、195カ国にわたる4億以上のレジデンシャルプロキシネットワークであり、高度にスケーラブルで並行したウェブデータ収集をサポートします。このエンタープライズグレードのインフラは、GDPRおよびCCPAに準拠しており、その他のプライバシーおよびセキュリティ標準にも対応しています。
Bright Dataのウェブデータ向けサービスには以下が含まれます:
- ウェブデータマーケットプレイス:250以上のドメイン(Reddit、Amazon、LinkedIn、Yahoo Financeなど)をカバーする350以上のすぐに使えるデータセットのコレクション。これらのデータセットは17ペタバイト以上のウェブデータにわたり、MLトレーニングとAIアプリケーション向けに最適化されています。JSON、CSV、Parquetなどの複数の形式で、クラウド配信などの配布方法で提供されます。
- ウェブスクレイピング製品:ライブウェブデータ抽出のためのAPIベースのソリューションスイート:
– Web Unlocker API:ブロックとCAPTCHAをバイパスして、あらゆるウェブページへのデータアクセスを確保します。
– SERP API:Google、Bing、Yandexなどからの構造化されたリアルタイム検索エンジン結果を提供します。
– Discover API:ダウンストリーム処理に対応した、公開ウェブからランク付けされたライブURLセットを返します。
– Crawl API:スケーラブルなウェブサイトクローリングと構造化データ抽出を実行します。
– スクレイパーAPI:人気ドメインからの直接的な構造化データ抽出のために120以上のウェブサイトをカバーします。
Bright Dataはまた、ターンキーデータ取得のためのマネージドサービスも提供しています。これにより、組織はデータエンジニアリングではなくモデル開発に集中できます。
合成データの領域に入る
この章では、AI/MLモデルトレーニングのための合成データの使用について探ります。
合成データとは?
合成データとは、リアルワールドデータの統計的パターンと特性を複製する人工的に生成された情報です。実際のイベントから収集されるのではなく、人工的に生成されます。
合成データの種類
合成データは以下のように分類できます:
- 構成とプライバシーレベル別:
– 完全合成:リアルデータでトレーニングされた機械学習モデルを使用してゼロから生成されます。元のデータポイントが含まれないため、最高レベルのプライバシー保護を提供します。
– 部分合成:既存のリアルデータセットを取り、名前、住所、社会保障番号などの機密属性のみを人工的な値に置き換えます。特定のデータトレンドを保持しながらPIIを匿名化します。
– ハイブリッド:リアルな匿名化されたレコードと人工的に生成されたレコードを混合します。これは、レアイベントを人工的に作成することでデータセットを「アップサンプリング」またはエンリッチするために一般的に使用されます(例:バンキングデータセットへの合成詐欺レコードの追加)。
- データ構造別:
– 構造化データ:表形式で提示された高度に整理された定量的データ。
– 非構造化データ:定性的またはメディアヘビーなデータ形式。合成テキスト、人工的に生成された画像、動画、音声が含まれます。
合成データの生成方法
高レベルでは、合成データは3つの主要なアプローチを使用して生成できます:
- 完全AI生成:GAN(敵対的生成ネットワーク)、VAE(変分オートエンコーダー)、またはLLMなどのモデルを使用して作成されます。これらのシステムはリアルデータセットの基礎となる分布を学習し、元のデータを直接コピーせずに元のデータに似た完全に新しいサンプルを生成します。
- ルールベース生成:事前定義された人間が書いたルール、制約、またはビジネスロジックを使用してデータが生成されます。これにより、厳格な一貫性、構造的な正確さ、および制御された動作が確保され、予測可能な出力を必要とするシステムに有用です。
- シミュレートまたはモックデータ:物理的または行動シミュレーションを通じて生成されます。これは、デジタルツインと物理エンジンが現実的な「仮想」シナリオを作成する自律走行やロボティクスなどの環境で一般的に使用されます。
AI/MLモデルトレーニングにおける合成データとリアルウェブデータの影響
AIトレーニングに合成データとリアルウェブデータを使用した結果を理解するために、いくつかの側面を比較してみましょう。
データ分布とリアリズム
ウェブデータは自然なデータ分布に近似しています。リアルワールドに現れる人間の言語と行動の固有の複雑さを捉えます。これにより、特徴間の自然な相関関係、本物のエッジケース、多様な言語スタイル、人間のミス、曖昧さ、不一致などのリアルなノイズなど、重要なメリットがもたらされます。
しかし、リアルワールドのウェブデータは本質的に雑然としています。しばしば不均衡で重複しており、大規模にキュレーションが難しく、大規模なフィルタリングを必要とする低品質またはスパムコンテンツが含まれている場合があります。
対照的に、合成データは制御された分布を表します。意図的に設計・生成されており、実践者がデータセットのプロパティを正確な方法で形成できます。これにより、バランスのとれたクラス分布、特定シナリオの標的カバレッジ、レアイベントの生成、および構造化されたカリキュラム学習が可能になります。
同時に、合成データは分布シフト、非現実的なアーティファクト、モード崩壊、ジェネレーターが過度に制約されている場合の過剰正則化などの重要なリスクをもたらします。
重要:この点に関する中心的な機械学習の概念は、ロボティクスにおけるsim-to-real問題に類似した合成からリアルへのギャップです。合成データで大量にトレーニングされたモデルは、生成された分布が現実と完全に一致しないため、リアルな入力でパフォーマンスが低下する可能性があります。
ロングテールカバレッジ
リアルウェブデータは自然に幅広い知識を含んでいます。これには、人間の活動から有機的に生まれる曖昧な事実、レアイベント、および予期しないエッジケースが含まれます。しかし、これらのロングテールの例は本質的に希少です。定義上、レアイベントは頻繁に現れないため、トレーニング中にモデルがそれらから堅牢なパターンを学習することが難しくなります。
一方、合成データを使用してレアまたは過小表現されたシナリオを明示的に生成できます。そうすることで、データセット内の特定のギャップを標的にし、リアルデータが不十分なカバレッジを改善できます。例としては、レアなコーディングバグや低リソース言語が挙げられます。
ロングテールカバレッジのために合成データを使用する主な利点は、レアイベントをオーバーサンプリングできることです。これにより、クラスの不均衡を減らし、頻度は低いが重要なケースでのモデルパフォーマンスを改善できます。それでも、レアシナリオが人工的に過剰表現されると、モデルの学習した事前確率が歪む可能性があります。
例えば、サイバーセキュリティのエクスプロイトケースが合成データで大量にオーバーサンプリングされると、モデルはリアルワールドの設定でその可能性を過剰予測し始める可能性があります。その結果、合成ロングテール生成が非現実的な分布を導入せずにカバレッジを改善するために、慎重なキャリブレーションが不可欠です。
コストとプライバシーの考慮事項
前述のように、企業が独自のウェブスクレイピングおよびデータセットインフラを構築することはほとんどありません。代わりに、クローリング、アンブロッキング、クリーニング、配信を抽象化するBright Dataなどのサードパーティデータプロバイダーに依存します。これにより、データ取得のコスト構造とプライバシーのトレードオフが根本的に変わります。
以下は、ウェブデータ収集のためのBright Dataの価格モデルの簡略概要です:
| 価格 | エンタープライズ向けカスタムプラン | GDPR準拠 | CCPA準拠 | SEC規制準拠 | |
|---|---|---|---|---|---|
| データセット | レコードあたり$0.001〜$0.0025 | ✔️ | ✔️ | ✔️ | ✔️ |
| ウェブスクレイピングAPI | 1K結果あたり$1〜$1.5 | ✔️ | ✔️ | ✔️ | ✔️ |
Bright Dataはまた、データアノテーションサービスも提供しており、組織が社内データエンジニアリングへの依存を減らすのに役立ちます。重要なことに、そのデータはプライバシーフレームワークに準拠しており、法的および規制リスクの軽減に役立ちます。
このようなウェブデータプロバイダーなしでは、インフラ開発、継続的なメンテナンス、およびPII、著作権のある素材、機密行動データの複雑なガバナンスを社内で処理する必要があります。
合成データの場合、主なコストは推論計算と教師モデルまたはAPIへのアクセスから生じます。プライバシーの観点から、人工的に生成されたデータは固有の利点を提供します。実際の個人から収集されるのではなく生成されるため、合成データは個人を特定できる情報へのエクスポージャーを自然に排除します。
合成データとリアルウェブデータの間の正しい選択は、品質要件、スケール、プライバシー制約、および対象ユースケースによって異なります。これらの要因に応じて、どちらのアプローチも他方よりもコスト効率が高い場合も、高くなる場合もあります。
データ品質要因
ウェブデータは一般的に弱い監督を提供します。モデルは、次のトークン予測、メタデータ、および人間が生成したコンテンツなど、自然に発生するシグナルから学習します。問題は、リアルデータはノイズが多く、誤情報、矛盾、スパム、偏った意見、一貫性のない書式設定が含まれる可能性があることです。
逆に、合成データは品質と監督に対してより大きな制御を提供します。完全にフォーマットされたラベル、構造化された出力、ステップバイステップの推論、および自動検証された例を提供できます。例えば、合成データセットには数学的に検証された回答や単体テストを通じて検証されたコードスニペットを含めることができます。これにより一貫性が向上し、ターゲットトレーニングが容易になります。
合成データの主なリスクは、その品質が生成モデル、アルゴリズム、または基礎となるアプローチの品質によって根本的に制限されることです。生成された幻覚や事実の誤りが最終的なデータセットに伝播し、モデルが自信を持って誤ったパターンを学習する原因となる可能性があります。同様に、生成システムに存在する隠れたバイアスも、下流のモデルに継承される可能性があります。明るい面では、合成データはより強力なアライメントと安全性チューニングをサポートします。
汎化と堅牢性
機械学習において最も重要な問題の一つは、モデルが未見の入力にどれだけうまく汎化するかです。言い換えれば、分布シフト下でより良い堅牢性をもたらすデータソースはどちらか:リアルワールドのウェブデータか合成データか?
ウェブデータは、自然に発生する人間の行動、言語、ノイズを反映しているため、強い堅牢性を達成する傾向があります。これにより、分布外入力でのパフォーマンスが向上し、特にモデルが予測不可能な環境に展開される場合のドメイン転送が強化されます。
代わりに、合成データは標的最適化により適しています。特定のスキル、エッジケース、またはレアシナリオのためのトレーニング例を正確に考案できます。
合成データまたはリアルウェブデータでAIをトレーニングする際の主要な考慮事項
合成データとウェブデータの違いを理解したので、AIモデルトレーニングで各アプローチを使用する実際的な意味を見る準備ができました。
データトレーニングパイプライン
ウェブデータに依存する場合、パイプラインは通常以下のステップに従います:
- クローリング:大規模なスクレイピングシステムまたはカスタムウェブスクレイピングボットを使用して、複数のドメインからウェブサイトの生データを収集します。
- 重複排除:重複または類似コンテンツを削除して冗長性を減らし、データセットの多様性と効率を向上させます。
- 言語検出:各サンプルの言語を識別し、対象言語要件に基づいてデータセットをフィルタリングまたはセグメント化します。
- 品質スコアリング:ヒューリスティックまたはモデルを使用してコンテンツを評価およびランク付けし、低品質または無関係な情報をフィルタリングします。
- 毒性フィルタリング:有害、安全でない、または不適切なコンテンツを検出および削除して、トレーニングの安全性とコンプライアンスを確保します。
- PII削除と汚染除去:個人を特定できる情報を削除し、機密または不要なソースからの汚染を排除します。
合成データパイプラインに関しては、ステップはより生成に焦点を当てています:
- プロンプト生成:合成データ作成の構造、タスク、またはシナリオを定義するプロンプトまたはテンプレートを設計します。
- モデルサンプリング:LLM、GAN、またはその他のシステムなどの生成モデルを使用して候補出力を生成します。
- 検証:自動チェック、ルール、または外部ツールを使用して出力を検証し、正確性と一貫性を確保します。
- フィルタリング:事前定義された基準を満たさない低品質、一貫性のない、または幻覚されたサンプルを削除します。
- 報酬スコアリング:最良の合成例をランク付けして選択するために品質または好みスコアを割り当てます。
- 反復的改良:生成、フィルタリング、再サンプリングの繰り返しサイクルを通じてデータ品質を改善し、堅牢性を高めます。
お分かりのように、リアルウェブデータパイプラインはノイズの多いリアルワールド入力のクリーニングに焦点を当てています。代わりに、合成パイプラインは生成された出力の制御と検証に関するものです。最後に、トレーニングデータセットが作成されたら、AIモデルのトレーニングに進むことができます。
パフォーマンス比較
最終的な質問は、合成データがリアルワールドのウェブデータを上回ることができるかどうかです。
要件エンジニアリングのためのAI(AI4RE)の最近の論文は、リアルデータが希少または取得困難な場合、LLM生成データセットが強力な代替手段となり得ることを示唆しています。実証的な結果は、合成データのみでトレーニングされたモデルが、人間が作成したデータセットのみでトレーニングされたモデルを上回ることができることを示しています。詳細には、リアルデータのみのベースラインと比較して、精度で最大+37%、再現率で+30%の改善が観察されました。
とはいえ、これは二項対立または絶対的な結論ではありません。証拠は合成データがリアルデータを完全に置き換えるべきだということを示唆するのではなく、むしろ最高のパフォーマンスはしばしばハイブリッドアプローチによって達成されることを示しています。詳しく見てみましょう!
合成データ+リアルワールドウェブデータ:ハイブリッドアプローチが最も効果的な理由
合成データとリアルワールドウェブデータの議論は、どちらか一方を選ぶことではなく、どのように組み合わせるかについてになっています。
最近の証拠は、合成データとリアルデータを組み合わせたハイブリッド構成が、リアルワールドウェブデータのみを使用した場合と比較して、精度で最大+85%の向上と再現率の2倍化を達成することを示しています。
同時に、複数の研究と業界レポートは、合成サンプルとリアルサンプルを単純に混合すると、分布の不一致、冗長性、またはバイアスの増幅により、実際にパフォーマンスが低下する可能性があることを強調しています。これにより、パフォーマンスの向上は単純なデータ蓄積ではなく、慎重なデータセット設計に依存することが明確になります。
重要なオープンな質問は、合成データとリアルデータの最適な比率です。普遍的な答えはありません。一部の実践者はパレート式80/20分割(主にリアルデータに合成拡張)を採用し、他の人はタスクの複雑さ、ドメインリスク、データの可用性に応じて60/40などのよりバランスの取れた混合を好みます。
同様に、パイプラインにおける合成データの配置も重要です。業界の実践は段階的な戦略を導いています:カバレッジのための合成ヘビーな事前トレーニング、続いてグラウンディングと評価のためのリアルデータファインチューニング。
最終的に、ハイブリッドパイプラインが最も効果的な理由は、補完的な強みを組み合わせるからです。合成データはスケールとエッジケースカバレッジを提供し、リアルウェブデータは本番環境での忠実度、リアリズム、および信頼性の高い評価を確保します。
リアルウェブデータと合成データ:メリットとデメリット
まとめのセクションとして、2つのデータパラダイムの利点と欠点をご覧ください。
リアルウェブデータ
👍 メリット:
- 本物のリアルワールドパターンとノイズを捉える
- 評価と検証のための強力なベンチマーク
- 合成バイアスやアーティファクトのリスクを軽減
👎 デメリット:
- 収集とラベリングにコストと時間がかかる
- プライバシーおよび規制上の制約によって制限される可能性がある
- 不均衡または不完全な場合がある
合成データ
👍 メリット:
- 高度にスケーラブルで生成が速い
- レアイベントとエッジケースをシミュレートできる
- プライバシー保護トレーニングパイプラインをサポート
👎 デメリット:
- リアルワールドデータとのドメインギャップのリスク
- 慎重な検証と品質管理が必要
- リアルデータと比較して多様性が欠如し、合成アーティファクトへの過学習につながる可能性がある
リアルウェブデータ+合成データ
👍 メリット:
- スケール(合成)とリアリズム(リアルデータ)を組み合わせる
- 実際には最高のパフォーマンスを達成することが多い
- エッジケースと通常ケース全体でより強い堅牢性
👎 デメリット:
- 比率の慎重なバランス調整とチューニングが必要
- 不適切に混合するとパフォーマンスが低下するリスク
- より複雑なパイプライン設計とメンテナンス
まとめ
この合成データとリアルウェブデータのブログ記事では、AI/MLモデルトレーニングにリアルワールドまたは人工的に生成されたデータを使用することの影響を学びました。このような状況では常にそうであるように、単一の勝者はいません。正しいアプローチは、特定の予算、技術的スキル、およびパフォーマンス目標によって異なります。
どのような設定であっても、ウェブデータは事前トレーニングまたは最終ファインチューニングのいずれかで、AIモデルトレーニングにおいて中心的な役割を果たし続けています。その広範なカバレッジとリアルワールドのグラウンディングは不可欠です。しかし、一部の企業はより合成ヘビーなアプローチを選択することを好みます。主な理由は、社内でウェブデータ取得パイプラインを構築・維持することの複雑さです。
これがBright Dataが役立てる部分です。エンタープライズグレードの高スケーラブルで準拠したインフラで、以下を提供します:
- ウェブデータセット:AIトレーニングのユースケース向けにすでに収集、キュレーション、最適化された数十億のレコードを持つ350以上の既製データセット。
- ウェブスクレイピング製品:多くのサイトから大規模に新鮮なウェブデータにアクセスするためのAPIベースのソリューション。
さらに、Bright Dataはデータアノテーションサービスを提供しています。NLP、コンピュータビジョン、および音声認識のユースケース向けにスケーラブルで正確かつカスタマイズ可能なラベリングソリューションを提供します。
AIのためのBright Dataのすべてのソリューションをご覧ください!
無料でBright Dataアカウントを作成し、ウェブデータソリューションをご体験ください!






